 AI時代企業需要怎樣的數據存儲
AI時代企業需要怎樣的數據存儲
作者:周立旸
IBM 大中華區科技事業部存儲軟件產品總監
隨著 DeepSeek 等新一代開源大模型的發布,AI 變得越來越智能,使用更少的資源就能夠創造更高的應用價值,越來越多的企業都正在由內而外、由淺入深地部署各種 AI 應用。從更大的視角看,市場的不確定性進一步加劇企業的“算力焦慮”,如何盤活現有計算資源、打通內部數據已經成為 CIO、CTO 們的當務之急。
在今年 1月的 CES 大會上,英偉達等科技公司認為 AI 發展至今,已經需要新的定律來描述不同的計算資源配置如何影響模型性能,包括預訓練擴展、后訓練擴展和測試時擴展 (也稱為長思考)。在強化學習、模型調優以及運用 AI 推理模型階段,企業能夠用更小的算力增加來獲得更智能、更強大的 AI。為了防范數據泄露風險,大多用戶采用了本地化部署的 AI 基礎設施來進行應用開發和調優,并通過思維鏈和多模型矩陣來優化 AI 推理效果。這些算力集群不僅需要對應的高性能分布式存儲,更需要與之匹配的現代化數據訪問和管理服務。
企業為什么需要 AI 存儲?
當我們問 DeepSeek “AI 時代需要哪種存儲”,它給出了如下答案:
具體到真實的企業應用場景,AI 存儲解決方案需要應對如下挑戰:
昂貴的 GPU 資源:許多用戶投入了巨額資金來購買一體機和算力平臺,需要存儲方案縮短 AI 開發的時間、提升推理應用的效率,更快地獲得所需的結果;
分散的 AI 數據:AI 需要實時、可信的數據才能發揮作用,企業端的應用更是需要結合企業自有的歷史和實時數據。這需要企業有效地整合非結構化數據,在需要的時間和地點交付數據,為各種 AI 應用提供透明的數據訪問;
不斷增加的存儲成本:伴隨數據量的不斷增大,企業需要消除數據孤島,實現數據生命周期管理,用更低的成本實現更高性能的數據訪問和更大容量的數據保留,通過智能化的數據分層降低總體開銷;
確保數據安全合規:隨著數據成為關鍵生產要素,企業需要更安全的手段和更嚴格的規定來抵御安全風險、自然災害和人為錯誤,確保數據一直可用;同時實現網絡安全彈性,在勒索攻擊等事件發生后快速恢復數據,確保業務持續性。
AI 時代,企業需要怎樣的數據存儲?
以 DeepSeek 為代表的“小而美”開源模型,通過算法層面的優化實現了可觀的“降本增效”。那么,基礎架構層面的優化能否滿足以上需求,帶來更大收益呢?
答案是肯定的。得益于在高性能計算和并行計算領域的長期積累,IBM 的 AI 數據存儲解決方案可以提供優化的數據基礎架構,包括:
加速 AI 發現和 GPU 的數據訪問:IBM Storage Scale 軟件可以并行訪問全局數據,幫助實現協議互通 (如容器、對象、文件、POSIX 等),支持 NVIDIA GPUDirect 提升 GPU 數據訪問效率,通過“容器原生數據訪問”為各種 AI 應用和微服務提供更高性能;
增強基于分布式/云數據的協同工作:IBM 的全局數據平臺可以實現存儲抽象和加速能力,將企業分布的數據整合為統一的數據資源,實現自動化的數據加速和透明的遠程數據訪問,全局訪問位于磁帶、云或現有存儲資源上的數據來幫助消除數據孤島;
綠色節能,降低成本:通過 IBM 軟件定義存儲強大的數據調度能力,結合高性能存儲、對象存儲(如 Ceph)和磁帶存儲實現基于策略的數據分層,可以為 AI 應用優化數據存儲的性能和成本;
實現數據安全彈性:為 AI 治理提供集成的數據目錄,為實現網絡安全彈性提供快速恢復和 Safeguarded Copy(不可變副本),通過高效的數據保護機制可以提供高達6個 9 的可用性。
AI 存儲的應用場景
以上技術的集合將為企業打造更高效、更安全的存儲平臺,以解鎖數據價值,應對 AI 時代的數據挑戰。典型場景包括:
AI 調優、推理與訓練:其中,用于調優和推理的系統往往采用容器化部署,需要豐富的數據管理功能和接口,同時提供企業級的安全容災能力支持業務連續性;用于訓練的系統需要能支持大規模 GPU 集群運行所需的讀寫性能和擴展能力。采用高效的數據存儲可以實現數據加速,提升應用效率。
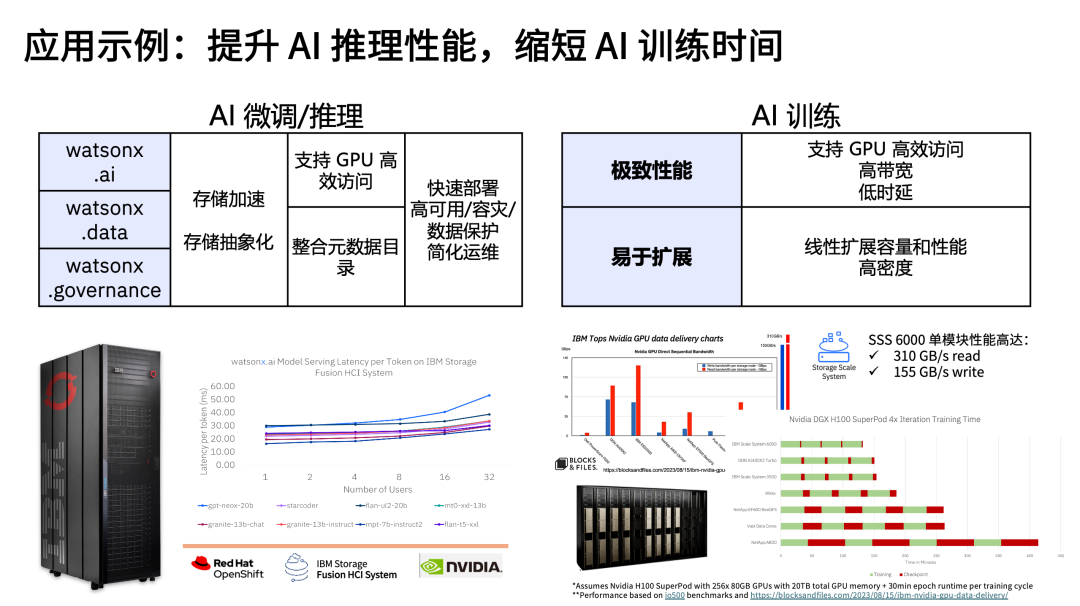
以 IBM watsonx.ai 平臺為例,IBM 配備了 AI 一體機 IBM Fusion HCI,其后臺采用 IBM 軟件定義的高性能存儲,可以滿足不同規模大模型部署的需求,同時確保在幾十乃至上百個用戶并發訪問的情況下,維持穩定的 token 輸出速度來滿足推理應用的服務水平。
在 AI 訓練領域,全球許多千卡萬卡的大集群都采用了 IBM 的 AI 存儲,例如部署在德國尤里希超級計算中心的 JUPITER、部署在西班牙巴塞羅那超算中心的 MareNostrum 5、IBM 用于訓練 Granite 模型的 Blue Vela 等等。基于英偉達 SuperPOD 的測試結果顯示,采用同樣數量的節點訓練同樣的模型,采用 IBM SSS 6000 高性能并行存儲的 4個迭代訓練時間,比基于全 NVMe 的 NAS 整整縮短一倍。對于一個投入幾千萬甚至是幾億的基礎設施來講,這意味著經濟成本的巨大節約。
在國內,某智能駕駛應用的領軍企業、某頭部量化私募基金以及某高校的冷凍電鏡項目都選擇了 IBM Storage Scale System,在多云環境中打造統一的全局數據平臺,同時快速響應數據調度需求,實現高效開發迭代和系統管理。
AI 數據湖倉
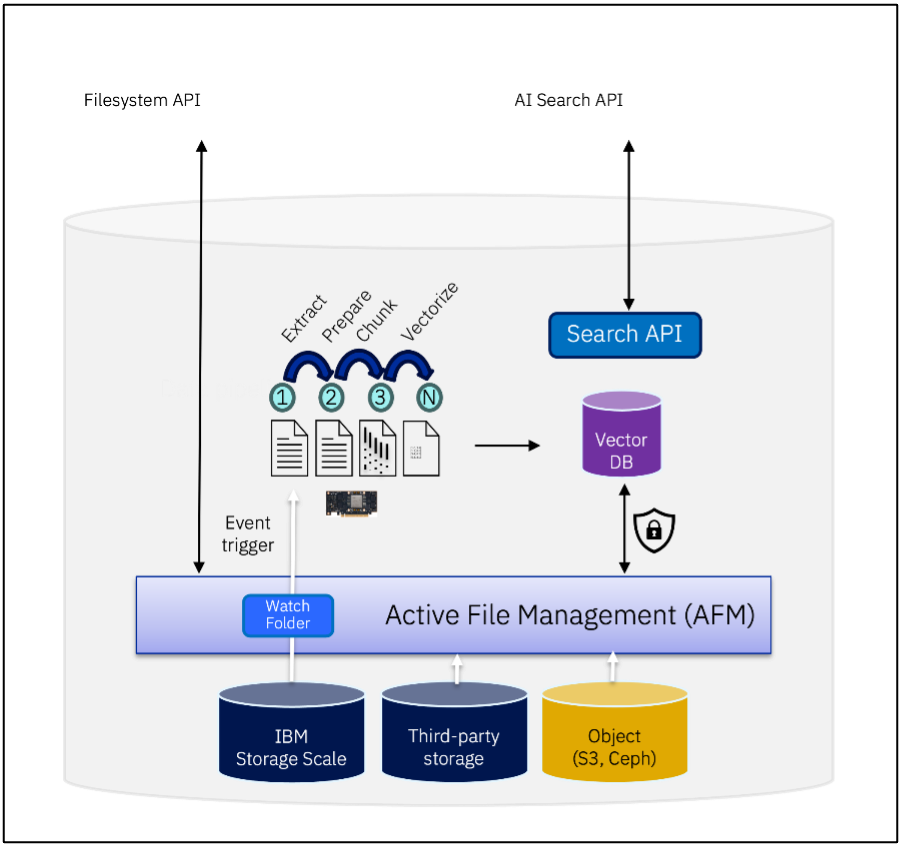
伴隨 AI 應用的飛速發展,企業需要從快速增長的非結構化數據中提取洞察并用于推理,不斷擴展檢索增強生成(RAG)、AI 推理等應用場景。AI 數據湖倉可以在不影響信任和安全的前提下,提供更實時、更可信的數據訪問。以汽車制造為例,車企客戶可以通過車聯網實時收集和整理車載傳感器的數據,用于開發更智能的模型,并利用這些數據為用戶提供更好的服務。
基于 IBM 全局數據平臺強大的混合云支持能力和靈活的容器應用接口,以及對多應用多集群的多租戶的支持能力,用戶可以整合現有數據存儲,為數據構建高效的 AI 數據管道。今年,IBM 還開發了新一代內容感知存儲 (Content-aware Storage) 功能,以增強其檢索增強生成 (RAG) 能力來幫助用戶加速各種推理應用。
數據深度歸檔
隨著 AI 應用的拓展,企業對數據的安全性、可靠性、合規性的要求也不斷提高,需要采用更安全、更低成本的存儲來大幅降低數據保留的成本。
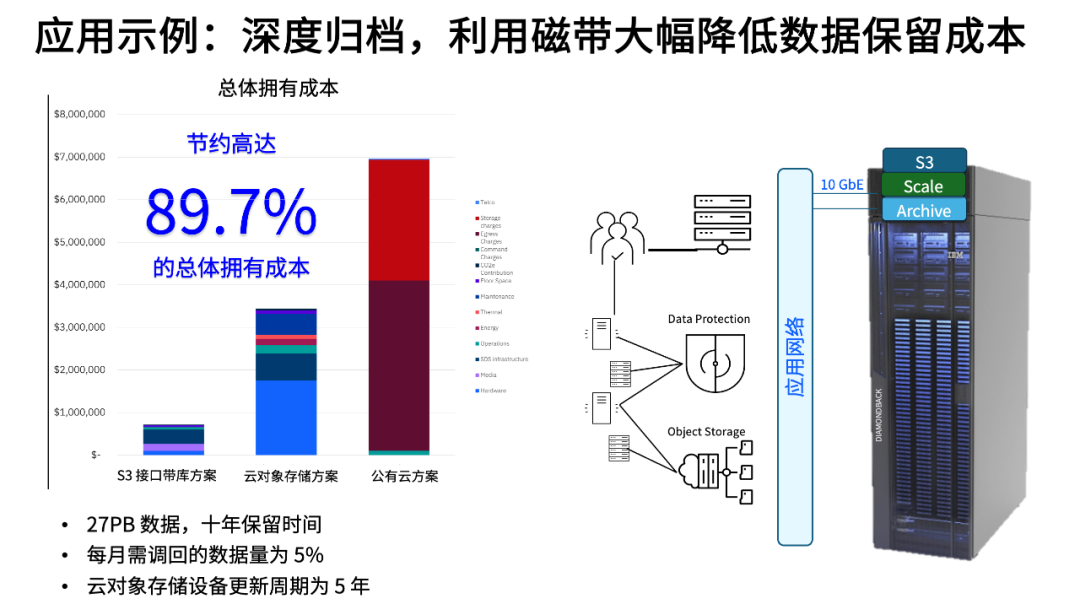
通過IBM 軟件定義存儲技術,IBM 磁帶庫可以提供 S3 接口,讓企業可以使用對象存儲或者公有云存儲一樣的方式實現數據歸檔。磁帶的大容量、低成本等優勢,可以大幅降低 PB 級別數據的長期保留成本。例如,采用 IBM Diamondback 的深度歸檔方案,27PB 數據的 10年保留成本比公有云存儲降低近 90%。
寫在最后
在 Gartner 發布的 2024年分布式文件和對象存儲魔力象限中,IBM 第九次被評為領導者,大量金融、汽車、電子等行業的全球領先企業都采用了 IBM AI 存儲解決方案。通過和全球 AI 技術領導者的合作,IBM 將持續創新,提供現代化、開放、安全的數據基礎架構,助力客戶在 AI 時代解鎖更多商業價值。
關于 IBM
IBM 是全球領先的混合云、人工智能及企業服務提供商,幫助超過 175個國家和地區的客戶,從其擁有的數據中獲取商業洞察,簡化業務流程,降低成本,并獲得行業競爭優勢。金融服務、電信和醫療健康等關鍵基礎設施領域的超過 4000家政府和企業實體依靠 IBM 混合云平臺和紅帽 OpenShift 快速、高效、安全地實現數字化轉型。IBM 在人工智能、量子計算、行業云解決方案和企業服務方面的突破性創新為我們的客戶提供了開放和靈活的選擇。對企業誠信、透明治理、社會責任、包容文化和服務精神的長期承諾是 IBM 業務發展的基石。
-
IBM
+關注
關注
3文章
1808瀏覽量
75457 -
AI
+關注
關注
87文章
34197瀏覽量
275355 -
大模型
+關注
關注
2文章
3025瀏覽量
3825 -
DeepSeek
+關注
關注
1文章
773瀏覽量
1336
原文標題:IBM 專家觀點:假如 DeepSeek 們使用了 IBM AI 存儲
文章出處:【微信號:IBMGCG,微信公眾號:IBM中國】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
AI驅動新型存儲器技術,國內新興存儲企業進階

數智化時代,數據存儲“進化論”該如何書寫?


華為加速AI時代數據存儲產業發展
英偉達GTC2025亮點:NVIDIA與行業領先存儲企業共同推出面向AI時代的新型企業基礎設施
NVIDIA 與行業領先的存儲企業共同推出面向 AI 時代的新型企業基礎設施

數字化時代的存儲變革:閃迪引領AI應用的數據支持

當我問DeepSeek AI爆發時代的FPGA是否重要?答案是......
AI賦能邊緣網關:開啟智能時代的新藍海
AI存儲瓶頸破解之道,西部數據用前沿技術持續引領存儲革命
大模型時代的算力需求

平衡創新與倫理:AI時代的隱私保護和算法公平
AI時代,我們需要怎樣的數據中心?AI重新定義數據中心






 工商網監
工商網監
評論