") SC23 | 新型加速節(jié)能 AI 系統(tǒng)開創(chuàng)超級(jí)計(jì)算的新時(shí)代
SC23 | 新型加速節(jié)能 AI 系統(tǒng)開創(chuàng)超級(jí)計(jì)算的新時(shí)代

世界各地的研究人員將在配備最新 NVIDIA Hopper GPU 和 NVIDIA Grace Hopper 超級(jí)芯片的系統(tǒng)上,借助生成式 AI 和 HPC 來應(yīng)對(duì)科學(xué)和工業(yè)領(lǐng)域的重大挑戰(zhàn)。
11 月 13 日,NVIDIA 在 SC23 上發(fā)布了一系列新技術(shù),將全球各地的科學(xué)和工業(yè)研究中心推向性能和能效新高。
NVIDIA 高性能計(jì)算和超大規(guī)模數(shù)據(jù)中心業(yè)務(wù)副總裁 Ian Buck 在 SC 大會(huì)發(fā)表的特別演講中提到:“NVIDIA 的硬件和軟件創(chuàng)新正在創(chuàng)造一種新型 AI 超級(jí)計(jì)算機(jī)。”
其中一些超級(jí)計(jì)算機(jī)將配備內(nèi)存增強(qiáng)的 NVIDIA Hopper 加速器,另一些則采用全新 NVIDIA Grace Hopper 系統(tǒng)架構(gòu)。它們都將使用擴(kuò)展的并行結(jié)構(gòu)來運(yùn)行面向生成式 AI 、HPC 和混合量子計(jì)算的全棧加速軟件。
Buck 將全新 NVIDIA HGX H200 稱為“世界領(lǐng)先的 AI 計(jì)算平臺(tái)”。
它配備高達(dá) 141 GB 的 HBM3e,是首款使用這項(xiàng)超快技術(shù)的 AI 加速器。在運(yùn)行 GPT-3 等模型時(shí),NVIDIA H200 Tensor Core GPU 的性能比上一代加速器高出 18 倍。

NVIDIA H200 Tensor Core GPU 配備HBM3e 內(nèi)存,
可運(yùn)行不斷增長的生成式 AI 模型
在其他生成式AI基準(zhǔn)測(cè)試中,它們?cè)谝粋€(gè) Llama2-13B 大語言模型(LLM)上每秒可快速通過 12,000 個(gè) token 。
Buck 還展示了一個(gè)服務(wù)器平臺(tái),該平臺(tái)在一個(gè) NVIDIA NVLink 互聯(lián)下連接了四個(gè) NVIDIA GH200 Grace Hopper 超級(jí)芯片。這一四組芯片的配置使得在一個(gè)計(jì)算節(jié)點(diǎn)內(nèi)有高達(dá) 288 個(gè) Arm Neoverse 核心,以及 2.3 TB 的高速內(nèi)存 ,實(shí)現(xiàn)了 16 petaflops 的 AI 性能。

基于四個(gè) GH200 超級(jí)芯片的服務(wù)器節(jié)點(diǎn),提供 16 petaflops 的 AI 性能
采用 NVIDIA TensorRT-LLM 開源庫的單個(gè) GH200 超級(jí)芯片比一個(gè)雙插槽 x86 CPU 系統(tǒng)快 100 倍,比一臺(tái) x86 + H100 GPU 服務(wù)器節(jié)能近 2 倍,展現(xiàn)了卓越的節(jié)能效果。
Buck 說:“加速計(jì)算是可持續(xù)的計(jì)算。通過充分利用加速計(jì)算和生成式 AI,我們可以推動(dòng)各行各業(yè)的創(chuàng)新,同時(shí)減少對(duì)環(huán)境的影響。”
新上榜 TOP500 的 49 個(gè)系統(tǒng)中
有 38 個(gè)采用了 NVIDIA 技術(shù)
最新發(fā)布的全球最快的超級(jí)計(jì)算機(jī) TOP500 榜單顯示,人們正在轉(zhuǎn)向加速、節(jié)能的超級(jí)計(jì)算。
由于諸多新建超級(jí)計(jì)算機(jī)采用了 NVIDIA H100 Tensor Core GPU,NVIDIA 目前在這些世界領(lǐng)先的系統(tǒng)中提供超過 2.5 exaflops 的 HPC 性能,相較此前 5 月榜單中的 1.6 exaflops 有了不少提升。僅在全球超級(jí)計(jì)算機(jī) Top 10 中,NVIDIA 就提供近 1 exaflop 的 HPC 性能和 72 exaflops 的 AI 性能。
在新榜單中,采用 NVIDIA 技術(shù)的超級(jí)計(jì)算機(jī)數(shù)量再創(chuàng)新高,從 5 月份的 372 個(gè)增加到 379 個(gè),其中包括 49 個(gè)新上榜超級(jí)計(jì)算機(jī)中的 38 個(gè)。
部署在 Microsoft Azure 中的 Eagle 系統(tǒng)是算力最高的新上榜超級(jí)計(jì)算機(jī),其采用 H100 GPU,在 NDv5 實(shí)例中以 561 petaflops 的算力在總榜中排名第三。巴塞羅那的 Mare Nostrum5 排名第 8 ,而最近在 MLPerf 基準(zhǔn)測(cè)試中創(chuàng)下 AI 訓(xùn)練新紀(jì)錄的 NVIDIA Eos 排名第 9 。
在 Green500 的前 30 名中有 23 個(gè)采用了 NVIDIA GPU ,彰顯了它們的節(jié)能優(yōu)勢(shì)。配備 H100 GPU 的 Henri 系統(tǒng)蟬聯(lián)第一,它位于紐約 Flatiron 研究所,能效為每瓦 65.09 gigaflops 。
使用生成式 AI 探索新冠病毒
美國阿貢國家實(shí)驗(yàn)室展現(xiàn)了無限可能,它使用 NVIDIA BioNeMo(一個(gè)面向生物分子大語言模型的生成式 AI 平臺(tái))開發(fā)了 GenSLM 模型。這個(gè)模型可以生成與冠狀病毒的現(xiàn)實(shí)變種非常相似的基因序列。使用 NVIDIA GPU 以及來自 150 萬個(gè)新冠病毒基因組序列的數(shù)據(jù),它還可以快速識(shí)別出新的病毒變種。
這項(xiàng)工作去年獲得了戈登·貝爾特別獎(jiǎng),并在包括美國阿貢國家實(shí)驗(yàn)室的 Polaris 系統(tǒng)、美國能源部的 Perlmutter 和 NVIDIA 的 Selene 在內(nèi)的超級(jí)計(jì)算機(jī)上進(jìn)行了訓(xùn)練。
NVIDIA 醫(yī)療業(yè)務(wù)副總裁 Kimberly Powell 在此次特別演講中提到:“這只是冰山一角。隨著生成式 AI 不斷重新定義科學(xué)探索,未來充滿了無限可能。”
節(jié)約時(shí)間、金錢和能源
Buck 提到,使用最新技術(shù)為工作負(fù)載加速可以將系統(tǒng)的成本和能耗降低一個(gè)數(shù)量級(jí)。
例如,西門子與梅賽德斯合作為新其款 EQE 電動(dòng)汽車分析空氣動(dòng)力學(xué)和相關(guān)聲學(xué)。這類模擬此前在 CPU 集群上通常耗時(shí)數(shù)周時(shí)間,而借助最新的 NVIDIA H100 GPU ,其速度要快很多。此外,Hopper GPU 使成本降低了 3 倍,能耗降低了 4 倍(如下如所示)。
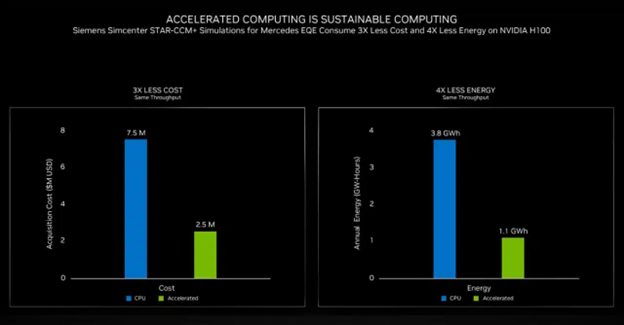
明年將開啟 200 Exaflops 時(shí)代
在全球各地,部署這些最新系統(tǒng)將推動(dòng)科學(xué)和工業(yè)領(lǐng)域不斷取得進(jìn)步。
Buck 說:“我們已經(jīng)看到,2024 年將有基于 Grace Hopper 超級(jí)計(jì)算機(jī)的總計(jì) 200 exaflopsAI 算力投入生產(chǎn)。”
其中包括德國于希利研究中心的大型 JUPITER 超級(jí)計(jì)算機(jī)。它可以為 AI 訓(xùn)練提供 93 exaflops 的性能,為 HPC 應(yīng)用提供 1 exaflop 的性能,而能耗僅為 18.2 兆瓦。
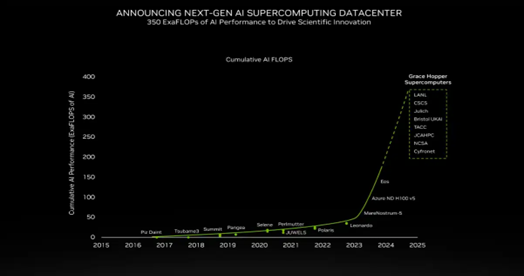
GH200 為研究中心帶來性能飆升
基于 Eviden 的 BullSequana XH3000 液冷系統(tǒng),JUPITER 將使用 NVIDIA quad GH200 系統(tǒng)架構(gòu)和 NVIDIA Quantum-2 InfiniBand 網(wǎng)絡(luò),用于進(jìn)行氣候和天氣預(yù)測(cè)、藥物發(fā)現(xiàn)、混合量子計(jì)算和數(shù)字孿生。JUPITER 所采用的 quad GH200 節(jié)點(diǎn)將配置 864 GB 的高速內(nèi)存。
這是 NVIDIA 在 SC23 上宣布的數(shù)個(gè)使用 Grace Hopper 的新型超級(jí)計(jì)算機(jī)之一。
慧與(Hewlett Packard Enterprise)的 HPE Cray EX2500 系統(tǒng)將為明年投入使用的眾多AI超級(jí)計(jì)算機(jī)配備 quad GH200。
例如,慧與建設(shè)的 OFP-II(一個(gè)由日本筑波大學(xué)和東京大學(xué)共享的先進(jìn) HPC 系統(tǒng))以及 DeltaAI 系統(tǒng)(將使美國國家超級(jí)計(jì)算應(yīng)用中心的算力提升三倍)均將采用 quad GH200。
HPE 正在為美國洛斯阿拉莫斯國家實(shí)驗(yàn)室建造 Venado 系統(tǒng),這是在美國部署的首個(gè) GH200,其還將在中東、瑞士和英國建設(shè)更多 GH200 超級(jí)計(jì)算機(jī)。
德克薩斯及更多地區(qū)采用 Grace Hopper
在德克薩斯高級(jí)計(jì)算中心(TACC),戴爾科技集團(tuán)正在使用 NVIDIA Grace Hopper 和 Grace CPU 超級(jí)芯片建造 Vista 超級(jí)計(jì)算機(jī)。
Buck 表示,包括美國航空航天局艾姆斯研究中心(NASA Ames Research Center)和 Total Energies 在內(nèi)的全球 100 多個(gè)企業(yè)和組織已經(jīng)采購了 Grace Hopper 早期訪問系統(tǒng)。
此前已宣布采用 GH200 的用戶包括軟銀和布里斯托大學(xué),以及配備 14000 個(gè) NVIDIA A100 GPU 的大型 Leonardo 系統(tǒng),后者為意大利 Cineca 聯(lián)盟提供 10 exaflops 的 AI 性能。
超算中心的觀點(diǎn)
來自世界各地超算中心的主管介紹了他們采用最新系統(tǒng)的計(jì)劃及進(jìn)展。
瑞士國家超級(jí)計(jì)算中心負(fù)責(zé)阿爾卑斯超級(jí)計(jì)算機(jī)的主任 Thomas Schultess 表示:“我們一直在與 MeteoWiss ECMWP 以及參與 ETH EXCLAIM 和 NVIDIA Earth-2 計(jì)劃的科學(xué)家合作打造一個(gè)基礎(chǔ)設(shè)施,以期在大數(shù)據(jù)分析和超大規(guī)模計(jì)算的各個(gè)方面取得突破。”
德克薩斯高級(jí)計(jì)算中心(TACC)的執(zhí)行主任 Dan Stanzione 在談到 Vista 時(shí)表示:“我們的各個(gè)堆棧都極大提升了能效。”
他說:“這真的是一塊墊腳石,推動(dòng)用戶從過去使用的系統(tǒng)轉(zhuǎn)向這種將 Grace Arm CPU 和 Hopper GPU 緊密配合的新系統(tǒng),而且……我們希望在幾年后部署 Horizon 時(shí),其規(guī)模將是 Vista 的 10 或 15 倍。”
加速量子進(jìn)程
研究人員們還在利用當(dāng)今的加速系統(tǒng)開拓通往未來超級(jí)計(jì)算機(jī)的道路。
于利希研究中心量子信息處理研究小組負(fù)責(zé)人 Kristel Michelson 表示,在德國,JUPITER 超級(jí)計(jì)算機(jī)“將徹底改變氣候、材料、藥物發(fā)現(xiàn)和量子計(jì)算領(lǐng)域的科研工作”。
她說:“ JUPITER 的架構(gòu)還允許量子算法與并行 HPC 算法無縫集成,這對(duì)于有效的量子 HPC 混合模擬來說是必需的。”
CUDA Quantum 推動(dòng)進(jìn)步
此次演講還展示了 NVIDIA CUDA Quantum —— 一個(gè)用于編程 CPU、GPU 和 QPU(量子計(jì)算機(jī))的平臺(tái),是如何推進(jìn)量子計(jì)算研究的。
例如,全球最大的化工企業(yè)巴斯夫的研究人員開創(chuàng)了一種新的混合量子經(jīng)典方法,用于模擬可以保護(hù)人類免受有害金屬侵害的化合物。此外,美國布魯克海文國家實(shí)驗(yàn)室和 HPE 的研究人員也分別在利用 CUDA Quantum 推動(dòng)前沿科研工作。
NVIDIA 還宣布與量子編程工具開發(fā)商 Classiq 合作,在以色列最大的教學(xué)醫(yī)院 Tel Aviv Sourasky Medical Center 創(chuàng)建一個(gè)生命科學(xué)研究中心。該中心將使用 Classiq 軟件和運(yùn)行于 NVIDIA DGX H100 系統(tǒng)之上的 CUDA Quantum 。
另外,Quantum Machines 公司將在以色列國家量子中心部署首個(gè)配備 Grace Hopper 超級(jí)芯片的 NVIDIA DGX Quantum ,旨在推動(dòng)各個(gè)科學(xué)領(lǐng)域的進(jìn)步。這個(gè) DGX 系統(tǒng)將連接到一臺(tái) Quantware 的超導(dǎo) QPU 和一臺(tái) ORCA Computing 的光子 QPU,兩者均由 CUDA Quantum 驅(qū)動(dòng)。
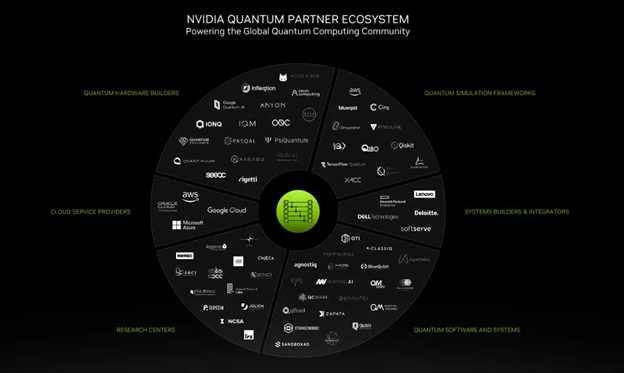
Buck 說:“在短短兩年內(nèi),NVIDIA 的量子計(jì)算平臺(tái)已經(jīng)擁有 120 多個(gè)合作伙伴(如上圖),這證明它是一個(gè)開放、創(chuàng)新的平臺(tái)。”
總的來說,諸多科研領(lǐng)域的工作揭示了一種新趨勢(shì),那就是將數(shù)據(jù)中心規(guī)模的加速計(jì)算與 NVIDIA 的全棧創(chuàng)新相結(jié)合。
他總結(jié)道:“加速計(jì)算正在為可持續(xù)計(jì)算鋪平道路,并且已經(jīng)取得了諸多進(jìn)步,不僅提供令人驚嘆的技術(shù),而且將開創(chuàng)更加可持續(xù)、更有影響力的未來。”
GTC 2024 將于 2024 年 3 月 18 至 21 日在美國加州圣何塞會(huì)議中心舉行,線上大會(huì)也將同期開放。點(diǎn)擊“閱讀原文”或掃描下方海報(bào)二維碼,立即注冊(cè) GTC 大會(huì)。
原文標(biāo)題:SC23 | 新型加速節(jié)能 AI 系統(tǒng)開創(chuàng)超級(jí)計(jì)算的新時(shí)代
文章出處:【微信公眾號(hào):NVIDIA英偉達(dá)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
-
英偉達(dá)
+關(guān)注
關(guān)注
22文章
3952瀏覽量
93759
原文標(biāo)題:SC23 | 新型加速節(jié)能 AI 系統(tǒng)開創(chuàng)超級(jí)計(jì)算的新時(shí)代
文章出處:【微信號(hào):NVIDIA_China,微信公眾號(hào):NVIDIA英偉達(dá)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
迅為RK3576核心板高算力AI開發(fā)板開啟智能應(yīng)用新時(shí)代

LMFD格子多相流體力學(xué)仿真機(jī):超級(jí)計(jì)算如何實(shí)現(xiàn)平民化?
Intel-Altera FPGA:通信行業(yè)的加速引擎,開啟高速互聯(lián)新時(shí)代
誠邁科技、智達(dá)誠遠(yuǎn)隆重推出ArraymoAIOS 2.0 端側(cè)AI操作系統(tǒng),開啟智能體協(xié)作新時(shí)代

聯(lián)想集團(tuán)領(lǐng)跑AI普惠新時(shí)代
適用于數(shù)據(jù)中心和AI時(shí)代的800G網(wǎng)絡(luò)
英偉達(dá)GTC25亮點(diǎn):NVIDIA Blackwell Ultra 開啟 AI 推理新時(shí)代
FPGA+AI王炸組合如何重塑未來世界:看看DeepSeek東方神秘力量如何預(yù)測(cè)......
當(dāng)我問DeepSeek AI爆發(fā)時(shí)代的FPGA是否重要?答案是......
NVIDIA JetPack 6.2引入Super模式

中國信通院栗蔚:云計(jì)算與AI加速融合,如何開啟智算時(shí)代新紀(jì)元?

星河AI加速新時(shí)代教育數(shù)智化轉(zhuǎn)型
NVIDIA加速全球大多數(shù)超級(jí)計(jì)算機(jī)推動(dòng)科技進(jìn)步

NVIDIA 以太網(wǎng)加速 xAI 構(gòu)建的全球最大 AI 超級(jí)計(jì)算機(jī)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論