 把數據緩存到文件系統有哪些優勢
把數據緩存到文件系統有哪些優勢
1 背景
在讀完kafka官方文檔,kafka設計里的持久化一章后,給我的第一印象是內容很抽象,于是草擬和總結了給個副標題,并把相關內容進行了歸類;有些生澀的句子,盡量用大白話和舉例進行說明,并加入了總結。
2 磁盤IO速度的快和慢,不取決我們的主觀認知,而是由我們的使用方式決定的
kafka 里消息的緩存和存儲,嚴重依賴文件系統。(根據上下文推測,這里的緩存消息和存儲消息,指的是broker端 緩存和存儲消息)
在我們普遍的認知里,都覺得“磁盤IO速度是非常慢的”,這種固有的觀點,使得人們懷疑持久性結構是否能夠提供競爭性的性能。
(和其它MQ中間件相對,你把數據 存入到磁盤上,還有性能上的優勢嗎?)
但實際上,磁盤速度,取決于他們的使用方式,設計得當的磁盤結構往往可以和網絡一樣快。
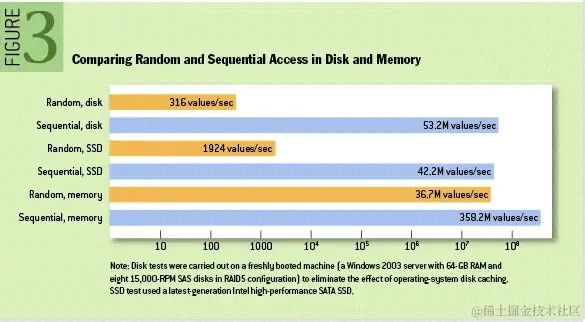
從順序寫數據到磁盤的角度分析 ------順序寫磁盤,比隨機訪問內存的速度還快
事實上 關于磁盤性能,在過去十年中,硬盤驅動器的吞吐量與磁盤尋道的延遲一直存在差異。
在具有六個 7200rpm SATA RAID-5 陣列的 JBOD 配置上,線性寫入性能約為 600MB/秒,但隨機寫入性能僅為約 100k/秒,相差超過 6000 倍。
這些線性讀取和寫入是所有使用模式中最可預測的,并且經過操作系統的大力優化。現代操作系統提供預讀和后寫技術,以大塊倍數預取數據,并將較小的邏輯寫入分組為較大的物理寫入。
有關此問題的進一步討論可以在這篇 ACM Queue 文章中找到;他們實際上發現順序磁盤訪問在某些情況下比隨機內存訪問更快!如下圖所示:
從磁盤讀寫數據的角度 ------使用磁盤緩存,加速磁盤讀寫速度
為了彌補這種性能差異,現代操作系統在使用主內存進行磁盤緩存方面變得越來越積極。
現代操作系統將所有空閑內存快樂地用于磁盤緩存,當內存被回收時幾乎沒有性能損失。
所有磁盤讀寫都將通過這個統一緩存進行。
這個特性很難關閉,即使進程在進程內保持數據緩存,這些數據也可能會在OS頁面緩存中重復存儲,實際上將所有東西存儲兩次。
(日常 數據在寫入磁盤時,并沒有刷新到磁盤上,只是寫到了磁盤緩存里,而磁盤緩存其實是操作系統的主內存;即把數據寫入文件的時候,其實還是寫到內存中)
圖 kafka broker端 數據寫入過程
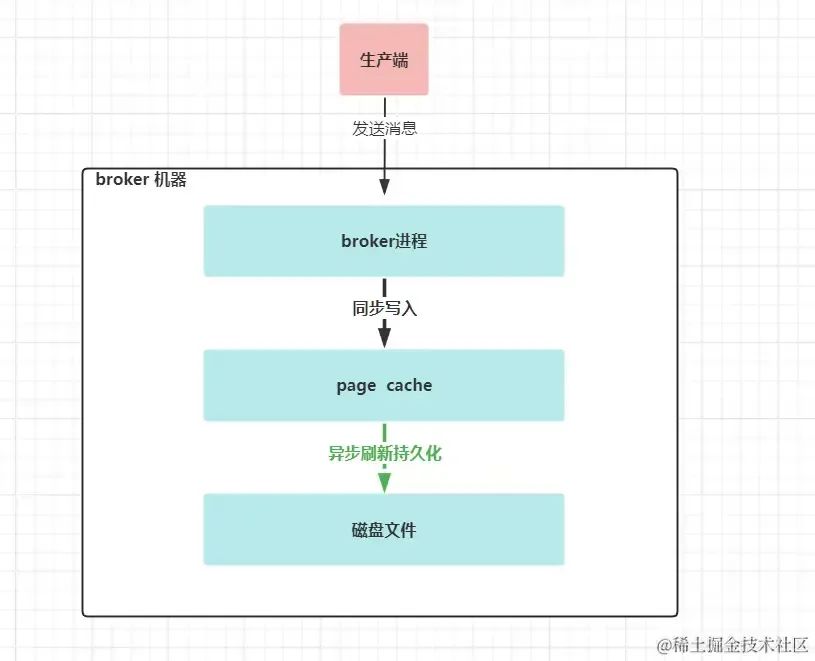
kafka在寫入數據到文件系統時,同步寫入到pagecache,異步刷新并持久化到磁盤里。
3 把數據緩存到JVM有哪些劣勢了?
kafka構建在JVM之上,任何花費過時間了解過 Java內存使用的人都知道兩件事:
對象的內存開銷很高,通常會使存儲的數據大小翻倍(或更糟)。(即原數據可能只有1K大小,但是轉換為java對象,可能要3K)
隨著堆內數據的增加,Java垃圾回收變得越來越繁瑣和慢。(jvm里緩存的數據,會放到堆內存中;隨這數據越來越多,達到GC的臨界點會越來越快,導致GC越來越頻繁 ;這樣就會導致系統會把資源用于GC,而不是業務處理了)
4 把數據緩存到文件系統有哪些優勢了?
使用文件系統并依賴頁面緩存方式,比維護內存中緩存或其他結構要更優 。主要原因:
相對于把數據緩存到jvm中,直接使用操作系統頁面緩存,可讓程序能使用的緩存加倍。(因為jvm 對象的內存開銷很高,他會膨脹。1K的數據放入到頁面緩存還是1K;但是轉換為JVM對象,可能就占用了3K空間)
把消息數據使用字節結構并且壓縮的方式進行存儲,比單個對象的存儲更節約空間,并且還可能進一步帶來緩存內存的加倍使用。
這樣做即使在 32GB 機器上也可產生高達 28-30GB 的緩存,而不會造成 GC 損失。(---即使緩存中的數據變大,也不會帶來頻繁的GC)
即使kafka 服務重新啟動,此緩存也將保持熱狀態。(頁面緩存中數據還在,因為kafka進程重新,而操作系統可能不會重啟) 而如果把數據放入到進程內緩存,kafka服務重啟時將需要在內存中重建(對于 10GB 緩存可能需要 10 分鐘),否則它將需要以完全冷的緩存啟動 (這可能意味著糟糕的初始性能)。
極大地簡化了代碼,因為用于維護緩存和文件系統之間一致性的所有邏輯現在都在操作系統中,這往往比一次性進程內嘗試更有效、更正確。
如果您的磁盤使用有利于順序讀取的方式,那么操作系統的預讀實際上是在每次磁盤讀取時使用有用的數據預先填充此緩存。
(這里涉及到操作系統讀取磁盤上的數據時的一種優化---預讀。即往磁盤里讀一行數據,操作系統實際上是把這一行數據,和他后面的5K數據,都會一次性讀出來,放入到緩存里。這對于kafka這種順序消費消息的模式,非常適用,因為多讀出來的數據,其實在后續消費的時候,是需要的,這避免了重復從硬盤多次讀取數據,非常類似于一次性加載大塊的數據到內存中;然后還沒有浪費內存空間,因為這些數據后續馬上也是需要被消費者消費的)
5 kafka 以文件系統進行存儲和緩存的設計建議
我們不是在內存中保留盡可能多的內容,而是在空間不足時將其全部刷新到文件系統,而是將其反轉。所有數據都會立即寫入文件系統上的持久日志,而不必刷新到磁盤。實際上,這僅僅意味著它被轉移到內核的頁面緩存中
(我們不會把數據 緩存到jvm進程內存里,當空間不足時,再刷新到緩存里;而是采用了相反的方式:即所有數據會立即寫入到文件系統里,即磁盤緩存里(即頁緩存里),但不會寫入后馬上刷新數據到磁盤里)
============以下為個人總結和觀點==============
6 kafka 這種同步寫文件緩存,異步順序刷新數據到磁盤的方式就不怕,操作系統掛了,數據會丟失嗎?
如果page cache在持久化到磁盤前,broker進程宕機了,這個時候不會丟失消息,重啟broker即可;如果此時操作系統宕機或者物理機宕機了,page cache里的數據還沒有持久化到磁盤里,此種情況數據就丟了。
kafka應對此種情況,建議是通過多副本機制來解決的,核心思想也挺簡單的:如果數據保存在一臺機器上你覺得可靠性不夠,那么我就把相同的數據保存到多臺機器上,某臺機器宕機了可以由其它機器提供相同的服務和數據。 更加詳細的配置 請看《kafka 消息“零丟失”的配方》 broker端丟失消息的情況和解決方法一節
7 那能不能自己控制這個數據刷盤行為了?
可以的,在kafka的官方配置文檔里有兩個參數:
log.flush.interval.messages 和 log.flush.interval.ms
一個控制消息量達到了多少,一個控制間隔時間多少;會把頁緩存里消息刷新到磁盤里;但這個控制刷盤行為也是異步的
8 總結
1、kafka broker端會把文件系統,做為消息緩存和存儲;因為操作系統在寫數據到磁盤時,已進行了優化
2、kafka broker 在寫入數據到文件系統時,同步寫入到磁盤緩存里(即內存里),異步把緩存中的數據寫入到磁盤里。這是kafka 寫數據到文件系統高效的主要原因,也是核心業務 寫數據主流程 高效的主原因;異步順序刷新數據到磁盤里,我覺得是性能高的次要原因,畢竟不阻塞到主流程
3、kafka 作為消息系統,天生就是順序寫入數據到文件系統,并順序讀取文件系統的,這種天然的順序性,恰好可以利用操作系統的預讀功能:即一次磁盤IO 讀取數據時,會把數據附近其他磁盤數據也讀寫到內存中;下一次讀取下一條消息時,不需要磁盤IO了,直接從內存中獲取數據,減少磁盤IO 這種非常慢的讀取次數,加速取數過程。
審核編輯:湯梓紅
-
存儲
+關注
關注
13文章
4502瀏覽量
87065 -
內存
+關注
關注
8文章
3108瀏覽量
74986 -
磁盤
+關注
關注
1文章
388瀏覽量
25655 -
文件
+關注
關注
1文章
578瀏覽量
25202 -
kafka
+關注
關注
0文章
53瀏覽量
5361
原文標題:為什么kafka使用磁盤文件來緩存和存儲消息
文章出處:【微信號:magedu-Linux,微信公眾號:馬哥Linux運維】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
如何把文件系統燒到EMMC并從EMMC加載

談談什么是文件系統 文件系統的功能與特點
Linux文件系統課程
NTFS文件系統,NTFS文件系統是什么意思
XfS文件系統,XfS文件系統是什么意思
Ceph文件系統的數據緩存備份
文件系統是什么?淺談EXT文件系統歷史

linux文件系統中的虛擬文件系統設計詳解
xv6的文件系統是如何實現的


Linux的文件系統及文件緩存的知識點
適用于Linux的最佳通用文件系統 Linux文件系統的安裝

Linux的文件系統特點






 工商網監
工商網監
評論