 人工智能對醫療領域的研究現狀與數據分析以及總結
人工智能對醫療領域的研究現狀與數據分析以及總結
Luke Oakden-Rayner 是澳大利亞知名學府阿德萊德大學的在讀醫學博士生、放射線學專家,曾發表過多篇醫療人工智能方面的論文。他在頂級雜志《Nature》上發表的一項研究成果顯示,其團隊開創性地研發出可以預測人類壽命的儀器。他一直在追逐醫療AI領域的發展,從今年5月份開始,他寫了一系列的博客來介紹這一領域的最新研究進展,目前更新到了第三篇,其系列博客的名字就叫《人類醫學的終結 - 醫學AI研究最前沿》(The End of Human Doctors – The Bleeding Edge of Medical AI Research)。今天給大家介紹第一部分,希望你可以從中領會到人工智能對醫療領域的影響。
接下來幾天,我們會陸續放出同系列另外兩篇。歡迎繼續關注人工智能和醫療這個熱點話題。
今天的話題:機器學習最終是否會代替人類醫生?
我們要探討的這篇論文,它采取的方法,絕對可以比以往任何一種方法都好。本來我想在一篇博客里討論好幾篇類似的論文,可惜每一篇論文都有很多值得人們深思的地方(這篇文章就已經占了3000字了),所以每一篇論文我將花整個篇幅去深度探討和理解。然后我將在幾周里分開討論這些文章,于是就產生了我博客中關于醫療人工智能這個系列專題。
對于本次話題,我非常感謝 Lily Peng博士,這篇論文的作者之一,他對我提出的許多問題做出了非常充分的解答。
這里先奉上一份簡單的總結:
TL:DR
-
google(和他們的合作者)訓練了一個系統,可以檢測糖尿病視網膜病變(全世界5%的失明由它引起),該系統能夠像一個眼科醫生一樣做出診斷。
-
這是一個有用的臨床任務,它可能不會節省很多的費用,也不會在醫療自動化以后取代醫生,但是它的提出有很大的人文情懷。
-
他們使用了13萬個視網膜圖像進行訓練,比公開的數據集大了1到2個數量級。
-
他們使用陽性案例豐富了他們的訓練集,在某些程度上抵消了不平衡的數據分布帶來的影響。
-
由于大多數深度學習模型都是針對低分辨率的圖像,所以原數據被下采樣處理,丟棄了90%以上的像素值,然而我們無法評測這樣做是否有利。
-
他們雇傭了一組眼科醫生來對圖像進行標注,可能會花費數百萬美元,這樣做的目的是為了使標注更準確,避免出現誤判。
-
第5點和第6點是造成當前所有深度學習系統錯誤率高的原因,而且這個問題很少被談及。
-
深度學習之所以比醫生更有優勢,是因為它們可以在各個“操作點”上運作,相同的系統可以執行高靈敏度篩選和高特異性診斷,不需要再加額外的訓練。
-
這是一個很棒的研究內容,人們能夠很容易的理解,并且在文本和補充中有很多有用的信息。
-
這項研究似乎符合目前FDA對510(k)批準的要求。雖然這項技術不太可能通過,但是該系統或衍生物在未來的一兩年內很可能加入到臨床的實踐當中去。
免責聲明:本文主要針對大眾化的群體,包括機器學習領域的專家、醫生等。相關專家們可能會覺得,我對一些概念的理解很膚淺,可是我還是希望他們能在自己研究領域之外找到更多有趣的新想法。還有一點要強調的是,如果這篇文章里有任何說錯的地方,請讀者告訴我,我會及時改正。
研究現狀
在討論之前,我想提醒大家,雖然從2012年開始,深度學習就逐漸發展成一種研究者經常使用的方法,但是五年之內我們并沒有在醫學中使用這種方法,為了安全起見,我們的醫療人員也通常比技術的發展落后一步。大家了解到這個背景以后,就可以想象到現在取得的一些成果更是令人難以置信,而且我們應該客觀地認識到,人工智能對醫療的發展只是一個開始。
在論文中提出了,醫療自動化已經實現了突破性的進展,我會在本文中簡單回顧一下,也適當地增加了一些有用的知識。我會進一步介紹這個研究,在介紹之前先花幾分鐘時間說明幾個關鍵性的問題:
-
任務——這項任務是臨床任務嗎?如果實現自動化,在醫療實踐過程中會面臨多大的干擾呢?為什么選擇這項特定的任務呢?
-
數據——如何收集和處理需要的數據?數據怎么處理才能符合醫學實驗和監管的要求呢?我們需要深入了解醫療人工智能對大數據的要求。
-
結果——人工智能將戰勝醫生還是打成平手?他們究竟測試了什么?我們還能有什么其他的收獲嗎?
-
結論——這個結果有多大的影響力?我們還可以進一步得到其他的結論嗎?
Google的最新研究
任務:
糖尿病視網膜病是造成失明的一個重要病變,其成因是由于眼睛后部的細小血管損傷的造成的。醫生可以通過觀察眼睛后部的血管進行診斷,這其實是一項感知任務。
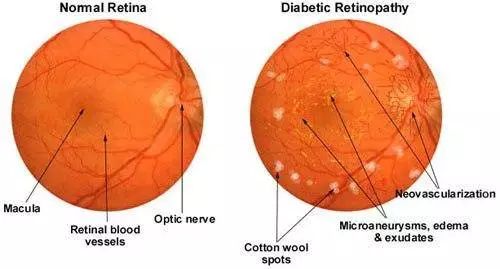
圖一 例如,DL系統能夠學會如何識別“棉花狀斑點”一樣的白斑圖案
他們訓練了一個深度學習系統,可以完成和評估與糖尿病視網膜病變相關的幾項工作,主要的成果是對一組糖尿病視網膜病變的病例進行評估,這些患者有著中度或者更嚴重的眼睛疾病(這組患者的治療方式和非對照組的患者的治療方式不同)。他們還測試了深度學習系統對其他嚴重的視網膜病變的識別能力,以及黃斑是否水腫的能力。
數據:
他們使用13萬張視網膜圖片對設計的深度學習系統進行訓練,每個級別由3到7名眼科醫生來投票確定,最終的結果以多數票來決定。圖像是從四個地方的醫院(美國EyePACS和3家印度醫院)采集的可追溯的臨床數據,由不同的相機拍攝出來的。
他們在兩個數據集上驗證了這個系統(在醫學中,術語“驗證”是指不參與到系統開發、訓練環節的患者,與機器學習中的測試集是一個意思)。其中的一個數據集是對EyePACS數據集隨機采樣得到的,另一個數據集來自3家法國醫院(Messidor-2)的公開數據集。第二個數據集中的所有圖片是由同一個相機拍攝的。這些測試集由7-8個眼科專家進行分級,同樣采用多數表決機制。
用來開發、訓練的數據集中,視網膜病變的患病率占比55%,惡化率占比8%,驗證數據中患者的患病率遠遠低于一般患者的患病率,在19.5%的患病率中,只有1.7%的嚴重或惡化。這樣的數據集是研究者刻意設計的,訓練集中有很多陽性病例(他們增加了病例,比通常發生在臨床人群中更多)。
對于數據集的質量,視網膜圖片的分辨率通常在1.3到350萬像素之間。這些像素被縮小到299*299的分辨率,也就是0.08百萬像素(整整少了94%到98%的像素!)。這是他們設計的網絡結構的特性,其他大小分辨率的圖像不能使用。
神經網絡:
他們使用了Google Inception-v3深度神經網絡的預訓練版本,這也是到目前為止使用效果最好的圖像處理系統之一。預訓練意味著這個網絡已經拿來訓練過一些非醫療的物體(例如貓和汽車的照片),然后再在這個基礎上對特定的醫療圖片進行訓練。這也是網絡只接受229*229分辨率圖片輸入的原因。
結果:
我認為這篇論文是深度學習在醫學人工智能領域取得的第一大突破。機器與眼科醫生擁有幾乎相同的疾病判斷能力,甚至可以與“中級”眼科醫生進行較量,表現也相當不錯。
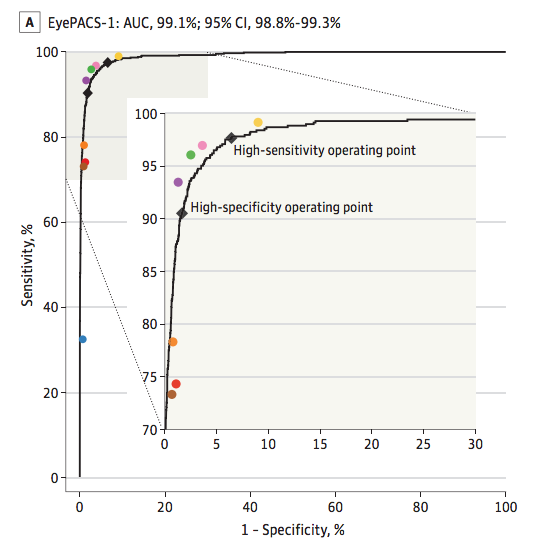
圖二 這是所謂的ROC曲線,是判斷疾病診斷系統的最佳方式之一。 通過計算曲線AUC下方的面積,能夠將靈敏度和特異度結合在單一的指標中。99.1%是非常好的。
彩色點是專業眼科醫生的診斷結果,黑線是所訓練的深度學習系統的診斷結果。正如你所看到的,如果我們將所有的彩色點連接起來,就可以得到眼科醫生診斷結果的ROC曲線*,與深度學習系統的ROC曲線相似。如果你不了解ROC曲線,你可以相信我,這絕對是一個證明兩種診斷結果相同的有效方式(食品藥品監督管理局將同意我的看法)。
他們的系統可以很準確的檢測出黃斑水腫,但在一些嚴重的視網膜病變方面,它的絕對值(AUC值)數據有些差距,但與眼科醫生的正面比較沒有說明這些。
討論:
關于這項研究,這里有一些有趣的事情要討論一下。
-
費用:他們雇用了一組眼科醫生來標注他們的數據,一共有50萬個標簽需要去標注。如果按照正常的看病價格去支付醫生,大概需要數百萬美元。這筆費用比大多數創業公司的成本還要多,而且他們肯定無法接受只有一個單一數據集的標注任務。從統計的角度考慮,數據就是力量。對于醫療人工智能來說,只有金錢才能產生這么多數據。換句話說,金錢就是力量。
-
任務:他們能夠從眼睛的照片中檢測到兩類以上的“可視眼病”(中度或者重度視網膜病變),甚至更嚴重的視網膜病變和黃斑水腫。這些都是臨床上非常重要的任務。最重要的是,這些任務涵蓋了大多數醫生在看糖尿病患者眼睛時在做的工作。當然,這個系統檢測不出罕見的視網膜黑色素瘤,但是對于日常的眼睛檢查,這是一個可以很好模擬醫生的系統。
數據:數據是很有趣的方面,原因有兩個:質量和數量。
從他們進行的系列實驗中,我們可以看出來他們需要的圖片的數量。他們還用不同數量的訓練樣本對系統的性能進行了測試。
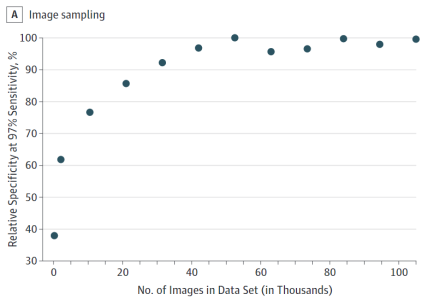
圖三 數據集中圖像的數量(單位:千)
這幅圖像給我們展示了一些非常有趣的東西,他們的訓練集中圖像的數量上限為6萬例,這些圖像至少在97%的靈敏度工作點。值得關注的是,這比已經公開的數據集大了一到兩個數量級,如果你的實驗能超過97%的靈敏度,毫無疑問你的數據需求也一定會增加。
這個結果也向我們傳達了關于數據集大小的其他內容。當他們努力復制眼科醫生的工作時,對常見眼科疾病的靈敏度能夠達到90%,但是對于重度或者更嚴重的疾病的靈敏度只有84%。可能是因為識別重度疾病的任務比較困難。
另外,我還注意到“中度或者重度”疾病的訓練數據是普通的3到4倍。絕對數據較少(約9500例vs 34000例),而且關于流行眼病的數據也較少(9%為陽性,30%為陽性)。
機器學習需要訓練分布不平衡的數據,但是不平衡的數據并不容易獲得。以我的經驗看來,不平衡的情況比低于30/70,機器學習會很難進行下去。這樣的數據不僅使訓練更加困難(較少的案例=較少的學習),并且也會讓實際地診斷變得更加困難(系統在預測多類問題時會有一些干擾)。
不過,我們發現研究小組也在試圖解決這個問題。在篩選人群的過程中,“參考”疾病的患病率在10%以下,所以這是一個高度不平衡的任務。因此,他們采用了額外的陽性病例以擴增訓練數據集,令患病率達到30%。這樣,訓練結果得到了提升。并且,系統對其臨床普遍性約為8%驗證數據表現的較好。
但是,這種擴增較少的數據類型的方法只有在有更多的陽性案例情況下才有效,這種情況并不常發生。現在已經有了一些解決不平衡數據的方法,但是仍然沒有找到一個解決不平衡數據的最佳方式。
這里還有兩個關于數據質量的有趣的現象。
首先是數據的下采樣。這個系統在比人類觀測到的圖片少98%像素點的情況下,能否觀測結果和人類一樣呢?我們可以肯定的說,這個系統真的可以做到。當然前提是大部分丟棄的像素必須是無用的噪聲信息,否則會使深度學習系統訓練的過程更加艱難。人類比計算機更善于忽視視覺噪音。
這個意義實際上更深遠,因為深度學習系統已經在很多場合用來處理小型圖片,但對于百萬像素的大型圖片**的處理,還從沒有過很好的效果。實際上,高分辨率圖像可能包含更多有用的信息,但是并不能適用于深度學習系統。
下采樣的設想引發了一系列的問題討論:
-
深度學習能對高分辨率圖像有更好的訓練效果嗎?
-
低分辨率的圖像是否適用于所有的醫療任務呢?
-
從技術的角度來看,我們是否可以在深度學習中采用高分辨率圖像呢?
我不知道這些問題的答案,但是在接下來的幾個星期,我們會通過閱讀其他的論文來明確這些問題的答案。
關于數據的質量的第二個有趣的內容就是標注的質量問題。在機器學習中,我們需要非常準確的信息。也就是說,我們希望訓練數據能夠被正確的標注。比如視網膜病變的訓練數據就應該是真正的視網膜病變。這些理論說起來很容易,但在實際操作中,醫生們對疾病的診斷意見常常會出現分歧。所以,論文作者只是提供了數據。
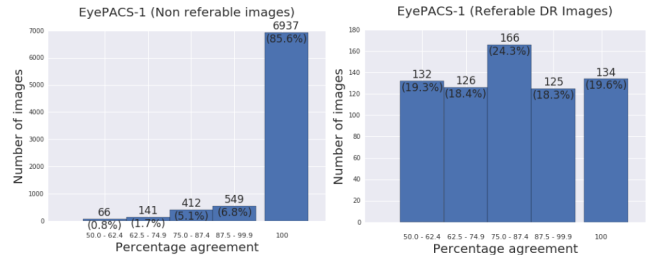
你可以從這幅圖中看到,對于中等或中等以上程度的疾病,有80%的概率,至少有一個醫生得出了與其他人不一致的結論!所以,使用一致的標簽就是為了減少可能出現的人為錯誤。
然而數據集中的標簽錯誤很難避免,并且危害著模型的性能。深度學習可以學習到任何你給它的東西。反過來說,如果標注出現問題,深度學習機器很容易做出誤判。
有一個達成共識的標注并不是解決這個問題的唯一方法。一些任務可能有更準確的信息,例如我們下周會看到的一篇關于皮膚病變的論文。這篇論文中的每個病變都有病理學家給出的活檢證實的診斷,但是變化不大。在極端的情況下,一些任務有非常完美的標簽。我自己的一個項目就在關注著一個不能被誤解的標簽——死亡率。
我認為標簽的關鍵在于你能得到的和你所投入的東西成正比。如果你使用個別醫生的標簽,至少你能和這個醫生一樣優秀。如果你使用共識性的數據,你將會比其中的任何一個人更厲害。如果你完整的使用校正信息,你可能會完美地完成任務。
影響:我對作者提出將醫療機器人作為疾病篩查工具的想法表示衷心的敬佩。他們展示了機器和眼科醫生一樣的運行結果(假陽性率較低,但缺少一些陽性病例),同時還顯示了系統優化篩選時的結果(識別幾乎所有陽性病例,但還有幾個假陽性)。
這些系統和醫生相比有一個主要的優勢:人類醫生在假設的ROC曲線上有一個單一的操作點,這是基于他們經驗的靈敏度和特異性的平衡,并且很難用任何可預測到的方式去改變。相比之下,深度學習系統可以在ROC曲線的任何地方運行,不需要再加額外的訓練。你可以在診斷模式和篩選模式之間進行切換,而且不需要額外的費用,這種靈活性真的太酷了!在實際的臨床測試中非常有用。
考慮到監管部門,這項研究已經接近于臨床使用的水平。他們驗證了從真實醫療中篩選的數據集的模型,并且每個案例都有多個參與者。這項稱為MRMC研究,也是FDA用于計算機輔助檢測系統的一般證據標準。盡管我們并不清楚這項研究和診斷系統的關系,但是如果這個系統或者類似的系統在最近兩年里取得了FDA批準,我并不驚訝。
這項任務在醫療費用方面還是很可觀的。眼科并不是醫學的一大部分,在成本方面,眼睛檢查也并不會很昂貴。
如果這個用人工智能進行眼部病變篩檢的技術能得到推廣,那么它人類的影響會非常大。在許多發展中國家,糖尿病病情日益嚴重,但是眼科專家奇缺。鑒于圖像處理在低分辨率的圖片上上成功率跟高,如果能將該系統與低成本且易于使用的手持式視網膜攝像機結合起來,可以挽救數百萬人的生命。
然而,即使人工智能可以代替醫生對視網膜病變進行評估,這對醫療工作的影響還是很局限。并且,我認為視網膜病變篩查自動會很容易導致醫生工作量增加,因為以前未確診的患者現在也需要進一步地評估和治療。
現在我們只討論了對視網膜病變的評估,在我們再看幾篇論文以后,我們將能夠探索醫療自動化軌跡的發展意義。
接下來我會看看斯坦福大學的論文,他們聲稱訓練的深度學習系統可以實現“對皮膚癌進行分類”。
曲線上眼科醫生的結果的分布讓我覺得非常驚訝,因為不同的醫生可能做出非常不同的預測。 其中有的醫生認為有0個假陽性,而其他的醫生認為有10%的假陽性。這是一個很大的錯誤范圍。
已經使用了一些解決方案,例如首先將圖像進行切片操作。但這通常會大量增加負面例子的數量,加劇了數據不平衡的問題。
-
AI
+關注
關注
88文章
34653瀏覽量
276494 -
人工智能
+關注
關注
1805文章
48861瀏覽量
247625
原文標題:機器學習最終是否會代替人類醫生?
文章出處:【微信號:AI_Thinker,微信公眾號:人工智能頭條】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄





 工商網監
工商網監
評論