 NeurIPS 2023 | 大模型時代自監督預訓練的隱性長尾偏見
NeurIPS 2023 | 大模型時代自監督預訓練的隱性長尾偏見
離開學校加入公司的業務部門已經半年多了,往后應該會努力抽時間做點開源項目,但暫時沒什么計劃再發一作論文了。這次介紹下我和我(前)實驗室一位非常優秀的學弟 beier 合作的一篇 NeurIPS 2023 論文《Generalized Logit Adjustment: Calibrating Fine-tuned Models by Removing Label Bias in Foundation Models》,算是我入職前在學術界最后的回響吧。
這次學弟的文章主要嘗試解決我做長尾問題期間的一個始終縈繞在我腦袋里的疑慮,我覺得長尾領域最大的坎在于明明在研究一個普世的問題,但是學術界把問題模型簡化后做出來的算法卻只能在精心設計的實驗數據集上生效。 這次和學弟合作的這篇工作得益于模型自監督預訓練帶來的優秀 OOD 效果和我們提出的 GLA 算法對預訓練模型在下游任務上偏見的矯正,我們第一次基于長尾問題本身的特性設計出了一個通用的提點算法,不僅能在狹義的傳統 LT 數據集上生效,也能用于其他非 LT 設定的任務,比如我們的算法可以提升模型在原始的 ImageNet 測試集的效果,還有一些few-shot等其他任務。

論文鏈接:
https://arxiv.org/pdf/2310.08106.pdf
代碼鏈接:https://github.com/BeierZhu/GLA

大模型時代的長尾分布研究該何去何從
在當下這個大模型群星閃耀的時代,想必過去兩三年中關注長尾任務的同學都面臨著何去何從的困惑。長尾問題固然普世,除了狹義的類間長尾還有廣義長尾問題 [1],但過去幾年學術界中研究的主流長尾算法卻并不同樣普世。 以最常見的圖像長尾分類任務為例,要想大多數長尾分類算法能夠生效,首先訓練過程中的長尾分布就必須是顯性的,要通過統計具體的類別分布來實現去偏。而大模型成功的根基,卻恰恰也給傳統長尾算法關上了大門,因為大模型所依賴的自監督預訓練無法為下游任務提供一個顯性的長尾分布去矯正。 以大語言模型(如 GPT 等)和多模態模型(如 CLIP 等)為例,即便近來有一些論文嘗試去研究大模型在下游任務微調時的下游數據偏見問題,但卻并沒有工作能夠解決大模型預訓練階段本身的數據不均衡問題。但我們都知道在海量的預訓練數據之下,數據的長尾分布是必然的。之所以鮮有人嘗試去研究自監督預訓練階段本身的數據偏見,是因為要想在大模型的自監督預訓練中研究長尾問題存在三大挑戰: 其一,原始文本數據的歧義性導致無法精準的統計類別的分布。比如以 CLIP 為例,其預訓練目標是將圖片與文本配對,而下游的視覺端 backbone 可以用作圖像分類任務,但此時如果下游是一個 {human, non-human} 的二分類,我們并不能直接用 human 關鍵詞的出現與否作為預訓練數據分布的統計標準,比如包含 a worker 的圖片雖然沒有 human 這個詞但也應該被統計為 human,因此文本天然的歧義和多意會給長尾分布研究帶來極大的困難和偏差。 其二,預訓練任務與下游任務的弱耦合導致無法明確數據分布的統計方式。大模型的強大之處在于可以通過一個簡單有效的預訓練支撐花樣百出的下游任務,然而這卻大大增加了研究預訓練數據偏見對下游任務影響的難度。比如 GPT 等大語言模型的預訓練是預測下一個或是缺失的 Token,雖然我們可以統計 Token 的詞頻,但如果我們的下游任務是對文本的語氣進行三分類 {positive, neutral, negative}。 此時單純統計 positive,neutral 和 negative 這三個詞在預訓練中的詞頻顯然并不完全合適,因為這幾個詞出現的場景并非都是語氣分類,要想精準統計不僅困難,其具體的下游任務更是無法在預訓練階段知曉的(下游任務太多了,模型提供者并不能知道模型被其他人拿到后會如何使用)。 最后,也是最重要的,預訓練數據的保密性也是不得不考慮的問題,出于用戶隱私和商業機密的考量,一個開源公司即便開放了大模型參數往往也不會開放預訓練數據,這使得研究預訓練數據的分布變得幾乎不可能。這也是目前鮮有該方面研究的主要原因之一。而在我們最新的工作中,我們不僅實現了在下游任務直接估計預訓練的偏見,更是完全規避了對預訓練數據本身的訪問,使得我們可以在只有模型權重沒有預訓練數據的情況下實現對自監督預訓練模型的去偏。

自監督預訓練引入的數據偏見
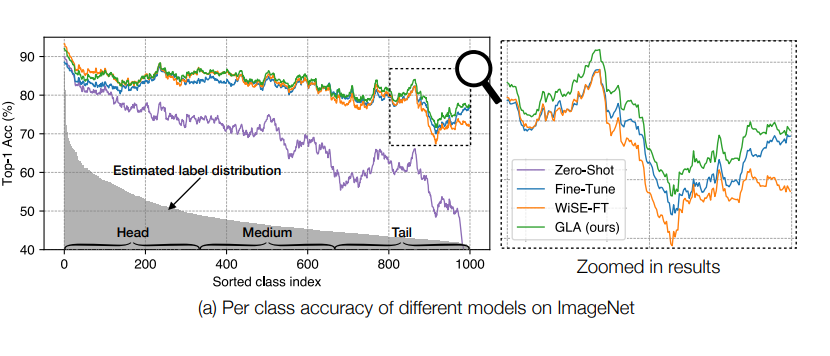
▲ 圖一:自監督預訓練階段引入的長尾數據偏見(可從 zero-shot 分類效果看出其對模型效果的影響)
目前大多數預訓練模型魯棒性相關的研究中,他們往往會把自監督預訓練模型本身當作是一個無偏的基準,而強調模型在下游任務上微調時會引入下游任務的偏見,因此需要對下游任務去偏的同時盡可能保留預訓練模型的魯棒性,其中代表作有利用 zero-shot 模型和微調模型 Ensemble 的 WiSE-FT [2] 和利用梯度約束的 ProGrad [3]。但正如我上文說的,預訓練數據的偏見同樣無法忽視,這導致上述模型從理論上便不可能是最優的。 事實上早在兩年前,長尾問題領域便有人嘗試利用自監督學習來提取特征,并認為無需顯性標注的自監督 loss 可以大大緩解模型的長尾偏見問題。于是在我們的工作開始前,我們首先便要推倒這個假設。自監督預訓練并不是一味萬能藥。如圖一所示,我們將 CLIP-ViT/B16 預訓練模型在下游的 ImageNet 測試集上的分類效果按我們估計的類別分布(可視化中進行了平滑處理)進行排序,我們發現自監督預訓練模型同樣有著明顯的長尾偏見(zero-shot 結果),尾部類別的準確率會有明顯的下滑。 尤其是當我們將 zero-shot 結果和微調結果(fine-tune)對比時,我們就會看到他們的頭部類別效果相當,而尾部類別 zero-shot 模型明顯更差,也就是說自監督預訓練模型的長尾問題其實很嚴重,模型在下游任務上微調時其實類似于在一個更均衡的數據集上微調去提升尾部效果。 至于為什么之前的論文認為預訓練模型魯棒性更高,這就需要了解我之前一篇工作中提及的類間長尾和類內長尾兩個概念的區別了,我認為預訓練的魯棒性更多的體現在類內分布的魯棒性上,本文在這暫不展開,有興趣的同學可以看我另一篇文章(ECCV 2022 | 計算機視覺中的長尾分布問題還值得做嗎?)。 此時單純 zero-shot 和 fine-tune 的 Ensemble 模型 WiSE-FT 更像一個 Trade-off,用尾部的損失去提升頭部性能。而我們提出的 Generalized Logit Adjustment(GLA)通過在 Ensemble 之前先消除預訓練 zero-shot 模型的長尾偏見來有效的實現了頭尾全分布的同時提升。 而我們之所以叫 Generalized Logit Adjustment 是為了致敬在經典的狹義長尾分布任務上的一個非常優雅且有效的算法 Logit Adjustment [4]。之所以無法簡單的套用到自監督預訓練上,其實最重要的一個難點就是我上面說到的預訓練分布估計了。而僅利用模型參數不獲取預訓練數據就能在下游任務上估計預訓練階段數據偏見的算法也是我們文章的主要貢獻之一。

預訓練數據中下游任務的類別分布估計
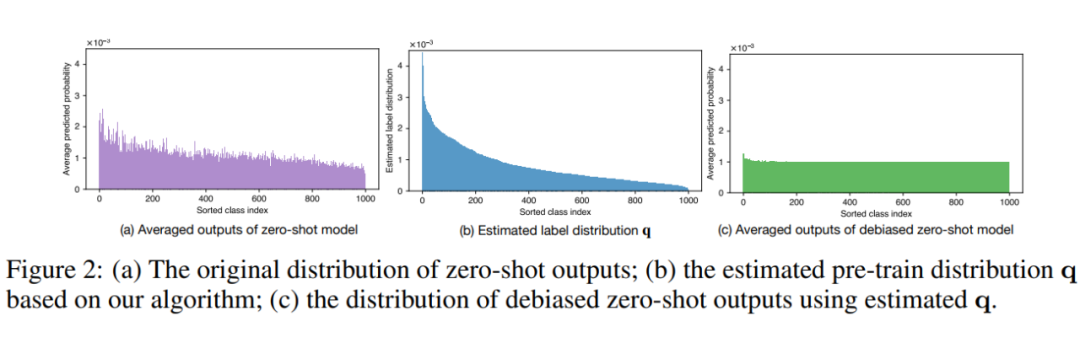
在本文中,我們主要以 CLIP 為引子,討論以圖文對比學習作為自監督預訓練的多模態模型(主要是視覺端),不過本文提出的算法也可以推廣至以文本自監督預訓練為基礎的大語言模型在下游文本分類任務上的偏見估計問題。 在給出本文提供的預訓練階段數據偏見估計算法之前,我們需要回顧一篇我非常推崇的 Google 的 Logit Adjustment 長尾算法。在不考慮類內不均衡 OOD 樣本的情況下,Logit Adjustment 研究已經從理論上提供了非常優雅的最優解:傳統分類問題的概率模型 可以通過貝葉斯分解為如下形式 。那么在訓練集與測試集獨立同分布(IID)的情況下,我們自然而然可以得到如下的假設:,也就是說對于分類模型 ,唯一的類別 bias 來自 中的第二項 。那么問題就簡單了,我們可以直接通過 來將類別分布從訓練分布更改為測試分布。如果以類別均衡的驗證集上的結果作為模型在無偏見下的表現的衡量標準, 就是平均分布,那么我們就可以去掉最后一項 。基于上文的 Logit Adjustment 長尾算法,我們不難發現,只要能給出自監督預訓練模型的分布 ,我們就可以得到模型在類別均衡驗證集上的理論最優解(給定模型 backbone 下)。那么換而言之,我們也可以利用這一特性來反向計算 ,如圖二所示,只要能提供一個額外的類別均衡的子集,我們就可以通過最小化 Risk 去學習一個對模型輸出的 logits 的偏置項,即通過最小化均衡子集上的誤差去估計 。詳細的理論推導和最優保證請參考我們的原文和原文的補充材料。

▲ 圖二:以 Logit Adjustment 推導結果的理論最優解為前提,反向通過一個均衡子集去估計偏置項。
基于上述預訓練偏見估計的算法,我們不僅不需要獲取預訓練數據,更不需要預訓練過程是嚴格的傳統分類 loss,任意分類模型都可以僅僅通過權重本身在一個均衡子集上估算出其訓練階段積累的偏見。為了更好的體現我們的去偏效果,我們也可視化了我們的去偏算法在 CLIP zero-shot 模型的去偏效果,詳見圖三。
 通用Logit矯正算法(GLA)應用于任意下游數據分布上述偏見估計算法雖然提供了解決模型在 zero-shot 設定下的預訓練偏見矯正問題,但是其取得的最優僅限于類別均衡的下游數據。但目前最優的模型還是利用 zero-shot 模型和微調模型 Ensemble 的 WiSE-FT [2],因為他們除了解決類間的不均衡,還通過微調更好的適配了下游數據分布 和 。
那么微調模型的偏見又該如何解決呢?如果下游任務提供的微調數據本身還帶有不均衡分布 ,且往往 ,我們還需要額外對微調模型 去偏,這里我們略過具體的推導和理論分析,先給出結論:我們認為如果微調模型在下游數據上收斂后,其所帶的偏見就是下游數據 的偏見,可以用原始 Logit Adjustment 解決。綜上,我們提出的 Generalized Logit Adjustment 框架就可以總結為如下公式:
通用Logit矯正算法(GLA)應用于任意下游數據分布上述偏見估計算法雖然提供了解決模型在 zero-shot 設定下的預訓練偏見矯正問題,但是其取得的最優僅限于類別均衡的下游數據。但目前最優的模型還是利用 zero-shot 模型和微調模型 Ensemble 的 WiSE-FT [2],因為他們除了解決類間的不均衡,還通過微調更好的適配了下游數據分布 和 。
那么微調模型的偏見又該如何解決呢?如果下游任務提供的微調數據本身還帶有不均衡分布 ,且往往 ,我們還需要額外對微調模型 去偏,這里我們略過具體的推導和理論分析,先給出結論:我們認為如果微調模型在下游數據上收斂后,其所帶的偏見就是下游數據 的偏見,可以用原始 Logit Adjustment 解決。綜上,我們提出的 Generalized Logit Adjustment 框架就可以總結為如下公式:
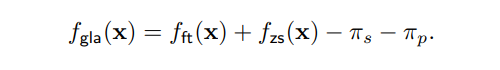
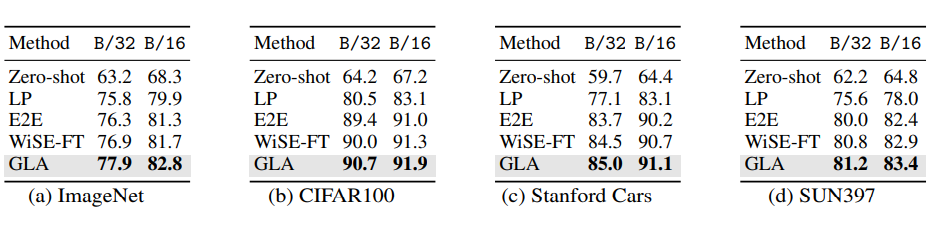
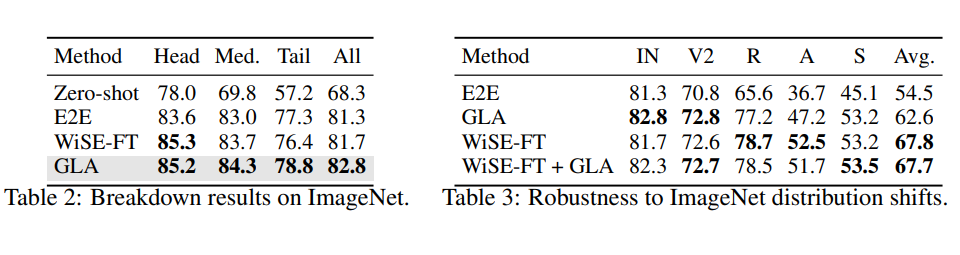
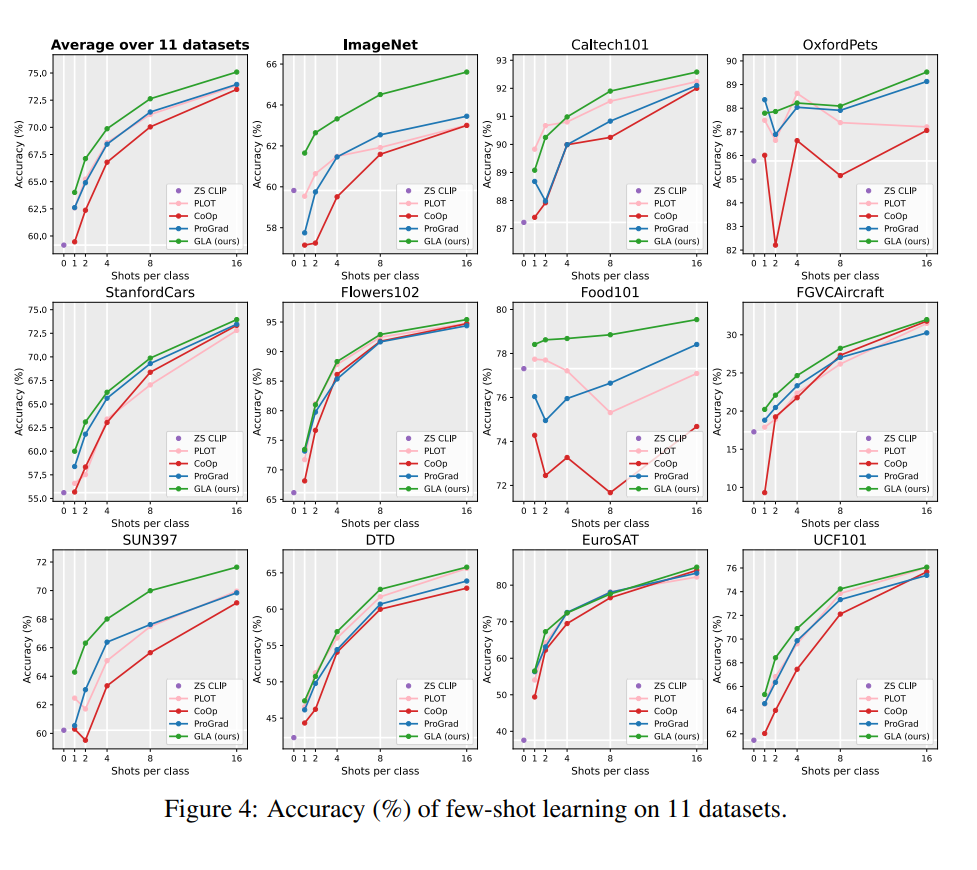
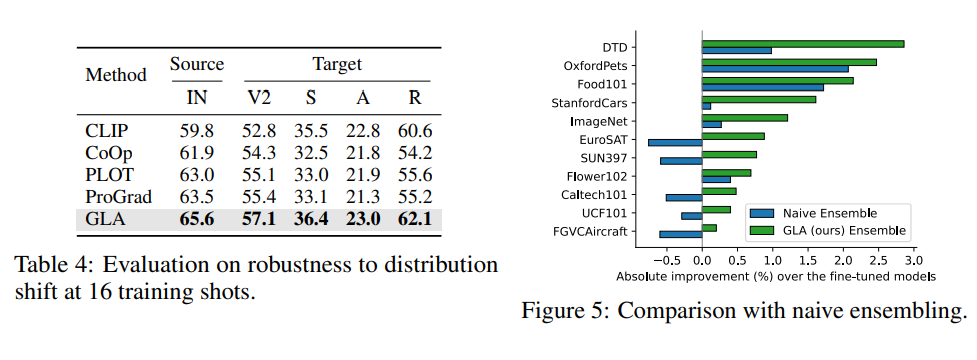
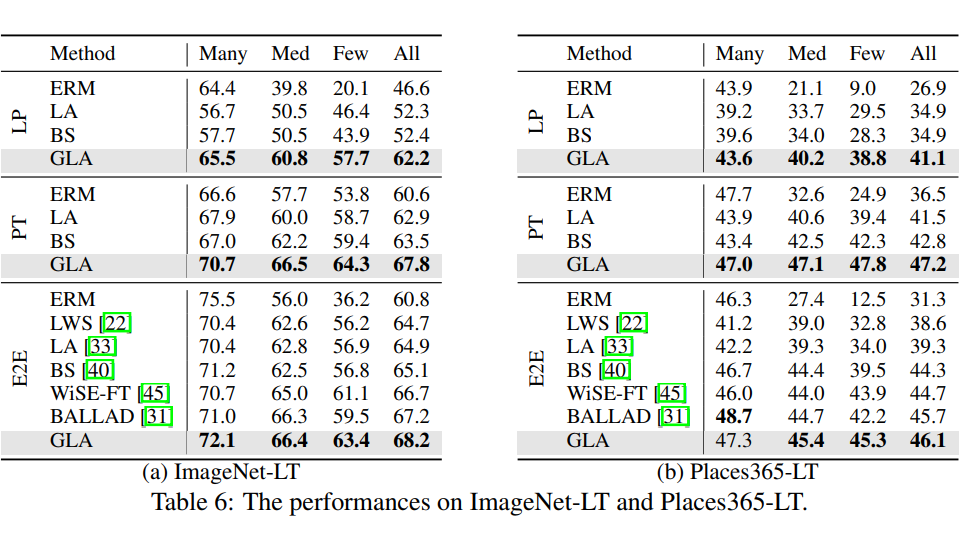
 GLA算法的最終效果值得注意的是,GLA 算法據我所知是首個能“真正體現”長尾問題廣泛性的算法,該算法以長尾問題為切入點,但最后得到的模型不僅在長尾分類任務上有提升,更在經典分類任務與數據上,在 few-shot 任務上等都有提升。是第一個做到利用長尾算法提升傳統分類任務的工作。
經典分類場景(非 Long-Tailed,Few-shot 等細分場景):在傳統分類設定上,我們利用 CLIP ViT-B/32 和 ViT-B/16 兩個模型,在 ImageNet,CIFAR100,Stanford Cars 和 SUN397 上都取得了顯著的提升:
GLA算法的最終效果值得注意的是,GLA 算法據我所知是首個能“真正體現”長尾問題廣泛性的算法,該算法以長尾問題為切入點,但最后得到的模型不僅在長尾分類任務上有提升,更在經典分類任務與數據上,在 few-shot 任務上等都有提升。是第一個做到利用長尾算法提升傳統分類任務的工作。
經典分類場景(非 Long-Tailed,Few-shot 等細分場景):在傳統分類設定上,我們利用 CLIP ViT-B/32 和 ViT-B/16 兩個模型,在 ImageNet,CIFAR100,Stanford Cars 和 SUN397 上都取得了顯著的提升:
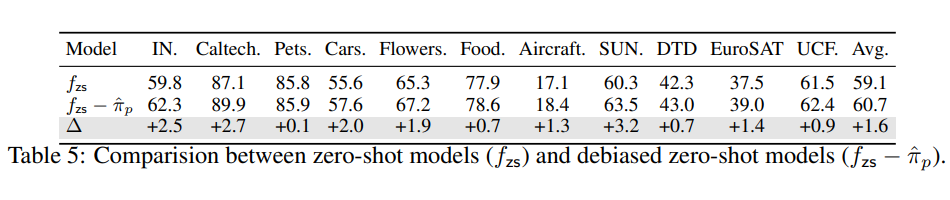 GLA 在傳統 Long-Tail 設定數據集上提升:
GLA 在傳統 Long-Tail 設定數據集上提升:
 總結
總結研究長尾問題對各個任務的具體影響可以說是貫穿我的博士生涯,從我研究開始該領域內便有個共識就是長尾問題是普世的,是任何實際問題都繞不開的坎。但奈何長尾問題卻又無比復雜,不僅有類間長尾還有類內屬性長尾,因此學術界不得不對任務做了很多簡化,但這也導致了長尾問題明明是個普世的問題,該領域的算法卻只能在精心設計的實驗室環境下生效。
而如今大模型時代借助于預訓練模型本身對于 OOD 的魯棒性,以及我們提出的預訓練偏見估計算法對于分布的矯正,我們終于拼上了最后一塊拼圖,第一次提出一個基于分布矯正和 Ensemble 的真正通用的長尾算法,可以在實際問題實際應用中提升各種任務的表現,而不僅限于精心設計的長尾數據集。
我們也希望這個研究可以為大模型時代的研究者打開一扇研究預訓練分布偏見的大門,而不用因為無法訪問預訓練數據在大模型偏見研究的門口束手無策。希望這篇文章沒有浪費大家的時間,能給大家以啟發。
@inproceedings{zhu2023generalized,
title={GeneralizedLogitAdjustment:CalibratingFine-tunedModelsbyRemovingLabelBiasinFoundationModels},
author={Zhu,BeierandTang,KaihuaandSun,QianruandandZhang,Hanwang},
journal={NeurIPS},
year={2023}
}

參考文獻
?[1] https://arxiv.org/abs/2207.09504[2] https://arxiv.org/abs/2109.01903[3] https://arxiv.org/abs/2205.14865[4] https://arxiv.org/abs/2007.07314·
-
物聯網
+關注
關注
2927文章
45875瀏覽量
387963
原文標題:NeurIPS 2023 | 大模型時代自監督預訓練的隱性長尾偏見
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯網技術研究所】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
大模型時代的深度學習框架

用PaddleNLP為GPT-2模型制作FineWeb二進制預訓練數據集

從Open Model Zoo下載的FastSeg大型公共預訓練模型,無法導入名稱是怎么回事?
用PaddleNLP在4060單卡上實踐大模型預訓練技術

基于移動自回歸的時序擴散預測模型
知行科技大模型研發體系初見效果
KerasHub統一、全面的預訓練模型庫

時空引導下的時間序列自監督學習框架

直播預約 |數據智能系列講座第4期:預訓練的基礎模型下的持續學習






 工商網監
工商網監
評論