") 復(fù)旦提出大模型推理新思路:Two-Player架構(gòu)打破自我反思瓶頸
復(fù)旦提出大模型推理新思路:Two-Player架構(gòu)打破自我反思瓶頸
在 AI 領(lǐng)域,近期的新聞焦點無疑是關(guān)于「Scaling Law 是否撞墻?」的辯論。這一曾經(jīng)被視作大模型發(fā)展的第一性原理,如今卻遭遇了挑戰(zhàn)。 在這樣的背景下,研究人員開始意識到,與其單純堆砌更多的訓(xùn)練算力和數(shù)據(jù)資源,不如讓模型「花更多時間思考」。以 OpenAI 推出的 o1 模型為例,通過增加推理時間,這種方法讓模型能夠進行反思、批評、回溯和糾正,大幅提升了推理表現(xiàn)。 但問題在于,傳統(tǒng)的自我反思(Self-Reflection)和自我糾正(Self-Correction)方法存在明顯局限 —— 模型的表現(xiàn)往往受制于自身能力,缺乏外部信號的引導(dǎo),因此容易觸及瓶頸,止步不前。
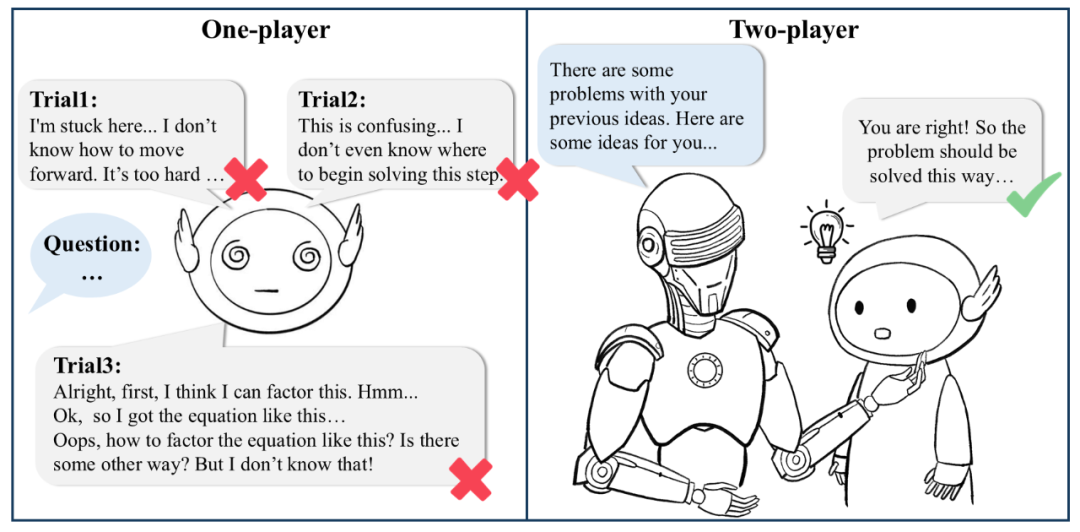
▲單一模型在傳統(tǒng)自我糾正與自我優(yōu)化時往往難以糾正自身,而雙模型協(xié)作架構(gòu)下能夠獲得更有建設(shè)性的建議。 針對這些挑戰(zhàn),復(fù)旦 NLP 研究團隊提出了一種全新的雙模型協(xié)作架構(gòu)(Two-Player Paradigm)。簡單來說,就是讓評判模型(Critique Model)參與到行為模型(Actor Model)的推理過程中 —— 行為模型專注推理,評判模型則以步驟級別的反饋為行為模型指路。 這種設(shè)計打破了傳統(tǒng)依賴于單一模型的限制,也讓行為模型能夠在訓(xùn)練和推理階段實現(xiàn)自我改進。更重要的是,整個框架無需依賴模型蒸餾過程(例如直接模仿 o1 的思考過程),而是通過多模型協(xié)作互動獲得了高質(zhì)量、可靠的反饋信號,最終實現(xiàn)性能隨計算投增大的不斷提升。
在這篇工作中,研究團隊聚焦以下四個核心內(nèi)容:
如何自動化構(gòu)建 critique 數(shù)據(jù)集,訓(xùn)練高效、可靠的評判模型(Critique Model);
使用評判模型推動測試階段的擴展(Test-time Scaling);
通過交互協(xié)作提升行為模型的訓(xùn)練性能(Training-time Scaling);
基于 critique 數(shù)據(jù)的 Self-talk 幫助模型自我糾錯。
作者們提出了一個創(chuàng)新性框架——AutoMathCritique,可以自動生成步驟級別的反饋(step-level feedback),并基于此構(gòu)建了名為 MathCritique-76k 的數(shù)據(jù)集,用于訓(xùn)練評判模型。 進一步,研究團隊深入探討了評判模型在測試階段助力推理性能的機制,并通過引入雙模型協(xié)作架構(gòu) Critique-in-the-Loop,有效緩解了模型探索與學(xué)習(xí)的自訓(xùn)練過程中常見的長尾分布問題,為復(fù)現(xiàn) OpenAI o1 深度推理表現(xiàn)開辟了新的可能性。
論文題目:
Enhancing LLM Reasoning via Critique Models with Test-Time and Training-Time Supervision
論文鏈接:
http://arxiv.org/abs/2411.16579
項目主頁:
https://mathcritique.github.io/
代碼鏈接:
https://github.com/WooooDyy/MathCritique
數(shù)據(jù)鏈接:
https://huggingface.co/datasets/MathCritique/MathCritique-76k
* 本工作部分實驗基于昇騰 910 完成
AutoMathCritique—自動化、可擴展地構(gòu)造步驟級Critique數(shù)據(jù)為了研究 Critique 模型在架構(gòu)中的作用與性能,作者們首先訓(xùn)練了一個可靠的 Critique 模型。鑒于步驟級別反饋數(shù)據(jù)的稀缺,作者們提出了一種新的框架AutoMathCritique,用于自動化構(gòu)造多樣性推理數(shù)據(jù),并獲得步驟級別的反饋。
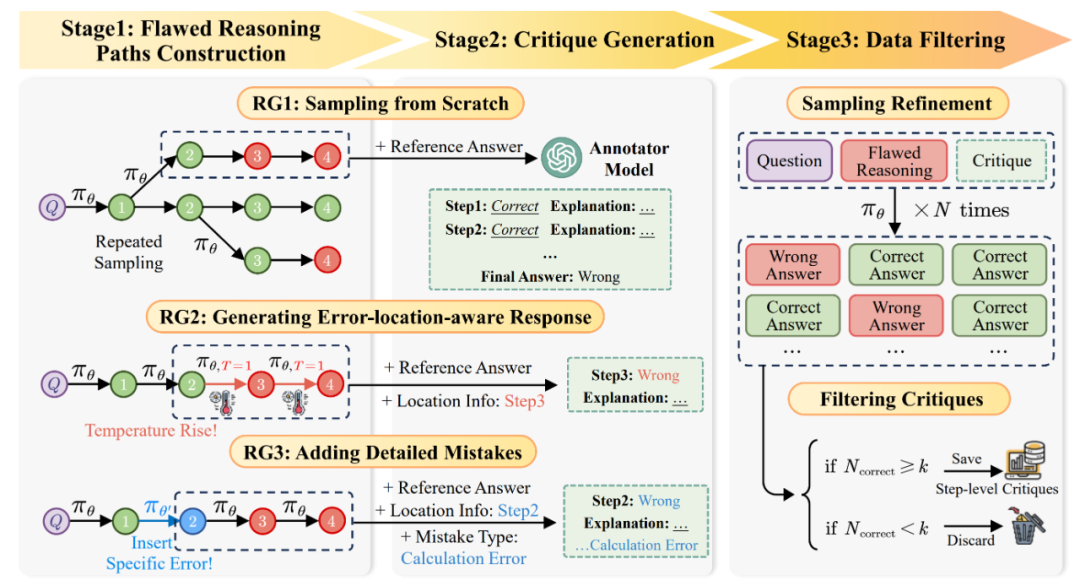
▲ AutoMathCritique 流程:通過多種方式收集錯誤數(shù)據(jù)與錯誤信息,并交由標注模型進行步驟級別標注。在標注完相應(yīng)問答反饋對后,交由 Actor 模型進行進一步篩選。
圖中,第一個階段「構(gòu)建錯誤推理路徑」包含三種策略:
RG1: 直接構(gòu)建整體推理路徑,在高溫度下讓 Actor 模型進行重復(fù)采樣,采樣出的數(shù)據(jù)只會包含最終答案的錯誤信息;
RG2: 以某一條推理路徑為模板,在特定的推理步后逐漸提高溫度,讓 Actor 模型采樣出新的軌跡,采樣出的數(shù)據(jù)會包含最終答案的錯誤信息與錯誤步驟的位置信息;
RG3: 以某一條推理路徑為模板,對特定的推理步插入多樣化錯誤內(nèi)容,讓 Actor 模型繼續(xù)采樣出完整軌跡,采樣出的數(shù)據(jù)會包含最終答案的錯誤信息與錯誤步驟的位置與錯誤信息。
第二個階段「標注步驟級別反饋」提供了詳細的反饋數(shù)據(jù):為了更好的提升反饋數(shù)據(jù)的質(zhì)量,研究人員將第一階段獲得的各類錯誤信息交由標注模型,并提供參考答案、錯位定位和錯誤類型信息作為輔助,幫助標注模型提供步驟級別的反饋。 第三個階段「精篩反饋」篩選出更加高質(zhì)量的數(shù)據(jù):為了進一步篩選出能夠更好幫助 Actor 模型的數(shù)據(jù),研究人員將錯誤推理路徑與反饋數(shù)據(jù)一起輸入給 Actor 模型,根據(jù)其修改后答案的正確率決定是否保留。

▲AutoMathCritique收集到的信息示例 通過如上方案構(gòu)建的數(shù)據(jù)既包含模型本身所可能犯下的錯誤,又構(gòu)建了域外錯誤,使 Critique 模型能夠?qū)W習(xí)大批量、多樣化錯誤數(shù)據(jù)。而步驟級別的反饋數(shù)據(jù)使得 Actor 模型能夠更好的定位自己所犯下的錯誤,進而提升修改的質(zhì)量。 使用如上框架,研究團隊構(gòu)建了一個擁有 76k 數(shù)據(jù)量的數(shù)據(jù)集MathCritique-76k,其中既包含了正確推理軌跡又包含了自動化合成的錯誤軌跡,并且篩選了優(yōu)質(zhì)的步驟級別反饋數(shù)據(jù)用于之后的訓(xùn)練。

▲MathCritique-76k 的數(shù)據(jù)構(gòu)成
Critique模型如何幫助Actor模型提高測試性能?
實驗探究:Critique模型在測試時對Actor模型的幫助
基于如上構(gòu)建的數(shù)據(jù)集,作者以 Llama3-Instruct 系列為基座模型,微調(diào)了一個專門用于提供步驟級別反饋的 Critique 模型。其選取了常用的數(shù)學(xué)推理數(shù)據(jù)集 GSM8K 與 MATH 為測試對象,進行了多種實驗。 1. Critique 模型對錯誤的識別率與對 Actor 模型的幫助
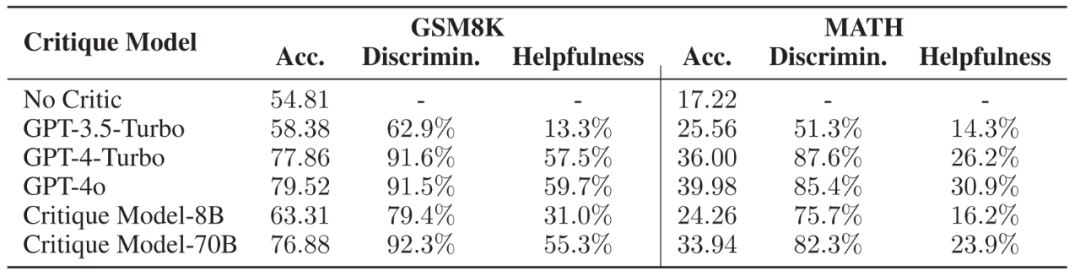
▲ 不同 Critique 模型的推理軌跡正誤判斷能力與對 Actor 模型的幫助,Acc. 代表 Actor 模型在不同 Critique 模型的幫助下能夠達到的正確率。
作者選取了兩個微調(diào)后的模型與 SOTA 模型作為研究對象,發(fā)現(xiàn) Critique 模型能夠極為有效地識別出推理軌跡的正確與否,并且其所提供的步驟級別反饋能夠被 Actor 模型所用,使得 Actor 模型能夠顯著改進自己的錯誤,以達到更高的正確率。 為了更進一步探究 Actor 模型是如何受到幫助的,作者將數(shù)據(jù)集按照 Actor 模型初始的正確率分為了 5 個難度,并且比較在不同難度下,有無反饋數(shù)據(jù)對模型回答正確率的影響。
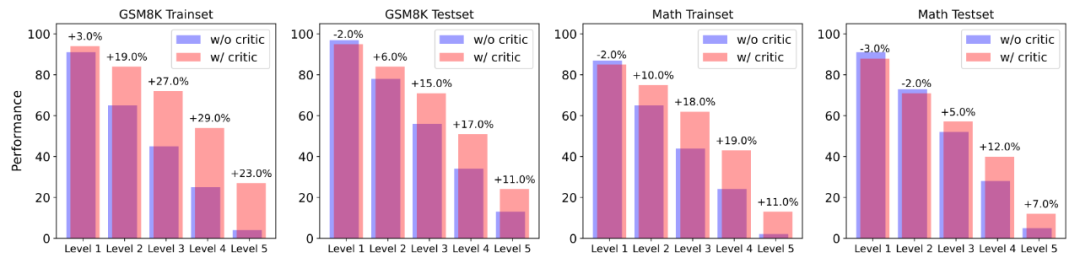
▲以 Actor 模型正確率(采樣 100 次)作為難度分級的指標,使用 Critique 模型的反饋數(shù)據(jù)能在更高難度題目下獲得更大的幫助。 研究發(fā)現(xiàn) Actor 模型在幾乎各個難度下,正確率均有所提升。而且在難度級別較高的題目中,Actor 模型均收到了更大的幫助,表現(xiàn)為正確率的顯著提升。這說明,使用 Critique 模型幫助 Actor 模型改進其所不會的難題,可以是解決自我提升長尾分布難題的新方法。 2. 在 Critique 模型幫助下增加推理計算投入的性能
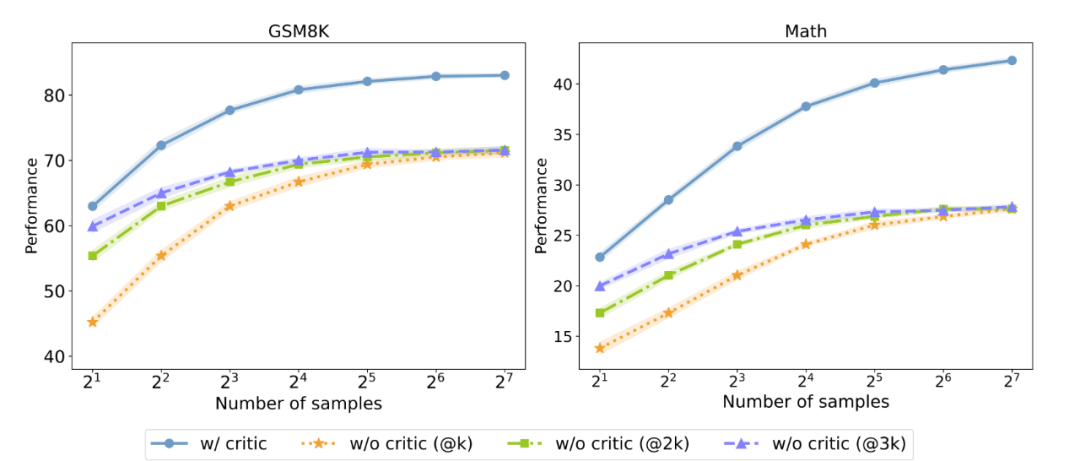
▲有無反饋數(shù)據(jù)對測試時 Majority voting 性能的影響,@3K 代表采樣數(shù)量為橫坐標的三倍,以控制采樣消耗相同。
研究人員進一步探究 Critique 模型能否在測試時提高 Actor 模型性能。他們以并行 Majority voting 的結(jié)果作為測試指標,發(fā)現(xiàn)即使在控制了相同的采樣消耗的情況下,擁有反饋數(shù)據(jù)依舊能夠顯著超過沒有反饋數(shù)據(jù)的 Actor 模型。這說明,加入 Critique 模型可以作為實現(xiàn) Test-time Scaling 的新方法之一。
Critique模型如何幫助Actor模型探索與學(xué)習(xí)?基于以上在 Test-time 的發(fā)現(xiàn),研究人員將測試階段所展現(xiàn)出來的優(yōu)勢用于訓(xùn)練階段(Training-time)的探索與學(xué)習(xí)(Exploration & Learning),進一步探究 Critique 模型能否幫助 Actor 模型在訓(xùn)練時進行自我優(yōu)化。 為此,他們提出了一個有難度感知的雙模型協(xié)作優(yōu)化架構(gòu)Critique-in-the-loop Self-Improvement,用于獲得更高質(zhì)量、多樣化的數(shù)據(jù),并緩解自我優(yōu)化采樣時的長尾難題。 Critique-in-the-loop Self-Improvement:有難度感知的雙模型協(xié)作優(yōu)化架構(gòu)

▲Critique-in-the-loop Self-Improvement算法偽代碼 研究人員提出了一種雙模型協(xié)作優(yōu)化架構(gòu)。在第一次采樣時,Actor 模型會在訓(xùn)練集上重復(fù)多次采樣。針對錯誤數(shù)據(jù),研究人員使用 Critique 模型輔助 Actor 模型進行多次自我修正,從而達到了難度感知的目的。每一輪迭代時,Actor 模型總會學(xué)習(xí)正確的數(shù)據(jù),從而實現(xiàn)自我提升。
實驗探究:Critique模型在訓(xùn)練時對模型性能的影響
1. Critique-in-the-loop 能夠有效幫助模型自我提升
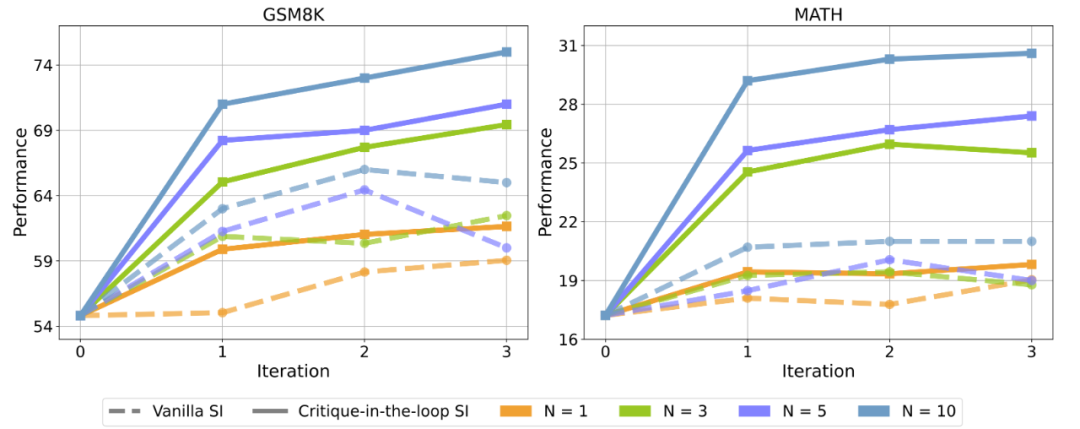
▲相比于在訓(xùn)練階段只使用 Actor 模型進行采樣(Vanilla SI), 使用 Critique 模型后,Actor 模型在測試集正確率上均有顯著提升。圖中 N 代表采樣次數(shù)。 實驗發(fā)現(xiàn),Vanilla Self-Improve 盡管能在一定程度上提升模型的性能,然而其很快達到瓶頸,甚至開始出現(xiàn)性能的下滑。但是 Critique-in-the-loop 能夠顯著改善這一情況,既使得模型的自我提升較為穩(wěn)定,又能夠在多個采樣次數(shù)下獲得相當顯著的性能提升。研究人員認為,這與長尾分布難題的緩解密不可分。 2. Critique-in-the-loop 能夠緩解長尾分布難題 為了進一步證實長尾分布難題獲得了緩解,研究人員進一步探究在訓(xùn)練時,不同難度問題的訓(xùn)練數(shù)據(jù)占總體數(shù)據(jù)集的比例。
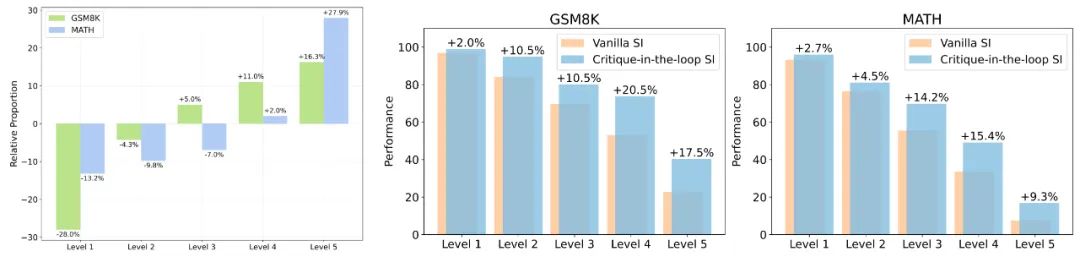
▲圖1. 相比于 Vanilla SI、Critique-in-the-loop 在不同難度問題中采樣出的訓(xùn)練數(shù)據(jù)比例變化。圖 2、圖 3:兩者在測試集中,不同難度問題的性能表現(xiàn)比較。 實驗發(fā)現(xiàn),Critique-in-the-loop 能夠更有效地平衡不同難度問題占總體數(shù)據(jù)集的占比。值得注意的是,難度較高的問題所占的比例出現(xiàn)顯著上升,證實了長尾分布難題得到緩解。與此同時,研究團隊還分析了測試集上不同難度問題的性能表現(xiàn)。實驗結(jié)論也說明,在較難問題上模型展現(xiàn)出性能的顯著提高。 3. 在測試時使用 Critique 模型,Critique-in-the-loop 能夠帶來更大的提升
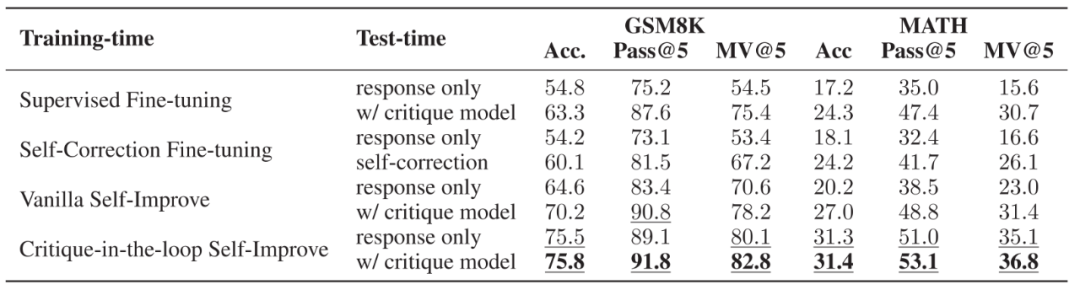
▲不同訓(xùn)練策略與測試策略的性能性能。訓(xùn)練時,使用了直接微調(diào)推理與有反饋的糾正數(shù)據(jù),直接微調(diào)推理與自我糾正數(shù)據(jù),無 Critique 模型的自我提升以及有 Critique 模型的自我提升四種方式。測試時,比較了是否使用 Critique 模型兩種方式。 鑒于作者之前所提到的訓(xùn)練與測試時 Critique 模型的好處,作者進一步分析了兩者結(jié)合后的效果。實驗發(fā)現(xiàn)當使用 Critique-in-the-loop 時,在測試階段使用 Critique 模型帶來的性能提升較小,說明 Critique 模型所帶來的性能提升已經(jīng)被融入到了推理模型中。盡管如此,相比于其他訓(xùn)練方案,其性能依舊有顯著優(yōu)勢。
深入分析Critique Models
實驗探究:Critique模型擴展性(Scaling Properties)
為了探究 Critique 模型是否對多種模型——尤其是那些模型大小與性能高于自己的 Actor 模型——做到相類似的幫助,作者固定 Critique 模型為 3B 大小的 Qwen-2.5 模型,并使用不同模型大小的 Qwen-2.5 系列模型(1.5B、3B、7B、14B)作為 Actor 模型進行了實驗。
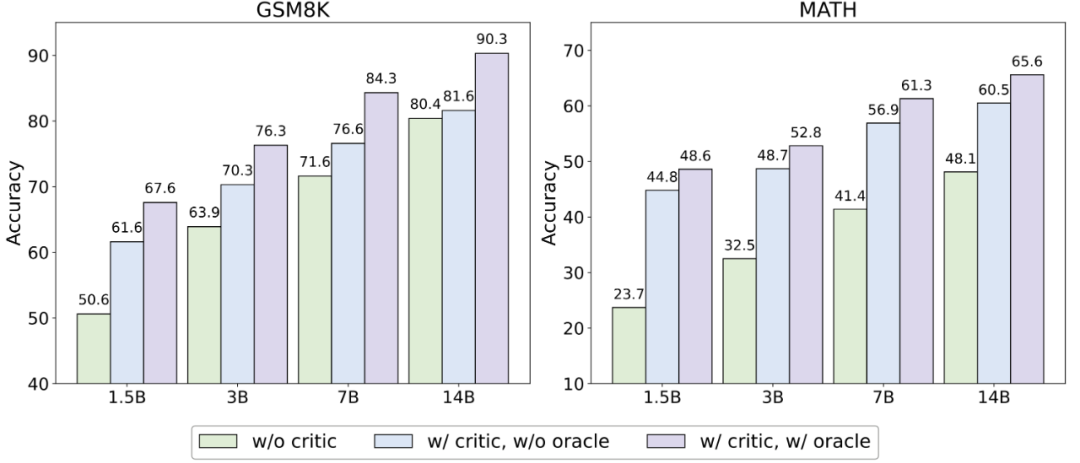
▲不同模型大小的 Actor 模型在測試賽上正確率表現(xiàn)。其中 w/o critic 代表不使用 Critique 模型,w/orcale 代表僅對原始回答錯誤的數(shù)據(jù)進行修正。 實驗結(jié)論發(fā)現(xiàn),無論何種模型大小, Critique 模型的存在均能顯著提升模型測試性能。然而,在較為簡單的數(shù)據(jù)集 GSM8K 上,更大的模型獲得的幫助不如較小的模型;但在較為困難的數(shù)據(jù)集 MATH 上,性能的提升依舊顯著。
實驗探究:Critique模型對Majority Voting性能的影響
作者進一步探究Critique 模型對 Majority Voting 性能的影響,探究當采樣次數(shù)更大時的表現(xiàn)。
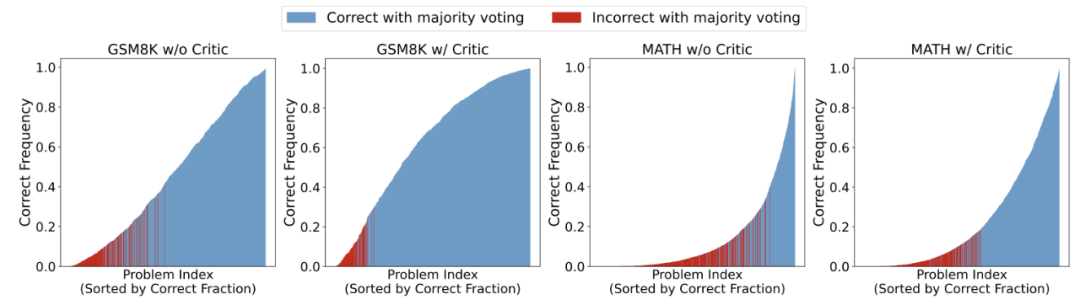
▲對 Actor 模型采樣 1000 次后的性能圖,問題按照通過率由低到高進行排序,其中紅色部分表示該問題在 Majority Voting 下依舊做錯。 研究發(fā)現(xiàn),擁有 Critique 模型的情況下,Actor 模型在整體上提高了問題的正確率,從而帶來了 Majority Voting 的穩(wěn)定性。另外,作者們還發(fā)現(xiàn),不使用 Critique 模型時,盡管 Actor 模型會給出占比較多的正確答案,然而非正確答案卻擁有更高的占比。 而擁有 Critique 模型時, Actor 模型最終修改給出的答案更為一致,使得正確答案的占比會超過某些出現(xiàn)頻率較高的錯誤答案,幫助模型能夠更好的選出正確答案。
實驗探究:不同計算投入策略對性能的影響
作者繼續(xù)探討了多種計算提升消耗策略下 Actor 模型的表現(xiàn)。實驗使用了并行采樣與線性采樣兩種方式,并且比較了 Pass@k、Majority Voting 以及 Sequential Final(僅選取最終答案)三種方式。

▲圖 1 及圖 2:線性與并行采樣策略下,模型的 Pass@k 表現(xiàn);圖 3 及圖 4:不同采樣策略下模型的 Majority voting 表現(xiàn)。橫坐標表示采樣樣本的數(shù)量 實驗結(jié)果發(fā)現(xiàn),在 Pass@k 的設(shè)定下,線性采樣的表現(xiàn)略低于并行采樣,這可能源于并行采樣會帶來更多樣化的答案選擇。而在模型需要給出答案的設(shè)定下,僅選取最終答案并不如 Majority voting 的表現(xiàn)要好,強調(diào)了內(nèi)在一致方式的重要性。 隨著采樣次數(shù)的提高,線性采樣的性能超過了并行采樣的方式,這有可能源于當采樣次數(shù)足夠大時,并行采樣帶來的多樣性答案可能有害于最終的性能表現(xiàn),而線性采樣通過反復(fù)修改一個回答,使得結(jié)果更加穩(wěn)定。
A Step Further—基于Critique數(shù)據(jù)構(gòu)建Self-talk模型幫助自我糾錯最后,受到 OpenAI o1 模型的推理啟發(fā),研究人員進一步探究Self-talk形式幫助模型自我糾錯的可能性。Self-talk 形式幫助模型在每一個推理步驟后立刻開始反思與改進,而不必等整個軌跡生成完之后再進行改進。
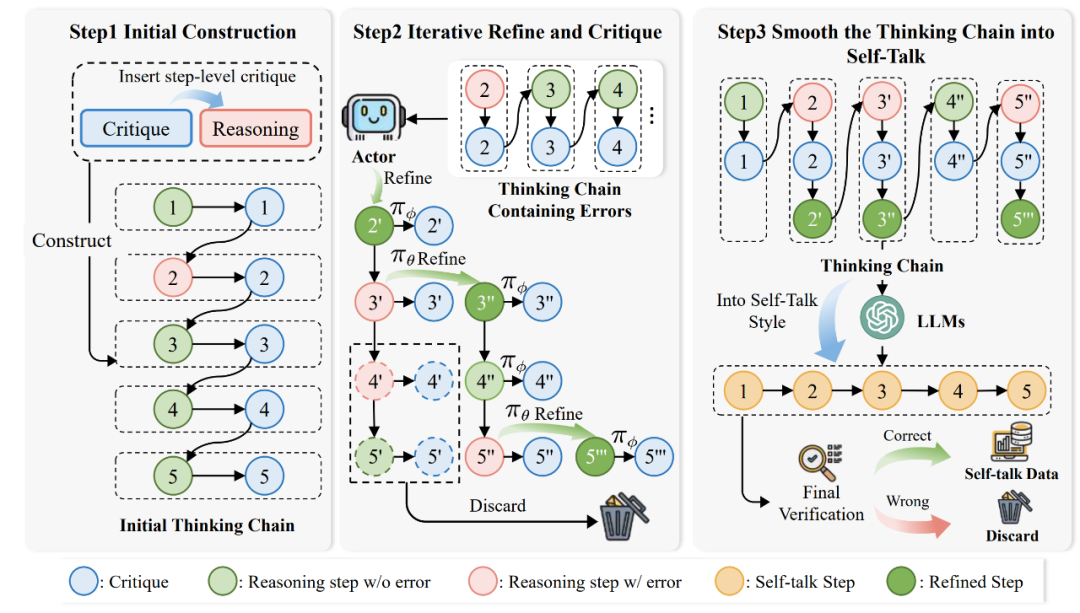
▲Self-talk 形式數(shù)據(jù)構(gòu)建示意圖 圖中,第一個階段用于「構(gòu)建初始反饋數(shù)據(jù)」。研究人員使用AutoMathCritique框架構(gòu)建步驟級別的反饋數(shù)據(jù),并加入到推理路徑中,形成初始的思維鏈。 第二個階段用于「循環(huán)修正錯誤思考鏈」。第一階段中的數(shù)據(jù)存在著錯誤的推理路徑,研究人員使用 Critique 模型幫助 Actor 模型生成新的推理路徑,并將反饋數(shù)據(jù)同樣加入到推理路徑中逐步生成思維鏈,直到整個推理路徑?jīng)]有錯誤為止。 第三個階段用于「優(yōu)化思考鏈為 Self-talk 形式」。前兩階段得到的思考鏈較為生硬,因此研究人員進一步使用模型優(yōu)化思維鏈,使其變?yōu)樽匀坏?Self-talk 形式,并保證了最終答案的正確性。

▲Self-talk 形式數(shù)據(jù)示例 使用如上構(gòu)建的數(shù)據(jù),研究人員訓(xùn)練了一個 Self-talk 模型。初步實驗發(fā)現(xiàn),相比于軌跡級別的自我改進,Self-talk 格式能夠顯著改善模型性能。盡管表現(xiàn)不如所提出的雙模型合作架構(gòu),然而這也揭示了其潛能所在。
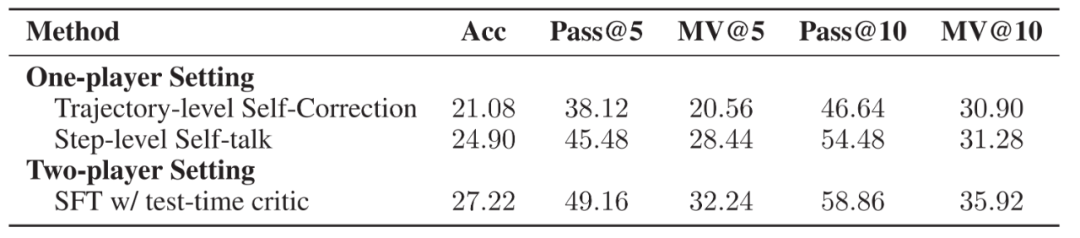
▲在 MATH 數(shù)據(jù)集上三種方法的各種指標,分別使用軌跡層面的自我改進,步驟層面的自我對話改進以及雙模型協(xié)作架構(gòu)。實驗比較了正確率、Pass@k 和 MV@k 三個指標。
總結(jié)
本文的主要貢獻包括:
提出自動化構(gòu)造步驟級別 Critique 的框架AutoMathCritique;
探究 Critique 模型對于 Actor 模型在推理時的幫助;
提出擁有難度感知方式的自我改進框架Critique-in-the-loop Self-Improvement,緩解長尾難題;
探究測試時的各種 Scaling 策略,包括模型大小,采樣策略與采樣數(shù)量等方面。
-
框架
+關(guān)注
關(guān)注
0文章
404瀏覽量
17790 -
模型
+關(guān)注
關(guān)注
1文章
3486瀏覽量
49989
原文標題:Scaling Law撞墻?復(fù)旦提出大模型推理新思路:Two-Player架構(gòu)打破自我反思瓶頸
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯(lián)網(wǎng)技術(shù)研究所】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
基于RAKsmart云服務(wù)器的AI大模型實時推理方案設(shè)計
詳解 LLM 推理模型的現(xiàn)狀

字節(jié)豆包大模型團隊提出稀疏模型架構(gòu)
字節(jié)豆包大模型團隊推出UltraMem稀疏架構(gòu)
北大攜智元機器?團隊提出OmniManip架構(gòu)
GPT架構(gòu)及推理原理

中國電提出大模型推理加速新范式Falcon


阿里云開源推理大模型QwQ
使用vLLM+OpenVINO加速大語言模型推理

高效大模型的推理綜述






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論