") 對(duì)于大模型RAG技術(shù)的一些思考
對(duì)于大模型RAG技術(shù)的一些思考
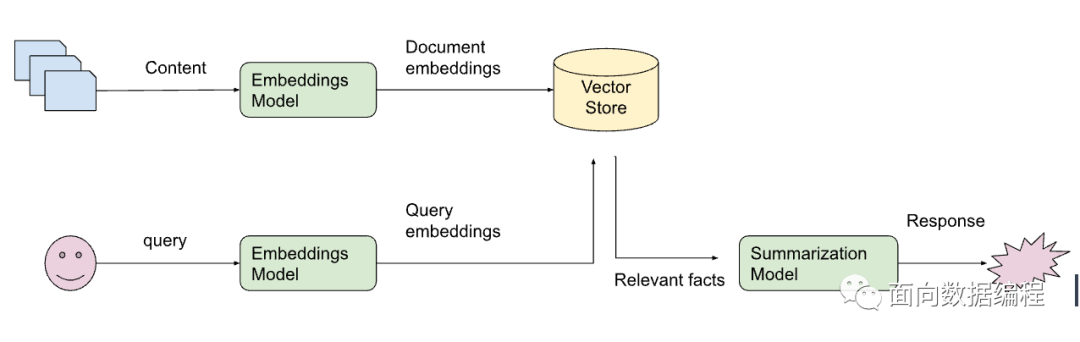
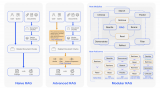
最近在公司完成了一個(gè)內(nèi)部知識(shí)問(wèn)答應(yīng)用,實(shí)現(xiàn)流程很簡(jiǎn)單,實(shí)際上就是Langchain那一套:
對(duì)文檔進(jìn)行切片
將切片后的文本塊轉(zhuǎn)變?yōu)橄蛄啃问酱鎯?chǔ)至向量庫(kù)中
用戶問(wèn)題轉(zhuǎn)換為向量
匹配用戶問(wèn)題向量和向量庫(kù)中各文本塊向量的相關(guān)度
將最相關(guān)的Top 5文本塊和問(wèn)題拼接起來(lái),形成Prompt輸入給大模型
將大模型的答案返回給用戶
具體可以參考下圖,
這個(gè)流程的打通其實(shí)特別容易,基本上1天就能把架子搭起來(lái),然后開(kāi)發(fā)好了API對(duì)外服務(wù)。并且在嘗試了幾個(gè)通用的文檔后,覺(jué)得效果也不錯(cuò)。
但是,當(dāng)公司內(nèi)部真實(shí)文檔導(dǎo)入之后,效果急轉(zhuǎn)直下。
當(dāng)時(shí)初步分析,有以下幾個(gè)原因:
1. 文檔種類(lèi)多
有doc、ppt、excel、pdf,pdf也有掃描版和文字版。
doc類(lèi)的文檔相對(duì)來(lái)說(shuō)還比較容易處理,畢竟大部分內(nèi)容是文字,信息密度較高。但是也有少量圖文混排的情況。
Excel也還好處理,本身就是結(jié)構(gòu)化的數(shù)據(jù),合并單元格的情況使用程序填充了之后,每一行的信息也是完整的。
真正難處理的是ppt和pdf,ppt中包含大量架構(gòu)圖、流程圖等圖示,以及展示圖片。pdf基本上也是這種情況。
這就導(dǎo)致了大部分文檔,單純抽取出來(lái)的文字信息,呈現(xiàn)碎片化、不完整的特點(diǎn)。
2. 切分方式
如果沒(méi)有定制切分方式,則是按照一個(gè)固定的長(zhǎng)度對(duì)文本進(jìn)行切分,同時(shí)連續(xù)的文本設(shè)置一定的重疊。
這種方式導(dǎo)致了每一段文本包含的語(yǔ)義信息實(shí)際上也是不夠完整的。同時(shí)沒(méi)有考慮到文本中已包含的標(biāo)題等關(guān)鍵信息。
這就導(dǎo)致了需要被向量化的文本段,其主題語(yǔ)義并不是那么明顯,和自然形成的段落顯示出顯著的差距,從而給檢索過(guò)程造成巨大的困難。
3. 內(nèi)部知識(shí)的特殊性
大模型或者句向量在訓(xùn)練時(shí),使用的語(yǔ)料都是較為通用的語(yǔ)料。這導(dǎo)致了這些模型,對(duì)于垂直領(lǐng)域的知識(shí)識(shí)別是有缺陷的。它們沒(méi)有辦法理解企業(yè)內(nèi)部的一些專(zhuān)用術(shù)語(yǔ),縮寫(xiě)所表示的具體含義。這樣極大地影響了生成向量的精準(zhǔn)度,以及大模型輸出的效果。
4. 用戶提問(wèn)的隨意性
實(shí)際上大部分用戶在提問(wèn)時(shí),寫(xiě)下的query是較為模糊籠統(tǒng)的,其實(shí)際的意圖埋藏在了心里,而沒(méi)有完整體現(xiàn)在query中。使得檢索出來(lái)的文本段落并不能完全命中用戶想要的內(nèi)容,大模型根據(jù)這些文本段落也不能輸出合適的答案。
例如,用戶如果直接問(wèn)一句“請(qǐng)給我推薦一個(gè)酒店”,那么模型不知道用戶想住什么位置,什么價(jià)位,什么風(fēng)格的酒店,給出的答案肯定是無(wú)法滿足用戶的需求的。
問(wèn)題解決方法
對(duì)于以上問(wèn)題,我采取了多種方式進(jìn)行解決,最終應(yīng)用還是能夠較好的滿足用戶的需求。
1. 對(duì)文檔內(nèi)容進(jìn)行重新處理
針對(duì)各種類(lèi)型的文檔,分別進(jìn)行了很多定制化的措施,用于完整的提取文檔內(nèi)容。這部分基本上臟活累活,
Doc類(lèi)文檔還是比較好處理的,直接解析其實(shí)就能得到文本到底是什么元素,比如標(biāo)題、表格、段落等等。這部分直接將文本段及其對(duì)應(yīng)的屬性存儲(chǔ)下來(lái),用于后續(xù)切分的依據(jù)。
PDF類(lèi)文檔的難點(diǎn)在于,如何完整恢復(fù)圖片、表格、標(biāo)題、段落等內(nèi)容,形成一個(gè)文字版的文檔。這里使用了多個(gè)開(kāi)源模型進(jìn)行協(xié)同分析,例如版面分析使用了百度的PP-StructureV2,能夠?qū)?a href="http://www.asorrir.com/tags/te/" target="_blank">Text、Title、Figure、Figure caption、Table、Table caption、Header、Footer、Reference、Equation10類(lèi)區(qū)域進(jìn)行檢測(cè),統(tǒng)一了OCR和文本屬性分類(lèi)兩個(gè)任務(wù)。

PPT的難點(diǎn)在于,如何對(duì)PPT中大量的流程圖,架構(gòu)圖進(jìn)行提取。因?yàn)檫@些圖多以形狀元素在PPT中呈現(xiàn),如果光提取文字,大量潛藏的信息就完全丟失了。于是這里只能先將PPT轉(zhuǎn)換成PDF形式,然后用上述處理PDF的方式來(lái)進(jìn)行解析。
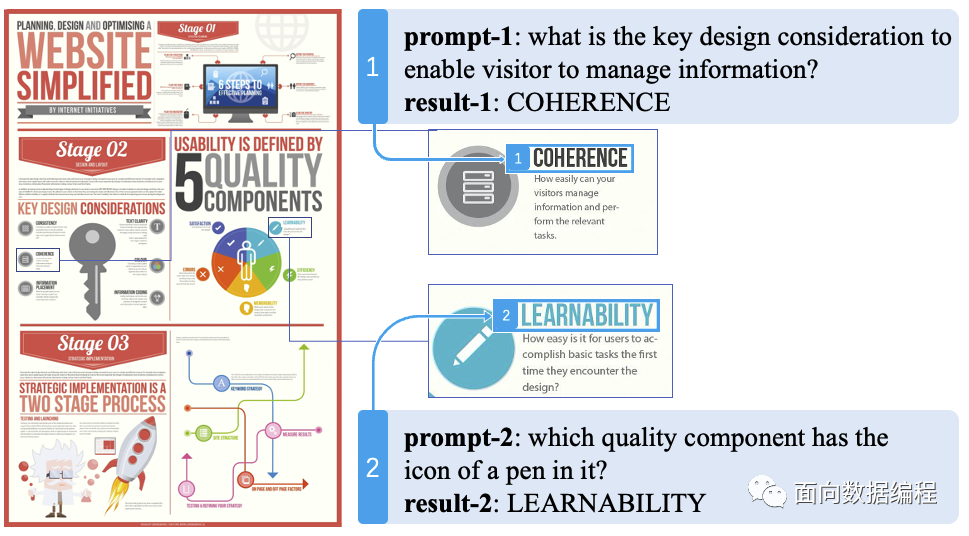
當(dāng)然,這里還沒(méi)有解決出圖片信息如何還原的問(wèn)題。大量的文檔使用了圖文混排的形式,例如上述的PPT文件,轉(zhuǎn)換成PDF后,僅僅是能夠識(shí)別出這一塊是一幅圖片,對(duì)于圖片,直接轉(zhuǎn)換成向量,不利于后續(xù)的檢索。所以我們只能通過(guò)一個(gè)較為昂貴的方案,即部署了一個(gè)多模態(tài)模型,通過(guò)prompt來(lái)對(duì)文檔中的圖片進(jìn)行關(guān)鍵信息提取,形成一段摘要描述,作為文檔圖片的索引。效果類(lèi)似下圖。
2. 語(yǔ)義切分
對(duì)文檔內(nèi)容進(jìn)行重新處理后,語(yǔ)義切分工作其實(shí)就比較好做了。我們現(xiàn)在能夠拿到的有每一段文本,每一張圖片,每一張表格,文本對(duì)應(yīng)的屬性,圖片對(duì)應(yīng)的描述。
對(duì)于每個(gè)文檔,實(shí)際上元素的組織形式是樹(shù)狀形式。例如一個(gè)文檔包含多個(gè)標(biāo)題,每個(gè)標(biāo)題又包括多個(gè)小標(biāo)題,每個(gè)小標(biāo)題包括一段文本等等。我們只需要根據(jù)元素之間的關(guān)系,通過(guò)遍歷這顆文檔樹(shù),就能取到各個(gè)較為完整的語(yǔ)義段落,以及其對(duì)應(yīng)的標(biāo)題。
有些完整語(yǔ)義段落可能較長(zhǎng),于是我們對(duì)每一個(gè)語(yǔ)義段落,再通過(guò)大模型進(jìn)行摘要。這樣文檔就形成了一個(gè)結(jié)構(gòu)化的表達(dá)形式:
| id | text | summary | source | type | image_source |
|---|---|---|---|---|---|
| 1 | 文本原始段落 | 文本摘要 | 來(lái)源文件 | 文本元素類(lèi)別(主要用于區(qū)分圖片和文本) | 圖片存儲(chǔ)位置(在回答中返回這個(gè)位置,前端進(jìn)行渲染) |
3. RAG Fusion
檢索增強(qiáng)這一塊主要借鑒了RAG Fusion技術(shù),這個(gè)技術(shù)原理比較簡(jiǎn)單,概括起來(lái)就是,當(dāng)接收用戶query時(shí),讓大模型生成5-10個(gè)相似的query,然后每個(gè)query去匹配5-10個(gè)文本塊,接著對(duì)所有返回的文本塊再做個(gè)倒序融合排序,如果有需求就再加個(gè)精排,最后取Top K個(gè)文本塊拼接至prompt。
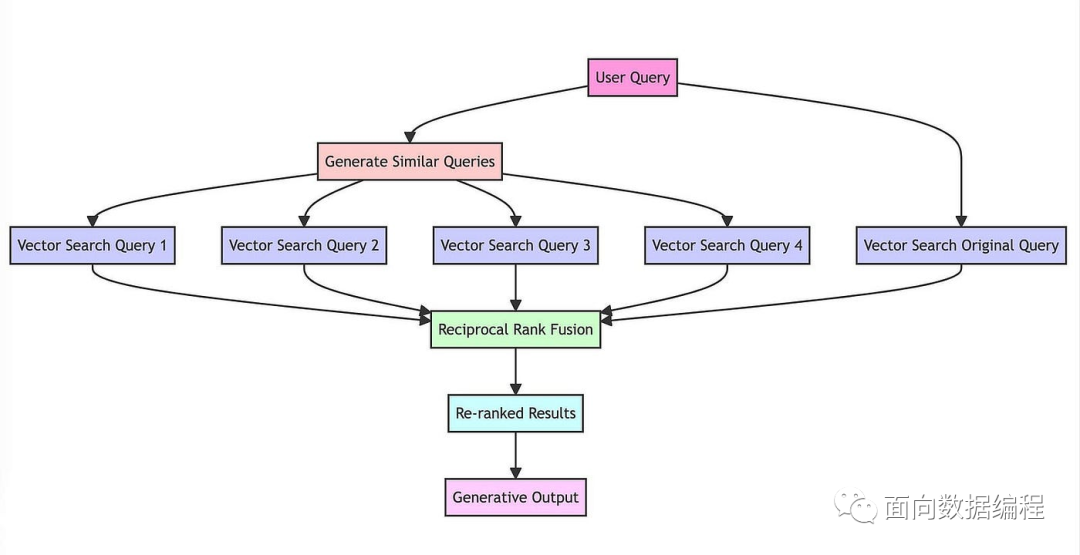
實(shí)際使用時(shí)候,這個(gè)方法的主要好處,是增加了相關(guān)文本塊的召回率,同時(shí)對(duì)用戶的query自動(dòng)進(jìn)行了文本糾錯(cuò)、分解長(zhǎng)句等功能。但是還是無(wú)法從根本上解決理解用戶意圖的問(wèn)題。
4. 增加追問(wèn)機(jī)制
這里是通過(guò)Prompt就可以實(shí)現(xiàn)的功能,只要在Prompt中加入“如果無(wú)法從背景知識(shí)回答用戶的問(wèn)題,則根據(jù)背景知識(shí)內(nèi)容,對(duì)用戶進(jìn)行追問(wèn),問(wèn)題限制在3個(gè)以?xún)?nèi)”。這個(gè)機(jī)制并沒(méi)有什么技術(shù)含量,主要依靠大模型的能力。不過(guò)大大改善了用戶體驗(yàn),用戶在多輪引導(dǎo)中逐步明確了自己的問(wèn)題,從而能夠得到合適的答案。
5. 微調(diào)Embedding句向量模型
這部分主要是為了解決垂直領(lǐng)域特殊詞匯,在通用句向量中會(huì)權(quán)重過(guò)大的問(wèn)題。比如有個(gè)通用句向量模型,它在訓(xùn)練中很少見(jiàn)到“SAAS”這個(gè)詞,無(wú)論是文本段和用戶query,只要提到了這個(gè)詞,整個(gè)句向量都會(huì)被帶偏。舉個(gè)例子:
假如一個(gè)用戶問(wèn)的是:我是一個(gè)SAAS用戶,我希望訂購(gòu)一個(gè)云存儲(chǔ)服務(wù)。由于SAAS的權(quán)重很高,使得檢索匹配時(shí)候,模型完全忽略了后面的那句話,才是真實(shí)的用戶需求。返回的內(nèi)容可能是SAAS的介紹、SAAS的使用手冊(cè)等等。
這里的微調(diào)方法使用的數(shù)據(jù),是讓大模型對(duì)語(yǔ)義分割的每一段,形成問(wèn)答對(duì)。用這些問(wèn)答對(duì)構(gòu)建了數(shù)據(jù)集進(jìn)行句向量的訓(xùn)練,使得句向量能夠盡量理解垂直領(lǐng)域的場(chǎng)景。
總結(jié)
經(jīng)過(guò)這么一套組合拳,系統(tǒng)的回答效果從一開(kāi)始的完全給不了幫助以及胡說(shuō)八道,到了現(xiàn)在可以參考的程度。但是與用戶實(shí)際期望還是相差甚遠(yuǎn)。
這里不由得讓我思考了下整個(gè)過(guò)程,RAG的本意是想讓模型降低幻想,同時(shí)能夠?qū)崟r(shí)獲取內(nèi)容,使得大模型給出合適的回答。
在嚴(yán)謹(jǐn)場(chǎng)景中,precision比recall更重要。
如果大模型胡亂輸出,類(lèi)比傳統(tǒng)指標(biāo),就好比recall高但是precision低,但是限制了大模型的輸出后,提升了precision,recall降低了。所以給用戶造成的觀感就是,大模型變笨了,是不是哪里出問(wèn)題了。
總之,這個(gè)balance很難取,我對(duì)比了下市面主流的一些基于單篇文檔的知識(shí)庫(kù)問(wèn)答,比如WPS AI,或者海外的ChatDoc。我發(fā)現(xiàn)即使基于單篇文檔回答,它們?cè)谖覀兇怪鳖I(lǐng)域的文檔的幻想問(wèn)題還是很?chē)?yán)重。但是輸出的答案不認(rèn)真看的話,確實(shí)挺驚艷。例如問(wèn)個(gè)操作步驟問(wèn)題,文檔壓根沒(méi)這個(gè)內(nèi)容,但是它一步步輸出的極其自信。
反正最后就想感慨一下,RAG確實(shí)沒(méi)有想的那么容易。
-
向量
+關(guān)注
關(guān)注
0文章
55瀏覽量
11849 -
檢索
+關(guān)注
關(guān)注
0文章
27瀏覽量
13255 -
大模型
+關(guān)注
關(guān)注
2文章
3025瀏覽量
3824
原文標(biāo)題:對(duì)于大模型RAG技術(shù)的一些思考
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
TaD+RAG-緩解大模型“幻覺(jué)”的組合新療法
【大語(yǔ)言模型:原理與工程實(shí)踐】大語(yǔ)言模型的應(yīng)用
名單公布!【書(shū)籍評(píng)測(cè)活動(dòng)NO.52】基于大模型的RAG應(yīng)用開(kāi)發(fā)與優(yōu)化
【「基于大模型的RAG應(yīng)用開(kāi)發(fā)與優(yōu)化」閱讀體驗(yàn)】+大模型微調(diào)技術(shù)解讀
【「基于大模型的RAG應(yīng)用開(kāi)發(fā)與優(yōu)化」閱讀體驗(yàn)】+Embedding技術(shù)解讀
【「基于大模型的RAG應(yīng)用開(kāi)發(fā)與優(yōu)化」閱讀體驗(yàn)】+第一章初體驗(yàn)
【「基于大模型的RAG應(yīng)用開(kāi)發(fā)與優(yōu)化」閱讀體驗(yàn)】RAG基本概念
《AI Agent 應(yīng)用與項(xiàng)目實(shí)戰(zhàn)》閱讀心得3——RAG架構(gòu)與部署本地知識(shí)庫(kù)
關(guān)于MCU,給研發(fā)提供一些思考吧!
《 AI加速器架構(gòu)設(shè)計(jì)與實(shí)現(xiàn)》+學(xué)習(xí)和一些思考
未來(lái)寬帶移動(dòng)通信網(wǎng)絡(luò)技術(shù)發(fā)展的一些思考
一些區(qū)塊鏈公鏈技術(shù)發(fā)展的思考
有關(guān)Redis的一些思考和理解
什么是RAG,RAG學(xué)習(xí)和實(shí)踐經(jīng)驗(yàn)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論