 OpenVINO?助力谷歌大語言模型Gemma實現高速智能推理
OpenVINO?助力谷歌大語言模型Gemma實現高速智能推理
大型語言模型(LLM)正在迅速發展,變得更加強大和高效,使人們能夠在廣泛的應用程序中越來越復雜地理解和生成類人文本。谷歌的Gemma是一個輕量級、先進的開源模型新家族,站在LLM創新的前沿。然而,對更高推理速度和更智能推理能力的追求并不僅僅局限于復雜模型的開發,它擴展到模型優化和部署技術領域。
OpenVINO 工具套件因此成為一股引人注目的力量,在這些領域發揮著越來越重要的作用。這篇博客文章深入探討了優化谷歌的Gemma模型,并在不足千元的AI開發板上進行模型部署、使用OpenVINO 加速推理,將其轉化為能夠更快、更智能推理的AI引擎。
此文使用了研揚科技針對邊緣AI行業開發者推出的哪吒(Nezha)開發套件,以信用卡大小(85x56mm)的開發板-哪吒(Nezha)為核心,哪吒采用Intel N97處理器(Alder Lake-N),最大睿頻3.6GHz,Intel UHD Graphics內核GPU,可實現高分辨率顯示;板載LPDDR5內存、eMMC存儲及TPM 2.0,配備GPIO接口,支持Windows和Linux操作系統,這些功能和無風扇散熱方式相結合,為各種應用程序構建高效的解決方案,適用于如自動化、物聯網網關、數字標牌和機器人等應用。
什么是Gemma?
Gemma是谷歌的一個輕量級、先進的開源模型家族,采用了與創建Gemini模型相同的研究和技術。它們以拉丁語單詞 “Gemma” 命名,意思是“寶石”,是文本到文本的、僅解碼器架構的LLM,有英文版本,具有開放權重、預訓練變體和指令調整變體。Gemma模型非常適合各種文本生成任務,包括問答、摘要和推理。
Gemma模型系列,包括Gemma-2B和Gemma-7B模型,代表了深度學習模型可擴展性和性能的分層方法。在本次博客中,我們將展示OpenVINO 如何優化和加速Gemma-2B-it模型的推理,即Gemma-2B參數模型的指令微調后的版本。
利用OpenVINO 優化和加速推理
優化、推理加速和部署的過程包括以下具體步驟,使用的是我們常用的OpenVINO Notebooks GitHub倉庫 中的254-llm-chatbot代碼示例。
由安裝必要的依賴包開始
運行OpenVINO Notebooks倉庫的具體安裝指南在這里。運行這個254-llm-chatbot的代碼示例,需要安裝以下必要的依賴包。
選擇推理的模型
由于我們在Jupyter Notebook演示中提供了一組由OpenVINO 支持的LLM,您可以從下拉框中選擇 “Gemma-2B-it” 來運行該模型的其余優化和推理加速步驟。當然,很容易切換到 “Gemma-7B-it” 和其他列出的型號。
使用Optimum Intel實例化模型
Optimum Intel是Hugging Face Transformers和Diffuser庫與OpenVINO 之間的接口,用于加速Intel體系結構上的端到端流水線。接下來,我們將使用Optimum Intel從Hugging Face Hub加載優化模型,并創建流水線,使用Hugging Face API以及OpenVINO Runtime運行推理。在這種情況下,這意味著我們只需要將AutoModelForXxx類替換為相應的OVModelForXxx類。
權重壓縮
盡管像Gemma-2B這樣的LLM在理解和生成類人文本方面變得越來越強大和復雜,但管理和部署這些模型在計算資源、內存占用、推理速度等方面帶來了關鍵挑戰,尤其是對于這種不足千元級的AI開發板等客戶端設備。權重壓縮算法旨在壓縮模型的權重,可用于優化模型體積和性能。
我們的Jupyter筆記本電腦使用Optimum Intel和NNCF提供INT8和INT4壓縮功能。與INT8壓縮相比,INT4壓縮進一步提高了性能,但預測質量略有下降。因此,我們將在此處選擇INT4壓縮。

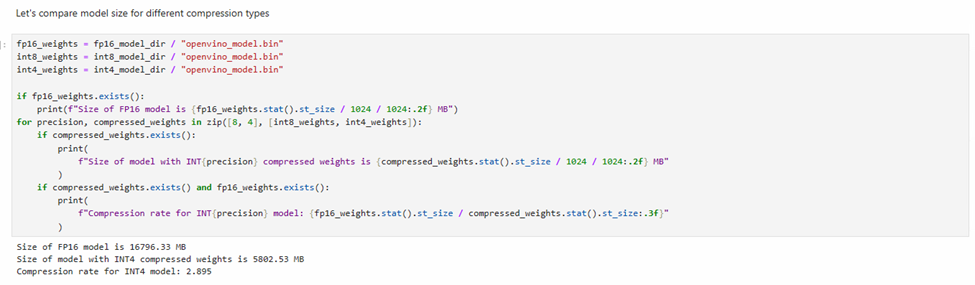
我們還可以比較模型權重壓縮前后的模型體積變化情況。
選擇推理設備和模型變體
由于OpenVINO 能夠在一系列硬件設備上輕松部署,因此還提供了一個下拉框供您選擇將在其上運行推理的設備。考慮到內存使用情況,我們將選擇CPU作為推理設備。
運行聊天機器人
現在萬事具備,在這個Notebook代碼示例中我們還提供了一個基于Gradio的用戶友好的界面。現在就讓我們把聊天機器人運行起來吧。
小結
整個的步驟就是這樣!現在就開始跟著我們提供的代碼和步驟,動手試試用OpenVINO 在哪吒開發板上運行基于大語言模型的聊天機器人吧。
審核編輯:劉清
-
處理器
+關注
關注
68文章
19799瀏覽量
233502 -
機器人
+關注
關注
213文章
29467瀏覽量
211521 -
物聯網
+關注
關注
2927文章
45848瀏覽量
387830 -
GPIO
+關注
關注
16文章
1270瀏覽量
53550 -
OpenVINO
+關注
關注
0文章
113瀏覽量
413
原文標題:千元開發板,百萬可能:OpenVINO? 助力谷歌大語言模型Gemma實現高速智能推理 | 開發者實戰
文章出處:【微信號:英特爾物聯網,微信公眾號:英特爾物聯網】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
如何在Ollama中使用OpenVINO后端
Google發布最新AI模型Gemma 3
為什么深度學習中的Frame per Second高于OpenVINO?演示推理腳本?
為什么無法在運行時C++推理中讀取OpenVINO?模型?
C#集成OpenVINO?:簡化AI模型部署

在龍芯3a6000上部署DeepSeek 和 Gemma2大模型
C#中使用OpenVINO?:輕松集成AI模型!

使用OpenVINO C++在哪吒開發板上推理Transformer模型






 工商網監
工商網監
評論