 Kaggle知識點:7種超參數搜索方法
Kaggle知識點:7種超參數搜索方法
本文轉自:Coggle數據科學
超參數搜索確實是機器學習生命周期中不可或缺的一步,特別是在模型性能方面。正確的超參數選擇可以顯著提高模型的準確性、對未見數據的泛化能力以及收斂速度。不當的超參數選擇可能導致過擬合或欠擬合等問題。
一些常見的超參數例子包括梯度基算法中的學習率,或者決策樹算法中樹的深度,這些可以直接影響模型準確擬合訓練數據的能力。超參數調優涉及在復雜的、高維的超參數空間中搜索模型的最佳配置。挑戰不僅在于計算成本,還在于模型復雜性、泛化能力和過擬合之間的權衡。
方法1:網格搜索
網格搜索(Grid Search)是一種流行的超參數優化方法,它系統地遍歷多種超參數的組合。這種方法簡單、直觀,但可能在高維參數空間中變得非常耗時和計算密集。
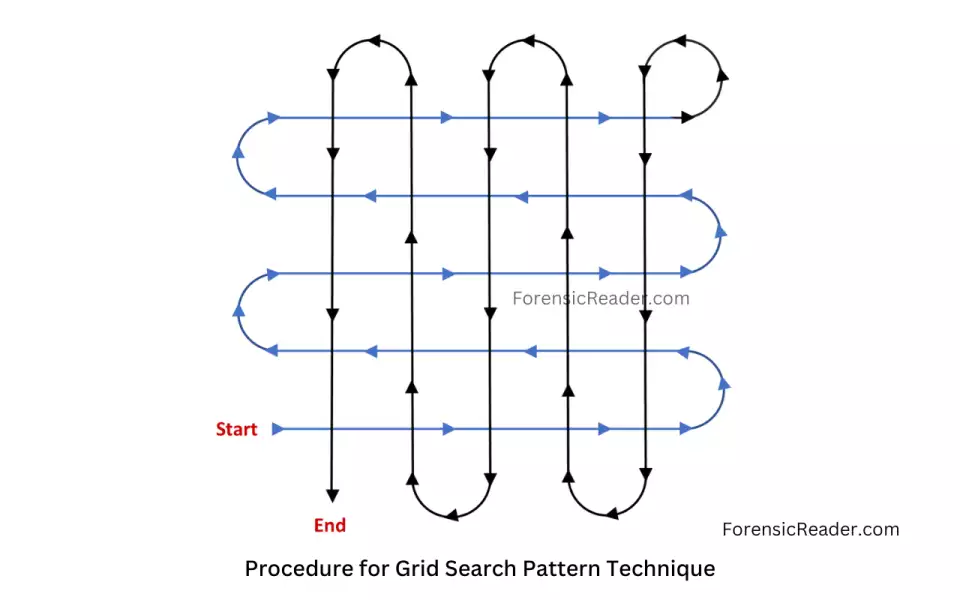
網格搜索會生成所有可能的參數組合。如果你有兩個超參數,每個參數有3個可能的值,那么網格搜索將會產生 9 種不同的參數組合。
簡單易懂:網格搜索的概念直觀,易于理解和實現。
全面搜索:如果你定義的參數網格足夠密集,網格搜索可以保證找到全局最優解。
- 計算成本高:隨著超參數數量和每個參數的可能值數量增加,需要評估的組合數量呈指數級增長,這可能導致計算成本非常高。
fromsklearnimportsvm,datasets
fromsklearn.model_selectionimportGridSearchCV
iris=datasets.load_iris()
parameters={'kernel':('linear','rbf'),'C':[1,10]}
svc=svm.SVC()
clf=GridSearchCV(svc,parameters)
clf.fit(iris.data,iris.target)
sorted(clf.cv_results_.keys())
方法2:隨機搜索
隨機搜索(Random Search)是另一種流行的超參數優化方法,與網格搜索相比,它不嘗試遍歷所有可能的參數組合,而是在參數空間中隨機選擇參數組合進行評估。
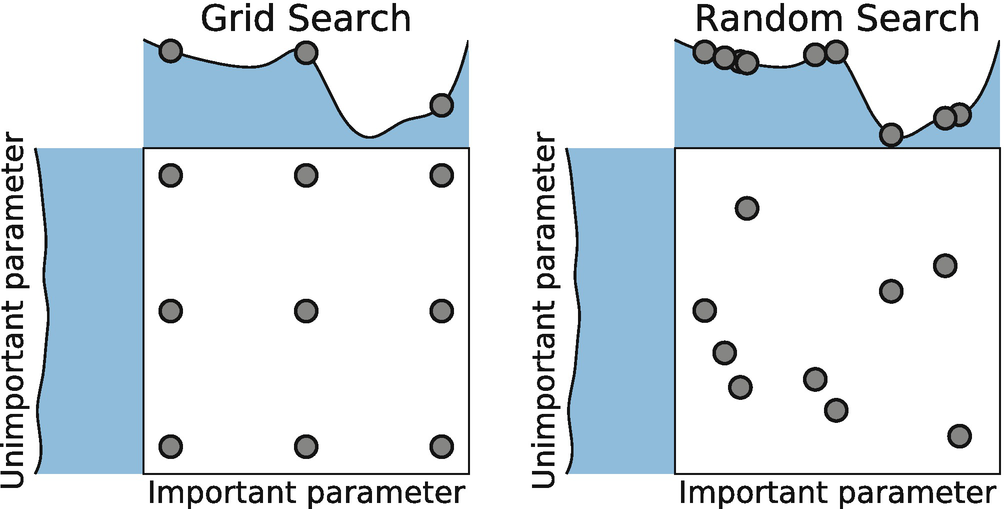
隨機搜索會從這些分布中隨機抽取參數值,形成參數組合。每次抽取都是獨立的,這意味著同一參數的不同組合可以被多次抽取。
靈活性:隨機搜索可以很容易地處理連續參數和離散參數。
避免局部最優:由于隨機搜索的隨機性,它不太可能陷入局部最優解,有更高的機會探索到全局最優解。
結果不可重復:每次運行隨機搜索可能會得到不同的結果,因為參數組合是隨機選擇的。
fromsklearn.datasetsimportload_iris
fromsklearn.linear_modelimportLogisticRegression
fromsklearn.model_selectionimportRandomizedSearchCV
fromscipy.statsimportuniform
iris=load_iris()
logistic=LogisticRegression(solver='saga',tol=1e-2,max_iter=200,
random_state=0)
distributions=dict(C=uniform(loc=0,scale=4),
penalty=['l2','l1'])
clf=RandomizedSearchCV(logistic,distributions,random_state=0)
search=clf.fit(iris.data,iris.target)
search.best_params_
方法3:貝葉斯優化貝葉斯優化核心思想是構建一個概率模型,該模型能夠預測目標函數(通常是模型的性能指標,如準確率或損失)在不同超參數組合下的表現。
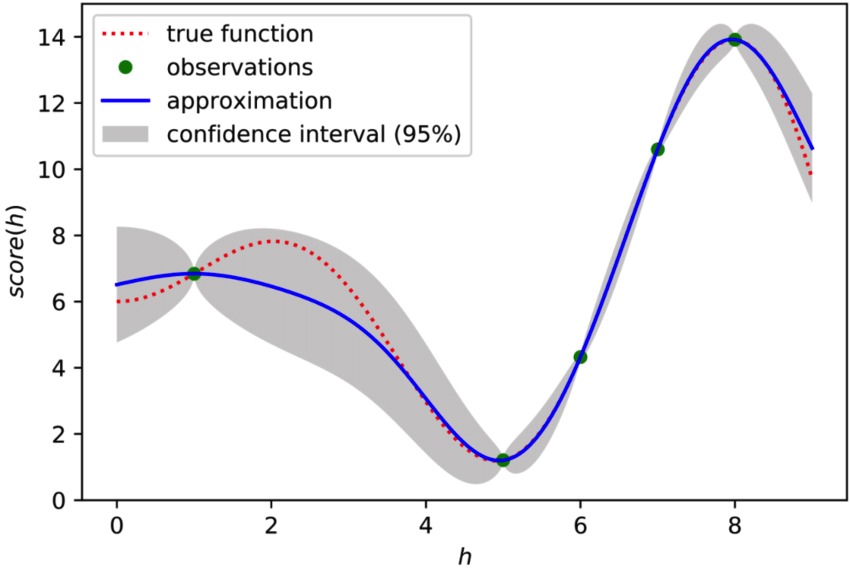
這個概率模型通常是基于高斯過程(Gaussian Process),它能夠根據已有的觀測數據(即之前評估過的超參數組合及其對應的性能指標)來預測新的超參數組合的性能,并據此選擇新的超參數組合進行評估。
避免稀疏梯度和探索-利用平衡問題:貝葉斯優化避免了傳統優化方法中遇到的稀疏梯度和探索-利用平衡問題的影響。
提高搜索效率:貝葉斯優化能夠有效地搜索高維參數空間,從而提高搜索效率
defblack_box_function(x,y):
"""Functionwithunknowninternalswewishtomaximize.
Thisisjustservingasanexample,forallintentsand
purposesthinkoftheinternalsofthisfunction,i.e.:theprocess
whichgeneratesitsoutputvalues,asunknown.
"""
return-x**2-(y-1)**2+1
frombayes_optimportBayesianOptimization
pbounds={'x':(2,4),'y':(-3,3)}
optimizer=BayesianOptimization(
f=black_box_function,
pbounds=pbounds,
random_state=1,
)
optimizer.maximize(
init_points=2,
n_iter=3,
)
方法4:模擬退火模擬退火算法(Simulated Annealing,簡稱SA)是一種基于概率的啟發式隨機搜索優化算法,靈感來源于物理中的退火過程。它通過模擬金屬退火過程中分子運動的方式來解決復雜的優化問題。
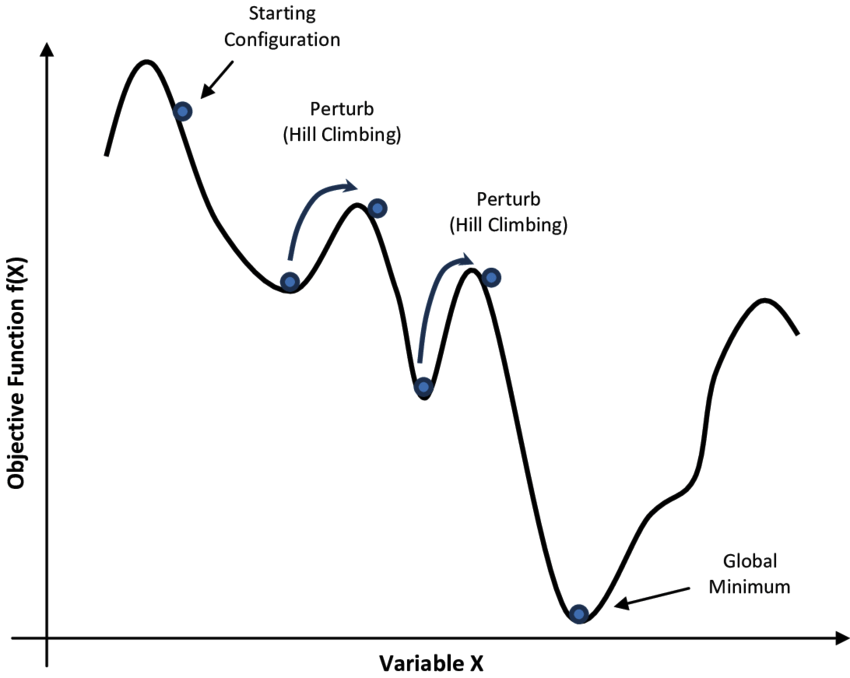
從一個初始解開始,并設置一個較高的初始溫度。在當前解的鄰域中隨機生成一個新的解,計算新解的目標函數值。如果新解比當前解好,則接受新解;如果新解比當前解差,仍然以一定的概率接受新解。
- 全局優化:模擬退火算法能夠在整個解空間中進行搜索,有助于找到全局最優解,尤其適用于解決具有多個局部最優解的復雜問題。
隨機性:算法通過隨機擾動和接受劣解的方式,增加了搜索過程的隨機性,有助于跳出局部最優解。
方法5:遺傳算法遺傳算法(Genetic Algorithm, GA)是一種模擬自然界進化過程的優化算法,它基于自然選擇和群體遺傳機理,通過模擬繁殖、雜交和突變等現象來求解優化問題。 隨機生成一個初始種群,每個個體(解決方案)被編碼為一個染色體,將兩個個體的一部分基因組合在一起,生成新的個體。隨機更改個體的一些基因值,以引入新的遺傳變異。
隨機生成一個初始種群,每個個體(解決方案)被編碼為一個染色體,將兩個個體的一部分基因組合在一起,生成新的個體。隨機更改個體的一些基因值,以引入新的遺傳變異。
- 全局搜索能力:遺傳算法采用群體方式進行搜索,能夠有效地探索整個搜索空間,避免陷入局部最優解。
并行性:遺傳算法天然適合并行計算,因為每個個體的評估和選擇過程相對獨立
方法6:連續減半Successive Halving(連續減半)算法是一種高效的超參數優化方法,特別適用于大規模的參數搜索問題。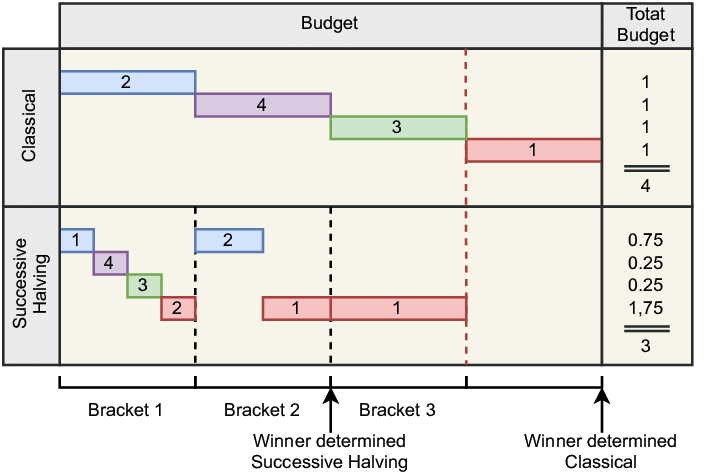 Successive Halving是一種迭代選擇過程,它通過逐步減少候選解的數量并增加剩余候選解的資源分配來優化超參數。這種方法類似于“錦標賽”或“達爾文進化”,其中表現不佳的候選解會被淘汰,而表現較好的候選解則獲得更多的資源以進行進一步的評估。
Successive Halving是一種迭代選擇過程,它通過逐步減少候選解的數量并增加剩余候選解的資源分配來優化超參數。這種方法類似于“錦標賽”或“達爾文進化”,其中表現不佳的候選解會被淘汰,而表現較好的候選解則獲得更多的資源以進行進一步的評估。
fromsklearn.datasetsimportload_iris
fromsklearn.ensembleimportRandomForestClassifier
fromsklearn.experimentalimportenable_halving_search_cv #noqa
fromsklearn.model_selectionimportHalvingGridSearchCV
X,y=load_iris(return_X_y=True)
clf=RandomForestClassifier(random_state=0)
param_grid={"max_depth":[3,None],
"min_samples_split":[5,10]}
search=HalvingGridSearchCV(clf,param_grid,resource='n_estimators',
max_resources=10,
random_state=0).fit(X,y)
search.best_params_
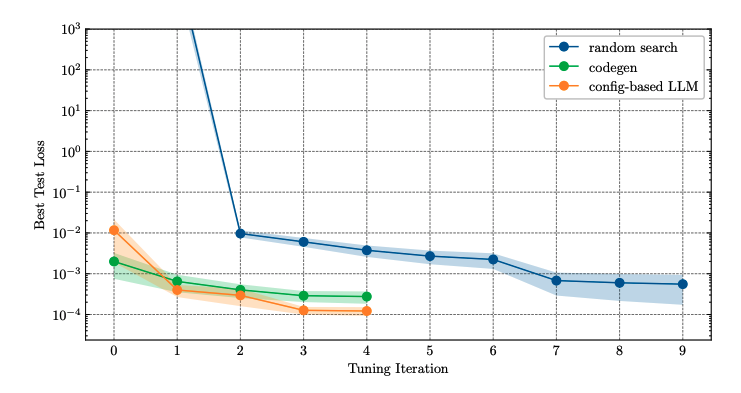
方法7:大模型思維鏈在超參數優化中,LLMs可以被用來推薦一組超參數進行評估。在接收到這些超參數后,根據提議的配置訓練模型,并記錄最終的指標(例如,驗證損失)。然后,再次詢問LLM以獲取下一組超參數。這個過程是迭代的,直到耗盡搜索預算。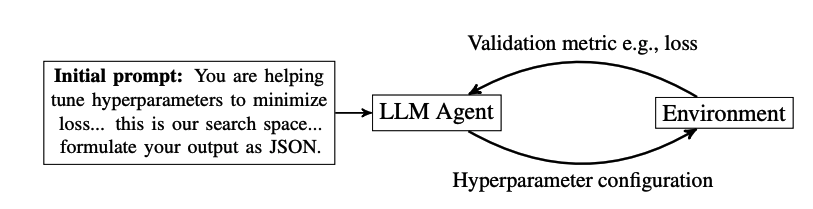
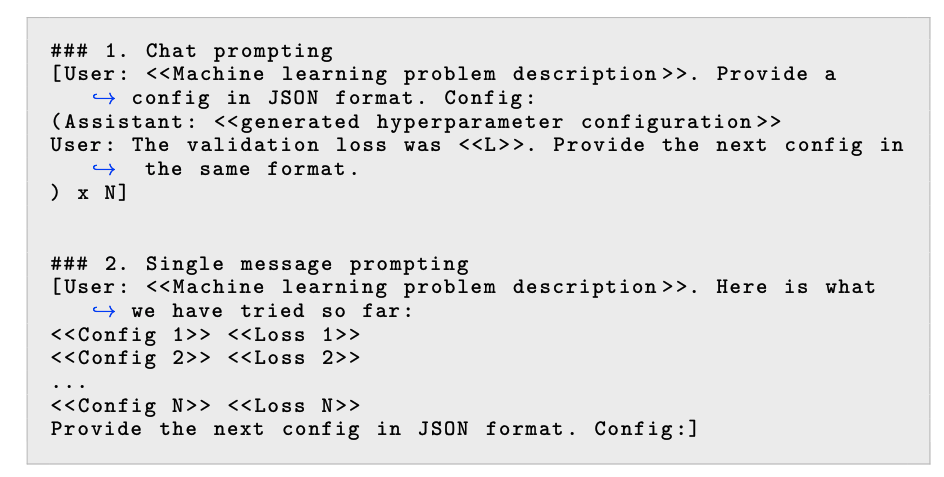
LLMs在進行超參數優化時,可以利用鏈式思考推理,這意味著它們可以生成解釋其推薦的理由。這種推理能力可以幫助理解模型為何推薦特定的超參數,并提供更深入的洞察。
-
人工智能
+關注
關注
1804文章
48750瀏覽量
246697 -
模型
+關注
關注
1文章
3493瀏覽量
50026 -
機器學習
+關注
關注
66文章
8492瀏覽量
134125
發布評論請先 登錄








 工商網監
工商網監
評論