 在AWS Graviton4處理器上運行大語言模型的性能評估
在AWS Graviton4處理器上運行大語言模型的性能評估
作者:Arm 基礎設施事業部 AI 解決方案架構師 Na Li;Arm 基礎設施事業部首席軟件工程師 Masoud Koleini
亞馬遜云科技 (AWS) 新一代基于 Arm 架構的定制 CPU —— AWS Graviton4 處理器已于 2024 年 7 月正式上線。這款先進的處理器基于 64 位 Arm 指令集架構的 Arm Neoverse V2 核心打造,使其能為各種云應用提供高效且性能強大的解決方案[1]。
在本文中,我們將評估在基于 Graviton4 處理器的 AWS EC2 實例(C8g 實例類型)上運行語言模型的推理性能。通過利用針對 Arm 內核優化的 Q_4_0_4_8 量化技術,在參數范圍從 38 億到 700 億不等的模型[2-5]上使用 llama.cpp[6] 進行基準測試。此外,我們還比較了基于 Graviton4 的實例與采用上一代 Graviton3 處理器的 EC2 實例上運行模型的性能。
Llama 3 70B 在 AWS Graviton4 上的執行速度快于人類可讀性水平
與 Graviton3 相比,AWS Graviton4 處理器提供了執行更大參數規模語言模型的潛力。為了評估 Graviton4 處理器在運行不同參數大小的大語言模型 (LLM) 時的性能,我們在 Graviton4 C8g.16xlarge 實例上部署了三個模型,分別為 Llama 3 70B、Phi-3-mini 3.8B 和 Llama 3 8B,并測量了其推理性能。主要性能指標是生成下個詞元 (next-token) 的延遲,如圖表 1 所示。盡管 Llama 3 70B 模型相對于其他較小的模型表現出更長的延遲,但在批次大小為 1 的情況下,它仍然能達到每秒生成 5 至 10 個詞元的人類可讀性水平,并近乎滿足生成下個詞元延遲 100 毫秒的目標服務等級協議 (SLA)。
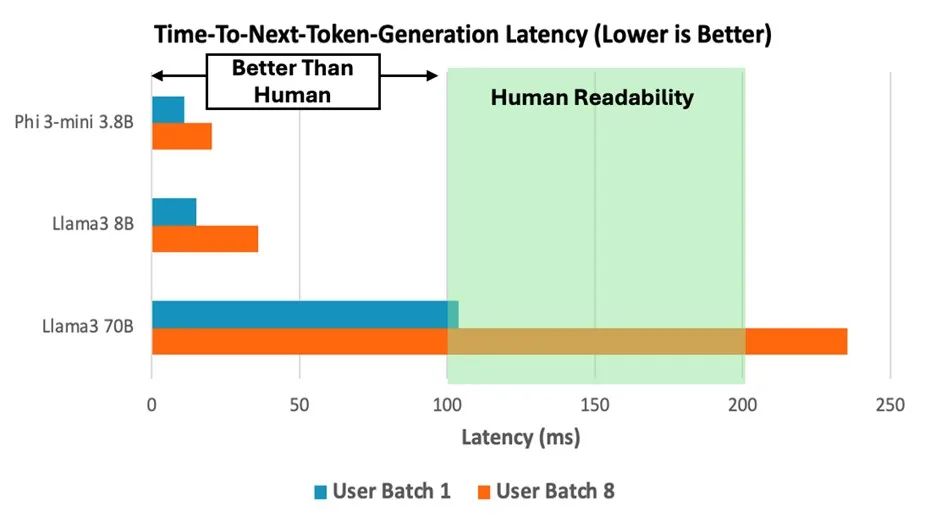
圖表 1:在 C8g.16xlarge 實例上運行 Llama 3 70B、Phi-3-mini 3.8B 和 Llama 3 8B 模型時,下個詞元生成時間的性能表現,其中批次大小模擬了一個或多個用戶同時調用模型的場景
根據 Meta[7] 的說法,盡管與 Llama 3 8B 模型相比,Llama 3 70B 模型生成下個詞元的延遲更長(圖表 1),但該模型在需要高級邏輯推理的任務中表現相當卓越(見圖 1 中的示例)。對于看重低延遲響應時間且無需復雜邏輯推理的應用而言,Llama 3 8B 模型是合適之選。相反,如果應用在延遲性方面的要求更為寬松,但需要高級推理或創造性能力,則 Llama 3 70B 模型是合適的選擇。

圖 1:在第一行顯示的示例中,Llama 3 8B 和 Llama 3 70B 模型都為基于知識的問題提供了很好的回答;而在第二行的示例中,只有 Llama 3 70B 回答正確,因為問題的解答需要進行邏輯推理
使用 Graviton3 和 Graviton4 處理器
支持不同的語言模型
為了評估 AWS Graviton 處理器在運行 LLM 時的性能,我們在 Graviton3 (C7g.16xlarge) 和 Graviton4 (C8g.16xlarge) 實例上部署了參數范圍從 38 億到 700 億不等的模型,并評測了它們的推理能力。
如表 1 所示,基于 Graviton3 和 Graviton4 的實例均能支持多達 270 億參數的模型,包括 Phi-3-mini 3.8B、Llama 3 8B 和 Gemma 2 27B。然而,在被評估的模型中,Graviton4 能夠處理參數量最大的 Llama 3 70B 模型。

表 1:Graviton3 和 Graviton4 處理器支持多種語言模型
從 Graviton3 到Graviton4 處理器的性能提升
我們在 Graviton3 (C7g.16xlarge) 和 Graviton4 (C8g.16xlarge) 的實例上部署了 Llama 3 8B 模型,以評估性能方面的提升。性能是基于提示詞編碼進行評估的,它衡量了語言模型處理和解釋用戶輸入的速度,如圖表 2 所示。在不同的用戶批次大小測試中,Graviton4 的提示詞編碼性能相較 Graviton3 提升了 14% 至 26%(見圖表 2 右軸)。
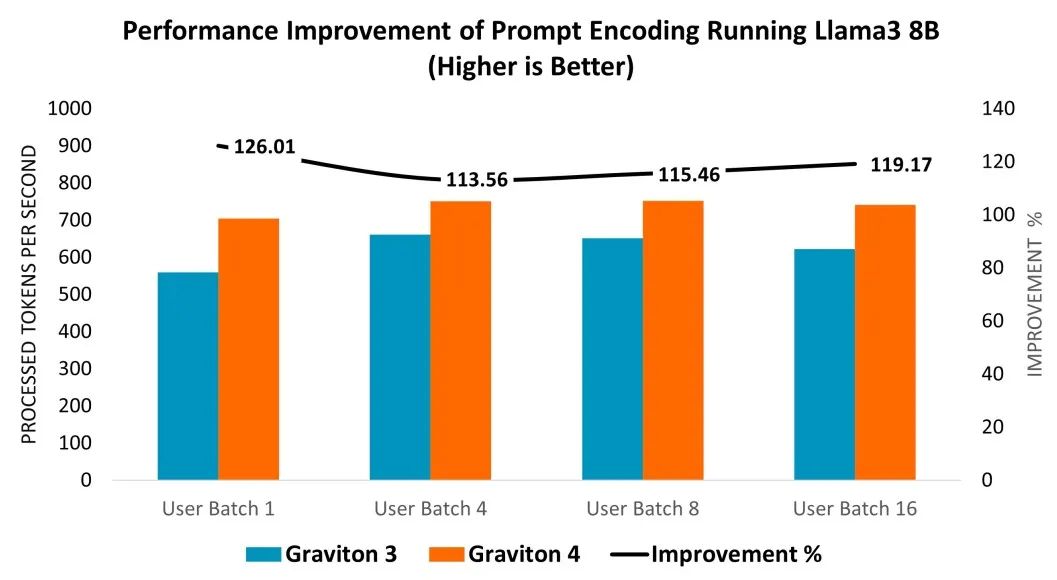
圖表 2:從 Graviton3 (C7g.16xlarge) 到 Graviton4 (C8g.16xlarge) 運行 Llama 3 8B 模型的提示詞編碼所實現的性能提升
如圖表 3 所示,詞元生成(評估語言模型在運行 Llama 3 8B 時響應和生成文本的速度)也展示了顯著的性能提升。性能曲線顯示,在不同的用戶批次大小測試中,性能都有明顯增長,Graviton4 在較小的用戶批次上顯示出更顯著的效率提升,實現了 5% 至 50% 的增長(參見圖表 3 右軸)。
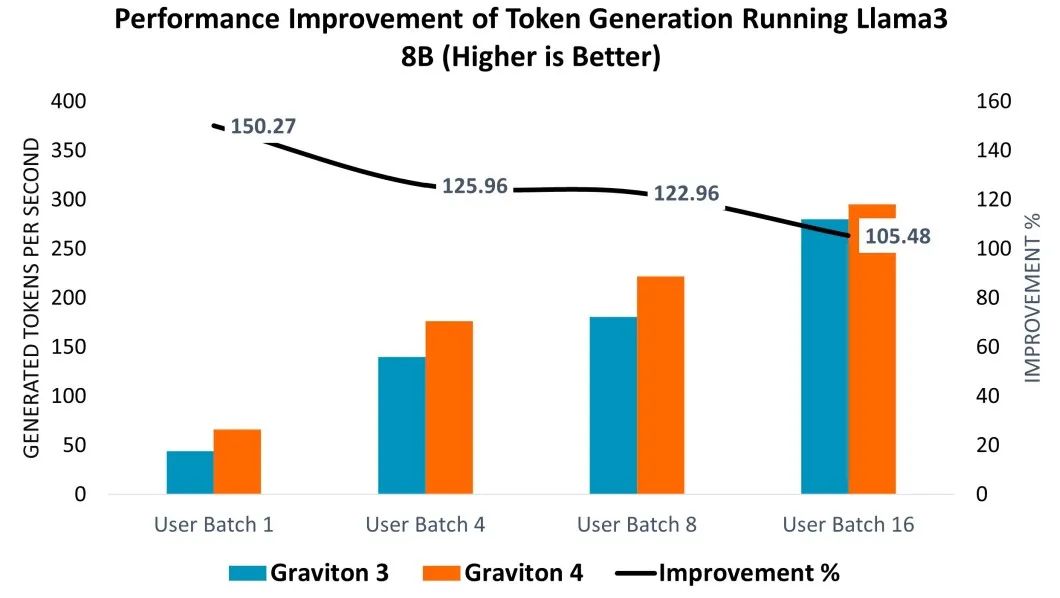
圖表 3:從 Graviton 3 (C7g.16xlarge) 到 Graviton 4 (C8g.16xlarge) 運行 Llama 3 8B 模型實現的詞元生成性能提升
結論
在 AWS Graviton4 C8g.x16large 實例上運行 Llama 3 70B,每秒可生成 10 個詞元,該速度超過了人類可讀性水平。與 Graviton3 相比,這種性能增強使 Graviton4 能夠處理包括需要高級推理等更廣泛的生成式 AI 任務。在運行 Llama 3 8B 模型時,Graviton4 的提示詞編碼性能較 Graviton3 提高了 14% 至 26%,詞元生成性能提高了 5% 至 50%。
-
cpu
+關注
關注
68文章
11033瀏覽量
215989 -
亞馬遜
+關注
關注
8文章
2691瀏覽量
84439 -
AWS
+關注
關注
0文章
435瀏覽量
25087
原文標題:在 AWS Graviton4 CPU 上運行 Llama 3 70B 模型,執行速度超過人類可讀性水平
文章出處:【微信號:Arm社區,微信公眾號:Arm社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
強悍的AWS Graviton4處理器及其背后的Arm Neoverse
基于ARM Cortex-M4處理器與板載NAND閃存的ATSAM4E-EK評估套件
Arm Neoverse V1的AWS Graviton3在深度學習推理工作負載方面的作用
在AWS云中使用Arm處理器設計Arm處理器
Sitara AM62處理器的資料分享
Cortex?-M4處理器介紹
AMD Athlon 4處理器
A14處理器性能已超酷睿i9處理器,意味著ARM超越Intel嗎?
A14處理器的性能超過酷睿i9處理器,ARM勝出一籌






 工商網監
工商網監
評論