 Python 爬取CSDN的極客頭條
Python 爬取CSDN的極客頭條
這兩周花了點時間讀了《Python網絡數據采集》,內容不多,不到200頁,但是非常豐富,有入門,有提高,有注意事項,有經驗之談,有原理,有分析,讀完受益匪淺。書中講了很多反爬蟲、圖片驗證碼之類的東西,不過感謝csdn的開放性,這些都沒有。所以第一個練習,就是爬取csdn的極客頭條的更新文章。
1、思路
思路比較簡單,首先是登錄,然后爬取頁面的更新文章名稱和鏈接。要注意的一點是,極客頭條的列表刷新是動態的,只有頁面有滾動條并且往下拉的時候,才會加載新的文章列表。我用豎屏顯示器試了下,沒有滾動條的情況下,默認顯示20條的文章列表,結果不能加載新的文章列表,應該算是bug。
2、準備
通過瀏覽器的開發人員工具抓包,可以發現極客頭條申請新列表的時候URL格式如下:
http://geek.csdn.net/service/news/get_news_list?jsonpcallback=jQuery203014439105321047596_1516862462757&username=[賬戶名]&from=-&size=20&type=hackernewsv2_new&_=1516862462758
請求參數:
jsonpcallback:
jQuery20302827217349787545_1516863701413 #該參數是jQuery框架自動生成的匿名回調函數的函數名,用于ajax獲取數據時的數據處理,看網頁源代碼,應該是利用getJSON,所以是頁面端生成的參數,可以隨意填寫
username: [賬戶名]
from:
6:252765 #這個參數代表的是下一次請求文章列表時,文章的起始編號,如果是第一次請求列表,則這里填‘-’(短杠),和上面例子中一樣,下次編號會在本次請求返回的JSON數據中攜帶
size:
20 #本次請求的文章條目數,我試過1000都成功了。。。
type:
hackernewsv2_new #文章類型,類型在首頁的“最熱 最新 業界”等等那一行小標題,選擇的分類不同,這個參數不同,具體抓包可見
_:
1516863701415 #沒什么用,就是第一個參數下短杠后面的數字累加,實際測試沒有也可以
通過查找資料和抓包,發現csdn的登錄還是很簡單的,只要用戶名密碼,不需要驗證碼等等,抓包可以看到請求參數:
gps:
39.890503,116.431339
username:
[賬戶名]
password:
[密碼] #抓包的話這里是明碼,發出去的話應該是加密的
rememberMe:
true #是否記住密碼
lt:
LT-448149-vgNusKFi3i7wBRIZUrzCFLDfoDVP34 #這個參數是在登錄主頁面中的,需要自己解析出來,數值隨機,每次登錄需要獲取
execution:
e3s1 #目前是固定值,和網文對比這個值不同,所以還是每次登錄獲取的好
_eventId:
submit #固定值,就是代表提交
登錄時要注意的是,csdn為了防爬蟲,要求HTTP頭的User-Agent字段必須是真實的,所以我用了抓包里面真實的瀏覽器填充的字段,否則會一直登錄失敗,返回登錄頁。
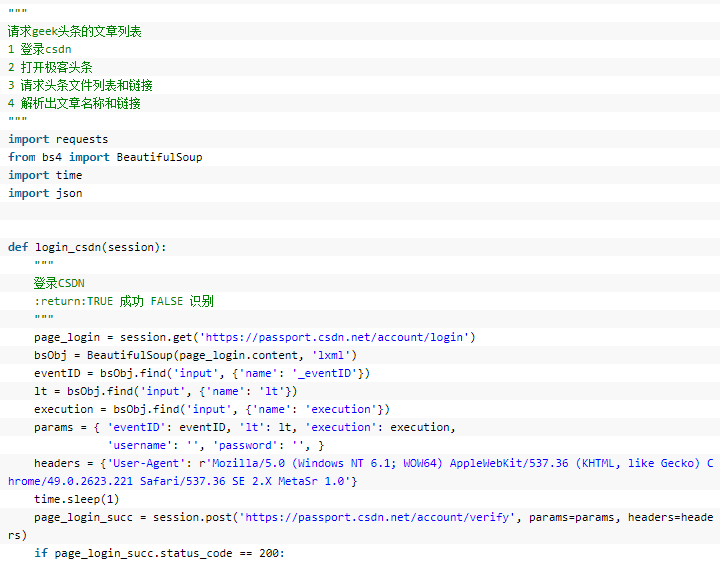
通過抓包可以看到,請求文章后,返回的是json數據,其中‘from’自動用于下次請求,‘html’字段就是返回的網頁,utf-8編碼的Unicode字符串,Python默認用的就是Unicode,所以取出html字段的數據后自動轉為了漢字、符號等,然后解析其中的class類型為‘title’的鏈接,就可以獲得文章鏈接和名稱。
3、代碼(非常短)


-
python
+關注
關注
56文章
4825瀏覽量
86175 -
csdn
+關注
關注
2文章
17瀏覽量
6972
原文標題:Python 爬取CSDN的極客頭條
文章出處:【微信號:magedu-Linux,微信公眾號:馬哥Linux運維】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
python實現網頁爬蟲爬取圖片
百度92年程序員因“篡改數據”被抓
python基礎語法及流程控制
豆瓣電影Top250信息爬取
Python如何爬取實時變化的WebSocket數據

華為發布麒麟 990 芯片;蘋果召回部分電源插頭轉換器;KDevelop 5.4.2 發布? | 極客頭條...






 工商網監
工商網監
評論