") 阿里提出低計算量語音合成系統(tǒng),速度提升4倍
阿里提出低計算量語音合成系統(tǒng),速度提升4倍
阿里巴巴語音交互智能團(tuán)隊提出一種基于深度前饋序列記憶網(wǎng)絡(luò)的語音合成系統(tǒng)。該系統(tǒng)在達(dá)到與基于雙向長短時記憶單元的語音合成系統(tǒng)一致的主觀聽感的同時,模型大小只有后者的四分之一,且合成速度是后者的四倍,非常適合于對內(nèi)存占用和計算效率非常敏感的端上產(chǎn)品環(huán)境。該研究已入選語音頂會ICASSP會議Oral論文,本文帶來詳細(xì)解讀。
研究背景
語音合成系統(tǒng)主要分為兩類,拼接合成系統(tǒng)和參數(shù)合成系統(tǒng)。其中參數(shù)合成系統(tǒng)在引入了神經(jīng)網(wǎng)絡(luò)作為模型之后,合成質(zhì)量和自然度都獲得了長足的進(jìn)步。另一方面,物聯(lián)網(wǎng)設(shè)備(例如智能音箱和智能電視)的大量普及也對在設(shè)備上部署的參數(shù)合成系統(tǒng)提出了計算資源的限制和實時率的要求。本工作引入的深度前饋序列記憶網(wǎng)絡(luò)可以在保持合成質(zhì)量的同時,有效降低計算量,提高合成速度。
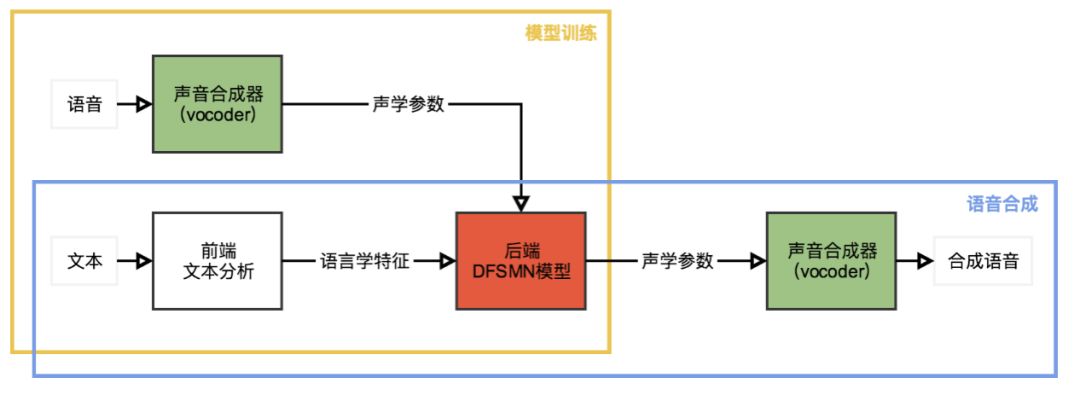
我們使用基于雙向長短時記憶單元(BLSTM)的統(tǒng)計參數(shù)語音合成系統(tǒng)作為基線系統(tǒng)。與其他現(xiàn)代統(tǒng)計參數(shù)語音合成系統(tǒng)相似,我們提出的基于深度前饋序列記憶網(wǎng)絡(luò)(DFSMN)的統(tǒng)計參數(shù)語音合成系統(tǒng)也是由3個主要部分組成,聲音合成器(vocoder),前端模塊和后端模塊,如上圖所示。我們使用開源工具WORLD作為我們的聲音合成器,用來在模型訓(xùn)練時從原始語音波形中提取頻譜信息、基頻的對數(shù)、頻帶周期特征(BAP)和清濁音標(biāo)記,也用來在語音合成時完成從聲學(xué)參數(shù)到實際聲音的轉(zhuǎn)換。前端模塊用來對輸入的文本進(jìn)行正則化和詞法分析,我們把這些語言學(xué)特征編碼后作為神經(jīng)網(wǎng)絡(luò)訓(xùn)練的輸入。后端模塊用來建立從輸入的語言學(xué)特征到聲學(xué)參數(shù)的映射,在我們的系統(tǒng)中,我們使用DFSMN作為后端模塊。
深度前饋序列記憶網(wǎng)絡(luò)
緊湊前饋序列記憶網(wǎng)絡(luò)(cFSMN)作為標(biāo)準(zhǔn)的前饋序列記憶網(wǎng)絡(luò)(FSMN)的改進(jìn)版本,在網(wǎng)絡(luò)結(jié)構(gòu)中引入了低秩矩陣分解,這種改進(jìn)簡化了FSMN,減少了模型的參數(shù)量,并加速了模型的訓(xùn)練和預(yù)測過程。
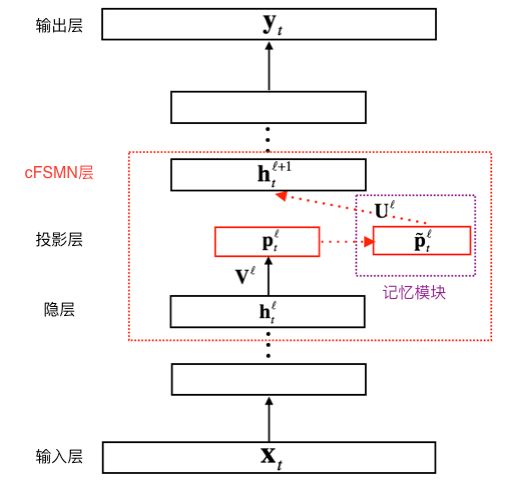
上圖給出了cFSMN的結(jié)構(gòu)的圖示。對于神經(jīng)網(wǎng)絡(luò)的每一個cFSMN層,計算過程可表示成以下步驟①經(jīng)過一個線性映射,把上一層的輸出映射到一個低維向量②記憶模塊執(zhí)行計算,計算當(dāng)前幀之前和之后的若干幀和當(dāng)前幀的低維向量的逐維加權(quán)和③把該加權(quán)和再經(jīng)過一個仿射變換和一個非線性函數(shù),得到當(dāng)前層的輸出。三個步驟可依次表示成如下公式。
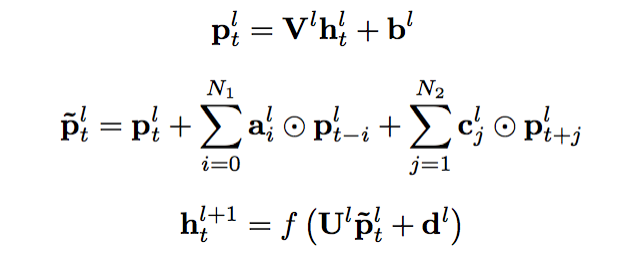
與循環(huán)神經(jīng)網(wǎng)絡(luò)(RNNs,包括BLSTM)類似,通過調(diào)整記憶模塊的階數(shù),cFSMN有能力捕捉序列的長程信息。另一方面,cFSMN可以直接通過反向傳播算法(BP)進(jìn)行訓(xùn)練,與必須使用沿時間反向傳播算法(BPTT)進(jìn)行訓(xùn)練的RNNs相比,訓(xùn)練cFSMN速度更快,且較不容易受到梯度消失的影響。
對cFSMN進(jìn)一步改進(jìn),我們得到了深度前饋序列記憶網(wǎng)絡(luò)(DFSMN)。DFSMN利用了在各類深度神經(jīng)網(wǎng)絡(luò)中被廣泛使用的跳躍連接(skip-connections)技術(shù),使得執(zhí)行反向傳播算法的時候,梯度可以繞過非線性變換,即使堆疊了更多DFSMN層,網(wǎng)絡(luò)也能快速且正確地收斂。對于DFSMN模型,增加深度的好處有兩個方面。一方面,更深的網(wǎng)絡(luò)一般來說具有更強(qiáng)的表征能力,另一方面,增加深度可以間接地增大DFSMN模型預(yù)測當(dāng)前幀的輸出時可以利用的上下文長度,這在直觀上非常有利于捕捉序列的長程信息。具體來說,我們把跳躍連接添加到了相鄰兩層的記憶模塊之間,如下面公式所示。由于DFSMN各層的記憶模塊的維數(shù)相同,跳躍連接可由恒等變換實現(xiàn)。
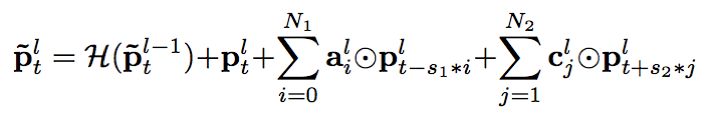
我們可以認(rèn)為DFSMN是一種非常靈活的模型。當(dāng)輸入序列很短,或者對預(yù)測延時要求較高的時候,可以使用較小的記憶模塊階數(shù),在這種情況下只有當(dāng)前幀附近幀的信息被用來預(yù)測當(dāng)前幀的輸出。而如果輸入序列很長,或者在預(yù)測延時不是那么重要的場景中,可以使用較大的記憶模塊階數(shù),那么序列的長程信息就能被有效利用和建模,從而有利于提高模型的性能。
除了階數(shù)之外,我們?yōu)镈FSMN的記憶模塊增加了另一個超參數(shù),步長(stride),用來表示記憶模塊提取過去或未來幀的信息時,跳過多少相鄰的幀。這是有依據(jù)的,因為與語音識別任務(wù)相比,語音合成任務(wù)相鄰幀之間的重合部分甚至更多。
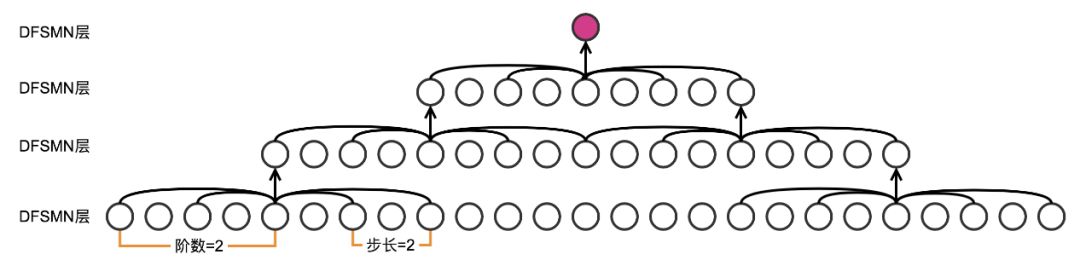
上文已經(jīng)提到,除了直接增加各層的記憶模塊的階數(shù)之外,增加模型的深度也能間接增加預(yù)測當(dāng)前幀的輸出時模型可以利用的上下文的長度,上圖給出了一個例子。
實驗
在實驗階段,我們使用的是一個由男性朗讀的中文小說數(shù)據(jù)集。我們把數(shù)據(jù)集劃分成兩部分,其中訓(xùn)練集包括38600句朗讀(大約為83小時),驗證集包括1400句朗讀(大約為3小時)。所有的語音數(shù)據(jù)采樣率都為16k赫茲,每幀幀長為25毫秒,幀移為5毫秒。我們使用WORLD聲音合成器逐幀提取聲學(xué)參數(shù),包括60維梅爾倒譜系數(shù),3維基頻的對數(shù),11維BAP特征以及1維清濁音標(biāo)記。我們使用上述四組特征作為神經(jīng)網(wǎng)絡(luò)訓(xùn)練的四個目標(biāo),進(jìn)行多目標(biāo)訓(xùn)練。前端模塊提取出的語言學(xué)特征,共計754維,作為神經(jīng)網(wǎng)絡(luò)訓(xùn)練的輸入。
我們對比的基線系統(tǒng)是基于一個強(qiáng)大的BLSTM模型,該模型由底層的1個全連接層和上層的3個BLSTM層組成,其中全連接層包含2048個單元,BLSTM層包含2048個記憶單元。該模型通過沿時間反向傳播算法(BPTT)訓(xùn)練,而我們的DFSMN模型通過標(biāo)準(zhǔn)的反向傳播算法(BP)訓(xùn)練。包括基線系統(tǒng)在內(nèi),我們的模型均通過逐塊模型更新過濾算法(BMUF)在2塊GPU上訓(xùn)練。我們使用多目標(biāo)幀級別均方誤差(MSE)作為訓(xùn)練目標(biāo)。
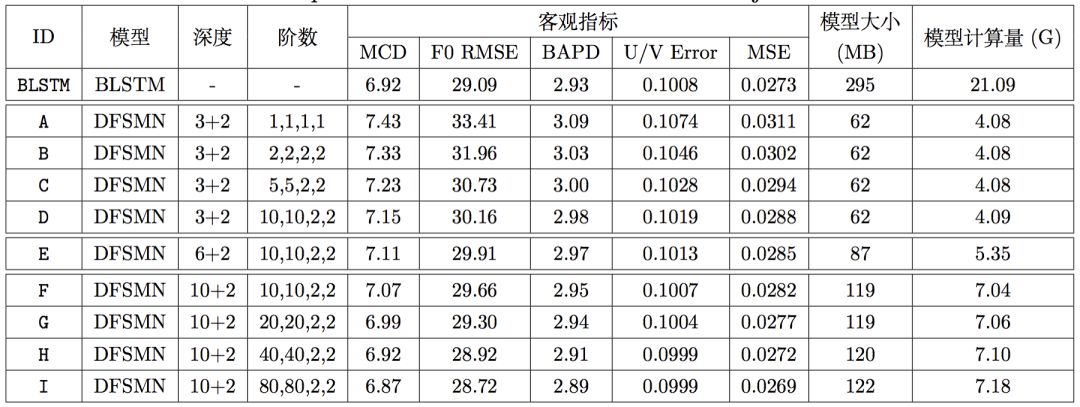
所有的DFSMN模型均由底層的若干DFSMN層和上的2個全連接層組成,每個DFSMN層包含2048個結(jié)點和512個投影結(jié)點,而每個全連接層包含2048個結(jié)點。在上圖中,第三列表示該模型由幾層DFSMN層和幾層全連接層組成,第四列表示該模型DFSMN層的記憶模塊的階數(shù)和步長。由于這是FSMN這一類模型首次應(yīng)用在語音合成任務(wù)中,因此我們的實驗從一個深度淺且階數(shù)小的模型,即模型A開始(注意只有模型A的步長為1,因為我們發(fā)現(xiàn)步長為2始終稍好于步長為1的相應(yīng)模型)。從系統(tǒng)A到系統(tǒng)D,我們在固定DFSMN層數(shù)為3的同時逐漸增加階數(shù)。從系統(tǒng)D到系統(tǒng)F,我們在固定階數(shù)和步長為10,10,2,2的同時逐漸增加層數(shù)。從系統(tǒng)F到系統(tǒng)I,我們固定DFSMN層數(shù)為10并再次逐漸增加階數(shù)。在上述一系列實驗中,隨著DFSMN模型深度和階數(shù)的增加,客觀指標(biāo)逐漸降低(越低越好),這一趨勢非常明顯,且系統(tǒng)H的客觀指標(biāo)超過了BLSTM基線。
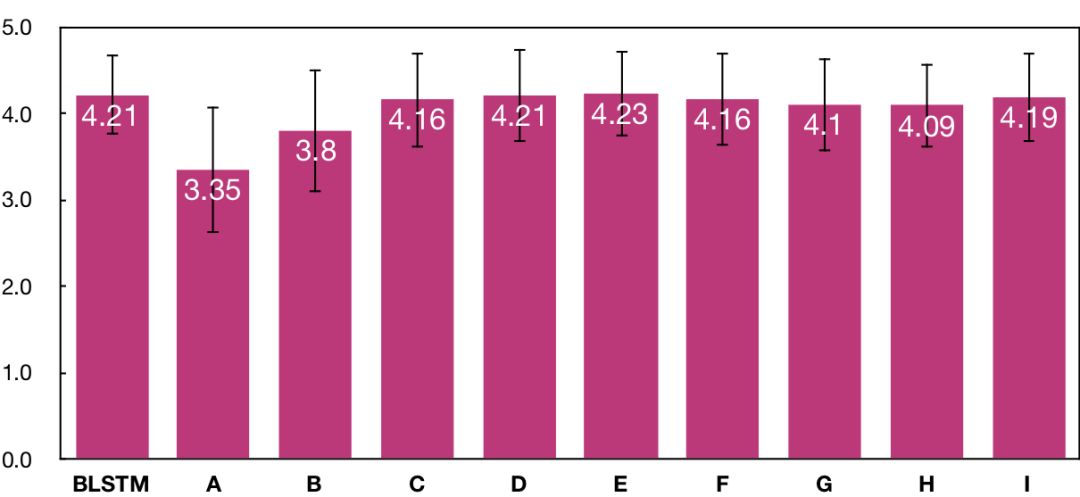
另一方面,我們也做了平均主觀得分(MOS)測試(越高越好),測試結(jié)果如上圖所示。主觀測試是通過付費眾包平臺,由40個母語為中文的測試人員完成的。在主觀測試中,每個系統(tǒng)生成了20句集外合成語音,每句合成語音由10個不同的測試人員獨立評價。在平均主觀得分的測試結(jié)果表明,從系統(tǒng)A到系統(tǒng)E,主觀聽感自然度逐漸提高,且系統(tǒng)E達(dá)到了與BLSTM基線系統(tǒng)一致的水平。但是,盡管后續(xù)系統(tǒng)客觀指標(biāo)持續(xù)提高,主觀指標(biāo)只是在系統(tǒng)E得分的上下波動,沒有進(jìn)一步提高。
結(jié)論
根據(jù)上述主客觀測試,我們得到的結(jié)論是,歷史和未來信息各捕捉120幀(600毫秒)是語音合成聲學(xué)模型建模所需要的上下文長度的上限,更多的上下文信息對合成結(jié)果沒有直接幫助。與BLSTM基線系統(tǒng)相比,我們提出的DFSMN系統(tǒng)可以在獲得與基線系統(tǒng)一致的主觀聽感的同時,模型大小只有基線系統(tǒng)的1/4,預(yù)測速度則是基線系統(tǒng)的4倍,這使得該系統(tǒng)非常適合于對內(nèi)存占用和計算效率要求很高的端上產(chǎn)品環(huán)境,例如在各類物聯(lián)網(wǎng)設(shè)備上部署。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4809瀏覽量
102829 -
物聯(lián)網(wǎng)
+關(guān)注
關(guān)注
2927文章
45910瀏覽量
388292 -
智能語音交互
+關(guān)注
關(guān)注
0文章
24瀏覽量
2973
原文標(biāo)題:ICASSP Oral 論文:阿里提出低計算量語音合成系統(tǒng),速度提升4倍
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
DeepSeek最新論文:訓(xùn)練速度提升9倍,推理速度快11倍!

明遠(yuǎn)智睿SSD2351開發(fā)板:語音機(jī)器人領(lǐng)域的變革力量
大模型時代的新燃料:大規(guī)模擬真多風(fēng)格語音合成數(shù)據(jù)集
智能收銀語音交互新標(biāo)桿—WT3000T8語音合成芯片TTS技術(shù)應(yīng)用解析

WT3000TX語音合成芯片介紹V1
YX5p多功能單芯片CMOS語音合成4位微控制器中文手冊
【CW32模塊使用】語音合成播報模塊

芯資訊|WT3000T8語音合成芯片:高性價比語音交互解決方案

ADA4522-4輸出±21.5V矩形波電壓,上升/下降時間過長速度慢怎么解決?
WT3000T8-32N語音合成TTS芯片:小體積、強(qiáng)性能,重塑智能語音交互體驗

無人機(jī)低延時目標(biāo)跟蹤識別智算系統(tǒng)
EMMC存儲速度如何提升
阿里云海外收入五年增長20倍
聲發(fā)射系統(tǒng)的技術(shù)指標(biāo):最高采樣速度的選擇





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論