 推理芯片的最大挑戰
推理芯片的最大挑戰
在不到一年的時間里,生成式人工智能通過 OpenAI 的 ChatGPT(一種基于 Transformer 的流行算法)獲得了全球聲譽和使用。基于 Transformer 的算法可以學習對象不同元素(例如句子或問題)之間的復雜交互,并將其轉換為類似人類的對話。
在 Transformer 和其他大型語言模型 (LLM) 的引領下,軟件算法取得了快速進展,而負責執行它們的處理硬件卻被拋在了后面。即使是最先進的算法處理器也不具備在一兩秒的時間范圍內詳細闡述最新 ChatGPT 查詢所需的性能。
為了彌補性能不足,領先的半導體公司構建了由大量最好的硬件處理器組成的系統。在此過程中,他們權衡了功耗、帶寬/延遲和成本。該方法適用于算法訓練,但不適用于部署在邊緣設備上的推理。
功耗挑戰
雖然訓練通常基于生成大量數據的 fp32 或 fp64 浮點算法,但它不需要嚴格的延遲。功耗高,成本承受能力高。
相當不同的是推理過程。推理通常在 fp8 算法上執行,該算法仍會產生大量數據,但需要關鍵的延遲、低能耗和低成本。
模型訓練的解決方案來自于計算場。它們運行數天,使用大量電力,產生大量熱量,并且獲取、安裝、操作和維護成本高昂。更糟糕的是推理過程,碰壁并阻礙了 GenAI 在邊緣設備上的擴散。
邊緣生成人工智能推理的最新技術
成功的 GenAI 推理硬件加速器必須滿足五個屬性:
petaflops 范圍內的高處理能力和高效率(超過 50%)
低延遲,可在幾秒鐘內提供查詢響應
能耗限制在 50W/Petaflops 或以下
成本實惠,與邊緣應用兼容
現場可編程性可適應軟件更新或升級,以避免工廠進行硬件改造
大多數現有的硬件加速器可以滿足部分要求,但不能滿足全部要求。老牌CPU是最差的選擇,因為執行速度令人無法接受;GPU 在高功耗和延遲不足的情況下提供相當快的速度(因此是訓練的選擇);FPGA 在性能和延遲方面做出了妥協。
完美的設備將是定制/可編程片上系統 (SoC),旨在執行基于變壓器的算法以及其他類型算法的發展。它應該支持合適的內存容量來存儲法學碩士中嵌入的大量數據,并且應該可編程以適應現場升級。
有兩個障礙阻礙了這一目標的實現:內存墻和 CMOS 器件的高能耗。
內存墻
人們在半導體發展歷史的早期就觀察到,處理器性能的進步被內存訪問的缺乏進步所抵消。
隨著時間的推移,兩者之間的差距不斷擴大,迫使處理器等待內存傳送數據的時間越來越長。結果是處理器效率從完全 100% 利用率下降(圖 1)。
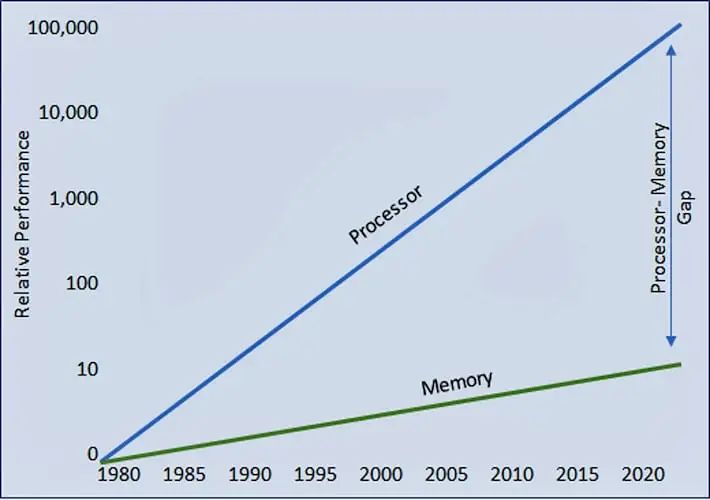
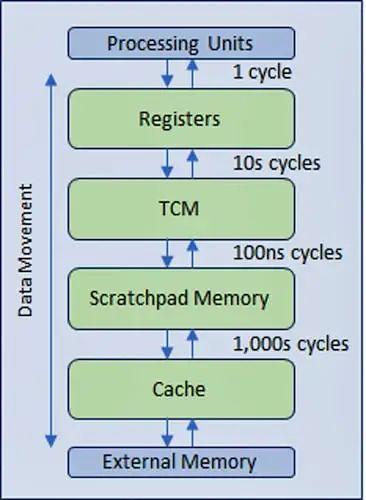
為了緩解效率的下降,業界設計了一種多級分層內存結構,采用更快、更昂貴的內存技術,靠近處理器進行多級緩存,從而最大限度地減少較慢主內存甚至較慢外部內存的流量(圖 2)。
CMOS IC 的能耗
與直覺相反,CMOS IC 的功耗主要由數據移動而非數據處理決定。根據馬克·霍洛維茨教授領導的斯坦福大學研究(表 1),內存訪問的功耗比基本數字邏輯計算消耗的能量高出幾個數量級。
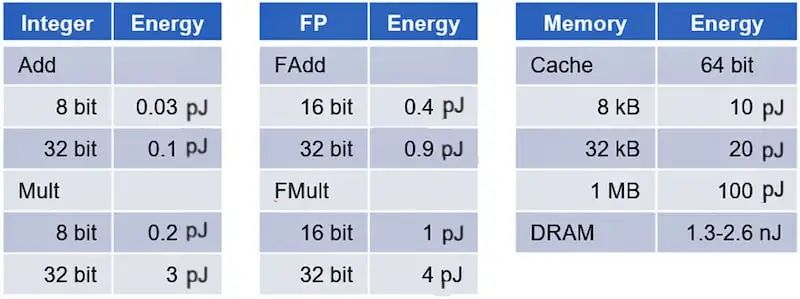
加法器和乘法器的功耗從使用整數運算時的不到一皮焦耳到處理浮點運算時的幾皮焦耳。相比之下,在 DRAM 中訪問數據時,訪問高速緩存中的數據所花費的能量會躍升一個數量級,達到 20-100 皮焦耳,并且會躍升三個數量級,達到超過 1,000 皮焦耳。
GenAI 加速器是以數據移動為主導的設計的典型例子。
內存墻和能耗對延遲和效率的影響
生成式人工智能處理中的內存墻和能耗的影響正變得難以控制。
幾年之內,為 ChatGPT 提供支持的基礎模型 GPT 從 2019 年的 GPT-2 發展到 2020 年的 GPT-3,再到 2022 年的 GPT-3.5,再到目前的 GPT-4。每一代模型的大小和參數(weights, tokens和states)的數量都增加了幾個數量級。
GPT-2 包含 15 億個參數,GPT-3 模型包含 1750 億個參數,最新的 GPT-4 模型將參數規模推至約 1.7 萬億個參數(尚未發布官方數字)。
這些參數的龐大數量不僅迫使內存容量達到 TB 范圍,而且在訓練/推理過程中同時高速訪問它們也會將內存帶寬推至數百 GB/秒(如果不是 TB/秒)。為了進一步加劇這種情況,移動它們會消耗大量的能量。
昂貴的硬件閑置
內存和處理器之間令人畏懼的數據傳輸帶寬以及顯著的功耗壓倒了處理器的效率。最近的分析表明,在尖端硬件上運行 GPT-4 的效率下降至 3% 左右。為運行這些算法而設計的昂貴硬件在 97% 的時間內處于閑置狀態。
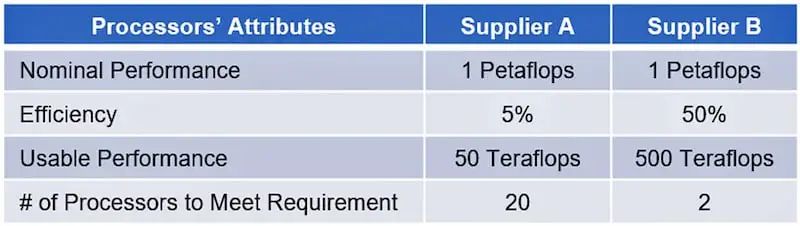
執行效率越低,執行相同任務所需的硬件就越多。例如,假設 1 Petaflops(1,000 Teraflops)的要求可以由兩個供應商滿足。供應商(A 和 B)提供不同的處理效率,分別為 5% 和 50%(表 2)。
那么供應商 A 只能提供 50 Teraflops 的有效處理能力,而不是理論處理能力。供應商 B 將提供 500 Teraflops。為了提供 1 petaflop 的有效計算能力,供應商 A 需要 20 個處理器,但供應商 B 只需 2 個。
例如,一家硅谷初創公司計劃在其超級計算機數據中心使用 22,000 個 Nvidia H100 GPU。粗略計算,22,000 個 H100 GPU 的售價為 8 億美元——這是其最新融資的大部分。該數字不包括其余基礎設施的成本、房地產、能源成本以及本地硬件總擁有成本 (TCO) 中的所有其他因素。
系統復雜性對延遲和效率的影響
另一個例子,基于當前最先進的 GenAI 訓練加速器,將有助于說明這種擔憂。硅谷初創公司的 GPT-4 配置將需要 22,000 個 Nvidia H100 GPU 副本以八位字節的形式部署在HGX H100 或 DGX H100 系統,總共產生 2,750 個系統。
考慮到 GPT-4 包括 96 個解碼器,將它們映射到多個芯片上可能會減輕對延遲的影響。由于 GPT 結構允許順序處理,因此為總共 96 個芯片為每個芯片分配一個解碼器可能是一種合理的設置。
該配置可轉換為 12 個 HGX/DGX H100 系統,不僅對單芯片之間、電路板之間和系統之間移動數據帶來的延遲提出挑戰。使用增量變壓器可以顯著降低處理復雜性,但它需要狀態的處理和存儲,這反過來又增加了要處理的數據量。
底線是,前面提到的 3% 的實施效率是不現實的。當加上系統實現的影響以及相關的較長延遲時,實際應用程序中的實際效率將顯著下降。
綜合來看,GPT-3.5所需的數據量遠不及GPT-4。從商業角度來看,使用類似 GPT-3 的復雜性比 GPT-4 更具吸引力。另一方面是 GPT-4 更準確,如果可以解決硬件挑戰,它會成為首選。
最佳猜測成本分析
讓我們重點關注能夠處理大量查詢的系統的實施成本,例如類似 Google 的每秒 100,000 個查詢的量。
使用當前最先進的硬件,可以合理地假設總擁有成本(包括購置成本、系統運營和維護成本)約為 1 萬億美元。據記錄,這大約相當于世界第八大經濟體意大利 2021 年國內生產總值 (GDP) 的一半。
ChatGPT 對每次查詢成本的影響使其在商業上具有挑戰性。摩根士丹利估計,2022 年 Google 搜索查詢(3.3 萬億次查詢)的每次查詢成本為 0.2 英鎊(被視為基準)。同一分析表明,ChatGPT-3 上的每次查詢成本在 3 到 14 歐元之間,比基準高 15-70 倍。
半導體行業正在積極尋找應對成本/查詢挑戰的解決方案。盡管所有嘗試都受到歡迎,但解決方案必須來自新穎的芯片架構,該架構將打破內存墻并大幅降低功耗。
-
處理器
+關注
關注
68文章
19808瀏覽量
233561 -
人工智能
+關注
關注
1804文章
48716瀏覽量
246523 -
語言模型
+關注
關注
0文章
558瀏覽量
10673
原文標題:推理芯片的最大挑戰
文章出處:【微信號:TenOne_TSMC,微信公眾號:芯片半導體】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
AI推理的存儲,看好SRAM?
谷歌第七代TPU Ironwood深度解讀:AI推理時代的硬件革命

谷歌新一代 TPU 芯片 Ironwood:助力大規模思考與推理的 AI 模型新引擎?
詳解 LLM 推理模型的現狀

黑芝麻智能芯片加速DeepSeek模型推理

Neuchips展示大模型推理ASIC芯片

高效大模型的推理綜述

當前主流的大模型對于底層推理芯片提出了哪些挑戰
AMD助力HyperAccel開發全新AI推理服務器






 工商網監
工商網監
評論