") CES亮點:AI賦能與產業(yè)創(chuàng)新 | DALL-E 3、SD等20+圖像生成模型綜述
CES亮點:AI賦能與產業(yè)創(chuàng)新 | DALL-E 3、SD等20+圖像生成模型綜述
隨著科技飛速發(fā)展,CES(國際消費電子展)已然成為全球科技產業(yè)的風向標,每年的CES大會都是業(yè)界矚目的盛事。回顧2024年CES大會,不難發(fā)現(xiàn)其亮點紛呈,其中以人工智能的深度賦能為最引人注目之處。AI技術的深入應用成為CES大會上的一大亮點,各大廠商紛紛展示了在AI領域的最新成果。
關鍵詞:CES;AI;VR;消費電子;生成式AI;NVIDIA;Copilot;Rabbit R1;Vision Pro;Micro LED;GeForce RTX 40 SUPER
AI深度賦能
產業(yè)創(chuàng)新紛呈
各大芯片公司圍繞生成式AI展開激烈競爭。英偉達RTX 40 SUPER系列表現(xiàn)優(yōu)秀,不僅提高性能還節(jié)約成本;AMD銳龍8000G系列突出AI能力;英特爾已經(jīng)開始與OEM企業(yè)合作,率先構建AI PC生態(tài)系統(tǒng)。這些的芯片制造商通過不懈努力,有望加速AI及AI PC在不同行業(yè)中的應用,并推動AI技術為各行各業(yè)注入新活力。
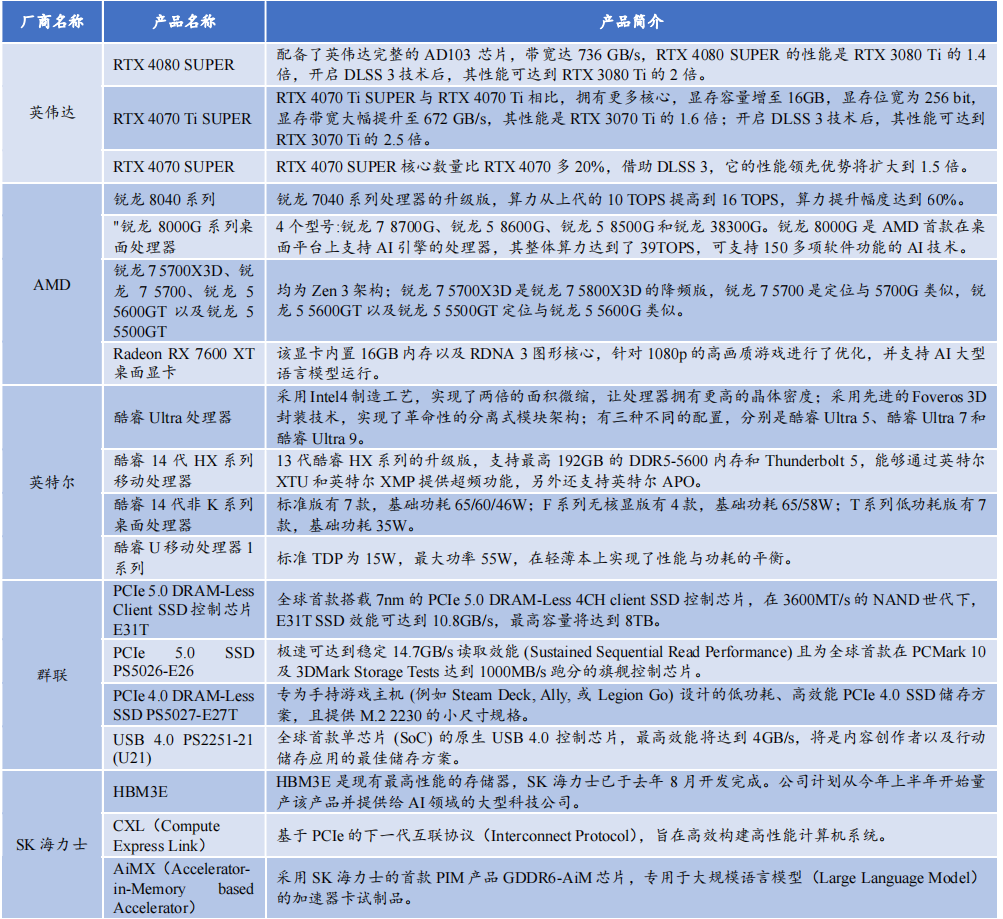
一、英偉達
1、芯片
在本屆CES大會上,英偉達發(fā)布基于Ada Lovelace架構的GeForce RTX 40 SUPER系列顯卡,型號涵蓋RTX 4080 SUPER、RTX 4070 Ti SUPER和 RTX 4070 SUPER三款產品(均可應用于筆記本電腦)。RTX 4080 SUPER憑借AD103芯片和強大的CUDA核心數(shù),736 GB/s的內存帶寬,可輕松應對4K全景光線追蹤游戲。在游戲圖形高性能需求情況下,RTX 4080 SUPER速度是RTX 3080 Ti的1.4倍。此外,借助836 TOPSAI算力和DLSS幀生成功能,RTX 4080 SUPER的性能可達到RTX 3080 Ti的2倍。
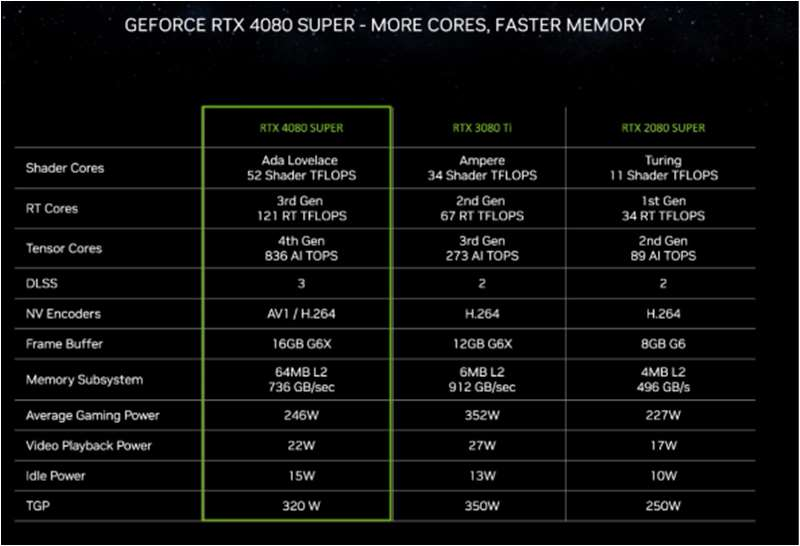
英偉達 RTX 4080 SUPER 性能對比
英偉達RTX 4070 Ti SUPER在核心數(shù)量和顯存容量上優(yōu)于RTX 4070 Ti,顯存容量提升至16GB,顯存位寬為256 bit,帶寬增加至672 GB/s。相較于上代RTX 3070 Ti,其性能提升1.6倍,在開啟DLSS 3技術后,性能可提升至RTX 3070 Ti的2.5倍。
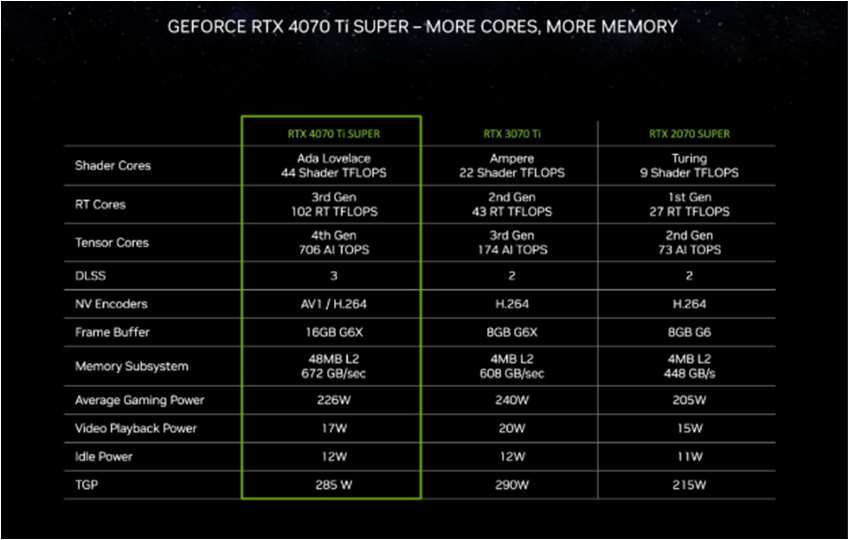
英偉達 RTX 4070 Ti SUPER 性能對比
RTX 4070 SUPER的核心數(shù)量比RTX 4070高出20%,并且僅用RTX 3090部分功耗情況下,就已經(jīng)超越RTX 3090性能表現(xiàn)。當使用DLSS 3時,其性能優(yōu)勢可擴大到1.5倍。
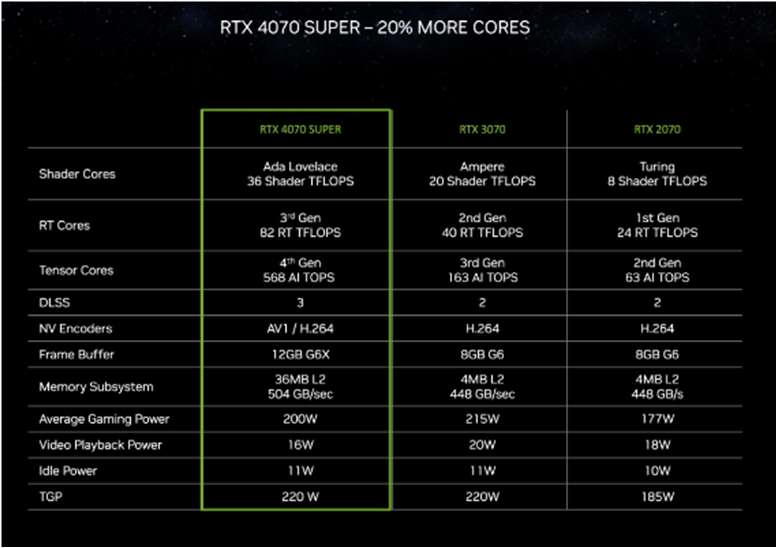
英偉達 RTX 4070 SUPER 性能對比
2、AI軟件服務
英偉達首次將AI應用到游戲虛擬人物生成上,該服務包括NVIDIA Audio2 Face(A2F)和NVIDIA Riva 自動語音識別(ASR)。前者依據(jù)聲音來源制作富有表情的面部動畫,后者能為虛擬數(shù)字人物開發(fā)多語言語音和翻譯應用。

3、智能駕駛領域
在CES2024展會上,梅賽德斯-奔馳發(fā)布一系列軟件驅動功能以及基于NVIDIA DRIVE Orin芯片的CLA級智能駕駛輔助系統(tǒng)。
英偉達近日宣布,理想汽車等一系列廠商選擇使用NVIDIA DRIVE Thor集中式車載計算平臺。此外,電動汽車制造商如長城汽車、極氪和小米汽車已決定在其新一代自動駕駛系統(tǒng)中采用NVIDIA DRIVE Orin平臺。
二、AMD
AMD引入基于Zen 3架構的四款新品,包括銳龍7 5700X3D、銳龍7 5700、銳龍5 5600GT和銳龍5 5500GT:
- 銳龍7 5700X3D具有8核16線程設計,最大加速頻率為4.1GHz,并支持3D V-CACHE技術,游戲性能十分突出;
- 銳龍7 5700是8核16線程,最大加速頻率4.6GHz,無核顯;
- 銳龍5 5600GT和銳龍5 5500GT都是6核12線程,最大加速頻率分別為4.6GHz和4.4GHz,并帶有Radeon核顯。
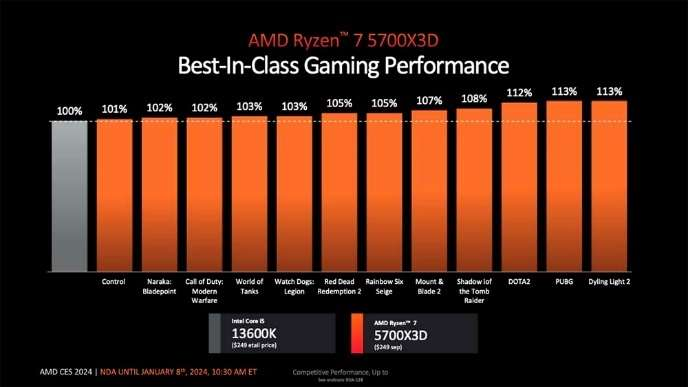
銳龍 7 5700X3D 游戲性能優(yōu)秀
AMD發(fā)布新顯卡Radeon RX 7600 XT,配備RDNA 3圖形核心和16GB內存,專門優(yōu)化1080p高畫質游戲,并可以處理一些1440p游戲。該顯卡支持HYPR-RX、Ray Tracing、AV1、FSR3等軟件,提供更順暢的游戲體驗。此外,16GB內存使Radeon RX 7600 XT能夠支持AI大語言模型,顯著提高處理和創(chuàng)作速度。

Radeon RX 7600 XT 16GB 顯卡的游戲性能得到較大提升
三、英特爾
英特爾推出14代酷睿移動和臺式機處理器系列,包括升級版的HX系列移動處理器,以及適用于移動平臺的低壓酷睿移動處理器系列。14代酷睿HX系列提升游戲和多任務創(chuàng)作性能,支持最高192GB DDR5-5600內存和Thunderbolt 5,并配備超頻功能以及增強的聯(lián)網(wǎng)能力。酷睿i9-14900HX是14代移動處理器家族的頂級產品,擁有24核心32線程,最高頻率為5.8 GHz。

英特爾 14 代酷睿 HX 系列移動處理器
四、群聯(lián)
群聯(lián)電子推出全球首款7納米制程的PCIe 5.0 DRAM-Less 4CH client SSD控制芯片E31T,標志著其在PC OEM和主流SSD市場開展業(yè)務。這顆新芯片在現(xiàn)有的3600MT/s NAND時代下,SSD效能可達到10.8GB/s,最高容量可達8TB。未來4800MT/s NAND發(fā)布后,其速度可能提升至14GB/s。此外,群聯(lián)還展示其他新產品,如PCIe 5.0 SSD PS5026-E26、PCIe 4.0 DRAM-Less SSD PS5027-E27T和USB 4.0 PS2251-21 (U21)。
CES 2024大會亮點
CES作為頗具影響力的科技展覽,展示芯片硬件到終端應用的全方位科技成果,涉及AI、VR、消費電子、汽車電子和智能家居等領域,標志著未來科技的方向。
一、AI PC
AI PC作為本次盛會主角,集結全鏈條科技力量,包括芯片、系統(tǒng)和終端,預示著AI PC元年來臨。戴爾、惠普、華碩、三星等知名廠商的AI PC產品勢如破竹,在硬件提升、AI助手整合和性能優(yōu)化方面展示出其領先地位。特別是大多數(shù)AI PC都增加AI專用啟動鍵。英偉達、AMD、英特爾等核心元件制造商的最新AI PC芯片部署,使整體計算能力有了顯著的提升。在CES 2024引領下,全球PC產業(yè)正在以更快的速度進入AI時代。
二、生成式AI與筆記本電腦完美結合:開啟智能辦公新時代
2023年,生成式AI成為科技領域的大熱話題。因此在CES展上,生成式AI大放光彩。
戴爾Windows 11筆記本將配備微軟自然語言AI助手,即通過Windows for Copilot按鈕實現(xiàn)更智能操作。NVIDIA首次推出Chat with RTX展示應用程序,可以在Windows RTX個人電腦或工作站上搜索包括聊天、文檔和視頻在內的各種內容。
在零售商業(yè)領域,生成型AI也在2024年的CES展上大放異彩。如沃爾瑪首次亮相Shop With Friends社交商務平臺。大眾汽車正在嘗試將ChatGPT技術融入到汽車產品中。目前不能確定這些功能是否會像語言AI助手一樣受歡迎,從長遠角度來看,都是值得密切關注的重要發(fā)展趨勢。
三、生產力小工具強調速度和易用性
在2024年CES展覽會上Rabbit R1是另外一個令人矚目的焦點,這是一款基于生成式AI的手持設備。其可以改變人們與應用程序的互動方式,甚至可以取代智能手機。例如,通過用戶簡單口頭指令,Rabbit R1能完成如“預訂航班”等任務。
 ?
?
此外,屏幕顯示技術也取得重大突破。如聯(lián)想ThinkVision 27 3D顯示器能快速將2D圖像轉換為3D內容,滿足用戶多樣化的需求。
值得一提的是,Wi-Fi 7認證推出意味著更多設備將具備更高的數(shù)據(jù)處理能力,為虛擬現(xiàn)實等應用領域帶來無限可能。在展會上,眾多制造商如TP-Link、UniFi、MSI和Acer都發(fā)布適配Wi-Fi 7的路由器產品。
四、多合一筆記本電腦為專業(yè)人士提供選擇
在CES 2024上,能夠輕松轉換為平板電腦的筆記本成為焦點,其中惠普Spectre x360和戴爾新款XPS系列備受矚目。華碩的Zenbook DUO(2024)UX8406更是獨樹一幟,憑借其獨特的雙屏設計和靈活的變形模式,為用戶提供豐富的功能。
五、高通、汽車制造商和其他公司推廣虛擬現(xiàn)實和混合現(xiàn)實產品
預計一月底,三星將推出一款搭載高通驍龍XR2+ Gen 2芯片的虛擬混合現(xiàn)實耳機,與蘋果的Vision Pro展開競爭。在CES展覽會上,除三星和寶馬之外,混合現(xiàn)實和虛擬現(xiàn)實還在其他領域得到展示。
六、曲面透明的電視屏幕引人注目
在家庭辦公環(huán)境中,透明電視屏幕已從單純的電視設備轉變?yōu)榱钊梭@嘆的藝術品。三星透明Micro LED和LG Signature OLED T就是杰出代表。此外,許多大型曲面顯示器也在展現(xiàn)游戲市場的吸引力。不僅提升電視的觀感體驗,也進一步拓寬顯示技術的應用領域。
?
DALL-E、Stable Diffusion
等 20+ 圖像生成模型綜述
近兩年圖像生成模型如Stable Diffusion和DALL-E系列模型的不斷發(fā)展引起廣大關注。為深入理解 Stable Diffusion 和 DALL-E 3 等最新圖像生成模型,從頭開始探索這些模型的演變過程就顯得至關重要。下面主要通過任務場景、評估指標、模型類型、效率優(yōu)化、局限性等11個方面為大家進行講解。
一、任務場景
1、無條件生成
無條件生成是一種生成模型不受任何額外條件影響,只根據(jù)訓練數(shù)據(jù)分布生成圖像。其適用于不需要額外信息或上下文的場景,如根據(jù)隨機噪聲生成逼真的人臉圖像。舉列來說:CelebA-HQ和FFHQ是高質量的人臉數(shù)據(jù)集,分別包含30,000和70,000張1024x1024分辨率的人臉圖像。而LSUN是一款場景類別數(shù)據(jù)集,包括臥室、廚房、教堂等類別,每個圖像的大小為256x256分辨率,每個類別包含12萬到300萬張圖像。這些都是常用的無條件評估任務。
2、有條件生成
有條件生成是一種生成模型,在形成圖像時會受到額外條件或上下文的影響,如類別標簽、文本描述或特定屬性等。廣泛應用于需要按特定條件生成結果的任務。如根據(jù)給定的文本描述生成相應的圖像或在生成特定類別圖像時提供相應類別標簽。
1)類別條件生成
類別條件生成常用于圖像生成領域,ImageNet 是其常見的實例,主要用于圖像分類任務,擁有1000個類別標簽。在生成圖像時,可以指定對應的類別標簽,讓模型按照類別進行圖像生成。
2)文本條件生成
文本條件生成是目前最流行的圖像生成方法,其模型可根據(jù)輸入的自然語言描述來生成相應的圖像。
3)位置條件
當對圖像的物體布局或主體位置有特定需求時,可以結合使用類別條件和文本條件指導模型生成過程。
4)圖像擴充
圖像條件經(jīng)常被用于按需處理圖像,如圖像擴充(Outpainting)。

5)圖像內編輯
圖像內編輯(Inpainting)是另一個以圖像為條件的常見生成方式,結合文本輸入進行操作。
6)圖像內文字生成
需要圖片中包含特定文本內容,也可以條件形式輸入。
7)多種條件生成
有些場景會包含多種條件,如給定圖像、文本等,模型要綜合考量這些條件才能生成滿足要求的圖像。
三、評估指標
1、IS
IS(Inception Score)一個評估生成圖像質量和多樣性的標準,主要考慮生成圖像的真實性與多樣性。其計算過程通過分類模型確定各類別的概率分布,再計算概率分布的KL散度,最后以指數(shù)平均值形式表達。
2、FID
FID(Frechet Inception Distance)即衡量生成圖片與真實圖片距離指標,其值越小代表越優(yōu)秀。計算方法包括提取真實圖像和生成圖像的特征向量,并計算二者的Frechet距離。在實踐中通常利用IS評估真實性,而FID則用來評估多樣性。
3、CLIP Score
OpenAI發(fā)布的CLIP模型包含圖像和文本編碼器,主要目的是實現(xiàn)圖文特征的匹配。其工作方式是分別提取文本和圖片的嵌入值計算相似性,距離大則說明相似性低,圖片和文本不相關。
4、DrawBench
在 Imagen 中,Google 提出 DrawBench,是一個全面且具有挑戰(zhàn)性的文本生成圖片模型評測基準。

DrawBench 基準包含 11 個類別的 200 個文本提示
針對各類別進行獨立人工評估,評估員對兩組模型A和B生成的圖像進行評分。每組有8個隨機生成結果。評分員需要回答:哪組圖像質量更高,以及哪組圖像與文本描述更匹配。每個問題都有三個選項:更喜歡A,無法確定,更喜歡B。
四、常用模型
1、模型結構
圖像生成任務通常由多個子模型組成,包括常見的 CNN、AutoEncoder、U-Net、Transformer等。其中,AutoEncoder 和 U-Net等模型相似,都是各種模型的主要組成部分。主要的差別在于AutoEncoder由編碼器和解碼器組成,可以單獨使用,編碼器壓縮輸入,比如把圖像映射到隱空間,解碼器用編碼重構輸入,即從隱空間恢復圖像。而U-Net模型在編碼器和解碼器之間添加Skip Connection,使得解碼器不僅依賴隱空間編碼,還依賴輸入,因此不能單獨使用。
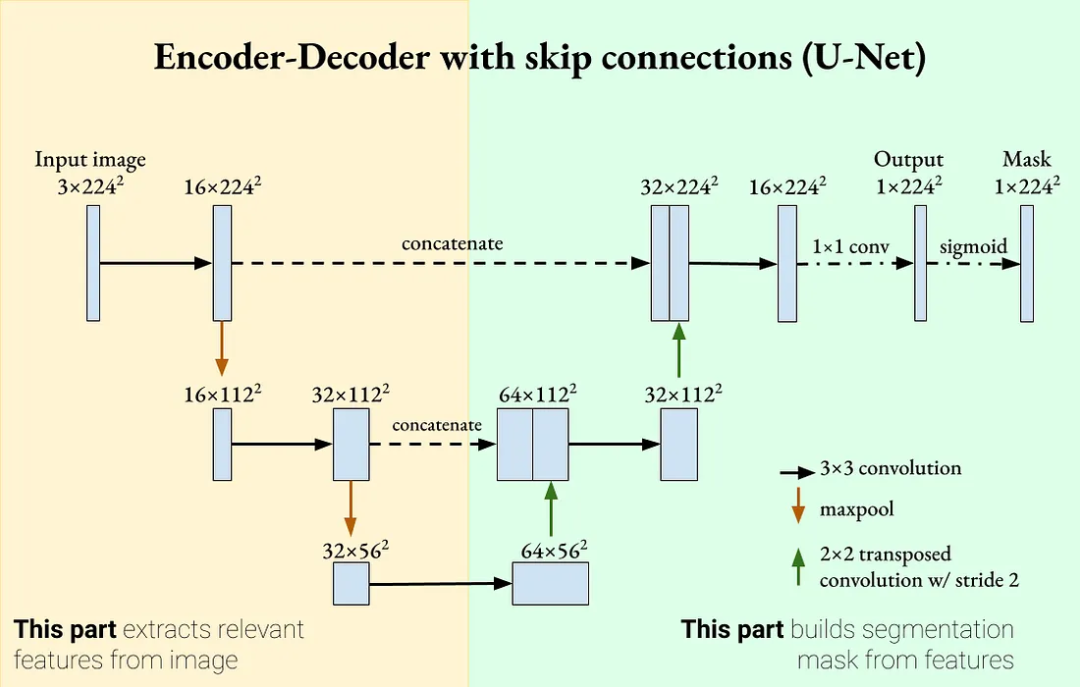
2、預訓練模型
1)CLIP 模型
OpenAI的CLIP是一個強大的圖文對齊模型,利用對比學習在海量圖文數(shù)據(jù)對(4億)上進行預訓練。在訓練過程中,將配對的圖文特征視為正面,將圖片特征與其他文本特征視為負面。由于其強大的表征能力,CLIP的文本和圖像編碼器常常被其他模型用于圖像或文本編碼。
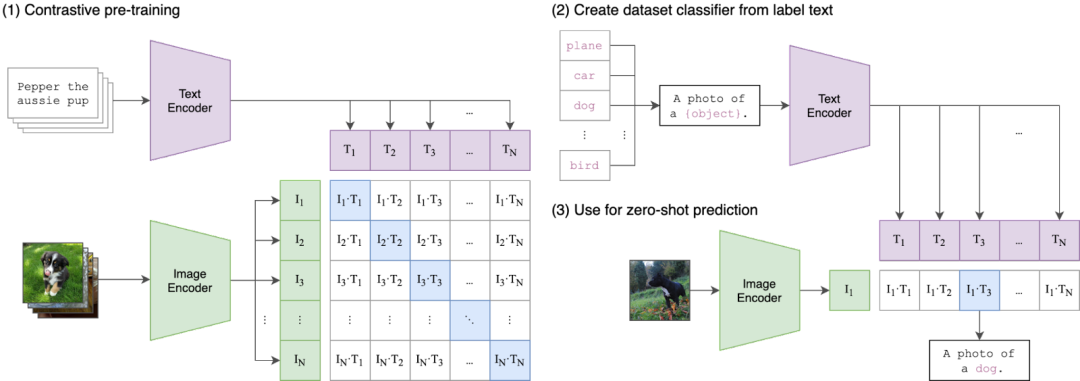
2)CoCa 模型
CoCa模型在CLIP模型基礎上,增加多模態(tài)文本解碼器。訓練過程中,除使用原來CLIP模型對比損失,增加描述損失。
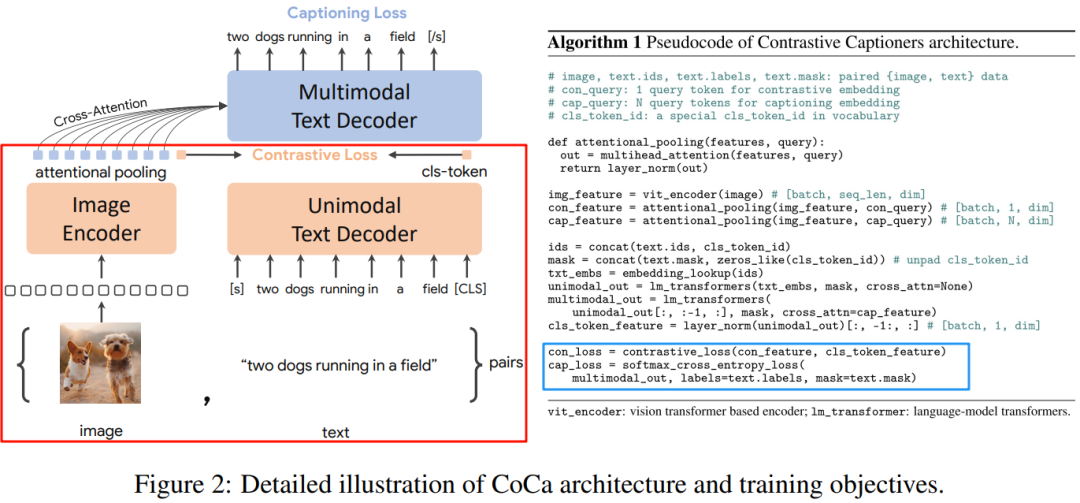
五、模型類型
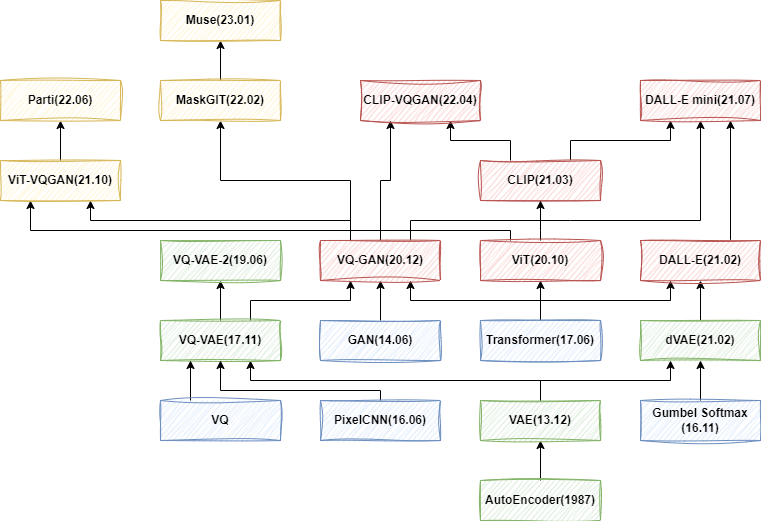
1、VAE 系列
VAE系列模型發(fā)展從最初自編碼器(AE)發(fā)展到變分自編碼器(VAE),然后出現(xiàn)向量量化VAE(VQ-VAE)、VQ-VAE-2以及VQ-GAN、ViT-VQGAN和MaskGIT等。但這些通常只用于無條件生成或簡單類別和圖像條件,對文本輸入支持能力不足。
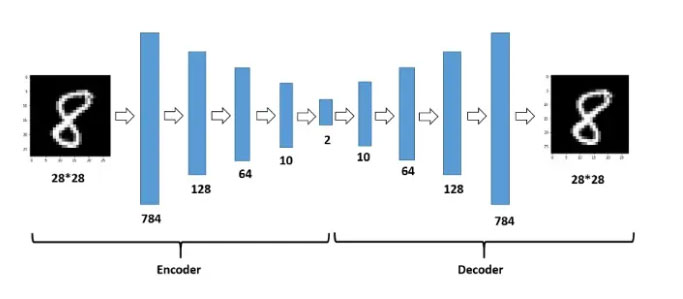
1)AE
自編碼器(AE)是一種人工神經(jīng)網(wǎng)絡技術,用于實現(xiàn)無標簽數(shù)據(jù)的有效編碼學習。該過程涉及將高維度數(shù)據(jù)做低維度表示,進而實現(xiàn)數(shù)據(jù)壓縮,因此主要應用于降維任務。AE主要由兩部分組成:編碼器(負責將輸入數(shù)據(jù)編碼,即壓縮)和解碼器(負責使用這些編碼重構輸入,即解壓)。
2)VAE
變分自編碼器(VAE)在自編碼器(AE)的基礎上,引入概率生成模型思想,通過設置隱空間概率分布,生成多樣樣本,同時更好地理解數(shù)據(jù)的分布性質。
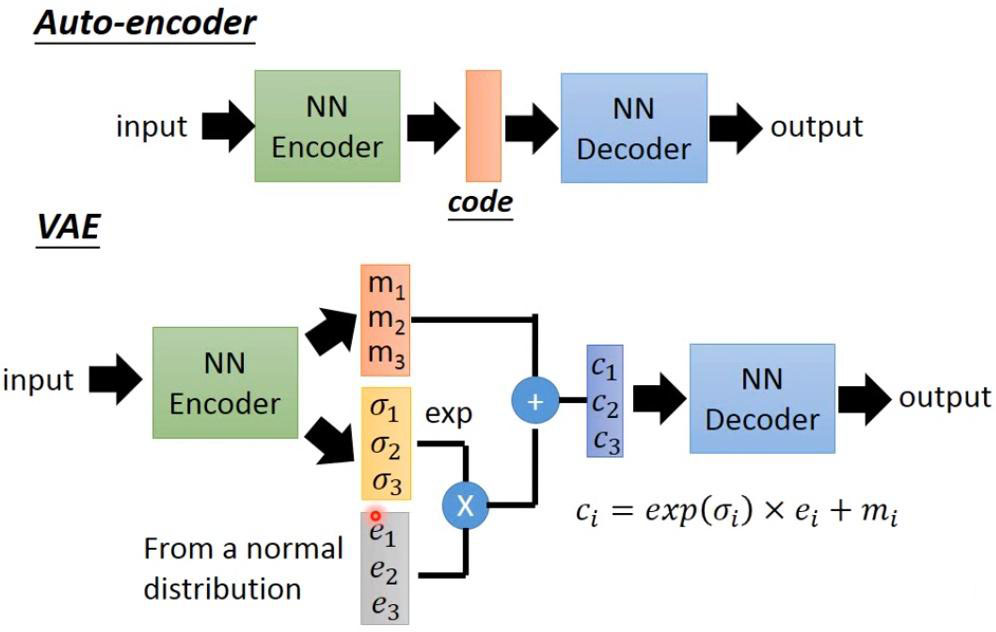
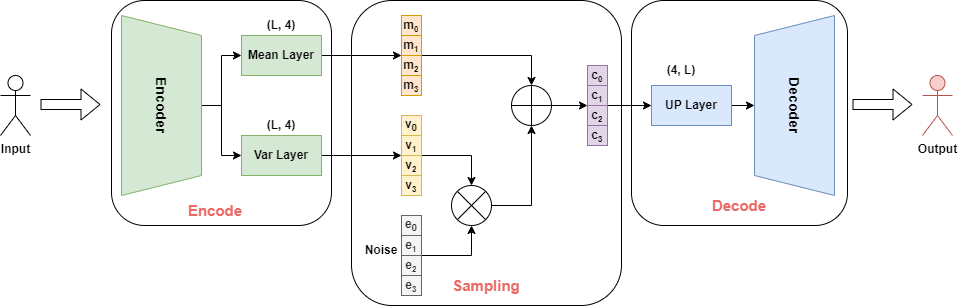
3)VQ-VAE
向量量化變分自編碼器(VQ-VAE)在變分自編碼器(VAE)基礎上加入離散、可度量的隱空間表示形式,有利于模型理解數(shù)據(jù)中的離散結構和語義信息,同時可以避免過擬合。VQ-VAE與VAE的工作原理相通,只是在中間步驟中,沒有學習概率分布,而是利用向量量化(VQ)學習代碼書(Codebook)。
4)VQ-GAN
向量量化生成對抗網(wǎng)絡(VQ-GAN)的主要改進是使用生成對抗網(wǎng)絡(GAN)策略,將變分自編碼器(VAE)作為生成器,并配合一個判別器對生成圖像進行質量評估。該模型引入感知重建損失方案,不僅關注像素差異,同時也關注特征圖差異,以此來生成更高保真度的圖片,從而使學習的代碼書更加豐富。
5)ViT-VQGAN
圖像轉換器 VQ-GAN (ViT-VQGAN)的模型結構保持VQGAN的基礎結構,關鍵差異在于將編解碼器的CNN框架切換為ViT模型。首先,編碼器對每8x8像素塊進行獨立編碼,從而產生1024個 token 序列。再者通過量化過程,這1024個token序列被映射到大小為8192的codebook空間。然后,解碼器從1024個離散的潛在編碼中復原原始圖像。最后,自回歸轉換器被應用于生成離散潛在編碼。訓練期間,可以直接使用由編碼器生成的離線潛在編碼作為目標,計算交叉熵損失。
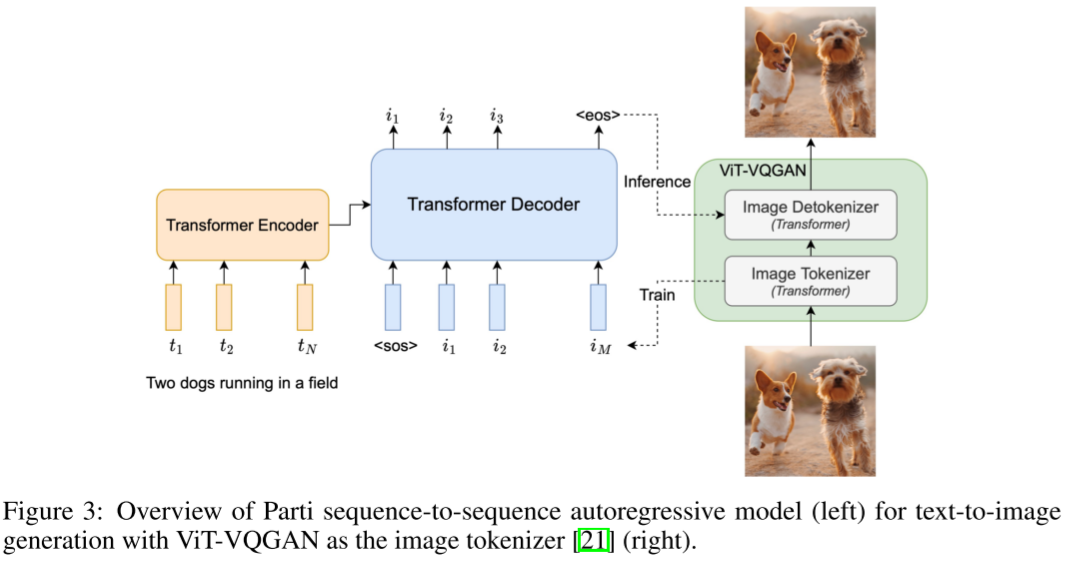
6)Parti
相較于VQ-GAN或ViT-VQGAN僅使用解碼器(Decoder Only)形式的Transformer來生成離散的潛在編碼,Parti的作者采取編碼器+解碼器(Encoder + Decoder)的模式。這樣做的好處就在于可以使用編碼器對文本進行編碼,生成文本嵌入(Text Embedding),再將這個文本嵌入作為條件引入解碼器中,通過交叉注意力機制(Cross Attention)與視覺Token產生交互。
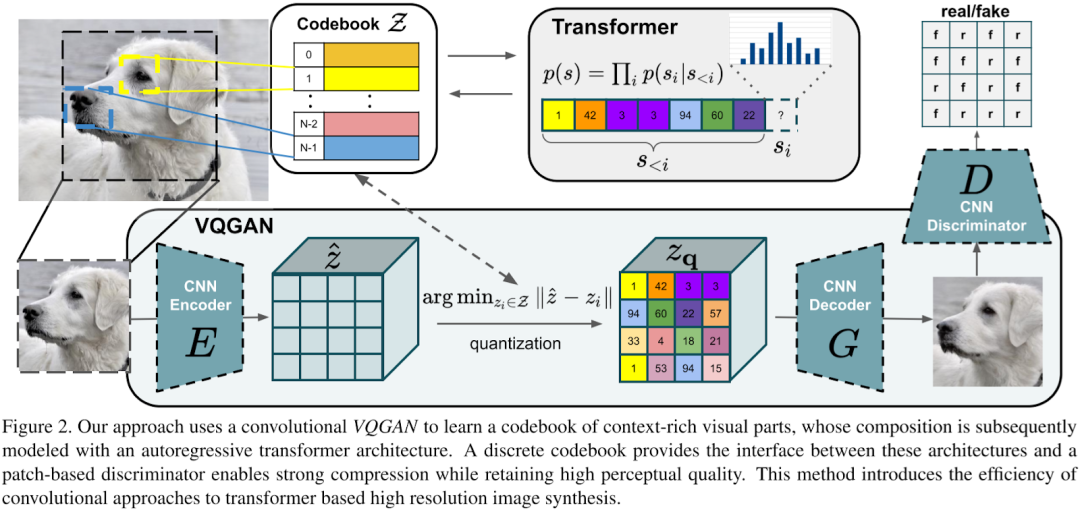
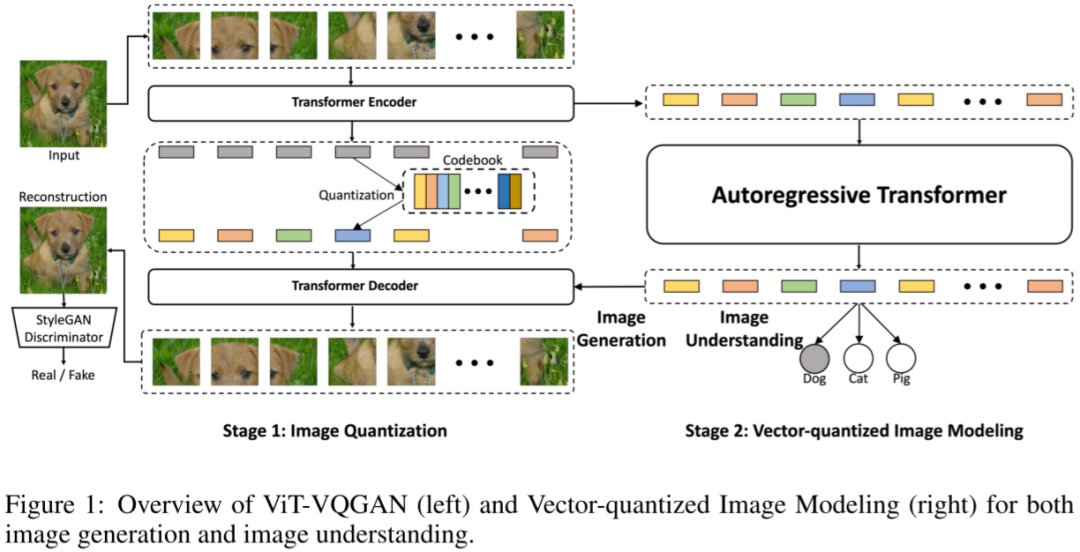
7)MaskGIT
MaskGIT模型采用VQGAN范式,但在實現(xiàn)上有所不同。VQGAN中的Transformer通過序列生成方式預測圖像Token,一次只預測一個,效率不高。相比之下,MaskGIT采用蒙面視覺Token建模法(Masked Visual Token Modeling)進行訓練,這種方法使用類似BERT的雙向Transformer模型,訓練時會隨機遮擋部分圖像Token,目標就是預測這些被遮擋的Token。
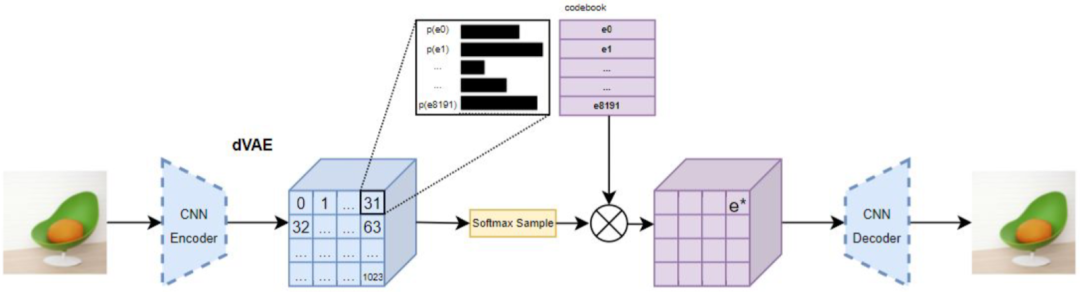
8)DALL-E
DALL-E訓練過程和VQ-GAN相似,但DALL-E并未使用VQ-VAE,而是選擇Discrete VAE(dVAE),其的總體概念相似。dVAE的主要不同之處在于引入Gumbel Softmax進行訓練,有效避免VQ-VAE訓練中由于ArgMin操作不能求導而產生的問題。
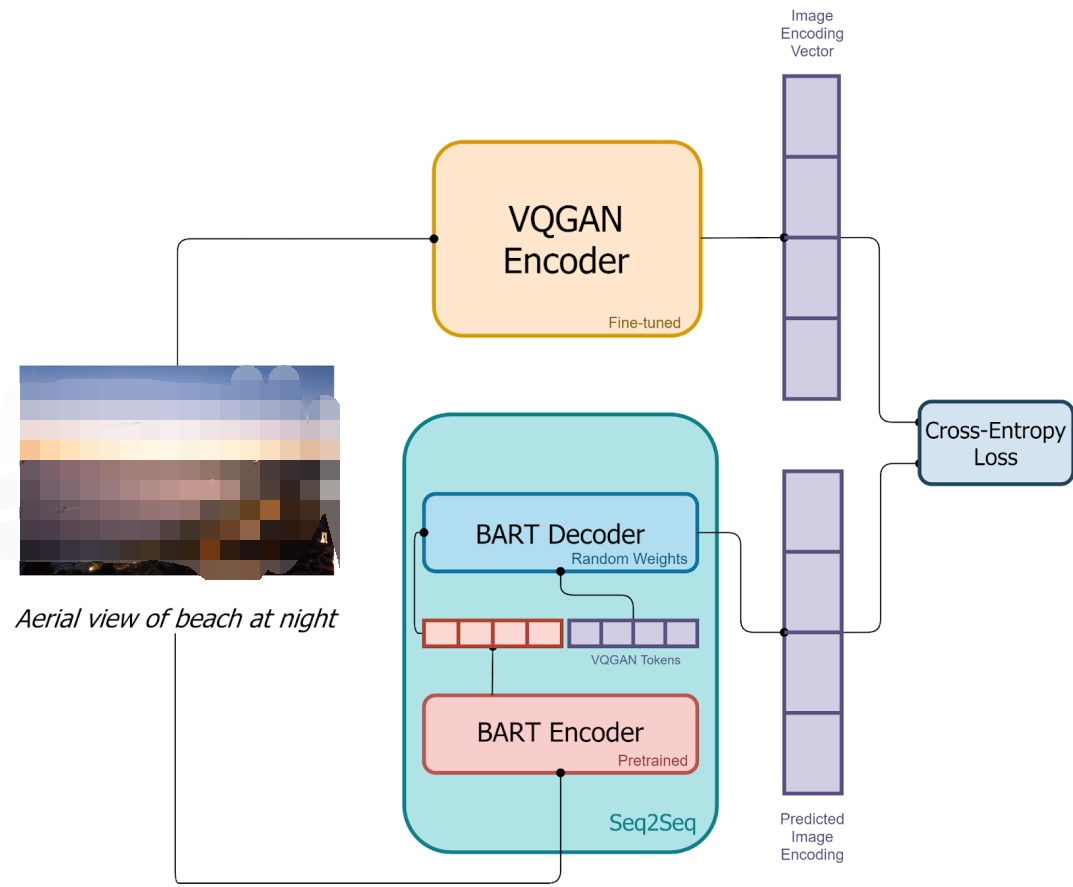
9)DALL-E mini
DALL-E mini是社區(qū)對DALL-E的開源復現(xiàn)。其使用VQ-GAN替代dVAE,用具有編碼器和解碼器的BART替代DALL-E中僅解碼器的Transformer。此外,會用VQ-GAN的解碼器生成多張候選圖像,利用CLIP提取這些圖像和文本嵌入,進行比較排序,以挑選出最匹配的生成結果。
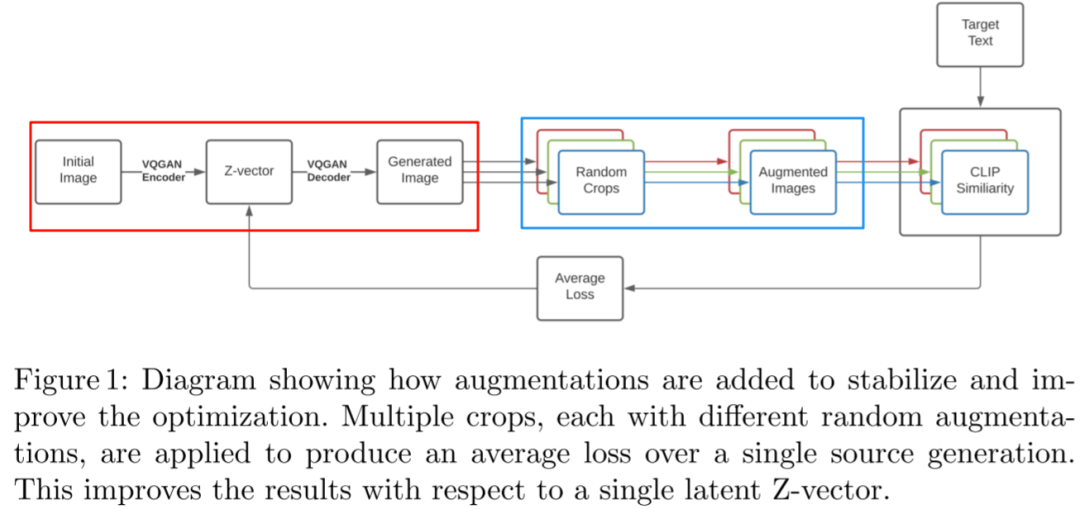
10)VQGAN-CLIP
VQGAN-CLIP的實現(xiàn)思路直接明了,通過VQ-GAN將初始圖像轉化成一幅新圖像,然后使用CLIP對這個生成圖像以及目標文本提取embedding,計算它們之間的相似性,并將誤差反饋到隱空間的Z-vector上進行迭代更新。
2、Diffusion 系列
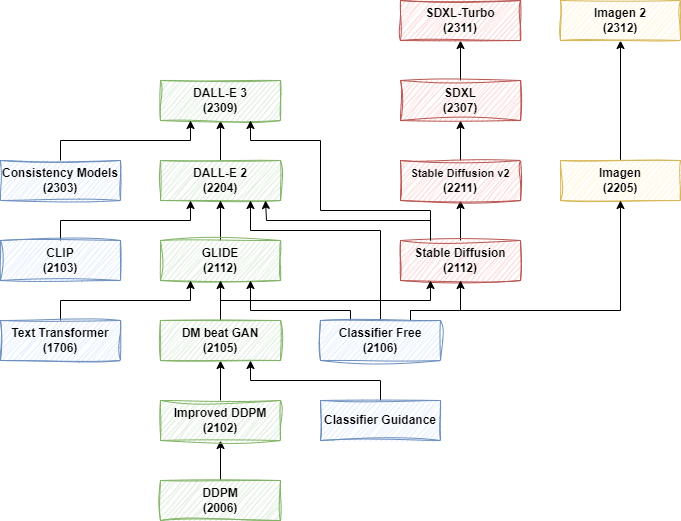
Diffusion模型雖在2015年首次被提出,但因效果不佳未受到廣泛關注。直到2020年06月OpenAI發(fā)布DDPM后,該模型才逐漸為人所知。Diffusion模型的發(fā)展路徑主要包括OpenAI系列模型,Stable Diffusion系列模型,以及Google的Imagen和Imagen 2。
1)DDPM
在擴散模型中存在兩個關鍵步驟:前向過程(或稱為擴散過程)以及逆向過程。簡單來說前向過程的要點在于不斷向圖片添加高斯噪聲,而逆向過程的主旨則在于通過逐步去除高斯噪聲以重建圖像。
2)Diffusion Model Beat GANs
主要有兩個亮點:首先對無條件圖像生成中不同模型結構對生成效果的影響進行大量的消融實驗驗證。其次引入分類器引導以提升生成質量。
模型結構主要變動包括在保持模型大小不變的前提下增加深度、減小寬度,以及增加Attention頭的數(shù)量,并擴大Attention的應用范圍至16x16、32x32和8x8的分辨率上。結果表明,更多和更廣泛的Attention應用范圍以及采用BigGAN的residual block都可以幫助提升模型表現(xiàn)。這些工作不僅創(chuàng)建了一種新的模型--ADM(Ablate Diffusion Model), 為OpenAI后續(xù)的生成模型打下堅實基礎,同時也為Stable Diffusion的模型開發(fā)提供參考。
3)GLIDE
在GLIDE模型中,將Diffusion模型應用于文本條件圖像生成,主要包含兩個子模型:
- 文本條件的擴散模型
由一個文本編碼的變壓器(1.2B,24個殘差塊,寬度2048)以及一個在Diffusion Model Beat GANs中的ADM(Ablated Diffusion Model)的擴散模型組成,后者的分辨率為64x64,參數(shù)為2.3B,寬度擴展至512通道,并在該基礎上擴展文本條件信息。
- 文本條件+上采樣模型
包括類似于前述文本變壓器模型,但是寬度減少到1024,還有一種同樣源自ADM-U的上采樣模型,分辨率從64x64擴展到256x256,通道數(shù)從192擴展到384。
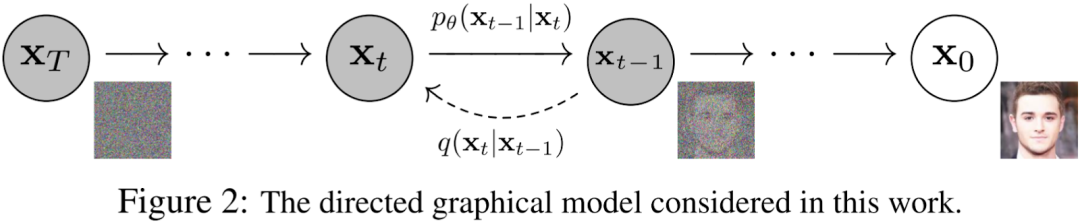
4)DALL-E 2
GLIDE模型對文本引導圖像生成進行全新的嘗試,并取得優(yōu)秀成果。在這項工作中,利用強大的CLIP模型,構建一個兩階段圖像生成模型,該模型主要由四個部分構成。
- 一個對應CLIP模型的圖像編碼器,其生成的圖像嵌入在訓練階段被用做prior目標,要求prior生成嵌入盡可能與其相似。
- 一個在訓練和生成階段對文本編碼的文本編碼器,生成的嵌入作為prior的輸入。
- prior根據(jù)這個嵌入生成圖像嵌入。
- 根據(jù)圖像嵌入生成最終圖像解碼器,其可以選擇是否考慮文本條件。
在訓練階段,圖像編碼器和文本編碼器保持不變,而在生成階段則不再需要圖像編碼器。
5)DALL-E 3
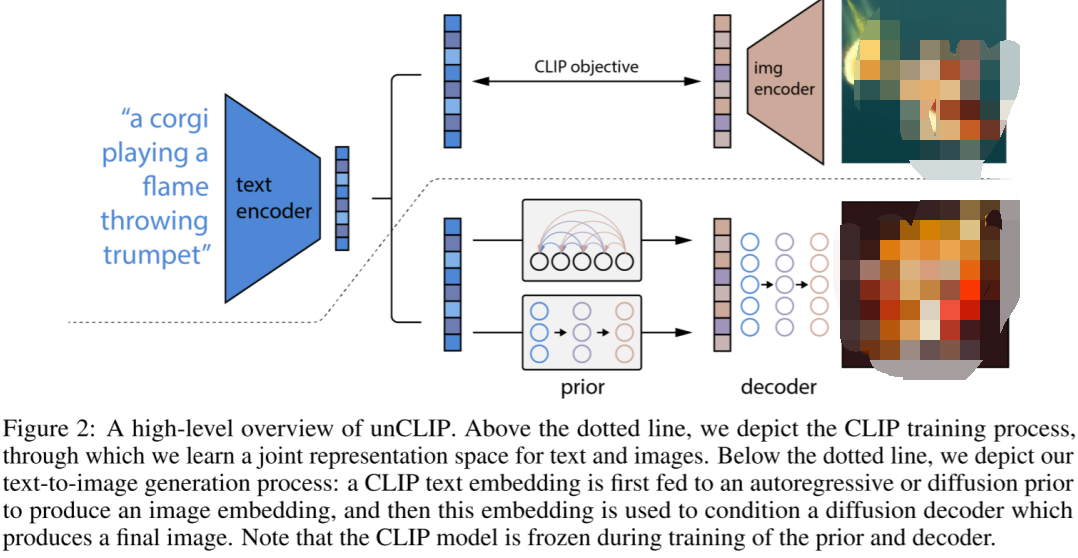
OpenAI的DALL-E 3是一款先進的文生圖模型,針對傳統(tǒng)模型在遵循詳細圖像描述方面的不足進行優(yōu)化。由于傳統(tǒng)模型常常會忽略或混淆語義提示,為解決該問題,需要先訓練一個圖像描述器,并生成一組高度描述性的圖像描述,用于訓練文生圖模型,從而顯著提高模型的指令跟隨能力。
DALL-E 3的圖像解碼器借鑒穩(wěn)定擴散的實現(xiàn),采用一個三階段的隱擴散模型。其VAE和穩(wěn)定擴散相同,都采用8倍的下采樣,訓練的圖像分辨率為256x256,并生成32x32的隱向量。為處理時間步長條件,模型采用GroupNorm并學規(guī)模和偏差。對文本條件的處理,則是使用T5 XXL作為文本編碼器,然后將輸出的embedding和xfnet進行交叉注意。
6)Stable Diffusion(LDM)
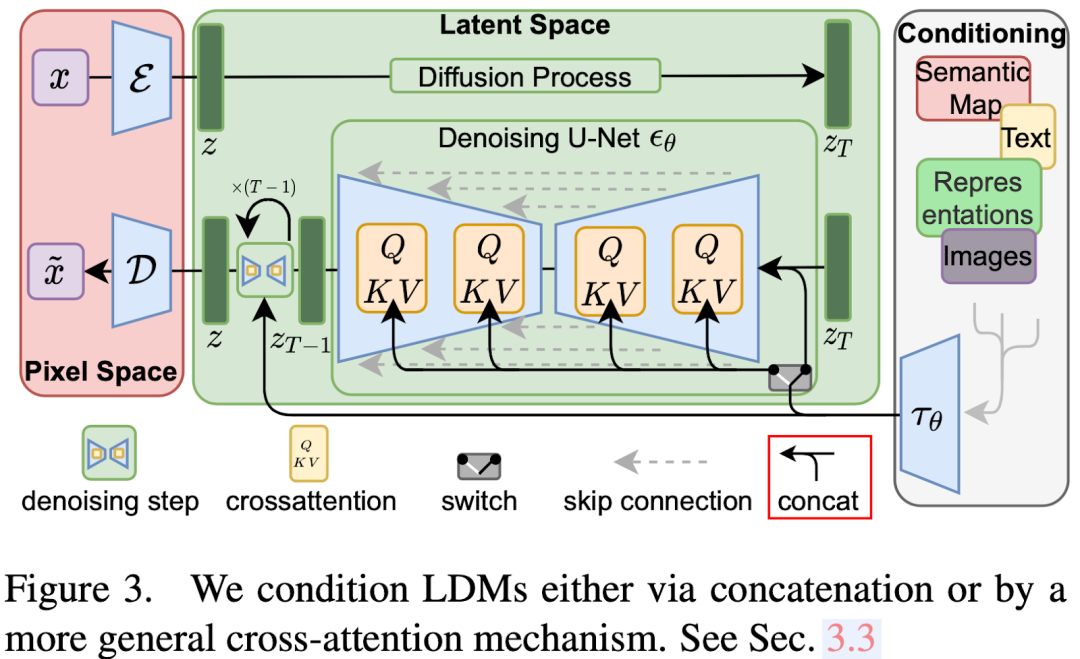
LDM模型與其他擴散生成模型類似,主要由三個部分組成:
-自動編碼器
包括編碼器和解碼器兩部分。編碼器主要用于生成目標z,而解碼器則用于從潛在編碼中恢復圖像。
-調節(jié)部分
用于對各種條件信息進行編碼,其生成的嵌入將在擴散模型U-Net中使用。不同的條件需利用不同的編碼器模型以及使用方法。
-去噪U-Net
該部分主要用于從隨機噪聲zT生成潛在編碼,然后利用解碼器恢復圖像。各種條件信息會通過交叉注意機制進行融合。

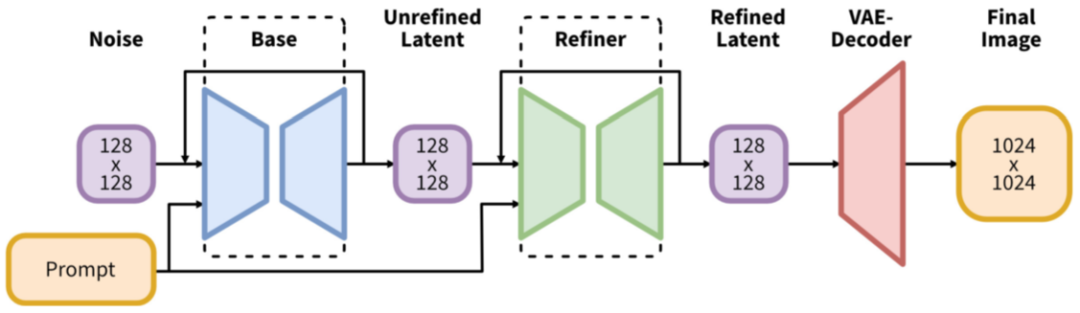
7)SDXL
SDXL模型針對SD模型作出一些關鍵的改進(總參數(shù)量為26億,其中文本編碼器有8.17億的參數(shù)):
- 增加一個Refiner模型,用于進一步精細化圖像。
- 使用兩個文本編碼器,即CLIP ViT-L和OpenCLIP ViT-bigG。
- 基于OpenCLIP的文本嵌入中添加一個匯集文本嵌入。
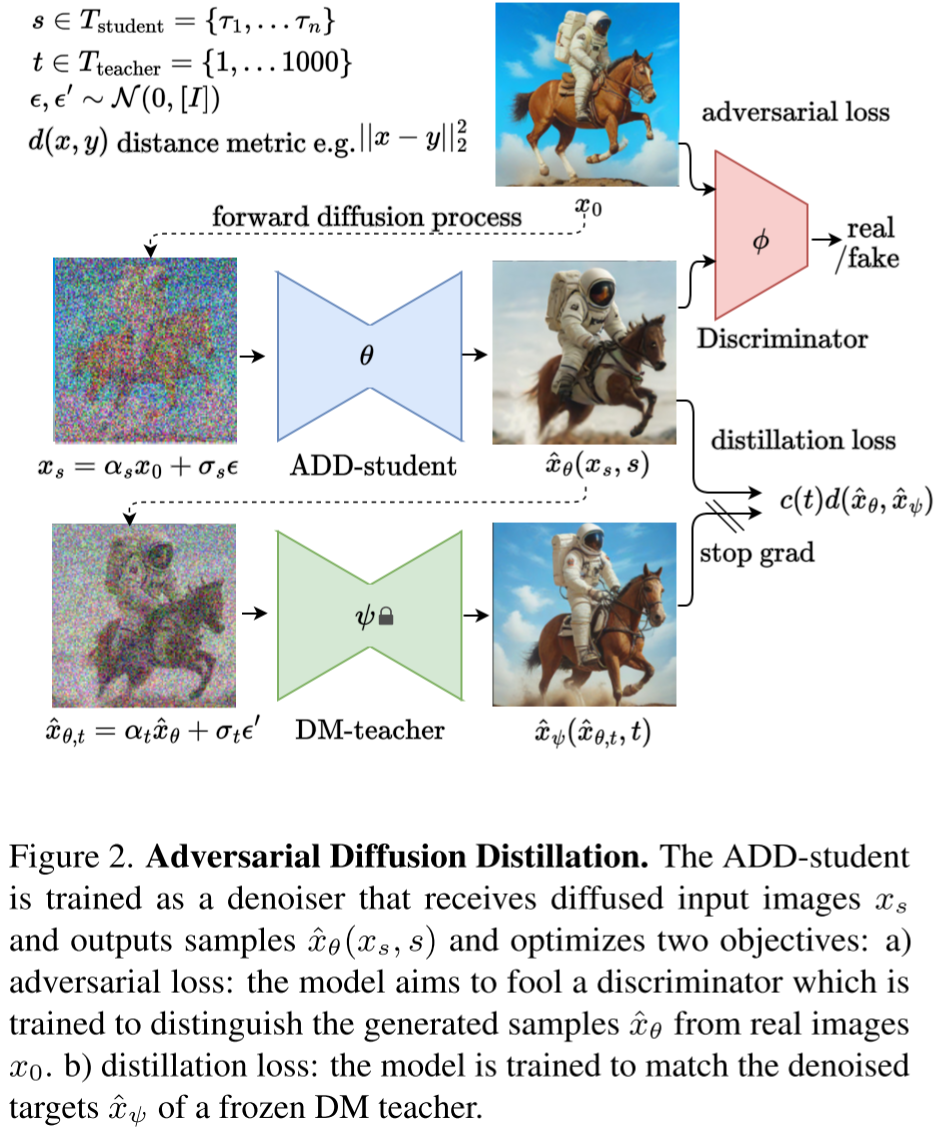
8)SDXL-Turbo
SDXL-Turbo模型的主要改進在于引入蒸餾技術減少生成步數(shù)并提升生成速度。其主要流程包括:
- 從Tstudent模型中選擇步長s進行前向擴散,生成加噪圖像。
- 使用學生模型對加噪圖像進行去噪,得到去噪后的圖像。
- 基于原始圖像和去噪后的圖像計算對抗損失。
- 從Tteacher模型中選擇步長t對去噪后的圖像進行前向擴散,生成新圖像。
- 使用教師模型對新生成的圖像進行去噪,得到新的去噪圖像。
- 基于學生模型和教師模型的去噪圖像計算蒸餾損失。
- 根據(jù)損失進行反向傳播,注意教師模型不會進行更新。
9)Imagen
Google推出的Imagen模型是一個復雜且強大的基于擴散模型的文生圖模型,能生成極其逼真的圖像并深度理解語言。該模型主要由四個部分組成:
- Frozen Text Encoder
將文本進行編碼得到嵌入,經(jīng)過比較后,選擇T5-XXL模型。
- Text-to-Image Diffusion Model
該模塊使用U-Net結構的擴散模型,把步數(shù)t和前一步的文本嵌入作為條件,總共有20億參數(shù)。
- 第一Super-Resolution Diffusion Model
采用優(yōu)化過的高效U-Net,把64x64的圖像超分為256x256的圖像,用文本嵌入作為條件,總共有6億參數(shù)。
- 第二Super-Resolution Diffusion Model
利用優(yōu)化過的高效U-Net,將256x256的圖像超分為1024x1024的圖像,以文本嵌入作為條件,總共有4億參數(shù)。
六、Guidance
1、Class Guidance
在Diffusion Model Beat GANs中,采用額外訓練分類器的Classifier Guidance方式會增加復雜性和成本。這種方法有以下幾個主要問題:
- 需要增訓一個分類器,使生成模型訓練流程變得更復雜。
- 必須在噪聲數(shù)據(jù)上進行分類器的訓練,無法使用已經(jīng)預訓練好的分類器。
- 在采樣過程中,需要進行分數(shù)估計值和分類器梯度的混合,虛假地提高了基于分類器的指標,如FID和IS。
2、Class Free Guidance
Classifier Free Guidance的主要理念是不再采用圖像分類器的梯度方向進行采樣,而是同時訓練有條件和無條件的擴散模型,并將他們的分數(shù)估計混合。通過調整混合權重,實現(xiàn)Classifier Guidance類似的FID和IS平衡。
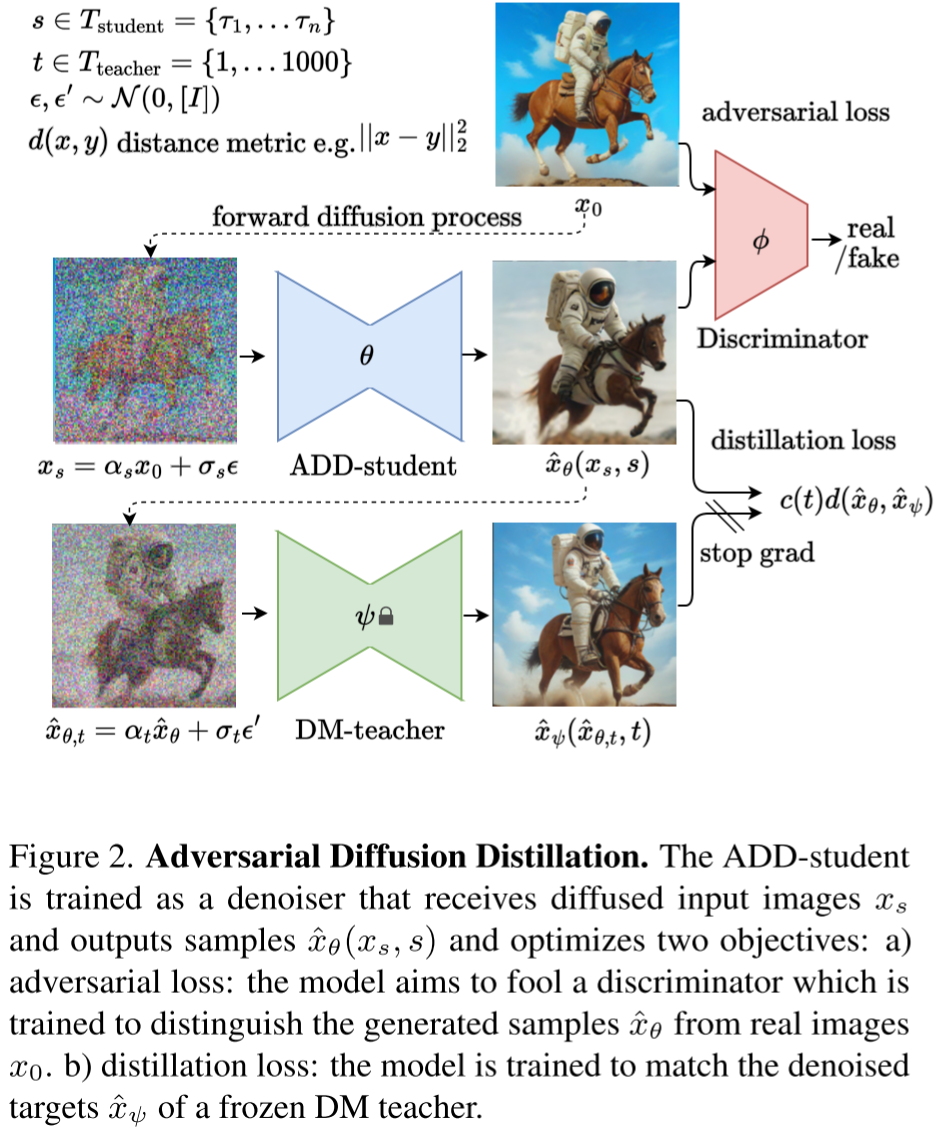
在生成過程中,模型同時使用有條件和無條件生成,并通過權重w來調節(jié)二者的影響:
- 如果w值較大,那么有條件生成的作用就更大,因此生成的圖像看起來更為逼真(IS分數(shù)更高)。
- 如果w值較小,那么無條件生成的作用就更為明顯,從而生成的圖像具有更好的多樣性(FID分數(shù)更低)。

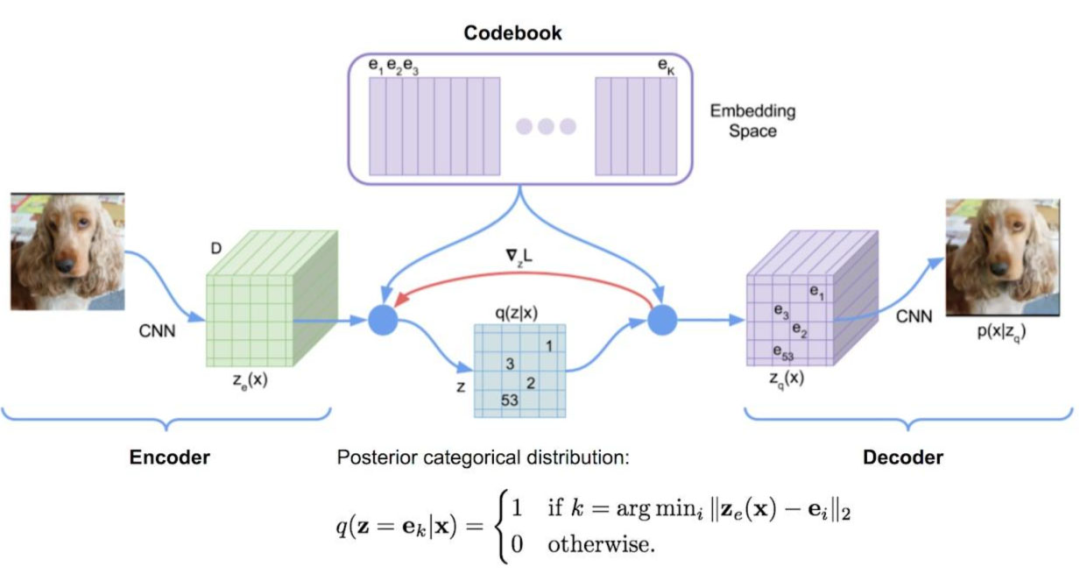
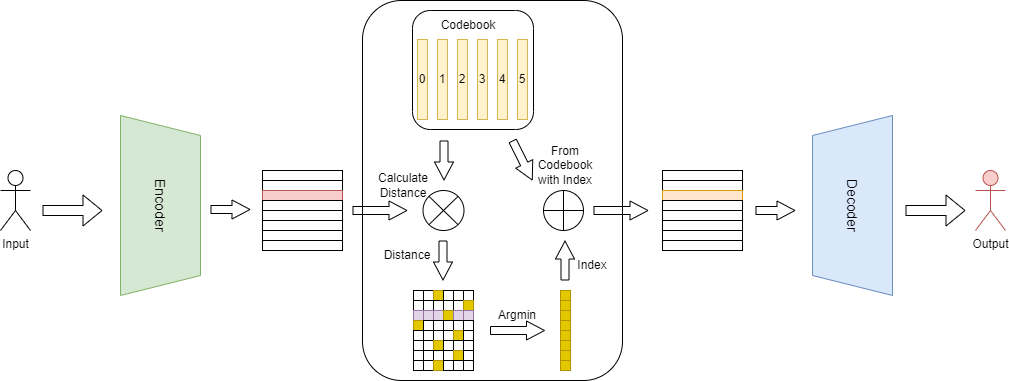
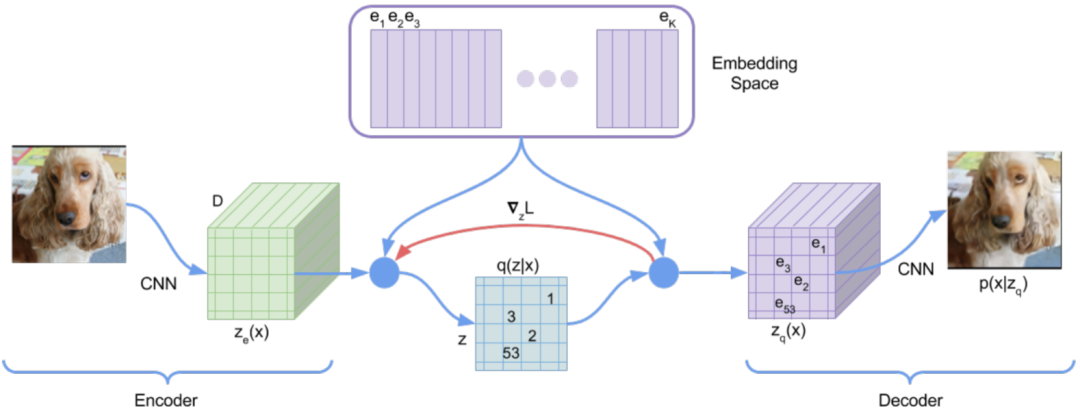
七、VQ-VAE 不可導
1、梯度拷貝
VQ-VAE和VAE結構相似,只是VQ-VAE在中間部分使用VQ(矢量量化)來學習碼本,而非學習概率分布。然而,在VQ中為獲取距離最小值,使用非微分的Argmin操作,就造成無法聯(lián)合訓練解碼器和編碼器的問題。為解決這個問題,可以采取直接將量化后的表示梯度復制到量化前表示,使其可以持續(xù)進行微分。
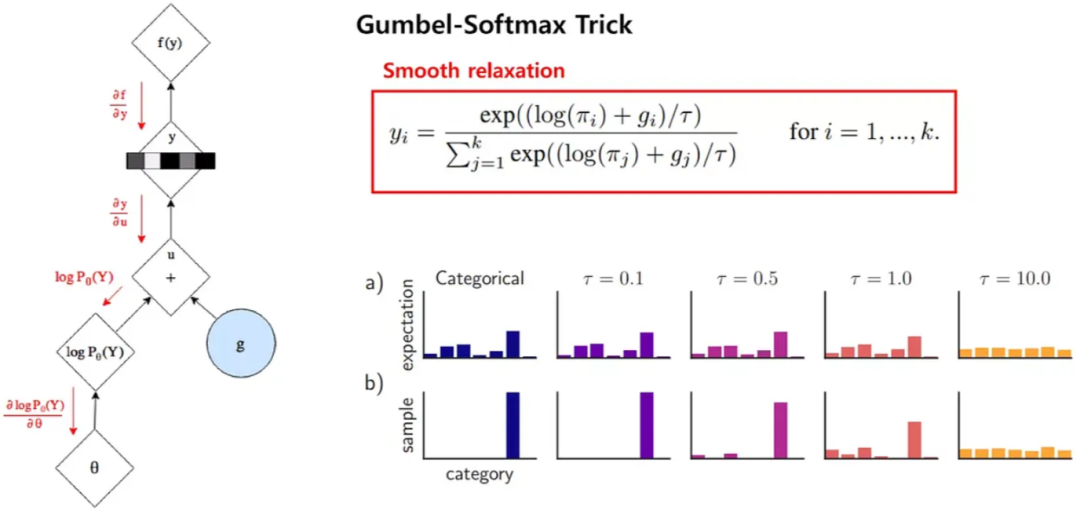
2、Gumbel Softmax
Gumbel Softmax是一種將離散采樣問題轉化為可微分操作的技巧,廣泛應用于深度學習中的生成模型,如VAE和GAN等。Gumbel Softmax運用Gumbel分布來模擬離散分布的采樣,具體來說,它生成一組噪聲樣本,然后用Softmax函數(shù)將這些樣本映射為類別分布。
表現(xiàn)在圖像中,一個圖像經(jīng)過編碼器編碼后會生成32x32個嵌入向量,與碼本(8192個)進行內積,再經(jīng)過Softmax函數(shù)處理,就落實每個碼本向量的概率。
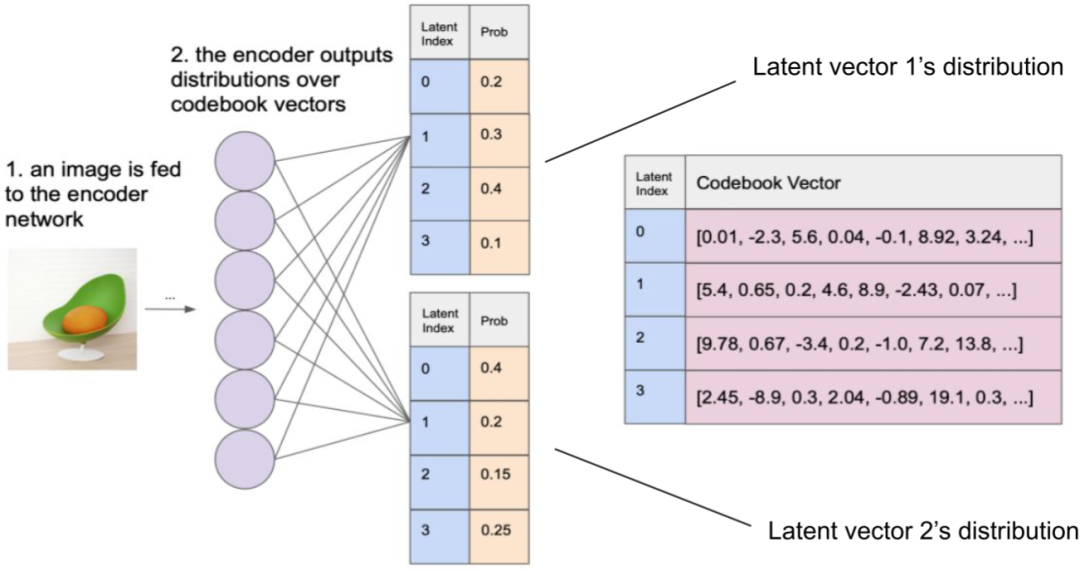
通過應用Gumbel Softmax采樣,得到新的概率分布。再以此作為權重,累加對應的碼本向量,獲得潛在向量。然后,解碼器基于潛在向量來重建輸出圖像。
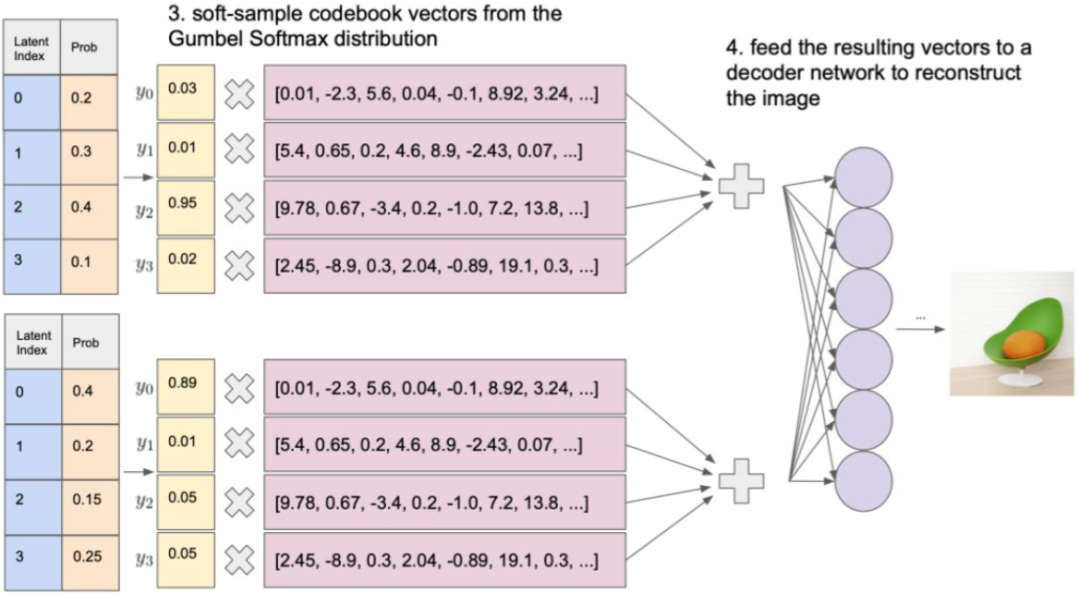
上述過程中,使用Gumbel噪聲實現(xiàn)離散采樣,能夠近似選擇概率最大的類別,為處理離散采樣問題提供一種可微分的解決方案。其中,gi是從Gumbel(0, 1)分布中得到的噪聲,τ是溫度系數(shù)。τ小的時候,Softmax函數(shù)更接近ArgMax,而τ大時,更接近于均勻分布。
八、擴大分辨率
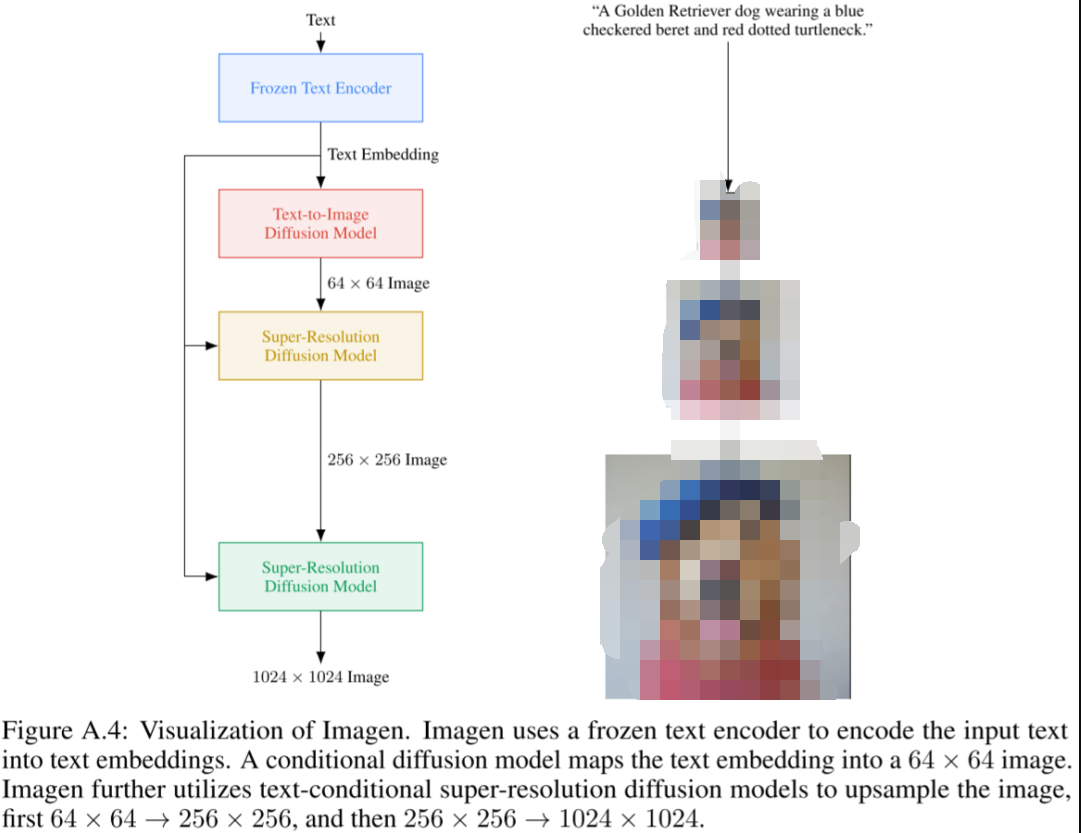
1、圖像超分
圖像超分是提高圖像分辨率的有效手段,被很多熱門的圖像生成模型,像Imagen、Parti、Stable Diffusion、DALL-E等所采用。就像圖Figure A.4所展示,Imagen使用兩個圖像超分模型,將分辨率從64x64提升到256x256,然后再進一步提升到1024x1024。
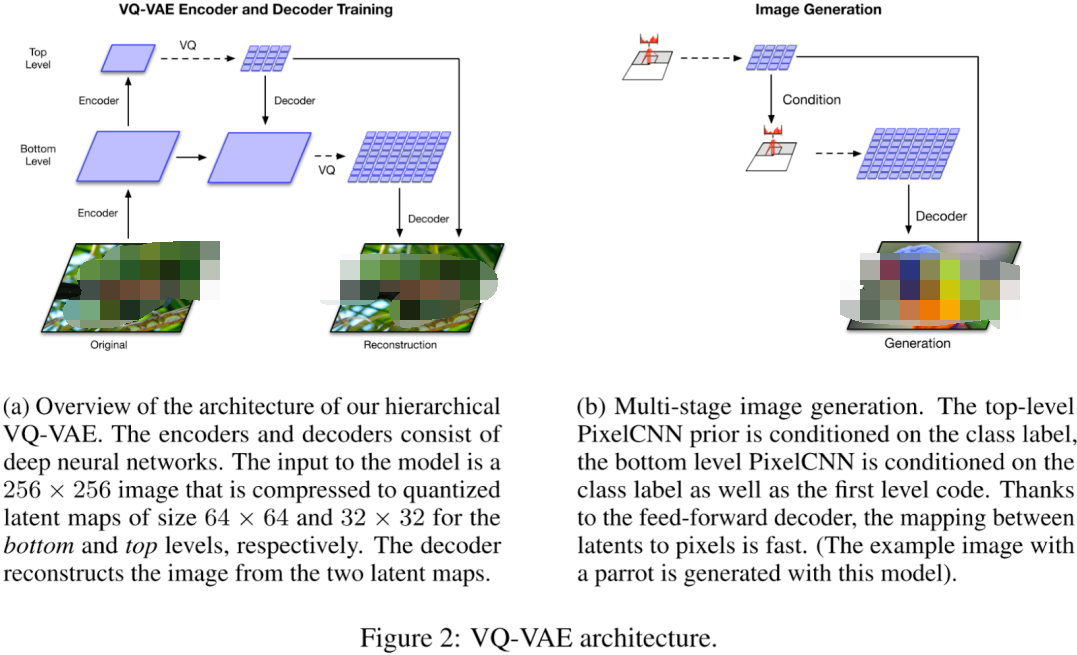
2、多級 Latent code
在VQ-VAE-2模型中,采用多級潛在編碼方案。以256x256的圖像為例,在訓練階段,圖像首先被編碼壓縮到64x64大小的底層,然后進一步壓縮到32x32大小的頂層。重建階段,32x32的表征通過VQ量化轉換為潛在編碼,然后通過解碼器重建為64x64的壓縮圖像,再進一步通過VQ和解碼器重建為256x256大小的圖像。而在推理階段,首先使用PixelCNN生成頂層的離散潛在編碼,然后作為輸入條件生成更高分辨率的底層離散潛在編碼。
3、多級 Latent code + 圖像超分
在Muse模型中,直接預測512x512分辨率的圖像可能會過度關注低級細節(jié),而采用級聯(lián)模型更有效。模型首先生成16x16的潛在地圖(對應256x256分辨率的圖像),然后基于這個潛在地圖使用超分模型采樣到64x64的潛在地圖(對應512x512分辨率的圖像)。
訓練分為兩階段,首先訓練Base模型生成16x16的潛在地圖;然后基于此訓練超分模型,用于生成64x64的潛在地圖和最終的512x512圖像。
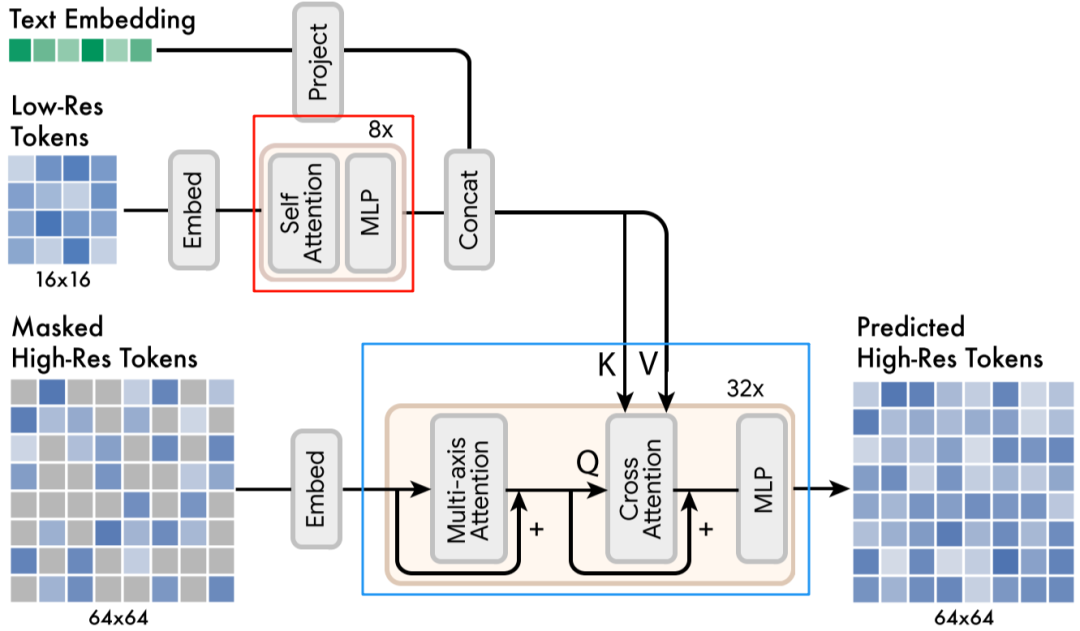
九、指令遵循
1、更大的 Text Encoder
在Imagen模型中,擴大語言模型的規(guī)模比增大圖像擴散模型的規(guī)模更能提高生成樣本的逼真度和圖像-文本的對齊效果。
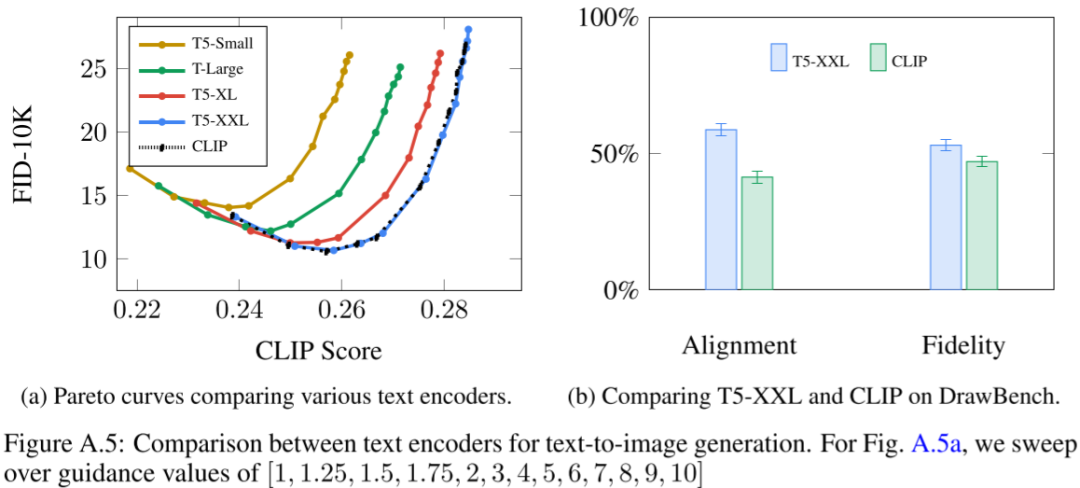
2、多個 Text Encoder
在SDXL模型中,為增強文本編碼能力,采用兩個文本編碼器,具體來說,同時使用CLIP ViT-L和OpenCLIP ViT-bigG中的文本編碼器。

3、數(shù)據(jù)增強
OpenAI的新模型DALL-E 3是一款文本生成圖像模型,解決傳統(tǒng)模型不能精準遵循圖像描述和忽視或混淆語義提示的問題。
十、效率優(yōu)化
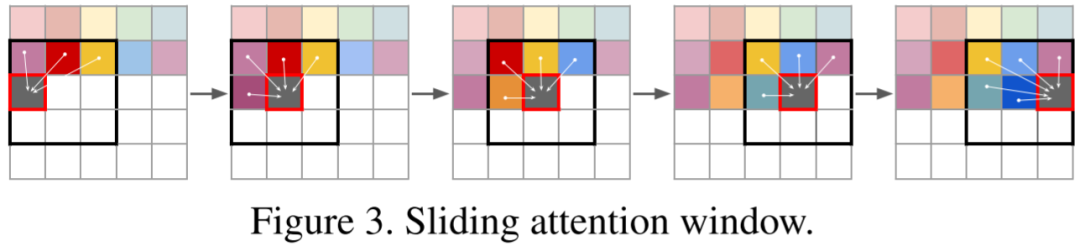
1、滑動窗口 Attention
在VQ-GAN模型中,自回歸Transformer模型用于預測離散的latent code,然后通過解碼器使用latent code恢復圖像。通常離散latent code相比原始圖像有16x16或8x8的壓縮率。例如要生成一個分辨率為1024x1024的圖像,相應的離散latent code為64x64。但是,由于Transformer模型的推理計算量與序列長度成二次方關系,計算量較大。具體來說,預測每個位置的code時只考慮局部code,而不是全局code,例如使用16x16的窗口,計算量將降低到原來的1/16。對于邊界區(qū)域,將窗口向圖像中心偏移,以保持窗口大小。
2、Sparse Transformer
在DALL-E中,采用參數(shù)量達到12B的Sparse Transformer,利用三種不同的注意力遮罩來加速推理過程。這些注意力遮罩保證所有的圖像令牌都可以觀察到所有的文本令牌,但只能觀察到部分圖像令牌。具體來說,行注意力用于(i-2)%4不等于0的層,如第2層和第6層,列注意力用于(i-2)%4等于0的層,如第1層和第3層,而卷積性注意力則僅在最后一層使用。

3、Efficient U-Net
在Imagen中,在兩個超分辨模型中使用高效的U-Net。具體調整包括:在低分辨率添加更多殘差塊,將高分辨率的模型參數(shù)轉移到低分辨率,從而增加模型容量,但無需更多計算和內存;使用大量低分辨率殘差塊時,將Skip connection縮放到1/sqrt(2),以提升收斂速度;將下采樣和上采樣塊的順序交換,以提高前向傳播速度,且不降低性能。同時,在256x256至1024x1024的超分模型中,刪除自注意力模塊,僅保留交叉注意力模塊。
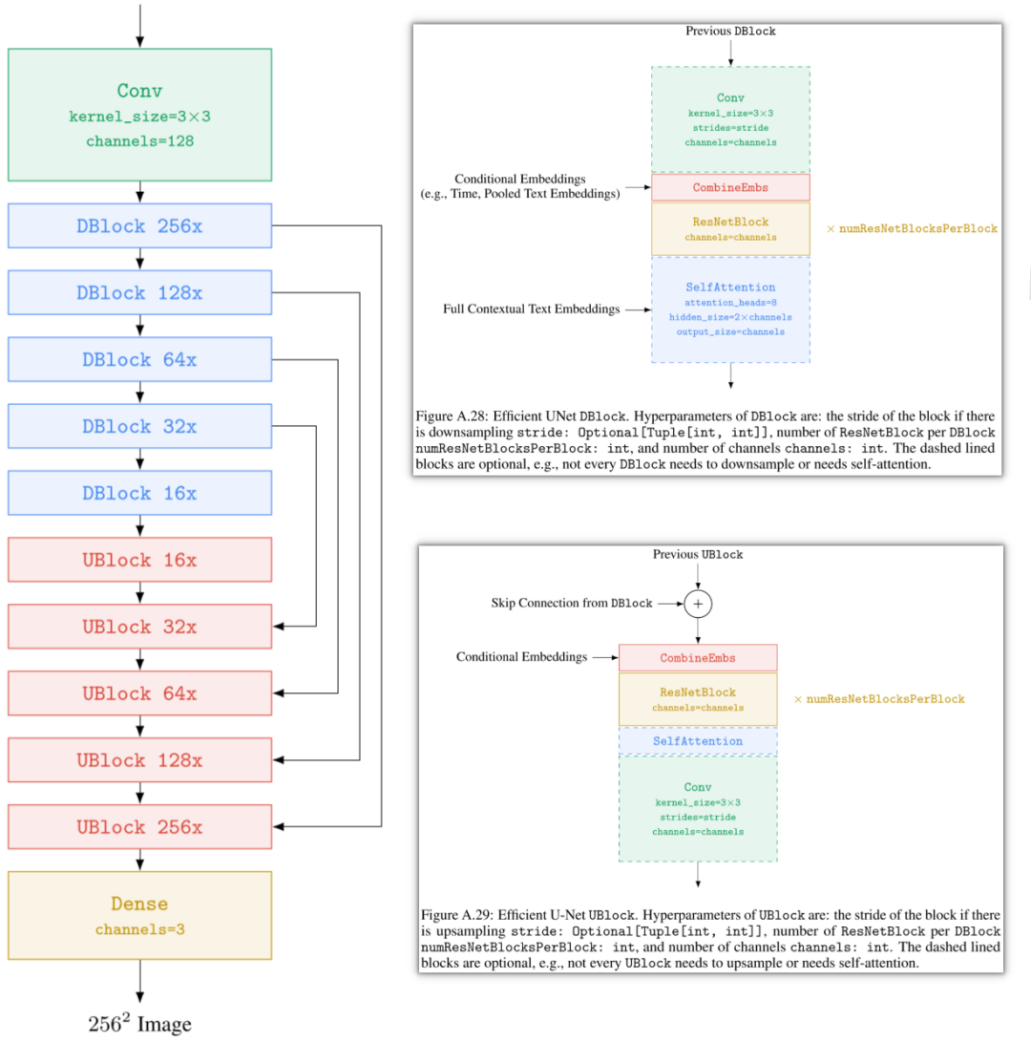
4、并行解碼-推理效率
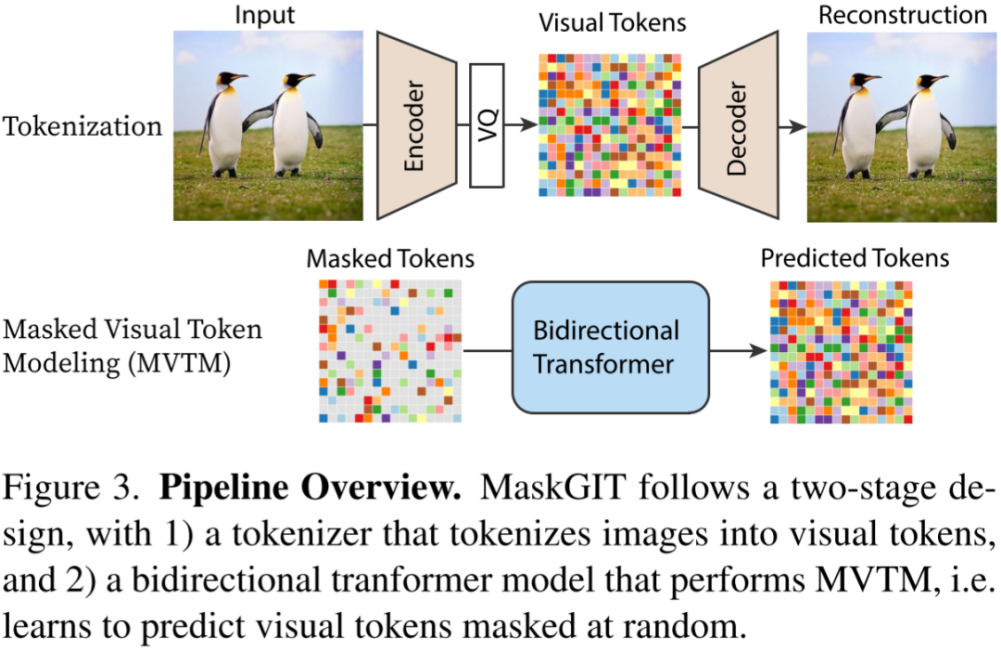
Google在圖像生成模型MaskGIT和Muse中采用并行解碼的策略,與VQGAN中使用的序列解碼方式不同,該并行解碼方案只需要8個解碼步驟就能生成16x16=256個圖像token,相比之下,VQGAN需要256次解碼才能生成同樣數(shù)量的token。
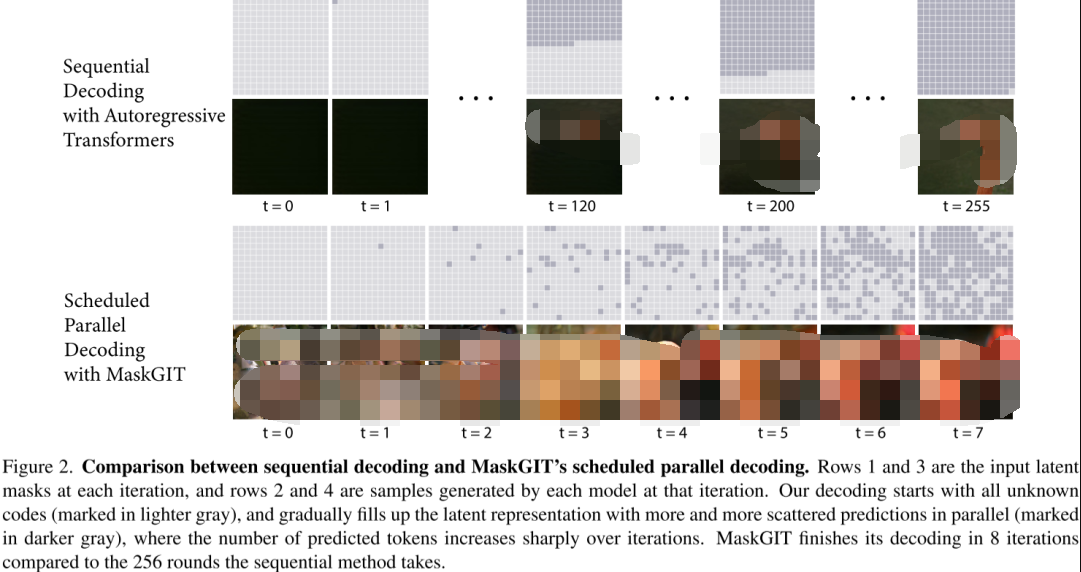
并行解碼過程主要包括四個步驟:
- Predict
給定一個遮罩的token序列(已確定的token未被遮罩,待生成的token被遮罩)的情況下,預測每個token位置可能的token概率。
- Sample
在每個遮罩的token位置執(zhí)行采樣,采樣后的概率直接作為token的置信度,而已生成的token的置信度則為1。
- Mask Schedule
根據(jù)遮罩調度函數(shù)、當前步數(shù)、總步數(shù)以及總token數(shù),計算當前需要采納的token數(shù)。
- Mask
根據(jù)Sample步驟獲得的置信度以及Mask Schedule步驟得到的待采納的token數(shù),對置信度進行排序,并采納置信度最高的token。
5、子圖訓練-訓練效率
當前圖像生成模型處理的圖像越來越大,計算量因此呈指數(shù)級增長,同時需要在大型數(shù)據(jù)集上進行訓練,進一步增大成本。因此一些優(yōu)化方案應運而生。例如,在LDM中利用全卷積網(wǎng)絡支持可變分辨率的特性,選擇在較小分辨率上訓練,但在推理時應用在較大分辨率。此外,如Imagen和DALL-E 2等后續(xù)工作也采用相似策略,主要應用在超分辨模型。以Imagen為例,在訓練超分辨模型時,移除自注意力功能,僅在文本嵌入融合時使用交叉注意力;同時,從高分辨率圖像中裁剪出低分辨率的子圖進行訓練,從而大大提高效率。
6、Denoising蒸餾-推理效率
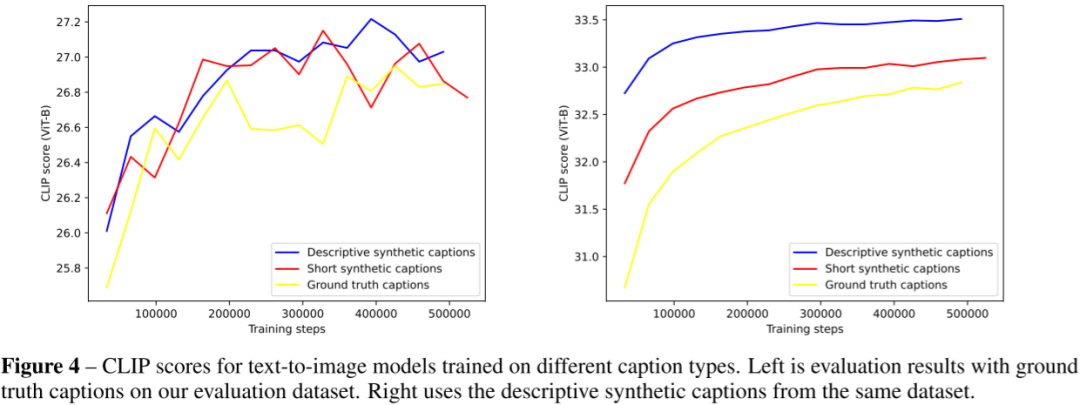
由于擴散模型需要大量迭代來生成滿意結果,對資源消耗極大,因此有研究者試圖減少生成步驟以提高生成速度。例如,DPM Solver通過大幅降低迭代步數(shù),實現(xiàn)4到16倍的加速。OpenAI的Consistency Models進一步將迭代步數(shù)降至1到4步,其后的LCM和LCM-LoRA(Latent Consistency Models)也沿用這一策略。在SDXL-Turbo中,將迭代步數(shù)進一步減至1到4步甚至只需要1步,也可以得到優(yōu)秀的生成結果。在與各種蒸餾方案的比較中,作者的方法在只需一步的情況下就能獲得最優(yōu)的FID和CLIP得分。
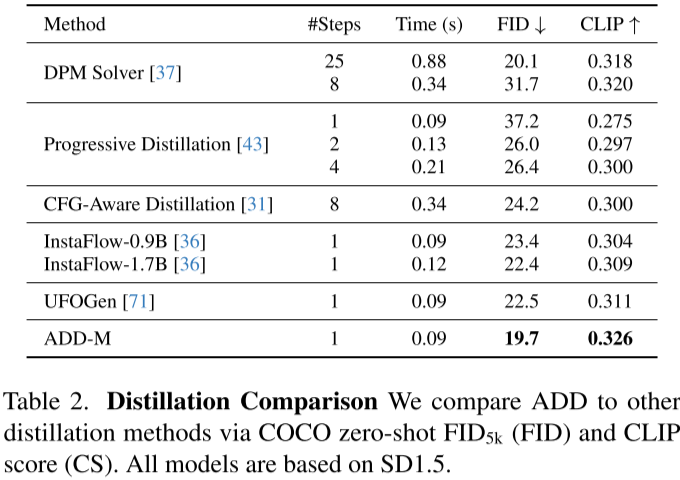
十一、局限性
1、場景內文本
DALL-E 2的作者發(fā)現(xiàn)模型在圖像生成正確文本方面存在問題,可能是由于BPE文本編碼的問題。然而,Google的Parti和Imagen 2已經(jīng)比較有效地解決了這個問題。
2、細節(jié)、空間位置、屬性關聯(lián)
模型在處理物體的細節(jié)和空間關系時,往往出現(xiàn)錯誤且容易混淆不同物體。例如,處理手指細節(jié)時常有錯誤;在設計lion和giraffe在電視里的任務時,位置未能準確控制;在請求將長凳設置為白色時,鋼琴也被誤設為白色;要求車門為白色時,錯誤地在引擎蓋等位置生成白色。
在DALL-E 2中,如圖Figure 15所示,模型可能會混淆不同物體的顏色,如在“創(chuàng)建一個紅色的方塊在藍色的方塊之上”的任務上,無法完成顏色屬性的準確賦予。另外,模型可能在重建對象的相對大小關系上存在問題,這可能是由于使用CLIP模型的影響。
十二、其他
1、BSR 退化
許多模型在超分模型訓練中采用BSR退化技術,如Stable Diffusion和DALL-E 2等模型。BSR退化流程包括JPEG壓縮噪聲、相機傳感器噪聲,下采樣的不同圖像插值方法,以及高斯模糊核和高斯噪聲,這些處理按隨即順序對圖像進行應用。具體的退化方式和順序可以在提供的代碼鏈接中找到。
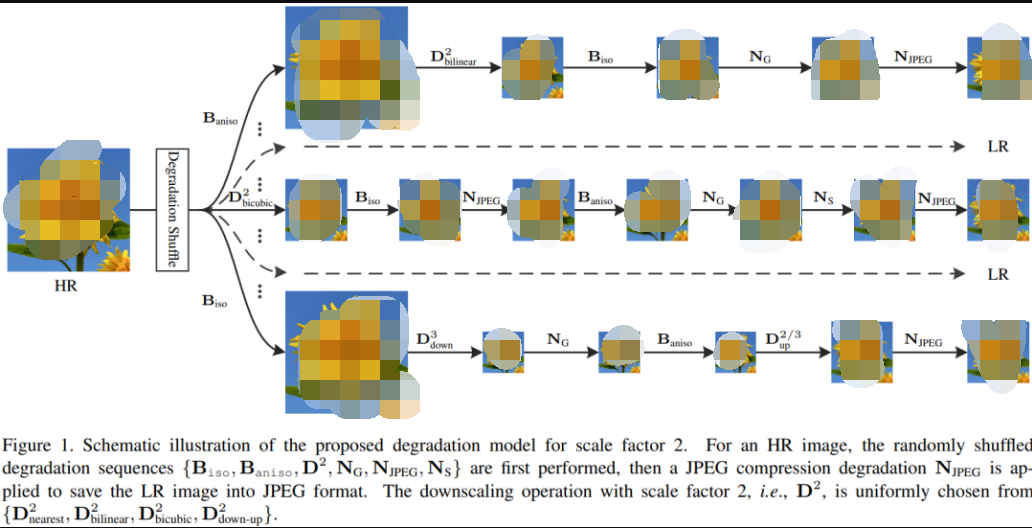
2、采樣+排序
模型在生成圖像的過程中都有一定隨機性,因此每次采樣生成的圖像可能不一樣,因此就有工作嘗試每次多生成幾個圖像,然后挑選和文本最匹配的輸出,比如 DALL-E mini,每次都生成多個圖像,然后通過 CLIP Score 獲得最匹配的一個。
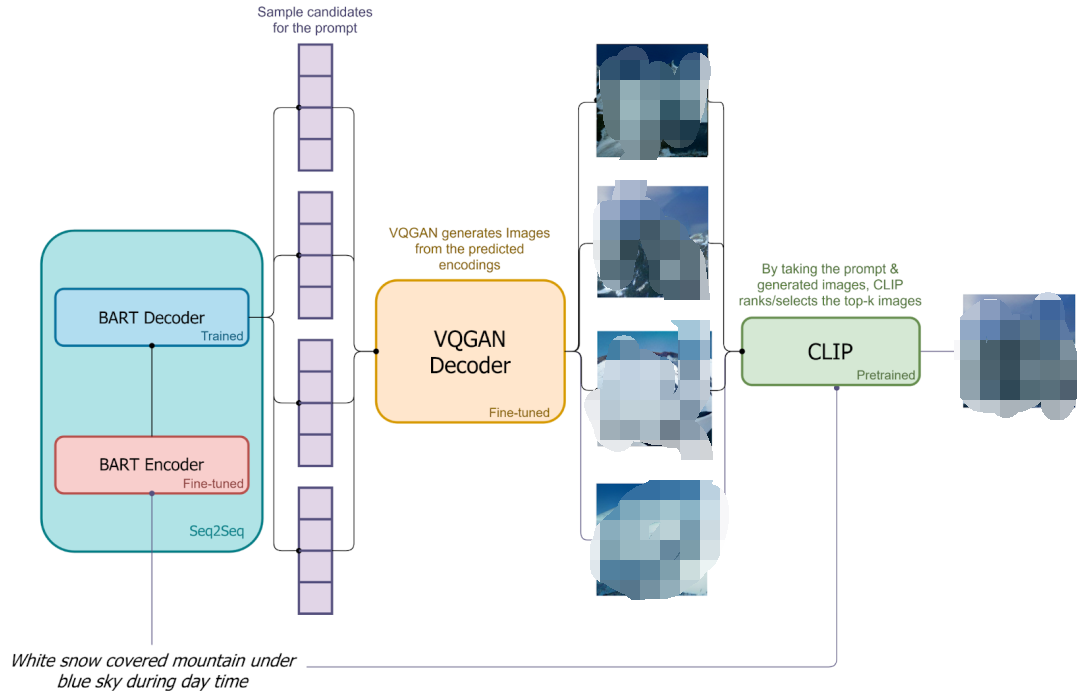
在 DALL-E 2 中,為提升采樣階段的生成質量,會同時生成兩個圖像 embedding zi,然后選擇一個與文本 embedding zt 內積更大的(相似性更高)使用。
3、多分辨率訓練
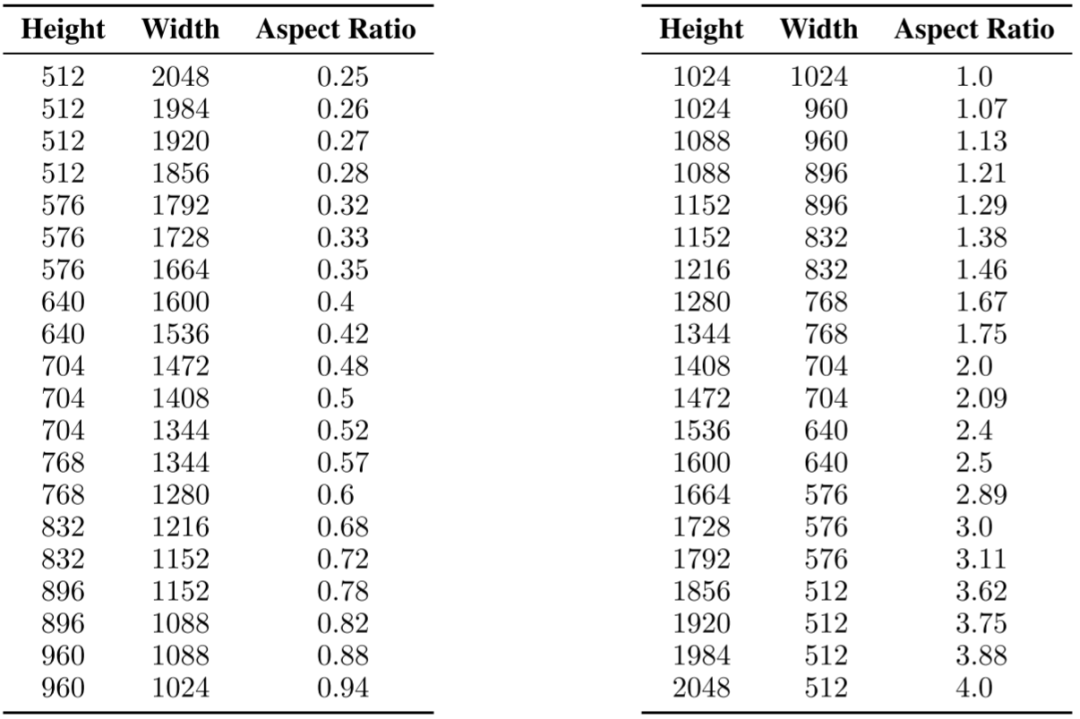
在SDXL中,對模型進行微調,以適應不同的長寬比,應對真實世界圖像的多樣性。首先將數(shù)據(jù)劃分為不同長寬比的桶,保證總像素接近1024x1024,同時高寬需是64的整數(shù)倍。在訓練時,每次從相同類型的桶里選擇一個批次,并在不同的桶中輪流進行。還將桶的高度和寬度(h, w)作為條件,通過傅立葉編碼后,添加到時間步驟嵌入中。
藍海大腦集成StableDiffusion
PC集群解決方案
AIGC和ChatGPT4技術的爆燃和狂飆,讓文字生成、音頻生成、圖像生成、視頻生成、策略生成、GAMEAI、虛擬人等生成領域得到了極大的提升。不僅可以提高創(chuàng)作質量,還能降低成本,增加效率。同時,對GPU和算力的需求也越來越高,因此GPU服務器廠商開始涌向該賽道,為這一領域提供更好的支持。在許多領域,如科學計算、金融分析、天氣預報、深度學習、高性能計算、大模型構建等領域,需要大量的計算資源來支持。為了滿足這些需求,藍海大腦PC集群解決方案應運而生。
PC集群是一種由多臺計算機組成的系統(tǒng),這些計算機通過網(wǎng)絡連接在一起,共同完成計算任務。PC集群解決方案是指在PC集群上運行的軟件和硬件系統(tǒng),用于管理和優(yōu)化計算資源,提高計算效率和可靠性。
藍海大腦PC集群解決方案提供高密度部署的服務器和PC節(jié)點,采用機架式設計,融合PC高主頻和高性價比以及服務器穩(wěn)定性的設計,實現(xiàn)遠程集中化部署和便捷運維管理。采用模塊化可插拔設計,簡化維護和升級的流程。有效降低網(wǎng)絡延遲,提高游戲的流暢性。GPU圖像渲染加速,減少畫面卡頓和延遲。同時動態(tài)調度算法,實現(xiàn)負載均衡;大幅降低運營成本。高品質的游戲體驗增加用戶的粘度,大大提升游戲運營商收益。
同時,集成Stable Diffusion AI模型,可以輕松地安裝和使用,無需進行任何額外的配置或設置。與傳統(tǒng)的人工創(chuàng)作方式相比,Stable Diffusion Al模型可以更快地生成高品質的創(chuàng)作內容。通過集成這個模型,可以使創(chuàng)作者利用人工智能技術來優(yōu)化創(chuàng)作流程。另外,藍海大腦PC集群解決方案還具有開箱即用的特點,不僅易于安裝和使用,而且能夠快速適應各種創(chuàng)作工作流程。這意味著用戶可以在短時間內開始創(chuàng)作,并且在整個創(chuàng)作過程中得到更好的體驗。

一、客戶收益
Stable Diffusion技術對游戲產業(yè)帶來了極大的影響和改變。它提升了游戲圖像的質量和真實感、增強了游戲體驗和沉浸感、優(yōu)化了游戲制作流程、擴展了游戲應用領域,并推動了游戲產業(yè)的發(fā)展和創(chuàng)新。這些都表明,Stable Diffusion技術在游戲產業(yè)中的應用前景十分廣闊,有助于進一步推動游戲行業(yè)的發(fā)展,提高用戶體驗和娛樂價值。
1、提升游戲圖像質量和真實感
Stable Diffusion可以在保證渲染速度的前提下,提高游戲圖像的細節(jié)和真實感。傳統(tǒng)的光線追蹤方法需要檢查和模擬每條光線,這樣會消耗大量計算資源,并放緩渲染速度。而Stable Diffusion則利用深度學習技術對光線的擴散過程進行建模,使得處理數(shù)百萬條光線所需的計算時間更短,同時還能夠生成更為精準的光線路徑。這意味著,Stable Diffusion可以讓計算機產生更加逼真的景觀、人物、物品等元素,在視覺效果上得到質的飛躍。
2、增強游戲體驗和沉浸感
游戲是一個交互式體驗,它的目標是盡可能地讓玩家沉浸到虛構的世界中。Stable Diffusion可以使游戲環(huán)境變得更加真實,并增添一些更具有交互性和觀賞性的場景。例如,利用Stable Diffusion技術,游戲可以在水面上添加波紋、落葉,或者使搖曳的草叢更逼真。這些改善能夠讓玩家更好地感受游戲中所處的環(huán)境,增強沉浸感。
3、優(yōu)化游戲制作流程
Stable Diffusion的應用可以提高游戲開發(fā)的效率和質量,減少手動制作和修改的工作量。渲染過程的快速執(zhí)行還可以加速開發(fā)周期,甚至使一些在過去被看做是計算機圖形學難題的事情變得可能。例如,在模擬復雜的自然現(xiàn)象或在大范圍內生成游戲元素時,使用Stable Diffusion可有效降低游戲開發(fā)的成本和時間,讓開發(fā)者有更多的精力關注其他方面的設計和創(chuàng)意。
4、擴展游戲的應用領域
Stable Diffusion的應用使得游戲在更多的領域得到應用。例如,在心理治療、教育、文化傳播等領域中,人工智能游戲可以根據(jù)用戶的情緒和行為變化來調整游戲內容和策略,為用戶提供更符合需求和娛樂性的游戲體驗。此外,利用Stable Diffusion技術,游戲可以生成不同類型的場景,包括虛擬現(xiàn)實和增強現(xiàn)實等體驗,開發(fā)出更豐富更多變的游戲內容。
5、推動游戲產業(yè)的發(fā)展和創(chuàng)新
Stable Diffusion作為先進的計算機圖形學技術之一,進一步推動了游戲產業(yè)的發(fā)展和創(chuàng)新。利用人工智能技術渲染的游戲將會產生更高品質、更廣泛的游戲類別,從而吸引更多領域的玩家參與,并且會推動相關行業(yè)的發(fā)展,如文化傳媒行業(yè)、數(shù)字娛樂業(yè)等。同時,穩(wěn)定性更好、性能更高的Stable Diffusion技術還具有在未來制造更復雜的虛擬世界的潛力,例如更多樣化、更逼真、更具交互性的虛擬現(xiàn)實環(huán)境和游戲。
二、PC集群解決方案的優(yōu)勢
1、高性能
PC集群解決方案可將多臺計算機的計算能力整合起來,形成一個高性能的計算系統(tǒng)。可支持在短時間內完成大量的計算任務,提高計算效率。
2、可擴展性
可以根據(jù)需要進行擴展,增加計算節(jié)點,提高計算能力。這種擴展可以是硬件的,也可以是軟件的,非常靈活。
3、可靠性
PC集群可以通過冗余設計和備份策略來提高系統(tǒng)的可靠性。當某個節(jié)點出現(xiàn)故障時,其他節(jié)點可以接管其任務,保證計算任務的順利進行。
4、低成本
相比于傳統(tǒng)的超級計算機,PC集群的成本更低。這是因為PC集群采用的是普通的PC硬件,而不是專門的高性能計算硬件。
三、PC集群解決方案的應用領域有哪些?
PC集群是指將多臺個人電腦連接在一起,通過網(wǎng)絡協(xié)同工作,實現(xiàn)高性能計算的一種方式。它的應用領域非常廣泛,以下是一些常見的應用領域:
1、科學計算
PC集群可以用于各種科學計算,如天文學、生物學、物理學、化學等領域的計算模擬和數(shù)據(jù)分析。
2、工程計算
PC集群可以用于工程領域的計算,如飛機設計、汽車設計、建筑結構分析等。
3、金融計算
PC集群可以用于金融領域的計算,如股票交易、風險評估、投資組合優(yōu)化等。
4、大數(shù)據(jù)處理
PC集群可以用于大數(shù)據(jù)處理,如數(shù)據(jù)挖掘、機器學習、人工智能等領域的數(shù)據(jù)處理和分析。
5、圖像處理
PC集群可以用于圖像處理,如視頻編碼、圖像識別、虛擬現(xiàn)實等領域的圖像處理和渲染。
四、常用配置推薦
1、處理器CPU:
i9-13900 24C/32T/2.00GHz/32MB/65W
i7-13700 16C/24T/2.10GHz/30MB/65W
i5 13400 10C/16T/1.80GHz/20MB/65W
i3 13100 4C/8T/3.40GHz/12MB/60W
G6900 2C/2T/3.40GHz/4MB/46W
G7400 2C/4T/3.70GHz/6MB/46W
i3 12100 4C/8T/3.30GHz/12MB/60W
i5 12400 6C/12T/2.50GHz/18MB/65W
i7 12700 12C/20T/2.10GHz/25MB/65W
i9 12900 16C/24T/2.40GHz/30MB/65W
2、顯卡GPU:
NVIDIA RTX GeForce 3070 8GB
NVIDIA RTX GeForce 3080 10GB
NVIDIA RTX GeForce 4070 12GB
NVIDIA RTX GeForce 4060Ti 8GB or 16GB
3、內存:
32GB×2
4、系統(tǒng)盤:
M.2 500GB
5、數(shù)據(jù)盤:
500GB 7200K
審核編輯 黃宇
-
芯片
+關注
關注
459文章
52145瀏覽量
435951 -
顯示器
+關注
關注
21文章
5058瀏覽量
141343 -
CES
+關注
關注
4文章
1134瀏覽量
71728 -
AI
+關注
關注
87文章
34146瀏覽量
275301 -
英偉達
+關注
關注
22文章
3920瀏覽量
93091
發(fā)布評論請先 登錄
英碼科技精彩亮相火爆的IOTE 2023,多面賦能AIoT產業(yè)發(fā)展!
OpenAI推出兩套多模態(tài)人工智能系統(tǒng)模型
AI新模型可將文本轉換為生動的圖像
給一個文本提示就能生成3D模型!
DALL-E 2的錯誤揭示出人工智能的局限性
DALL-E和生成式AI的未來
AIGC能掀起人工智能的產業(yè)革命嗎?
語音領域的GPT時刻:Meta 發(fā)布「突破性」生成式語音系統(tǒng),一個通用模型解決多項任務
伯克利AI實驗室開源圖像編輯模型InstructPix2Pix,簡化生成圖像編輯并提供一致結果
【AI簡報20230922期】華人AI芯片挑戰(zhàn)英偉達,深入淺出理解Transformer

OpenAI發(fā)布第三版DALL-E
【AI簡報20231020期】出自華人之手:DALL-E 3論文公布、上線ChatGPT!超火迷你GPT-4






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論