 基于TensorFlow和Keras的圖像識別
基于TensorFlow和Keras的圖像識別

來源:深度學習愛好者
簡介
TensorFlow和Keras最常見的用途之一是圖像識別/分類。通過本文,您將了解如何使用Keras達到這一目的。
定義
如果您不了解圖像識別的基本概念,將很難完全理解本文的內容。因此在正文開始之前,讓我們先花點時間來了解一些術語。
TensorFlow/Keras
TensorFlow是Google Brain團隊創建的一個Python開源庫,它包含許多算法和模型,能夠實現深度神經網絡,用于圖像識別/分類和自然語言處理等場景。TensorFlow是一個功能強大的框架,通過實現一系列處理節點來運行,每個節點代表一個數學運算,整個系列節點被稱為“圖”。Keras是一個高級API(應用程序編程接口),支持TensorFlow(以及像Theano等其他ML庫)。其設計原則旨在用戶友好和模塊化,盡可能地簡化TensorFlow的強大功能,在Python下使用無需過多的修改和配置圖像識別(分類)
圖像識別是指將圖像作為輸入傳入神經網絡并輸出該圖像的某類標簽。該標簽對應一個預定義的類。圖像可以標記為多個類或一個類。如果只有一個類,則應使用術語“識別”,而多類識別的任務通常稱為“分類”。
圖像分類的子集是對象檢測,對象的特定實例被識別為某個類如動物,車輛或者人類等。
特征提取
為了實現圖像識別/分類,神經網絡必須進行特征提取。特征作為數據元素將通過網絡進行反饋。在圖像識別的特定場景下,特征是某個對象的一組像素,如邊緣和角點,網絡將通過分析它們來進行模式識別。
特征識別(或特征提取)是從輸入圖像中拉取相關特征以便分析的過程。許多圖像包含相應的注解和元數據,有助于神經網絡獲取相關特征。
神經網絡如何學習識別圖像
直觀地了解神經網絡如何識別圖像將有助于實現神經網絡模型,因此在接下來的幾節中將簡要介紹圖像識別過程。
使用濾波器進行特征提取
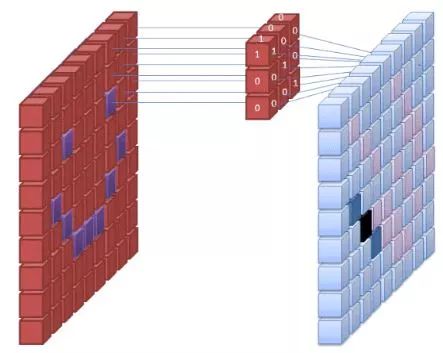
圖片來源:commons.wikimedia.org
神經網絡的第一層接收圖像的所有像素。當所有的數據傳入網絡后,將不同的濾波器應用于圖像,構成圖像不同部分的表示。這是特征提取,它創建了“特征映射”。
從圖像中提取特征的過程是通過“卷積層”完成的,并且卷積只是形成圖像的部分表示。由卷積的概念延伸出卷積神經網絡(CNN)這一術語,它是圖像分類/識別中最常用的神經網絡類型。
如果您無法想象特征映射是如何創建的,可以試想將手電筒照在暗室圖片的景象。當光束滑過圖片時,您正在學習圖像的特征。在這個比喻中,手電筒發射的光束就是濾波器,它被網絡用于形成圖像的表示。
光束的寬度控制著一次掃過的圖像的區域大小,神經網絡具有類似的參數,即濾波器的大小。它影響一次掃過的圖像的像素數。CNN中常見的濾波器尺寸為3,這包括高度和寬度,因此所掃描的像素區域大小為3×3。
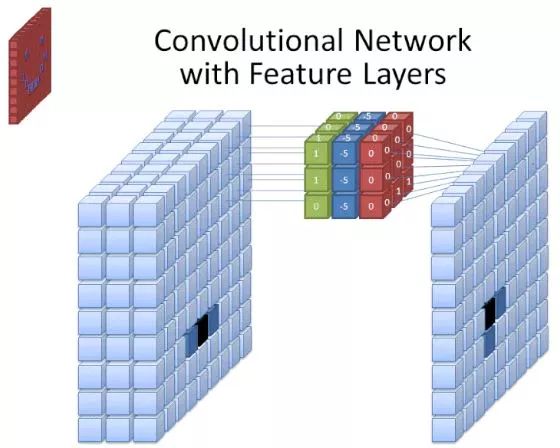 圖片來源:commons.wikimedia.org
圖片來源:commons.wikimedia.org
雖然濾波器的尺寸覆蓋其高度和寬度,同時也需要明確濾波器的深度。
2D圖像如何具有深度?
數字圖像被渲染為高度、寬度和一些定義像素顏色的RGB值,因此被跟蹤的“深度”是圖像具有的顏色通道的數量。灰度(非彩色)圖像僅包含1個顏色通道,而彩色圖像包含3個顏色通道。
這意味著對于應用于全彩色圖像的尺寸為3的濾波器,其規模為3×3×3。對于該濾波器覆蓋的每個像素,神經網絡將濾波器的值和像素本身的值相乘以獲取像素的數值表示。然后,對整個圖像完成上述過程以實現完整的表示。根據參數“步幅”,濾波器在圖像的其余部分滑動。該參數定義了在計算當前位置的值之后,濾波器要滑動的像素數。CNN的默認步幅取值為2。
通過上述計算,最終將獲取特征映射。此過程通常由多個濾波器完成,這有助于保持圖像的復雜性。
激活函數
當圖像的特征映射創建完成之后,表示圖像的值將通過激活函數或激活層進行傳遞。受卷積層的影響,激活函數獲取的表示圖像的值呈線性,并且由于圖像本身是非線性的,因此也增加了該值的非線性。
盡管偶爾會使用一些其他的激活函數,線性整流函數(Rectified Linear Unit, ReLU)是最常用的。
池化層
當數據被激活之后,它們將被發送到池化層。池化對圖像進行下采樣,即獲取圖像信息并壓縮,使其變小。池化過程使網絡更加靈活,更擅長基于相關特征來識別對象/圖像。
當觀察圖像時,我們通常不關心背景信息,只關注我們關心的特征,例如人類或動物。
類似地,CNN的池化層將抽象出圖像不必要的部分,僅保留相關部分。這由池化層指定的大小進行控制。
由于池化層需要決定圖像中最相關的部分,所以希望神經網絡只學習真正表示所討論對象的部分圖像。這有助于防止過度擬合,即神經網絡很好地學習了訓練案例,并無法類推到新數據。
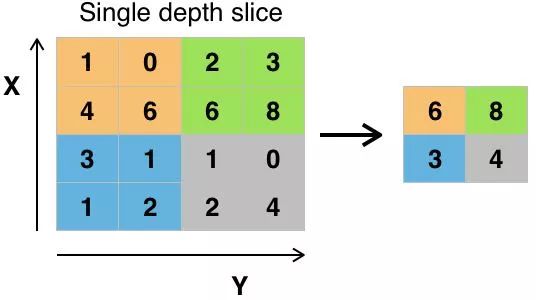
池化值的方式有多種,最大池化(max pooling)是最常用的。最大池化獲取單個濾波器中像素的最大值。假設使用卷積核大小為2×2的濾波器,將會丟失3/4的信息。
使用像素的最大值以便考慮可能的圖像失真,并且減小圖像的參數/尺寸以便控制過度擬合。還有一些其他的池化類型,如均值池化(average pooling)和求和池化(sum pooling),但這些并不常用,因為最大池化往往精確度更高。
壓平(Flattening)
CNN的最后一層,即稠密層,要求數據采用要處理的矢量形式。因此,數據必須“壓平”。值將被壓縮成向量或按順序排列的列。
全連接層
CNN的最后一層是稠密層,或人工神經網絡(ANN)。ANN主要用于分析輸入特征并將其組合成有助于分類的不同屬性。這些層基本上形成了代表所討論對象的不同部分的神經元集合,并且這些集合可能代表狗松軟的耳朵或者蘋果的紅色。當足夠的神經元被激活用于響應輸入圖像時,該圖像將被分類為某個對象。
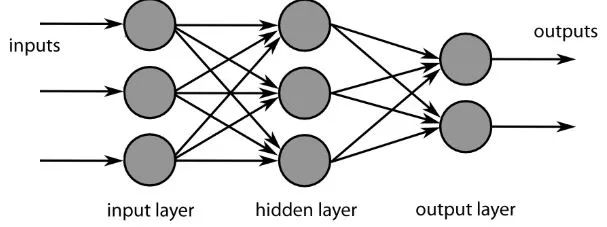
圖片來源:commons.wikimedia.org
數據集中計算值和期望值之間的誤差由ANN進行計算。然后網絡經過反向傳播,計算給定神經元對下一層神經元的影響并對其進行調整。如此可以優化模型的性能,然后一遍又一遍地重復該過程。以上就是神經網絡如何訓練數據并學習輸入特征和輸出類之間的關聯。
中間的全連接層的神經元將輸出與可能的類相關的二進制值。如果有四個不同的類(例如狗,汽車,房子以及人),神經元對于圖像代表的類賦“1”,對其他類賦“0”。最終的全連接層將接收之前層的輸出,并傳遞每個類的概率,總和為1。如果“狗”這一類別的值為0.75,則表示該圖像是狗的確定性為75%。至此圖像分類器已得到訓練,并且可以將圖像傳入CNN,CNN將輸出關于該圖像內容的猜想。
機器學習的工作流
在開始訓練圖像分類器的示例之前,讓我們先來了解一下機器學習的工作流程。訓練神經網絡模型的過程是相當標準的,可以分為四個不同的階段。
數據準備
首先,需要收集數據并將其放入網絡可以訓練的表中。這涉及收集圖像并標記它們。即使下載了其他人準備好的數據集,也可能需要進行預處理,然后才能用于訓練。數據準備本身就是一門藝術,包括處理缺失值,數據損壞,格式錯誤的數據,不正確的標簽等。
創建模型
創建神經網絡模型涉及各種參數和超參數的選擇。需要確定所用模型的層數,層輸入和輸出的大小,所用激活函數的類型,以及是否使用dropout等。
訓練模型
創建模型后,只需創建模型實例并將其與訓練數據相匹配即可。訓練模型時,一個重要的因素即訓練所需時間。您可以通過指定訓練的epoch數目來指定網絡的訓練時長。時間越長,其性能就越高,但是epoch次數過多將存在過度擬合的風險。
您可以適當地設置訓練時的epoch數目,并且通常會保存訓練周期之間的網絡權重,這樣一旦在訓練網絡方面取得進展時,就無需重新開始了。
模型評估
評估模型有多個步驟。評估模型的第一步是將模型與驗證數據集進行比較,該數據集未經模型訓練過,可以通過不同的指標分析其性能。評估神經網絡模型的性能有各種指標,最常見的指標是“準確率”,即正確分類的圖像數量除以數據集中的圖像總和。在了解模型性能在驗證數據集上的準確率后,通常會微調參數并再次進行訓練,因為首次訓練的結果大多不盡人意,重復上述過程直到對準確率感到滿意為止。
最后,您將在測試集上測試網絡的性能。該測試集是模型從未用過的數據。
也許您在想:為什么要用測試集呢?如果想了解模型的準確率,采用驗證數據集不就可以了嗎?
采用網絡從未訓練過的一批數據進行測試是有必要的。因為所有參數的調整,結合對驗證集的重新測試,都意味著網絡可能已經學會了驗證集的某些特征,這將導致無法推廣到樣本外的數據。
因此,測試集的目的是為了檢測過度擬合等問題,并且使模型更具實際的應用價值。
-
圖像識別
+關注
關注
9文章
527瀏覽量
39107 -
python
+關注
關注
56文章
4827瀏覽量
86724 -
tensorflow
+關注
關注
13文章
330瀏覽量
61176
發布評論請先 登錄
火車車號圖像識別系統如何應對不同光照條件下的識別問題?

想用K230放在無人機上做圖像識別,加裝一個4G模塊把識別結果和畫面同時傳輸的地面站或者手機上,怎么操作?
手持終端集裝箱識別系統的圖像識別技術
岸橋箱號識別系統如何工作?揭秘AI圖像識別技術!
驚了!這個“神器”讓樹莓派秒變智能管家,圖像識別+無線投屏,太秀了!

【幸狐Omni3576邊緣計算套件試用體驗】RKNN 推理測試與圖像識別
將YOLOv4模型轉換為IR的說明,無法將模型轉換為TensorFlow2格式怎么解決?
如何將Keras H5模型轉換為中間表示 (IR) 格式?
BP神經網絡在圖像識別中的應用
高幀頻圖像識別反無人機 慧視有辦法!

AI圖像識別攝像機






 工商網監
工商網監
評論