 OpenVINO賦能潛在一致性模型(LCMs)的高速圖像生成
OpenVINO賦能潛在一致性模型(LCMs)的高速圖像生成
提起生成式 AI,從去年開始爆火至今,相信無論是不是 AI 領域的開發者,對這個概念都是毫不陌生了。說到生成式 AI 領域的典型應用場景和模型,相信大家最先想到的就是文生圖這個場景,以及它背后一系列的潛在擴散模型(Latent Diffusion models, LDMs)。借由這些模型的強大能力,只需要輸入一段文字,人人都可化身設計師、插畫師,進行精美圖片的創作。但是,調用文生圖模型的時候,若是選擇調用云端運行的 API ,可能需要付費的同時、還有可能面臨排隊等待等問題。如果選擇在本地機器上運行,那么對于機器的算力和內存就有較高的要求,同時也需要進行長時間的等待,畢竟這些模型往往需要迭代幾十次之后才能生成一幅比較精美的圖片。
最近一個稱之為LCMs(Latent Consistency Models)的模型橫空出世,讓文生圖模型的圖片急速生成成為了可能。受到一致性模型(CM)的啟發,潛在一致性模型(LCMs),可以在任何預訓練的潛在擴散模型上進行快速推斷、步驟最少,包括穩定擴散模型(Stable Diffusion)。一致性模型是一種新的生成模型家族,可以實現一步或少量步驟生成。其核心思想是學習 PF-ODE(常微分方程概率流的軌跡)解的函數。通過學習保持 ODE 軌跡上點的一致性的一致性映射,這些模型允許進行單步生成,消除了計算密集的迭代的需求。然而,CM 受限于像素空間圖像生成任務,因此不適用于合成高分辨率圖像。LCMs 在圖像潛在空間采用一致性模型來生成高分辨率圖像。將引導反向擴散過程視為解決 PF-ODE 的過程。LCMs 旨在直接預測潛在空間中這種 ODE 的解,減少了大量迭代的需求,實現了快速、高保真度的采樣。在大規模擴散模型(如 Stable Diffusion)中利用圖像潛在空間有效地增強了圖像生成質量并減少了計算負載,使得圖片急速生成成為了可能。
有關所提出方法和模型的更多詳細信息,可以在項目頁面[1]、論文[2]和原始倉庫[3]中找到。
如此充滿魔力的 LCMs 文生圖模型,我們的 OpenVINO 當然也可以對它進行完全的優化、壓縮以及推理加速、快速部署的支持。接下來,就讓我們通過我們常用的 OpenVINO Notebooks 倉庫中關于 LCMs 模型的 Jupyter Notebook 代碼[4] 和拆解,來進一步了解具體步驟吧。
第一步:
安裝相應工具包、加載模型
并轉換為 OpenVINO IR 格式
%pip install -q "torch" --index-url https://download.pytorch.org/whl/cpu %pip install -q "openvino>=2023.1.0" transformers "diffusers>=0.22.0" pillow gradio "nncf>=2.6.0" datasets
左滑查看更多
模型下載
與傳統的 Stable Diffusion 流水線類似, LCMs 模型內部也包含了 Text Encoder, U-Net, VAE Decoder 三個模型。
Text Encoder 模型
負責從文本 text prompt創建圖片生成的條件
U-Net 模型
負責初步降噪潛在圖像表示
Autoencoder (VAE) Decoder
用于將潛在空間解碼為最終的圖片
因此分別需要對這三個模型進行下載,部分代碼如下:
import gc
import warnings
from pathlib import Path
from diffusers import DiffusionPipeline
warnings.filterwarnings("ignore")
TEXT_ENCODER_OV_PATH = Path("model/text_encoder.xml")
UNET_OV_PATH = Path("model/unet.xml")
VAE_DECODER_OV_PATH = Path("model/vae_decoder.xml")
def load_orginal_pytorch_pipeline_componets(skip_models=False, skip_safety_checker=True):
左滑查看更多
skip_conversion = ( TEXT_ENCODER_OV_PATH.exists() and UNET_OV_PATH.exists() and VAE_DECODER_OV_PATH.exists() ) ( scheduler, tokenizer, feature_extractor, safety_checker, text_encoder, unet, vae, ) = load_orginal_pytorch_pipeline_componets(skip_conversion)
左滑查看更多
模型轉換
包括將以上三個模型的轉換為 OpenVINO IR 格式。
第二步:
準備基于 OpenVINO
的推理流水線
流水線如下圖所示。
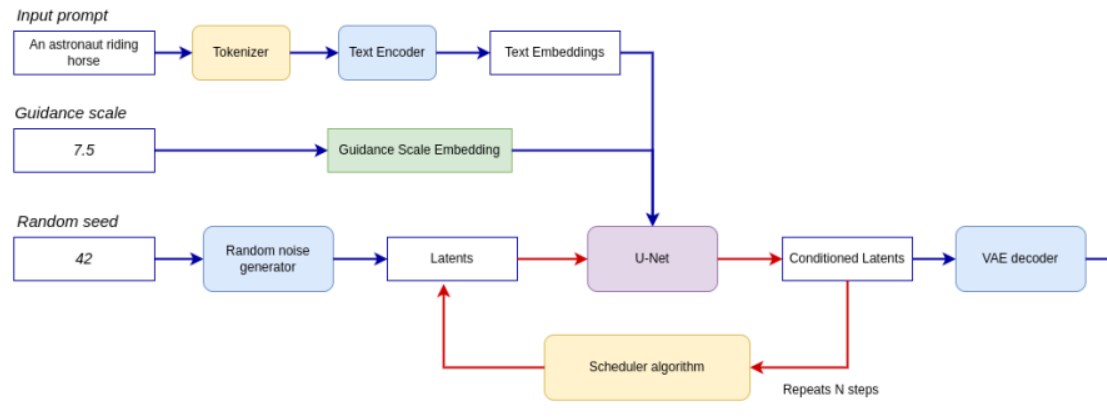
整個流水線利用一個潛在圖像表示和一個文本提示,通過 CLIP 的文本編碼器將文本提示轉化為文本嵌入作為輸入。初始的潛在圖像表示是使用隨機噪聲生成器生成的。與原始的 Stable Diffusion 流程不同,LCMs 還使用引導尺度來獲取時間步驟條件嵌入作為擴散過程的輸入,而在 Stable Diffusion 中,它用于縮放輸出的潛在表示。
接下來,U-Net 迭代地去噪隨機潛在圖像表示,同時以文本嵌入為條件。U-Net 的輸出是噪聲殘差,通過調度算法用于計算去噪后的潛在圖像表示。LCMs 引入了自己的調度算法,擴展了去噪擴散概率模型(DDPMs)中引入的非馬爾可夫引導。去噪過程會重復多次(注意:原始 SD 流程中默認為 50 次,但對于 LCM,只需要 2-8 次左右的小步驟即可!),以逐步獲取更好的潛在圖像表示。完成后,潛在圖像表示將由變 VAE 解碼器解碼為最終的圖像輸出。
定義關于 LCMs 推理流水線的類,部分代碼如下:
from typing import Union, Optional, Any, List, Dict from transformers import CLIPTokenizer, CLIPImageProcessor from diffusers.pipelines.stable_diffusion.safety_checker import ( StableDiffusionSafetyChecker, ) from diffusers.pipelines.stable_diffusion import StableDiffusionPipelineOutput from diffusers.image_processor import VaeImageProcessor class OVLatentConsistencyModelPipeline(DiffusionPipeline):
左滑查看更多
第三步:
配置推理流水線
首先,創建 OpenVINO模型的實例,并使用選定的設備對其進行編譯。從下拉列表中選擇設備,以便使用 OpenVINO運行推理。
core = ov.Core() import ipywidgets as widgets device = widgets.Dropdown( options=core.available_devices + ["AUTO"], value="CPU", description="Device:", disabled=False, ) device
左滑查看更多
text_enc = core.compile_model(TEXT_ENCODER_OV_PATH, device.value)
unet_model = core.compile_model(UNET_OV_PATH, device.value)
ov_config = {"INFERENCE_PRECISION_HINT": "f32"} if device.value != "CPU" else {}
vae_decoder = core.compile_model(VAE_DECODER_OV_PATH, device.value, ov_config)
左滑查看更多
模型分詞器(tokenizer)和調度器(scheduler)也是流水線的重要組成部分。該流水線還可以使用安全檢查器,該過濾器用于檢測相應生成的圖像是否包含“不安全工作”(nsfw)內容。nsfw 內容檢測過程需要使用 CLIP 模型獲得圖像嵌入,因此需要在流水線中添加額外的特征提取器組件。我們重用原始 LCMs 流水線中的標記器、特征提取器、調度器和安全檢查器。
ov_pipe = OVLatentConsistencyModelPipeline( tokenizer=tokenizer, text_encoder=text_enc, unet=unet_model, vae_decoder=vae_decoder, scheduler=scheduler, feature_extractor=feature_extractor, safety_checker=safety_checker, )
左滑查看更多
第四步:
文本到圖片生成
prompt = "a beautiful pink unicorn, 8k" num_inference_steps = 4 torch.manual_seed(1234567) images = ov_pipe( prompt=prompt, num_inference_steps=num_inference_steps, guidance_scale=8.0, lcm_origin_steps=50, output_type="pil", height=512, width=512, ).images
左滑查看更多
在我本地的機器上,我分別使用了我的英特爾 酷睿 第 12 代 CPU、以及英特爾銳炫 顯卡A770m運行了模型推理,生成圖片真的是在眨眼之間!

當然,為了方便各位開發者的使用,我們的notebook代碼[5] 中還為大家設計了基于 Gradio 的、更加用戶優化的界面。
第五步:
利用 NNCF 對模型進行量化壓縮
另外,如果大家對于模型還有進一步的尺寸壓縮以及內存占用壓縮的需求,我們的 notebook 中也同樣提供了基于 NNCF 進行量化壓縮的代碼示例。
量化壓縮的過程分為以下三個步驟:
為量化創建一個校準數據集
運行nncf.quantize()獲得量化模型
利用 openvino.save_model() 保存量化為INT8格式的模型
部分代碼如下:
%%skip not $to_quantize.value
import nncf
from nncf.scopes import IgnoredScope
if UNET_INT8_OV_PATH.exists():
print("Loading quantized model")
quantized_unet = core.read_model(UNET_INT8_OV_PATH)
else:
unet = core.read_model(UNET_OV_PATH)
quantized_unet = nncf.quantize(
model=unet,
subset_size=subset_size,
preset=nncf.QuantizationPreset.MIXED,
calibration_dataset=nncf.Dataset(unet_calibration_data),
model_type=nncf.ModelType.TRANSFORMER,
advanced_parameters=nncf.AdvancedQuantizationParameters(
disable_bias_correction=True
)
)
ov.save_model(quantized_unet, UNET_INT8_OV_PATH)
左滑查看更多
運行效果如下:

根據同樣的文本 text prompt,檢測一下量化后模型的生成效果:
當然推理時間上的表現有何提升呢,我們也歡迎大家利用如下的代碼在自己的機器上實測一下:
%%skip not $to_quantize.value
import time
validation_size = 10
calibration_dataset = datasets.load_dataset("laion/laion2B-en", split="train", streaming=True).take(validation_size)
validation_data = []
while len(validation_data) < validation_size:
? ?batch = next(iter(calibration_dataset))
? ?prompt = batch["TEXT"]
? ?validation_data.append(prompt)
def calculate_inference_time(pipeline, calibration_dataset):
? ?inference_time = []
? ?pipeline.set_progress_bar_config(disable=True)
? ?for prompt in calibration_dataset:
? ? ? ?start = time.perf_counter()
? ? ? ?_ = pipeline(
? ? ? ? ? ?prompt,
? ? ? ? ? ?num_inference_steps=num_inference_steps,
? ? ? ? ? ?guidance_scale=8.0,
? ? ? ? ? ?lcm_origin_steps=50,
? ? ? ? ? ?output_type="pil",
? ? ? ? ? ?height=512,
? ? ? ? ? ?width=512,
? ? ? ?)
? ? ? ?end = time.perf_counter()
? ? ? ?delta = end - start
? ? ? ?inference_time.append(delta)
? ?return np.median(inference_time)
左滑查看更多
小結
整個的步驟就是這樣!現在就開始跟著我們提供的代碼和步驟,動手試試用OpenVINO 和 LCMs 吧!
關于OpenVINO 開源工具套件的詳細資料[6],包括其中我們提供的三百多個經驗證并優化的預訓練模型的詳細資料。
除此之外,為了方便大家了解并快速掌握OpenVINO 的使用,我們還提供了一系列開源Jupyter notebook demo,運行這些notebook,就能快速了解在不同場景下如何利用OpenVINO實現一系列、包括計算機視覺、語音及自然語言處理任務。
審核編輯:湯梓紅
-
英特爾
+關注
關注
61文章
10167瀏覽量
173926 -
AI
+關注
關注
87文章
34196瀏覽量
275345 -
函數
+關注
關注
3文章
4369瀏覽量
64187 -
模型
+關注
關注
1文章
3486瀏覽量
49988
原文標題:一步到位:OpenVINO? 賦能潛在一致性模型(LCMs)的高速圖像生成|開發者實戰
文章出處:【微信號:英特爾物聯網,微信公眾號:英特爾物聯網】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
CAN一致性測試內容及解決方案
介紹ARM存儲一致性模型的相關知識
LTE基站一致性測試的類別
順序一致性和TSO一致性分別是什么?SC和TSO到底哪個好?
一致性規劃研究
CMP中Cache一致性協議的驗證
加速器一致性接口
Cache一致性協議優化研究
系統性質的一致性檢驗框架
優化模型的乘性偏好關系一致性改進

基于業務目標和業務場景的語義一致性驗證方法

DDR一致性測試的操作步驟
深入理解數據備份的關鍵原則:應用一致性與崩潰一致性的區別






 工商網監
工商網監
評論