") NeurIPS 2023 | 擴(kuò)散模型解決多任務(wù)強(qiáng)化學(xué)習(xí)問(wèn)題
NeurIPS 2023 | 擴(kuò)散模型解決多任務(wù)強(qiáng)化學(xué)習(xí)問(wèn)題
擴(kuò)散模型(diffusion model)在 CV 領(lǐng)域甚至 NLP 領(lǐng)域都已經(jīng)有了令人印象深刻的表現(xiàn)。最近的一些工作開(kāi)始將 diffusion model 用于強(qiáng)化學(xué)習(xí)(RL)中來(lái)解決序列決策問(wèn)題,它們主要利用 diffusion model 來(lái)建模分布復(fù)雜的軌跡或提高策略的表達(dá)性。
但是, 這些工作仍然局限于單一任務(wù)單一數(shù)據(jù)集,無(wú)法得到能同時(shí)解決多種任務(wù)的通用智能體。那么,diffusion model 能否解決多任務(wù)強(qiáng)化學(xué)習(xí)問(wèn)題呢?我們最近提出的一篇新工作——“Diffusion Model is an Effective Planner and Data Synthesizer for Multi-Task Reinforcement Learning”,旨在解決這個(gè)問(wèn)題并希望啟發(fā)后續(xù)通用決策智能的研究:

論文鏈接:
https://arxiv.org/abs/2305.18459

背景
數(shù)據(jù)驅(qū)動(dòng)的大模型在 CV 和 NLP 領(lǐng)域已經(jīng)獲得巨大成功,我們認(rèn)為這背后源于模型的強(qiáng)表達(dá)性和數(shù)據(jù)集的多樣性和廣泛性。基于此,我們將最近出圈的生成式擴(kuò)散模型(diffusion model)擴(kuò)展到多任務(wù)強(qiáng)化學(xué)習(xí)領(lǐng)域(multi-task reinforcement learning),利用 large-scale 的離線多任務(wù)數(shù)據(jù)集訓(xùn)練得到通用智能體。 目前解決多任務(wù)強(qiáng)化學(xué)習(xí)的工作大多基于 Transformer 架構(gòu),它們通常對(duì)模型的規(guī)模,數(shù)據(jù)集的質(zhì)量都有很高的要求,這對(duì)于實(shí)際訓(xùn)練來(lái)說(shuō)是代價(jià)高昂的。基于 TD-learning 的強(qiáng)化學(xué)習(xí)方法則常常面臨 distribution-shift 的挑戰(zhàn),在多任務(wù)數(shù)據(jù)集下這個(gè)問(wèn)題尤甚,而我們將序列決策過(guò)程建模成條件式生成問(wèn)題(conditional generative process),通過(guò)最大化 likelihood 來(lái)學(xué)習(xí),有效避免了 distribution shift 的問(wèn)題。

方法
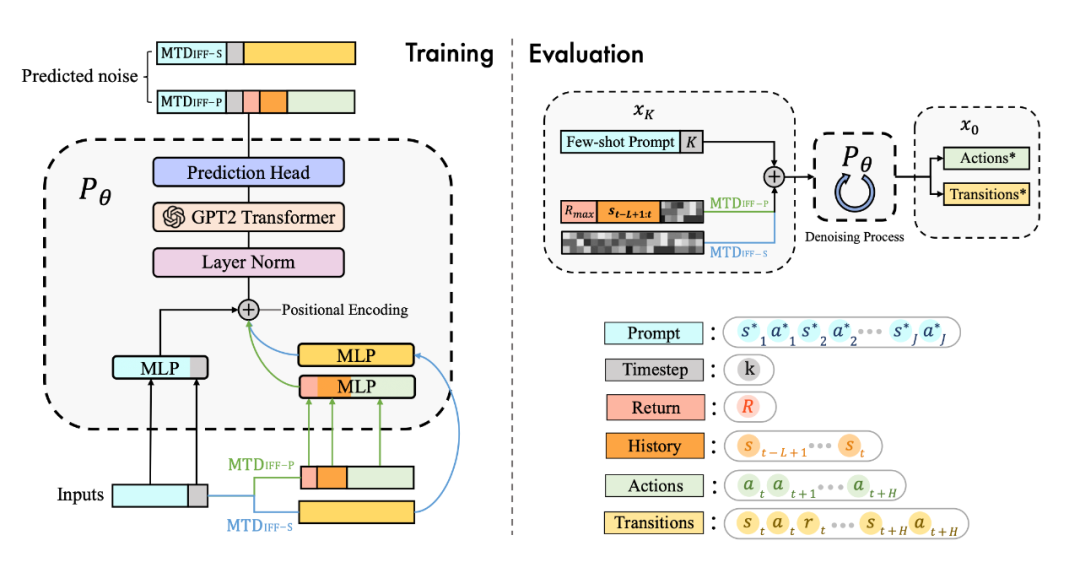
具體來(lái)說(shuō),我們發(fā)現(xiàn) diffusion model 不僅能很好地輸出 action 進(jìn)行實(shí)時(shí)決策,同樣能夠建模完整的(s,a,r,s')的 transition 來(lái)生成數(shù)據(jù)進(jìn)行數(shù)據(jù)增強(qiáng)提升強(qiáng)化學(xué)習(xí)策略的性能,具體框架如圖所示:
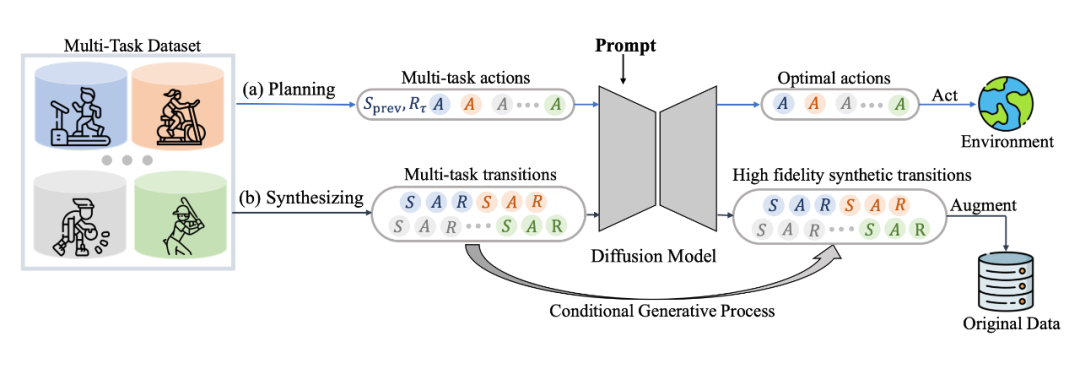
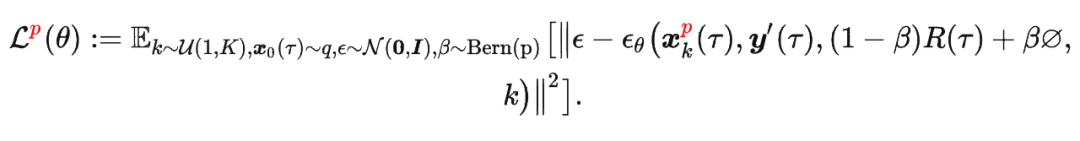 其中
其中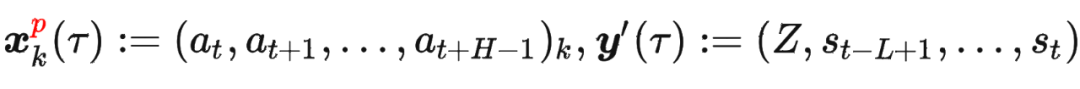 是軌跡的標(biāo)準(zhǔn)化累積回報(bào), 是 Demonstration Prompt,可以表示為:
是軌跡的標(biāo)準(zhǔn)化累積回報(bào), 是 Demonstration Prompt,可以表示為:

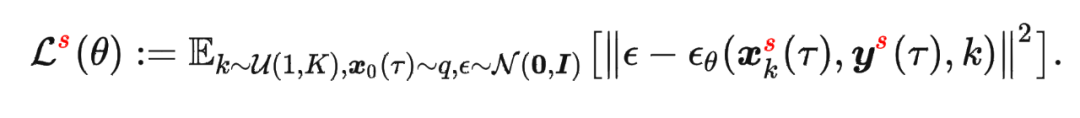 其中
其中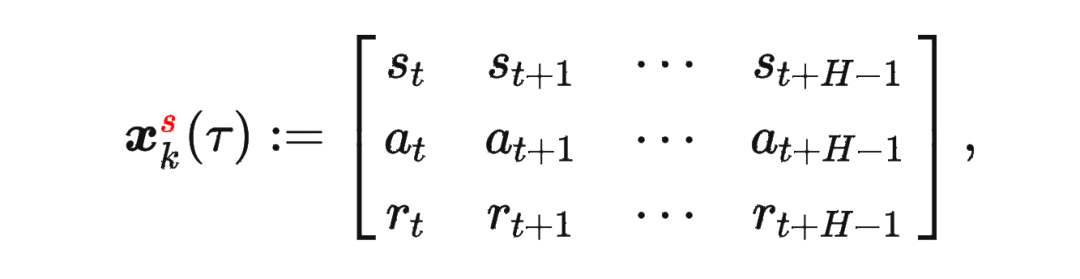
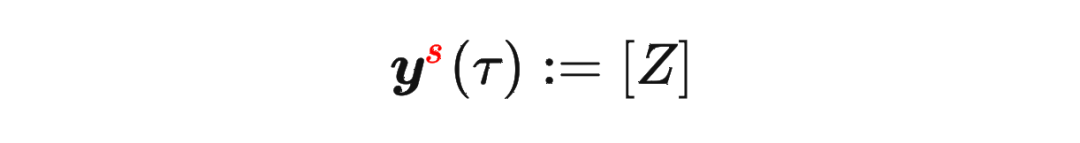

模型結(jié)構(gòu)
為了更好地建模多任務(wù)數(shù)據(jù),并且統(tǒng)一多樣化的輸入數(shù)據(jù),我們用 transformer 架構(gòu)替換了傳統(tǒng)的 U-Net 網(wǎng)絡(luò),網(wǎng)絡(luò)結(jié)構(gòu)圖如下:

實(shí)驗(yàn)
我們首先在 Meta-World MT50 上開(kāi)展實(shí)驗(yàn)并與 baselines 進(jìn)行比較,我們?cè)趦煞N數(shù)據(jù)集上進(jìn)行實(shí)驗(yàn),分別是包含大量專家數(shù)據(jù),從 SAC-single-agent 中的 replay buffer 中收集到的 Near-optimal data(100M);以及從 Near-optimal data 中降采樣得到基本不包含專家數(shù)據(jù)的 Sub-optimal data(50M)。實(shí)驗(yàn)結(jié)果如下:
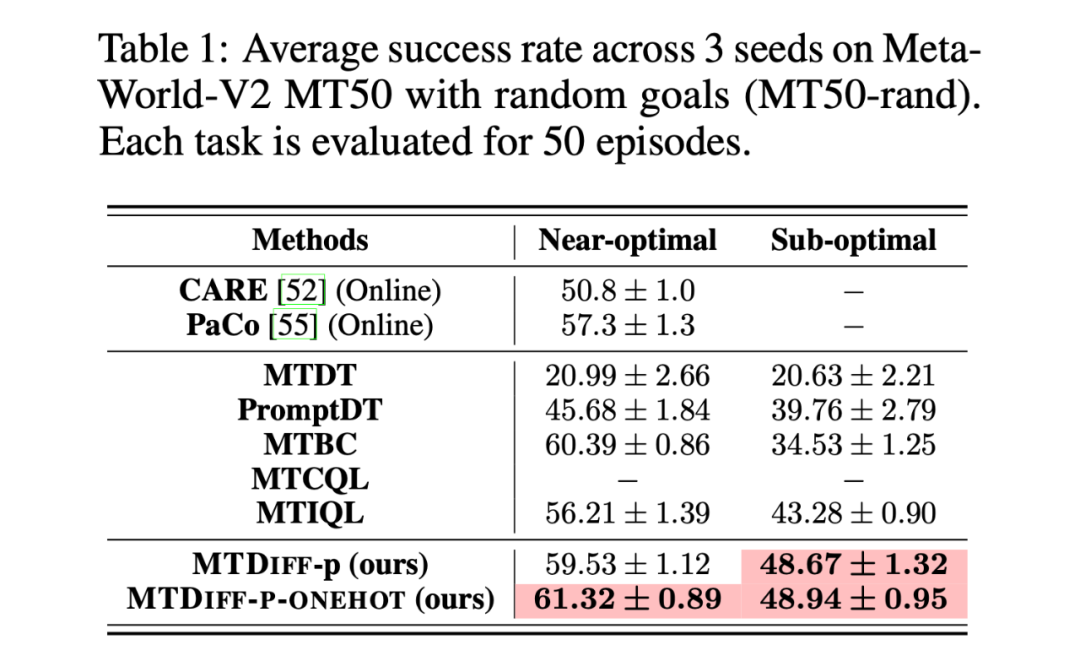
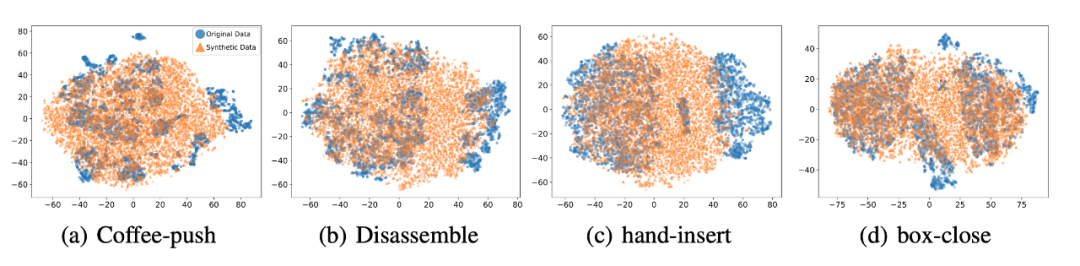
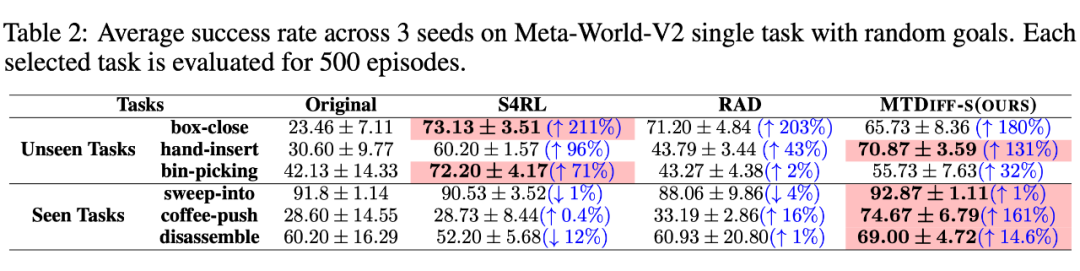 我們選取 45 個(gè)任務(wù)的 Near-optimal data 訓(xùn)練 ,從表中我們可以觀察到在 見(jiàn)過(guò)的任務(wù)上,我們的方法均取得了最好的性能。甚至給定一段 demonstration prompt, 能泛化到?jīng)]見(jiàn)過(guò)的任務(wù)上并取得較好的表現(xiàn)。我們選取四個(gè)任務(wù)對(duì)原數(shù)據(jù)和 生成的數(shù)據(jù)做 T-SNE 可視化分析,發(fā)現(xiàn)我們生成的數(shù)據(jù)的分布基本匹配原數(shù)據(jù)分布,并且在不偏離的基礎(chǔ)上擴(kuò)展了分布,使數(shù)據(jù)覆蓋更加全面。
我們選取 45 個(gè)任務(wù)的 Near-optimal data 訓(xùn)練 ,從表中我們可以觀察到在 見(jiàn)過(guò)的任務(wù)上,我們的方法均取得了最好的性能。甚至給定一段 demonstration prompt, 能泛化到?jīng)]見(jiàn)過(guò)的任務(wù)上并取得較好的表現(xiàn)。我們選取四個(gè)任務(wù)對(duì)原數(shù)據(jù)和 生成的數(shù)據(jù)做 T-SNE 可視化分析,發(fā)現(xiàn)我們生成的數(shù)據(jù)的分布基本匹配原數(shù)據(jù)分布,并且在不偏離的基礎(chǔ)上擴(kuò)展了分布,使數(shù)據(jù)覆蓋更加全面。

總結(jié)
我們提出了一種基于擴(kuò)散模型(diffusion model)的一種新的、通用性強(qiáng)的多任務(wù)強(qiáng)化學(xué)習(xí)解決方案,它不僅可以通過(guò)單個(gè)模型高效完成多任務(wù)決策,而且可以對(duì)原數(shù)據(jù)集進(jìn)行增強(qiáng),從而提升各種離線算法的性能。我們未來(lái)將把 遷移到更加多樣、更加通用的場(chǎng)景,旨在深入挖掘其出色的生成能力和數(shù)據(jù)建模能力,解決更加困難的任務(wù)。同時(shí),我們會(huì)將 遷移到真實(shí)控制場(chǎng)景,并嘗試優(yōu)化其推理速度以適應(yīng)某些需要高頻控制的任務(wù)。
原文標(biāo)題:NeurIPS 2023 | 擴(kuò)散模型解決多任務(wù)強(qiáng)化學(xué)習(xí)問(wèn)題
文章出處:【微信公眾號(hào):智能感知與物聯(lián)網(wǎng)技術(shù)研究所】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
聲明:本文內(nèi)容及配圖由入駐作者撰寫(xiě)或者入駐合作網(wǎng)站授權(quán)轉(zhuǎn)載。文章觀點(diǎn)僅代表作者本人,不代表電子發(fā)燒友網(wǎng)立場(chǎng)。文章及其配圖僅供工程師學(xué)習(xí)之用,如有內(nèi)容侵權(quán)或者其他違規(guī)問(wèn)題,請(qǐng)聯(lián)系本站處理。
舉報(bào)投訴
-
物聯(lián)網(wǎng)
+關(guān)注
關(guān)注
2927文章
45847瀏覽量
387819
原文標(biāo)題:NeurIPS 2023 | 擴(kuò)散模型解決多任務(wù)強(qiáng)化學(xué)習(xí)問(wèn)題
文章出處:【微信號(hào):tyutcsplab,微信公眾號(hào):智能感知與物聯(lián)網(wǎng)技術(shù)研究所】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
熱點(diǎn)推薦
快速入門——LuatOS:sys庫(kù)多任務(wù)管理實(shí)戰(zhàn)攻略!
在嵌入式開(kāi)發(fā)中,多任務(wù)管理是提升系統(tǒng)效率的關(guān)鍵。本教程專為快速入門設(shè)計(jì),聚焦LuatOS的sys庫(kù),通過(guò)實(shí)戰(zhàn)案例帶你快速掌握多任務(wù)創(chuàng)建、調(diào)度與同步技巧。無(wú)論你是零基礎(chǔ)新手還是希望快速提升開(kāi)發(fā)效率
18個(gè)常用的強(qiáng)化學(xué)習(xí)算法整理:從基礎(chǔ)方法到高級(jí)模型的理論技術(shù)與代碼實(shí)現(xiàn)
本來(lái)轉(zhuǎn)自:DeepHubIMBA本文系統(tǒng)講解從基本強(qiáng)化學(xué)習(xí)方法到高級(jí)技術(shù)(如PPO、A3C、PlaNet等)的實(shí)現(xiàn)原理與編碼過(guò)程,旨在通過(guò)理論結(jié)合代碼的方式,構(gòu)建對(duì)強(qiáng)化學(xué)習(xí)算法的全面理解。為確保內(nèi)容

詳解RAD端到端強(qiáng)化學(xué)習(xí)后訓(xùn)練范式
受限于算力和數(shù)據(jù),大語(yǔ)言模型預(yù)訓(xùn)練的 scalinglaw 已經(jīng)趨近于極限。DeepSeekR1/OpenAl01通過(guò)強(qiáng)化學(xué)習(xí)后訓(xùn)練涌現(xiàn)了強(qiáng)大的推理能力,掀起新一輪技術(shù)革新。

了解DeepSeek-V3 和 DeepSeek-R1兩個(gè)大模型的不同定位和應(yīng)用選擇
專業(yè)數(shù)據(jù)
注入大量數(shù)學(xué)/科學(xué)文獻(xiàn)與合成推理數(shù)據(jù)
微調(diào)策略
多任務(wù)聯(lián)合訓(xùn)練
推理鏈強(qiáng)化學(xué)習(xí)(RLCF)+ 符號(hào)蒸餾
推理效率
均衡優(yōu)化(適合常規(guī)任務(wù))
針對(duì)長(zhǎng)邏輯鏈的并行加速技術(shù)
4. 典型應(yīng)用場(chǎng)
發(fā)表于 02-14 02:08
【「基于大模型的RAG應(yīng)用開(kāi)發(fā)與優(yōu)化」閱讀體驗(yàn)】+大模型微調(diào)技術(shù)解讀
Tuning)和Prompt-Tuning:通過(guò)在輸入序列中添加特定提示來(lái)引導(dǎo)模型生成期望的輸出,簡(jiǎn)單有效,適用于多種任務(wù)。P-Tuning v1和P-Tuning v2:基于多任務(wù)學(xué)習(xí)
發(fā)表于 01-14 16:51
基于移動(dòng)自回歸的時(shí)序擴(kuò)散預(yù)測(cè)模型
回歸取得了比傳統(tǒng)基于噪聲的擴(kuò)散模型更好的生成效果,并且獲得了人工智能頂級(jí)會(huì)議 NeurIPS 2024 的 best paper。 然而在時(shí)間序列預(yù)測(cè)領(lǐng)域,當(dāng)前主流的擴(kuò)散方法還是傳統(tǒng)的
智譜GLM-Zero深度推理模型預(yù)覽版正式上線
近日,智譜公司宣布其深度推理模型GLM-Zero的初代版本——GLM-Zero-Preview已正式上線。這款模型是智譜首個(gè)基于擴(kuò)展強(qiáng)化學(xué)習(xí)技術(shù)訓(xùn)練的推理模型,標(biāo)志著智譜在AI推理領(lǐng)域
浙大、微信提出精確反演采樣器新范式,徹底解決擴(kuò)散模型反演問(wèn)題
隨著擴(kuò)散生成模型的發(fā)展,人工智能步入了屬于?AIGC?的新紀(jì)元。擴(kuò)散生成模型可以對(duì)初始高斯噪聲進(jìn)行逐步去噪而得到高質(zhì)量的采樣。當(dāng)前,許多應(yīng)用都涉及擴(kuò)

螞蟻集團(tuán)收購(gòu)邊塞科技,吳翼出任強(qiáng)化學(xué)習(xí)實(shí)驗(yàn)室首席科學(xué)家
近日,專注于模型賽道的初創(chuàng)企業(yè)邊塞科技宣布被螞蟻集團(tuán)收購(gòu)。據(jù)悉,此次交易完成后,邊塞科技將保持獨(dú)立運(yùn)營(yíng),而原投資人已全部退出。 與此同時(shí),螞蟻集團(tuán)近期宣布成立強(qiáng)化學(xué)習(xí)實(shí)驗(yàn)室,旨在推動(dòng)大模型強(qiáng)化
如何使用 PyTorch 進(jìn)行強(qiáng)化學(xué)習(xí)
強(qiáng)化學(xué)習(xí)(Reinforcement Learning, RL)是一種機(jī)器學(xué)習(xí)方法,它通過(guò)與環(huán)境的交互來(lái)學(xué)習(xí)如何做出決策,以最大化累積獎(jiǎng)勵(lì)。PyTorch 是一個(gè)流行的開(kāi)源機(jī)器學(xué)習(xí)庫(kù),
擴(kuò)散模型的理論基礎(chǔ)
擴(kuò)散模型的迅速崛起是過(guò)去幾年機(jī)器學(xué)習(xí)領(lǐng)域最大的發(fā)展之一。在這本簡(jiǎn)單易懂的指南中,學(xué)習(xí)你需要知道的關(guān)于擴(kuò)散

谷歌AlphaChip強(qiáng)化學(xué)習(xí)工具發(fā)布,聯(lián)發(fā)科天璣芯片率先采用
近日,谷歌在芯片設(shè)計(jì)領(lǐng)域取得了重要突破,詳細(xì)介紹了其用于芯片設(shè)計(jì)布局的強(qiáng)化學(xué)習(xí)方法,并將該模型命名為“AlphaChip”。據(jù)悉,AlphaChip有望顯著加速芯片布局規(guī)劃的設(shè)計(jì)流程,并幫助芯片在性能、功耗和面積方面實(shí)現(xiàn)更優(yōu)表現(xiàn)。
【《大語(yǔ)言模型應(yīng)用指南》閱讀體驗(yàn)】+ 基礎(chǔ)知識(shí)學(xué)習(xí)
今天來(lái)學(xué)習(xí)大語(yǔ)言模型在自然語(yǔ)言理解方面的原理以及問(wèn)答回復(fù)實(shí)現(xiàn)。
主要是基于深度學(xué)習(xí)和自然語(yǔ)言處理技術(shù)。
大語(yǔ)言模型涉及以下幾個(gè)過(guò)程:
數(shù)據(jù)收集:大語(yǔ)言
發(fā)表于 08-02 11:03
【《大語(yǔ)言模型應(yīng)用指南》閱讀體驗(yàn)】+ 基礎(chǔ)篇
章節(jié)最后總結(jié)了機(jī)器學(xué)習(xí)的分類:有監(jiān)督學(xué)習(xí)、無(wú)監(jiān)督學(xué)習(xí)、半監(jiān)督學(xué)習(xí)、自監(jiān)督學(xué)習(xí)和強(qiáng)化學(xué)習(xí)。
1.3
發(fā)表于 07-25 14:33
通過(guò)強(qiáng)化學(xué)習(xí)策略進(jìn)行特征選擇
來(lái)源:DeepHubIMBA特征選擇是構(gòu)建機(jī)器學(xué)習(xí)模型過(guò)程中的決定性步驟。為模型和我們想要完成的任務(wù)選擇好的特征,可以提高性能。如果我們處理的是高維數(shù)據(jù)集,那么選擇特征就顯得尤為重要。





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論