") 提高TinyML、ML-DSP和深度學(xué)習(xí)工作負(fù)載的能效
提高TinyML、ML-DSP和深度學(xué)習(xí)工作負(fù)載的能效
近來(lái),對(duì)實(shí)時(shí)決策、降低數(shù)據(jù)吞吐量以及注重隱私的需求,已將人工智能處理的很大一部分工作轉(zhuǎn)移到邊緣。這一轉(zhuǎn)變催生了大量邊緣人工智能應(yīng)用,每種應(yīng)用都有著不同的要求,面臨著不同的挑戰(zhàn)。
據(jù)預(yù)測(cè),2025年人工智能SoC市場(chǎng)規(guī)模將達(dá)到500億美元(資料來(lái)源:Pitchbook Emerging Tech Research),邊緣人工智能芯片預(yù)計(jì)將在這一市場(chǎng)中占據(jù)重要地位。
人工智能處理向邊緣轉(zhuǎn)移及提高能效勢(shì)在必行
人工智能處理向邊緣轉(zhuǎn)移標(biāo)志著一系列應(yīng)用(從物聯(lián)網(wǎng)傳感器到自主系統(tǒng))進(jìn)入了實(shí)時(shí)決策的新時(shí)代。這一轉(zhuǎn)移有助于:減少延遲,這對(duì)即時(shí)響應(yīng)起到?jīng)Q定性作用;通過(guò)本地處理提高數(shù)據(jù)隱私保證;支持離線功能,確保在遠(yuǎn)程或具有挑戰(zhàn)性的環(huán)境中不間斷運(yùn)行。由于這些邊緣應(yīng)用在電池供電的設(shè)備上運(yùn)行,能效有限,因此能效在這一變革中會(huì)成為焦點(diǎn)。
邊緣人工智能工作負(fù)載本質(zhì)多元
確保邊緣人工智能處理能效的關(guān)鍵難題之一是工作負(fù)載本質(zhì)多元。不同應(yīng)用的工作負(fù)載大不相同,帶來(lái)獨(dú)特挑戰(zhàn)。總體而言,所有人工智能處理工作負(fù)載可大致分為TinyML、ML-DSP及深度學(xué)習(xí)工作負(fù)載。
TinyML:聲音分類(lèi)、關(guān)鍵詞識(shí)別及人體存在檢測(cè)等任務(wù)需要在傳感器附近進(jìn)行低延遲、實(shí)時(shí)處理。此處涉及的工作負(fù)載稱(chēng)為T(mén)inyML,牽涉到在資源有限的邊緣設(shè)備上運(yùn)行輕量級(jí)機(jī)器學(xué)習(xí)模型。TinyML模型專(zhuān)為特定硬件定制,支持順利執(zhí)行人工智能任務(wù)。定制硬件處理器和高度優(yōu)化的軟件庫(kù)對(duì)于滿(mǎn)足TinyML嚴(yán)格至極的功耗要求至關(guān)重要。
深度學(xué)習(xí):相較而言,深度學(xué)習(xí)應(yīng)用程序是一種計(jì)算密集型工作負(fù)載。此類(lèi)應(yīng)用程序涉及運(yùn)行復(fù)雜的計(jì)算,通常出現(xiàn)在高級(jí)計(jì)算機(jī)視覺(jué)、自然語(yǔ)言處理及其他經(jīng)典和生成式人工智能密集型任務(wù)中。深度學(xué)習(xí)具有計(jì)算密集型特性,通常需要專(zhuān)門(mén)的硬件,如神經(jīng)處理單元 (NPU)。NPU采用多層神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu),能夠高效地處理各種復(fù)雜的計(jì)算任務(wù)。NPU可為高級(jí)人工智能任務(wù)提供所需的計(jì)算能力,而且能效很高。
ML-DSP:介于上述兩類(lèi)工作負(fù)載之間的是ML-DSP工作負(fù)載,涉及DSP處理、過(guò)濾及清理信號(hào),然后才能執(zhí)行人工智能感知任務(wù)。雷達(dá)屬于此類(lèi)工作負(fù)載,是一種涉及點(diǎn)云圖像分析的常見(jiàn)應(yīng)用。
工作負(fù)載決定采用的架構(gòu)
為了應(yīng)對(duì)邊緣人工智能工作負(fù)載的多面性及其帶來(lái)的能效挑戰(zhàn),人們開(kāi)發(fā)了各種架構(gòu)和硬件引擎。為各工作負(fù)載選擇有針對(duì)性的架構(gòu)和硬件是為了在提供最佳計(jì)算性能的同時(shí)最大限度地降低功耗。就此而言,TOPS/Watt(每秒萬(wàn)億次運(yùn)算/瓦)是常用的能效指標(biāo)。選擇合適的架構(gòu)來(lái)處理TinyML、ML-DSP及深度學(xué)習(xí)工作負(fù)載,是滿(mǎn)足所需能效指標(biāo)的關(guān)鍵。
標(biāo)量處理架構(gòu)最適合TinyML工作負(fù)載,此類(lèi)負(fù)載通常涉及用戶(hù)界面管理、基于時(shí)間數(shù)據(jù)制定決策以及非密集型計(jì)算需求。矢量處理架構(gòu)非常適合同時(shí)處理多個(gè)數(shù)據(jù)元素的運(yùn)算,及在人工智能感知之前涉及信號(hào)處理的工作負(fù)載。張量和矩陣處理架構(gòu)是涉及復(fù)雜矩陣運(yùn)算、圖像識(shí)別、計(jì)算機(jī)視覺(jué)及自然語(yǔ)言處理等深度學(xué)習(xí)任務(wù)的理想選擇。能夠以盡量高的能效高效處理涉及大型矩陣和神經(jīng)網(wǎng)絡(luò)的任務(wù)。人工智能處理器通常結(jié)合利用這些架構(gòu)來(lái)高效處理各種任務(wù)。請(qǐng)參閱下圖。
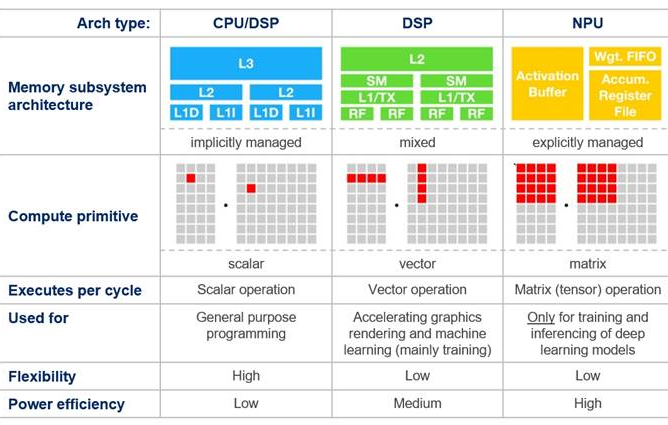
CEVA產(chǎn)品可應(yīng)對(duì)各種人工智能工作負(fù)載
CEVA提供一系列產(chǎn)品,希望滿(mǎn)足TinyML、ML-DSP 及深度學(xué)習(xí)工作負(fù)載的需求。我們的產(chǎn)品包括CEVA-BX、SensPro2及NeuPro-M,品質(zhì)優(yōu)越,既能支持搭載人工智能功能的邊緣設(shè)備,也能確保能效。
CEVA-BX處理器高度靈活,能夠根據(jù)具體應(yīng)用配置和優(yōu)化,包括音頻、語(yǔ)音處理及人工智能相關(guān)的工作負(fù)載。其架構(gòu)旨在實(shí)現(xiàn)性能和能效平衡,因此適用于廣泛的邊緣計(jì)算應(yīng)用。
CEVA的SensPro2是一種高度可配置且獨(dú)立的矢量DSP架構(gòu),針對(duì)浮點(diǎn)和整數(shù)數(shù)據(jù)類(lèi)型進(jìn)行標(biāo)量和矢量處理。專(zhuān)為計(jì)算機(jī)視覺(jué)和其他傳感器中的并行高帶寬數(shù)據(jù)應(yīng)用而設(shè)計(jì)。能夠高效處理多達(dá)5 TOPS的人工智能工作負(fù)載,集成多達(dá)1,000個(gè)MAC。SensPro2是需要高帶寬數(shù)據(jù)和人工智能處理能力的視覺(jué)和雷達(dá)系統(tǒng)的合適選擇。
CEVA的NeuPro-M是一款神經(jīng)處理單元(NPU)IP,涵蓋在CEVA深度學(xué)習(xí)人工智能處理器NeuPro系列中。NeuPro-M旨在處理當(dāng)今大多數(shù)經(jīng)典和生成式人工智能網(wǎng)絡(luò)模型,包括Transformer。專(zhuān)門(mén)針對(duì)低功耗、高效率處理優(yōu)化,包括一個(gè)矢量處理單元(VPU)和許多其他異構(gòu)處理引擎,如稀疏性、壓縮和激活邏輯。隨著人工智能網(wǎng)絡(luò)模型快速發(fā)展,NeuPro-M憑借內(nèi)置VPU,可以為邊緣人工智能應(yīng)用提供經(jīng)得起未來(lái)考驗(yàn)的功能。NeuPro-M目前無(wú)法處理的更新、更復(fù)雜的人工智能網(wǎng)絡(luò)層,可以利用VPU得到高效管理。
CEVA的音頻人工智能處理器、傳感器中樞 DSP、NeuPro-M NPU IP以及相關(guān)軟件工具和開(kāi)發(fā)套件可滿(mǎn)足所有邊緣人工智能處理工作負(fù)載的需求。
本文作者:Moshe Sheier, Vice President of Marketing, CEVA
關(guān)于CEVA
CEVA是排名前列的無(wú)線連接和智能傳感技術(shù)以及集成IP解決方案授權(quán)商,旨在打造更智能、更安全、互聯(lián)的世界。我們?yōu)閭鞲衅魅诤稀D像增強(qiáng)、計(jì)算機(jī)視覺(jué)、語(yǔ)音輸入和人工智能應(yīng)用提供數(shù)字信號(hào)處理器、人工智能處理器、無(wú)線平臺(tái)、加密內(nèi)核和配套軟件。許多世界排名前列的半導(dǎo)體廠商、系統(tǒng)公司和OEM利用我們的技術(shù)和芯片設(shè)計(jì)技能,為移動(dòng)、消費(fèi)、汽車(chē)、機(jī)器人、工業(yè)、航天國(guó)防和物聯(lián)網(wǎng)等各種終端市場(chǎng)開(kāi)發(fā)高能效、智能、安全的互聯(lián)設(shè)備。
我們基于DSP的解決方案包括移動(dòng)、物聯(lián)網(wǎng)和基礎(chǔ)設(shè)施中的5G基帶處理平臺(tái);攝像頭設(shè)備的高級(jí)影像技術(shù)和計(jì)算機(jī)視覺(jué);適用于多個(gè)物聯(lián)網(wǎng)市場(chǎng)的音頻/語(yǔ)音/話(huà)音應(yīng)用和超低功耗的始終開(kāi)啟/感應(yīng)應(yīng)用。對(duì)于傳感器融合,我們的Hillcrest Labs傳感器處理技術(shù)為耳機(jī)、可穿戴設(shè)備、AR/VR、PC機(jī)、機(jī)器人、遙控器、物聯(lián)網(wǎng)等市場(chǎng)提供廣泛的傳感器融合軟件和慣性測(cè)量單元 (“IMU”) 解決方案。在無(wú)線物聯(lián)網(wǎng)方面,我們的藍(lán)牙(低功耗和雙模)、Wi-Fi 4/5/6/6E (802.11n/ac/ax)、超寬帶(UWB)、NB-IoT和GNSS 平臺(tái)是業(yè)內(nèi)授權(quán)較為廣泛的連接平臺(tái)。
-
dsp
+關(guān)注
關(guān)注
555文章
8142瀏覽量
355205 -
CEVA
+關(guān)注
關(guān)注
1文章
189瀏覽量
76429 -
ML
+關(guān)注
關(guān)注
0文章
150瀏覽量
34972 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5554瀏覽量
122478 -
TinyML
+關(guān)注
關(guān)注
0文章
43瀏覽量
1475
原文標(biāo)題:提高TinyML、ML-DSP和深度學(xué)習(xí)工作負(fù)載的能效
文章出處:【微信號(hào):CEVA-IP,微信公眾號(hào):CEVA】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
利用TinyML在MCU上實(shí)現(xiàn)AI/ML推論工作
開(kāi)發(fā)TinyML系統(tǒng)必須考慮的四大指標(biāo)
Alif Semiconductor宣布推出先進(jìn)的BLE和Matter無(wú)線微控制器,搭載適用于AI/ML工作負(fù)載的神經(jīng)網(wǎng)絡(luò)協(xié)同處理器

【先楫HPM5361EVK開(kāi)發(fā)板試用體驗(yàn)】:4、TinyML測(cè)試(1)
交流充電樁負(fù)載能效提升技術(shù)
深度學(xué)習(xí)及無(wú)線通信熱點(diǎn)問(wèn)題介紹
什么是TinyML?微型機(jī)器學(xué)習(xí)
Arm Neoverse V1的AWS Graviton3在深度學(xué)習(xí)推理工作負(fù)載方面的作用
優(yōu)化用于深度學(xué)習(xí)工作負(fù)載的張量程序

微軟要讓ML.NET框架也能用于開(kāi)發(fā)深度學(xué)習(xí)應(yīng)用
TinyML推動(dòng)深度學(xué)習(xí)和人工智能發(fā)展
一文知道TinyML的演變
機(jī)器學(xué)習(xí)概述、工作原理及重要性
如何在 MCU 上快速部署 TinyML
什么是TinyML?





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論