") OpenAI o1 思維鏈模型的筆記
OpenAI o1 思維鏈模型的筆記

“對于復雜推理任務來說,這是一個重要的進展,代表了人工智能能力的新水平。鑒于此,我們將計數(shù)器重置為 1,并將這一系列命名為 OpenAI o1。”
OpenAI 上周發(fā)布了兩個新的預覽模型:o1-preview 和 o1-mini(mini 不是預覽版)--之前傳言的代號為 “草莓”。關于這些模型有很多需要了解的地方--它們并不像 GPT-4o 那樣簡單,而是在成本和性能方面做了一些重大權衡,以換取 “推理 ”能力的提高。 新模型的能力用以下兩張圖表述的很清楚了(主要是數(shù)學和代碼能力的提升):
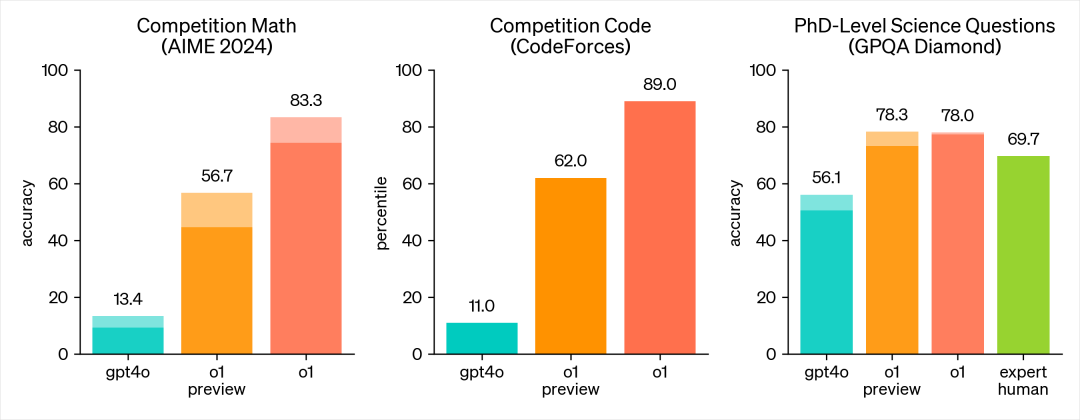
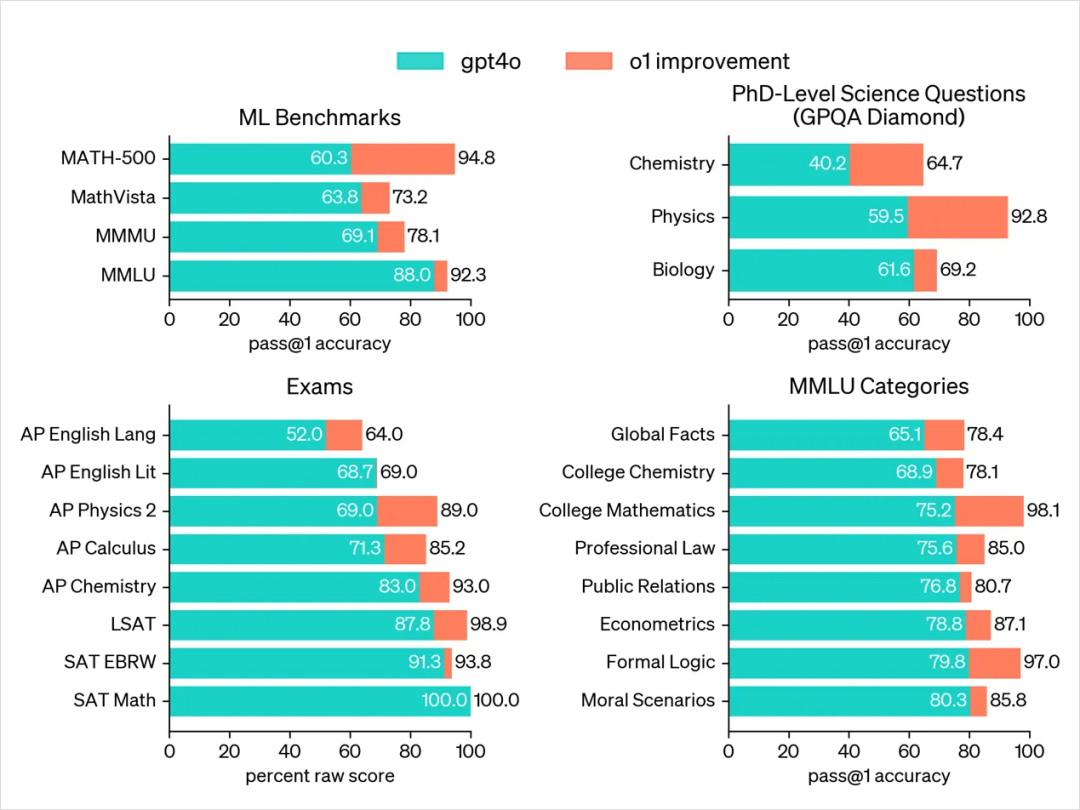
o1 詳細的介紹很多公眾號都有,這里就不再贅述了。本文只從思維鏈的角度,做一些分享,主要分為以下幾方面:
為思維鏈訓練
API 文檔中的細節(jié)
隱藏的推理 token
示例
未來的創(chuàng)新
為思維鏈訓練
我們開發(fā)了一系列新的人工?智能模型,旨在花更多時間思考后再做出反應。
? 理解新模型的一種方式是將其視為思維鏈提示模式(Promopt)的擴展,即 “一步一步思考” 的技巧。 OpenAI 的文章 Learning to Reason with LLMs (https://openai.com/index/learning-to-reason-with-llms/)解釋了新模型的訓練方法:
我們的大規(guī)模強化學習算法在一個數(shù)據(jù)效率極高的訓練過程中,教會模型如何利用其思維鏈進行富有成效的思考。我們發(fā)現(xiàn),隨著強化學習(訓練時間計算)和思考時間(測試時間計算)的增加,o1 的性能也在不斷提高。這種方法的擴展限制與 LLM 預訓練的限制有很大不同,我們正在繼續(xù)研究。
[...]
通過強化學習,o1 學會了訓練自己的思維鏈和完善自己使用的策略。它學會識別和糾正錯誤。它學會把棘手的步驟分解成更簡單的步驟。它學會在當前方法無效時嘗試不同的方法。這一過程極大地提高了模型的推理能力。
實際上,這意味著模型可以更好地處理更為復雜的提示,在這種情況下,要想取得好的結果,除了預測下一個 token 外,還需要回溯和 “思考”。API 文檔中的細節(jié)關于新模型及其權衡的一些最有趣的細節(jié)可以在它們的 API 文檔中找到:
對于需要圖像輸入、函數(shù)調用或持續(xù)快速響應時間的應用程序,GPT-4o 和 GPT-4o mini 仍將是正確的選擇。但是,如果您的目標是開發(fā)需要深度推理并能適應較長響應時間的應用程序,那么 o1 型號可能是一個極佳的選擇。
從文檔中可以歸納出一些要點:
API 訪問限制:新的 o1-preview 和 o1-mini 模型的 API 訪問權限目前僅限于 tier 5 級賬戶--你需要至少花費 1000 美元購買 API 點數(shù)。
不支持系統(tǒng)提示(system prompt):模型使用現(xiàn)有的聊天完成 API,但只能發(fā)送用戶和助手消息。
不支持的功能:不支持流式傳輸(streaming)、工具使用(tool usage)、批量調用或圖片輸入。
響應時間:根據(jù)模型解決問題所需的推理量,請求可能需要幾秒到幾分鐘不等。
最有趣的是 “推理令牌”(reasoning tokens)的引入:這些 token 在 API 響應中不可見,但仍作為輸出令牌(output token)計費和計算。所以您將支付比 API 響應結果 token 數(shù)量更多的費用。
鑒于推理令牌的重要性,OpenAI 建議為受益于新模型的提示分配約 25000 個推理令牌。輸出令牌的數(shù)量限制將大幅增加,o1-preview 增加到 32768 個,規(guī)模較小的 o1-mini 增加到 65536 個!與 gpt-4o 和 gpt-4o-mini 模型相比,這兩個模型目前的輸出令牌限制都增加到了 16,384 個。
API 文檔中還有最后一個有趣的提示:
限制檢索增強生成(RAG)中的附加上下文:在提供附加上下文或文檔時,只包含最相關的信息,以防止模型的響應過于復雜。
這與通常的 RAG 實現(xiàn)方式有很大不同,通常的建議是在提示中塞入盡可能多的潛在相關文檔。
隱藏的推理 Token
一個讓人感覺很不爽的點:這些推理令牌在應用程序接口(API)中是不可見的,但還是要收費(花了錢看不到買了什么東西)。OpenAI 在博客中解釋了其中的原因:
假設它是忠實和可讀的,那么隱藏的思維鏈就能讓我們 “讀懂” 模型的思想,了解它的思維過程。例如,將來我們可能希望監(jiān)控思維鏈,以發(fā)現(xiàn)操縱用戶的跡象。但是,要做到這一點,模型必須能夠以不改變的形式自由表達自己的想法,因此我們不能在思維鏈上訓練任何政策遵從或用戶偏好。我們也不想讓用戶直接看到不一致的思維鏈。
因此,在權衡了用戶體驗、競爭優(yōu)勢以及對思維鏈進行監(jiān)控的選項等多重因素后,我們決定不向用戶展示原始的思維鏈。
因此,這里有兩個關鍵原因:
安全性和政策合規(guī)性:OpenAI希望模型能夠在不暴露可能違反政策規(guī)則的情況下,自由地表達其思想。這意味著模型需要有能力在不受到政策合規(guī)性或用戶偏好影響的情況下,進行自由的思考。
競爭優(yōu)勢:OpenAI不希望其他模型能夠通過訓練來模仿他們投入資源開發(fā)的推理工作。隱藏推理令牌可以作為一種保護措施,防止其他公司或模型復制他們的推理技術。
這一做法顯然無法讓用戶滿意。作為一個希望使用 LLMs 進行開發(fā)的人,可解釋性和透明度對我來說非常重要:如果我輸入了一個復雜的提示,而提示評估的關鍵細節(jié)卻被隱藏起來,而只能看到最后的結論,這讓我覺得是一大倒退。
示例OpenAI 在其公告的 “思維鏈” 部分提供了一些簡單的示例,包括生成 Bash 腳本、解決填字游戲和計算中等復雜的化學溶液的 pH 值。 這些示例表明,新的 CHatGPT 網頁版本確實展示了思維鏈的細節(jié),但并沒有顯示原始的推理令牌,而是使用了一個單獨的機制來將步驟總結為更易于人類了解的形式。
OpenAI 還有兩本新的 cookbook,其中包含更復雜的示例,但我覺得有點難以理解:
使用推理進行數(shù)據(jù)驗證展示了一個多步驟的過程,用于生成一個包含11列的CSV格式的示例數(shù)據(jù),然后以各種不同的方式進行驗證。https://cookbook.openai.com/examples/o1/using_reasoning_for_data_validation
使用推理進行例程生成(routine generation)展示了o1-preview代碼,將知識庫文章轉換成大型語言模型可以理解和遵循的一系列例程。https://cookbook.openai.com/examples/o1/using_reasoning_for_routine_generation
Twitter上還有些在 GPT-4o 上失敗但在 o1-preview 上有效的提示例子。其中有幾個是我最喜歡的:
由 Matthew Berman 提出的 “你的回應中有多少個單詞?” 這個問題,模型在五個可見的回合中思考了十秒鐘,然后回答說“這個句子中有七個單詞。”(There are seven words in this sentence)。正好7個!
由 Fabian Stelzer 提出的“解釋這個笑話:‘兩頭牛站在田野里,一頭牛問另一頭:‘你覺得現(xiàn)在流行的瘋牛病怎么樣?’另一頭說:‘誰在乎,我是直升機!’” 真正的瘋牛其他模型對這個無能為力。
不過,好的例子還是有點少。以下是參與創(chuàng)建這些新模型的 OpenAI 研究員 Jason Wei 的相關說明:
AIME 和 GPQA 的結果確實很強,但這并不一定能轉化為用戶能感受到的東西。即使是從事科學工作的人,要找到 GPT-4o 失敗、o1 做得很好、而我能給答案打分的提示詞也并不容易。但是,當你找到這樣的提示詞時,o1 就會給人一種完全神奇的感覺。我們都需要找到更難的提示。
Ethan Mollick已經預覽了這些模型幾周,并發(fā)表了他的初步印象。他對填字游戲的示例特別有趣,因為其中包含了可見的推理步驟,包括這樣的注釋:
我注意到1 Across和1 Down的首字母不匹配。考慮將1 Across的“LIES”改為“CONS”,以確保對齊。
未來的創(chuàng)新
社區(qū)需要一段時間來摸索出這些新模型的最佳實踐和應用場景。估計大部分人仍會會繼續(xù)主要使用 GPT-4o 和 Claude 3.5 Sonnet 模型,但新的思維鏈模型對擴展對大型語言模型(LLMs)能解決的任務類型會有相當大的啟發(fā)。
希望我們能看到其他人工智能實驗室,包括開源模型社區(qū),開始用他們自己的模型版本復制其中的一些結果,這些模型經過專門訓練,可以應用這種思維鏈推理方式。
注意:如果想第一時間收到 KiCad 內容推送,請點擊下方的名片,按關注,再設為星標。
常用合集匯總:
和 Dr Peter 一起學 KiCad
KiCad 8 探秘合集
KiCad 使用經驗分享
KiCad 設計項目(Made with KiCad)
常見問題與解決方法
KiCad 開發(fā)筆記
插件應用
發(fā)布記錄
審核編輯 黃宇
-
人工智能
+關注
關注
1806文章
48996瀏覽量
249239 -
模型
+關注
關注
1文章
3517瀏覽量
50391 -
OpenAI
+關注
關注
9文章
1207瀏覽量
8896
發(fā)布評論請先 登錄
OpenAI發(fā)布o1大模型,數(shù)理化水平比肩人類博士,國產云端推理芯片的新藍海?
DeepSeek與Kimi揭示o1秘密,思維鏈學習方法顯成效
OpenAI:DeepSeek與Kimi揭秘o1,長思維鏈提升模型表現(xiàn)
OpenAI o3-mini模型思維鏈遭質疑

對標OpenAI o1,DeepSeek-R1發(fā)布





 工商網監(jiān)
工商網監(jiān)
評論