 Hadoop 生態系統在大數據處理中的應用與實踐
Hadoop 生態系統在大數據處理中的應用與實踐
隨著數據量的爆發式增長,大數據處理技術成為企業關注焦點,Hadoop 生態系統在其中扮演著核心角色。
Hadoop Distributed File System(HDFS)是其分布式文件存儲基礎。它將大文件分割成多個數據塊,存儲在不同節點上,實現高容錯性和高擴展性。NameNode 負責管理文件系統命名空間和元數據,DataNode 負責實際數據存儲。上傳文件時,HDFS 自動將文件切塊并分配到不同 DataNode,確保數據可靠性。
MapReduce 是分布式計算模型,用于大規模數據集并行處理。以經典的 WordCount 案例來說,Map 階段將輸入文本分割成單詞,并映射為鍵值對,如(“apple”,1);Reduce 階段將相同單詞的鍵值對匯總,統計出每個單詞的出現次數。這種分而治之的思想,能高效處理海量數據。
Hive 提供了類 SQL 的查詢語言 HiveQL,使數據分析人員能方便地對存儲在 HDFS 上的數據進行查詢和分析。Hive 將 HiveQL 語句轉化為 MapReduce 任務執行,降低了大數據處理的門檻。例如統計電商訂單數據中的總訂單數、各品類銷售數量等,使用 HiveQL 能快速完成。
HBase 是基于 HDFS 的分布式 NoSQL 數據庫,適用于海量結構化數據的實時讀寫。比如在物聯網場景中,設備產生的海量實時數據,可通過 HBase 快速存儲和查詢。深入掌握 Hadoop 生態系統,能有效應對大數據處理挑戰,挖掘數據價值。
審核編輯 黃宇
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
大數據
+關注
關注
64文章
8950瀏覽量
139467
發布評論請先 登錄
相關推薦
熱點推薦
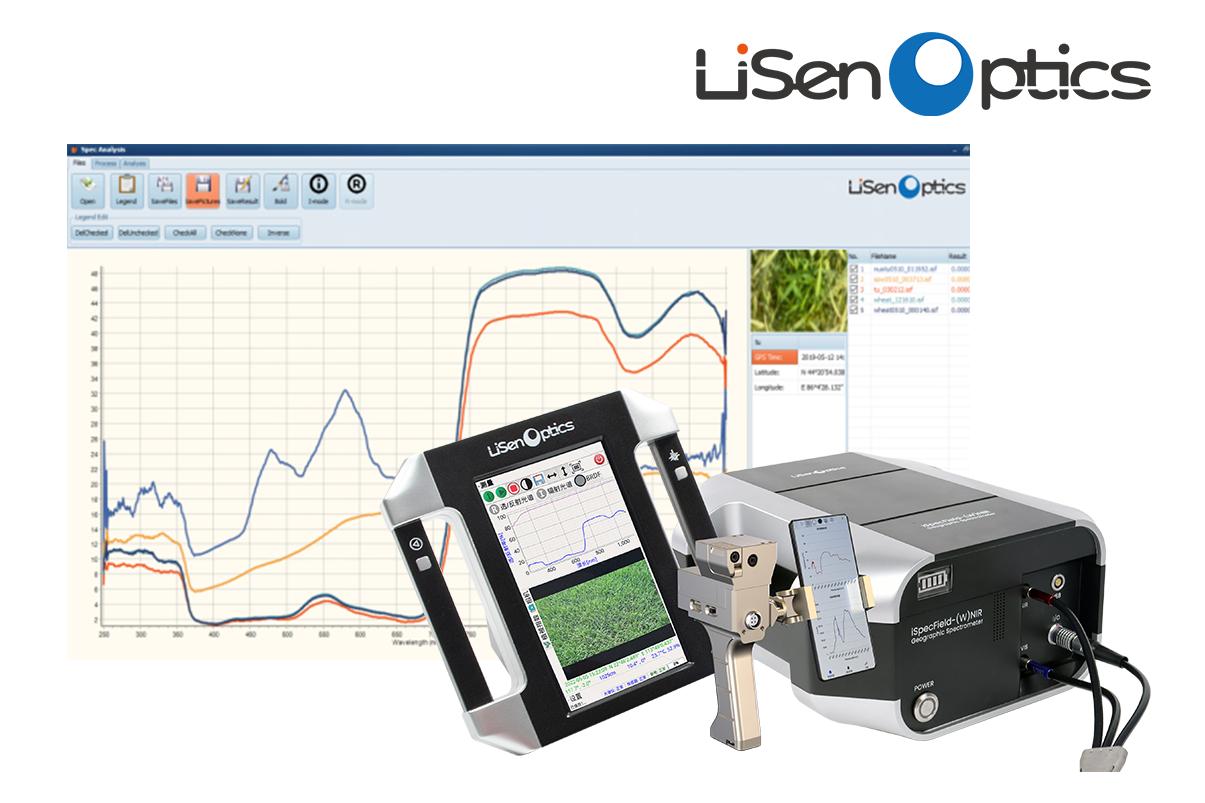
地物光譜儀在多維生態系統監測中的應用
在氣候變化與生物多樣性快速演變的背景下,生態系統的監測與研究正走向精細化、數據化和智能化。越來越多科研人員將一種名為“地物光譜儀”的設備,視為構建生態研究“
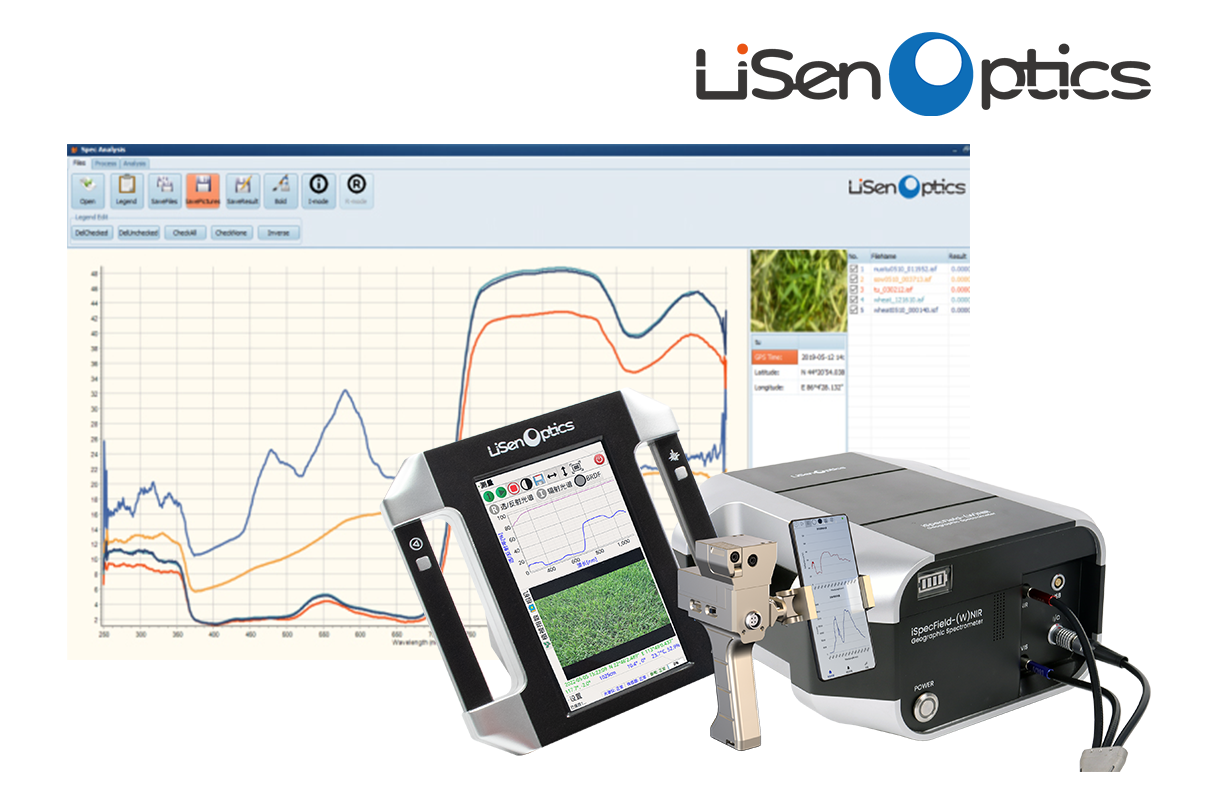
水色遙感精細化:地物光譜儀在水生態系統監測中的典型應用
在遙感生態監測日益精細化的今天,“地物光譜儀”已經成為水生態系統監測中不可或缺的利器。從湖泊富營養化預警到水華藍藻監測,再到水體透明度與懸浮物濃度的估算,地物光譜儀正以其高光譜分辨率和
如何在光子學中利用電子生態系統
本文介紹了如何在光子學中利用電子生態系統。 這一目標要求光子學制造利用現有的電子制造工藝和生態系統。光子學必須采用無晶圓廠模型、可以在焊接步驟中
安森美PRISM生態系統助力相機開發
安森美(onsemi)開發了一個高級圖像傳感器模塊參考設計 (Premier Reference Image Sensor Module,PRISM) 生態系統,大大縮短了原型開發周期,進一步減輕了工程負擔,提高了相機質量,并最終幫助我們的客戶實現產品快速上市。
英監管機構或優先調查蘋果谷歌移動生態系統
是基于調查小組對蘋果和谷歌在移動生態系統中的行為進行的深入研究。研究結果顯示,蘋果和谷歌在移動設備上的操作系統、應用商店和網絡瀏覽器等領域形
英國CMA將對蘋果谷歌移動生態系統展開調查
。 據悉,此次調查將重點關注蘋果和谷歌在操作系統、應用商店以及智能手機瀏覽器等領域的市場地位。CMA將仔細審查這兩家公司是否存在濫用市場支配地位、阻礙創新或損害消費者權益的行為。 隨著科技的飛速發展,移動生態系統已成為數
笙泉完善的MCU生態系統(ECO System),賦能高效開發、提升競爭優勢
本帖最后由 noctor 于 2024-12-27 10:46 編輯
笙泉完善的MCU生態系統(ECO System),賦能高效開發、提升競爭優勢
完善的生態系統
笙泉科技已深耕MCU
發表于 12-27 09:58
對三星而言開放生態系統是什么
在過去的五年里,三星投入了大量精力來建立團隊、文化和流程,成為開放生態系統的積極貢獻者。那么,為什么一家硬件公司會進行這樣的投資?其價值何在?我們如何將硬件差異化與開源和標準結合起來?
FPGA在數據處理中的應用實例
廣泛應用于以太網、USB、PCI Express、SATA、HDMI等通信協議的處理。它們通過高速串行接口實現數據傳輸,并利用硬件加速技術進行協議解析和數據處理,從而提高系統性能。例如
英特爾和AMD組建x86生態系統咨詢小組
在聯想2024 Tech World大會上,英特爾CEO帕特·基辛格宣布了一項重大合作:英特爾與AMD將共同組建X86生態系統咨詢小組。
基于Kepware的Hadoop大數據應用構建-提升數據價值利用效能
處理超大數據集。 Hadoop的生態系統非常豐富,包括許多相關工具和技術,如Hive、Pig、HBase等,這些工具可以方便地構建復雜的大數據
邊緣計算物聯網關如何優化數據處理流程
在物聯網技術日新月異的今天,數據的產生、傳輸與處理已成為推動行業智能化轉型的關鍵。邊緣計算物聯網關,作為這一生態系統中的核心組件,正以其獨特






 工商網監
工商網監
評論