 小白學大模型:從零實現 LLM語言模型
小白學大模型:從零實現 LLM語言模型
來源:Coggle數據科學
在當今人工智能領域,大型語言模型(LLM)的開發已經成為一個熱門話題。這些模型通過學習大量的文本數據,能夠生成自然語言文本,完成各種復雜的任務,如寫作、翻譯、問答等。
https://github.com/FareedKhan-dev/train-llm-from-scratch
本文將為你提供一個簡單直接的方法,從下載數據到生成文本,帶你一步步構建大院模型。
步驟1:GPU設備
在開始訓練語言模型之前,你需要對面向對象編程(OOP)、神經網絡(NN)和 PyTorch 有基本的了解。
訓練語言模型需要強大的計算資源,尤其是 GPU。不同的 GPU 在內存容量和計算能力上有所不同,適合不同規模的模型訓練。以下是一個詳細的 GPU 對比表,幫助你選擇合適的硬件。
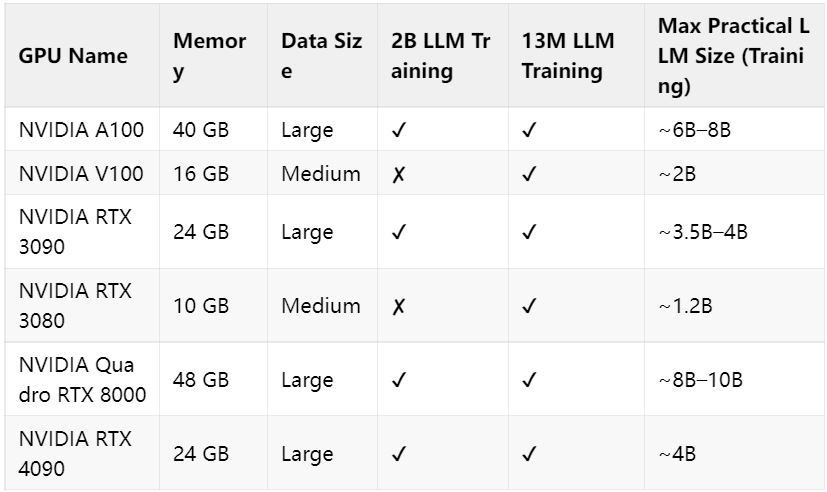
13M LLM 訓練
- 參數規模:1300 萬參數。
- 應用場景:適合初學者和小型項目,例如簡單的文本生成、情感分析或語言理解任務。
- 硬件需求:相對較低。大多數中高端 GPU(如 NVIDIA RTX 3060 或更高)都可以勝任。
- 特點:訓練速度快,資源消耗低,適合快速迭代和實驗。
2B LLM 訓練
- 參數規模:20 億參數。
- 應用場景:適合更復雜的任務,如高質量的文本生成、多語言翻譯或更高級的語言理解任務。
- 硬件需求:較高。需要至少 16GB 內存的 GPU,如 NVIDIA RTX 3090 或更高配置。
- 特點:能夠生成更流暢、更自然的文本,但訓練時間長,資源消耗大。
步驟2:導入環境
在開始之前,我們需要導入一些必要的 Python 庫。這些庫將幫助我們處理數據、構建模型以及訓練模型。
# PyTorch for deep learning functions and tensors
import torch
import torch.nn as nn
import torch.nn.functional as F
# Numerical operations and arrays handling
import numpy as np
# Handling HDF5 files
import h5py
# Operating system and file management
import os
# Command-line argument parsing
import argparse
# HTTP requests and interactions
import requests
# Progress bar for loops
from tqdm import tqdm
# JSON handling
import json
# Zstandard compression library
import zstandard as zstd
# Tokenization library for large language models
import tiktoken
# Math operations (used for advanced math functions)
import math
步驟3:加載數據集
The Pile 數據集是一個大規模、多樣化的開源數據集,專為語言模型訓練設計。它由 22 個子數據集組成,涵蓋了書籍、文章、維基百科、代碼、新聞等多種類型的文本。
# Download validation dataset
!wget https://huggingface.co/datasets/monology/pile-uncopyrighted/resolve/main/val.jsonl.zst
# Download the first part of the training dataset
!wget https://huggingface.co/datasets/monology/pile-uncopyrighted/resolve/main/train/00.jsonl.zst
# Download the second part of the training dataset
!wget https://huggingface.co/datasets/monology/pile-uncopyrighted/resolve/main/train/01.jsonl.zst
# Download the third part of the training dataset
!wget https://huggingface.co/datasets/monology/pile-uncopyrighted/resolve/main/train/02.jsonl.zst
最終處理好的數據集格式如下:
#### OUTPUT ####
Line: 0
{
"text":"Effect of sleep quality ... epilepsy.",
"meta": {
"pile_set_name":"PubMed Abstracts"
}
}
Line: 1
{
"text":"LLMops a new GitHub Repository ...",
"meta": {
"pile_set_name":"Github"
}
}
步驟4:Transformer 架構
Transformer 通過將文本分解成更小的單元,稱為“標記”(token),并預測序列中的下一個標記來工作。Transformer 由多個層組成,這些層被稱為 Transformer 塊,它們一層疊一層,最后通過一個最終層來進行預測。
每個 Transformer 塊包含兩個主要組件:
1. 自注意力頭(Self-Attention Heads)
自注意力頭的作用是確定輸入中哪些部分對模型來說最為重要。例如,在處理一個句子時,自注意力頭可以突出顯示單詞之間的關系,比如代詞與其所指代的名詞之間的關系。通過這種方式,模型能夠更好地理解句子的結構和語義。
2. 多層感知器(MLP,Multi-Layer Perceptron)
多層感知器是一個簡單的前饋神經網絡。它接收自注意力頭強調的信息,并進一步處理這些信息。MLP 包含:
- 輸入層:接收來自自注意力頭的數據。
- 隱藏層:為處理過程增加復雜性。
- 輸出層:將處理結果傳遞給下一個 Transformer 塊。
- 輸入嵌入與位置編碼 :輸入的文本被分解為標記(tokens),然后轉換為嵌入向量(embeddings)。同時,加入位置編碼(position embeddings)以提供標記的位置信息。
- Transformer 塊堆疊 :模型由多個(例如 64 個)相同的 Transformer 塊組成,這些塊依次對數據進行處理。
- 多頭注意力機制 :每個 Transformer 塊首先通過多頭注意力機制(例如 16 個頭)分析標記之間的關系,捕捉不同類型的關聯。
- MLP 處理 :注意力機制處理后的數據通過一個 MLP(多層感知器)進行進一步處理,先擴展到更大維度(例如 4 倍),再壓縮回原始維度。
- 殘差連接與層歸一化 :每個 Transformer 塊中使用殘差連接(residual connections)和層歸一化(layer normalization),以幫助信息流動并穩定訓練。
- 最終預測 :理后的數據通過最終層,轉換為詞匯表大小的預測結果,生成下一個最有可能的標記。
- 文本生成 :模型通過反復預測下一個標記,逐步生成完整的文本序列。
步驟5:多層感知器(MLP)
多層感知器(MLP)是 Transformer 架構中前饋神經網絡(Feed-Forward Network, FFN)的核心組成部分。它的主要作用是引入非線性特性,并學習嵌入表示中的復雜關系。在定義 MLP 模塊時,一個重要的參數是n_embed,它定義了輸入嵌入的維度。
MLP 的整個序列轉換過程使得它能夠對注意力機制學習到的表示進行進一步的精細化處理。具體來說:
- 引入非線性:通過 ReLU 激活函數,MLP 能夠捕捉到嵌入表示中的復雜非線性關系。
- 特征增強:隱藏層的擴展操作為模型提供了更大的空間來學習更豐富的特征。
- 維度一致性:投影線性層確保 MLP 的輸出維度與輸入維度一致,便于后續的 Transformer 塊繼續處理。
# --- MLP (Multi-Layer Perceptron) Class ---
class MLP(nn.Module):
"""
A simple Multi-Layer Perceptron with one hidden layer.
This module is used within the Transformer block for feed-forward processing.
It expands the input embedding size, applies a ReLU activation, and then projects it back
to the original embedding size.
"""
def __init__(self, n_embed):
super().__init__()
self.hidden = nn.Linear(n_embed, 4 * n_embed) # Linear layer to expand embedding size
self.relu = nn.ReLU() # ReLU activation function
self.proj = nn.Linear(4 * n_embed, n_embed) # Linear layer to project back to original size
def forward(self, x):
"""
Forward pass through the MLP.
Args:
x (torch.Tensor): Input tensor of shape (B, T, C), where B is batch size,
T is sequence length, and C is embedding size.
Returns:
torch.Tensor: Output tensor of the same shape as the input.
"""
x = self.forward_embedding(x)
x = self.project_embedding(x)
returnx
def forward_embedding(self, x):
"""
Applies the hidden linear layer followed by ReLU activation.
Args:
x (torch.Tensor): Input tensor.
Returns:
torch.Tensor: Output after the hidden layer and ReLU.
"""
x = self.relu(self.hidden(x))
returnx
def project_embedding(self, x):
"""
Applies the projection linear layer.
Args:
x (torch.Tensor): Input tensor.
Returns:
torch.Tensor: Output after the projection layer.
"""
x = self.proj(x)
returnx
步驟6:Single Head Attention
注意力頭(Attention Head)是 Transformer 模型的核心部分,其主要作用是讓模型能夠專注于輸入序列中與當前任務最相關的部分。在定義注意力頭模塊時,有幾個重要的參數:
- head_size:決定了鍵(key)、查詢(query)和值(value)投影的維度,從而影響注意力機制的表達能力。
- n_embed:輸入嵌入的維度,定義了這些投影層的輸入大小。
- context_length:用于創建因果掩碼(causal mask),確保模型只能關注前面的標記,從而實現自回歸(autoregressive)特性。
在注意力頭內部,我們初始化了三個無偏置的線性層(nn.Linear),分別用于鍵、查詢和值的投影。此外,我們注冊了一個大小為context_length x context_length的下三角矩陣(tril)作為緩沖區(buffer),以實現因果掩碼,防止注意力機制關注未來的標記。
# --- Attention Head Class ---
class Head(nn.Module):
def __init__(self, head_size, n_embed, context_length):
super().__init__()
self.key = nn.Linear(n_embed, head_size, bias=False) # Key projection
self.query = nn.Linear(n_embed, head_size, bias=False)# Query projection
self.value = nn.Linear(n_embed, head_size, bias=False)# Value projection
# Lower triangular matrix for causal masking
self.register_buffer('tril', torch.tril(torch.ones(context_length, context_length)))
def forward(self, x):
B, T, C = x.shape
k = self.key(x) # (B, T, head_size)
q = self.query(x) # (B, T, head_size)
scale_factor = 1 / math.sqrt(C)
# Calculate attention weights: (B, T, head_size) @ (B, head_size, T) -> (B, T, T)
attn_weights = q @ k.transpose(-2, -1) * scale_factor
# Apply causal masking
attn_weights = attn_weights.masked_fill(self.tril[:T, :T] == 0,float('-inf'))
attn_weights = F.softmax(attn_weights, dim=-1)
v = self.value(x) # (B, T, head_size)
# Apply attention weights to values
out = attn_weights @ v# (B, T, T) @ (B, T, head_size) -> (B, T, head_size)
returnout
步驟7:Multi Head Attention
多頭注意力(Multi-Head Attention)是 Transformer 架構中的關鍵機制,用于捕捉輸入序列中多樣化的關聯關系。通過將多個獨立的注意力頭(attention heads)并行運行,模型能夠同時關注輸入的不同方面,從而更全面地理解序列信息。
- n_head:決定了并行運行的注意力頭的數量。每個注意力頭獨立處理輸入數據,從而讓模型能夠從多個角度捕捉輸入序列中的關系。
- 上下文長度context_length定義了輸入序列的長度,用于創建因果掩碼(causal mask),確保模型只能關注前面的標記,從而實現自回歸特性。
class MultiHeadAttention(nn.Module):
"""
Multi-Head Attention module.
This module combines multiple attention heads in parallel. The outputs of each head
are concatenated to form the final output.
"""
def __init__(self, n_head, n_embed, context_length):
super().__init__()
self.heads = nn.ModuleList([Head(n_embed // n_head, n_embed, context_length)for_inrange(n_head)])
def forward(self, x):
"""
Forward pass through the multi-head attention.
Args:
x (torch.Tensor): Input tensor of shape (B, T, C).
Returns:
torch.Tensor: Output tensor after concatenating the outputs of all heads.
"""
# Concatenate the output of each head along the last dimension (C)
x = torch.cat([h(x)forhinself.heads], dim=-1)
returnx
步驟8:Transformer 塊
Transformer 塊是 Transformer 架構的核心單元,它通過組合多頭注意力機制和前饋網絡(MLP),并應用層歸一化(Layer Normalization)以及殘差連接(Residual Connections),來處理輸入并學習復雜的模式。
- n_head:多頭注意力中并行注意力頭的數量。
- n_embed:輸入嵌入的維度,也是層歸一化的參數維度。
- context_length:上下文長度,用于定義序列的長度,并創建因果掩碼。
每個 Transformer 塊包含以下部分:
- 多頭注意力層(Multi-Head Attention):負責捕捉輸入序列中不同位置之間的關系。
- 前饋網絡(MLP):用于進一步處理多頭注意力層的輸出,引入非線性特性。
- 層歸一化(Layer Normalization):在每個子層之前應用,有助于穩定訓練。
- 殘差連接(Residual Connections):在每個子層之后應用,幫助信息流動并緩解深層網絡訓練中的梯度消失問題。
class Block(nn.Module):
def __init__(self, n_head, n_embed, context_length):
super().__init__()
self.ln1 = nn.LayerNorm(n_embed)
self.attn = MultiHeadAttention(n_head, n_embed, context_length)
self.ln2 = nn.LayerNorm(n_embed)
self.mlp = MLP(n_embed)
def forward(self, x):
# Apply multi-head attention with residual connection
x = x + self.attn(self.ln1(x))
# Apply MLP with residual connection
x = x + self.mlp(self.ln2(x))
returnx
def forward_embedding(self, x):
res = x + self.attn(self.ln1(x))
x = self.mlp.forward_embedding(self.ln2(res))
returnx, res
步驟9:完整模型結構
到目前為止,我們已經編寫了 Transformer 模型的一些小部件,如多頭注意力(Multi-Head Attention)和 MLP(多層感知器)。接下來,我們需要將這些部件整合起來,構建一個完整的 Transformer 模型,用于執行序列到序列的任務。為此,我們需要定義幾個關鍵參數:n_head、n_embed、context_length、vocab_size和N_BLOCKS。
# --- Transformer Model Class ---
class Transformer(nn.Module):
"""
The main Transformer model.
This class combines token and position embeddings with a sequence of Transformer blocks
and a final linear layer for language modeling.
"""
def __init__(self, n_head, n_embed, context_length, vocab_size, N_BLOCKS):
super().__init__()
self.context_length = context_length
self.N_BLOCKS = N_BLOCKS
self.token_embed = nn.Embedding(vocab_size, n_embed)
self.position_embed = nn.Embedding(context_length, n_embed)
self.attn_blocks = nn.ModuleList([Block(n_head, n_embed, context_length)for_inrange(N_BLOCKS)])
self.layer_norm = nn.LayerNorm(n_embed)
self.lm_head = nn.Linear(n_embed, vocab_size)
self.register_buffer('pos_idxs', torch.arange(context_length))
def _pre_attn_pass(self, idx):
B, T = idx.shape
tok_embedding = self.token_embed(idx)
pos_embedding = self.position_embed(self.pos_idxs[:T])
returntok_embedding + pos_embedding
def forward(self, idx, targets=None):
x = self._pre_attn_pass(idx)
forblockinself.attn_blocks:
x = block(x)
x = self.layer_norm(x)
logits = self.lm_head(x)
loss = None
iftargets is not None:
B, T, C = logits.shape
flat_logits = logits.view(B * T, C)
targets = targets.view(B * T).long()
loss = F.cross_entropy(flat_logits, targets)
returnlogits, loss
def forward_embedding(self, idx):
x = self._pre_attn_pass(idx)
residual = x
forblockinself.attn_blocks:
x, residual = block.forward_embedding(x)
returnx, residual
def generate(self, idx, max_new_tokens):
for_inrange(max_new_tokens):
idx_cond = idx[:, -self.context_length:]
logits, _ = self(idx_cond)
logits = logits[:, -1, :]
probs = F.softmax(logits, dim=-1)
idx_next = torch.multinomial(probs, num_samples=1)
idx = torch.cat((idx, idx_next), dim=1)
returnidx
步驟10:訓練參數配置
現在我們已經完成了模型的編碼工作,接下來需要定義訓練參數,包括注意力頭的數量、Transformer 塊的數量等,以及數據路徑等相關配置。
- VOCAB_SIZE:詞匯表大小,表示詞匯表中唯一標記的數量。
- CONTEXT_LENGTH:模型能夠處理的最大序列長度。
- N_EMBED:嵌入空間的維度,決定了標記嵌入和位置嵌入的大小。
- N_HEAD:每個 Transformer 塊中的注意力頭數量。
- N_BLOCKS:模型中 Transformer 塊的數量,決定了模型的深度。
- T_BATCH_SIZE:訓練時每個批次的樣本數量。
- T_CONTEXT_LENGTH:訓練批次的上下文長度。
- T_TRAIN_STEPS:總訓練步數。
步驟11:模型訓練
我們使用 AdamW 優化器,這是一種改進版的 Adam 優化器,適用于深度學習任務。
- 高初始損失:20 億參數模型在訓練初期的損失值通常非常高。這是因為模型的參數量巨大,初始權重隨機分布,導致模型在開始時對數據的理解非常有限。
- 劇烈波動:在訓練的前幾輪,損失值可能會出現劇烈波動。這是因為模型需要在龐大的參數空間中尋找合適的權重組合,而初始的學習率可能過高,導致優化過程不穩定。
- 快速下降:盡管初始損失很高,但隨著訓練的進行,損失值通常會迅速下降。這是因為模型逐漸開始學習數據中的模式和結構。
- 波動調整:在快速下降之后,損失值可能會出現一些波動。這是因為模型在調整權重時,可能會在不同的局部最優解之間徘徊。這種波動表明模型在尋找更穩定的全局最優解。
步驟12:生成文本
接下來,我們將創建一個函數generate_text,用于從保存的模型中生成文本。該函數接受保存的模型路徑和輸入文本作為輸入,并返回生成的文本。我們還將比較數百萬參數模型和數十億參數模型在生成文本時的表現。
def generate_text(model_path, input_text, max_length=512, device="gpu"):
# Load the model checkpoint
checkpoint = torch.load(model_path)
# Initialize the model (you should ensure that the Transformer class is defined elsewhere)
model = Transformer().to(device)
# Load the model's state dictionary
model.load_state_dict(checkpoint['model_state_dict'])
# Load the tokenizer for the GPT model (we use 'r50k_base' for GPT models)
enc = tiktoken.get_encoding('r50k_base')
# Encode the input text along with the end-of-text token
input_ids = torch.tensor(
enc.encode(input_text, allowed_special={'<|endoftext|>'}),
dtype=torch.long
)[None, :].to(device) # Add batch dimension and move to the specified device
# Generate text with the model using the encoded input
with torch.no_grad():
# Generate up to 'max_length' tokens of text
generated_output = model.generate(input_ids, max_length)
# Decode the generated tokens back into text
generated_text = enc.decode(generated_output[0].tolist())
returngenerated_text
-
語言模型
+關注
關注
0文章
558瀏覽量
10661 -
大模型
+關注
關注
2文章
3020瀏覽量
3803 -
LLM
+關注
關注
1文章
319瀏覽量
677
發布評論請先 登錄
LLM之外的性價比之選,小語言模型
【大語言模型:原理與工程實踐】大語言模型的應用
無法在OVMS上運行來自Meta的大型語言模型 (LLM),為什么?
基于Transformer的大型語言模型(LLM)的內部機制

大語言模型(LLM)快速理解

LLM模型的應用領域
llm模型和chatGPT的區別
llm模型本地部署有用嗎
大模型LLM與ChatGPT的技術原理
LLM大模型推理加速的關鍵技術
新品|LLM Module,離線大語言模型模塊

如何訓練自己的LLM模型
小白學大模型:構建LLM的關鍵步驟





 工商網監
工商網監
評論