") 全面解析大語言模型(LLM)
全面解析大語言模型(LLM)
作者:野風(fēng)
本文是自己在學(xué)習(xí)LLM時(shí),閱讀《A Survey of Large Language Models》和其他相關(guān)材料時(shí)的筆記,力求對構(gòu)建LLM涉及的主要環(huán)節(jié)有一個(gè)大顆粒度的全景感知,一些比較關(guān)鍵或者感興趣的話題會(huì)附上一些推薦閱讀的博客。希望能根據(jù)這篇博客,讀者也能按圖索驥式的去學(xué)習(xí)LLM。
LLM涌現(xiàn)出的3大能力
In-context learning:在GPT-3中正式被提出。在不需要重新訓(xùn)練的情況下,通過自然語言指令,并帶幾個(gè)期望輸出的樣例,LLM就能夠?qū)W習(xí)到這種輸入輸出關(guān)系,新的指令輸入后,就能輸出期望的輸出。
Instruction following:通過在多種任務(wù)數(shù)據(jù)集上進(jìn)行指令微調(diào)(instruction tuning),LLM可以在沒有見過的任務(wù)上,通過指令的形式表現(xiàn)良好,因此具有較好的泛化能力。
Step-by-step reasoning:通過思維鏈(chain-of-thought)提示策略,即把大任務(wù)分解成一步一步小任務(wù),讓模型think step by step得到最終答案。
LLM的關(guān)鍵技術(shù)
Scaling:更多的模型參數(shù)、數(shù)據(jù)量和訓(xùn)練計(jì)算,可以有效提升模型效果。
Training:分布式訓(xùn)練策略及一些提升訓(xùn)練穩(wěn)定性和效果的優(yōu)化trick。另外還有GPT-4也提出去建立一些特殊的工程設(shè)施通過小模型的表現(xiàn)去預(yù)測大模型的表現(xiàn)(predictable scaling)。
Ability eliciting:能力引導(dǎo)。設(shè)計(jì)合適的任務(wù)指令或具體的上下文學(xué)習(xí)策略可以激發(fā)LLM在龐大預(yù)料上學(xué)習(xí)到的能力。
Alignment tuning:對齊微調(diào)。為了避免模型輸出一些不安全或者不符合人類正向價(jià)值觀的回復(fù),InstructGPT利用RLHF(reinforcement learning with human feedback)技術(shù)實(shí)現(xiàn)這一目的。
Tools manipulation:工具操作。為了彌補(bǔ)模型不擅長非文本輸出任務(wù)和實(shí)時(shí)信息缺失的問題,讓模型可以使用計(jì)算器、搜索引擎或者給模型安裝插件等工具
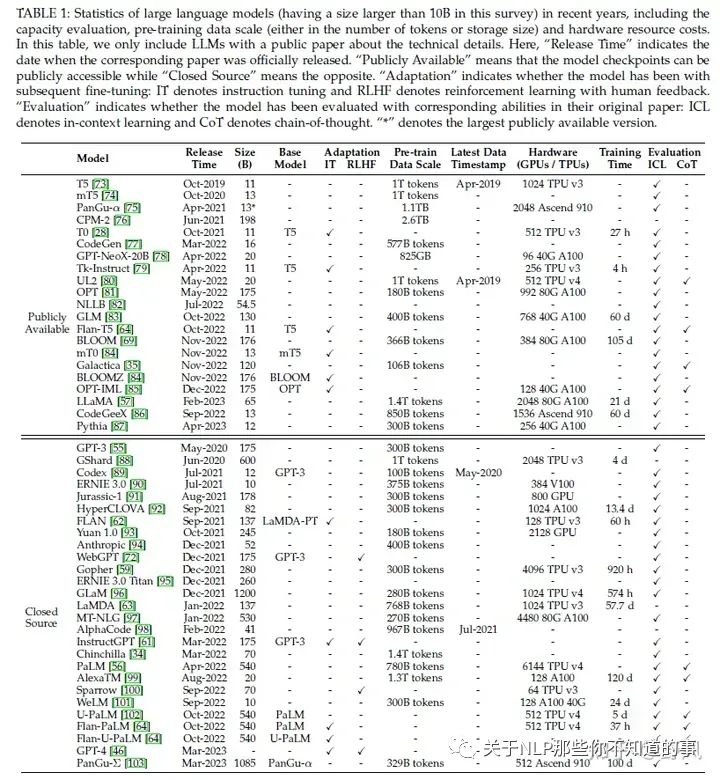
OpenAI GPT系列模型發(fā)展歷程
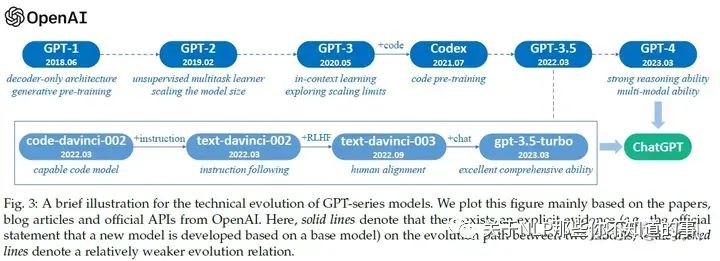
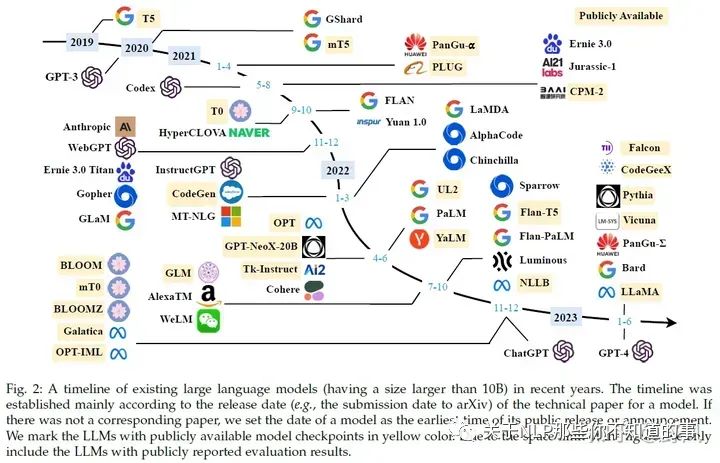
推薦閱讀
拆解追溯 GPT-3.5 各項(xiàng)能力的起源 https://yaofu.notion.site/GPT-3-5-360081d91ec245f29029d37b54573756
GPT / GPT-2 / GPT-3 / InstructGPT 進(jìn)化之路 https://zhuanlan.zhihu.com/p/609716668
LLM訓(xùn)練一般流程
Andrej Karpathy在他的演講State of GPT中分享了GPT大模型的訓(xùn)練pipline,可以作為如何訓(xùn)練LLM的一個(gè)步驟全景圖,后文內(nèi)容也是圍繞這些步驟進(jìn)行展開的

演講內(nèi)容記錄:
資源
模型/API資源
推薦閱讀:
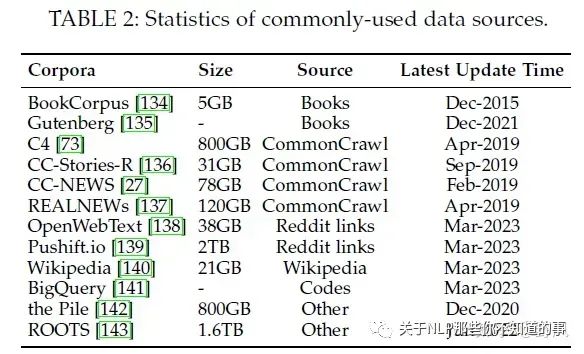
數(shù)據(jù)集
分為六類:Books, CommonCrawl, Reddit links, Wikipedia, Code, and others.
推薦閱讀
庫
預(yù)訓(xùn)練
數(shù)據(jù)預(yù)處理
預(yù)訓(xùn)練數(shù)據(jù)包括通用文本數(shù)據(jù),比如網(wǎng)頁信息文本、對話文本還有書籍,另外還有專業(yè)文本數(shù)據(jù),比如多語言文本、科學(xué)領(lǐng)域文本、代碼等。對于來自不同地方,多種格式類型的數(shù)據(jù),需要做很仔細(xì)的數(shù)據(jù)預(yù)處理,不然會(huì)對模型效果產(chǎn)生很大的影響。

推薦閱讀:
模型架構(gòu)

基于Transformer架構(gòu)的LLM可以分為3類:
目前大部分模型都是基于Causal Decoder,但為什么比其他架構(gòu)好,缺乏理論支撐。Long Context目前是基于Transformer結(jié)果模型的一大缺點(diǎn),受限于較長時(shí)間和內(nèi)存的資源需求。LLM能編碼Long Context的能力稱為extrapolation capability。
推薦閱讀
模型訓(xùn)練
GPT-4相關(guān)技術(shù)
已下截圖來自開源項(xiàng)目MetaGPT作者直播分享
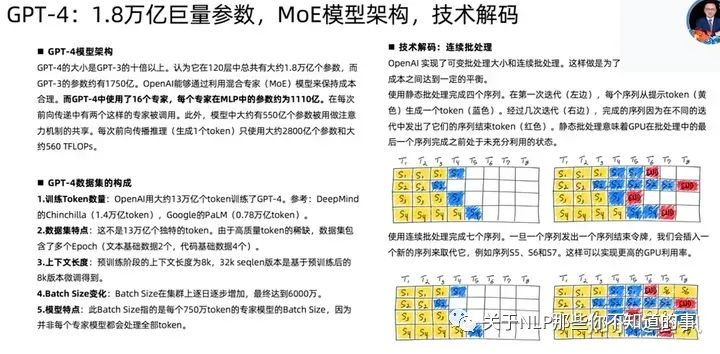
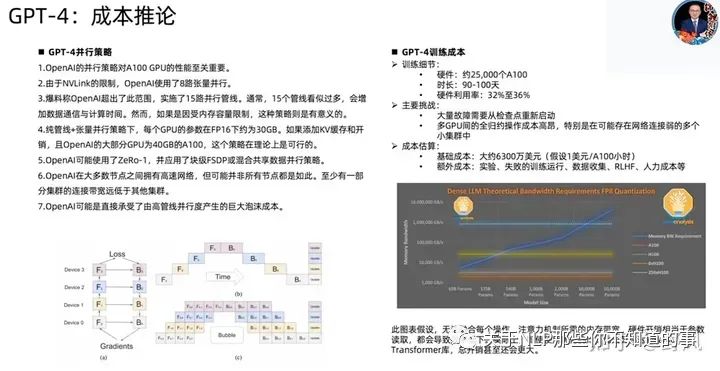
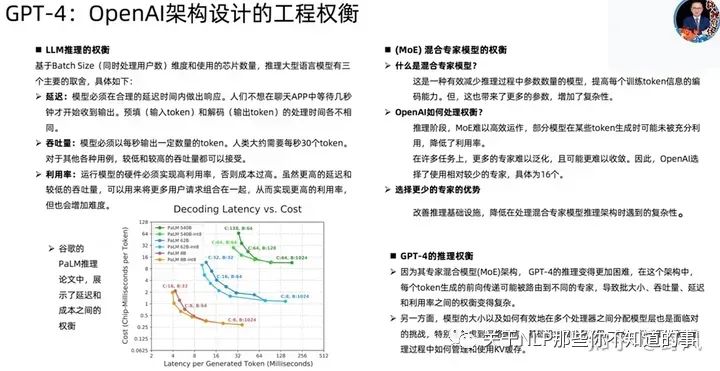
Adaptation of LLMs
Instruction Tuning
指令微調(diào)指的是使用一些自然語言描述的指令形式樣本去用監(jiān)督學(xué)習(xí)的方式微調(diào)預(yù)訓(xùn)練大模型(base model),經(jīng)過指令精調(diào)后,LLM能在一些未見過的任務(wù)上表現(xiàn)較好的能力,甚至是多語言場景。
指令形式的樣本實(shí)例
包含
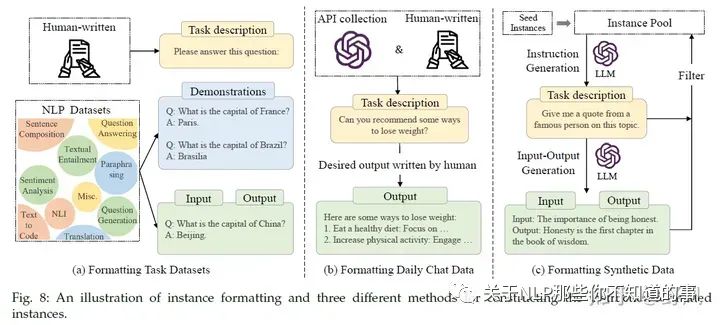
指令樣本的關(guān)鍵點(diǎn):
指令精調(diào)可以看做是一個(gè)有監(jiān)督訓(xùn)練的過程,相比于預(yù)訓(xùn)練過程,它的訓(xùn)練目標(biāo)是seq2seq loss,同時(shí)也需要更小的batch size和learning rate,關(guān)于attention的使用也有差別,下面是幾個(gè)訓(xùn)練時(shí)的做法
一些效果
對self-instruct指令進(jìn)行效果提升的策略
指令微調(diào)建議:
要在 LLMs 上進(jìn)行指令調(diào)優(yōu),可以根據(jù)下表 中關(guān)于所需 GPU 數(shù)量和調(diào)優(yōu)時(shí)間的基本統(tǒng)計(jì)數(shù)據(jù)來準(zhǔn)備計(jì)算資源。設(shè)置好開發(fā)環(huán)境后,建議初學(xué)者按照 Alpaca 軟件倉庫的代碼進(jìn)行指令調(diào)優(yōu)。隨后,應(yīng)選擇基礎(chǔ)模型并構(gòu)建指令數(shù)據(jù)集,當(dāng)用于訓(xùn)練的計(jì)算資源有限時(shí),用戶可以利用 LoRA 進(jìn)行參數(shù)高效調(diào)整。至于推理,用戶可以進(jìn)一步使用量化方法,在更少或更小的 GPU 上部署 LLM。

Alignment Tuning
對齊微調(diào)是為了讓LLM的輸出更符合人類價(jià)值觀和偏好(helpful,honest, and harmless)),減少虛假、不準(zhǔn)確或者避免生成一些有害的信息。但這種對齊微調(diào)也會(huì)一定程度減弱模型的泛化程度,一般稱這種現(xiàn)象為alignment tax。
人類反饋收集
對工人打標(biāo)員要求會(huì)比較高,如有一定的教育水平,會(huì)英文等。標(biāo)注的方式可以分為兩種:
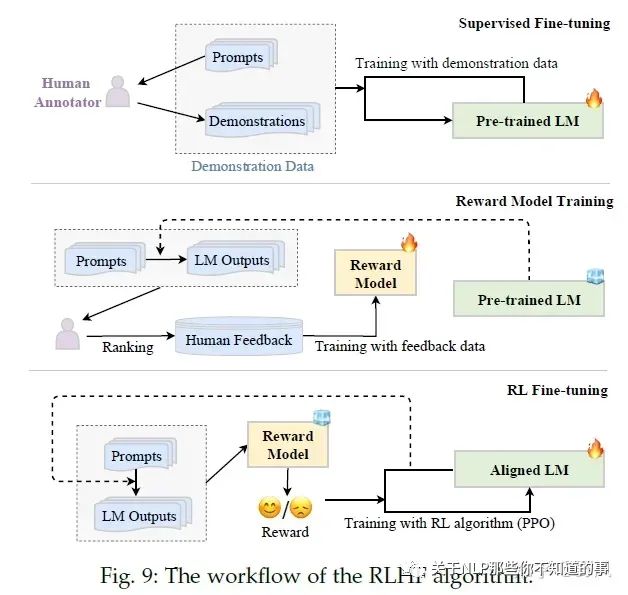
RLHF
RLHF(Reinforcement Learning from Human Feedback)系統(tǒng)主要包含三個(gè)關(guān)鍵元素:需要被對齊精調(diào)的預(yù)訓(xùn)練LM、通過人類反饋學(xué)習(xí)的的獎(jiǎng)勵(lì)模型和強(qiáng)化學(xué)習(xí)訓(xùn)練LM。
RLHF分為三個(gè)步驟:
Pretraining
該步驟占99%的訓(xùn)練時(shí)間
對LLM涉及的一些數(shù)字有個(gè)粗略印象:每個(gè)LLM開發(fā)者都應(yīng)該知道的數(shù)字
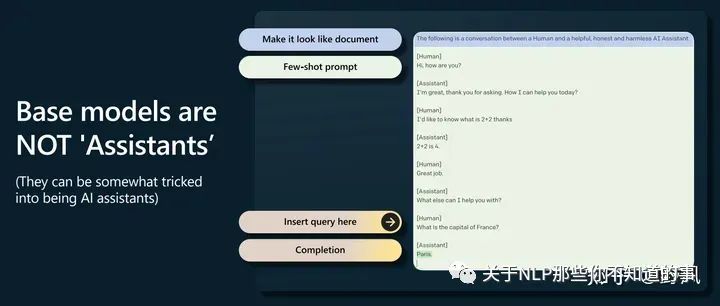
GPT-2開啟了prompting 高于finetuning的時(shí)代
base model不會(huì)回答問題,只會(huì)去補(bǔ)全一個(gè)文檔,經(jīng)常會(huì)用更多問題去回答一個(gè)問題,但是可以通過提示工程觸發(fā)它完成一些任務(wù),如下圖這樣做。(這里有點(diǎn)像CoT了
Supervised Finetuning,對應(yīng)后文Instruction Tuning
在高質(zhì)量少量數(shù)據(jù)上finetuning,讓模型更像一個(gè)助手
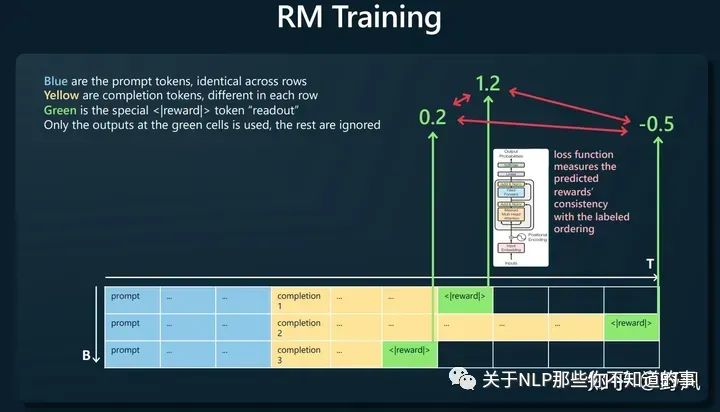
Reward Modeling,對應(yīng)后文Alignment Tuning
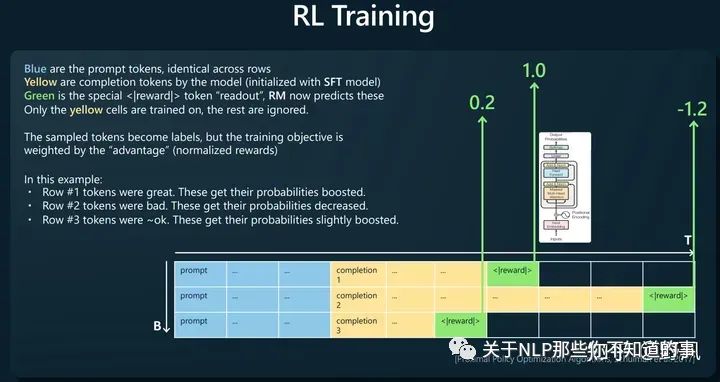
人工對同一prompt的多條響應(yīng)進(jìn)行排序,如下圖構(gòu)建訓(xùn)練樣本,讓獎(jiǎng)勵(lì)模型去預(yù)測<|reward|>,loss函數(shù)則去比較這個(gè)預(yù)測值大小與人工排序的一致性。
Reinforcement Learning
使用RM對SFT模型生成的結(jié)果進(jìn)行打分,使用PPO算法以最大化rewards為目標(biāo)進(jìn)行訓(xùn)練,得到最終模型
判斷比生成更容易。比如判斷一首詩壞好壞比寫一首詩更容易。所以這也解釋了為什么使用RLHF
base model相比RLHF model有更多的“熵”,所以能生成更多樣的內(nèi)容
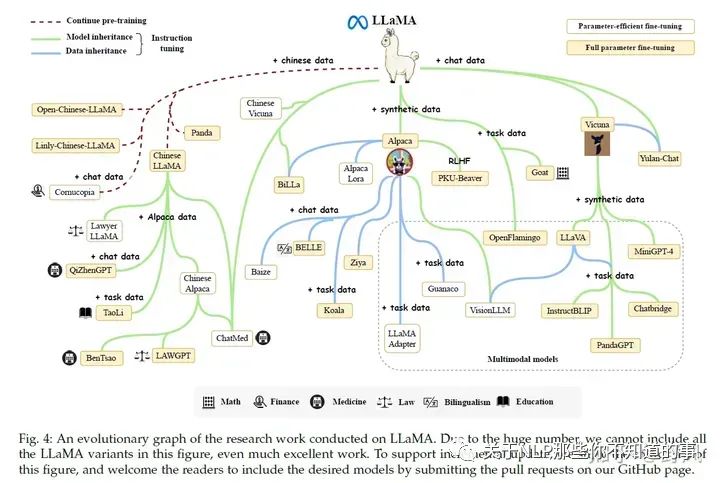
LLaMA (65B version)、LLaMA 2:目前開源模型中,生態(tài)最好。很多基于LLaMA小版本的指令精調(diào)定制模型,如果需要LLaMA適配非英語,一般需要擴(kuò)充詞表和在目標(biāo)語言數(shù)據(jù)進(jìn)行指令精調(diào)。
Flan-T5 (11B version):可以作為指令精調(diào)的首選模型
CodeGen (11B version):自回歸模型,可作為代碼生成的模型。同時(shí)發(fā)布了MTPB數(shù)據(jù)集,用于評測大模型代碼生成能力
NLLB:54.5B,機(jī)器翻譯大模型
mT0 (13B version):在多語言任務(wù)上進(jìn)行了多語言指令精調(diào)
PanGu-α:中文任務(wù)上表現(xiàn)了良好的zero-shot 和 few-shot性能。最大200B,公開的13B
Falcon(7B、40B):數(shù)據(jù)清理工作做的好,RefinedWeb數(shù)據(jù)集
GPT-NeoX-20B
OPT (175B version):及其指令精調(diào)版本OPT-IML
BLOOM (176B version) BLOOMZ (176B version):可以作為多語言模型的基礎(chǔ)模型
GLM:中文對話模型ChatGLM2-6B
GPT-3 series:ada, babbage(GPT3-1B), curie(GPT3-6.7B), davinci (the most powerful version in GPT-3 series 178B), text-ada-001, text-babbage-001, and text-curie-001。前四個(gè)可以在OpenAI的服務(wù)上作為基礎(chǔ)模型進(jìn)行微調(diào)。code-cushman-001、code-davinci-002用于代碼生成。
GPT-3.5 series:基礎(chǔ)模型code-davinci-002,三個(gè)加強(qiáng)版text-davinci-002, text-davinci-003, and gpt-3.5-turbo-0301(ChatGPT客戶端背后的模型)
GPT-4 series:gpt-4, gpt-4-0314, gpt-4-32k, and gpt-4-32k-0314
想學(xué)習(xí)大語言模型(LLM),應(yīng)該從哪個(gè)開源模型開始? https://www.zhihu.com/question/608820310
大模型訓(xùn)練的有哪些數(shù)據(jù)集?LLM大模型訓(xùn)練有哪些通用語料? https://www.zhihu.com/question/609604943/answers/updated
Transformers:Hugging Face維護(hù)的,社區(qū)活躍,有眾多基于Transformer架構(gòu)的模型實(shí)現(xiàn),使用便捷
大模型訓(xùn)練框架:DeepSpeed(Microsoft)、Megatron-LM(NVIDIA)、JAX(Google)、Colossal-AI(HPC-AI Tech)、BMTrain(OpenBMB)、FastMoE等
PyTorch、TensorFlow、MXNet 、 PaddlePaddle 、MindSpore、OneFlow
大模型時(shí)代下數(shù)據(jù)的重要性:Data-centric Artificial Intelligence: A Survey 這篇綜述的一個(gè)講解,并在后面介紹了一些與大模型有關(guān)的數(shù)據(jù)方面的工作,即相關(guān)工作中心都是在研究怎么玩轉(zhuǎn)數(shù)據(jù) https://zhuanlan.zhihu.com/p/639207933
Causal Decoder:從左到右的單向注意力。自回歸語言模型,預(yù)訓(xùn)練和下游應(yīng)用一致,生成類任務(wù)效果好。訓(xùn)練效率高。Zero-Shot能力強(qiáng),涌現(xiàn)能力。如GPT系列、LLaMA、BLOOM、OPT
Encoder-Decoder:輸入雙向注意力,輸出單向注意力。對問題的編碼理解更充分,在偏理解的NLP任務(wù)上表現(xiàn)相對較好,缺點(diǎn)是在長文本生成任務(wù)上效果較差,訓(xùn)練效率低。如T5、Flan-T5、BART
Prefix Decoder:輸入雙向注意力,輸出單向注意力。前兩者的折中。訓(xùn)練效率也低。如GLM、ChatGLM、U-PaLM
[Transformer 101系列] 初探LLM基座模型 https://zhuanlan.zhihu.com/p/640784855
Batch Training:一般會(huì)設(shè)一個(gè)較大的數(shù)2048 examples~4M tokens,GPT-3中還介紹了一種動(dòng)態(tài)增大batch size的方法
learning rate:預(yù)訓(xùn)練時(shí)一般都會(huì)用warm-up和decay策略,最大值一般在5e-5到1e-4之間
梯度裁剪:通常將梯度裁剪為1
optimizer:Adam 和 AdamW。權(quán)重衰減系數(shù)設(shè)置為0.1。AdamW相當(dāng)于Adam加了一個(gè)L2正則項(xiàng)
穩(wěn)定性:weight decay、gradient clipping。LLM訓(xùn)練的時(shí)候還會(huì)碰到loss spike問題,有些簡單的解決辦法就是重新訓(xùn)練,重最近的一個(gè)checkpoint開始,跳過發(fā)生loss spike的數(shù)據(jù)。GLM工作中發(fā)現(xiàn),embedding layer中不正常的梯度會(huì)導(dǎo)致這個(gè)問題,通過縮減這個(gè)梯度,會(huì)環(huán)節(jié)spike的問題
Scalable Training Techniques:
3D Parallelism:指結(jié)合data parallelism, pipeline parallelism(GPipe、PipeDream), 和 tensor parallelism(Megatron-LM、Colossal-AI)三種并行方法
ZeRO:data parallelism場景下,每個(gè)GPU都會(huì)存模型參數(shù)、模型梯度和優(yōu)化器參數(shù),但這些數(shù)據(jù)在每個(gè)GPU上都存一遍是存在冗余的,ZeRO就是去解決這個(gè)問題。pytorch的FSDP也是做了這樣的優(yōu)化。
Mixed Precision Training:BF16 vs FP16
predictable scaling:GPT4提出的通過小模型預(yù)測大模型的性能,減少出錯(cuò)帶來的損失
任務(wù)描述(即指令)
(optional) 示例輸入
輸出
(optional) 解釋
擴(kuò)大指令范圍:增加指令的任務(wù)種類數(shù)、加強(qiáng)對任務(wù)描述的長度、結(jié)構(gòu)和創(chuàng)意性對加強(qiáng)LLM泛化能力很重要
格式的設(shè)計(jì):增加任務(wù)描述和對輸入輸出的解釋有幫助,但在指令中加入其他內(nèi)容(如應(yīng)避免的事項(xiàng)、原因和建議)對效果提示幫助有限甚至有負(fù)向影響。對于需要推理的任務(wù),同時(shí)加入思維鏈和非思維鏈的樣例,也有助于提升效果
邀請人去注釋人類需要的任務(wù),比只使用數(shù)據(jù)集里的任務(wù)要強(qiáng)
平衡不同任務(wù)的指令樣本數(shù)量,examples-proportional mixing strategy
將指令微調(diào)和預(yù)訓(xùn)練結(jié)合。OPT-IML在指令微調(diào)的時(shí)候結(jié)合預(yù)訓(xùn)練的數(shù)據(jù);GLM-130B和Galactica直接將指令微調(diào)的數(shù)據(jù)作為預(yù)訓(xùn)練的一小部分?jǐn)?shù)據(jù)去預(yù)訓(xùn)練LLM
僅使用英文指令精調(diào),可以提升多語言任務(wù)的表現(xiàn)
在垂直專業(yè)領(lǐng)域進(jìn)行指令微調(diào),可以提升LLM在該領(lǐng)域的表現(xiàn)
增強(qiáng)指令的復(fù)雜度,比如增加更多任務(wù)要求和更多的推理步驟
增加指令話題的多樣性
增加指令的數(shù)量,不一定有效
平衡指令的復(fù)雜程度。通過困惑度去除過于簡單和復(fù)雜的指令
基于問題的:研究人員設(shè)計(jì)一系列問題讓打標(biāo)人員去回答
基于規(guī)則的:不僅打標(biāo)員去選擇一個(gè)最好的輸出(LLMs生成的),并且通過提前設(shè)定一系列規(guī)則去過濾模型生成的不符合人類價(jià)值偏好的結(jié)果。
(可選)Supervised fine-tuning:將收集的有監(jiān)督指令集,包含指令+人類回答作為預(yù)訓(xùn)練模型fine-tuning的數(shù)據(jù),提升LM初始化能力
Reward model training:采樣指令(來自有監(jiān)督指令集或者人工生成)輸入LM,LM生成若干個(gè)結(jié)果,標(biāo)注員對這些結(jié)果進(jìn)行排序,從而訓(xùn)練獎(jiǎng)勵(lì)模型
RL fine-tuning:將對齊過程視為一個(gè)強(qiáng)化學(xué)習(xí)過程,預(yù)訓(xùn)練LM作為policy,指令作為其輸入,其輸出指令的回答,action space是所有詞表,state是當(dāng)前已經(jīng)生成的tokens序列,獎(jiǎng)勵(lì)reward由第二步的獎(jiǎng)勵(lì)模型給出。InstructGPT使用PPO算法優(yōu)化,為了避免最終的Aligned LM與初始預(yù)訓(xùn)練LM表現(xiàn)差距過大,還加入了兩者對同一指令輸入得到的輸出的KL散度作為懲罰。
注意2、 3步可以多次迭代進(jìn)行,以得到更好的結(jié)果。由于RL并不太穩(wěn)定,也有工作使用其他有監(jiān)督的方法取到RL進(jìn)行微調(diào)。
推薦閱讀:
RLHF實(shí)踐:比較詳細(xì)的講了強(qiáng)化學(xué)習(xí)微調(diào)階段的原理和踩的坑,具有實(shí)踐指導(dǎo)意義 https://zhuanlan.zhihu.com/p/635569455
從零實(shí)現(xiàn)LLM-RLHF https://zhuanlan.zhihu.com/p/649665766
基于 LoRA 的 RLHF:可以自己跟著動(dòng)手玩一玩的教程 https://zhuanlan.zhihu.com/p/644900128
反思RLHF,如何更加高效訓(xùn)練有偏好的LLM
如何有效進(jìn)行RLHF的數(shù)據(jù)標(biāo)注?:對數(shù)據(jù)標(biāo)注過程有一個(gè)非常有指導(dǎo)意義的介紹
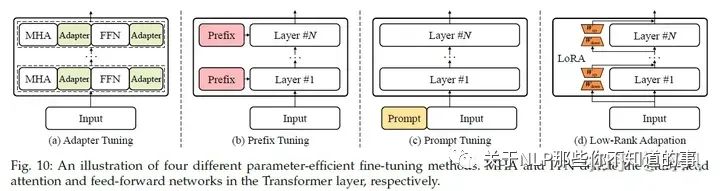
Parameter-Efficient Model Adaptation
LLM參數(shù)量很大,想要去做全量參數(shù)的fine turning代價(jià)很大,所以需要一些高效經(jīng)濟(jì)的方法。
一些PEFT(Parameter-Efficient Fine-Tuning)方法
Adapter Tuning
Prefix Tuning
Prompt Tuning
Low-Rank Adapation(LoRA)
推薦閱讀:
【萬字長文】LLaMA, ChatGLM, BLOOM的參數(shù)高效微調(diào)實(shí)踐 https://zhuanlan.zhihu.com/p/635710004
大模型參數(shù)高效微調(diào)技術(shù)原理綜述(六)-MAM Adapter、UniPELT - 知乎 (zhihu.com) https://zhuanlan.zhihu.com/p/636362246
讓天下沒有難Tuning的大模型-PEFT技術(shù)簡介 - 知乎 (zhihu.com) https://zhuanlan.zhihu.com/p/618894319
Memory-Efficient Model Adaptation
由于LLM的參數(shù)量巨大,在推理的時(shí)候非常占用內(nèi)存,導(dǎo)致其很難在應(yīng)用中部署,所以需要一些減少內(nèi)存占用的方法,比如LLM中的量化壓縮技術(shù)
quantization-aware training (QAT),需要額外的全模型重訓(xùn)練
Efficient fine-tuning enhanced quantization,QLoRA
Quantization-aware training (QAT) for LLMs
post-training quantization (PTQ),不需要重訓(xùn)練
Mixed-precision decomposition
Fine-grained quantization
Balancing the quantization difficulty
Layerwise quantization
LLM由于參數(shù)量巨大,更適合PTQ。另外,LLM 呈現(xiàn)出截然不同的激活模式(即較大的離群特征),因此量化 LLM(尤其是隱層激活)變得更加困難。
一些經(jīng)驗(yàn)
INT8 權(quán)重量化通常可以在 LLM 上產(chǎn)生非常好的結(jié)果,而較低精度權(quán)重量化的性能則取決于特定的方法
激活函數(shù)比權(quán)重更難量化
Efficient fine-tuning enhanced quantization是提升量化LLM一個(gè)較好的方法
開源量化庫:
Bitsandbytes
GPTQ-for-LLaMA
AutoGPTQ
llama.cpp
利用
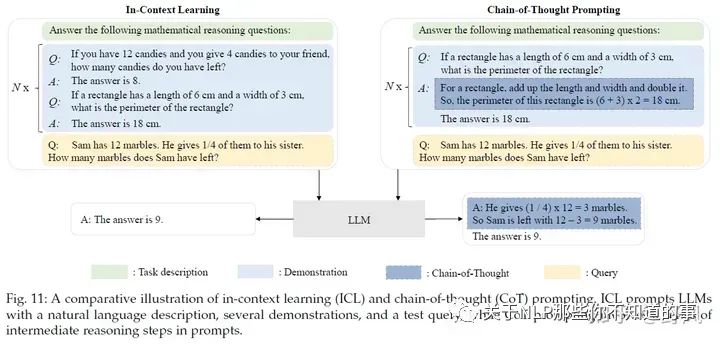
In-Context Learning
In-Context Learning(ICL)的prompt由任務(wù)描述和若干個(gè)QA示例(demonstration)組成,LLM可以識別這些內(nèi)容并理解,無需進(jìn)行梯度更新(區(qū)別于instruction tuning)就能在新的問題(Q)上進(jìn)行回答(A)。
樣例的設(shè)計(jì)
Demonstration Selection
Heuristic approaches:一些研究采用基于 k-NN 的檢索器來選擇與query語義相關(guān)的示例。也會(huì)同時(shí)考慮相關(guān)性和多樣性
LLM-based approaches:利用 LLM,根據(jù)添加樣例后的性能增益,直接測量每個(gè)樣例的信息量。先根據(jù)無監(jiān)督的方法(如BM25)召回一些相似的樣例,然后使用一個(gè)dense retriever(由LLM打標(biāo)的正負(fù)樣本)去查找。
Demonstration Format
最直接的方法就是給一些QA樣例對
使用CoT,增加對任務(wù)的描述去增強(qiáng)推理能力
Auto-CoT, 通過"Let's think step by step",得到子問題
Demonstration Order LLMs有時(shí)傾向于去重復(fù)最后一個(gè)樣例的答案
通過query與樣例之間的embedding space的相似度排序
最大限度地減少壓縮和傳輸任務(wù)標(biāo)簽所需的代碼長度,其靈感來自信息論
底層機(jī)制
How Pre-Training Affects ICL?:
GPT-3中發(fā)現(xiàn)在大規(guī)模的預(yù)訓(xùn)練模型中會(huì)出現(xiàn)ICL,但后面也有研究發(fā)現(xiàn),小規(guī)模模型在特定設(shè)計(jì)的訓(xùn)練任務(wù)上繼續(xù)預(yù)訓(xùn)練或者微調(diào)后也能出現(xiàn)ICL能力。
另外,ICL的出現(xiàn)可以理論上看做是預(yù)訓(xùn)練過程中,模型在學(xué)習(xí)具有長距離語義聯(lián)系的文檔過程中誕生的。
也有研究認(rèn)為,在擴(kuò)大訓(xùn)練參數(shù)和數(shù)據(jù)的時(shí)候,LLM通過“下一個(gè)詞預(yù)測”訓(xùn)練任務(wù),模型可以從字或詞如何組成具有語言含義的句子學(xué)習(xí)過程中得到ICL能力。
How LLMs Perform ICL?
Task recognition:有研究認(rèn)為在預(yù)訓(xùn)練數(shù)據(jù)中包含了標(biāo)識任務(wù)(task)的隱變量,而LLM可以根據(jù)demonstration捕捉到這些變量,從而能夠識別ICL中的任務(wù)。所以,有部分研究認(rèn)為LLM不是從demonstration中學(xué)習(xí),而是識別任務(wù),所以有實(shí)驗(yàn)表明即使prompt template是無關(guān)的甚至是有誤導(dǎo)的,LLM表現(xiàn)也很好
Task learning:ICL 可以解釋如下:通過前向計(jì)算,LLM 生成與demonstration相關(guān)的元梯度,并通過注意力機(jī)制隱式地執(zhí)行梯度下降。LLM 本質(zhì)上是在預(yù)訓(xùn)練過程中通過參數(shù)對隱式模型進(jìn)行編碼。利用 ICL 中提供的示例,LLM 可以實(shí)施梯度下降等學(xué)習(xí)算法,或直接計(jì)算閉式解,以便在前向計(jì)算中更新這些模型。
Chain-of-Thought Prompting
CoT 并非像 ICL 那樣簡單地用輸入-輸出對來構(gòu)建提示,而是將可能導(dǎo)致最終輸出的中間推理步驟納入提示中。
In-context Learning with CoT
Few-shot CoT:demonstration由?input, output? 變成 ?input, CoT, output?,區(qū)別見上圖。
使用不同類型的CoT(不同的推理路徑)和使用復(fù)雜的CoT都可以加強(qiáng)效果。
為了減少手工提供CoT,可以使用Auto-CoT。
self-consistency技巧:首先生成幾條推理路徑,然后對所有答案進(jìn)行綜合(例如,通過在這些路徑中投票選出最一致的答案),可以較大提升CoT效果。
Zero-shot CoT:LLM 首先在 "Let’s think step by step"的提示下產(chǎn)生推理步驟,然后在 "Therefore, the answer is "的提示下得出最終答案。
底層機(jī)制
When CoT works for LLMs?:在需要做一步一步推理的任務(wù)中(算術(shù)推理、常識推理和符號推理),CoT會(huì)表現(xiàn)不錯(cuò),但那些如果不需要復(fù)雜推理的任務(wù),加了CoT反而會(huì)不好
Why LLMs Can Perform CoT Reasoning?:廣泛認(rèn)為CoT能力來自于在代碼數(shù)據(jù)上訓(xùn)練,但目前缺乏消融實(shí)驗(yàn)的證明。CoT包含三個(gè)元素symbols、patterns和text,后兩個(gè)對效果影響最大,text幫助LLM生成有用的pattern,pattern幫助LLM理解任務(wù)和生成幫助解決任務(wù)的text
Planning for Complex Task Solving
對于一些復(fù)雜的問題,僅用ICL和CoT還是很難取到好的效果,所以采用prompt-based planning的方法去將復(fù)雜問題分解為更簡單的子問題,并通過規(guī)劃一系列action去完成這些子問題任務(wù)。
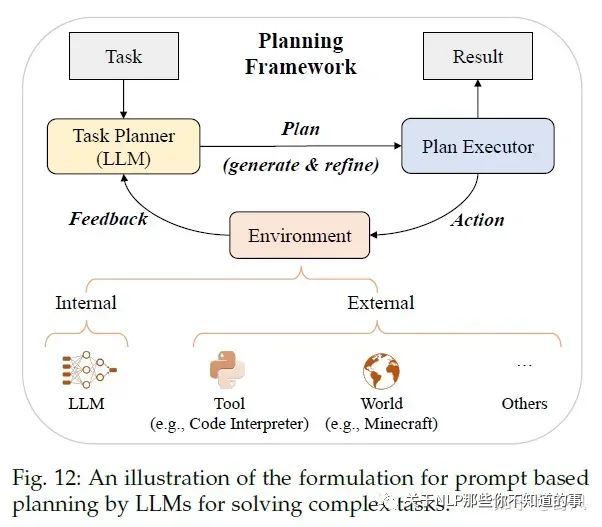
那這個(gè)plan具體是什么呢?它可以是一系列用自然語言描述的action或者用編程語言描述的可執(zhí)行代碼等
Plan Generation
text-based:通過指令利用LLM去生成執(zhí)行計(jì)劃,比如利用ICL的、讓LLM在“使用API解決問題”的語料上微調(diào),從而讓模型可以調(diào)用API、HuggingGPT還讓LLM可以調(diào)用模型
code-based:生成Python、PDDL等可執(zhí)行的代碼
Feedback Acquisition
internal feedback:使用LLM去預(yù)測生成的plan取得成功的概率、Tree of Thought去對比不同的plan(有點(diǎn)類似AlphaGo的蒙特卡諾搜索的意思)、對中間結(jié)果進(jìn)行評估并作為長期記憶存儲
external feedback:外部工具或者虛擬世界
Plan Refinement
Reasoning:React通過給LLM一些demonstrations去在feedback的時(shí)候生成推理路徑、ChatCoT進(jìn)一步將工具增強(qiáng)推理過程統(tǒng)一為基于LLM的任務(wù)規(guī)劃器與基于工具的環(huán)境之間的多輪對話
Backtracking:Tree of Thought利用DFS或者BFS去搜索,使得plan全局最優(yōu);另外還可以把feedback作為prompt去利用LLM refine plan
Memorization:將feedback和一些success plan作為長期記憶存儲在向量數(shù)據(jù)庫中
實(shí)際上這塊又引出了一個(gè)熱度很高的話題——LLM Powered Autonomous Agents,我覺得這是一個(gè)可能顛覆整個(gè)軟件行業(yè),甚至整個(gè)社會(huì)數(shù)字化生產(chǎn)力形態(tài)的話題,后面再好好介紹一下吧。
能力評估
基礎(chǔ)能力評估

Language Generation
Language Modeling:即根據(jù)前序tokens預(yù)測下一個(gè)token的能力,常用數(shù)據(jù)集有Penn Treebank、WikiText-103、和 Pile。在zero-shot的設(shè)定下,通過困惑度(perplexity)作為指標(biāo)去評估。對于長依賴能力的評估,可以使用LAMBADA數(shù)據(jù)集
Conditional Text Generation:具體任務(wù)下的文本生成,比如機(jī)器翻譯、文本摘要、問答、更難的結(jié)構(gòu)化數(shù)據(jù)生成、長文本生成等。常用指標(biāo)有Accuracy、BLEU和Rouge,以及人工評價(jià)、利用LLM去評價(jià)
Code Synthesis:通過運(yùn)行代碼測試pass rate,APPS、HumanEval、MBPP
主要問題:
Unreliable generation evaluation:LLM能生成與人類相當(dāng)?shù)馁|(zhì)量的文本,基于現(xiàn)有的一些自動(dòng)評價(jià)指標(biāo)會(huì)低估這些文本質(zhì)量。目前另一種方法是利用LLM去做評價(jià),對單個(gè)文本進(jìn)行評價(jià)和對多個(gè)候選文本進(jìn)行比較來改進(jìn)現(xiàn)有評價(jià)指標(biāo)
Underperforming Specialized Generation:LLM 可能無法勝任需要特定領(lǐng)域知識或生成結(jié)構(gòu)化數(shù)據(jù)的生成任務(wù)。在保持 LLM 原有能力的同時(shí),為 LLM 注入專業(yè)知識并非易事。
Knowledge Utilization
問答(question answering)和知識補(bǔ)全(knowledge completion)兩個(gè)任務(wù)常被用來檢驗(yàn)這個(gè)能力
Closed-Book QA:測試LLM根據(jù)給定的上下文信息回答而不使用外部數(shù)據(jù),常使用accuracy作為評價(jià)指標(biāo),實(shí)驗(yàn)表明更大的參數(shù)量或者數(shù)據(jù)量,都能提升該任務(wù)效果
Open-Book QA:可以利用外部資源來回答問題,常用accuracy和F1作為評價(jià)指標(biāo)。為了使用外部數(shù)據(jù),一般會(huì)用一個(gè)text retriever(獨(dú)立于LLM或者和LLM一起訓(xùn)練)去選擇外部數(shù)據(jù),甚至可以直接是利用搜索引擎。外部數(shù)據(jù)能提升回答效果,并且可以最新的數(shù)據(jù),去回答time-sensitive問題。
Knowledge Completion:這個(gè)任務(wù)可以去評價(jià)一個(gè)LLM從預(yù)訓(xùn)練數(shù)據(jù)中學(xué)到了什么和學(xué)到了多少知識。一般有知識圖譜補(bǔ)全任務(wù)和事實(shí)補(bǔ)全任務(wù)。目前對于特定領(lǐng)域的知識補(bǔ)全,LLM表現(xiàn)的不好。
推薦閱讀:
Retrieval-based LMs https://zhuanlan.zhihu.com/p/649820484
主要問題:
Hallucination:產(chǎn)生的信息要么與現(xiàn)有信息源相沖突(內(nèi)在幻覺),要么無法得到現(xiàn)有信息源的驗(yàn)證(外在幻覺),這在實(shí)際使用中影響較大。一般會(huì)通過在高質(zhì)量數(shù)據(jù)和人工反饋上進(jìn)行對齊微調(diào),另外通過整合外部信息源提供可信的信息也有助于減少幻覺
Knowledge recency:LLM 的參數(shù)知識很難及時(shí)更新。用外部知識源,比如搜索引擎,把搜索結(jié)果作為context去增強(qiáng) LLM 是解決這一問題的實(shí)用方法。然而,如何有效更新 LLM 內(nèi)部的知識仍是一個(gè)有待解決的研究課題。
推薦閱讀:
大模型的幻覺問題調(diào)研: LLM Hallucination Survey https://zhuanlan.zhihu.com/p/642648601
Complex Reasoning
復(fù)雜推理是指理解并利用輔助證據(jù)或邏輯推理得出結(jié)論或做出決定的能力
Knowledge Reasoning:一般使用LLM的CoT能力去觸發(fā)step by step推理能力。LLM容易生成一些錯(cuò)誤的中間步驟,導(dǎo)致最終的錯(cuò)誤結(jié)果,有研究使用特殊的解碼和集成策略去解決這個(gè)問題
Symbolic Reasoning:知識推理任務(wù)依靠邏輯關(guān)系和事實(shí)知識證據(jù)來回答給定問題
Mathematical Reasoning:數(shù)學(xué)推理任務(wù)需要綜合運(yùn)用數(shù)學(xué)知識、邏輯和計(jì)算來解決問題或生成證明陳述。
主要問題:
Reasoning inconsistency:LLM 可能會(huì)在無效的推理路徑后生成正確的答案,或者在正確的推理過程后生成錯(cuò)誤的答案,從而導(dǎo)致得出的答案與推理過程不一致。要解決這個(gè)問題,可以利用過程級反饋對 LLM 進(jìn)行微調(diào),使用多種推理路徑組合,并通過自我反思或外部反饋完善推理過程。
Numerical computation:LLM 在數(shù)字計(jì)算方面面臨困難,尤其是在前期訓(xùn)練中很少遇到的符號。除了使用外部數(shù)學(xué)工具外,將數(shù)字標(biāo)記化為單個(gè)標(biāo)記也是提高 LLM 算術(shù)能力的有效設(shè)計(jì)選擇。
高級能力評估
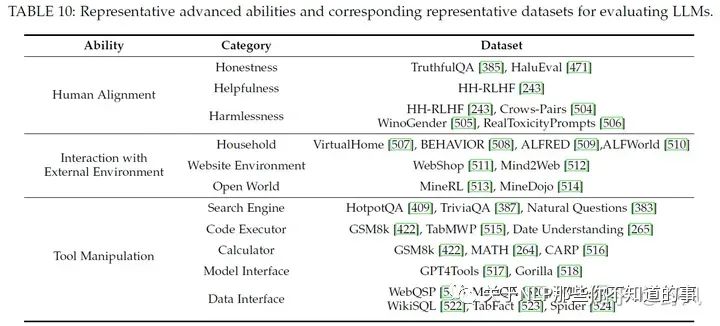
Human Alignment
對齊人類價(jià)值一般會(huì)從helpfulness、honesty、safety和harmlessness角度去評估,通過alignment tuning和高質(zhì)量的預(yù)訓(xùn)練數(shù)據(jù),可以提高這方面的能力
Interaction with External Environment
一般會(huì)在虛擬環(huán)境中進(jìn)行測試評估,通過對生成的action plans進(jìn)行可執(zhí)行性和正確性評估以及在現(xiàn)實(shí)環(huán)境中實(shí)驗(yàn)的成功率去評價(jià)該能力。最近也有一些研究在虛擬環(huán)境做基于LLM的多智能體協(xié)作的工作。
Tool Manipulation
將工具使用API封裝給LLM調(diào)用、ChatGPT的插件等都是工具的形式,驗(yàn)證LLM工作操作的能力一般會(huì)使用一些推理任務(wù)去評估。隨著工具的增多,LLM有限的context導(dǎo)致其無法很好的利用這些工具反饋的信息,現(xiàn)在的做法是將這些信息存儲為embedding使用
基準(zhǔn)和經(jīng)驗(yàn)性評估
Comprehensive Evaluation Benchmarks
MMLU
BIG-bench、BIG-bench-Lite、BIG-bench hard
HELM
Human-level test benchmarks:AGIEval、MMCU、M3KE、C-Eval、Xiezhi
Empirical Ability Evaluation
論文作者通過在閉源大模型(ChatGPT, Claude, Davinci003 and Davinci002)和開源大模型(LLaMA 7B、Pythia 7B和12B、Falcon 7B,經(jīng)過instruction-tuned的Vicuna 7B、Alpaca 7B、ChatGLM 6B)上做了一些實(shí)驗(yàn)評估,得到了一些結(jié)論
閉源大模型相比開源大模型,效果更好,尤其是ChatGPT
ChatGPT 和 Davinci003 在與環(huán)境互動(dòng)和工具操作任務(wù)方面表現(xiàn)更佳
所有模型在難度很大的推理任務(wù)中都表現(xiàn)不佳
instruction-tuned model效果要優(yōu)于base model
這些小型開源模型在數(shù)學(xué)推理、與環(huán)境互動(dòng)和工具操作任務(wù)方面表現(xiàn)不佳
在Human Alignment任務(wù)上,開源模型的表現(xiàn)方差較大
作為最新發(fā)布的型號,F(xiàn)alcon-7B 性能不俗,尤其是在語言生成任務(wù)方面
推薦閱讀:
LLM Evaluation 如何評估一個(gè)大模型? https://zhuanlan.zhihu.com/p/644373658
A Survey on Evaluation of Large Language Models https://github.com/MLGroupJLU/LLM-eval-survey
一些Leaderboard
MMLU
Chatbot Arena
BIG-bench
Open LLM Leaderboard
SuperCLUE
C-Eval
GaoKao-Bench
AlpacaEval
OpenCompass
Prompt設(shè)計(jì)指南
原則:
① 清楚地表達(dá)任務(wù)目標(biāo);
② 分解成簡單、詳細(xì)的子任務(wù);
③ 提供少量演示;
④ 使用模型友好格式
任務(wù)描述
描述越細(xì)節(jié)越好;
告訴LLM自己是某方面的專家;
告訴LLM更多應(yīng)該做什么而不是不應(yīng)該做什么;如果不希望太長的輸出,可以使用“Question: Short Answer: ”或者"in a or a few words”, “in one of two sentences”.
輸入數(shù)據(jù)
對于要求提供事實(shí)性知識的問題,可以先通過搜索引擎檢索相關(guān)文檔,然后將其串聯(lián)到提示語中作為參考;
為了突出提示中的某些重要部分,請使用特殊標(biāo)記,如引號("")和換行符( )。您也可以同時(shí)使用這兩種符號來強(qiáng)調(diào)
上下文信息
對于復(fù)雜的任務(wù),可以清楚地描述完成任務(wù)所需的中間步驟,例如:Please answer the question step by step as: Step 1 - Decompose the question into several sub-questions, · · ·
如果您想讓 LLM 為文本打分,則有必要詳細(xì)說明評分標(biāo)準(zhǔn),并提供示例作為參考
當(dāng) LLM 根據(jù)上下文生成文本時(shí)(例如,根據(jù)購買歷史記錄進(jìn)行推薦),向它們解釋根據(jù)上下文生成的結(jié)果有助于提高生成文本的質(zhì)量。
示例(Demonstration):
格式良好的上下文示例對指導(dǎo) LLM 非常有用,尤其是在制作格式復(fù)雜的輸出時(shí)。
在進(jìn)行few-shot CoT提示時(shí),也可以使用 "Let’s think step-by-step "的提示語,而且少量示例之間應(yīng)該用" "分隔,而不是句號。
檢索與上下文相似的示例去補(bǔ)充LLM任務(wù)相關(guān)的領(lǐng)域知識,為了獲取更多的示例,可以先搜索問題的答案,然后再把問題和答案拼在一起去檢索
提示中語境范例的多樣性也很有用。如果不容易獲得多樣化的問題,也可以設(shè)法保持問題解決方案的多樣性。
在使用chat-based LLM時(shí),可以將示例分解為多輪對話形式
復(fù)雜且詳細(xì)的示例可以幫助LLM回答復(fù)雜問題
由于一個(gè)符號序列通常可分為多個(gè)片段(如 i1、i2、i3 -→ i1、i2 和 i2、i3),因此前面的片段可作為上下文中的范例,引導(dǎo) LLM 預(yù)測后面的片段,同時(shí)提供歷史信息。
上下文中的示例和提示組件的順序很重要。對于很長的輸入數(shù)據(jù),問題的位置(第一個(gè)或最后一個(gè))也會(huì)影響性能。
如果無法從現(xiàn)有數(shù)據(jù)集中獲取上下文示例,另一種方法是使用 LLM 本身生成的zero-shot示例
其他設(shè)計(jì)
讓LLM在輸出的時(shí)候檢測內(nèi)容是否正確。如Check whether the above solution is correct or not.
如果LLM不能很好的解決問題,可以讓LLM使用外部API工具,如function calling能力
提示語應(yīng)自成一體,最好不要在上下文中使用代詞(如 it 和 they)。
在使用 LLM 比較兩個(gè)或多個(gè)示例時(shí),順序?qū)π阅苡绊懞艽蟆?/p>
在提示之前,為 LLM 分配一個(gè)角色非常有用,可以幫助它更好地完成以下任務(wù)指令
與其他語言相比,OpenAI 模型可以更好地用英語執(zhí)行任務(wù)。因此,首先將輸入內(nèi)容翻譯成英語,然后將其輸入 LLM 是非常有用的。
對于多選題,限制 LLM 的輸出空間是非常有用的。您可以使用更詳細(xì)的解釋,也可以只對對數(shù)施加限制。
對于基于排序的任務(wù)(如推薦),我們可以為未排序的項(xiàng)目分配指標(biāo)(如 ABCD),并指示 LLM 直接輸出排序后的指標(biāo),而不是在排序后直接輸出每個(gè)項(xiàng)目的完整文本
審核編輯:黃飛
-
GPT
+關(guān)注
關(guān)注
0文章
368瀏覽量
15918 -
OpenAI
+關(guān)注
關(guān)注
9文章
1200瀏覽量
8616 -
大模型
+關(guān)注
關(guān)注
2文章
3009瀏覽量
3787 -
LLM
+關(guān)注
關(guān)注
1文章
319瀏覽量
673
原文標(biāo)題:萬字長文入門大語言模型(LLM)
文章出處:【微信號:vision263com,微信公眾號:新機(jī)器視覺】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
LLM之外的性價(jià)比之選,小語言模型
無法在OVMS上運(yùn)行來自Meta的大型語言模型 (LLM),為什么?
基于Transformer的大型語言模型(LLM)的內(nèi)部機(jī)制

Long-Context下LLM模型架構(gòu)全面介紹

2023年大語言模型(LLM)全面調(diào)研:原理、進(jìn)展、領(lǐng)跑者、挑戰(zhàn)、趨勢
大語言模型(LLM)快速理解

LLM模型的應(yīng)用領(lǐng)域
llm模型和chatGPT的區(qū)別
llm模型有哪些格式
llm模型本地部署有用嗎
大模型LLM與ChatGPT的技術(shù)原理
新品|LLM Module,離線大語言模型模塊

什么是LLM?LLM在自然語言處理中的應(yīng)用
新品| LLM630 Compute Kit,AI 大語言模型推理開發(fā)平臺
小白學(xué)大模型:從零實(shí)現(xiàn) LLM語言模型





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論