") 多路IO復用模型和異步IO模型介紹
多路IO復用模型和異步IO模型介紹

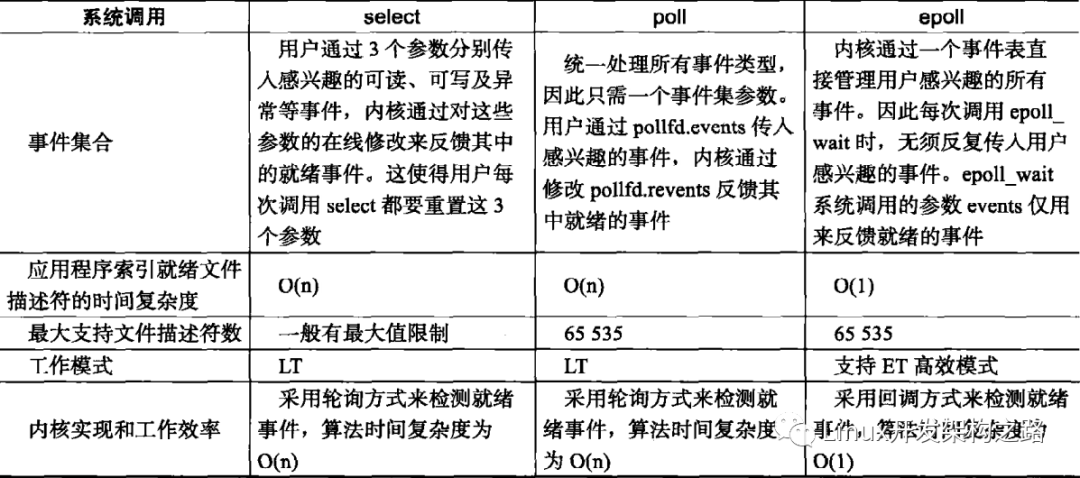
多路 IO 復用模型
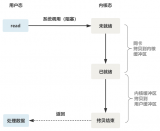
多路 IO 復用,有時也稱為事件驅(qū)動 IO。它的基本原理就是有個函數(shù)會不斷地輪詢所負責的所有 socket ,當某個 socket有數(shù)據(jù)到達了,就通知用戶進程。IO 復用模型的流程如圖:
當用戶進程調(diào)用了 select ,那么整個進程會被阻塞,而同時,內(nèi)核會 “監(jiān)視” 所有 select 負責的 socket ,當任何一個 socket中的數(shù)據(jù)準備好了, select 就會返回。這個時候用戶進程再調(diào)用 read 操作,將數(shù)據(jù)從內(nèi)核拷貝到用戶進程。
這個模型和阻塞 IO 的模型其實并沒有太大的不同,事實上還更差一些 因為這里需要使用兩個系統(tǒng)調(diào)用,而阻塞 IO 只調(diào)用了一個系統(tǒng)調(diào)用recvfrom,用 select 的優(yōu)勢在于它可以同時處理多個連接。
如果處理的連接數(shù)不是很高的話,使用 select/epoll Web server 定比使用多線程的阻塞 IO Web server性能更好,可能延遲還更大;select/poll 的優(yōu)勢并不是對于單個連接能處理得更快,而是在于能處理更多的連接。
異步 IO 模型
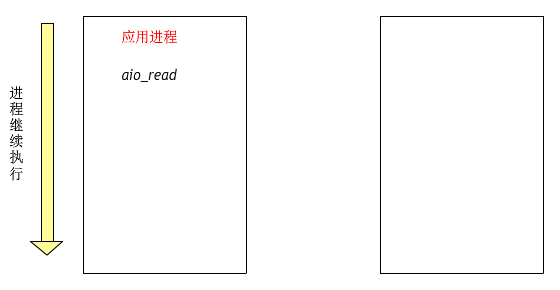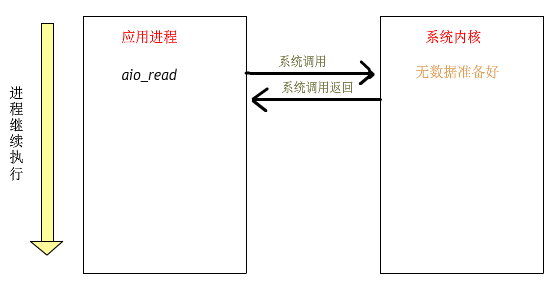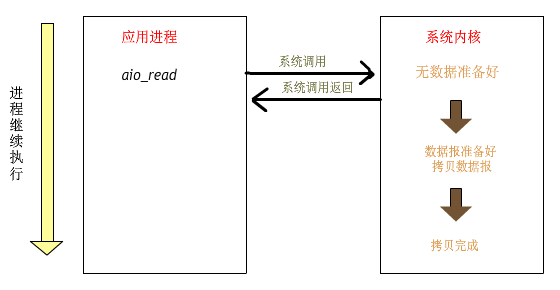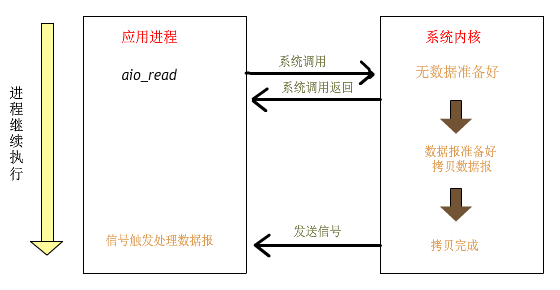
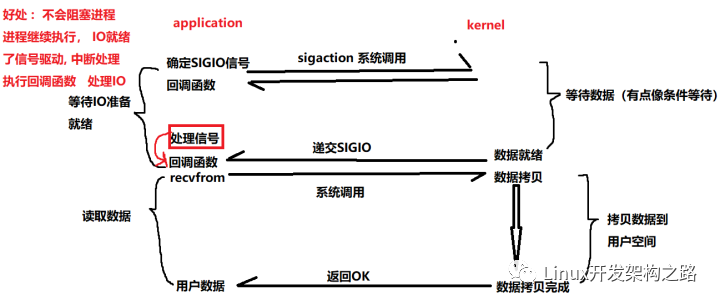
上面是異步 IO 模型。
用戶進程發(fā)起 read 操作之后,立刻就可以開始去做其他的事;而另一方面,從內(nèi)核的角度,當它收到一個異步的 read請求操作之后,首先會立刻返回,所以不會對用戶進程產(chǎn)生任何阻塞。
然后,內(nèi)核會等待數(shù)據(jù)準備完成,然后將數(shù)據(jù)拷貝到用戶內(nèi)存中,當這一切都完成之后,內(nèi)核會給用戶進程發(fā)送一個信號,返回 read 操作已完成的信息。
調(diào)用阻塞 IO 一直阻塞住對應的進程直到操作完成,而非阻塞 IO 在內(nèi)核還在準備數(shù)據(jù)的情況下會立刻返回。兩者的區(qū)別就在于同步 IO 進行 IO操作時會阻塞進程。
非阻塞 IO 在執(zhí)行 recvfrom 這個系統(tǒng)調(diào)用的時候,如果內(nèi)核的數(shù)據(jù)沒有準備好,這時候不會阻塞進程。但是當內(nèi)核中數(shù)據(jù)準備好時,recvfrom會將數(shù)據(jù)從內(nèi)核拷貝到用戶內(nèi)存中,這個時候進程則被阻塞。
而異步 IO 則不 樣,當進程發(fā)起 IO 操作之后,就直接返回,直到內(nèi)核發(fā)送一個信號,告訴進程 IO
已完成,則在這整個過程中,進程完全沒有被阻塞。
-
IO
+關注
關注
0文章
491瀏覽量
40547 -
驅(qū)動
+關注
關注
12文章
1918瀏覽量
86927 -
網(wǎng)絡
+關注
關注
14文章
7815瀏覽量
90951 -
模型
+關注
關注
1文章
3520瀏覽量
50420
發(fā)布評論請先 登錄
Linux驅(qū)動開發(fā)之IO模型介紹
基于多路復用模型的Netty框架
IO模型以及多路復用的總結(jié)及視頻資料
IO多路復用的幾種實現(xiàn)機制的分析
網(wǎng)絡IO的弊端以及多路復用IO的優(yōu)勢

信號驅(qū)動IO與異步IO的區(qū)別
linux異步io框架iouring應用
異步IO框架iouring介紹





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論