") CPU程序幾個優(yōu)化程序性能的手段詳解
CPU程序幾個優(yōu)化程序性能的手段詳解

作者:MegEngine
一個程序首先要保證正確性,在保證正確性的基礎(chǔ)上,性能也是一個重要的考量。要編寫高性能的程序,第一,必須選擇合適的算法和數(shù)據(jù)結(jié)構(gòu);第二,應(yīng)該編寫編譯器能夠有效優(yōu)化以轉(zhuǎn)換成高效可執(zhí)行代碼的源代碼,要做到這一點,需要了解編譯器的能力和限制;第三,要了解硬件的運行方式,針對硬件特性進行優(yōu)化。本文著重展開第二點和第三點。
簡單認(rèn)識編譯器
要寫出高性能的代碼,首先需要對編譯器有基礎(chǔ)的了解,原因在于現(xiàn)代編譯器有很強的優(yōu)化能力,但有些代碼編譯器不能進行優(yōu)化。對編譯器有了基礎(chǔ)的了解,才能寫出編譯器友好型高性能代碼。
編譯器的優(yōu)化選項
以GCC為例,GCC 支持以下優(yōu)化級別:
-O
-Ofast,除了開啟 -O3 的所有優(yōu)化選項外,會額外打開 -ffast-math 和 -fallow-store-data-races。注意這兩個選項可能會引起程序運行錯誤。
-ffast-math: Sets the options-fno-math-errno,-funsafe-math-optimizations,-ffinite-math-only,-fno-rounding-math,-fno-signaling-nans,-fcx-limited-rangeand-fexcess-precision=fast. It can result in incorrect output for programs that depend on an exact implementation of IEEE or ISO rules/specifications for math functions. It may, however, yield faster code for programs that do not require the guarantees of these specifications.
-fallow-store-data-races: Allow the compiler to perform optimizations that may introduce new data races on stores, without proving that the variable cannot be concurrently accessed by other threads. Does not affect optimization of local data. It is safe to use this option if it is known that global data will not be accessed by multiple threads.
-Og,調(diào)試代碼時推薦使用的優(yōu)化級別。
gcc -Q --help=optimizer -Ox 可查看各優(yōu)化級別開啟的優(yōu)化選項。 參考鏈接:https://gcc.gnu.org/onlinedocs/gcc/Optimize-Options.html
編譯器的限制
為了保證程序運行的正確性,編譯器不會對代碼的使用場景做任何假設(shè),所以有些代碼編譯器不會進行優(yōu)化。下面舉兩個比較隱晦的例子。 1、memory aliasing
void twiddle1(long *xp, long *yp) {
*xp += *yp;
*xp += *yp;
}
void twiddle2(long *xp, long *yp) {
*xp += 2 * *yp;
}
當(dāng)xp和yp指向同樣的內(nèi)存(memory aliasing)時,twiddle1和twiddle2是兩個完全不同的函數(shù),所以編譯器不會嘗試將twiddle1優(yōu)化為twiddle2。如果本意是希望實現(xiàn)twiddle2的功能,應(yīng)該寫成twiddle2而非twwidle1的形式,twiddle2只需要 2 次讀 1 次寫,而twiddle1需要 4 次讀 2 次寫。 可以顯式使用__restrict修飾指針,表明不存在和被修飾的指針指向同一塊內(nèi)存的指針,此時編譯器會將twiddle3優(yōu)化為和twiddle2等效。可自行通過反匯編的方式觀察匯編碼進一步理解。
void twiddle3(long *__restrict xp, long *__restrict yp) {
*xp += *yp;
*xp += *yp;
}
2、side effect
long f();
long func1() {
return f() + f() + f() + f();
}
long func2() {
return 4 * f();
}
由于函數(shù)f的實現(xiàn)可能如下,存在side effect,所以編譯器不會將func1優(yōu)化為func2。如果本意希望實現(xiàn)func2版本,則應(yīng)該直接寫成func2的形式,可減少 3 次函數(shù)調(diào)用。
long counter = 0;
long f() {
return counter++;
}
程序性能優(yōu)化
在介紹之前,我們先引入一個程序性能度量標(biāo)準(zhǔn)每元素的周期數(shù)(Cycles Per Element, CPE),即每處理一個元素需要花費的周期數(shù),可以表示程序性能并指導(dǎo)性能優(yōu)化。 下面通過一個例子介紹幾個優(yōu)化程序性能的手段。首先定義一個數(shù)據(jù)結(jié)構(gòu) vector 以及一些輔助函數(shù),vector 使用一個連續(xù)存儲的數(shù)組實現(xiàn),可通過typedef來指定元素的數(shù)據(jù)類型data_t。
typedef struct {
long len;
data_t *data;
} vec_rec, *vec_ptr;
/* 創(chuàng)建vector */
vec_ptr new_vec(long len) {
vec_ptr result = (vec_ptr)malloc(sizeof(vec_rec));
if (!result)
return NULL;
data_t *data = NULL;
result->len = len;
if (len > 0) {
data = (data_t*)calloc(len, sizeof(data_t));
if (!data) {
free(result);
return NULL;
}
}
result->data = data;
return result;
}
/* 根據(jù)index獲取vector元素 */
int get_vec_element(vec_ptr v, long index, data_t *dest) {
if (index < 0 || index >= v->len)
return 0;
*dest = v->data[index];
return 1;
}
/* 獲取vector元素個數(shù) */
long vec_length(vec_ptr v) {
return v->len;
}
下面的函數(shù)的功能是使用某種運算,將一個向量中所有的元素合并為一個元素。下面的IDENT和OP是宏定義,#define IDENT 0和#define OP +進行累加運算,#define IDENT 1和#define OP *則進行累乘運算。
void combine1(vec_ptr v, data_t *dest) {
long i;
*dest = IDENT;
for (i = 0; i < vec_length(v); i++) {
data_t val;
get_vec_element(v, i, &val);
*dest = *dest OP val;
}
}
對于上面的combine1,可以進行下面三個基礎(chǔ)的優(yōu)化。 1、對于多次執(zhí)行返回同樣結(jié)果的函數(shù),使用臨時變量保存 combine1的實現(xiàn)在循環(huán)測試條件中反復(fù)調(diào)用了函數(shù)vec_length,在此場景下,多次調(diào)用vec_length會返回同樣的結(jié)果,所以可以改寫為combine2的實現(xiàn)進行優(yōu)化。在極端情況下,注意避免反復(fù)調(diào)用返回同樣結(jié)果的函數(shù)是更有效的。例如,若在循環(huán)結(jié)束條件中調(diào)用測試一個字符串長度的函數(shù),該函數(shù)時間復(fù)雜度通常是O(n),若明確字符串長度不會變化,反復(fù)調(diào)用會有很大的額外開銷。
void combine2(vec_ptr v, data_t *dest) {
long i;
long length = vec_length(v);
*dest = IDENT;
for (i = 0; i < length; i++) {
data_t val;
get_vec_element(v, i, &val);
*dest = *dest OP val;
}
}
2、減少過程調(diào)用 過程(函數(shù))調(diào)用會產(chǎn)生一定的開銷,例如參數(shù)傳遞、clobber 寄存器保存恢復(fù)和轉(zhuǎn)移控制等。所以可以新增一個函數(shù)get_vec_start返回指向數(shù)組的開頭的指針,在循環(huán)中避免調(diào)用函數(shù)get_vec_element。這個優(yōu)化存在一個 trade off,一方面可以一定程序提升程序性能,另一方面這個優(yōu)化需要知道 vector 數(shù)據(jù)結(jié)構(gòu)的實現(xiàn)細節(jié),會破壞程序的抽象,一旦 vector 修改為不使用數(shù)組的方式存儲數(shù)據(jù),則同時需要修改combine3的實現(xiàn)。
data_t *get_vec_start(vec_ptr v) {
return v->data;
}
void combine3(vec_ptr v, data_t *dest) {
long i;
long length = vec_length(v);
data_t *data = get_vec_start(v);
*dest = IDENT;
for (i = 0; i < length; i++) {
*dest = *dest OP data[i];
}
}
3、消除不必要的內(nèi)存引用 在上面的實現(xiàn)中,循環(huán)中每次都會去讀一次寫一次dest,由于可能存在memory aliasing,編譯器會謹(jǐn)慎地進行優(yōu)化。下面分別是-O1和-O2優(yōu)化級別時,combine3中for循環(huán)部分的匯編代碼。可以看到,開啟 -O2 優(yōu)化時,編譯器幫我們把中間結(jié)果存到了臨時變量中(寄存器 % xmm0),而不是像 -O1 優(yōu)化時每次從內(nèi)存中讀取;但是考慮到memory aliasing的情況,即使 -O2 優(yōu)化,依然需要每次循環(huán)將中間結(jié)果保存到內(nèi)存。
// combine3 -O1
.L1:
vmovsd (%rbx), %xmm0
vmulsd (%rdx), %xmm0, %xmm0
vmovsd %xmm0, (%rbx)
addq $8, %rdx
cmpq %rax, %rdx
jne .L1
// combine3 -O2
.L1
vmulsd (%rdx), %xmm0, %xmm0
addq $8, %rdx
cmpq %rax, %rdx
vmovsd %xmm0, (%rbx)
jne .L1
為了避免頻繁進行內(nèi)存讀寫,可以人為地使用一個臨時變量保存中間結(jié)果,如combine4所示。
void combine4(vec_ptr v, data_t *dest) {
long i;
long length = vec_length(v);
data_t *data = get_vec_start(v);
data_t acc = IDENT;
for (i = 0; i < length; i++) {
acc = acc OP data[i];
}
*dest = acc;
}
// combine4 -O1
.L1
vmulsd (%rdx), %xmm0, %xmm0
addq $8, %rdx
cmpq %rax, %rdx
jne .L1
以上優(yōu)化方法的效果可以通過 CPE 來度量,在 Intel Core i7 Haswell 的測試結(jié)果如下。從測試結(jié)果來看:
combine1 版本不同編譯優(yōu)化級別,-O1 的性能是 -O0 的兩倍,表明開啟適當(dāng)?shù)鼐幾g優(yōu)化級別是很有必要的。
combine2 將 vec_length 移出循環(huán)后,在同樣的優(yōu)化級別編譯,相較 combine1 的性能有微小的提升。
但是 combine3 相比 combine2 并沒有性能提升,原因是由于循環(huán)中的其它操作的耗時可以掩蓋調(diào)用 get_vec_element 的耗時,之所以可以掩蓋,得益于 CPU 支持分支預(yù)測和亂序執(zhí)行,本文的后面會簡單介紹這兩個概念。
同樣地,combine3 的 -O2 版本比 -O1 版本性能好很多,從匯編碼可以看到,-O2 時比 -O1 每次循環(huán)減少了一次對 (% rbx) 的讀,更重要的是消除了對 (% rbx) 寫后讀的訪存依賴。
經(jīng)過 combine4 將中間結(jié)果暫存到臨時變量的優(yōu)化,可以看到即使使用 -O1 的編譯優(yōu)化,也比 combine3 -O2 的編譯優(yōu)化性能更好,表明即使編譯器有強大的優(yōu)化能力,但是注意細節(jié)來編寫高性能代碼也是非常有必要的。
以下測試數(shù)據(jù)引用自《深入理解計算機系統(tǒng)》第五章。
| 函數(shù) | 優(yōu)化方法 | int + | int * | float + | float * |
|---|---|---|---|---|---|
| combine1 | -O0 | 22.68 | 20.02 | 19.98 | 20.18 |
| combine1 | -O1 | 10.12 | 10.12 | 10.17 | 11.14 |
| combine2 | 移動 vec_length -O1 | 7.02 | 9.03 | 9.02 | 11.03 |
| combine3 | 減少過程調(diào)用 -O1 | 7.17 | 9.02 | 9.02 | 11.03 |
| combine3 | 減少過程調(diào)用 -O2 | 1.60 | 3.01 | 3.01 | 5.01 |
| combine4 | 累積到臨時變量 -O1 | 1.27 | 3.01 | 3.01 | 5.01 |
指令級并行
以上優(yōu)化不依賴于目標(biāo)機器的任何特性,只是簡單地降低了過程調(diào)用的開銷,以及消除一些 “妨礙優(yōu)化的因素”,這些因素會給編譯器優(yōu)化帶來困難。要進行進一步優(yōu)化,需要了解一些硬件特性。下圖是 Intel Core i7 Haswell 的硬件結(jié)構(gòu)的后端部分: 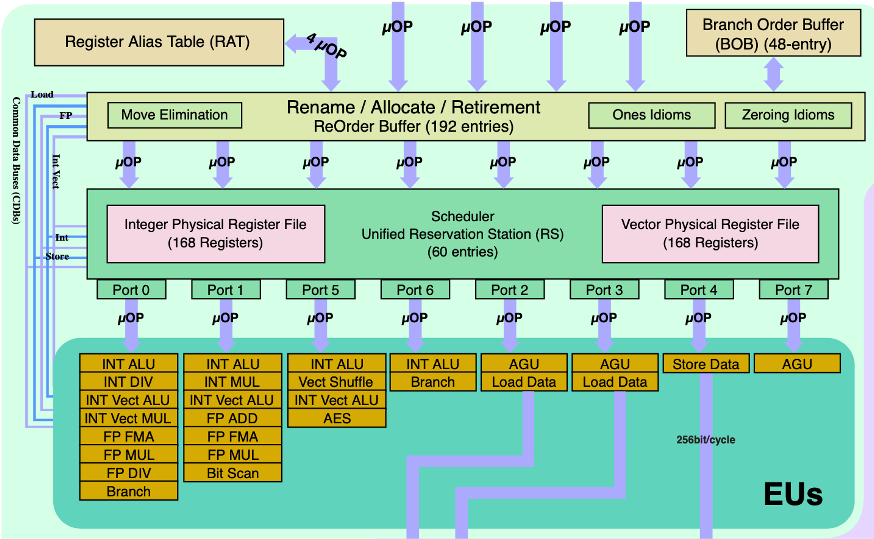
完整的 Intel Core i7 Haswell 的硬件結(jié)構(gòu)見:https://en.wikichip.org/w/images/c/c7/haswell_block_diagram.svg
硬件性能
該 CPU 支持以下特性:
指令級并行:即通過指令流水線技術(shù),支持同時對多條指令求值。
亂序執(zhí)行:指令的執(zhí)行順序未必和其書寫的順序一致,可以使硬件達到更好的指令級并行度。主要是通過亂序執(zhí)行、順序提交的機制,使得能夠獲得和順序執(zhí)行一致的結(jié)果。
分支預(yù)測:當(dāng)遇到分支時,硬件會預(yù)測分支的走向,如果預(yù)測成功則能夠加快程序的運行,但是預(yù)測失敗的話則需要把提前執(zhí)行的結(jié)果丟棄,重新 load 正確指令執(zhí)行,會帶來比較大的預(yù)測錯誤懲罰。
上圖中,主要關(guān)注執(zhí)行單元 (EUs),執(zhí)行單元由多個功能單元組成。功能單元的性能可以由延遲、發(fā)射時間和容量來度量。
延遲:執(zhí)行完一條指令需要的時鐘周期數(shù)。
發(fā)射時間:兩個連續(xù)的同類型的運算之間需要的最小時鐘周期數(shù)。
容量:某種執(zhí)行單元的數(shù)量。從上圖可以看出,在EUs中,有 4 個整數(shù)加法單元 (INT ALU)、1 個整數(shù)乘法單元 (INT MUL)、1 個浮點數(shù)加法單元 (FP ADD) 和 2 個浮點數(shù)乘法單元 (FP MUL)。
Intel Core i7 Haswell 的功能單元性能數(shù)據(jù)(單位為周期數(shù))如下,引自《深入理解計算機系統(tǒng)》第五章:
| 運算 | 延遲 (int) | 發(fā)射時間 (int) | 容量 (int) | 延遲 (float) | 發(fā)射時間 (float) | 容量 (float) |
|---|---|---|---|---|---|---|
| 加法 | 1 | 1 | 4 | 3 | 1 | 1 |
| 乘法 | 3 | 1 | 1 | 5 | 1 | 2 |
這些算術(shù)運算的延遲、發(fā)射時間和容量會影響上述combine函數(shù)的性能,我們用 CPE 的兩個界限來描述這種影響。吞吐界限是理論上的最優(yōu)性能。
延遲界限:任何必須按照嚴(yán)格順序完成combine運算的函數(shù)所需要的最小 CPE,等于功能單元的延遲。
吞吐界限:功能單元產(chǎn)生結(jié)果的最大速率,由容量/發(fā)射時間決定。若使用 CPE 度量,則等于容量/發(fā)射時間的倒數(shù)。
由于combine函數(shù)需要 load 數(shù)據(jù),故要同時受到加載單元的限制。由于只有兩個加載單元且其發(fā)射時間為 1 個周期,所以整數(shù)加法的吞吐界限在本例中只有 0.5 而非 0.25。
| 界限 | int + | int * | float + | float * |
|---|---|---|---|---|
| 延遲 | 1.0 | 3.0 | 3.0 | 5.0 |
| 吞吐 | 0.5 | 1.0 | 1.0 | 0.5 |
處理器操作的抽象模型
為了分析在現(xiàn)代處理器上執(zhí)行的機器級程序的性能,我們引入數(shù)據(jù)流圖,這是一種圖形化表示方法,展現(xiàn)了不同操作之間的數(shù)據(jù)相關(guān)是如何限制它們的執(zhí)行順序的。這些限制形成了圖中的關(guān)鍵路徑,這是執(zhí)行一組機器指令所需時鐘周期的一個下界。 通常 for 循環(huán)會占據(jù)程序執(zhí)行的大部分時間,下圖是combine4的 for 循環(huán)對應(yīng)的數(shù)據(jù)流圖。其中箭頭指示了數(shù)據(jù)的流向。可以將寄存器分為四類:
只讀:這些寄存器只用作源值,在循環(huán)中不被修改,本例中的%rax。
只寫:作為數(shù)據(jù)傳送的目的。本例沒有這樣的寄存器。
局部:在循環(huán)內(nèi)部被修改和使用,迭代與迭代之間不相關(guān),比例中的條件碼寄存器。
循環(huán):這些寄存器既作為源值,又作為目的,一次迭代中產(chǎn)生的值會被下一次迭代用到,本例中的%rdx和%xmm0。由于兩次迭代之間有數(shù)據(jù)依賴,所以對此類寄存器的操作通常是程序性能的限制因素。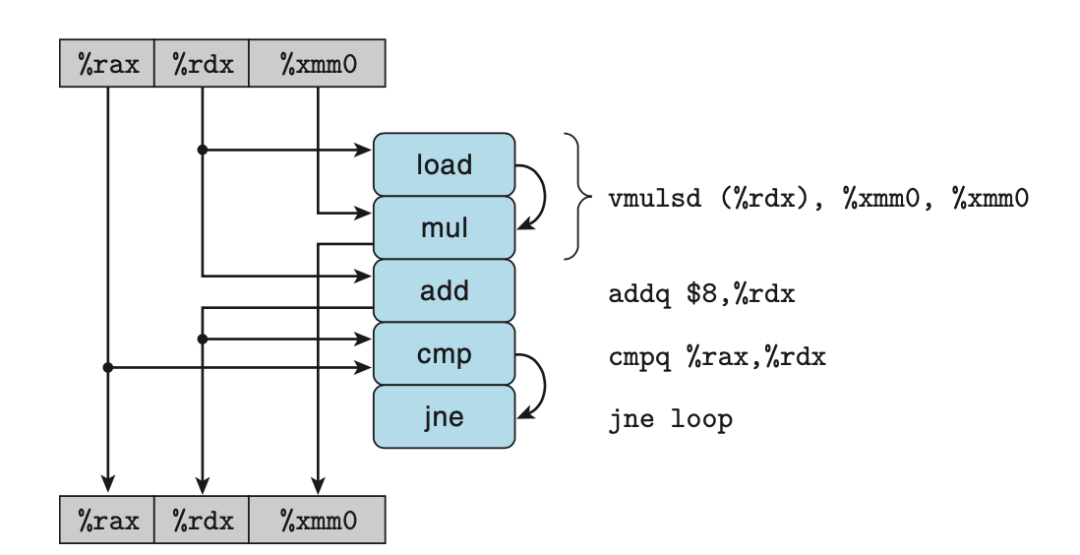
將上圖重排,并只留下循環(huán)寄存器相關(guān)的路徑,可得到簡化的數(shù)據(jù)流圖。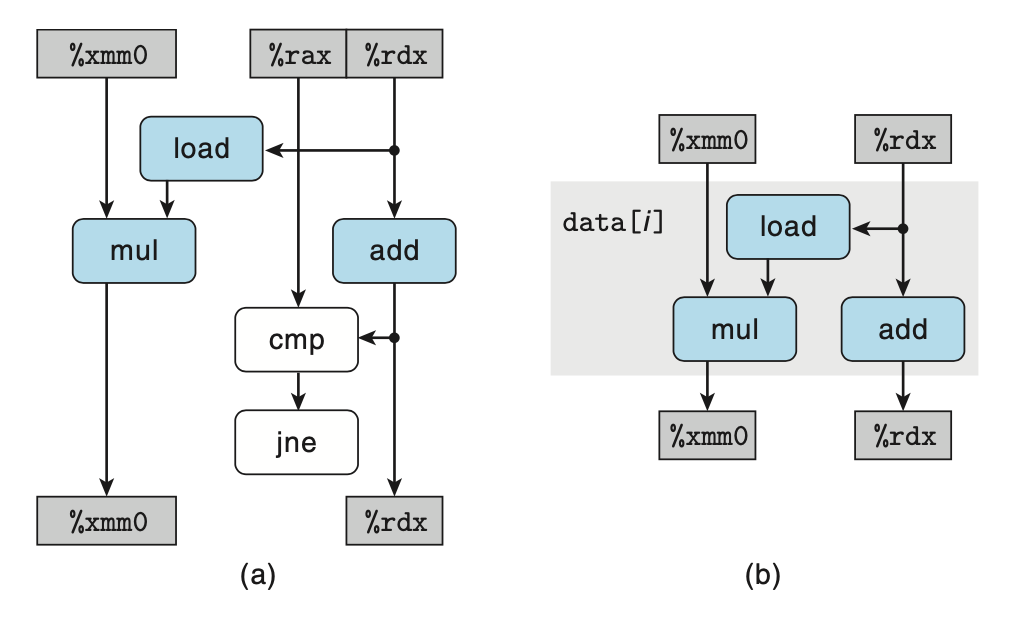 將簡化完的數(shù)據(jù)流圖進行簡單地重復(fù),可以得到關(guān)鍵路徑,如下圖。如果?combine4?中計算的是浮點數(shù)乘法,由于支持指令級并行,浮點數(shù)乘法的的延遲能夠掩蓋整數(shù)加法 (指針移動,圖中右半邊的路徑) 的延遲,所以?combine4CPE 的理論下界就是浮點乘法的延遲 5.0,與上面給出的測試數(shù)據(jù) 5.01 基本一致。?
將簡化完的數(shù)據(jù)流圖進行簡單地重復(fù),可以得到關(guān)鍵路徑,如下圖。如果?combine4?中計算的是浮點數(shù)乘法,由于支持指令級并行,浮點數(shù)乘法的的延遲能夠掩蓋整數(shù)加法 (指針移動,圖中右半邊的路徑) 的延遲,所以?combine4CPE 的理論下界就是浮點乘法的延遲 5.0,與上面給出的測試數(shù)據(jù) 5.01 基本一致。?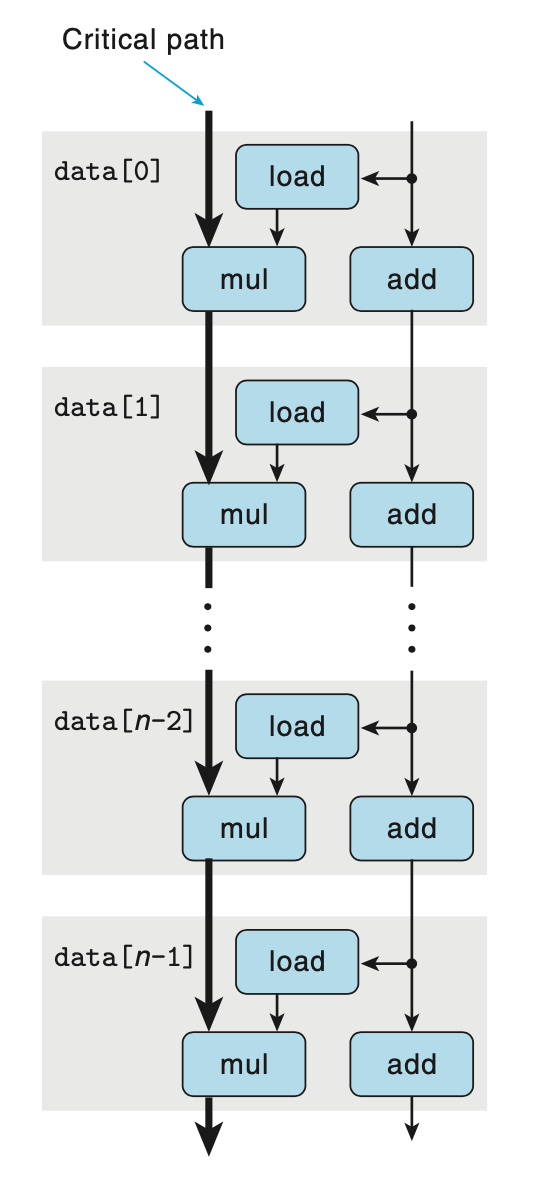
循環(huán)展開
目前為止,我們程序的性能只達到了延遲界限,這是因為下一次浮點乘法必須等上一次乘法結(jié)束后才開始,不能充分利用硬件的指令級并行。使用循環(huán)展開的技術(shù),可以提高關(guān)鍵路徑的指令并行度。
void combine5(vec_ptr v, data_t *dest) {
long i;
long length = vec_length(v);
long limit = length - 1;
data_t *data = get_vec_start(v);
data_t acc0 = IDENT;
data_t acc1 = IDENT;
for (i = 0; i < limit; i += 2) {
acc0 = acc0 OP data[i];
acc1 = acc1 OP data[i + 1];
}
for (; i < length; ++i) {
acc0 = acc0 OP data[i];
}
*dest = acc0 OP acc1;
}
combine5的關(guān)鍵路徑的數(shù)據(jù)流圖如下,圖中有兩條關(guān)鍵路徑,但兩條關(guān)鍵路徑是可以指令級并行的,每條關(guān)鍵路徑只包含n/2個操作,因此性能可以突破延遲界限,理論上浮點乘法的 CPE 約為5.0/2=2.5。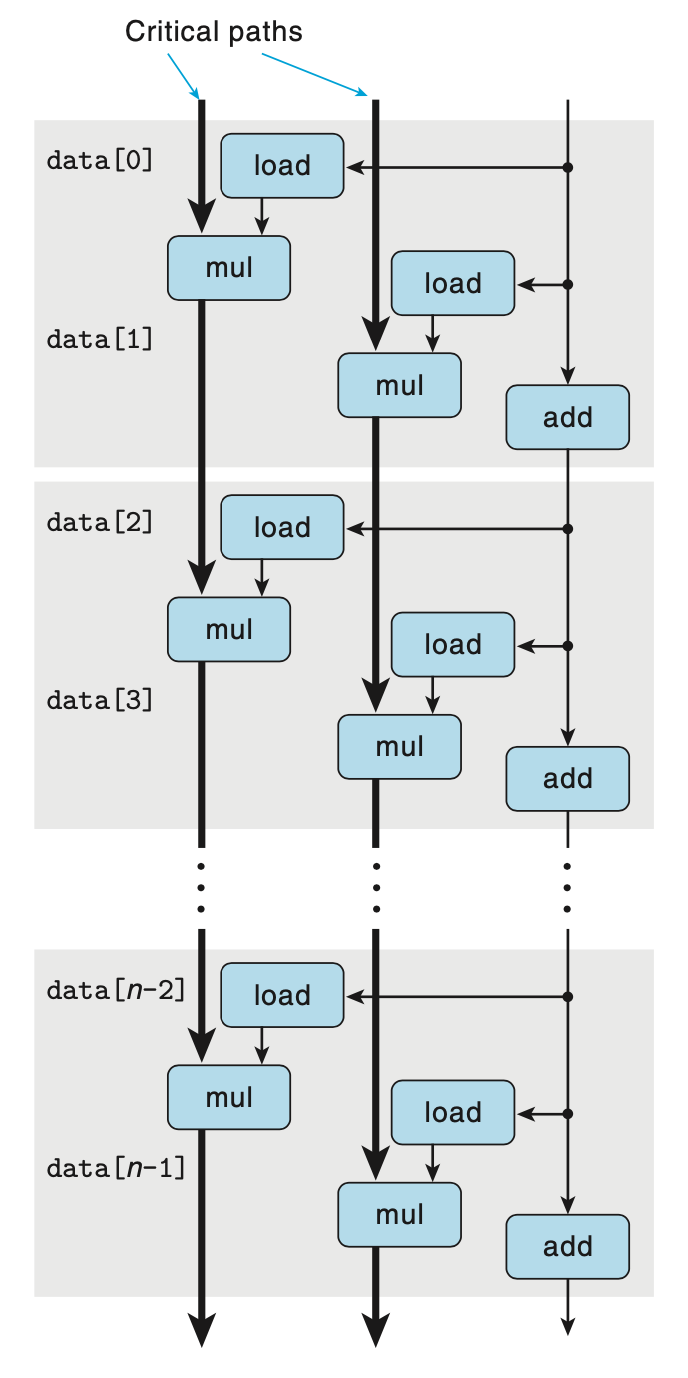 假如增加臨時變量的個數(shù)進一步增加循環(huán)展開次數(shù),理論上可以提高指令并行度,最終達到吞吐界限。但是不能無限制地增加循環(huán)展開次數(shù),一是由于硬件的功能單元有限,CPE 的下界由吞吐界限限制,達到一定程度后繼續(xù)增加也不能提高指令并行度;二是由于寄存器資源有限,增加循環(huán)展開次數(shù)會增加寄存器的使用,使用的寄存器個數(shù)超過硬件提供的寄存器資源之后,則會發(fā)生寄存器溢出,可能會需要將寄存器的內(nèi)存臨時保存到內(nèi)存,使用時再從內(nèi)存恢復(fù)到寄存器,反而導(dǎo)致性能的下降,如下表中循環(huán)展開 20 次相較展開 10 次性能反而略有下降。幸運的是,大多數(shù)硬件在寄存器溢出之前已經(jīng)達到了吞吐界限。
假如增加臨時變量的個數(shù)進一步增加循環(huán)展開次數(shù),理論上可以提高指令并行度,最終達到吞吐界限。但是不能無限制地增加循環(huán)展開次數(shù),一是由于硬件的功能單元有限,CPE 的下界由吞吐界限限制,達到一定程度后繼續(xù)增加也不能提高指令并行度;二是由于寄存器資源有限,增加循環(huán)展開次數(shù)會增加寄存器的使用,使用的寄存器個數(shù)超過硬件提供的寄存器資源之后,則會發(fā)生寄存器溢出,可能會需要將寄存器的內(nèi)存臨時保存到內(nèi)存,使用時再從內(nèi)存恢復(fù)到寄存器,反而導(dǎo)致性能的下降,如下表中循環(huán)展開 20 次相較展開 10 次性能反而略有下降。幸運的是,大多數(shù)硬件在寄存器溢出之前已經(jīng)達到了吞吐界限。
| 函數(shù) | 展開次數(shù) | int + | int * | float + | float * |
|---|---|---|---|---|---|
| combine5 | 2 | 0.81 | 1.51 | 1.51 | 2.51 |
| combine5 | 10 | 0.55 | 1.00 | 1.01 | 0.52 |
| combine5 | 20 | 0.83 | 1.03 | 1.02 | 0.68 |
| 延遲界限 | / | 1.00 | 3.00 | 3.00 | 5.00 |
| 吞吐界限 | / | 0.50 | 1.00 | 1.00 | 0.50 |
SIMD(single instruction multi data)
SIMD是另外一種行之有效的性能優(yōu)化手段,不同于指令級并行,其采用數(shù)據(jù)級并行。SIMD 即單指令多數(shù)據(jù),一條指令操作一批向量數(shù)據(jù),需要硬件提供支持。X86 架構(gòu)的 CPU 支持 AVX 指令集,ARM CPU 支持 NEON 指令集。在我們開發(fā)的一款深度學(xué)習(xí)編譯器 MegCC 中,就廣泛使用了 SIMD 技術(shù)。MegCC 是曠視天元團隊開發(fā)的深度學(xué)習(xí)編譯器,其接受 MegEngine 格式的模型為輸入,輸出運行該模型所需的所有 kernel,方便模型部署,具有高性能和輕量化的特點。為了方便用戶將其它格式的模型轉(zhuǎn)換為 MegEngine 格式模型,曠視天元團隊同時提供了模型轉(zhuǎn)換工具 MgeConvert,您可以將模型轉(zhuǎn)換為onnx,然后使用 MgeConvert 轉(zhuǎn)換為 MegEngine 格式模型。同時如果您想測試您設(shè)備上某條指令的吞吐和延遲,以指導(dǎo)您的優(yōu)化,可以使用 MegPeak。 MegCC 中實現(xiàn)了許多高性能的深度學(xué)習(xí)算子,卷積和矩陣乘法是典型的計算密集型的算子,同時卷積也可以借助矩陣乘法來實現(xiàn) (im2col/winograd 算法等)。 MegCC 在 ARM 平臺支持了 NEON DOT 和 I8MM 指令實現(xiàn)的矩陣乘和卷積。一條DOT指令可完成 32 次乘加運算 (16 次乘法和 16 次加法運算);一條I8MM指令可完成 64 次乘加運算 (32 次乘法和 32 次加法運算)。這就是 SIMD 技術(shù)能夠加速計算的原理。
編輯:黃飛
-
處理器
+關(guān)注
關(guān)注
68文章
19893瀏覽量
235175 -
寄存器
+關(guān)注
關(guān)注
31文章
5434瀏覽量
124469 -
cpu
+關(guān)注
關(guān)注
68文章
11080瀏覽量
217055 -
函數(shù)
+關(guān)注
關(guān)注
3文章
4381瀏覽量
64862 -
編譯器
+關(guān)注
關(guān)注
1文章
1662瀏覽量
50217
原文標(biāo)題:CPU程序性能優(yōu)化
文章出處:【微信號:OSC開源社區(qū),微信公眾號:OSC開源社區(qū)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
《現(xiàn)代CPU性能分析與優(yōu)化》---精簡的優(yōu)化書
《現(xiàn)代CPU性能分析與優(yōu)化》--讀書心得筆記
XScale 應(yīng)用程序性能的優(yōu)化策略
快速識別應(yīng)用程序性能瓶頸
ARM程序設(shè)計優(yōu)化
DVFS對程序性能影響模型
7個好習(xí)慣快速提升Python程序性能

了解 LabVIEW 程序運行性能的關(guān)鍵因素
了解CPI對分析程序性能的意義
LabVIEW應(yīng)用程序中性能瓶頸的解決
通過32Gb/S光纖通道提高應(yīng)用程序性能

第6代光纖通道:加速全閃存數(shù)據(jù)中心的數(shù)據(jù)訪問和應(yīng)用程序性能
使用Brocade Gen 7 SAN確保應(yīng)用程序性能和可靠性





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論