 高性能計算與多模態處理的探索之旅:英偉達GH200性能優化與GPT-4V的算力加速未來
高性能計算與多模態處理的探索之旅:英偉達GH200性能優化與GPT-4V的算力加速未來

★多模態大模型;GPU算力;LLMS;LLM;LMM;GPT-4V;GH200;圖像識別;目標定位;圖像描述;視覺問答;視覺對話;英偉達;Nvidia;H100;L40s;A100;H100;A800;H800,AI算力,AI算法
隨著人工智能技術的不斷發展,多模態大模型成為越來越重要的發展趨勢。多模態大模型通過融合視覺等多種感知能力來擴展語言模型,實現更強大的通用人工智能。GPT-4V(GPT-4 近日開放的視覺模態)大型多模型(LMMs)擴展大型語言模型(LLMs)以增強多感知技能(如視覺理解等)從而實現更強大的通用智能。本文著重對GPT-4V進行深入分析,以進一步深化對LMM的理解。在此本文分析核心是GPT-4V可以執行的任務,同時包含用于探測其能力質量和通用性的測試樣本。
研究結果表明,GPT-4V在處理交錯多模態輸入方面有著前所未有的能力,并且其通用性使其成為一個強大的多模態綜合智能系統。GPT-4V的獨特能力主要表現在理解輸入圖像上繪制的視覺標記,同時還能產生新的人機交互方法如視覺指引提示。本文將探討GPT-4V的初步探索、多模態對算力影響、英偉達最強AI芯片GH200究竟強在哪里,以及藍海大腦大模型訓練平臺等多個方面的內容。
GPT-4V的初步探索
本文采用定性案例設計方法,對GPT-4V進行全面探索。著重以案例方式進行評估,而非傳統的定量評測,旨在激發后續研究建立針對大型多模態模型的評估基準。考慮到不同的交互模式可能會對模型表現產生影響,因此主要采用零樣本提示的方式,以減少對上下文示例的依賴,從而更好地評估GPT-4V獨立處理復雜多模態輸入的能力。
一、GPT-4V的輸入模式
GPT-4V是一個文本輸入的單模型語言系統,同時具備接受圖像-文本對輸入的能力。作為純文本輸入模型,GPT-4V表現出強大的語言處理能力。對于文本輸入,GPT-4V只需要純文本輸入和輸出即可完成各種語言和編碼任務。GPT-4V的另一個應用模式是接受單個圖像-文本對輸入,可以完成各種視覺及視覺語言任務(如圖像識別、目標定位、圖像描述、視覺問答、視覺對話以及生成密集式圖像描述等)。此外,GPT-4V還支持交錯的圖像-文本輸入模式,這種靈活的輸入方式使其具有更廣泛的應用場景,比如計算多張收據圖片的總稅額、從多圖片中提取查詢信息,以及關聯交錯的圖像文本信息等。處理這種交錯輸入也是少樣本學習和其他高級提示技術的基礎,從而進一步增強GPT-4V的適用范圍。


GPT-4V支持使用多圖像和交錯圖像-文本輸入
二、GPT-4V的工作方式和提示技術

GPT-4V可以理解并遵循文本指令,生成所需的文本輸出或學會完成一項新任務。紅色表示信息較少的答案。
GPT-4V的獨特優勢在于其強大自然語言指令理解和遵循能力。指令可以用自然語言形式規定各種視覺語言任務所需的輸出文本格式。此外,GPT-4V能夠通過理解復雜指令來完成具有挑戰性的任務,如包含中間步驟的抽象推理問題。GPT-4V具有適應未知應用和任務的巨大潛力。
1、視覺指向和視覺引用提示
指點是人與人之間互動的基本方面,為提供可比的交互渠道,探索各種形式的“指點”來表示圖片中的空間興趣區域(如數字坐標框、箭頭、框、圈、手繪等)。鑒于圖像上繪制的靈活性,提出一種新的提示方式即“視覺指代提示”,通過編輯輸入圖像的像素來指定目標(如畫視覺指示器或手寫場景文字)。不同于傳統文本提示,視覺指代提示通過圖像像素編輯來完成任務。例如:可以基于畫出的對象生成簡單描述,同時保持對整體場景的理解,或者將指定對象與場景文本索引關聯起來,或者回答貼邊或刁鉆角度的問題等。
2、視覺+文本提示
視覺引用提示可以與其他圖像文本提示結合使用,呈現簡潔細致的界面。GPT-4V展現出強大的提示靈活性,特別是在集成不同輸入格式以及無縫混合指導方面。GPT-4V具有強大的泛化性和靈活性,可以像人類一樣理解多模態指令,并具有適應未知任務的能力。
同時GPT-4V能處理多模態指令(包括圖像、子圖像、文本、場景文本和視覺指針),這使其具有更強的擴展能力和通用性。此外,GPT-4V可將抽象語言指令與視覺示例關聯,作為多模態演示,這比僅文本指令或上下文少樣本學習更符合人類學習方式。

約束提示以JSON格式返回。圖像是樣本的示例id。紅色的突出顯示錯誤的答案。
在大型語言模型(LLM)中,The_Dawn_of_LMMs:Preliminary_Explorations_with_GPT-4V(ision)報告中觀察到一種新的上下文少樣本學習能力,即LLM可以通過添加格式相同的上下文示例生成預期輸出,無需參數更新。類似的能力也在多模態模型中被觀察到,查詢輸入為格式化的圖像-文本對。展示GPT-4V的上下文少樣本學習能力,強調在某些情況下,充分的示例數量至關重要,特別是在零射或一射指令不足時。
例如,在速度計的復雜場景中,GPT-4V在提供2個上下文示例后成功預測正確讀數。在另一個多步推理的線圖案例中,只有在給出額外示例的二射提示下,GPT-4V才能得出正確結論。這些驗證實例展示了上下文少樣本學習對提升LMM性能的重要作用,成為可行的微調替代選擇。

在讀取速度計的挑戰性場景下的零射擊性能。GPT-4V即使采用不同的提示方式,也能夠準確讀取速度表并避免失敗。紅色表示錯誤的答案。
三、視覺語言能力
1、不同域的圖像描述
GPT-4V在處理“圖像-文字對”輸入時的能力和泛化性。要求其生成自然語言描述并涵蓋以下主題:名人識別、地標識別、食物識別、醫學圖像理解、Logo識別、場景理解和逆向示例。
名人識別方面,GPT-4V能夠準確識別不同背景的名人并理解場景與背景信息,例如在2023年G7峰會上識別總統演講。
地標識別方面,GPT-4V可以準確描述地標并生成生動詳細的敘述,捕捉地標本質。
食物識別方面,GPT-4V能夠準確識別各種菜肴并捕捉菜肴的復雜細節。
醫學圖像理解方面,GPT-4V可以識別X光牙齒結構并能根據CT掃描判斷潛在問題。
Logo識別方面,GPT-4V可以準確描述Logo的設計和含義。
場景理解方面,GPT-4V可以描述道路場景中的車輛位置、顏色并讀取路標限速提示。
逆向示例方面,當遇到誤導性問題時,GPT-4V可以正確描述圖像內容,不被誤導。

名人識別和描述結果:GPT-4V可以識別各種名人描述視覺信息(包括他們的職業、行動、背景和事件)細節
2、對象定位、計數和密集字幕
GPT-4V在理解圖像中人與物體的空間關系方面表現出色,能夠分析圖像中的空間信息并正確理解人與物體的相對位置。GPT-4V在物體計數方面的能力,能成功計算出圖像中出現的物體數量,如蘋果、橙子和人。但在物體被遮擋或場景混亂時,計數可能會出錯。
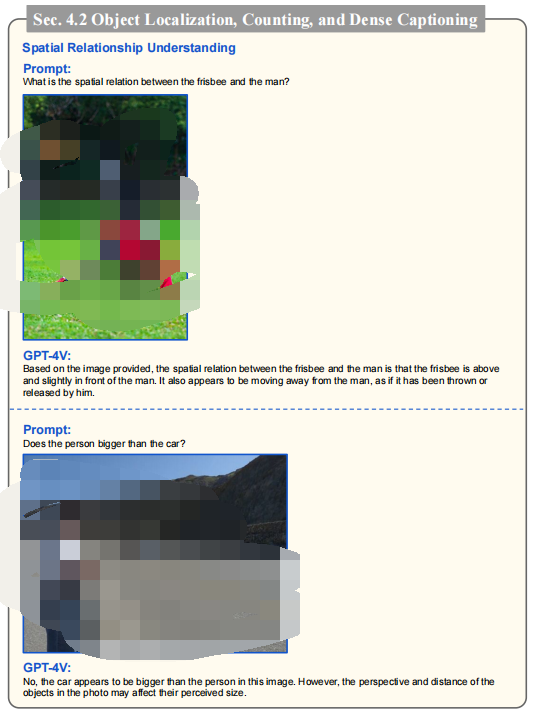
空間關系理解結果:GPT-4V能夠識別圖像中物體之間的空間關系
3、物體定位
物體定位是計算機視覺中的一項難題,而GPT-4V模型在初步實驗中能夠通過簡單的文本提示生成邊界框坐標來定位圖像中的人物,但在復雜場景中可能會遇到挑戰。在場景或背景相對簡單且較少混亂時,定位結果具有潛力,但更復雜的場景(如物體遮擋)中,模型仍需要進一步的提示技術來提升物體定位性能。在目標定位結果方面,GPT-4V能夠近似邊界框坐標的指定對象,但在更復雜的場景中模型仍有局限性。

4、密集字幕生成
密集字幕生成需要對每個圖像區域做出詳細描述,通常需要一個復雜的系統,包含目標檢測器、名人識別模型和圖像字幕生成模型。為了考察本模型在密集字幕生成方面的能力,采用文本提示形式,結果顯示模型成功地定位和識別圖像中的個體,并提供了簡潔的描述。

密集字幕的結果:成功為輸入圖像生成詳細的說明
四、多模態知識和常識
GPT-4V在解釋表情包和理解幽默元素方面表現出色,能從文本和圖像中收集信息并理解幽默效果。在科學知識推理任務中,GPT-4V也能夠正確回答涵蓋廣泛主題的問題。此外,GPT-4V在多模態常識推理方面也表現出強大的能力,能夠利用圖像中的邊界框識別個體執行的動作,并推斷出場景中的細節。在更具體的輸入提示下,還能夠辨別圖像中的微妙線索并提供可能的假設。

笑話和模因理解的結果:GPT-4V展示了令人印象深刻的能力理解表情包中的幽默
五、場景文本、表格、圖表和文檔推理
GPT-4V能準確地識別和解讀圖像中的場景文本,包括手寫和打印文本,并能提取關鍵數學信息解決問題。此外,對圖表、流程圖、x軸、y軸等細節均有理解和推理能力,還能將流程圖的詳細信息轉化為Python代碼。GPT-4V也能理解各種類型文檔(如平面圖、海報和考卷)并提供合理的回答。在更具挑戰性的案例中,GPT-4V展示出令人印象深刻的結果,但偶爾可能會遺漏一些實現細節。

場景文本識別結果:GPT-4V可以識別許多具有挑戰性的場景文本場景
六、多語言多模式理解
GPT-4V通過自然圖像測試成功識別不同語言的輸入文本提示,并生成相應正確語言的圖像描述。在涉及多語言場景文字識別的場景中,GPT-4V能夠正確識別和理解不同場景中的文字,并將其翻譯成不同語言。此外,在多元文化理解能力測試中,GPT-4V能夠理解文化細微差別并生成合理的多語言描述。

多語言圖像描述的結果:GPT-4V能夠根據圖像生成不同語言的描述
七、與人類的互動視覺參考提示
在人機交互中,指向特定空間位置的能力至關重要,特別是在多模態系統中的視覺對話。GPT-4V能夠很好地理解在圖像上直接繪制的視覺指示。因此提出了一種名為“視覺引用提示”的新型模型交互方法。其核心思想是將視覺指示或場景文本編輯繪制在圖像像素空間中,作為人類參考指令。
最后,科學家們探索了使GPT-4V生成視覺指針輸出來與人類進行交互的方法。這些視覺指針對于人類和機器都是直觀的,成為人機交互的良好渠道。GPT-4V可以識別不同類型的視覺標記作為指針,并生成具有基礎描述的字幕。與傳統的視覺語言模型相比,能夠處理更具挑戰性的問題,即生成專注于特定感興趣區域的視覺描述。此外,GPT-4V可以理解坐標,并在沒有額外的框令牌微調的情況下實現空間引用。盡管存在一些空間不精確問題,但與文本坐標相比,GPT-4V在帶有疊加視覺指示的提示下能夠更可靠地工作。

GPT-4V理解圖像上的視覺指針
受GPT-4V在理解和處理視覺指向上能力的啟發,提出一種新的與GPT-4V交互的方式,即視覺參照提示。這種方式利用了在輸入圖像的像素空間進行直接編輯的技巧,從而為人機交互增添新的可能性。例如,GPT-4V能夠自然地將箭頭指向的對象與給定的對象索引關聯起來;能夠理解圖像上書寫的問題并指向相應的邊緣或角度;可以指向圖中的任意區域。
視覺參照提示提供一種全新的交互方式,有望促進各種不同應用案例的實現。GPT-4V能夠生成自己的指示輸出,從而進一步促進人機交互中的閉環交互過程。例如,通過讓GPT-4V在文本格式中預測區域坐標來生成視覺指示輸出。在提示中包含例子引導指令有助于GPT-4V理解坐標的定義,進而生成更好的指示輸出。這種迭代指示生成、理解和執行的能力將有助于GPT-4V在各種復雜的視覺推理任務中取得更好的表現。

視覺參考提示直接編輯輸入圖像作為輸入提示,如繪圖視覺指針和場景文本。作為文本提示的補充,視覺引用提示提供了一個更微妙和自然的交互。例如,(1)將有指向的對象與索引相關聯,(2)指向對圖像進行質疑,(3)在文件和表格中突出線條,(4)繪制圖案在圖像上,以及許多其他新穎的用例。
八、情商測驗
GPT-4V在人類互動中展現出同理心和情商,理解和分享人類的情感。根據人類情商測試的定義,檢驗了其在以下方面的能力:
1、識別和解讀面部表情中的情感
2、理解視覺內容如何引發情感
3、在期望的情感和情緒態度下生成適當的文本輸出

GPT-4V了解不同的視覺內容如何激發人類的情感
接下來探討GPT-4V在理解視覺內容如何引發情感方面的能力。這種能力至關重要,因為要能預測不同的視覺內容如何喚起人類的情感并做出相應的反應(如憤怒、驚嘆和恐懼)。這種能力在家用機器人等使用場景中具有極其重要的意義。

GPT-4V根據社會標準和規范來判斷圖像美學
除理解視覺情感,GPT-4V還能與人類主觀判斷保持一致,如審美觀點。如圖所示,GPT-4V可以根據社會標準判斷圖像的美學。

GPT-4V能根據感知到的情緒,有效生成與所需情緒相匹配的適當文本輸出。例如GPT-4V能根據提示描述右邊的恐怖圖像,使其更加可怕或令人安心。這展示了其在實現情緒感知人機交流方面的潛力。
多模態對算力影響的探討
一、CLIP 打開圖文對齊大門,或成為實現多模態的核心基礎
目前視覺+語言的多模態大模型相對主流的方法為:借助預訓練好的大語言模型和圖像編碼器,用一個圖文特征對齊模塊來連接,從而讓語言模型理解圖像特征并進行更深層的問答推理。
根據 OpenAI 及微軟目前官方發布的 GPT-4V 相關新聞與論文,并不能詳細了解其實現多模態,尤其是視覺模型的具體方法,或許可以從 OpenAI 發布的 CLIP 以及其迭代后的 BLIP、BLIP2 等模型上,初步了解多模態大模型的實現方式。
1、CLIP 模型實現了圖像與文本的特征對齊,基礎架構已于 2021 年發布
過去的計算機視覺系統主要被訓練為圖像分類模型,這限制了它們在處理未知類別時的泛化能力。為了獲取大量廣泛的弱監督訓練數據,直接從原始文本中學習視覺表示,成為一種更有前途的方法。
OpenAI在2021年提出的CLIP模型采用了圖像文本對比學習的預訓練方法,這種預訓練模型可以在大規模數據上學習將圖像視覺特征與相匹配的文本進行關聯。即使不進行微調,也可以直接用于下游視覺任務,達到不錯的效果。CLIP克服了以往需要大量標注數據的限制。

代表性視覺大模型發布時間
2、CLIP 的輸入是配對好的圖片-文本對,輸出為對應特征,然后在特征上進行對比學習,即可以實現 zero-shot 的圖像分類
CLIP模型接受一系列圖像和對應的描述文本組成的訓練樣本對作為輸入。圖像通過圖像編碼器提取視覺特征,而文本則通過文本編碼器提取語義特征。模型會計算每一張圖像的視覺特征與相匹配的文本特征之間的相似度,作為正樣本;同時也會計算每一張圖像的視覺特征與不匹配的文本特征之間的相似度,作為負樣本。CLIP的訓練目標是最大程度地提高所有正樣本對的相似度,并最小程度地降低所有負樣本對的相似度。這意味著,匹配的圖像和文本對之間的特征盡可能相似,而不匹配的圖像和文本對之間的特征盡可能不同。通過這種預訓練方式,CLIP模型可以廣泛應用于下游的圖像理解任務中,無需進行額外的微調。
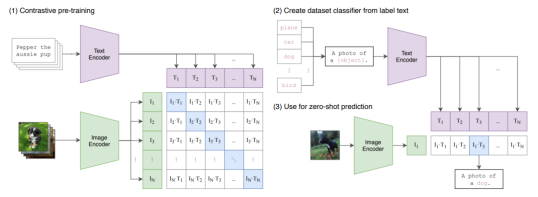
CLIP 訓練方法
在零樣本圖像分類中使用CLIP模型,首先根據每個類別設計描述文本,如“一張{label}的圖片”。通過輸入這些描述文本來提取文本特征。假設有n個類別,那么就會得到n個文本特征向量。然后,輸入需要預測的圖像,提取其圖像特征,并計算這個圖像特征與n個類別文本特征的相似度。相似度最高的類別對應的文本標簽就是模型對該圖像的預測。進一步將相似度轉化為logits,經過softmax處理后,得到每個類別的預測概率。預訓練的CLIP模型可以直接用于上述零樣本分類,無需進行額外的訓練或微調。
3、CLIP 最大的創新在于使用超大規模的數據集進行直接訓練,簡單而有效
CLIP模型的創新之處在于,它沒有提出新的網絡架構,而是采用高效的圖像文本匹配模型,并在大型數據集上進行訓練。在發布CLIP之前,主要的視覺數據集,如COCO和VisualGenome,都是人工標注的,質量很好,但數據量只有數百萬級別。相比之下,YFCC100M有1億個數據,但質量參差不齊,經過過濾后只剩下1500萬個,與ImageNet的數據規模相當。由于數據量不足,OpenAI構建了包含40億個數據點的WIT數據集,通過5000萬個查詢生成,每個查詢對應約20萬張圖像文本對的數據量,這個數據量與訓練GPT-2相當。WIT大數據量的存在使得CLIP模型的訓練更加充分。
4、2021 年,最優的模型大約需要 256 張 英偉達V100、訓練 12 天,效果即可顯著優于傳統視覺系統
OpenAI訓練了一系列CLIP模型,基于多種ResNet和Vision Transformer架構。最大的ResNet模型使用592個NVIDIAV100 GPU進行18天的訓練,而最大的ViT模型則使用256個V100 GPU進行12天的訓練。結果顯示,ViT模型優于ResNet模型,更大的ViT模型優于較小的ViT模型。最終的最優模型是ViT-L/14@336px。相比早期的工作,CLIP在零樣本分類上的表現有了顯著的提升,顯示出其在零樣本學習能力上達到了新的高度。

CLIP 與以往視覺分類模型效果比較
CLIP通過預訓練圖像文本匹配,將視覺和語義特征映射到統一的嵌入空間,從而架起文本和圖像理解之間的橋梁。這一技術的出現,使得在多模態上下文中進行推理成為可能。基于CLIP等模型,大規模語言模型如ChatGPT獲得了視覺理解的能力。CLIP系列模型為視覺語言統一預訓練奠定了基礎,是實現多模態ChatGPT的關鍵所在。
二、多模態應用空間廣闊,算力需求或呈量級式提升
多模態模型的訓練對算力需求有數量級的提升,可能需要數萬張GPU卡。有報道稱,與GPT-3.5相當的大規模語言模型Inflection在訓練時使用了約3500張英偉達H100 GPU。對于初創公司來說,訓練大型語言模型通常需要數千張H100 GPU,而微調過程則需要數十到數百張。還有報道顯示,GPT-4可能在1萬到2.5萬張英偉達A100 GPU上進行訓練,而GPT-5需要的H100 GPU數量可能是2.5萬到5萬張,相比GPT-3.5的規模提升了約10倍。
在推理階段,從數據量來看,圖像、視頻和語音相對于文本交互提升了數個數量級,導致算力需求急劇擴張。
1、在文本方面,從搜索到郵件主流軟件已逐步開放
Outlook和Gmail等主流電子郵件服務商已經支持ChatGPT功能。Outlook允許根據不同需求自動生成電子郵件回復,而Gmail用戶可以通過ChatGPT AI生成完整的電子郵件。此外,Chrome瀏覽器也提供免費支持。據統計,全球每天發送超過3300億封電子郵件,其中近一半是垃圾郵件。在郵件客戶端中,Gmail和Outlook的市場占有率分別是27.2%和7.8%。估算非垃圾郵件量,Outlook日均郵件數量約為137億封。根據郵件平均長度統計,考慮文本存儲格式的影響,估算Outlook日均郵件數據量約為25.52TB。假設ChatGPT在Outlook郵件場景中的使用率為1%,每日可能需要處理生成的數據量約261GB,比當前問答場景提升近8倍。
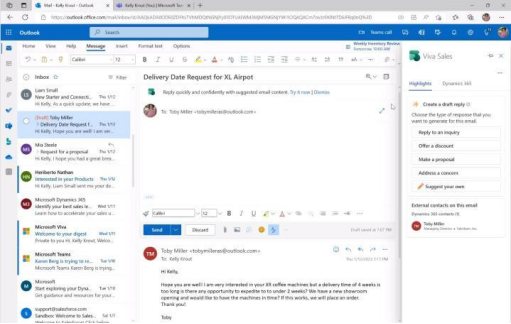
Outlook 利用 GPT 生成郵件
2、語音:Teams 已于 OpenAI 結合,大幅提升線上會議效率
微軟的Teams平臺已經與OpenAI實現了結合,支持自動生成會議紀要、章節劃分、時間標記等多種功能。用戶每月支付10美元后,可以使用GPT-3.5模型,獲得自動生成會議紀要、實時翻譯、章節劃分、時間軸標記等服務。Teams平臺擁有多種主要功能,其中包括自動生成紀要、40種語言的實時翻譯、AI章節劃分、個性化時間標記、保護隱私的水印和加密等。這些功能可以幫助用戶提高工作效率,節省時間成本,豐富會議體驗,而自動生成的紀要和章節劃分尤其有益。Teams實現與GPT-3.5的融合,代表了移動互聯時代生產力工具的新方向,為用戶提供更智能化的服務。
通過實時翻譯與字幕,減少會議期間的語言障礙
隨著語音輸入在大模型中的應用在Teams平臺中得到日益廣泛的應用,其新增數據量的需求也將得到相應的提升。數字音頻的存儲原理表明,采樣頻率、量化位數以及聲道數都會影響其存儲量。在電話質量的音頻中,采用8kHz的采樣率、8bit的量化、雙聲道的存儲方式,其存儲量約為每秒2字節。假設在Teams的語音交互場景下,ChatGPT每天需要處理1小時的音頻數據,那么每天新增的數據量需求約為7200字節,即7.03KB。
考慮到Teams目前日活躍用戶已過億,我們可以估算,如果所有用戶都使用1小時的音頻交互,那么每天新增的數據量需求約為7.03KB * 1億 = 703GB。相比當前的文本交互,語音數據量需求提升了約200倍。因此,語音交互場景的引入將給AI系統帶來數據量級的顯著提升。
音頻數字化后的數據量計算方式為:以字節為單位,模擬波形聲音被數字化后音頻文件的存儲量(假定未經壓縮)為:存儲量=采樣頻率(Hz)x量化位數(bit)/8x聲道數x時間。這種計算方式可以幫助我們更好地理解和預測音頻數據存儲的需求。
根據微軟公開數據,Teams平臺的日活躍用戶數量從2020年的1.15億增長到了2022年的2.7億。假設Teams的會議總時長與用戶數成比例增長,那么2022年Teams的會議總時長估計約為60億分鐘。根據音頻存儲原理,以電話質量參數估算,60億分鐘音頻對應的存儲量約為671GB。假設約50%的用戶使用ChatGPT生成會議紀要,那么Teams新增語音數據需求約為336GB。需要注意的是,這只是基于電話音質的參數估算,而實際上音頻采樣率和碼率的差異可能會導致實際數據量更大。另外,使用ChatGPT生成紀要的用戶比例也可能會有所調整,從而影響最終的需求。
3、圖片:Filmora 接入 OpenAI 服務,實現“文生圖”及“圖生圖”
Filmora視頻制作軟件已集成OpenAI功能,可通過一鍵智能生成圖片素材。萬興科技為Filmora提供了對OpenAI AI繪圖能力的支持,用戶只需簡單描繪出形狀,即可在幾秒鐘內獲得AI生成的完整圖像。在最新的情人節版本中,Filmora實現了從“文生圖”到“圖生圖”的轉換,用戶只需輸入簡單文本即可獲得高質量的AI生成圖片。這代表了創作工具與AI結合的新方向。通過與OpenAI的結合,Filmora可以幫助普通用戶輕松獲得高質量圖像,從而輔助視頻創作。未來,Filmora預計將加入更多AI生成內容的功能,為用戶提供更智能高效的創作體驗。
Wondershare Filmora 一鍵“創作”圖片
根據Filmora的圖片參數估算,其OpenAI生成圖片每天的輸出數據量約為586GB。Filmora的默認分辨率為1920*1080,每張圖片約為6MB。假設每月活躍用戶數為300萬,每天調用OpenAI 10萬次,則每天的數據量約為586GB。萬興科技旗下的億圖腦圖也已集成了AI生成內容功能,用戶只需輸入文本即可自動生成各種腦圖。這種技術的應用場景非常廣泛,包括營銷、出版、藝術、醫療等領域。未來,預計AI生成圖像的應用空間將會進一步擴大。
4、視頻:AIGC 輔助生成動畫,星辰大海拉開序幕
AIGC技術在商業動畫片《犬與少年》中的應用前景廣闊。該作品由Netflix、小冰公司日本分部(rinna)、WIT STUDIO共同創作。小冰公司是一家獨立的技術研發實體,前身為微軟人工智能小冰團隊,2020年分拆為獨立公司。2022年11月7日,小冰公司完成總額10億元的新融資,用于加速AI Being小冰框架技術研發,并宣布升級其人工智能數字員工(AI Being Employee)產品線,包括大模型對話引擎、3D神經網絡渲染、超級自然語音及AIGC人工智能內容生成。小冰公司的業務覆蓋全球多個國家和地區,擁有眾多用戶和觀眾。
《犬與少年》AI 參與制作
Runway Gen2已開放,視頻生成費用為0.2美元。Runway宣布開放Gen-1和Gen-2模型,免費提供給公眾試用,發布視頻長度4秒,每秒消耗5積分。若積分用盡,用戶可以選擇付費使用,0.01美元/積分,即生成一個視頻需要0.2美元。Gen-2只需文字、圖像或文字加圖像的描述即可快速生成相關視頻,是市場上首個公開可用的文本到視頻模型。視頻單秒輸出數據量達1MB,預示著未來星辰大海的序幕正在拉開。隨著AIGC技術在影視劇集、宣傳視頻等領域逐步滲透,視頻創作效率有望顯著提升。
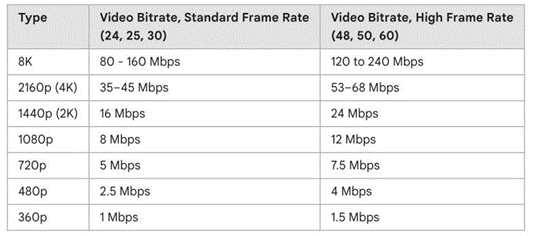
SDR 視頻上 Youtube 的推薦比特率
綜上所述,得出以下結論:目前ChatGPT和AIGC的應用場景遠未被完全挖掘,語音、圖片、視頻等多種形式的輸入輸出將為內容創作領域帶來革命性變化。更廣泛的數據形態、更多的應用場景和更深入的用戶體驗將增加對人工智能算力的需求,這可能導致算力的高速擴張時代到來。
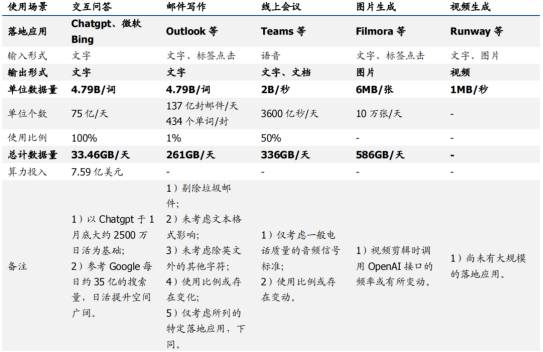
OpenAI 大模型各類場景數據量測算
三、英偉達最強AI芯片GH200究竟強在哪里?
GH200和H100屬于同一代產品,其AI計算芯片架構相同,計算能力相當。但是,GH200的內存容量比H100大了3.5倍,這對于需要處理更復雜模型或更大數據量的AI任務來說更加有利。因此,GH200相較于H100的優勢在于其更大容量的內存,而不是計算能力。
GH200包含一個Grace CPU芯片和一個Hopper GPU芯片,兩者通過高速NVLink-C2C互連,帶寬高達900GB/s,實現了緊密的CPU和GPU數據交換。這使得GH200的GPU能夠直接訪問CPU內存。相比之下,在H100系統中,CPU和GPU通常僅通過PCIe連接,即使是最新一代的帶寬也只有128GB/s,不及GH200的NVLink-C2C的七分之一。因此,通過芯片級別的優化設計,GH200實現了更高效的CPU-GPU內存共享,這對于需要頻繁進行CPU-GPU數據交換的AI計算更加友好。
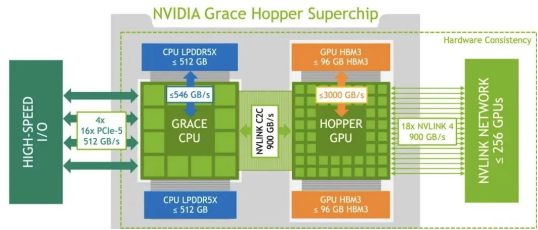
每個GH200集成512GB CPU內存和96GB GPU HBM3內存。Hopper GPU通過NVLink-C2C訪問Grace CPU全部內存。相比之下,單顆H100最多80GB HBM3內存,且無法高效連接CPU。基于GH200的DGX GH200集群,256個GPU連接后共享144TB內存(計算方式:(480GB+96GB)* 256)。DGX GH200適用于存在GPU內存瓶頸的AI和HPC應用。GH200通過超大內存和CPU-GPU互聯,可以加速這些應用。
藍海大腦大模型訓練平臺
藍海大腦大模型訓練平臺提供強大的算力支持,包括基于開放加速模組高速互聯的AI加速器。配置高速內存且支持全互聯拓撲,滿足大模型訓練中張量并行的通信需求。支持高性能I/O擴展,同時可以擴展至萬卡AI集群,滿足大模型流水線和數據并行的通信需求。強大的液冷系統熱插拔及智能電源管理技術,當BMC收到PSU故障或錯誤警告(如斷電、電涌,過熱),自動強制系統的CPU進入ULFM(超低頻模式,以實現最低功耗)。致力于通過“低碳節能”為客戶提供環保綠色的高性能計算解決方案。主要應用于深度學習、學術教育、生物醫藥、地球勘探、氣象海洋、超算中心、AI及大數據等領域。
一、為什么需要大模型?
1、模型效果更優
大模型在各場景上的效果均優于普通模型
2、創造能力更強
大模型能夠進行內容生成(AIGC),助力內容規模化生產
3、靈活定制場景
通過舉例子的方式,定制大模型海量的應用場景
4、標注數據更少
通過學習少量行業數據,大模型就能夠應對特定業務場景的需求
二、平臺特點
1、異構計算資源調度
一種基于通用服務器和專用硬件的綜合解決方案,用于調度和管理多種異構計算資源,包括CPU、GPU等。通過強大的虛擬化管理功能,能夠輕松部署底層計算資源,并高效運行各種模型。同時充分發揮不同異構資源的硬件加速能力,以加快模型的運行速度和生成速度。
2、穩定可靠的數據存儲
支持多存儲類型協議,包括塊、文件和對象存儲服務。將存儲資源池化實現模型和生成數據的自由流通,提高數據的利用率。同時采用多副本、多級故障域和故障自恢復等數據保護機制,確保模型和數據的安全穩定運行。
3、高性能分布式網絡
提供算力資源的網絡和存儲,并通過分布式網絡機制進行轉發,透傳物理網絡性能,顯著提高模型算力的效率和性能。
4、全方位安全保障
在模型托管方面,采用嚴格的權限管理機制,確保模型倉庫的安全性。在數據存儲方面,提供私有化部署和數據磁盤加密等措施,保證數據的安全可控性。同時,在模型分發和運行過程中,提供全面的賬號認證和日志審計功能,全方位保障模型和數據的安全性。
三、常用配置
1、處理器CPU:
Intel Xeon Gold 8358P 32C/64T 2.6GHz 48MB,DDR4 3200,Turbo,HT 240W
Intel Xeon Platinum 8350C 32C/64T 2.6GHz 48MB,DDR4 3200,Turbo,HT 240W
Intel Xeon Platinum 8458P 28C/56T 2.7GHz 38.5MB,DDR4 2933,Turbo,HT 205W
Intel Xeon Platinum 8468 Processor 48C/64T 2.1GHz 105M Cache 350W
AMD EPYC? 7742 64C/128T,2.25GHz to 3.4GHz,256MB,DDR4 3200MT/s,225W
AMD EPYC? 9654 96C/192T,2.4GHz to 3.55GHz to 3.7GHz,384MB,DDR5 4800MT/s,360W
2、顯卡GPU:
NVIDIA L40S GPU 48GB
NVIDIA NVLink-A100-SXM640GB
NVIDIA HGX A800 80GB
NVIDIA Tesla H800 80GB HBM2
NVIDIA A800-80GB-400Wx8-NvlinkSW×8
審核編輯 黃宇
-
人工智能
+關注
關注
1806文章
49028瀏覽量
249499 -
語言模型
+關注
關注
0文章
561瀏覽量
10789 -
英偉達
+關注
關注
22文章
3953瀏覽量
93776
發布評論請先 登錄
進一步解讀英偉達 Blackwell 架構、NVlink及GB200 超級芯片
英偉達DPU的過“芯”之處
搭載256顆GH200超級芯片的超級計算機
英偉達新發GH200對PCB的影響如何?

生成式AI新增多重亮點,英偉達推出超級芯片GH200 Grace

gh200和h100性能對比
gh200芯片參數介紹
gh200相比gh100的區別
gh200和超級計算機哪個牛
英偉達GH200、特斯拉Dojo超級算力集群,性能爆棚!算力之爭加劇!

178頁,128個案例,GPT-4V醫療領域全面測評,離臨床應用與實際決策尚有距離

如何在邊緣端獲得GPT4-V的能力:算力魔方+MiniCPM-V 2.6





 工商網監
工商網監
評論