") 聊聊循環(huán)緩沖區(qū)的使用
聊聊循環(huán)緩沖區(qū)的使用
我們在為 Arm Cortex-M 處理器系列設計矢量擴展 (MVE) —— Arm Helium 技術時,希望它能廣泛地適用于各種數(shù)字信號處理 (DSP) 的應用。具備高效的數(shù)據(jù)計算能力只成功了一半,同樣重要的是具備在內(nèi)存中訪問和存儲這些數(shù)據(jù)的能力。
正如之前的文章內(nèi)容所述,Helium 是一種四節(jié)拍矢量架構。將數(shù)據(jù)加載到矢量中的最直接的方法是連續(xù)加載操作(見圖一)。在每個節(jié)拍中,都從標量寄存器中指定的基址開始依次訪問內(nèi)存。無論目標數(shù)據(jù)類型如何(8、16 或 32 位),都可以通過充分利用總線寬度的訪問來高效地執(zhí)行這一操作,因為數(shù)據(jù)元素在內(nèi)存和矢量中都是相鄰的,存儲操作也是如此。
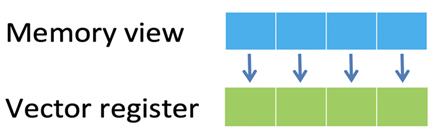
圖一:連續(xù)加載操作
內(nèi)存是一種稀缺資源,通常情況下,要盡可能緊湊地打包數(shù)據(jù),使用可容納數(shù)據(jù)的最小數(shù)據(jù)類型。不過,在處理數(shù)據(jù)時,可能需要更多的空間,以避免在計算的中間階段出現(xiàn)溢出。這可以作為一個獨立的拓寬指令來執(zhí)行,但正如本系列第一篇文章所述,它存在時間跨越問題(對于 8 到 32 位的擴展,將數(shù)據(jù)擴展到最后一節(jié)拍需要第一節(jié)拍的數(shù)據(jù),而第一節(jié)拍的數(shù)據(jù)已不可用)。
因此,擴展指令不能與其他指令重疊,否則會對性能產(chǎn)生不利影響。相反,Helium 引入了改變大小的內(nèi)存操作。數(shù)據(jù)可以作為單個 8、16 或 32 位訪問,針對每個節(jié)拍高效加載,并用零或符號擴展,以匹配所需的數(shù)據(jù)類型。在圖二的示例中,我們希望執(zhí)行將每個矢量通道的 8 位加載擴展到 16 位。兩個 8 位數(shù)據(jù)樣本作為一個 16 位加載操作加載,每個樣本在寫入矢量通道之前擴展到 16 位。同樣,對于存儲來說,數(shù)據(jù)可以截斷到所需的大小,實現(xiàn)高效存儲。
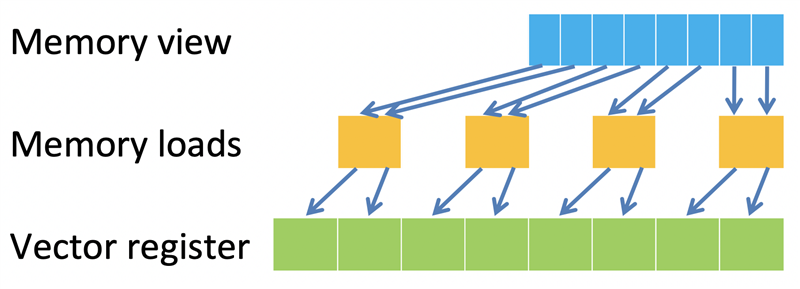
圖二:加載擴展
Helium 加載和存儲指令具有與 M 系列架構的其他部分相同的豐富的尋址模式集,支持預遞增或后遞增以及指針回寫等功能。這樣,在大多數(shù)情況下就不需要單獨進行指針操作了。
DSP 應用通常在數(shù)據(jù)結構而非單個元素上運行。例如,立體聲音頻數(shù)據(jù)通常以左右數(shù)值交織流的形式存儲。同樣,圖像數(shù)據(jù)通常以紅、綠、藍、Alpha 交錯值的形式存儲。這是上一篇文章的主題內(nèi)容,其中介紹了可以有效實現(xiàn)這一目標的結構化加載/存儲指令。
有時,存儲在內(nèi)存中的數(shù)據(jù)無法以便捷的方式構建以實現(xiàn)連續(xù)訪問。在某些架構中,這實際上會阻礙代碼的矢量化。Helium 通過“離散?聚合”操作解決了這一問題。這些操作將偏移矢量指向內(nèi)存,這樣就可以用一條指令訪問多個非連續(xù)地址(見圖三)。它們還能擴展或截斷所訪問的數(shù)據(jù)。
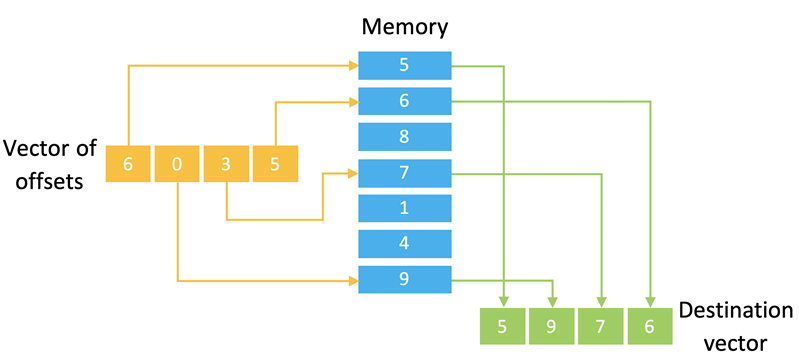
圖三:匯總負載
“離散-聚合”操作是一種功能強大的指令,可為應用提供很大的靈活性。例如,它們幾乎是實現(xiàn) FFT(快速傅里葉變換)不可或缺的工具;在這種算法中,第一個或最后一個蝴蝶階段的內(nèi)存訪問需要使用反位尋址執(zhí)行。專用反位指令 (VBRSR) 生成反位尋址模式,供這些離散-聚合指令使用。為了提高性能,這些指令重疊執(zhí)行,加載數(shù)據(jù)的效率遠遠超過同等序列的標量指令。而且,它們也更容易使用。雖然連續(xù)矢量訪問能為規(guī)律模式提供更好的性能,但由于離散-聚合指令無法對數(shù)據(jù)布局做出假設,因此有多少個不同的元素,匯總加載指令就必須執(zhí)行多少次單獨的訪問。對于 8 位數(shù)據(jù),訪問次數(shù)可能多達 16 次,這就成了不斷加載的負載。
DSP 應用通常使用一種稱為循環(huán)尋址的內(nèi)存布局。可以按順序訪問元素,但最多只能訪問配置的緩沖區(qū)大小,之后的訪問會繞回到第一個元素(見圖四)。例如,從元素 N?1 開始的四元素讀取操作將會訪問元素 N?1, 0, 1, 2。
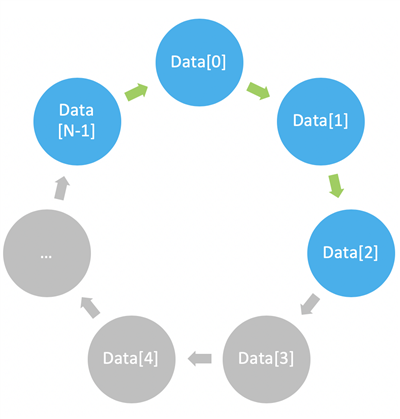
圖四:循環(huán)緩沖區(qū)示例
這在 DSP 應用中用途廣泛,包括在處理數(shù)據(jù)流后只需要前 N 個數(shù)據(jù)樣本時避免指針操作。在 FIR 濾波器中,最后 N 個數(shù)據(jù)樣本需要與一組系數(shù)相乘,才能產(chǎn)生所需的濾波器響應。當一個新的數(shù)據(jù)樣本到來時,需要處理的是之前的 N?1 個樣本和新樣本,最舊的樣本不再使用。數(shù)據(jù)可以重新排列,使要處理的緩沖區(qū)總是按正確的順序包含元素,但這需要在開始處理前將每個樣本復制到不同的位置,耗費大量資源。如果使用循環(huán)緩沖區(qū),就可以就地訪問數(shù)據(jù),必要時還可以繞回到開頭,而且只需要寫入一次就可以用最新的樣本替換最舊的樣本。
一些 DSP 通過專用訪問指令和專用寄存器來實現(xiàn)循環(huán)緩沖區(qū)的起始地址和結束地址。指針每次遞增時,硬件都會將其與結束地址進行比較,并相應地回繞。這意味著同時支持的循環(huán)緩沖區(qū)數(shù)量受到可用硬件的限制。這也意味著每次中斷都需要保留大量額外狀態(tài),而這會影響延遲。為此,所需的硬件支持不容忽視;在典型的實施中,需要更復雜的地址生成單元。為了避免這種情況,一些 DSP 要求循環(huán)緩沖區(qū)的大小等于 2 的冪次方,緩沖區(qū)的地址調整為該大小的倍數(shù)。可以通過將指針與位掩碼進行 AND 運算實現(xiàn),從而簡化硬件要求。但是,這樣會限制這些緩沖區(qū)的放置和使用,特別是幾乎無法直接從高級語言使用緩沖區(qū)。由于 M 系列的宗旨是讓一切都能通過 C 語言輕松使用,因此我們需要想出一種更好的方法。
我們的解決方案是將循環(huán)緩沖區(qū)分成兩個不同的操作,其方式與上文討論的反位尋址類似。我們將用于生成回繞偏移的指令與離散?聚合指令相結合來訪問這些偏移地址的數(shù)據(jù)。這就為緩沖區(qū)大小和位置提供了靈活性,而且關鍵路徑上也不需要有專用硬件。循環(huán)緩沖區(qū)生成指令 (VIWDUP) 可創(chuàng)建一個矢量,其中包含一連串遞增的偏移量,當?shù)竭_終點位置時會回繞到開頭(見圖五)。該指令用從 R0 值開始的序列填充矢量寄存器 Q0,并在達到 R1 值時回繞。然后,它將更新后的起始偏移量 2 寫回 R0。這條指令的一個巧妙設計是,每次寫入 Q0 的偏移量矢量都是由標量值重新生成的。
通常下一條指令就是使用偏移量的離散?聚合指令,因此 Q0 可以直接重復用于其他目的。立即值指定偏移量的增量,這對于處理不同的元素大小非常有用。例如,如果加載的是 32 位數(shù)值,將使用四個字節(jié)的增量。可以指定任意增量或減量,因此該指令可用于其他需要通用數(shù)字模式的情況。通過這種方式,Helium 可以提供任意數(shù)量的循環(huán)緩沖區(qū),在內(nèi)存中具有靈活的大小、方向和對齊方式,而且這個過程只需要使用現(xiàn)有的硬件就可以提供序列生成指令。
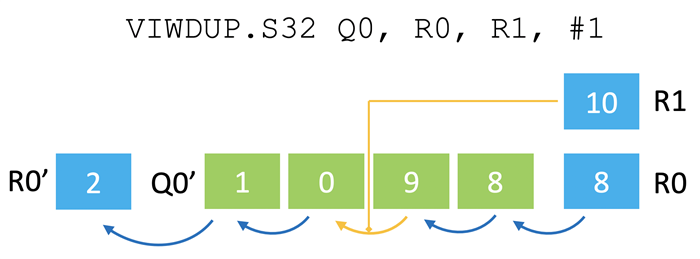
圖五:序列生成指令的操作示例
那么性能表現(xiàn)如何呢?雖然需要額外的偏移生成指令 (VIWDUP),但我們發(fā)現(xiàn)在許多情況下,可能會因為與內(nèi)存訪問本身重疊而隱藏了開銷。在所有情況下,這一開銷都小于在沒有硬件支持的情況下管理回繞的計算工作量。我們之前也說過,出于性能考慮,最好使用連續(xù)訪問。循環(huán)緩沖區(qū)的特別之處在于,大部分訪問都是連續(xù)的,只有偶爾發(fā)生回繞時才會出現(xiàn)不連續(xù)。一種方法是離散-聚合指令比較偏移值,然后合并連續(xù)的訪問。遺憾的是,這樣做將需要大量額外的硬件,并給設計的關鍵部分增加許多額外的復雜性。在負載連續(xù)的情況下,離散?聚合操作會降低性能,這違背了我們追求將每個 gate 的性能發(fā)揮到極致的原則。
當我們試圖找到解決這個問題的方法時,我們注意到偏移生成指令 (VIWDUP) 已經(jīng)掌握回繞點的位置。如果能將這一信息傳遞給離散-聚合指令,它就能將訪問提升為連續(xù)訪問,而無需使用昂貴又耗時的偏移比較器。那么我們能不能指定一個額外的標量寄存器來傳輸這些信息呢?遺憾的是,這將增加所需的讀取端口數(shù)量,而且標量依賴關系從 VIWDUP 改為離散?聚合指令將會導致指令無法重疊。Helium 實現(xiàn)是否可以將這些信息存儲在隱藏的微架構元數(shù)據(jù)中,并在矢量發(fā)生修改時清除元數(shù)據(jù)?一般不建議這樣做,因為元數(shù)據(jù)需要在中斷時保留,而這會影響延遲。
但我們發(fā)現(xiàn),在這種情況下,我們不需要保留元數(shù)據(jù)。在出現(xiàn)異常的極少數(shù)情況時,備選措施是正常執(zhí)行離散-聚合,而不是優(yōu)化連續(xù)訪問。通過使用易失性隱藏元數(shù)據(jù)來指示連續(xù)訪問,可以優(yōu)化普通非回繞情況下的性能,同時避免出現(xiàn)額外的架構狀態(tài)和中斷延遲。
在受限的環(huán)境中工作極具挑戰(zhàn)性,Helium 要求我們不斷尋找創(chuàng)新的解決方案,充分發(fā)揮硬件性能。我們努力聯(lián)合設計架構和微架構,尋找一系列內(nèi)存訪問指令,既能滿足 DSP 應用的需要,又能最大限度地減少實現(xiàn)這些指令所需的硬件數(shù)量。特別是在循環(huán)緩沖區(qū)方面,我們延續(xù)了 M 系列的傳統(tǒng),確保每個 gate 都物盡其用,從而以較低的面積實現(xiàn)性能表現(xiàn),同時為終端用戶提供良好的體驗感。
審核編輯:劉清
-
寄存器
+關注
關注
31文章
5421瀏覽量
123322 -
ARM處理器
+關注
關注
6文章
361瀏覽量
42439 -
人工智能
+關注
關注
1804文章
48701瀏覽量
246468 -
Cortex-M
+關注
關注
2文章
230瀏覽量
30224
原文標題:Helium 技術講堂 | 循環(huán)緩沖區(qū)的使用
文章出處:【微信號:Arm社區(qū),微信公眾號:Arm社區(qū)】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
解析RZ/N2L CANFD模塊的緩沖區(qū)機制(2)

解析RZ/N2L CANFD模塊的緩沖區(qū)機制(1)

FX3 Socket緩沖區(qū)切換的最大時間是多少?
求助,關于3014的緩沖區(qū)設置疑問求解
請問如何在Linux中使用幀緩沖區(qū)更新epdc顯示?
FreeRTOS進階使用之流緩沖區(qū):高效處理字節(jié)流的秘密武器
緩沖區(qū)溢出漏洞的原理、成因、類型及最佳防范實踐(借助Perforce 的Klocwork/Hleix QAC等靜態(tài)代碼分析工具)

RTOS的流緩沖區(qū)機制解析

AMD Zen 4處理器悄然禁用循環(huán)緩沖區(qū)
分享一個嵌入式通用FIFO環(huán)形緩沖區(qū)實現(xiàn)庫

內(nèi)存緩沖區(qū)和內(nèi)存的關系
單片機中的幾種環(huán)形緩沖區(qū)的分析和實現(xiàn)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論