 基于事件相機的統一幀插值與自適應去模糊框架(REFID)
基于事件相機的統一幀插值與自適應去模糊框架(REFID)

01
研究成果概述
在光照不足的環境下實現動態場景的清晰、高幀率視頻是經典成像領域的難題。近日,浙江大學光電科學與工程學院汪凱巍、白劍教授團隊聯合蘇黎世聯邦理工等國外科研團隊,為行業提供了基于事件相機(一種仿生傳感器)的解決方案。團隊提出了一種基于事件相機的統一幀插值與自適應去模糊框架(REFID)。該框架基于雙向遞歸網絡,結合事件流和圖像信息,自適應地融合來自不同時間點的信息,從而能夠在模糊的輸入幀情況下同步實現高質量的插幀與模糊圖像還原。此外,研究團隊還發布了高分辨率事件-視頻數據集 HighREV,為事件相機低級視覺任務提供了新的測試基準。
相關研究成果以“A Unified Framework for Event-based Frame Interpolation with Ad-hoc Deblurring in the Wild”為題于發表于人工智能領域頂級期刊IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) 。
02
研究背景
發明歷史超過60年的數字圖像傳感器,本質上是基于光子積分原理的:當我們打開快門時,每個像元上發生光電轉換將光子轉化為電子實現圖像信息記錄,每完成一輪累積就輸出一幅圖(幀)。然而,當在光線不足的環境中拍攝動態場景時,由于需要長時間打開快門累積足夠的光子會帶來“運動模糊”,同時也無法獲得高幀率視頻。
最近十年逐漸被行業關注的事件相機是一種類生物視覺傳感器,它的輸出不依賴光子累積,因而具有高時間分辨率(微秒級)和高動態范圍(超過140dB)的優勢,能夠捕捉傳統幀相機無法記錄的快速運動信息。因此,將事件信息與傳統圖像傳感器融合,指導每一幀圖像去除運動模糊,同時通過幀與幀之間的事件信息進行插值,有望同步實現暗光下的高幀率和清晰成像。
03
研究亮點
1
提出統一的事件相機幀插值與去模糊框架(REFID),能夠同時對銳利的視頻和模糊的視頻進行插幀。如圖1所示
?采用雙向遞歸網絡(bidirectional recurrent network),充分利用時間維度信息,在插值過程中自適應去模糊。
?設計了事件引導的自適應通道注意力模塊(EGACA),動態調整事件流與圖像信息的融合權重,提升插值質量。
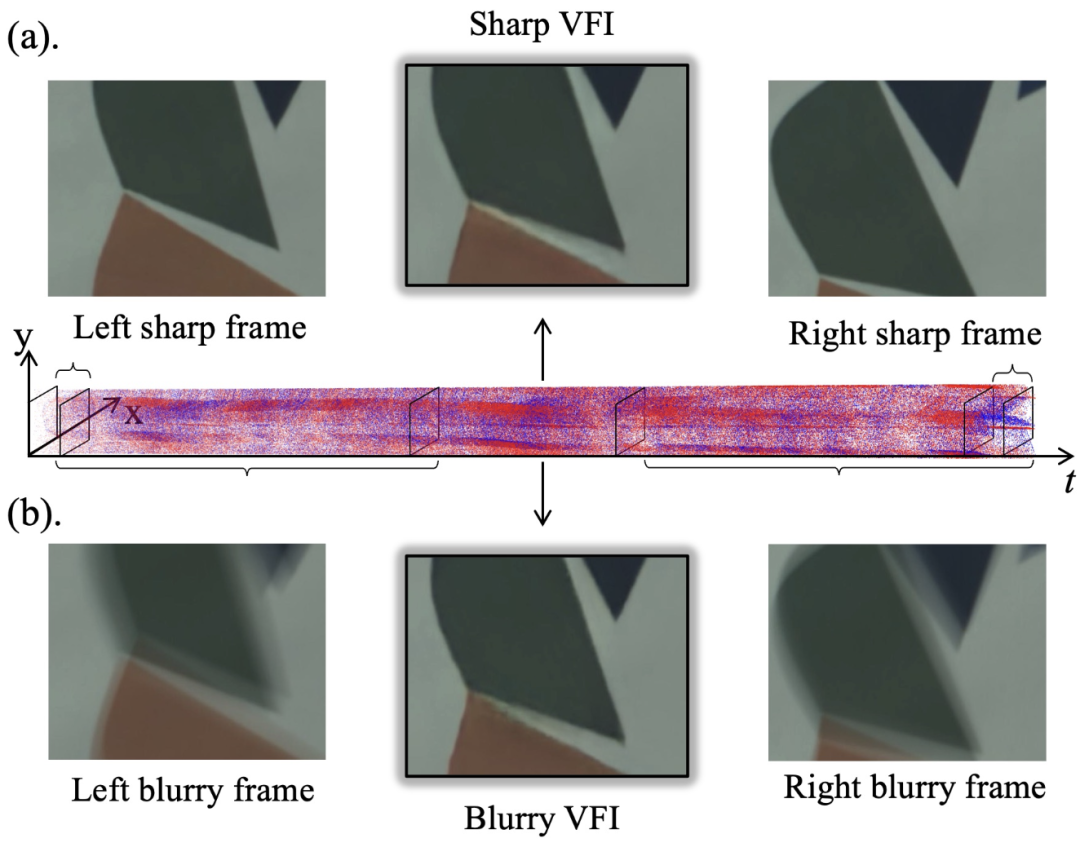
圖1. 統一的事件相機幀插值與去模糊框架, 同時實現對銳利的視頻和模糊的視頻進行還原和插幀
2
引入自監督學習策略,提高模型泛化能力:
?通過事件生成模型和運動補償機制,構建自監督損失,提高模型在無監督環境下的適應性。
?在真實數據集(HighREV)上進行自監督微調,實現從合成數據到真實數據的無縫遷移。引入自監督學習策略,提高模型泛化能力:
?通過事件生成模型和運動補償機制,構建自監督損失,提高模型在無監督環境下的適應性。
?在真實數據集(HighREV)上進行自監督微調,實現從合成數據到真實數據的無縫遷移。
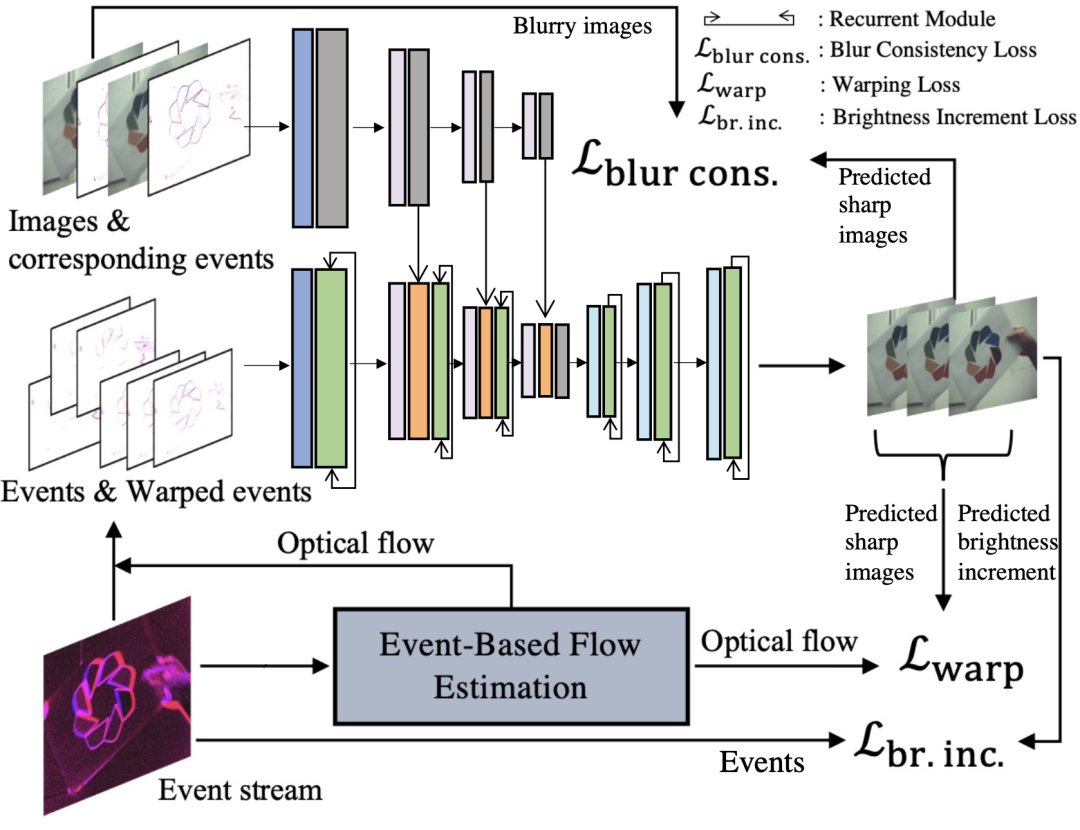
圖2:自監督訓練/微調框架
3
構建高分辨率事件-顏色視頻數據集(HighREV):
?采用1632×1224分辨率的事件相機采集數據,涵蓋室內外場景,提供高質量事件流與RGB視頻對齊數據。
?該數據集填補了現有事件相機數據集中高分辨率和彩色數據的空缺,為事件相機的低級視覺任務提供新的測試基準。
實驗驗證:
?在標準基準數據集(GoPro、HighREV)上,REFID在清晰幀插值、模糊幀插值、單幀去模糊任務上均超越了當前最先進的方法。
?在自監督微調場景下,REFID在真實世界數據集上的性能顯著提升,證明了其魯棒性和泛化能力。

圖3: 模糊視頻插幀和銳利視頻插幀結果(經過了慢放處理)。左側視頻展示暗光下的原始視頻,可以看到運動帶來的模糊和由于低幀率帶來的不連續;中間視頻為對標算法的效果;右側視頻為本文提出的新方法的效果,實現了高幀率清晰成像
04
總結與展望
人工智能在應用端的落地需要為智能終端提供穩定可靠的視覺信息,事件相機作為一種仿生傳感器可以提供高時間分辨率的視覺信息,有望補充傳統傳感器在面對復雜場景下的不足。本研究提出的算法框架結合了兩者的優勢,突破了傳統算法在運動模糊場景下的局限,首次在同一框架內同時實現高幀率清晰成像。該方法有望在瞬態信息捕捉、慢動作視頻生成、視頻編輯、增強現實(AR)、智能駕駛等領域發揮重要作用。
-
仿生傳感器
+關注
關注
1文章
10瀏覽量
2947
原文標題:前沿進展|汪凱巍團隊在IEEE TPAMI發文報道基于事件相機的高時間分辨清晰成像研究
文章出處:【微信號:zjuopt,微信公眾號:浙大光電】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄





 工商網監
工商網監
評論