 機器學習中的交叉驗證方法
機器學習中的交叉驗證方法
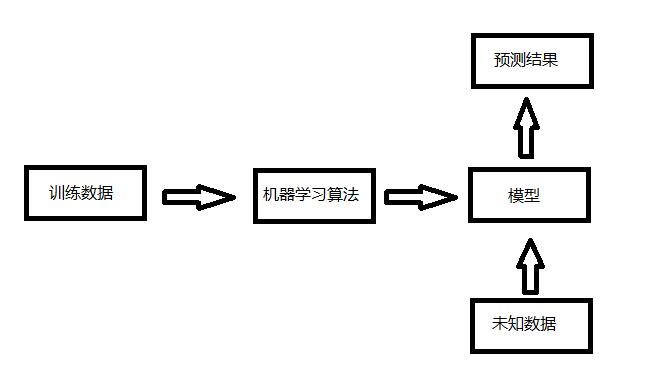
在機器學習中,交叉驗證(Cross-Validation)是一種重要的評估方法,它通過將數據集分割成多個部分來評估模型的性能,從而避免過擬合或欠擬合問題,并幫助選擇最優的超參數。本文將詳細探討幾種常見的交叉驗證方法,包括HoldOut交叉驗證、K-Fold交叉驗證、分層K-Fold交叉驗證、Leave P Out交叉驗證、留一交叉驗證、蒙特卡洛(Shuffle-Split)交叉驗證以及時間序列(滾動交叉驗證)。
一、交叉驗證的基本概念
交叉驗證是一種統計學上的方法,它將數據樣本切割成較小的子集,一部分作為訓練集,另一部分作為驗證集或測試集。這種方法的基本思想是通過在多個不同子集上訓練和測試模型,來評估模型的泛化能力和穩定性。交叉驗證的目的是為了得到可靠且穩定的模型性能評估結果,并幫助選擇最優的超參數。
二、常見的交叉驗證方法
1. HoldOut交叉驗證
HoldOut交叉驗證是最簡單的一種交叉驗證方法。它將原始數據集隨機劃分為兩部分:訓練集和測試集。通常,大部分數據(如70%)用于訓練模型,剩余部分(如30%)用于測試模型。這種方法簡單快速,但由于數據集只被分割一次,因此結果可能具有較大的偶然性。
優點 :
- 快速執行,只需將數據集分割一次。
缺點 :
- 結果可能具有偶然性,因為數據集只被分割一次。
- 不適合不平衡數據集,可能導致訓練集和測試集在類別分布上存在較大差異。
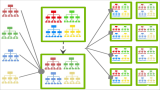
2. K-Fold交叉驗證
K-Fold交叉驗證是應用最廣泛的交叉驗證方法之一。它將數據集分成K個大小相等的子集(或“折疊”),然后在K-1個子集上訓練模型,并在剩余的一個子集上測試模型。這個過程重復K次,每次選擇不同的子集作為測試集,直到每個子集都被用作過測試集。最終,模型的性能評估結果是所有K次測試的平均值。
優點 :
- 有效地避免了過擬合和欠擬合。
- 充分利用了數據集中的所有樣本,每個樣本都被用于訓練和測試。
- 結果相對穩定,因為數據集被分割了多次。
缺點 :
- 不適合不平衡數據集,可能導致某些類別的樣本在訓練集或測試集中缺失。
- 不適合時間序列數據,因為樣本的順序在K-Fold交叉驗證中被打亂。
3. 分層K-Fold交叉驗證
分層K-Fold交叉驗證是K-Fold交叉驗證的改進版,主要用于處理不平衡數據集。在分層K-Fold交叉驗證中,每個折疊都盡量保持與整個數據集相同的類別分布。這樣,每個折疊中的樣本比例都與原始數據集相同,從而避免了因類別分布不均導致的性能偏差。
優點 :
- 對于不平衡數據集非常有效,每個折疊都能保持與原始數據集相同的類別分布。
缺點 :
- 與K-Fold交叉驗證類似,不適合時間序列數據。
4. Leave P Out交叉驗證
Leave P Out交叉驗證是一種詳盡的交叉驗證方法。在這種方法中,每次選擇P個樣本作為驗證集,剩余的樣本作為訓練集。這個過程重復進行,直到所有可能的P個樣本組合都被用作過驗證集。這種方法的計算成本較高,因為需要訓練的模型數量隨著P的增加而急劇增加。
優點 :
- 所有數據樣本都被用作訓練和驗證。
缺點 :
- 計算時間長,特別是對于大數據集。
- 不適合不平衡數據集,可能導致某些類別的樣本在訓練集或驗證集中缺失。
5. 留一交叉驗證
留一交叉驗證是Leave P Out交叉驗證的一個特例,其中P等于1。在留一交叉驗證中,每次只選擇一個樣本作為驗證集,剩余的樣本作為訓練集。這樣,每個樣本都將單獨作為一次驗證集,從而得到N個模型(N為樣本總數)。最后,所有模型的性能評估結果的平均值將作為模型的最終性能評估。
優點 :
- 幾乎利用了數據集中的所有信息,因為每個樣本都被單獨用作過驗證集。
- 結果相對穩定。
缺點 :
- 計算成本高,特別是對于大數據集。
6. 蒙特卡洛(Shuffle-Split)交叉驗證
蒙特卡洛交叉驗證是一種更為靈活的交叉驗證方法。它隨機地將數據集劃分為訓練集和測試集,并且可以指定劃分訓練集和測試集的比例以及劃分的次數。這種方法可以看作是HoldOut交叉驗證的多次隨機版本,因此結果可能具有一定的隨機性。
優點 :
- 靈活性強,可以指定訓練集和測試集的比例以及劃分的次數。
缺點 :
- 結果可能具有隨機性,因為數據集是隨機分割的,不同次運行可能得到不同的性能評估結果。
- 如果劃分次數較少,可能無法充分反映模型的真實性能。
7. 時間序列(滾動/滑動窗口)交叉驗證
時間序列交叉驗證,也稱為滾動或滑動窗口交叉驗證,特別適用于處理具有時間依賴性的數據。在這種方法中,數據集被劃分為多個連續的時間段(窗口),每個窗口都包含一定數量的連續樣本。訓練集由在時間上早于測試集的數據組成,而測試集則是緊接著訓練集之后的數據。隨著窗口的滑動,訓練集和測試集不斷更新,直到數據集的末尾。
優點 :
- 能夠更好地模擬實際的時間序列預測場景,因為模型的訓練和測試都是基于時間順序進行的。
- 適用于需要考慮時間依賴性和時序特征的數據集。
缺點 :
- 計算成本可能較高,特別是當數據集較大且窗口較多時。
- 需要仔細選擇窗口的大小和滑動步長,這些參數對模型的性能有顯著影響。
三、交叉驗證的應用場景
交叉驗證在機器學習中有著廣泛的應用場景,包括但不限于以下幾個方面:
- 模型評估 :通過交叉驗證,可以全面評估模型的性能,包括準確性、穩定性等,從而為模型的選擇和調優提供依據。
- 超參數調優 :在訓練模型時,通常需要調整一些超參數(如學習率、迭代次數、正則化系數等)。通過交叉驗證,可以系統地測試不同的超參數組合,找到最優的參數設置。
- 特征選擇 :在特征工程階段,可以通過交叉驗證來評估不同特征集對模型性能的影響,從而選擇出最有用的特征。
- 數據不平衡處理 :對于不平衡數據集,可以通過分層交叉驗證等方法來確保每個類別的樣本在訓練集和測試集中都有適當的比例,從而提高模型的性能。
- 時間序列預測 :在時間序列預測任務中,滾動/滑動窗口交叉驗證是評估模型性能的重要工具,因為它能夠模擬實際預測過程中的時間依賴性。
四、結論
交叉驗證是機器學習中一種重要的評估方法,它通過將數據集分割成多個部分來評估模型的性能,從而避免了過擬合和欠擬合問題,并幫助選擇最優的超參數。不同的交叉驗證方法各有優缺點,適用于不同的應用場景。在實際應用中,應根據數據集的特性和任務需求選擇合適的交叉驗證方法,以得到準確、穩定的模型性能評估結果。同時,還需要注意交叉驗證過程中的一些細節問題,如數據集的預處理、劃分比例的選擇、隨機種子的設置等,這些都會對最終的結果產生影響。
-
模型
+關注
關注
1文章
3486瀏覽量
49991 -
機器學習
+關注
關注
66文章
8492瀏覽量
134088 -
交叉驗證
+關注
關注
0文章
3瀏覽量
9534
發布評論請先 登錄
Python機器學習常用庫
R語言機器學習算法的性能分析比較

《機器學習與數據挖掘:方法和應用》
基于機器學習算法的水文趨勢預測方法






 工商網監
工商網監
評論