") 如何利用CXL協(xié)議實(shí)現(xiàn)高效能的計(jì)算架構(gòu)
如何利用CXL協(xié)議實(shí)現(xiàn)高效能的計(jì)算架構(gòu)
作者:張景濤
序言
近日我有幸閱讀了英特爾公司互聯(lián)系統(tǒng)領(lǐng)域的權(quán)威人物Debendra Das Sharma撰寫的一篇開創(chuàng)性文章——《Novel Composable and Scaleout Architectures Using Compute Express Link》(文末附鏈接)。在這篇文章中,Debendra Das Sharma詳盡地闡述了如何利用CXL(Compute Express Link)技術(shù)構(gòu)建一個(gè)可橫向擴(kuò)展的可組合分離架構(gòu)。眾所周知,CXL協(xié)議涵蓋了type1、type2、type3三種設(shè)備類型,而目前學(xué)術(shù)界和工業(yè)界的研究主要集中在如何利用CXL技術(shù)擴(kuò)展系統(tǒng)的內(nèi)存容量。
然而至今尚未有文獻(xiàn)系統(tǒng)地探討如何直接通過CXL技術(shù)在機(jī)架級(jí)別構(gòu)建一個(gè)支持異構(gòu)計(jì)算、內(nèi)存和存儲(chǔ)設(shè)備的池化系統(tǒng)。據(jù)我了解,現(xiàn)有的CXL協(xié)議在不進(jìn)行任何修改和優(yōu)化的情況下,似乎難以勝任這一重任。至少在性能和可擴(kuò)展性方面,它與PCIe相比并沒有展現(xiàn)出顯著的優(yōu)勢。(對于如何通過PCIe技術(shù)構(gòu)建可組合基礎(chǔ)設(shè)施感興趣的讀者,可以參考《基于PCIE的可組合基礎(chǔ)設(shè)施的性能洞察》。)
Debendra Das Sharma憑借其卓越的技術(shù)洞察力和對CXL技術(shù)的深刻理解,提出了一系列在現(xiàn)有CXL協(xié)議基礎(chǔ)上的增強(qiáng)措施。這些建議旨在提升協(xié)議的性能和擴(kuò)展性,部分提議已經(jīng)在最新的CXL 3.1規(guī)范中得到了采納。這些改進(jìn)不僅為CXL技術(shù)的發(fā)展提供了新的方向,也為構(gòu)建下一代高性能計(jì)算系統(tǒng)提供了可能。
在接下來的內(nèi)容中,我們將深入探討這些協(xié)議增強(qiáng)措施的具體細(xì)節(jié),以及它們?nèi)绾沃?shí)現(xiàn)大規(guī)模、高效能的計(jì)算架構(gòu)。這不僅涉及到硬件層面的創(chuàng)新,也包括軟件和系統(tǒng)設(shè)計(jì)的新思路。通過這些綜合措施,我們有望打破現(xiàn)有的技術(shù)瓶頸,推動(dòng)計(jì)算技術(shù)邁向一個(gè)新的高度。
背景知識(shí)
CXL是一個(gè)開放的行業(yè)標(biāo)準(zhǔn)互連,它在PCI-Express之上提供了緩存和內(nèi)存語義。除了在主機(jī)處理器和加速器、智能網(wǎng)絡(luò)接口卡以及內(nèi)存擴(kuò)展設(shè)備之間提供高帶寬和低延遲的連接外,它還支持跨多個(gè)系統(tǒng)的資源共享池,實(shí)現(xiàn)可擴(kuò)展、節(jié)能和成本效益高的計(jì)算。接下來會(huì)探討使用CXL互連在機(jī)架級(jí)別及更高級(jí)別上搭建可組合和可擴(kuò)展架構(gòu),以實(shí)現(xiàn)異構(gòu)內(nèi)存和異構(gòu)計(jì)算資源的池化和共享。
PCIe是一個(gè)非一致性互連。PCIe設(shè)備一般使用DMA完成系統(tǒng)內(nèi)存讀寫事務(wù)以非一致性方式訪問系統(tǒng)內(nèi)存。附加到PCIe設(shè)備的任何內(nèi)存都在系統(tǒng)中作為不可緩存的內(nèi)存映射I/O(MMIO)區(qū)域進(jìn)行映射。CXL 1.0/1.1在PCIe基礎(chǔ)設(shè)施之上增加了一致性和內(nèi)存語義,以支持細(xì)粒度的協(xié)同異構(gòu)處理以及滿足新興計(jì)算需求所需的內(nèi)存帶寬和容量擴(kuò)展。英特爾捐贈(zèng)了最初的CXL 1.0規(guī)范,并在2019年領(lǐng)導(dǎo)了CXL聯(lián)盟的啟動(dòng)。CXL 1.0/1.1支持I/O(CXL.io)、一致性(CXL.cache)和內(nèi)存(CXL.memory)協(xié)議之間的動(dòng)態(tài)多路復(fù)用,如圖1(b)所示。CXL基于內(nèi)存加載-存儲(chǔ)語義。它在中央處理單元(CPU(s))(主機(jī)處理器)和跨異構(gòu)內(nèi)存的CXL設(shè)備之間維護(hù)統(tǒng)一的、一致的內(nèi)存空間,如圖1(a)所示。
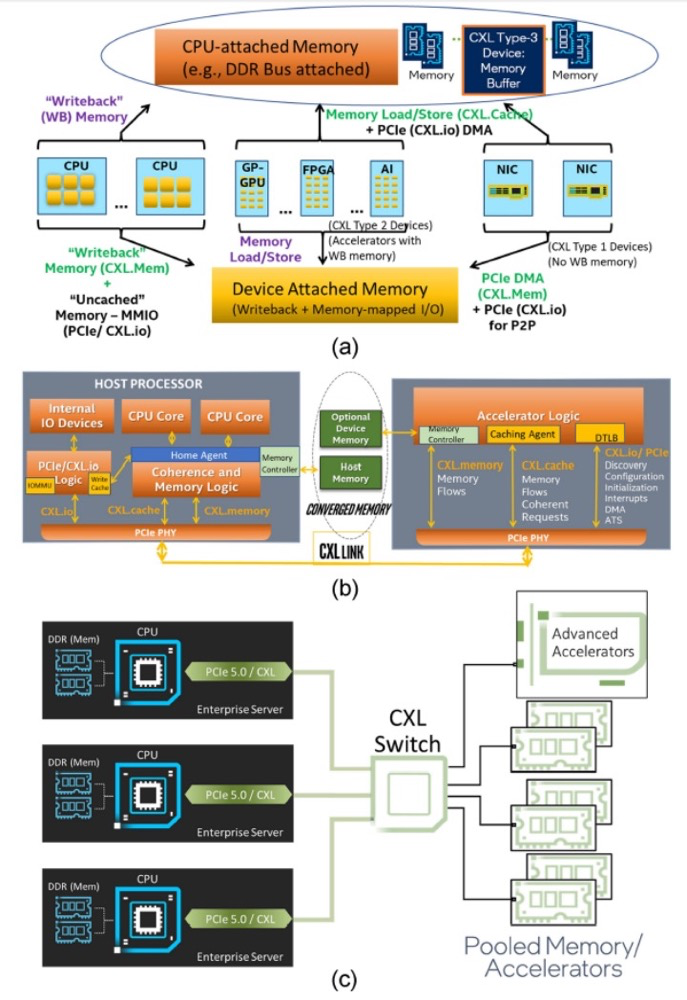
圖 1. CXL 1.0和CXL 2.0的使用模式和協(xié)議。(a) 綠色文本顯示了CXL 1.0啟用的新系統(tǒng)能力。三種類型的CXL 1.0設(shè)備。(b) CXL在PCIe PHV上的三種協(xié)議的動(dòng)態(tài)多路復(fù)用。(c) CXL 2.0的資源池化。
CXL類型1設(shè)備是加速器,例如使用一致性語義以及PCIe的DMA傳輸?shù)闹悄躈IC。CXL類型2設(shè)備是加速器,例如通用圖形處理單元(GP-GPU)和現(xiàn)場可編程門陣列(FPGA),它們具有可以部分或全部映射到可緩存系統(tǒng)內(nèi)存的本地內(nèi)存。CXL類型3設(shè)備用于使用可能具有自己內(nèi)存層次結(jié)構(gòu)的異構(gòu)內(nèi)存進(jìn)行內(nèi)存帶寬和容量擴(kuò)展。
后面文章會(huì)展示如何開發(fā)商業(yè)上可行的可組合系統(tǒng),在POD級(jí)別具有加載-存儲(chǔ)語義,并繼續(xù)向后兼容CXL的演進(jìn)。
CXL 2.0引入了通過允許多個(gè)域?qū)σ粋€(gè)或多個(gè)池化設(shè)備進(jìn)行加載-存儲(chǔ)訪問的內(nèi)存和加速器的池化概念。這種池化能力可以提供更高的能效同時(shí)降低總擁有成本,因?yàn)楦鱾€(gè)服務(wù)器不必過度配置內(nèi)存,因?yàn)樗鼈兛梢砸蕾噧?nèi)存池來應(yīng)對需求的臨時(shí)激增。CXL 2.0支持扇出和池化、內(nèi)存和加速器池化、熱插拔管理和資源管理器的切換,同時(shí)完全向后兼容CXL 1.0/1.1。因此,CXL 2.0為CXL提供了一種擴(kuò)展到機(jī)架級(jí)別低延遲互連的機(jī)制,具有加載-存儲(chǔ)語義。
CXL協(xié)議概述
68字節(jié)的FLIT是CXL中傳輸?shù)幕締挝弧XL.io基于帶有非一致性加載-存儲(chǔ)和生產(chǎn)者-消費(fèi)者排序語義的PCIe協(xié)議。CXL.cache 支持設(shè)備緩存數(shù)據(jù),采用請求和響應(yīng)協(xié)議。主機(jī)處理器管理修改、獨(dú)占、共享、無效(MESI)一致性協(xié)議,根據(jù)需要部署SNOOP消息。每個(gè)方向上都有三種消息類別:請求(Req)、響應(yīng)(Rsp)和數(shù)據(jù)。在設(shè)備到主機(jī)(D2H,上行)方向上,Req 包括讀取(例如,Rd_Shared,RdOwn)和寫入;相應(yīng)的下行 H2D 響應(yīng)是全局可觀察性(GO)。H2D-Req 是SNOOP,導(dǎo)致 D2H 響應(yīng)SNOOP(例如,RspI,RspSHitSE)。
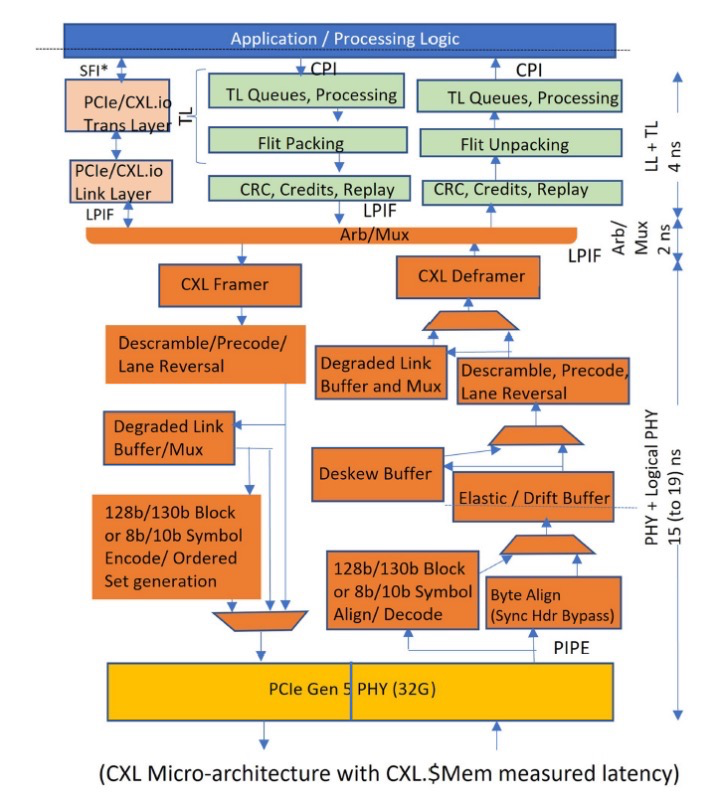
圖 2. CXL 實(shí)現(xiàn)和測量的延遲
CXL.memory 支持類型2/3設(shè)備將其內(nèi)存映射到系統(tǒng)的一致性內(nèi)存中,這將被稱為主機(jī)管理的設(shè)備內(nèi)存(HDM)。它以緩存行粒度(64字節(jié))在主機(jī)處理器(M)和類型2/3設(shè)備(S)之間傳輸內(nèi)存加載和存儲(chǔ)事務(wù)。請求從主機(jī)發(fā)送到設(shè)備在一個(gè)下游通道上:M2SReq(例如,讀取請求),以及 M2S RwD(例如,寫入)。響應(yīng)從設(shè)備發(fā)送到主機(jī)在兩個(gè)上行通道上:S2M NDR(無數(shù)據(jù)響應(yīng))和 S2M DRS(帶數(shù)據(jù)的響應(yīng))。
CXL 實(shí)現(xiàn)和結(jié)果
CXL 1.0/1.1 在英特爾的 Sapphire Rapids (SPR) CPU 中實(shí)現(xiàn),支持所有三種協(xié)議,符合 CXL 規(guī)范的要求。它已經(jīng)通過在 32.0 GT/s 下運(yùn)行的 x16 寬度的英特爾 FPGA 實(shí)現(xiàn) CXL 進(jìn)行了廣泛測試。最后一級(jí)緩存(LLC)和窺探過濾器涵蓋了 CXL設(shè)備中的緩存。無論是本地連接到 CPU 的雙倍數(shù)據(jù)速率動(dòng)態(tài)隨機(jī)存取存儲(chǔ)器(DDR)總線還是映射到系統(tǒng)地址空間的 CXL設(shè)備,內(nèi)存都在 CPU 中的 Home Agent 的管轄范圍內(nèi)。
圖 2 表示我們的 IP 級(jí)微架構(gòu)塊圖。SERDES 引腳到應(yīng)用層的總往返延遲目標(biāo)是 21 或 25 納秒,這取決于公共時(shí)鐘模式是否開啟。這符合 CXL 規(guī)范目標(biāo),即內(nèi)存訪問的引腳到引腳往返延遲為 80 納秒,SNOOP的響應(yīng)為 50 納秒。因此,跨 CXL 鏈路的加載到使用延遲預(yù)計(jì)為 CXL.Mem 的大約 150-175 納秒。
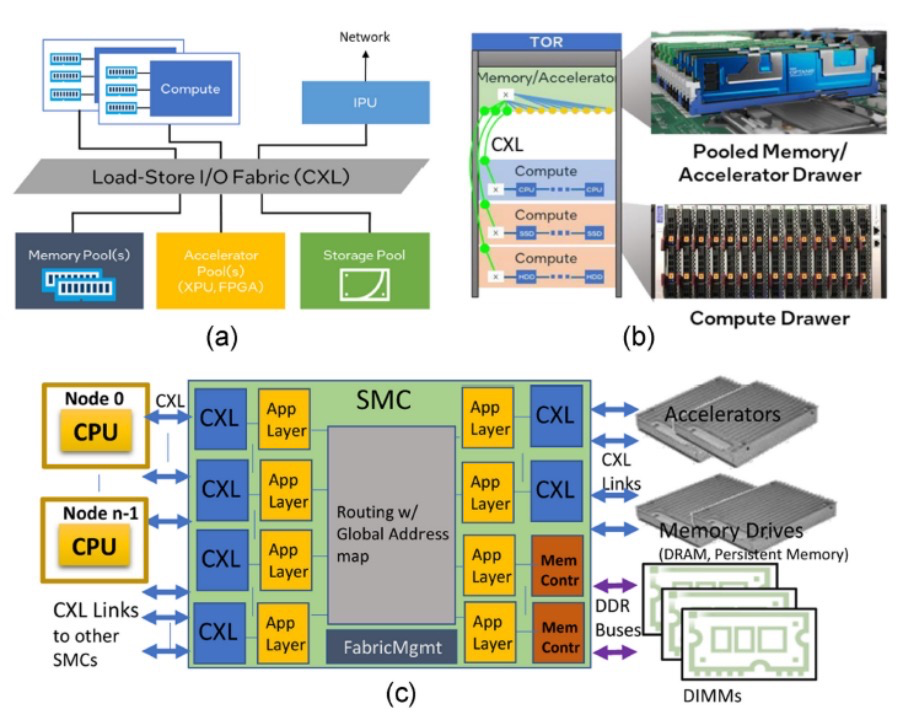
圖3(a)和(b)展示了我們構(gòu)建大型可組合服務(wù)器集群的架構(gòu)愿景,這些服務(wù)器跨越一個(gè)或多個(gè)機(jī)架,使用CXL作為互連。每個(gè)機(jī)架抽屜可以是計(jì)算抽屜(抽屜可以理解為一個(gè)機(jī)架中有獨(dú)立外殼的托盤),連接多個(gè)節(jié)點(diǎn)(服務(wù)器)與池化內(nèi)存(包括雙列內(nèi)存模塊、雙列內(nèi)存模塊(DIMM)和CXL內(nèi)存驅(qū)動(dòng)器),和池化加速器。每個(gè)節(jié)點(diǎn)可能有自己的專用內(nèi)存、加速器和其他I/O資源。一個(gè)抽屜也可以只由內(nèi)存或加速器組成,這些可以是跨機(jī)架資源池的一部分。共享內(nèi)存控制器(SMC)芯片提供CXL連接。SMC也可以本地托管DDR內(nèi)存,如圖3(c)所示。SMC之間的互連可以通過機(jī)架內(nèi)的銅纜(1-2米)。或者使用光纖用于SMC之間的跨機(jī)架連接。
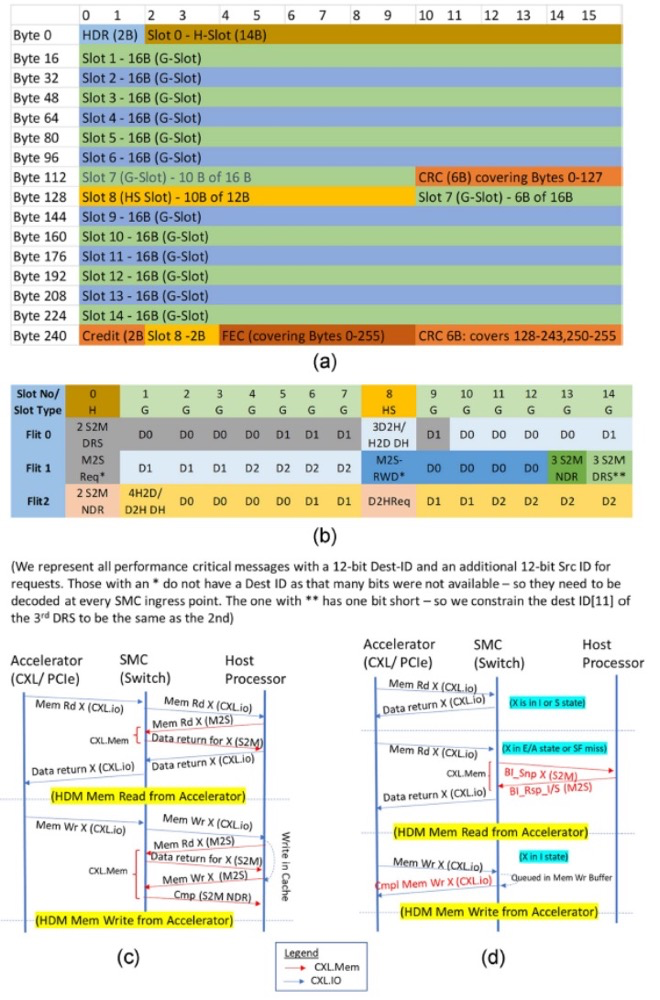
圖 4. 延遲優(yōu)化的FLIT布局,提出的CXLFLIT打包和CXL事務(wù)增強(qiáng)。(a) 128字節(jié)優(yōu)化的FLIT布局。(b) 使用我們提出的可擴(kuò)展性機(jī)制,在SMC-SMC鏈路中使用128字節(jié)LO FLIT的例子。(c) 現(xiàn)有的CXL(1.0,2.0)流程;所有HDM訪問都通過主機(jī)處理器與HA進(jìn)行。(d) 直接訪問HDM內(nèi)存的提出流程;新流程以紅色文本顯示。
CXL協(xié)議和能力增強(qiáng)
文中提出了幾項(xiàng)CXL增強(qiáng)措施,以實(shí)現(xiàn)可組合和可擴(kuò)展架構(gòu)。這使得跨多個(gè)域共享和池化資源(例如,內(nèi)存、加速器);每個(gè)域都是一個(gè)獨(dú)立的服務(wù)器。可以構(gòu)建跨機(jī)架的可組合系統(tǒng),每個(gè)域都可以根據(jù)需要?jiǎng)討B(tài)地從資源池中添加/移除資源。新的架構(gòu)還通過使用共享內(nèi)存、跨域中斷、信號(hào)量和基于CXL的直接加載存儲(chǔ)內(nèi)存訪問語義的消息傳遞,實(shí)現(xiàn)跨域的協(xié)同計(jì)算。
后面需要在不增加延遲懲罰的情況下將可擴(kuò)展架構(gòu)帶寬翻倍。CXL 3.0規(guī)范采用了64-GT/s PAM-4信號(hào)與我們的128字節(jié)sub-FLIT機(jī)制(與CXL 2.0相比沒有增加任何延遲)。圖4(a)顯示了不同slot的布局。通用(G)slot為16字節(jié),可用于頭和數(shù)據(jù),而H/HS slot(14/12字節(jié))僅用于頭。
為了構(gòu)建圖3所示的大規(guī)模可擴(kuò)展系統(tǒng),即使存在多級(jí)SMC也需要有接近單節(jié)點(diǎn)性能的表現(xiàn)。文中方法適用于任何使用無死鎖路由機(jī)制的拓?fù)浣Y(jié)構(gòu),沒有PCIe和CXL 1.0/2.0的樹形拓?fù)湎拗啤MC之間的CXL鏈路需要是CXL 3.0協(xié)議加上這里討論的增強(qiáng)功能,并支持每個(gè)CXL協(xié)議的上下游通道。
我們提議增強(qiáng)CXL 3.0的128字節(jié)延遲優(yōu)化(LO)FLIT,使用12位端口ID號(hào)通過SMC路由。這比256字節(jié)的方法提供了更低的延遲和更高的帶寬效率。端口ID號(hào)只需要唯一標(biāo)識(shí)連接到SMC的主機(jī)CPU或CXL設(shè)備,允許多達(dá)4,096個(gè)主機(jī)CPU或設(shè)備(可以是PCIe/CXL 1.0/CXL 2.0/CXL 3.0)連接到任何SMC端口。為此,我們需要在每個(gè)頭進(jìn)入第一個(gè)SMC時(shí)添加12位目標(biāo)端口ID(也稱為Dest-ID)。對于請求,我們需要添加12位源端口ID(Src-ID),以便響應(yīng)可以路由回源節(jié)點(diǎn)。當(dāng)事務(wù)傳遞到CPU或設(shè)備并在出口SMC端口交付時(shí),這些Dest-ID / Src-ID將被移除,并轉(zhuǎn)換為標(biāo)準(zhǔn)PCIe/CXL 1.0/1.1/2.0/3.0格式,以便現(xiàn)有的CPU/設(shè)備可以與我們提出的架構(gòu)一起工作,該架構(gòu)僅將可組合性和可擴(kuò)展性負(fù)擔(dān)放在SMC上。CXL.Cache/Mem頭有足夠的備用位來適應(yīng)這種擴(kuò)展,并且仍然適合CXL3流量的任何slot。
我們已經(jīng)確定了CXL 3.0規(guī)范中所有性能關(guān)鍵的頭編碼,如圖4(b)所示(例如,一個(gè)G slot中的3個(gè)S2M NDR)。即使在每個(gè)事務(wù)中添加了額外的端口ID位,我們也可以容納它們,包括每個(gè)slot有多個(gè)頭的那些。有兩個(gè)例外:1)有兩個(gè)頭(M2SReq,M2SRwD),由于沒有足夠的備用位,Dest-ID沒有發(fā)送。因此,這兩個(gè)需要在每個(gè)SMC進(jìn)行目的ID查找(而不是在進(jìn)入SMC復(fù)合體時(shí)一次)。我們認(rèn)為,為了保留外部鏈路帶寬而增加的查找邏輯帶寬是一個(gè)合理的權(quán)衡。2)有一個(gè)實(shí)例,其中插槽中的第三個(gè)數(shù)據(jù)返回頭(DRS)需要與第二個(gè)DRS具有相同的目標(biāo)ID位。這也是一個(gè)合理的權(quán)衡,因?yàn)槲覀儫o法發(fā)送3個(gè)DRS(而是發(fā)送2個(gè)DRS)的唯一時(shí)間是如果有超過2,048個(gè)CPU/CXL設(shè)備,并且在一個(gè)重負(fù)載系統(tǒng)中我們無法調(diào)度兩個(gè)具有相同Dest-ID的DRS。
通過這些提議的優(yōu)化,對于CXL.Cache/CXL.Mem,現(xiàn)有的單一域與我們?yōu)榇笮涂山M合系統(tǒng)提出的多域支持之間沒有效率損失。對于跨SMC鏈路的CXL.io訪問,在SMC的初始入口點(diǎn),目標(biāo)端口ID生成并添加為事務(wù)層數(shù)據(jù)包(TLP)前綴,并適當(dāng)轉(zhuǎn)換為目標(biāo)域的總線、設(shè)備和功能。TLP前綴的額外4個(gè)字節(jié)將對CXL.io帶寬產(chǎn)生很小的影響。
為了在大型系統(tǒng)中擴(kuò)展性能,我們還提出了新的CXL流程,其中一些已經(jīng)被采用在CXL 3.0規(guī)范中。在CXL 1.0/CXL 2.0中,所有HDM訪問都通過主機(jī)處理器進(jìn)行,以解決緩存一致性,即使類型2/3設(shè)備可以通過SMC直接訪問,如圖4(a)所示。這導(dǎo)致鏈路帶寬浪費(fèi)和額外的延遲。我們提出直接點(diǎn)對點(diǎn)(p2p)訪問HDM內(nèi)存,我們在CXL.io中稱之為“無序I/O”(UIO),類似于MMIO訪問的點(diǎn)對點(diǎn)。我們在S2M中添加了一個(gè)新的回退使能窺探(“BI-Snp”)和相應(yīng)的回退使能響應(yīng)(“BI-Rsp”),以支持這種直接p2p HDM訪問。這種方法保留了CXL的不對稱性,因?yàn)橹鳈C(jī)處理器仍然協(xié)調(diào)一致性并解決可緩存訪問的沖突。BI-Snp只啟用設(shè)備端內(nèi)存控制器支持直接點(diǎn)對點(diǎn)訪問,類似于自CXL 1.0時(shí)代以來類型2設(shè)備已經(jīng)具備的能力,而不會(huì)引入實(shí)現(xiàn)類型2設(shè)備的緩存語義和偏置翻轉(zhuǎn)流程的復(fù)雜性。
類型2/3設(shè)備已經(jīng)有一個(gè)目錄,由兩位存儲(chǔ)元數(shù)據(jù)(MESI狀態(tài):I、S、E/A,其中A代表任何MESI狀態(tài))。接收到其HDM內(nèi)存的直接UIO請求的類型2/3設(shè)備,如果可以在保持MESI一致性機(jī)制的同時(shí)本地服務(wù)事務(wù)[例如,如果狀態(tài)是I/S,則為讀取(寫入)請求];否則,它將觸發(fā)BI-Snp流程,如圖4(b)所示,以通過主機(jī)CPU強(qiáng)制執(zhí)行MESI一致性機(jī)制,然后完成請求。這些回退使能流程還使類型2設(shè)備能夠部署一個(gè)窺探過濾器。BI流程是CXL.Mem中的一個(gè)單獨(dú)消息類別,因?yàn)镃XL.Mem不依賴于其他消息類別,并且CXL.Mem存在于類型3(和類型2)設(shè)備中。我們還提議為CXL.io UIO寫事務(wù)添加一個(gè)可選的完成流程,如圖4(b)所示,從而將生產(chǎn)者-消費(fèi)者排序點(diǎn)移動(dòng)到源,以實(shí)現(xiàn)CXL.io的多路徑。
我們提議使用增強(qiáng)類型2/3設(shè)備在CPU和設(shè)備之間使用硬件強(qiáng)制緩存一致性共享內(nèi)存。內(nèi)存控制器可以在芯片上實(shí)現(xiàn)一個(gè)窺探過濾器,可選地由內(nèi)存中的目錄支持,或者僅僅是內(nèi)存中的目錄,其中它跟蹤可能擁有緩存行的主機(jī)處理器(s)的端口ID,并根據(jù)需要向主機(jī)處理器(s)發(fā)送BI-Snp。這使得SMC能夠在跨域的共享內(nèi)存上強(qiáng)制執(zhí)行緩存一致性。這種共享內(nèi)存也可以用來跨域?qū)崿F(xiàn)信號(hào)量。我們基于CXL.io(UIO)和非一致性CXL.Mem的節(jié)點(diǎn)間消息傳遞機(jī)制。
我們提議使用單根I/O虛擬化,為多個(gè)域中的CXL類型1/2和PCIe設(shè)備添加池化能力。在這種情況下,fabric管理器將負(fù)責(zé)設(shè)備。SMC將把所有配置請求轉(zhuǎn)發(fā)給fabric管理器,該管理器將模擬配置訪問并確保跨域的隔離。一個(gè)域只對其分配的設(shè)備功能(s)的內(nèi)存空間有直接訪問權(quán),這是為了提供最佳性能所必需的。
SMC微架構(gòu)
圖3(c)顯示了SMC芯片的塊圖,它支持連接到CXL節(jié)點(diǎn)(主機(jī)處理器或CXL設(shè)備)或其他SMC的CXL鏈路,以及連接到DRAM內(nèi)存的DDR總線。CXL管理接口提供了分布式fabric管理功能,這些功能對于協(xié)調(diào)資源分配、控制池化、共享CXL設(shè)備的配置寄存器空間以及在SMC內(nèi)部跨域設(shè)置公共數(shù)據(jù)結(jié)構(gòu)是必需的。每個(gè)主機(jī)都有獨(dú)立的系統(tǒng)地址空間視圖。帶有分布式fabric管理軟件棧的SMC協(xié)調(diào)全局地址映射,如圖5所示。因此,對從CXL節(jié)點(diǎn)的訪問通過SMC內(nèi)部的地址映射和路由邏輯進(jìn)行適當(dāng)?shù)闹赜成洹MC內(nèi)部數(shù)據(jù)路徑和SMC鏈路中的事務(wù)頭攜帶源和/或目標(biāo)的12位端口ID進(jìn)行路由。SMC需要在交付給CPU或設(shè)備時(shí)取下這些前綴、源/目標(biāo)端口ID,并在完成時(shí)重新分配它。除了跨域的地址轉(zhuǎn)換外,SMC在我們的提議架構(gòu)中還提供對復(fù)制、郵箱、信號(hào)量和中斷服務(wù)的支持。
性能指標(biāo)
SMC之間的連通性 一個(gè)抽屜可以有一個(gè)或多個(gè)SMC。對于大規(guī)模擴(kuò)展配置,我們期望每個(gè)獨(dú)立鏈接是[email protected]/s,每個(gè)方向32 GB/s。擁有192個(gè)通道或48個(gè)鏈接,每個(gè)SMC可以連接到機(jī)架中所有16個(gè)獨(dú)立服務(wù)器和16個(gè)池化設(shè)備,另外16個(gè)可以用于連接機(jī)架內(nèi)/跨機(jī)架的其他SMC。因此,使用兩個(gè)級(jí)別的SMC可以在16個(gè)機(jī)架之間實(shí)現(xiàn)連通性。
用于I/O一致性訪問和圖5中描述的跨域消息傳遞,可以部署CXL.io或CXL.Mem機(jī)制。由于帶寬效率CXL.io更高,并且它不會(huì)消耗連接到SMC(s)的系統(tǒng)內(nèi)存來備份消息傳遞空間,我們建議僅使用CXL.io進(jìn)行跨域消息傳遞,以獲得性能、實(shí)現(xiàn)簡單性和成本效益。表1(a)和(b)總結(jié)了我們使用CXL.io的帶寬結(jié)果。
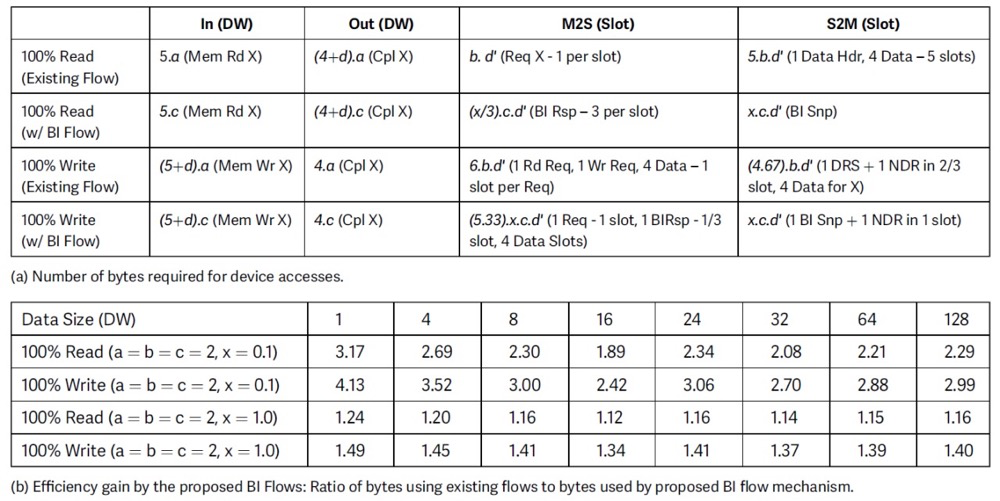
表1 架構(gòu)的鏈路效率
如上所述,我們提議通過直接點(diǎn)對點(diǎn)(包括不涉及緩存的DMA和跨域消息)繞過主機(jī)處理器進(jìn)行CXL.io訪問。預(yù)期絕大多數(shù)這些訪問不會(huì)引發(fā)BI-Snp機(jī)制來強(qiáng)制一致性。這有助于提高鏈路效率以及減輕主機(jī)處理器鏈路的擁塞。如表1(b)所示,即使在所有訪問都引發(fā)BI-Snp的極端情況下,這種機(jī)制的效率增益也是顯著的,因?yàn)檫@比跨鏈路的多緩存行傳輸更好。
根據(jù)我們在“帶有CXL的可組合、可擴(kuò)展機(jī)架級(jí)架構(gòu)”部分中介紹的結(jié)果,CXL堆棧的Tx+Rx路徑為25納秒。即使增加額外的15納秒用于內(nèi)部延遲,如排隊(duì)/地址查找/仲裁/傳播延遲等,每次通過SMC的跳轉(zhuǎn)少于40納秒。這使得兩次SMC跳轉(zhuǎn)對于內(nèi)存訪問非常可行。表2總結(jié)了我們基于在實(shí)現(xiàn)CXL和詳細(xì)微架構(gòu)SMC方面的工作經(jīng)驗(yàn)對各種訪問的估計(jì)。
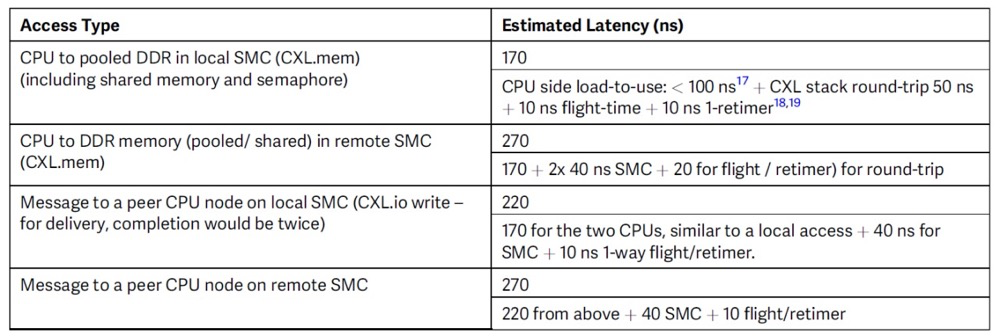
表2 架構(gòu)的延遲估計(jì)
結(jié)論
CXL技術(shù)由于在成熟穩(wěn)定的PCIe基礎(chǔ)設(shè)施上實(shí)現(xiàn)低延遲緩存和內(nèi)存語義的簡便性而在行業(yè)中獲得了廣泛的關(guān)注。CXL可以進(jìn)一步增強(qiáng)和部署,以跨越多個(gè)機(jī)架,為多種應(yīng)用提供高可靠性和低延遲的加載-存儲(chǔ)訪問。通過我們提出的方法,我們期望實(shí)現(xiàn)構(gòu)建跨越機(jī)架和數(shù)據(jù)中心的可組合和可擴(kuò)展系統(tǒng)的愿景,從而實(shí)現(xiàn)能效性能,并帶來顯著的總擁有成本優(yōu)勢。
-
內(nèi)存
+關(guān)注
關(guān)注
8文章
3107瀏覽量
74966 -
PCIe
+關(guān)注
關(guān)注
16文章
1318瀏覽量
84627 -
存儲(chǔ)設(shè)備
+關(guān)注
關(guān)注
0文章
166瀏覽量
19126
原文標(biāo)題:CXL協(xié)議演進(jìn),如何構(gòu)建未來可組合基礎(chǔ)設(shè)施?
文章出處:【微信號(hào):SDNLAB,微信公眾號(hào):SDNLAB】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評(píng)論請先 登錄
兩種高效能電源設(shè)計(jì)及拓?fù)浞治?/a>
突破新興高效能電源要求上的限制
高效能石英振蕩器的選擇
一窺CXL協(xié)議
曙光5000A高效能計(jì)算節(jié)點(diǎn)的設(shè)計(jì)與實(shí)現(xiàn)
符合新興高效能電源要求的設(shè)計(jì)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論