") Kafka工作流程及文件存儲(chǔ)機(jī)制
Kafka工作流程及文件存儲(chǔ)機(jī)制

【Kafka】Kafka 架構(gòu)深入
Kafka工作流程及文件存儲(chǔ)機(jī)制
Kafka 中消息是以topic進(jìn)行分類的,生產(chǎn)者生產(chǎn)消息,消費(fèi)者消費(fèi)消息,都是面向 topic 的。
topic 是邏輯上的概念,而 partition 是物理上的概念,每個(gè) partition 對(duì)應(yīng)于一個(gè) log 文件,該 log 文件中存儲(chǔ)的就是 producer 生產(chǎn)的數(shù)據(jù)。Producer 生產(chǎn)的數(shù)據(jù)會(huì)被不斷追加到該 log 文件末端,且每條數(shù)據(jù)都有自己的 offset。 消費(fèi)者組中的每個(gè)消費(fèi)者,都會(huì)實(shí)時(shí)記錄自己消費(fèi)到了哪個(gè) offset,以便出錯(cuò)恢復(fù)時(shí),從上次的位置繼續(xù)消費(fèi)。
由于生產(chǎn)者生產(chǎn)的消息會(huì)不斷追加到 log 文件末尾,為防止 log 文件過大導(dǎo)致數(shù)據(jù)定位效率低下,Kafka 采取了分片和索引機(jī)制,將每個(gè) partition 分為多個(gè) segment。每個(gè) segment 對(duì)應(yīng)兩個(gè)文件:“.index” 文件和 “.log” 文件。這些文件位于一個(gè)文件夾下,該文件夾的命名規(guī)則為:topic名稱+分區(qū)序號(hào)。
例如,test 這個(gè) topic 有三個(gè)分區(qū), 則其對(duì)應(yīng)的文件夾為 test-0、test-1、test-2。
index 和 log 文件以當(dāng)前 segment 的第一條消息的 offset 命名
“.index” 文件存儲(chǔ)大量的索引信息,“.log” 文件存儲(chǔ)大量的數(shù)據(jù),索引文件中的元數(shù)據(jù)指向?qū)?yīng)數(shù)據(jù)文件中 message 的物理偏移地址
數(shù)據(jù)可靠性保證
為保證 producer 發(fā)送的數(shù)據(jù),能可靠的發(fā)送到指定的 topic,topic 的每個(gè) partition 收到 producer 發(fā)送的數(shù)據(jù)后, 都需要向 producer 發(fā)送 ack(acknowledgement 確認(rèn)收到),如果 producer 收到 ack,就會(huì)進(jìn)行下一輪的發(fā)送,否則重新發(fā)送數(shù)據(jù)。
數(shù)據(jù)一致性問題
LEO:指的是每個(gè)副本最大的 offset;
HW:指的是消費(fèi)者能見到的最大的 offset,所有副本中最小的 LEO
1)follower 故障
follower 發(fā)生故障后會(huì)被臨時(shí)踢出 ISR(Leader 維護(hù)的一個(gè)和 Leader 保持同步的 Follower 集合),待該 follower 恢復(fù)后,follower 會(huì)讀取本地磁盤記錄的上次的 HW,并將 log 文件高于 HW 的部分截取掉,從 HW 開始向 leader 進(jìn)行同步。等該 follower 的 LEO 大于等于該 Partition 的 HW,即 follower 追上 leader 之后,就可以重新加入 ISR 了。
2)leader 故障
leader 發(fā)生故障之后,會(huì)從 ISR 中選出一個(gè)新的 leader, 之后,為保證多個(gè)副本之間的數(shù)據(jù)一致性,其余的 follower 會(huì)先將各自的 log 文件高于 HW 的部分截掉,然后從新的 leader 同步數(shù)據(jù)。
注:這只能保證副本之間的數(shù)據(jù)一致性,并不能保證數(shù)據(jù)不丟失或者不重復(fù)。
ack 應(yīng)答機(jī)制
對(duì)于某些不太重要的數(shù)據(jù),對(duì)數(shù)據(jù)的可靠性要求不是很高,能夠容忍數(shù)據(jù)的少量丟失,所以沒必要等 ISR 中的 follower 全部接收成功。所以 Kafka 為用戶提供了三種可靠性級(jí)別,用戶根據(jù)對(duì)可靠性和延遲的要求進(jìn)行權(quán)衡選擇。
當(dāng) producer 向 leader 發(fā)送數(shù)據(jù)時(shí),可以通過 request.required.acks 參數(shù)來設(shè)置數(shù)據(jù)可靠性的級(jí)別:
●0:這意味著producer無需等待來自broker的確認(rèn)而繼續(xù)發(fā)送下一批消息。這種情況下數(shù)據(jù)傳輸效率最高,但是數(shù)據(jù)可靠性確是最低的。當(dāng)broker故障時(shí)有可能丟失數(shù)據(jù)。
●1(默認(rèn)配置):這意味著producer在ISR中的leader已成功收到的數(shù)據(jù)并得到確認(rèn)后發(fā)送下一條message。如果在follower同步成功之前l(fā)eader故障,那么將會(huì)丟失數(shù)據(jù)。
●-1(或者是all):producer需要等待ISR中的所有follower都確認(rèn)接收到數(shù)據(jù)后才算一次發(fā)送完成,可靠性最高。但是如果在 follower 同步完成后,broker 發(fā)送ack 之前,leader 發(fā)生故障,那么會(huì)造成數(shù)據(jù)重復(fù)。
三種機(jī)制性能依次遞減,數(shù)據(jù)可靠性依次遞增。
注:在 0.11 版本以前的Kafka,對(duì)此是無能為力的,只能保證數(shù)據(jù)不丟失,再在下游消費(fèi)者對(duì)數(shù)據(jù)做全局去重。在 0.11 及以后版本的 Kafka,引入了一項(xiàng)重大特性:冪等性。所謂的冪等性就是指 Producer 不論向 Server 發(fā)送多少次重復(fù)數(shù)據(jù), Server 端都只會(huì)持久化一條。
Filebeat+Kafka+ELK
確保node1 上有安裝apache服務(wù)來產(chǎn)生日志
環(huán)境準(zhǔn)備
node1:192.168.67.11 elasticsearch kibana node2:192.168.67.12 elasticsearch apache:192.168.67.10 logstash apache/nginx/mysql Filebeat節(jié)點(diǎn):filebeat/192.168.67.13 Filebeat zk-kfk01:192.168.67.21 zookeeper、kafka zk-kfk02:192.168.67.22 zookeeper、kafka zk-kfk03:192.168.67.23 zookeeper、kafka systemctl stop firewalld systemctl enable firewalld setenforce 0
1、部署 Zookeeper+Kafka 集群
重啟服務(wù)
systemctl restart elasticsearch.service netstat -antp | grep 9200 cd /usr/local/src/elasticsearch-head/ npm run start &
2、部署 Filebeat
cd /etc/filebeat #cd /usr/local/filebeat vim filebeat.yml filebeat.prospectors: - type: log enabled: true paths: - /var/log/httpd/access_log tags: ["access"] - type: log enabled: true paths: - /var/log/httpd/error_log tags: ["error"] ...... #添加輸出到 Kafka 的配置 output.kafka: enabled: true #指定 Kafka 集群配置 hosts: ["192.168.67.21:9092","192.168.67.22:9092","192.168.67.23:9092"] #指定 Kafka 的 topic topic: "httpd"
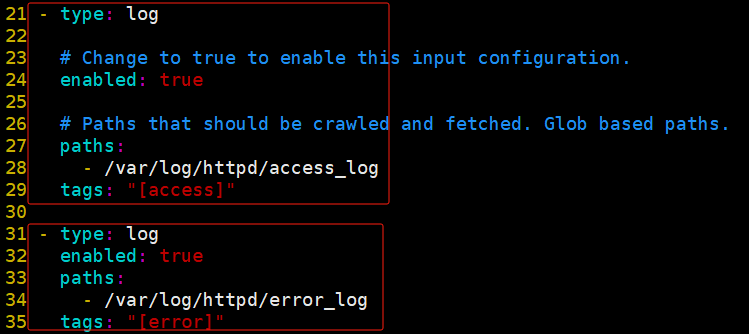
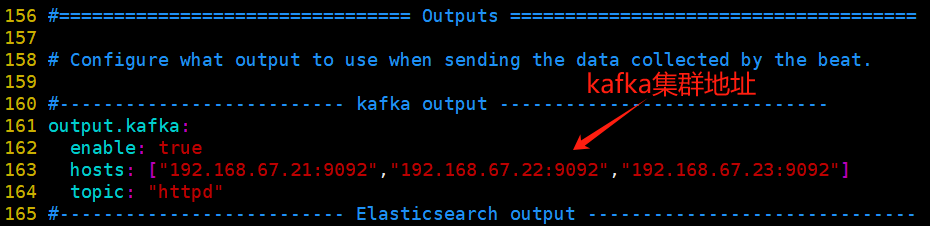
注釋掉logstash出口,留下kafka出口;出口只能有一個(gè)

啟動(dòng) filebeat
systemctl restart filebeat.service systemctl status filebeat.service # ./filebeat -e -c filebeat.yml

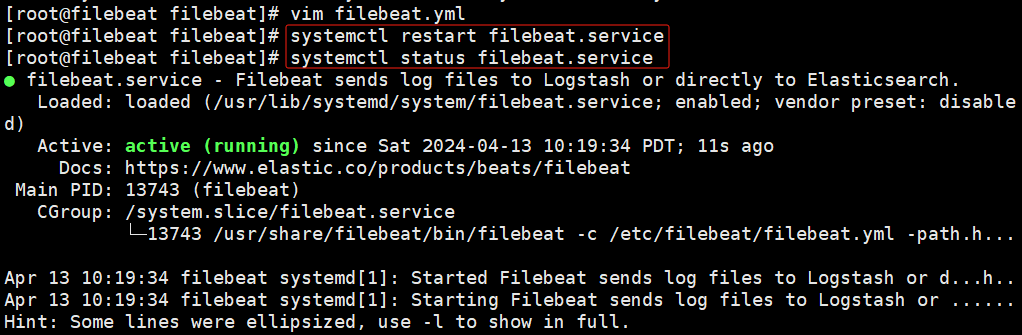
報(bào)錯(cuò):服務(wù)起不來;查看日志;

原因:是filebeat.yml中將日志同時(shí)輸出到了kafka和logstash
解決:注釋掉logstash即可
3、部署 ELK,在 Logstash 組件所在節(jié)點(diǎn)上新建一個(gè) Logstash 配置文件
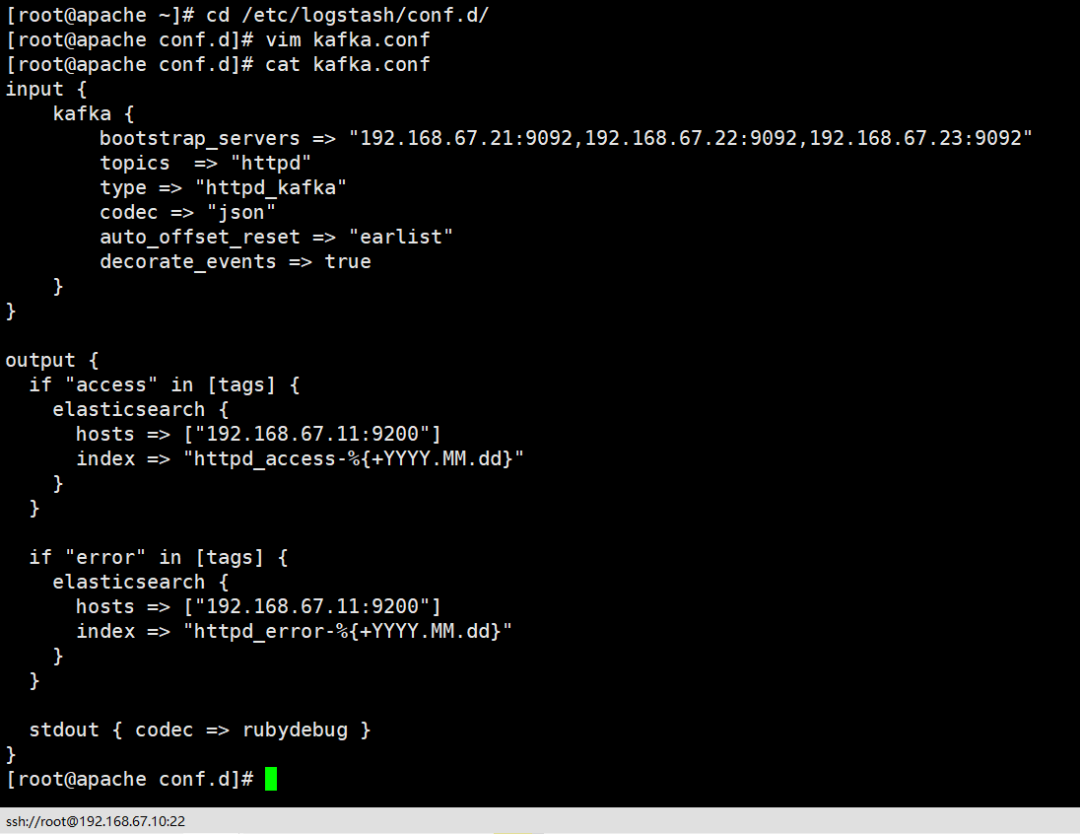
cd /etc/logstash/conf.d/
vim kafka.conf
input {
kafka {
#kafka集群地址
bootstrap_servers => "192.168.67.21:9092,192.168.67.22:9092,192.168.67.23:9092"
#拉取的kafka的指定topic
topics => "httpd"
#指定 type 字段
type => "httpd_kafka"
#解析json格式的日志數(shù)據(jù)
codec => "json"
#拉取最近數(shù)據(jù),earliest為從頭開始拉取
auto_offset_reset => "latest"
#傳遞給elasticsearch的數(shù)據(jù)額外增加kafka的屬性數(shù)據(jù)
decorate_events => true
}
}
output {
if "access" in [tags] {
elasticsearch {
hosts => ["192.168.67.11:9200"]
index => "httpd_access-%{+YYYY.MM.dd}"
}
}
if "error" in [tags] {
elasticsearch {
hosts => ["192.168.67.11:9200"]
index => "httpd_error-%{+YYYY.MM.dd}"
}
}
stdout { codec => rubydebug }
}
啟動(dòng) logstash
`logstash -f kafka.conf`
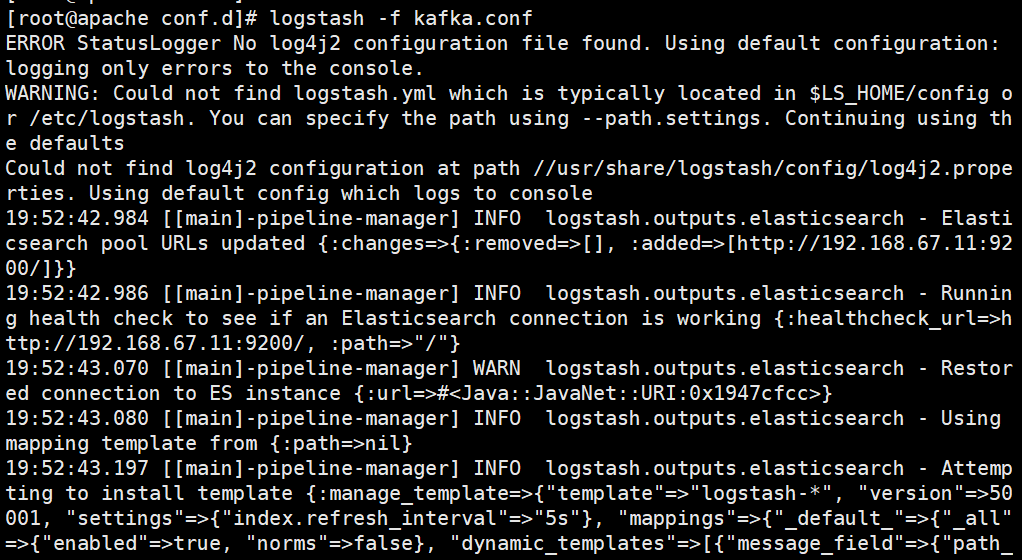
報(bào)錯(cuò):路徑重復(fù)
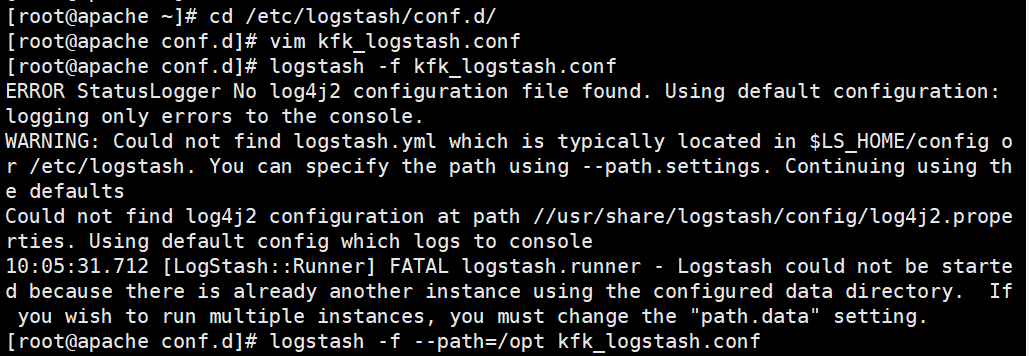
解決:指定一個(gè)新的路徑
`logstash -f kafka.conf --path.data=/opt`
報(bào)錯(cuò):配置文件有錯(cuò)
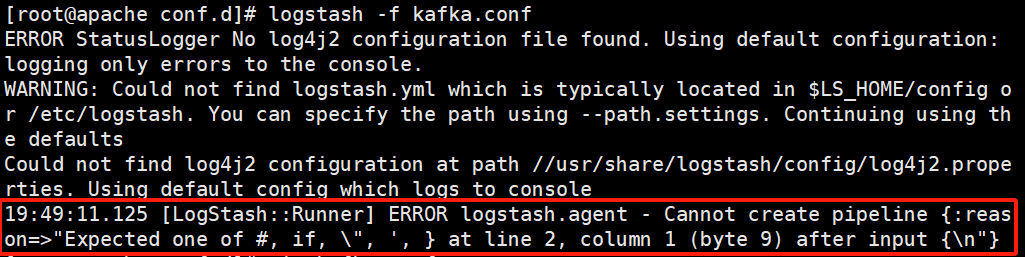
解決:配置文件刪了重寫
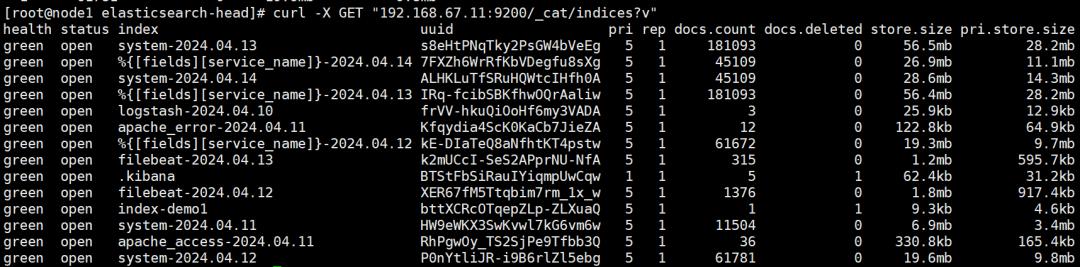
注:生產(chǎn)黑屏操作es時(shí)查看所有的索引:
`curl -XGET"192.168.67.11:9200/_cat/indices?v"`
4、瀏覽器訪問
`http://192.168.67.11:9100`
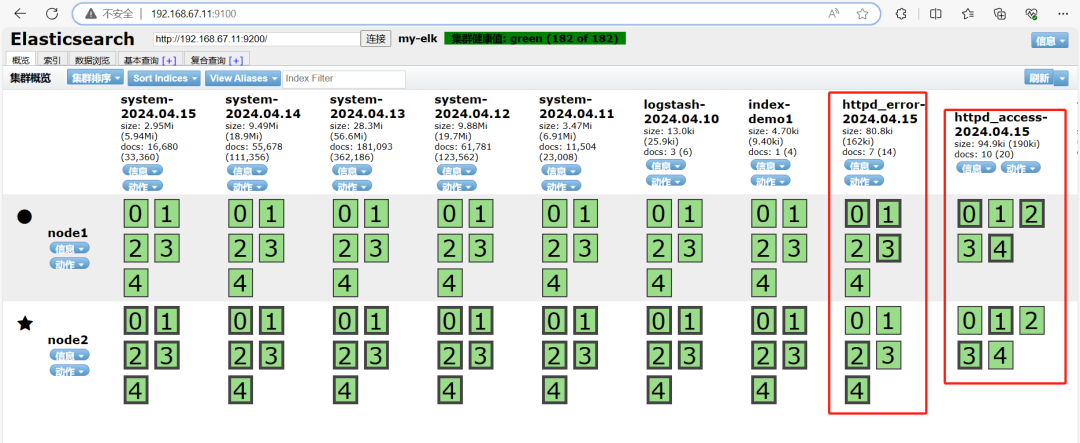
`http://192.168.67.11:5601/`
訪問一下apache再訪問9100
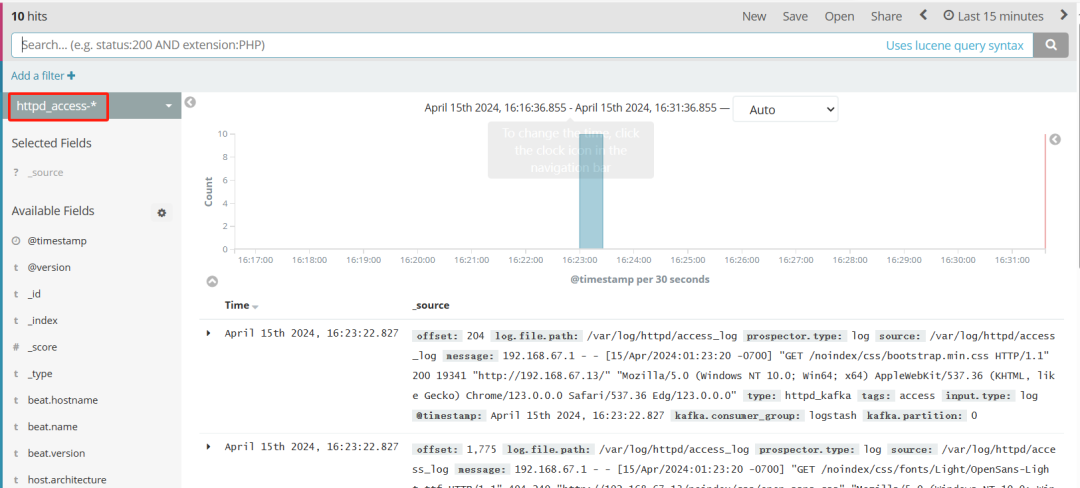
瀏覽器訪問 http://192.168.67.11:5601 登錄 Kibana,單擊“Create Index Pattern”按鈕添加索引“httpd_access-*”,單擊 “create” 按鈕創(chuàng)建,單擊 “Discover” 按鈕可查看圖表信息及日志信息。 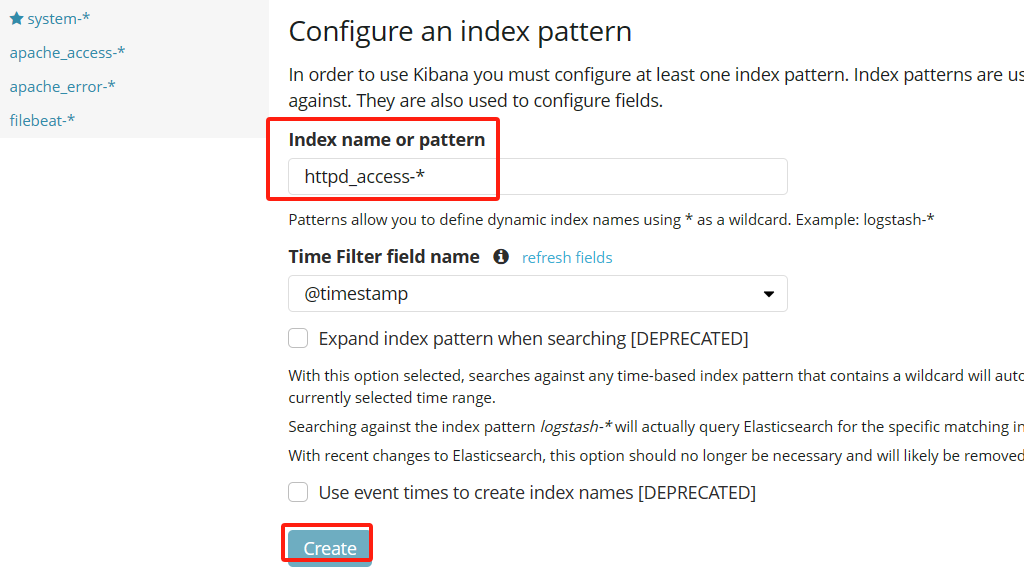
鏈接:https://blog.csdn.net/Mo_nor/article/details/137711958?spm=1001.2014.3001.5502
-
數(shù)據(jù)
+關(guān)注
關(guān)注
8文章
7256瀏覽量
91857 -
文件存儲(chǔ)
+關(guān)注
關(guān)注
0文章
17瀏覽量
10707 -
kafka
+關(guān)注
關(guān)注
0文章
54瀏覽量
5401
原文標(biāo)題:【Kafka】深度解析:高吞吐、低延遲背后的架構(gòu)奧秘?
文章出處:【微信號(hào):magedu-Linux,微信公眾號(hào):馬哥Linux運(yùn)維】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
電氣CAD文件中高效的工作流程
Kafka存儲(chǔ)機(jī)制詳解
SIwave 3.0 工作流程簡介
Kafka文件存儲(chǔ)機(jī)制分析
略談kafka的存儲(chǔ)機(jī)制
測試工程師工作流程有哪些
工作流程圖怎么用?有哪些繪制工作流程圖的軟件
Kafka框架的工作原理及工作流程

虹科方案|使用 HK-TRUENAS支持媒體和娛樂工作流程-2

NX CAD軟件:數(shù)字化工作流程解決方案(CAD工作流程)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論