 小白學解釋性AI:從機器學習到大模型
小白學解釋性AI:從機器學習到大模型

本文來源:Coggle數據科學
AI需要可解釋性
人工智能的崛起,尤其是深度學習的發展,在眾多領域帶來了令人矚目的進步。然而,伴隨這些進步而來的是一個關鍵問題——“黑箱”問題。許多人工智能模型,特別是復雜的模型,如神經網絡和大型語言模型(LLMs),常被視為“黑箱”,因為它們的決策過程是不透明的。
這些模型可能以高精度預測結果,但其決策背后的邏輯卻難以捉摸。這種缺乏可解釋性的情況引發了諸多重大問題:
信任與責任:如果一個AI模型做出改變人生的決策,比如診斷醫療狀況或批準貸款,用戶需要理解背后的邏輯。沒有這種理解,用戶就無法信任或驗證結果。
調試與改進模型:開發者需要深入了解決策過程,以便診斷錯誤或提升模型性能。如果無法解釋模型,尋找錯誤根源就只能靠猜測。
- 監管合規:在金融和醫療等領域,監管機構要求AI決策必須可解釋。例如,歐盟的《通用數據保護條例》(GDPR)中就包含了“解釋權”,要求組織為自動化決策提供清晰的理由。
可解釋性與模型復雜度之間的權衡
在人工智能中,可解釋性與模型復雜度之間常常存在權衡。像決策樹和線性回歸這樣的模型天生具有可解釋性,但往往缺乏捕捉數據中復雜模式的靈活性。而深度學習模型和LLMs雖然具有卓越的預測能力,但解釋起來卻非常困難。
來看一些例子:
線性回歸:這是一種簡單且可解釋的模型,其系數直接表明特征與目標變量之間的關系。然而,在復雜非線性數據集上,它的表現可能不盡如人意。
神經網絡:這些模型能夠近似復雜函數,并在圖像識別和自然語言處理等任務中展現出最先進的性能。但理解每個神經元或層在決策過程中的作用卻極具挑戰性。
可解釋性的不同層次與類型可解釋性不應與可視化混淆。可視化是一種技術手段,例如繪制特征重要性圖或激活圖,這些可以幫助我們理解模型,但它們本身并不是解釋。
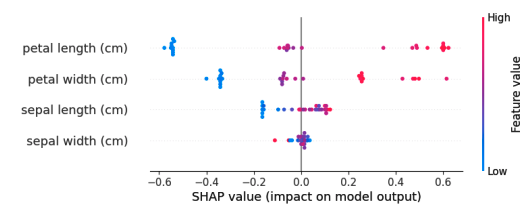
特征重要性圖確實為我們提供了關于每個特征相對重要性的寶貴見解。然而,它并沒有完全解釋模型為何對某個特定樣本做出這樣的決策。
白盒模型 vs 黑盒模型
白盒模型包括以下幾種:
- 線性回歸:通過系數直接反映特征與目標變量之間的線性關系。
- 邏輯回歸:通過系數反映特征對結果概率的影響。
- 決策樹:通過樹狀結構展示決策路徑,易于理解和解釋。
- 基于規則的系統:通過預定義的規則進行決策,規則透明且易于理解。
- K-最近鄰(KNN):通過查找最近的訓練樣本進行預測,決策過程直觀。
- 樸素貝葉斯分類器:基于貝葉斯定理和特征的獨立性假設進行分類,模型簡單且易于解釋。
- 廣義相加模型(GAMs):通過加性函數捕捉特征與目標變量之間的關系,支持對每個特征的獨立解釋。
黑盒模型包括以下幾種:
- 神經網絡(例如,深度學習模型):由于其復雜的結構和大量的參數,難以直接解釋。
- 支持向量機(SVMs):雖然線性核的SVM具有一定的可解釋性,但非線性核的SVM通常被視為黑盒模型。
- 集成方法(例如,隨機森林、梯度提升機):雖然基于決策樹,但其集成結構增加了復雜性,難以直接解釋。
- Transformer模型(例如,BERT、GPT):由于其復雜的自注意力機制和大量的參數,難以直接解釋。
圖神經網絡(GNNs):通過圖結構處理數據,內部工作機制復雜,難以直接解釋。
傳統機器學習的可解釋性
可解釋模型與不可解釋模型的區別
當我們討論機器學習中的可解釋性時,我們指的是能夠清晰地理解和追溯模型是如何得出其預測結果的能力。可解釋的模型是指人類觀察者可以跟隨決策過程,并直接將輸入特征與輸出預測聯系起來的模型。相比之下,不可解釋的模型,通常被稱為“黑箱”模型,由于其結構復雜,很難理解其預測背后的邏輯。
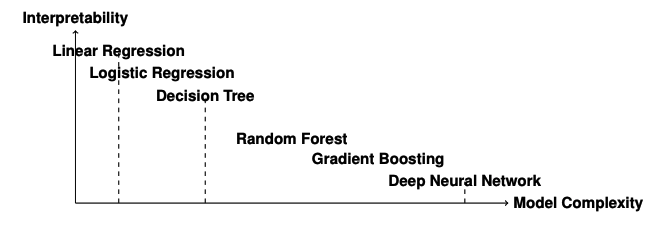
一個常見的區分方法是:
可解釋模型:決策樹和線性模型被認為是可解釋的。它們的結構設計使得每一個決策或系數都可以被解釋,并追溯回輸入特征。
- 不可解釋模型:神經網絡和集成方法(例如隨機森林和梯度提升)通常是不可解釋的。由于它們的復雜性,包含眾多的層、節點和參數,很難追溯單個預測。
決策樹決策樹在機器學習中被廣泛認為是最具可解釋性的模型之一。它們具有簡單直觀的流程圖結構,其中內部節點代表基于特征值的決策規則,分支表示這些決策的結果,而葉節點則包含最終預測。從根節點到葉節點的路徑提供了一個清晰且易于理解的決策過程。
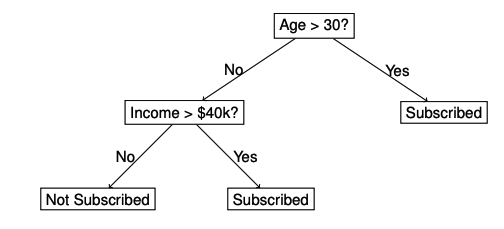
決策樹通過輸入特征的值將數據劃分為子集,目標是減少不確定性或“不純度”。常見的節點分裂標準包括:
- 基尼不純度(Gini Impurity)
- 信息增益(Information Gain)
這種結構突顯了為什么決策樹被認為是可解釋的:每個決策都可以用輸入特征來解釋,從而便于為模型的預測提供依據。盡管決策樹本身具有可解釋性,但它們很容易生長得過深,變得過于復雜,從而捕捉數據中的噪聲并導致過擬合。為了應對這一問題,我們采用剪枝技術,通過移除那些對預測能力貢獻微乎其微的節點來簡化樹。主要的剪枝策略有兩種:
- 預剪枝(Pre-pruning,早期停止):根據預定義的標準(如最大深度或每個葉節點的最小樣本數)限制樹的生長。這降低了過擬合的風險,同時保持了樹結構的簡單性。
- 后剪枝(Post-pruning):首先讓樹生長到最大深度,然后剪掉那些對模型性能提升不顯著的節點。這種方法通常能夠得到一個更平衡的模型,具有更強的泛化能力。
決策樹中的特征重要性是通過評估每個特征在分裂過程中減少節點不純度的作用來確定的。不純度是衡量節點內無序或隨機性的指標,通常使用基尼不純度或熵來評估。當一個特征顯著減少不純度時,它會獲得更高的重要性分數。
本質上,一個特征在樹分裂中減少不純度的貢獻越大,它就越重要。高特征重要性表明模型在做預測時高度依賴該特征,使其成為理解模型決策過程的關鍵因素。
線性模型
線性模型,包括線性回歸和邏輯回歸,是機器學習中最具可解釋性的模型之一。它們假設輸入特征與輸出之間存在線性關系,這使得理解每個特征對預測結果的影響變得非常直觀。盡管線性模型結構簡單,但在數據關系近似線性的情況下,它們依然非常強大。在對可解釋性要求極高的領域,如金融和醫療保健,線性模型通常是首選。
線性假設:線性回歸假設特征與目標之間存在線性關系。這一假設在復雜數據集中可能不成立。
對異常值敏感:異常值可能會嚴重影響擬合線,導致預測結果不佳。
- 多重共線性:當特征之間高度相關時,很難確定每個特征對輸出的獨立影響。
支持向量機(SVM)支持向量機(SVM)因其魯棒性以及能夠處理線性和非線性可分數據而備受推崇。盡管通常被視為“黑箱”模型,但使用線性核的SVM可以通過其決策邊界和支持向量提供一定程度的可解釋性。SVM的目標是找到一個超平面,能夠最好地將數據劃分為不同的類別。最優超平面會最大化邊界(即超平面與每個類別最近數據點之間的距離)。這些最近的數據點被稱為支持向量,它們是SVM決策過程的核心。
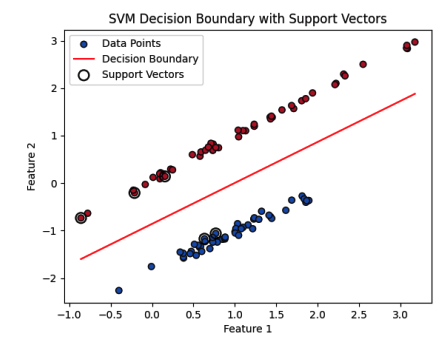
決策邊界:紅線表示將兩個類別分開的超平面。這條線由權重向量w和偏置項b決定。決策邊界將特征空間劃分為兩個區域,每個區域對應一個類別標簽(藍色和紅色點)。
支持向量:支持向量用較大的空心圓突出顯示。這些是離決策邊界最近的數據點,位于邊界邊界上。它們在定義邊界和超平面的方向上起著關鍵作用。如圖所示,來自兩個類別的幾個支持向量正好位于邊界上。
- 邊界:邊界是穿過支持向量的兩條平行線之間的區域。SVM算法的目標是最大化這個邊界,這提高了模型的泛化能力。較大的邊界表示一個更魯棒的分類器,對數據的小變化不那么敏感。
深度學習模型的可解釋性
深度學習模型,如卷積神經網絡(CNNs)和循環神經網絡(RNNs),包含多層神經元、非線性激活函數以及大量的參數。例如,一個簡單的用于圖像分類的CNN可能已經包含數百萬個參數。隨著網絡深度和復雜性的增加,理解每個單獨參數的貢獻變得不可行。
在深度學習中,高維數據通過層進行處理,這些層可能會減少或增加維度,使得直接將輸入特征映射到學習的表示變得困難。這種抽象阻礙了我們直接解釋學習到的特征。
卷積神經網絡(CNNs)的可解釋性
CNNs通過一系列卷積層和池化層從輸入圖像中提取特征。早期層通常捕獲簡單的模式,如邊緣和紋理,而深層則學習更抽象、高級的表示,例如物體部件。解釋CNNs最直觀的方法之一是通過可視化這些學習到的特征。特征可視化涉及檢查卷積濾波器生成的特征圖,使我們能夠了解輸入圖像的哪些部分激活了特定的濾波器。

特征圖提供了一個視覺上的窺視,讓我們能夠了解模型在不同網絡階段如何感知輸入圖像。雖然這種類型的可視化有助于理解網絡的早期層,但由于學習到的特征的復雜性和抽象性,解釋深層的特征圖變得越來越具有挑戰性。
- 缺乏直接可解釋性:并非所有特征圖都對應于人類可識別的模式。許多濾波器可能檢測到難以視覺解釋的抽象特征。
- 依賴輸入數據:可視化的特征高度依賴于輸入圖像。不同的圖像可能會激活不同的濾波器,這使得很難將解釋推廣到各種輸入。
循環神經網絡(RNNs)的可解釋性
RNN的核心能力在于其隱藏狀態,這些狀態隨每個時間步長演變。隱藏狀態作為記憶單元,存儲序列中以前輸入的信息。然而,解釋隱藏狀態中編碼的信息是具有挑戰性的,因為它們代表了過去輸入的復雜非線性組合。
為了深入了解隱藏狀態,一種常見的方法是可視化它們隨時間的變化。例如,繪制不同時間步長的隱藏狀態激活可以揭示模式,例如對輸入序列某些部分的注意力增加或敏感性增強。自注意力機制與Transformer模型的可解釋性自注意力機制允許模型根據每個輸入標記相對于其他所有標記的重要性進行加權。該機制涉及的關鍵組件是查詢(query)、鍵(key)和值(value)向量,這些向量是為每個標記計算的。
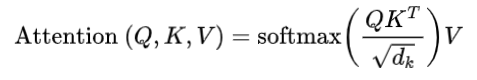
- is the query matrix.
- is the key matrix.
- is the value matrix.
- is the dimension of the key vectors.
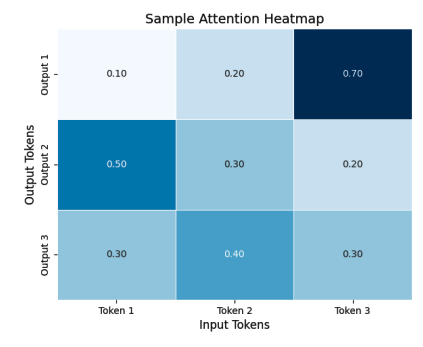
在這個例子中,熱力圖可視化了一個小的注意力權重矩陣,其中每個單元格代表輸入標記和輸出標記之間的注意力分數。每個單元格的顏色強度表示注意力分數的強度,便于識別對輸出標記最有影響力的輸入標記。
大型語言模型(LLMs)的可解釋性
大型語言模型(LLMs)是一類變革性的深度學習模型,旨在理解和生成人類語言。這些模型利用大量的訓練數據和Transformer架構,徹底改變了自然語言處理(NLP),在文本分類、翻譯、摘要、對話系統甚至代碼生成等廣泛任務中達到了最先進的性能。
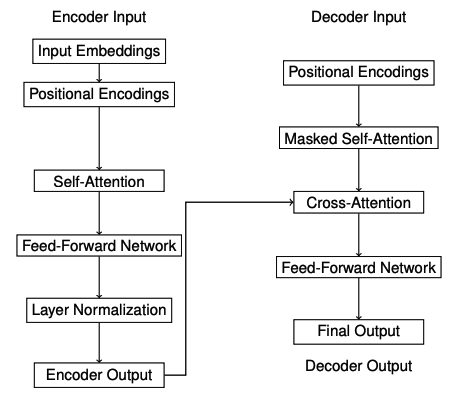
嵌入分析和探測LLMs中的嵌入是高維表示,編碼了關于單詞、短語和句子的豐富語義信息。嵌入分析幫助我們理解模型學到了哪些語言屬性以及這些屬性在嵌入空間中的組織方式。
降維技術如t-SNE(t分布隨機鄰域嵌入)和PCA(主成分分析)常用于可視化嵌入。通過將嵌入投影到二維或三維空間,我們可以觀察到揭示單詞之間語義關系的聚類模式。
神經逐層可解釋性神經逐層可解釋性專注于理解Transformer架構中各個層的作用。在像BERT這樣的大型語言模型(LLMs)中,每一層都捕捉了不同層次的語言信息,共同構成了模型對輸入文本的整體理解。
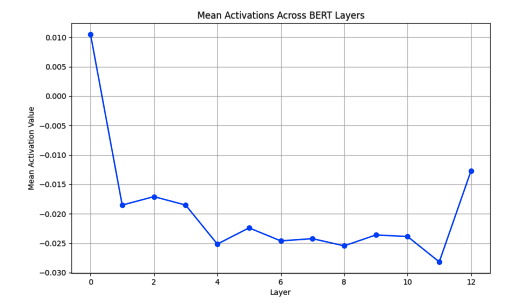
早期層:這些層傾向于捕捉表面級特征,如標記身份和基本的句法模式。模型在這個階段專注于理解單個單詞及其基本關系。
- 中間層:中間層負責捕捉更抽象的句法結構和依賴關系,如主謂一致和語法關系。這些層幫助模型理解句子結構。
- 晚期層:這些層編碼高級語義信息和特定于任務的表示。它們直接貢獻于最終預測,通常包含輸入文本中最抽象和上下文感知的特征。
探測嵌入中的知識
句法探測:評估模型對句法屬性的理解。例如,它檢查嵌入是否能夠區分句子中的主語和賓語,捕捉單詞的句法角色。
語義探測:檢查模型是否捕捉了語義關系,如單詞相似性或蘊含關系。它旨在了解嵌入是否反映了更深層次的語義特征,如同義詞或反義詞。
-
AI
+關注
關注
88文章
35080瀏覽量
279417 -
機器學習
+關注
關注
66文章
8501瀏覽量
134569 -
大模型
+關注
關注
2文章
3135瀏覽量
4057
發布評論請先 登錄
什么是“可解釋的”? 可解釋性AI不能解釋什么
機器學習模型的“可解釋性”的概念及其重要意義
Explainable AI旨在提高機器學習模型的可解釋性

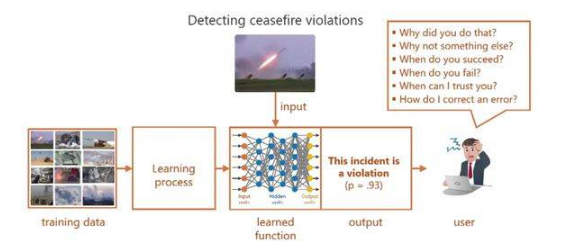
機器學習模型可解釋性的介紹
圖神經網絡的解釋性綜述

使用RAPIDS加速實現SHAP的模型可解釋性
機器學習模型的可解釋性算法匯總





 工商網監
工商網監
評論