 3D網格重建學習:單一角度預測物體3D結構的框架
3D網格重建學習:單一角度預測物體3D結構的框架
看到一張圖片,我們很容易就能猜測出圖中物體的立體模樣,但是機器能做到嗎?美國加州大學伯克利分校的研究人員就開發了一個框架,讓機器通過一張圖片就能還原出立體原型,并添加自然的紋理圖案。以下是論智對原論文的編譯,后附論文地址和實驗結果展示視頻。
我們開發了一種學習框架,能夠通過一張圖片還原圖中物體的3D形狀、攝像角度及紋理。形狀用可變形的3D網格模型表示。
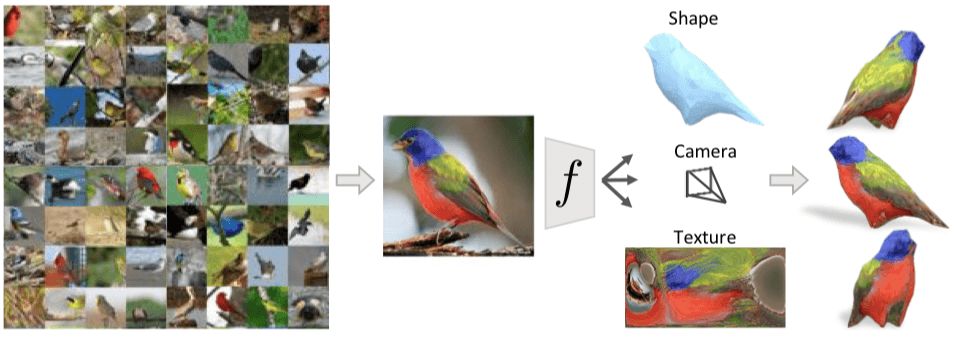
上圖中有許多小鳥,即使我們是第一次看到這種圖片上二維的鳥類,我們依然能推斷出它大概的3D形狀、了解拍攝的角度、甚至能猜出從另一個角度看它會是什么樣。我們能做到這些是因為之前我們見過的鳥類能讓我們對陌生小鳥有個大致輪廓,這些知識幫助我們還原這些案例的3D結構。
在這篇文章中,我們展示了一個能根據單張圖片推斷3D表示的計算模型,如上圖所示,學習過程只需要一張標注過的2D圖像,其中包括目標對象的類別、前景掩碼和語義重點標簽。
我們的目標是生成一個預測器fθ(參數化設置為一個CNN),它可以從單張照片I中推斷出目標物體的3D結構。在這個項目中我們希望將物體的形狀用3D網格表示,這種表示比其他方法(比如probabilistic volumetric grids)有更多優點,例如可對紋理進行模擬、進行相應的推理、表面水平推理和可解釋性。
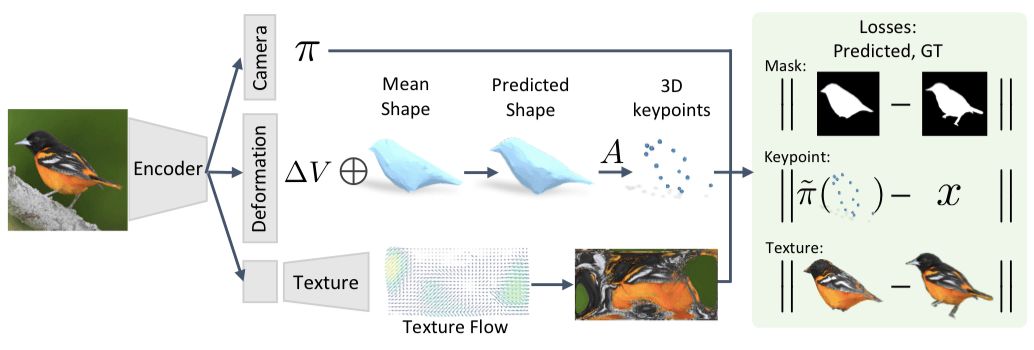
我們提出的框架如下圖所示。輸入的圖像通過一個編碼器后到達由三個模塊組成的表征,它可以預測相機位置、物體形狀和花紋的參數。
用模型推斷目標物的3D表示
首先,給定一張圖像I,我們預測fθ(I)≡(M, π),網格M和相機位置π用來捕捉對象的3D結構。具體的推導過程可查看原論文。除了這些直接預測的方面,我們還學習了網格和類別水平語義重點之間的關系。當我們在規范框架中使用特定類別的網格來表示形狀時,跨實例的規律能幫助我們找到語義一致的定點位置,從而隱含地賦予這些頂點語義。
經過這一步,我們就利用一張圖片I推斷出了相應的相機位置π和形狀?V。同時,我們還通過學習實例獨立的參數。推斷出了網格定點的位置V和語義重點A·V。
從圖像集合中學習
為了訓練fθ,我們提出了一種不依賴于實際3D形狀和多角度圖像實例的監督的方法,而是從帶有稀疏關鍵點和分割掩碼的圖像集中進行學習。這種設置更加自然,并且容易獲得,特別是對會動和可變形的物體,例如鳥類或其他動物。想要獲取對象的掃描件甚至同一物體多個角度的照片是非常困難的,但對于大多數物體來說,獲取單張圖像相對更容易。
有了帶注釋的圖像集,我們通過制定一個目標函數來訓練fθ,該函數包含和實例相關的損失和先驗。具體的實例能量術語(energy terms)可以保證預測的3D結構與現有的掩碼和關鍵點一致,并且先驗知識能幫助生成一些特征,例如光滑性。由于我們從許多實例中得到了通用的預測模型fθ,那么各個種類之間的通用結構也能讓我們從中得到有意義的3D預測,即使只有一個實例。
插入圖案預測
在我們的公式中,所有復原的形狀都有著共同的3D網格結構——每種形狀都是平均形狀的變形。我們可以利用這一屬性來減少特定實例中的圖案以預測平均圖案的形狀。我們的平均形狀是個球體,它的表面圖案可以表示成一張名為Iuv的圖像,其值通過固定的UV映射映射到表面上(類似于將地球展開成平面圖)。
于是,我們將預測圖案的這個任務看作是推斷Iuv的像素值。該圖像可以被認為是屬于目標物體類別的典型外觀空間。例如,預測形狀中的特殊三角形總是會映射到Iuv中的特定區域,不管它如何變形。
將圖案參數化之后,UV圖像中每個像素的語義含義都一致,從而使預測模型更容易利用通用模式,例如鳥背和身體之間的相關性。
我們通過設置一個解碼器,將圖案預測模塊添加到框架中,該解碼器可以將潛在表示轉換成Iuv的空間向量。雖然直接用回歸計算Iuv的像素值是一種可行的方法,但這通常會導致模糊圖像的產生。相反,我們將此任務看成預測外觀流,我們不回歸Iuv像素的值,而是讓模塊輸出從原始輸入圖像復制來的像素顏色。如圖所示:
實驗過程
模型設置好后,我們選擇CUB-200-2011數據集做實驗,該數據集有6000張訓練和測試圖像,包括了200種鳥類。每張圖片都有邊界框進行標注,另外還有14個語義關鍵點標注出了位置,同時還顯示出了前景的掩碼。我們從中挑選了近300張圖像,其中每張圖的關鍵點少于或等于6個。另外預測網絡的各個模塊示意圖如圖2所示,編碼器由一個在ImageNet上預訓練的ResNet-18組成,緊接著是一個卷積層。
最終在CUB測試集上得到的重建結果如圖所示:
論文附錄和文后視頻中會有360度全景展示。
另外,我們還對目標物體的圖案進行了替換,將一張圖上的紋理替換到預測形狀上去。我們發現,即使兩個視角可能不同,由于基礎的紋理圖像在空間上是一致的,所轉換的紋理在語義上也是一致的。
除此之外,我們還在PASCAL 3D+數據集上對車和飛機做了同樣的實驗,預測的形狀通常都很正常,不過圖案會出現較多錯誤,因為汽車上有反光的地方或是訓練數據較少:
結語
我們展示了可以從單一角度預測物體3D結構的框架。雖然這項結果非常令人興奮,但是我們并沒有提出一個通用的解決方案。最后,雖然我們只能使用實例的單一視圖進行學習,但對于有多個視圖的場景來說,我們的方法可能同樣適用,并產生更好的結果。
-
編碼器
+關注
關注
45文章
3775瀏覽量
137131 -
3D
+關注
關注
9文章
2951瀏覽量
109443
原文標題:讓平面變立體——特定類別3D網格重建學習
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
3D掃描的結構光
3D打印的優勢
PYNQ框架下如何快速完成3D數據重建
浩辰3D的「3D打印」你會用嗎?3D打印教程
使用結構光的3D掃描介紹
從榮耀角度解讀3D識別的結構光、TOF及雙目立體成像方案
淺析3D結構光技術

3D視覺主要技術路徑 3D結構光技術原理
大規模3D重建的Power Bundle Adjustment
基于未知物體進行6D追蹤和3D重建的方法

生成高質量 3D 網格,從重建到生成式 AI






 工商網監
工商網監
評論