 針對去重Cube的優化實踐思路分析
針對去重Cube的優化實踐思路分析
本文主要分享了作者在螞蟻集團高管數據鏈路改造升級過程中,針對去重Cube的優化實踐。
引言
SQL作為目前最通用的數據庫查詢語言,其功能和特性復雜度遠不止大家常用的“SELECT * FROM tbl”這樣簡單,一段好的SQL和差的SQL,其性能可能有幾十乃至上千倍的差距。而寫出一個好的能兼顧性能和易用性的SQL,考驗的不僅僅是了解到多少新特性新寫法,而是要深入理解數據的處理過程,然后設計好數據的處理過程。
一、場景描述
在做數據匯總計算和統計分析時,最頭疼的就是去重類指標計算(比如用戶數、商家數等),尤其還要帶多種維度的下鉆分析,由于其不可累加的特性,幾乎每換一種統計維度組合,都得重新計算。數據量小時可以暴力的用明細數據直接即時統計,但當數據量大時就不得不考慮提前進行計算了。
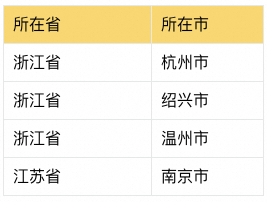
典型場景如下:省、市、區等維度下的支付寶客戶端的日支付用戶數(其中省、市、區為用戶支付時所在的位置,表格中指標數據均為虛構的)。
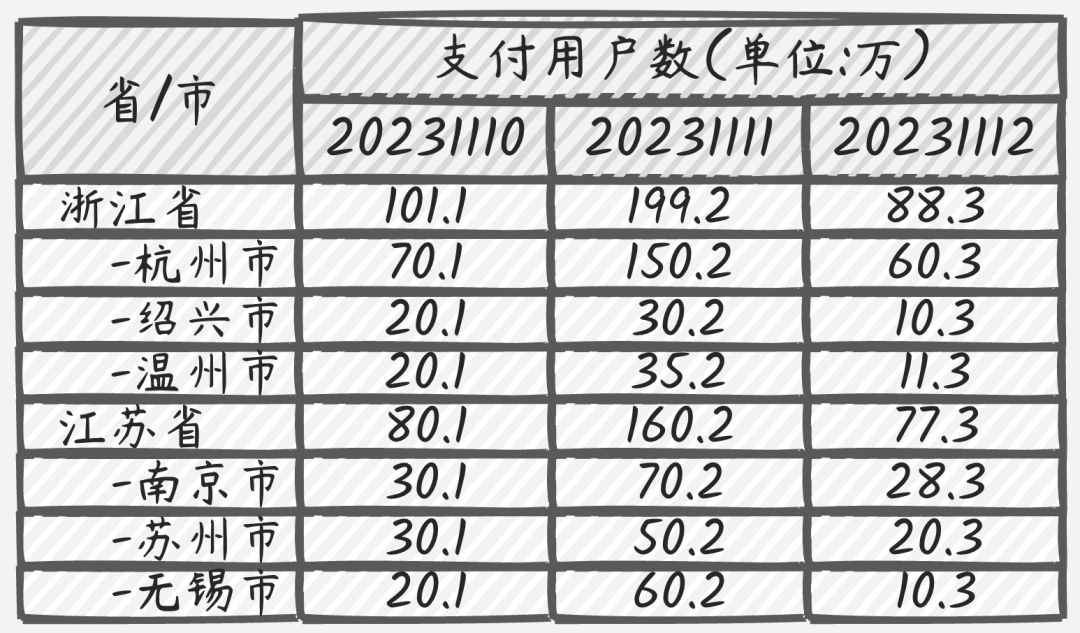
存在一個情況,某用戶早上在杭州市使用支付寶支付了一次,下午跑到紹興市時又使用支付寶線下支付了一次。那么在統計省+市維度的日支付用戶數,需要為杭州市、紹興市各計1;但在省維度下,需要按用戶去重,只能為浙江省計1。針對這種情況,通常就需要以Cube的方式完成數據預計算,同時每個維度組合都需要進行去重操作,因為不可累加。本文將此種場景簡稱為去重Cube。
二、常見的實現方法
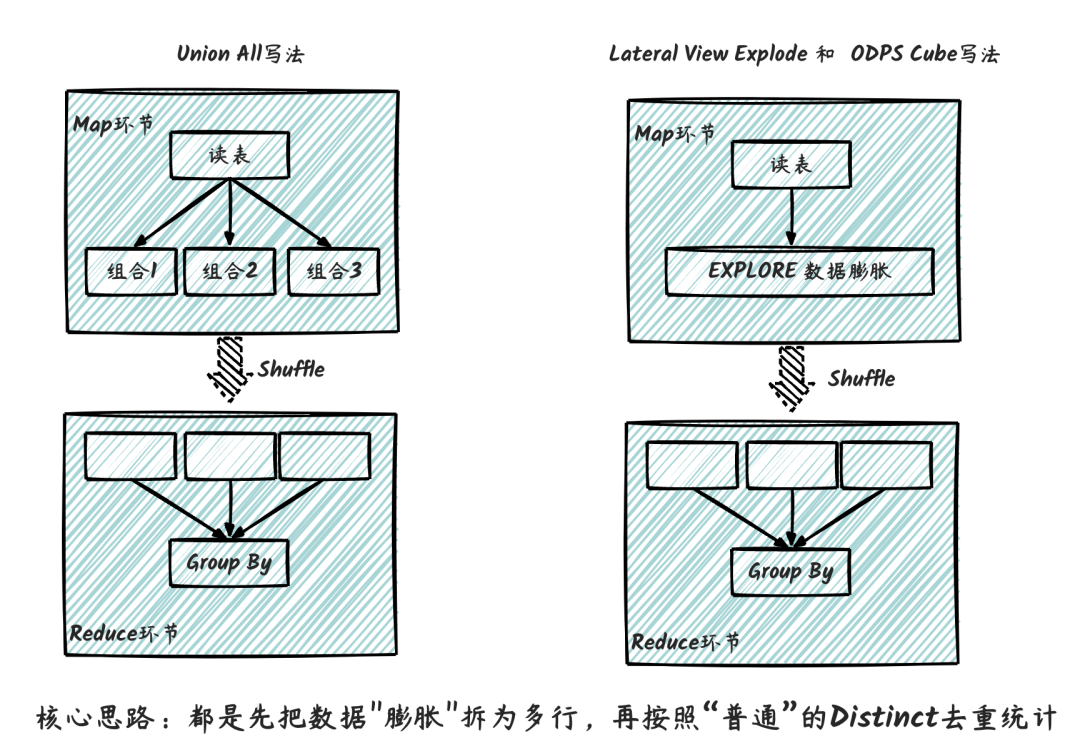
直接計算,每個維度組合單獨計算。比如單獨生成省、省+市、省+市+區等維度組合的多張表。每個表只計算固定的維度。然后是數據膨脹再計算,如Union All或者Lateral View Explode或者MaxCompute的 Cube計算功能,通過數據膨脹實現一行數據滿足多種維度組合的數據計算方法,如下圖所示。

這三種寫法其實都類似,重點都在于對數據進行膨脹,再進行去重統計。其執行流程如下圖所示,核心思路都是先把數據"膨脹"拆為多行,再按照“普通”的Distinct去重統計,因此性能上本身無太大差異,主要在于代碼可維護性上。
三、性能分析
上述方法核心都是先把數據"膨脹"拆為多行,再按照“普通”的Distinct去重統計,本身性能無太大差異,主要在于代碼可維護性上。這幾種方案計算消耗會隨著所需維度組合線性增加,同時還要疊加Distinct本身的計算性能差的影響。
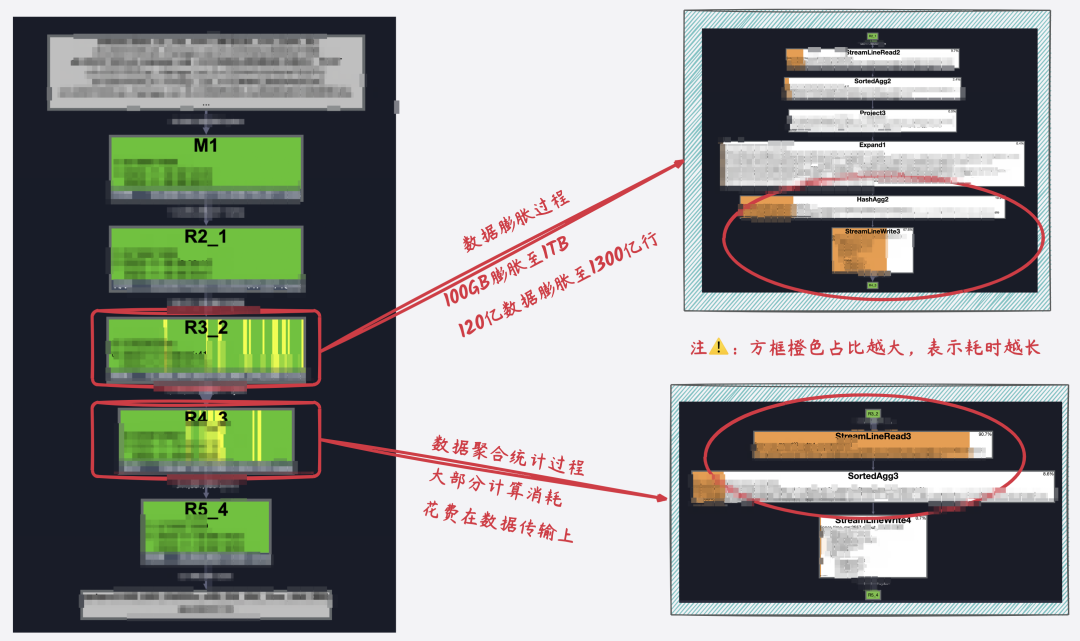
在實際實驗中,我們發現,去重Cube的計算過程中,80%+的計算成本消耗在數據膨脹和數據傳輸上。比如高管核心指標場景,需要計算各種組合維度下的支付用戶數以支持分析。實際實驗中,選取100億數據x25種維度組合進行測試,實際執行任務如下圖所示,其中R3_2為核心的數據膨脹過程,數據膨脹近10倍,中間結果數據大小由100GB膨脹至1TB、數據量由100億膨脹至近1300億,大部分計算資源和計算耗時都花在數據膨脹和傳輸上了。若實際的組合維度進一步增加的話,數據膨脹大小也將進一步增加。
四、一種新的思路
首先對問題進行拆解下,去重Cube的計算過程核心分為兩個部分,數據膨脹+數據去重。數據膨脹解決的是一行數據同時滿足多種維度組合的計算,數據去重則是完成最終的去重統計,核心思路還是在于原始數據去匹配結果數據的需要。其中數據去重本身的計算量就較大,而數據膨脹會導致這一情況加劇,因為計算過程中需要拆解和在shuffle過程中傳輸大量的數據。數據計算過程中是先膨脹再聚合,加上本身數據內容的中英文字符串內容較大,所以才導致了大量的數據計算和傳輸成本。
而我們的核心想法是能否避免數據膨脹,同時進一步減少數據傳輸大小。因此我們聯想到,是否可以采用類似于用戶打標簽的數據打標方案,先進行數據去重生成UID粒度的中間數據,同時讓需要的結果維度組合反向附加到UID粒度的數據上,在此過程中并對結果維度進行編號,用更小的數據結構去存儲,避免數據計算過程中的大量數據傳輸。整個數據計算過程中,數據量理論上是逐漸收斂的,不會因為統計維度組合的增加而增加。
4.1.核心思路
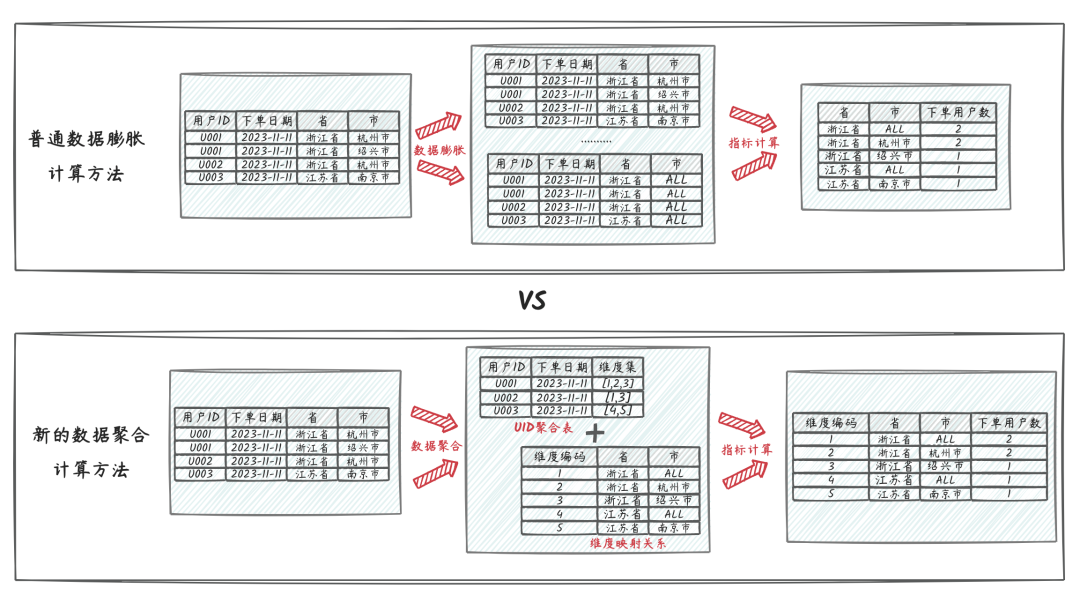
核心計算思路如上圖,普通的數據膨脹計算cube的方法,中間需要對數據進行膨脹,再聚合,其中結果統計需要的組合維度數就是數據膨脹的倍數,比如上述的“省、省+市”共計兩種維度組合,數據預計要膨脹2倍。
而新的數據聚合方法,通過一定的策略方法將維度組合拆解為維度小表并進行編號,然后將原本的訂單明細數據聚合至用戶粒度的中間過程數據,其中各類組合維度轉換為數字標記錄至用戶維度的數據記錄上,整個計算過程數據量是呈收斂聚合的,不會膨脹。
4.2.邏輯實現
明細數據準備:以用戶線下支付數據為例,明細記錄包含訂單編號、用戶ID、支付日期、所在省、所在市、支付金額。最終指標統計需求為統計包含省、市組合維度+支付用戶數的多維Cube。
| 訂單編號 | 用戶ID | 支付日期 | 所在省 | 所在市 | 支付金額 |
| 2023111101 | U001 | 2023-11-11 | 浙江省 | 杭州市 | 1.11 |
| 2023111102 | U001 | 2023-11-11 | 浙江省 | 紹興市 | 2.22 |
| 2023111103 | U002 | 2023-11-11 | 浙江省 | 杭州市 | 3.33 |
| 2023111104 | U003 | 2023-11-11 | 江蘇省 | 南京市 | 4.44 |
| 2023111105 | U003 | 2023-11-11 | 浙江省 | 溫州市 | 5.55 |
| 2023111106 | U004 | 2023-11-11 | 江蘇省 | 南京市 | 6.66 |
整體方案流程如下圖。
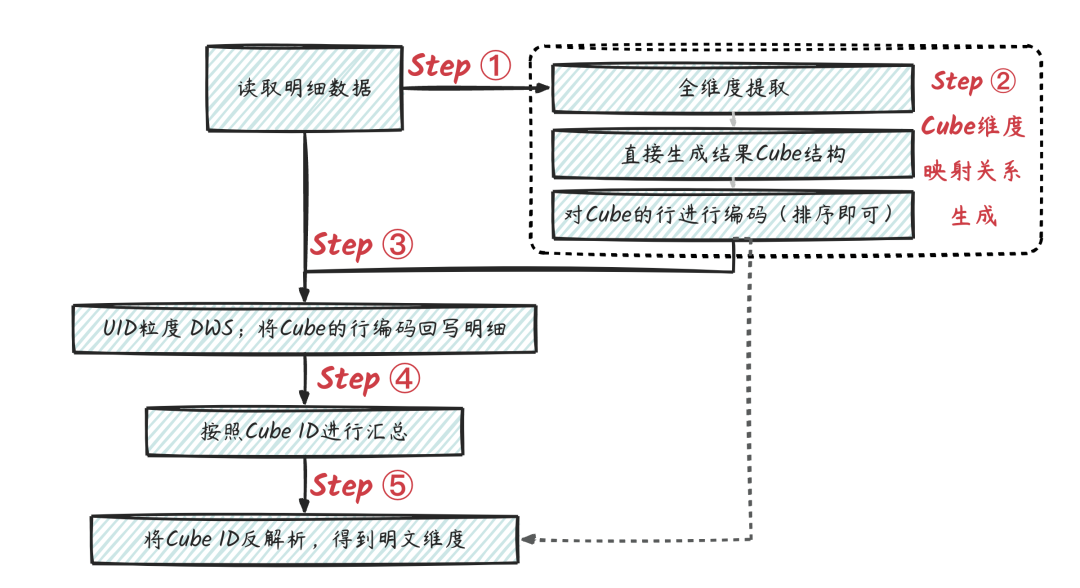
STEP1:對明細數據進行所需的維度提取(即Group By對應字段),得到維度集合。
STEP2:對得到的維度集合生成Cube,并對Cube的行進行編碼 (假設最終需要所在省、所在省+所在市2種組合維度),可以用ODPS的Cube功能實現,再根據生成的Cube維度組合進行排序生成唯一編碼。
| 原始維度:所在省 | 原始維度:所在省 | Cube 維度:所在省 | Cube 維度:所在市 | Cube行ID(可通過排序生成) |
| 浙江省 | 杭州市 | 浙江省 | ALL | 1 |
| 浙江省 | 杭州市 | 浙江省 | 杭州市 | 2 |
| 浙江省 | 紹興市 | 浙江省 | ALL | 1 |
| 浙江省 | 紹興市 | 浙江省 | 紹興市 | 3 |
| 浙江省 | 溫州市 | 浙江省 | ALL | 1 |
| 浙江省 | 溫州市 | 浙江省 | 溫州市 | 4 |
| 江蘇省 | 南京市 | 江蘇省 | ALL | 5 |
| 江蘇省 | 南京市 | 江蘇省 | 南京市 | 6 |
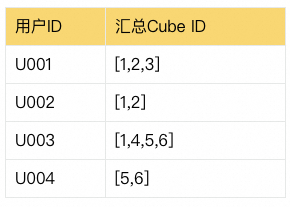
STEP3:將Cube的行編碼,根據映射關系回寫到用戶明細上,可用Mapjoin的方式實現。
| 訂單編號 | 用戶ID | 支付日期 | 所在省 | 所在市 | 匯總Cube ID |
| 2023111101 | U001 | 2023-11-11 | 浙江省 | 杭州市 | [1,2] |
| 2023111102 | U001 | 2023-11-11 | 浙江省 | 紹興市 | [1,3] |
| 2023111103 | U002 | 2023-11-11 | 浙江省 | 杭州市 | [1,2] |
| 2023111104 | U003 | 2023-11-11 | 江蘇省 | 南京市 | [5,6] |
| 2023111105 | U003 | 2023-11-11 | 浙江省 | 溫州市 | [1,4] |
| 2023111106 | U004 | 2023-11-11 | 江蘇省 | 南京市 | [5,6] |
STEP4:匯總到用戶維度,并對 Cube ID集合字段進行去重 (可以用ARRAY 的DISTINCT)
STEP5:按照Cube ID進行計數計算(由于STEP4已經去重啦,因此這里不需要再進行去重);然后按照映射關系進行維度還原。
| Cube ID | 下單用戶數指標 | Cube 維度還原:所在省 | Cube 維度還原:所在市 |
| 1 | 3 | 浙江省 | ALL |
| 2 | 2 | 浙江省 | 杭州市 |
| 3 | 1 | 浙江省 | 紹興市 |
| 4 | 1 | 浙江省 | 溫州市 |
| 5 | 2 | 江蘇省 | ALL |
| 6 | 2 | 江蘇省 | 江蘇省 |
Over~
4.3.代碼實現
WITH
-- 基本的明細數據表準備
base_dwd AS (
SELECT pay_no
,user_id
,gmt_pay
,pay_amt
,prov_name
,prov_code
,city_name
,city_code
FROM tmp_user_pay_order_detail
)
-- 生成多維Cube,并進行編碼
,dim_cube AS (
-- Step02:CUbe生成
SELECT *,DENSE_RANK() OVER(PARTITION BY 1 ORDER BY cube_prov_name,cube_city_name) AS cube_id
FROM (
SELECT dim_key
,COALESCE(IF(GROUPING(prov_name) = 0,prov_name,'ALL'),'na') AS cube_prov_name
,COALESCE(IF(GROUPING(city_name) = 0,city_name,'ALL'),'na') AS cube_city_name
FROM (
-- Step01:維度統計
SELECT CONCAT(''
,COALESCE(prov_name ,''),'#'
,COALESCE(city_name ,''),'#'
) AS dim_key
,prov_name
,city_name
FROM base_dwd
GROUP BY prov_name
,city_name
) base
GROUP BY dim_key
,prov_name
,city_name
GROUPING SETS (
(dim_key,prov_name)
,(dim_key,prov_name,city_name)
)
)
)
-- 將CubeID回寫到明細記錄上,并生成UID粒度的中間過程數據
,detail_ext AS (
-- Step04:指標統計
SELECT user_id
,ARRAY_DISTINCT(SPLIT(WM_CONCAT(';',cube_ids),';')) AS cube_id_arry
FROM (
-- Step03:CubeID回寫明細
SELECT /*+ MAPJOIN(dim_cube) */
user_id
,cube_ids
FROM (
SELECT user_id
,CONCAT(''
,COALESCE(prov_name,''),'#'
,COALESCE(city_name,''),'#'
) AS dim_key
FROM base_dwd
) dwd_detail
JOIN (
SELECT dim_key,WM_CONCAT(';',cube_id) AS cube_ids
FROM dim_cube
GROUP BY dim_key
) dim_cube
ON dwd_detail.dim_key = dim_cube.dim_key
) base
GROUP BY user_id
)
-- 指標匯總并將CubeID翻譯回可理解的維度
,base_dws AS (
-- Step05:CubeID翻譯
SELECT cube_id
,MAX(prov_name) AS prov_name
,MAX(city_name ) AS city_name
,MAX(uid_cnt ) AS user_cnt
FROM (
SELECT cube_id AS cube_id
,COUNT(1) AS uid_cnt
,CAST(NULL AS STRING) AS prov_name
,CAST(NULL AS STRING) AS city_name
FROM detail_ext
LATERAL VIEW EXPLODE(cube_id_arry) arr AS cube_id
GROUP BY cube_id
UNION ALL
SELECT CAST(cube_id AS STRING) AS cube_id
,CAST(NULL AS BIGINT) AS uid_cnt
,cube_prov_name AS prov_name
,cube_city_name AS city_name
FROM dim_cube
) base
GROUP BY cube_id
)
-- 大功告成,輸出結果!!!
SELECT prov_name
,city_name
,user_cnt
FROM base_dws
;
實際的執行過程(ODPS的Logview)如下圖。
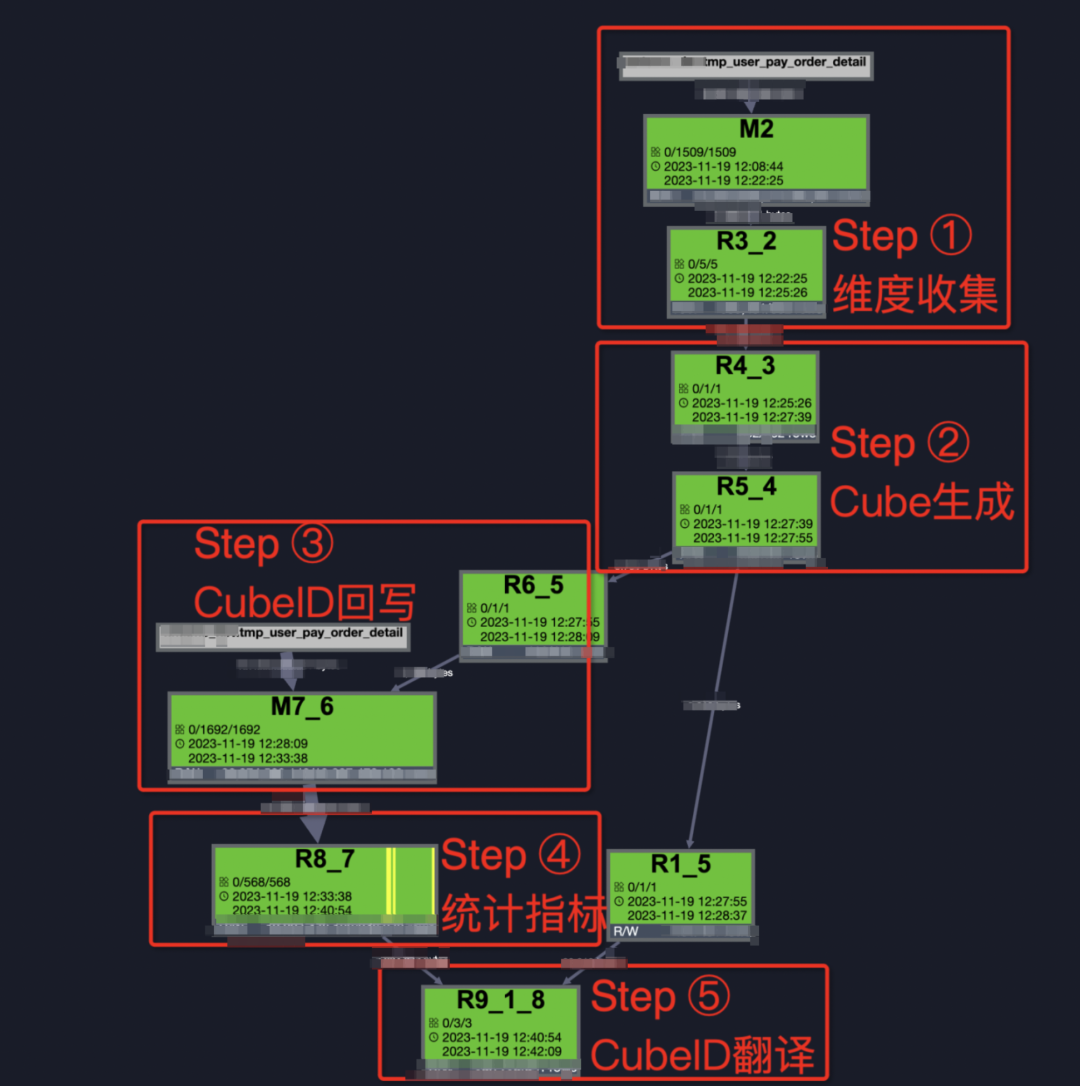
4.4.實驗效果
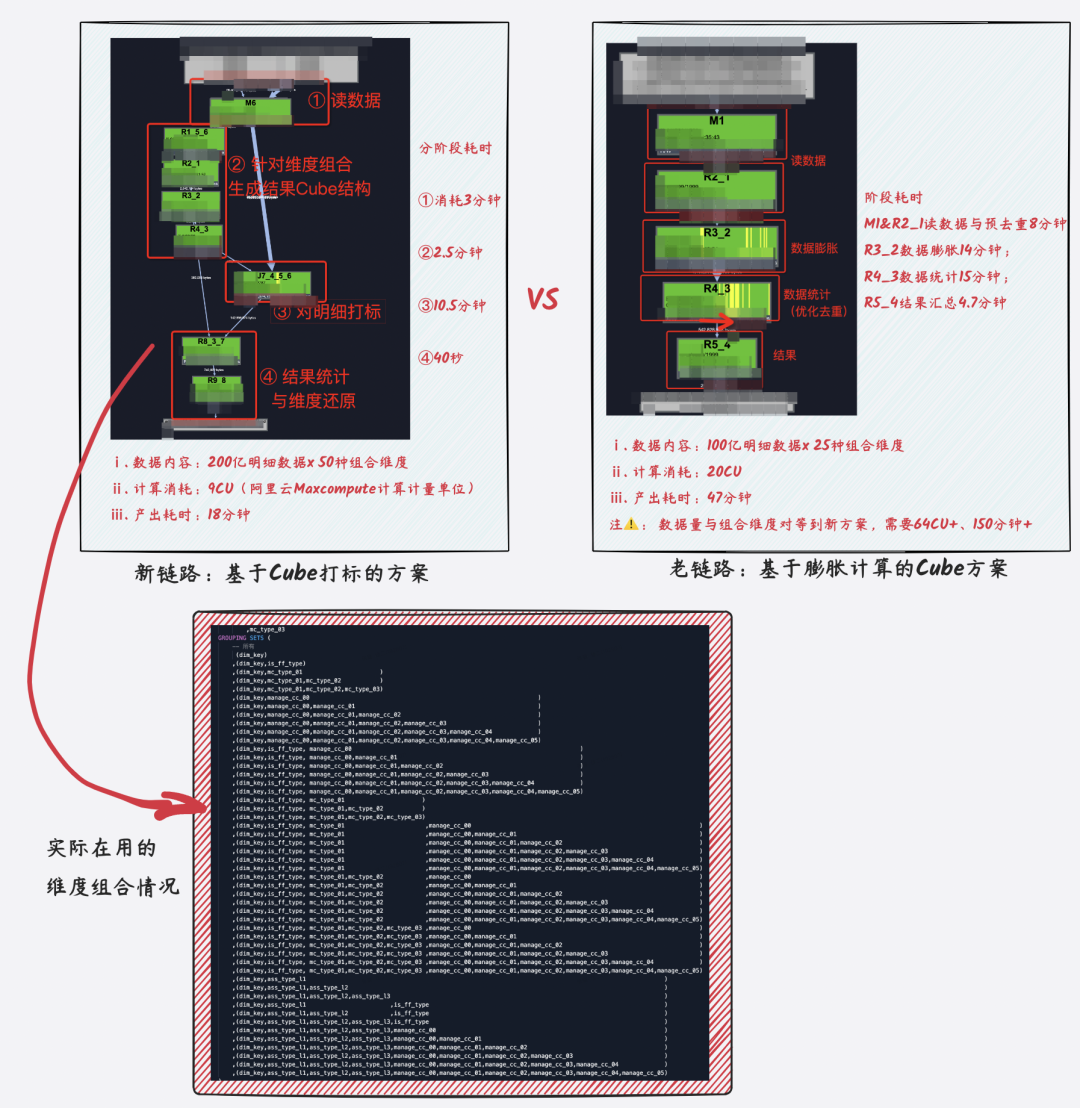
左邊是基于Cube打標方案的新鏈路。實驗過程中將實驗數據由100億增加至200億,組合維度數由原來的25個增加至50種組合維度,整體耗時在18分鐘,若只計算和原始數據量、組合維度均相同的數據,整體計算耗時可控制在10分鐘內。
右邊是基于數據膨脹計算的老鏈路。實驗數據設定為100億,組合維度數為25種,中間過數據將膨脹至1300億+,數據大小更是膨脹至1TB+,整體耗時47分鐘。若此方案擴展至新方法的200億數據x50種組合維度,中間過程數據將膨脹至4000億+,數據大小增加將膨脹至3TB+,整體計算耗時預估將達到2.5小時+。
新方法目前已經在業務核心高管鏈路上線,在數據統計維度組合、數據計算量都大幅增加的情況下,整體核心指標產出相較于以往,進一步提前1小時以上,有效的保障了相關核心指標數據的穩定性。
4.5.方案總結
常見的基于數據膨脹的Cube計算方法,數據計算大小和過程數據傳輸量將隨著組合維度的數量呈線性增長,組合維度數越多,花費在數據膨脹與Shuffle傳輸的資源和耗時占比越高。在實驗過程中,100億實驗數據x25種維度組合場景,過程數據已經膨脹至1300億+,數據大小由100GB膨脹至1TB,當數據量和維度組合數進一步增加時,整個計算過程基本上難以完成。
為了解決數據膨脹過程中產生的大量過程數據,我們基于數據打標的思路反向操作,先對數據聚合為UID粒度,過程中將需要的維度組合轉化編碼數字并賦予明細數據上,整個計算過程數據呈收斂聚合狀,數據計算過程較為穩定,不會隨著維度組合的進一步增加而大幅增加。在實驗中,將實驗數據由100億增加至200億+,組合維度數由原來的25個增加至50種組合維度,整體耗時控制在18分鐘左右。若同等的數據量,采用老的數據膨脹方案,中間過程數據將膨脹至4000億+,數據大小將增加至3TB+,整體計算耗時將達到2.5小時+。
綜上,當前的方案整體性能相較于以往有大幅度的提升,并且不會隨著維度組合的增加而有明顯的增加。但當前的方案也有不足之處,即代碼的可理解性和可維護性,過程中的打標計算過程雖然流程較為固定,但整體上需要有個初始化理解的過程,目前尚無法做到普通UnionAll/Cube等方案的易讀和易寫。另外,當組合維度數較少(即數據膨脹倍數不高)時,兩者的性能差異不大,此時建議還是用原始普通的Cube計算方案;但當組合維度數達幾十倍時,可以改用這種數據打標的思路進行壓縮,畢竟此時的性能優勢開始凸顯,并且維度組合數越高,此方案的性能優勢越大。
五、其他方案
BitMap方案。核心思路在于將不可累計的數據指標,通過可累加計算的數據結構,近似實現可累加指標的效果。具體實現過程方案是對用戶ID進行編碼,存入BitMap結構中,比如一個二進制位表示一個用戶是否存在,消耗1個Bit。維度統計上卷時,再對BitMap的數據結構進行合并和計數統計。
HyperLogLog方案。非精確數據去重,相對于Distinct的精確去重,性能提升明顯。
這兩種方案,性能上相對于普通的Cube計算有巨大的提升,但BitMap方案需要對去重統計用的UID進行編碼存儲,對一般用戶的理解和實操成本較高,除非系統級集成此功能,不然通常需要額外的代碼開發實現。而HyperLogLog方案的一大弊端就是數據的非精確統計。
審核編輯:黃飛
-
SQL
+關注
關注
1文章
780瀏覽量
44804 -
數據鏈路
+關注
關注
0文章
27瀏覽量
9065 -
CUBE
+關注
關注
0文章
10瀏覽量
9584
原文標題:去重Cube計算優化新思路
文章出處:【微信號:OSC開源社區,微信公眾號:OSC開源社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
請問cube生成的IAR工程的代碼編譯能進行默認優化等級的設定嗎?
STM32F407 LWIP掉線重連實現STM32CUBE配置
基于特征碼的網頁去重
輿情去重算法的研究







 工商網監
工商網監
評論