") 基于FPGA BRAM的多端口地址查找表與FPGA BRAM的資源分析
基于FPGA BRAM的多端口地址查找表與FPGA BRAM的資源分析
一、背景
在多端口交換機(jī)的設(shè)計(jì)中,交換機(jī)的每個(gè)端口都會(huì)各自維護(hù)一張查找表,數(shù)據(jù)幀進(jìn)入到交換機(jī)后,需要進(jìn)行查表和轉(zhuǎn)發(fā)。但隨著端口數(shù)量和表項(xiàng)需求的增加,每個(gè)端口都單獨(dú)維護(hù)一張表使得FPGA的資源變得非常緊張。因此,需要一張查找表(本質(zhì)是可讀可寫的RAM),能夠滿足多讀多寫的功能。但在Xilinx FPGA上,Xilinx提供的BRAM IP最高只能實(shí)現(xiàn)真雙端口RAM。不能滿足多讀多寫的需求。
補(bǔ)充:這里不使用其他RAM類型如URAM的原因是,BRAM擁有更好的時(shí)序,更適合在高速交換中用于查找表。
二、手寫Multiport Ram
Multiport Ram,即多讀多寫存儲(chǔ)器,本工程實(shí)現(xiàn)的是1個(gè)口寫,同時(shí)滿足11個(gè)口讀的BRAM。
為了讓vivado在綜合的時(shí)候把手寫ram例化為BRAM,我們需要按照官方手冊(cè)的要求編寫multiport ram。這時(shí)需要通過(*ram_style="block"*)對(duì)array進(jìn)行修飾。
查看Vivado的官方手冊(cè)u(píng)g901可知,對(duì)于Distributed RAM(LUTRAM)和Dedicated Block RAM(BRAM),二者都是寫同步的。主要區(qū)別在于讀數(shù)據(jù),前者為異步,后者為同步的。

下面給出一種手寫多端口bram的方案并給出一種優(yōu)化FPGA bram資源利用的方法。
Multiport RAM 代碼方案
實(shí)現(xiàn)多端口bram最簡(jiǎn)單的方法就是把讀數(shù)據(jù)部分的邏輯復(fù)制11份,寫數(shù)據(jù)部分的邏輯保留1份。
部分代碼如下,實(shí)現(xiàn)位寬73bit,深度為16K的multiport ram:
(*ram_style="block"*)reg [DATA_WIDTH-1:0] bram [0:DEPTH-1];
/*-------------復(fù)制讀端口11份---------------*/
always @(posedge clk)
begin
if(re1)
rd_data1 <= bram[rd_addr1];
else
rd_data1 <= rd_data1;
????end
/*-----------------------------------------*/
//write
always @(posedge clk)
begin
if(we)
bram[wr_addr]<=wr_data;
end
endmodule
資源評(píng)估
利用vivado綜合實(shí)現(xiàn)后,消耗的資源如下
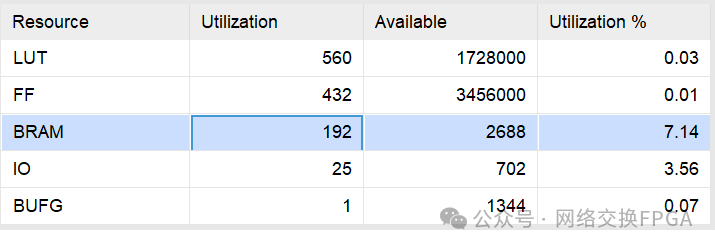
MultiportRAM:16K深度,73位寬的單口寫,11口讀的RAM消耗的BRAM數(shù)為192個(gè)。
普通真雙口RAM:利用vivado IP核生成的16K深度,73bit位寬的真雙口RAM消耗的BRAM數(shù)為32個(gè)。即如果11個(gè)端口各自維護(hù)一張地址查找表共使用352個(gè)RAM。
對(duì)比發(fā)現(xiàn),在滿足11個(gè)端口同時(shí)讀地址查找表的條件下,多端口RAM比普通RAM節(jié)約了45%左右的BRAM資源
三、Multiport RAM 資源利用的優(yōu)化
可能有的同學(xué)說,在某些大工程里面,192個(gè)BRAM還是有點(diǎn)多。下面我給出了一種降低BRAM資源消耗的方法。
首先我們把例化的ram array的位寬翻倍
//原本 (*ram_style="block"*)reg [DATA_WIDTH-1:0] bram [0:DEPTH-1]; //現(xiàn)在 (*ram_style="block"*)reg [DATA_WIDTH+DATA_WIDTH-1:0] bram [0:DEPTH-1];
(有同學(xué)會(huì)問了,這樣資源消耗不是翻倍了嗎?···別急!)
我們把需要寫入RAM的數(shù)據(jù),73位寫data復(fù)制成兩份,同時(shí)寫進(jìn)bram的高73位和低73位,地址不變,其中multi_wdata是我們要寫進(jìn)表中的73位表項(xiàng),代碼如下:
//bram例化模塊的寫使能、地址和數(shù)據(jù)
.we ( multi_wr),
.wr_addr (multi_waddr),
.wr_data({multi_wdata,multi_wdata})
在bram輸出中,每?jī)蓚€(gè)端口共用一個(gè)143位的bram行,并根據(jù)使能情況賦值:
//read1
assign rd_data1_wire = rd_data1[72:0] ;
assign rd_data2_wire = rd_data2[145:73];
always @(posedge clk)
begin
if (re1 & re2) begin
rd_data1 <= bram[rd_addr1];
rd_data2 <= bram[rd_addr2];
end
else
if(re1) begin
rd_data1 <= bram [rd_addr1];
end
else if (re2) begin
rd_data2 <= bram [rd_addr2];
end
end
***補(bǔ)充:具體代碼在文章開頭鏈接
資源評(píng)估
利用vivado綜合實(shí)現(xiàn)后,消耗的資源如下
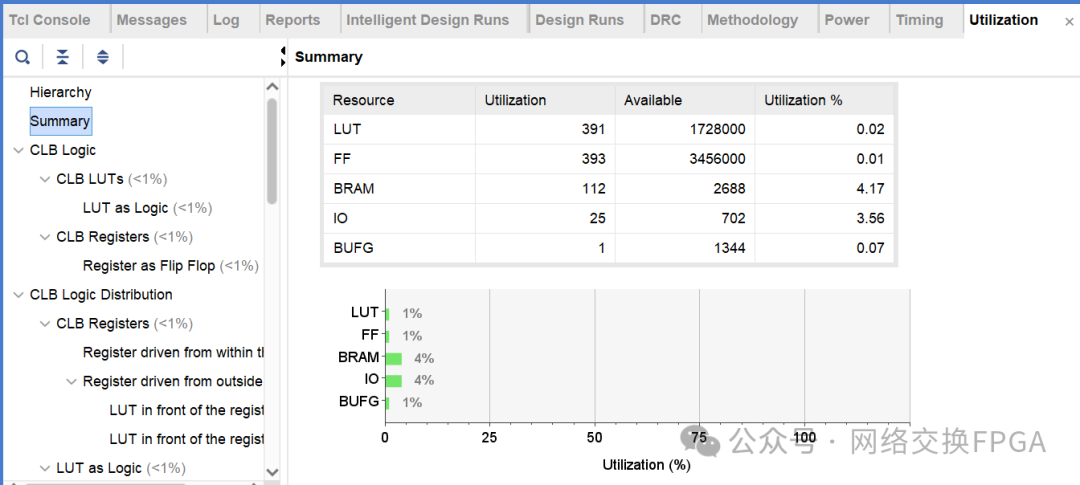
MultiportRAM:16K深度,146位寬的單口寫,11口讀的RAM消耗的BRAM數(shù)為112個(gè)。
普通真雙口RAM:利用vivado IP核生成的16K深度,73bit位寬的真雙口RAM消耗的BRAM數(shù)為32個(gè)。即如果11個(gè)端口各自維護(hù)一張表共使用352個(gè)RAM
對(duì)比發(fā)現(xiàn),在滿足11個(gè)端口同時(shí)讀地址查找表的條件下,多端口RAM比普通RAM節(jié)約了68%左右的BRAM資源
四、防止讀寫沖突的組合邏輯設(shè)計(jì)(寫優(yōu)先)
代碼原理,利用組合邏輯時(shí)序,當(dāng)寫入地址和讀地址相同時(shí),寫入地址、數(shù)據(jù)正常進(jìn)行,但讀端口不對(duì)RAM進(jìn)行讀取,而是將寫入端的數(shù)據(jù)直接賦值給讀出端的數(shù)據(jù)。
下一拍,即讀寫沖突結(jié)束后的下一拍,再讀一拍RAM中的數(shù)據(jù),使得讀端口數(shù)據(jù)保持這一次讀的結(jié)果(因?yàn)榻M合邏輯在讀寫沖突時(shí)沒有真正讀RAM,所以RAM輸出data會(huì)保持上一次輸出的data),但這一步不是必要的,純粹為了好看。
部分代碼如下:
//防止讀寫沖突,且為寫優(yōu)先邏輯 assign multi_rdata0 =(multi_raddr0_f ==multi_waddr_f && multi_raddr0_f !='b0 )?multi_wdata_f:multi_rdata0_ram ; assign multi_rdata1 =(multi_raddr1_f ==multi_waddr_f && multi_raddr1_f !='b0 )?multi_wdata_f:multi_rdata1_ram ; assign multi_rdata2 =(multi_raddr2_f ==multi_waddr_f && multi_raddr2_f !='b0 )?multi_wdata_f:multi_rdata2_ram ; assign multi_rdata3 =(multi_raddr3_f ==multi_waddr_f && multi_raddr3_f !='b0 )?multi_wdata_f:multi_rdata3_ram ; assign multi_rdata4 =(multi_raddr4_f ==multi_waddr_f && multi_raddr4_f !='b0 )?multi_wdata_f:multi_rdata4_ram ; assign multi_rdata5 =(multi_raddr5_f ==multi_waddr_f && multi_raddr5_f !='b0 )?multi_wdata_f:multi_rdata5_ram ; assign multi_rdata6 =(multi_raddr6_f ==multi_waddr_f && multi_raddr6_f !='b0 )?multi_wdata_f:multi_rdata6_ram ; assign multi_rdata7 =(multi_raddr7_f ==multi_waddr_f && multi_raddr7_f !='b0 )?multi_wdata_f:multi_rdata7_ram ; assign multi_rdata8 =(multi_raddr8_f ==multi_waddr_f && multi_raddr8_f !='b0 )?multi_wdata_f:multi_rdata8_ram ; assign multi_rdata9 =(multi_raddr9_f ==multi_waddr_f && multi_raddr9_f !='b0 )?multi_wdata_f:multi_rdata9_ram ; assign multi_rdata10=(multi_raddr10_f==multi_waddr_f && multi_raddr10_f!='b0 )?multi_wdata_f:multi_rdata10_ram; assign multi_raddr0_ram =(multi_raddr0_f ==multi_waddr_f && multi_raddr0_f !='b0 )?multi_waddr_f: multi_raddr0; assign multi_raddr1_ram =(multi_raddr1_f ==multi_waddr_f && multi_raddr1_f !='b0 )?multi_waddr_f: multi_raddr1; assign multi_raddr2_ram =(multi_raddr2_f ==multi_waddr_f && multi_raddr2_f !='b0 )?multi_waddr_f: multi_raddr2; assign multi_raddr3_ram =(multi_raddr3_f ==multi_waddr_f && multi_raddr3_f !='b0 )?multi_waddr_f: multi_raddr3; assign multi_raddr4_ram =(multi_raddr4_f ==multi_waddr_f && multi_raddr4_f !='b0 )?multi_waddr_f: multi_raddr4; assign multi_raddr5_ram =(multi_raddr5_f ==multi_waddr_f && multi_raddr5_f !='b0 )?multi_waddr_f: multi_raddr5; assign multi_raddr6_ram =(multi_raddr6_f ==multi_waddr_f && multi_raddr6_f !='b0 )?multi_waddr_f: multi_raddr6; assign multi_raddr7_ram =(multi_raddr7_f ==multi_waddr_f && multi_raddr7_f !='b0 )?multi_waddr_f: multi_raddr7; assign multi_raddr8_ram =(multi_raddr8_f ==multi_waddr_f && multi_raddr8_f !='b0 )?multi_waddr_f: multi_raddr8; assign multi_raddr9_ram =(multi_raddr9_f ==multi_waddr_f && multi_raddr9_f !='b0 )?multi_waddr_f: multi_raddr9; assign multi_raddr10_ram=(multi_raddr10_f==multi_waddr_f && multi_raddr10_f!='b0 )?multi_waddr_f: multi_raddr10; assign multi_rd0_ram =(multi_raddr0 ==multi_waddr && multi_raddr0!='b0 )? 1'b0:((multi_raddr0_f ==multi_waddr_f && multi_raddr0_f !='b0 )?multi_rd0_f :multi_rd0 ); assign multi_rd1_ram =(multi_raddr1 ==multi_waddr && multi_raddr1!='b0 )? 1'b0:((multi_raddr1_f ==multi_waddr_f && multi_raddr1_f !='b0 )?multi_rd1_f :multi_rd1 ); assign multi_rd2_ram =(multi_raddr2 ==multi_waddr && multi_raddr2!='b0 )? 1'b0:((multi_raddr2_f ==multi_waddr_f && multi_raddr2_f !='b0 )?multi_rd2_f :multi_rd2 ); assign multi_rd3_ram =(multi_raddr3 ==multi_waddr && multi_raddr3!='b0 )? 1'b0:((multi_raddr3_f ==multi_waddr_f && multi_raddr3_f !='b0 )?multi_rd3_f :multi_rd3 ); assign multi_rd4_ram =(multi_raddr4 ==multi_waddr && multi_raddr4!='b0 )? 1'b0:((multi_raddr4_f ==multi_waddr_f && multi_raddr4_f !='b0 )?multi_rd4_f :multi_rd4 ); assign multi_rd5_ram =(multi_raddr5 ==multi_waddr && multi_raddr5!='b0 )? 1'b0:((multi_raddr5_f ==multi_waddr_f && multi_raddr5_f !='b0 )?multi_rd5_f :multi_rd5 ); assign multi_rd6_ram =(multi_raddr6 ==multi_waddr && multi_raddr6!='b0 )? 1'b0:((multi_raddr6_f ==multi_waddr_f && multi_raddr6_f !='b0 )?multi_rd6_f :multi_rd6 ); assign multi_rd7_ram =(multi_raddr7 ==multi_waddr && multi_raddr7!='b0 )? 1'b0:((multi_raddr7_f ==multi_waddr_f && multi_raddr7_f !='b0 )?multi_rd7_f :multi_rd7 ); assign multi_rd8_ram =(multi_raddr8 ==multi_waddr && multi_raddr8!='b0 )? 1'b0:((multi_raddr8_f ==multi_waddr_f && multi_raddr8_f !='b0 )?multi_rd8_f :multi_rd8 ); assign multi_rd9_ram =(multi_raddr9 ==multi_waddr && multi_raddr9!='b0 )? 1'b0:((multi_raddr9_f ==multi_waddr_f && multi_raddr9_f !='b0 )?multi_rd9_f :multi_rd9 ); assign multi_rd10_ram=(multi_raddr10==multi_waddr && multi_raddr1!='b0 )? 1'b0:((multi_raddr10_f==multi_waddr_f && multi_raddr10_f!='b0 )?multi_rd10_f:multi_rd10);
***補(bǔ)充:具體代碼在文章開頭鏈接
讀寫沖突的仿真結(jié)果如下:
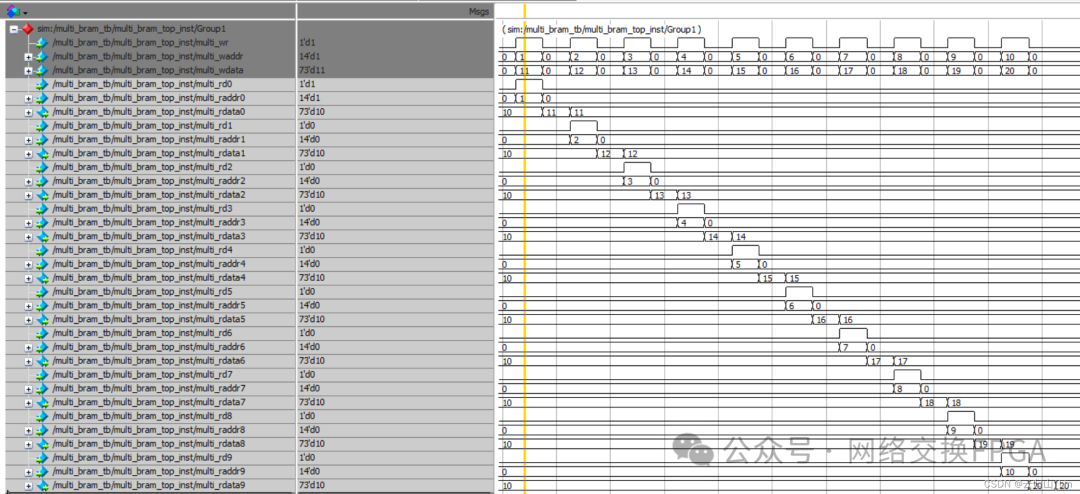
五、Multiport RAM仿真和時(shí)序
所有寫端口都是一拍寫入。讀端口是第一拍讀使能,讀地址,第二拍讀出數(shù)據(jù)。
1.單口寫數(shù)據(jù)

2.單端口讀數(shù)據(jù)

3.多口讀相同數(shù)據(jù)
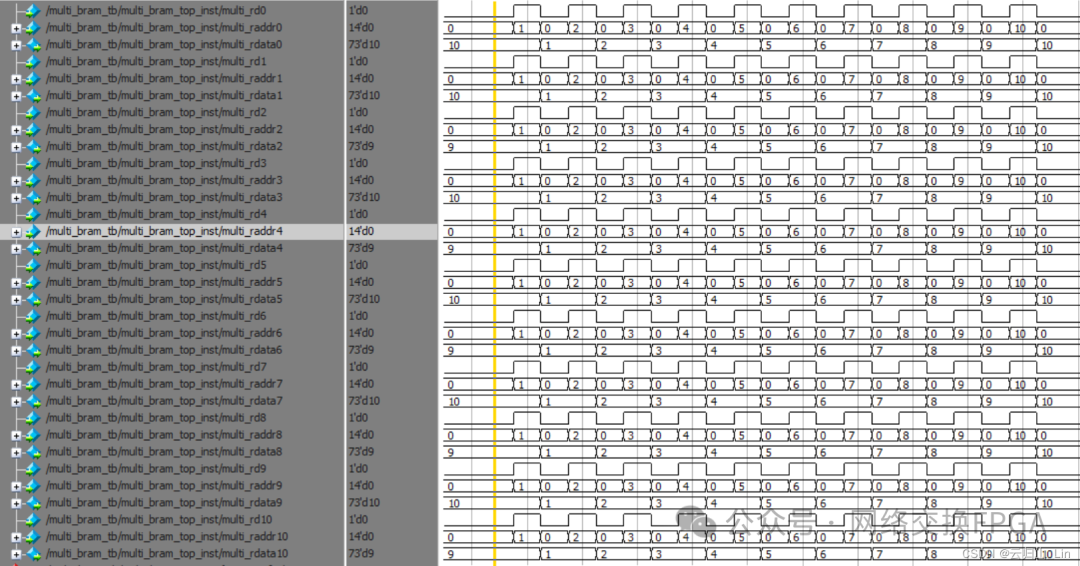
4.多口同時(shí)讀不同數(shù)據(jù)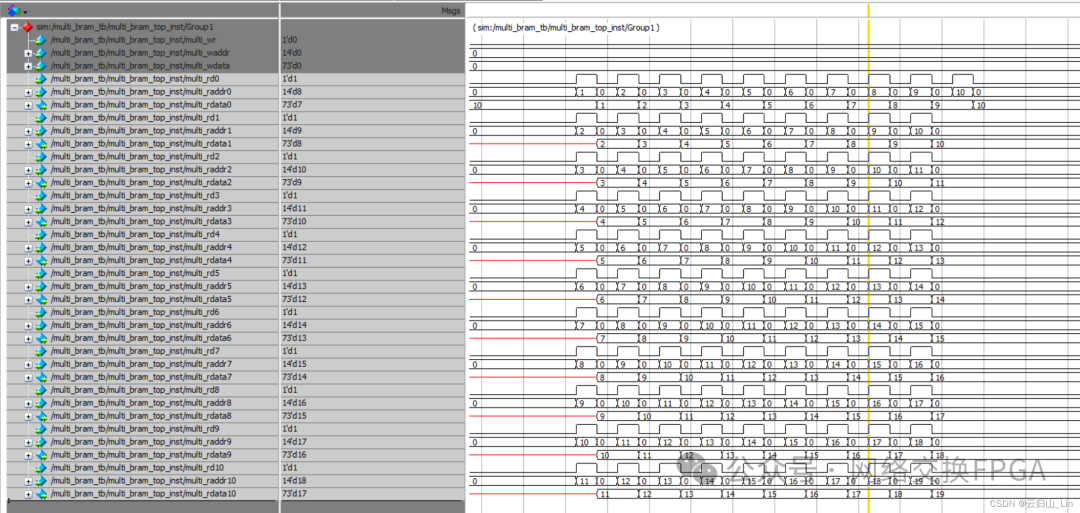
-
FPGA
+關(guān)注
關(guān)注
1643文章
21957瀏覽量
614038 -
存儲(chǔ)器
+關(guān)注
關(guān)注
38文章
7634瀏覽量
166399 -
交換機(jī)
+關(guān)注
關(guān)注
21文章
2721瀏覽量
101349 -
BRAM
+關(guān)注
關(guān)注
0文章
41瀏覽量
11234 -
Vivado
+關(guān)注
關(guān)注
19文章
828瀏覽量
68214
原文標(biāo)題:Multiport RAM,多讀多寫寄存器-——基于FPGA BRAM的多端口地址查找表與FPGA BRAM的資源分析
文章出處:【微信號(hào):gh_cb8502189068,微信公眾號(hào):網(wǎng)絡(luò)交換FPGA】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
【FPGA ZYNQ Ultrascale+ MPSOC教程】33.BRAM實(shí)現(xiàn)PS與PL交互
FPGA設(shè)計(jì)中BRAM的知識(shí)科普
怎么從Virtex 6的FPGA中取出BRAM轉(zhuǎn)儲(chǔ)
如何在不使用DDR內(nèi)存控制器的情況下設(shè)計(jì)FPGA BRAM大容量存儲(chǔ)單元?
無法正確寫入雙端口BRAM
URAM和BRAM的區(qū)別是什么
8255端口地址如何確定_8255怎樣計(jì)算端口地址
FPGA實(shí)現(xiàn)基于Vivado的BRAM IP核的使用
使用FPGA調(diào)用RAM資源的詳細(xì)說明
URAM和BRAM有哪些區(qū)別
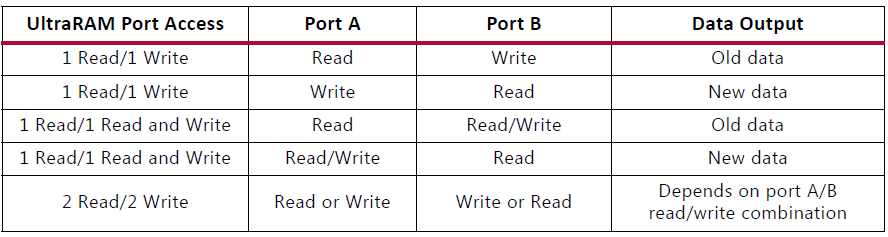
URAM和BRAM有什么區(qū)別
Vivado中BRAM IP的配置方式和使用技巧
FPGA的BRAM資源使用優(yōu)化策略
FPGA實(shí)現(xiàn)基于Vivado的BRAM IP核的使用
基于FPGA設(shè)計(jì)的BRAM內(nèi)部結(jié)構(gòu)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論