") 谷歌證實大模型能頓悟,特殊方法能讓模型快速泛化,或?qū)⒋蚱拼竽P秃谙?/h1>
谷歌證實大模型能頓悟,特殊方法能讓模型快速泛化,或?qū)⒋蚱拼竽P秃谙?/h1>

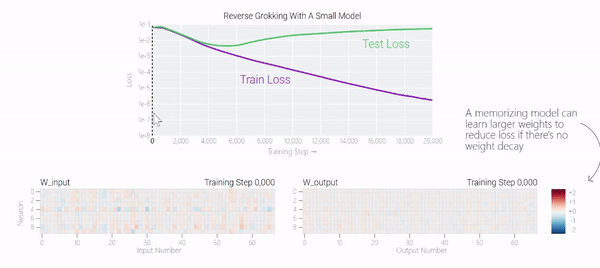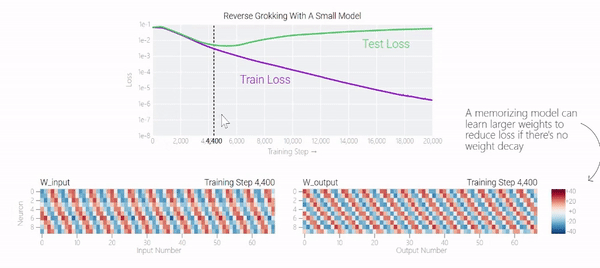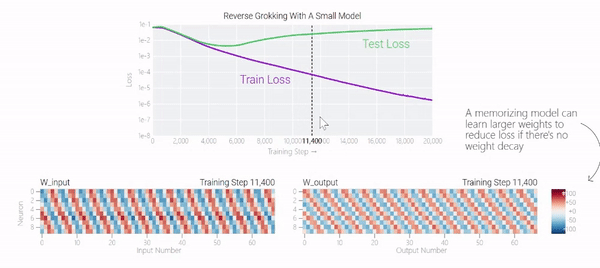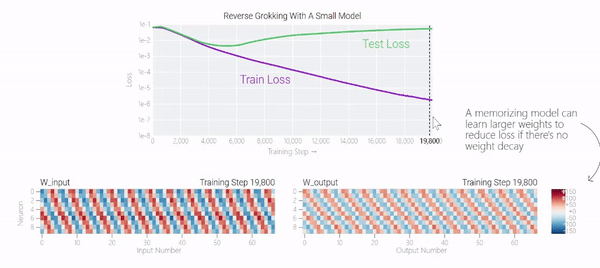
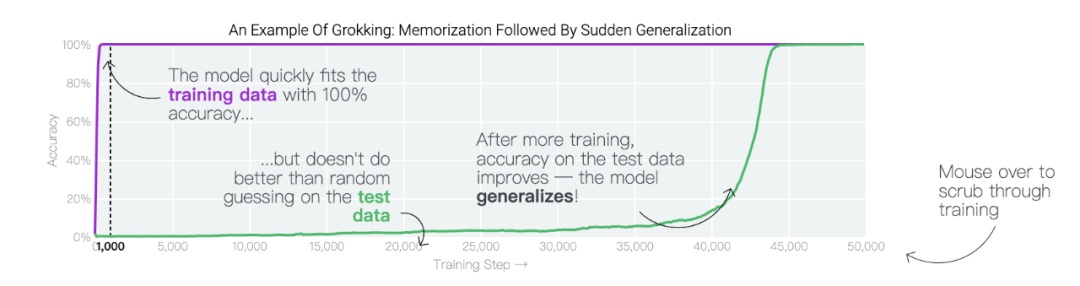
在特定情況下,人工智能模型會超越訓(xùn)練數(shù)據(jù)進(jìn)行泛化。在人工智能研究中,這種現(xiàn)象被稱為「頓悟」,而谷歌現(xiàn)在正在提供對最近發(fā)現(xiàn)的深入了解。在訓(xùn)練過程中,人工智能模型有時似乎會突然「理解」一個問題,盡管它們只是記住了訓(xùn)練數(shù)據(jù)。在人工智能研究中,這種現(xiàn)象被稱為「頓悟」,這是美國作家Robert A. Heinlein創(chuàng)造的一個新詞,主要在計算機文化中用來描述一種深刻的理解。當(dāng)人工智能模型發(fā)生頓悟時,模型會突然從簡單地復(fù)制訓(xùn)練數(shù)據(jù)轉(zhuǎn)變?yōu)榘l(fā)現(xiàn)可推廣的解決方案——因此,你可能會得到一個實際上構(gòu)建問題模型以進(jìn)行預(yù)測的人工智能系統(tǒng),而不僅僅是一個隨機的模仿者。谷歌團(tuán)隊:「頓悟」是一種「有條件的現(xiàn)象」。「頓悟」在希望更好地理解神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)方式的人工智能研究人員中引起了很大的興趣。這是因為「頓悟」表明模型在記憶和泛化時可能具有不同的學(xué)習(xí)動態(tài),了解這些動態(tài)可能為神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)提供重要見解。盡管最初是在單個任務(wù)上訓(xùn)練的小型模型中觀察到,但谷歌的最新研究表明,頓悟也可以發(fā)生在較大的模型中,并且在某些情況下可以被可靠地預(yù)測。然而,在大型模型中檢測這種頓悟動態(tài)仍然是一個挑戰(zhàn)。

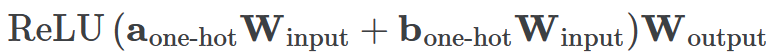 一個具有24個神經(jīng)元的單層MLP。模型的所有權(quán)重如下面的熱圖所示;通過將鼠標(biāo)懸停在上面的線性圖上,可以看到它們在訓(xùn)練過程中如何變化。
一個具有24個神經(jīng)元的單層MLP。模型的所有權(quán)重如下面的熱圖所示;通過將鼠標(biāo)懸停在上面的線性圖上,可以看到它們在訓(xùn)練過程中如何變化。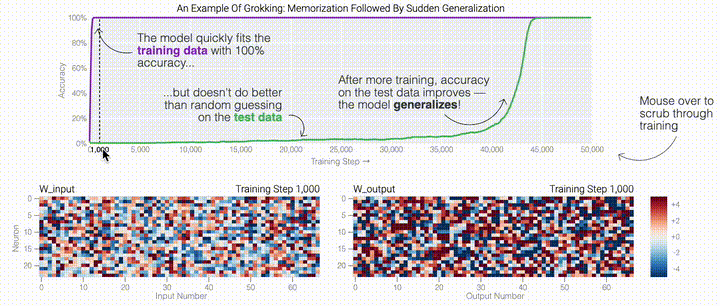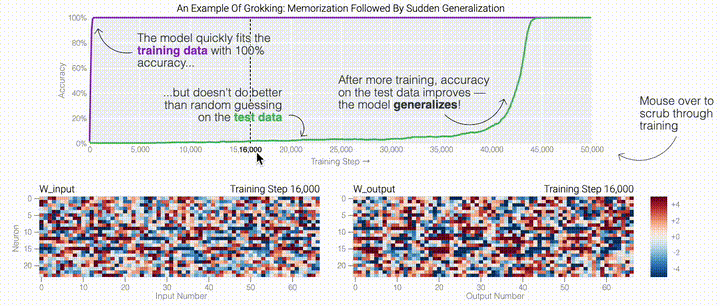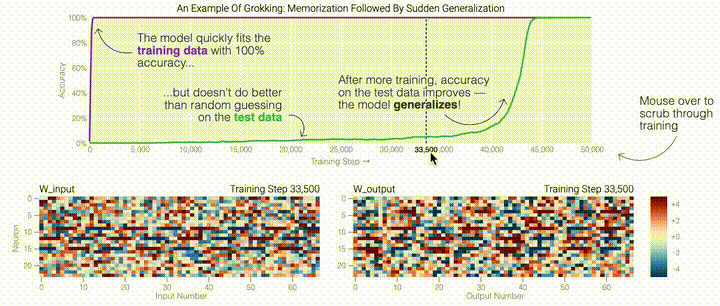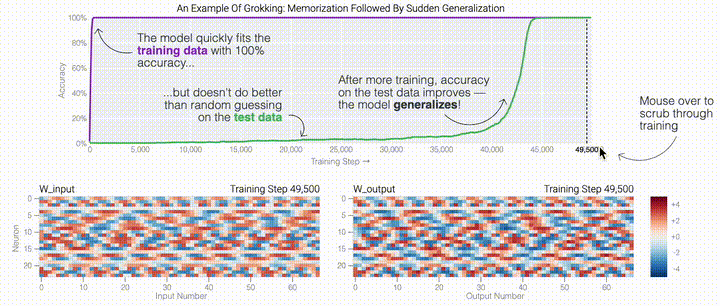 模型通過選擇與輸入a和b對應(yīng)的兩列
模型通過選擇與輸入a和b對應(yīng)的兩列 ,然后將它們相加以創(chuàng)建一個包含24個獨立數(shù)字的向量來進(jìn)行預(yù)測。接下來,它將向量中的所有負(fù)數(shù)設(shè)置為0,最后輸出與更新向量最接近的
,然后將它們相加以創(chuàng)建一個包含24個獨立數(shù)字的向量來進(jìn)行預(yù)測。接下來,它將向量中的所有負(fù)數(shù)設(shè)置為0,最后輸出與更新向量最接近的 列。模型的權(quán)重最初非常嘈雜,但隨著測試數(shù)據(jù)上的準(zhǔn)確性提高和模型逐漸開始泛化,它們開始展現(xiàn)出周期性的模式。在訓(xùn)練結(jié)束時,每個神經(jīng)元,也就是熱圖的每一行在輸入數(shù)字從0增加到66時會多次在高值和低值之間循環(huán)。如果研究人員根據(jù)神經(jīng)元在訓(xùn)練結(jié)束時的循環(huán)頻率將其分組,并將每個神經(jīng)元分別繪制成一條單獨的線,會更容易看出產(chǎn)生的變化。
列。模型的權(quán)重最初非常嘈雜,但隨著測試數(shù)據(jù)上的準(zhǔn)確性提高和模型逐漸開始泛化,它們開始展現(xiàn)出周期性的模式。在訓(xùn)練結(jié)束時,每個神經(jīng)元,也就是熱圖的每一行在輸入數(shù)字從0增加到66時會多次在高值和低值之間循環(huán)。如果研究人員根據(jù)神經(jīng)元在訓(xùn)練結(jié)束時的循環(huán)頻率將其分組,并將每個神經(jīng)元分別繪制成一條單獨的線,會更容易看出產(chǎn)生的變化。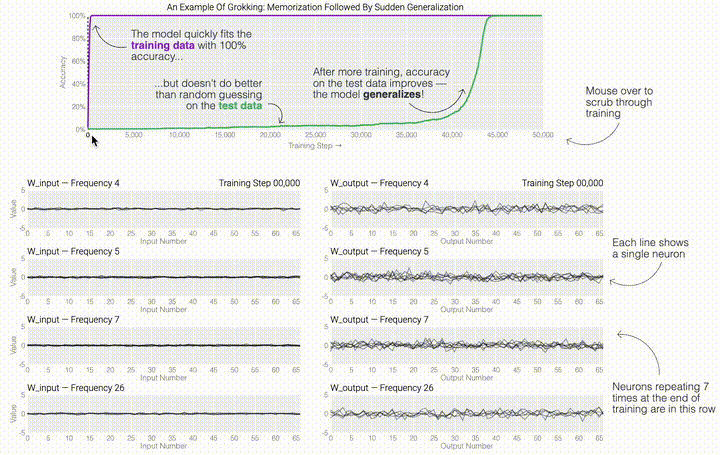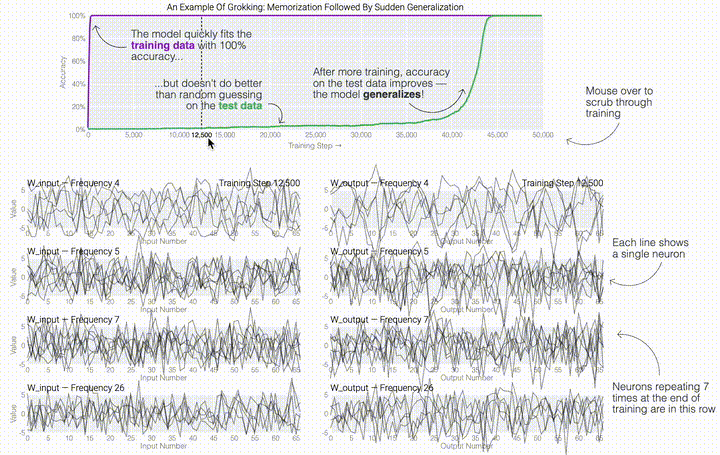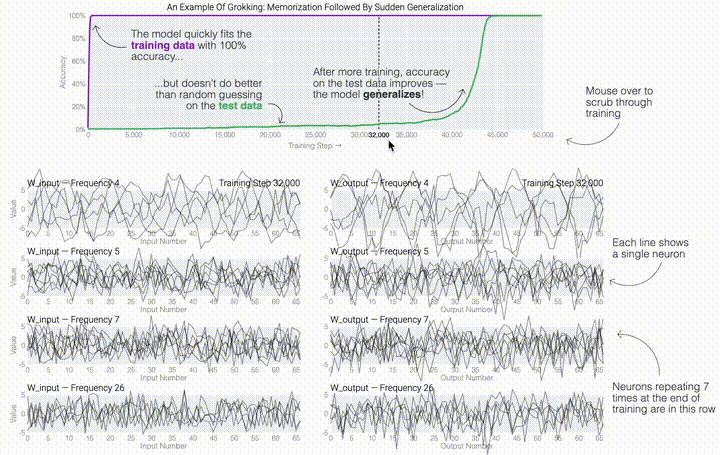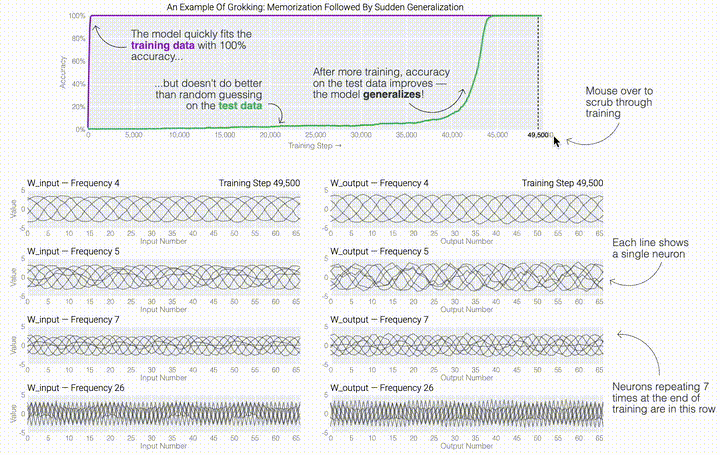 這些周期性的模式表明模型正在學(xué)習(xí)某種數(shù)學(xué)結(jié)構(gòu);當(dāng)模型開始計算測試樣本時出現(xiàn)這種現(xiàn)象,意味著模型開始出現(xiàn)泛化了。但是為什么模型會拋開記憶的解決方案?而泛化的解決方案又是什么呢?
這些周期性的模式表明模型正在學(xué)習(xí)某種數(shù)學(xué)結(jié)構(gòu);當(dāng)模型開始計算測試樣本時出現(xiàn)這種現(xiàn)象,意味著模型開始出現(xiàn)泛化了。但是為什么模型會拋開記憶的解決方案?而泛化的解決方案又是什么呢?

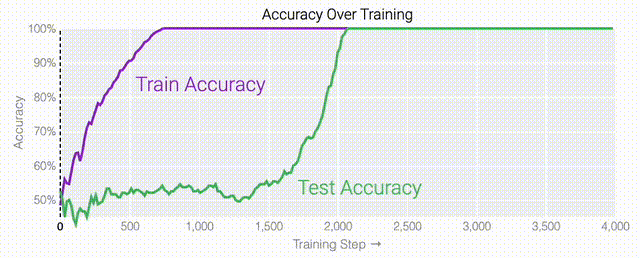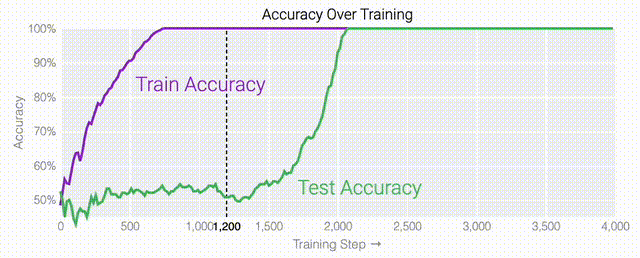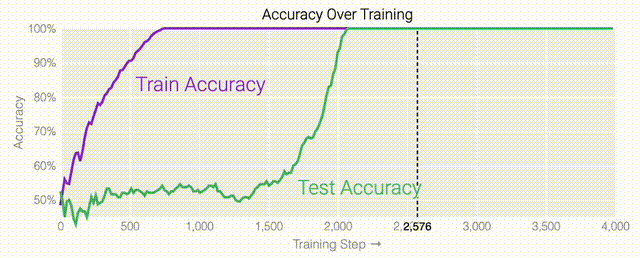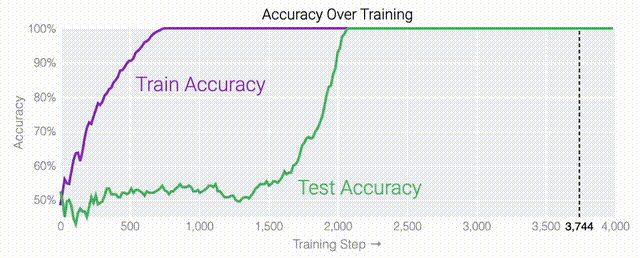 下面的權(quán)重圖標(biāo)顯示,在記憶訓(xùn)練數(shù)據(jù)時,模型看起來密集而嘈雜,有許多數(shù)值很大的權(quán)重(顯示為深紅色和藍(lán)色方塊)分布在數(shù)列靠后的位置,表明模型正在使用所有的數(shù)字進(jìn)行預(yù)測。隨著模型泛化后獲得了完美的測試數(shù)據(jù)準(zhǔn)確性,研究人員看到,與干擾數(shù)字相關(guān)的所有權(quán)重都變?yōu)榛疑捣浅5停P蜋?quán)重全部集中在前三位數(shù)字上了。這與研究人員預(yù)期的泛化結(jié)構(gòu)相一致。
下面的權(quán)重圖標(biāo)顯示,在記憶訓(xùn)練數(shù)據(jù)時,模型看起來密集而嘈雜,有許多數(shù)值很大的權(quán)重(顯示為深紅色和藍(lán)色方塊)分布在數(shù)列靠后的位置,表明模型正在使用所有的數(shù)字進(jìn)行預(yù)測。隨著模型泛化后獲得了完美的測試數(shù)據(jù)準(zhǔn)確性,研究人員看到,與干擾數(shù)字相關(guān)的所有權(quán)重都變?yōu)榛疑捣浅5停P蜋?quán)重全部集中在前三位數(shù)字上了。這與研究人員預(yù)期的泛化結(jié)構(gòu)相一致。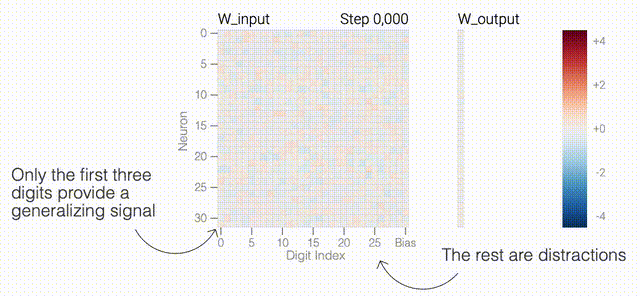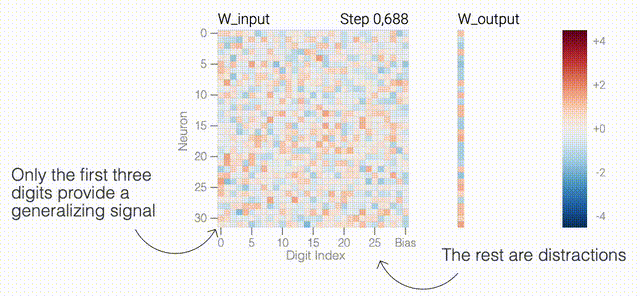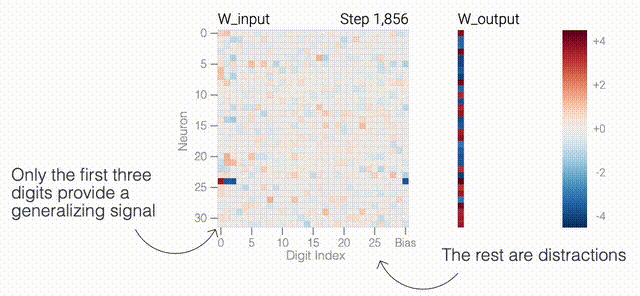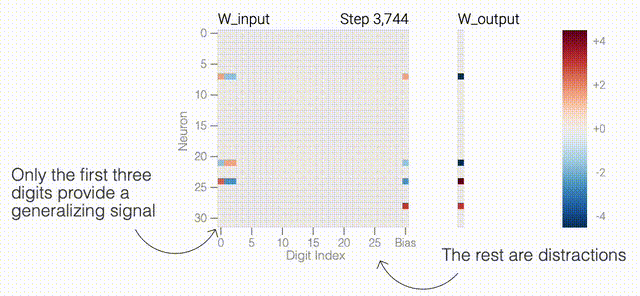 通過這個簡化的例子,更容易理解為什么會發(fā)生這種情況:其實在訓(xùn)練過程中,研究人員的要求是模型要同時完成兩個目標(biāo),一個是盡量高概率地輸出正確的數(shù)字(稱為最小化損失),另一個是使用盡量小的全權(quán)重來完成輸出(稱為權(quán)重衰減)。在模型泛化之前,訓(xùn)練損失略微增加(輸出準(zhǔn)確略微降低),因為它在減小與輸出正確標(biāo)簽相關(guān)的損失的同時,也在降低權(quán)重,從而獲得盡可能小的權(quán)重。
通過這個簡化的例子,更容易理解為什么會發(fā)生這種情況:其實在訓(xùn)練過程中,研究人員的要求是模型要同時完成兩個目標(biāo),一個是盡量高概率地輸出正確的數(shù)字(稱為最小化損失),另一個是使用盡量小的全權(quán)重來完成輸出(稱為權(quán)重衰減)。在模型泛化之前,訓(xùn)練損失略微增加(輸出準(zhǔn)確略微降低),因為它在減小與輸出正確標(biāo)簽相關(guān)的損失的同時,也在降低權(quán)重,從而獲得盡可能小的權(quán)重。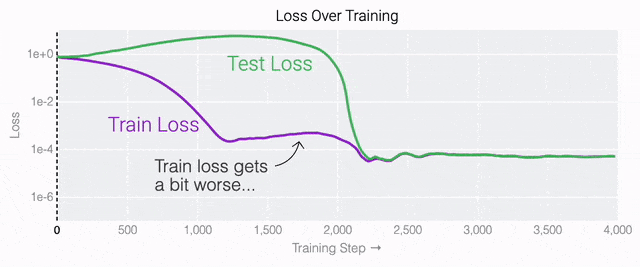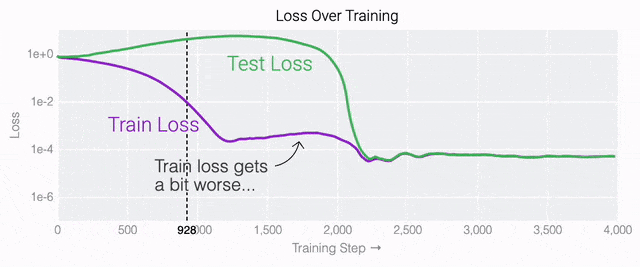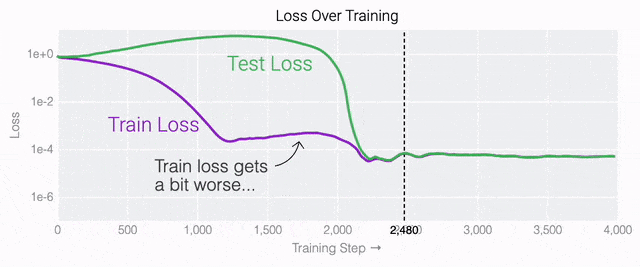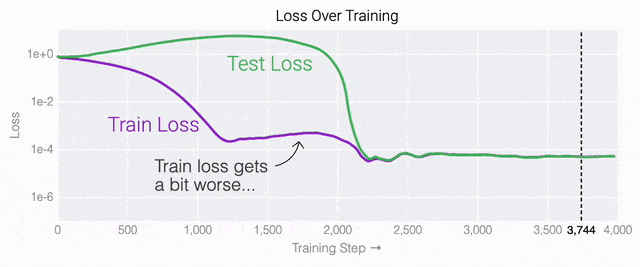 而測試數(shù)據(jù)損失的急劇下降,讓模型看起來像是似乎突然開始了泛化,但其實不是,這個過程在之前就已經(jīng)在進(jìn)行了。但是,如果觀察記錄模型在訓(xùn)練過程中的權(quán)重,大部分權(quán)重是平均分布在這兩個目標(biāo)之間的。當(dāng)與干擾數(shù)字相關(guān)的最后一組權(quán)重被權(quán)重衰減這個目標(biāo)「修剪」掉時,泛化馬上就發(fā)生了。
而測試數(shù)據(jù)損失的急劇下降,讓模型看起來像是似乎突然開始了泛化,但其實不是,這個過程在之前就已經(jīng)在進(jìn)行了。但是,如果觀察記錄模型在訓(xùn)練過程中的權(quán)重,大部分權(quán)重是平均分布在這兩個目標(biāo)之間的。當(dāng)與干擾數(shù)字相關(guān)的最后一組權(quán)重被權(quán)重衰減這個目標(biāo)「修剪」掉時,泛化馬上就發(fā)生了。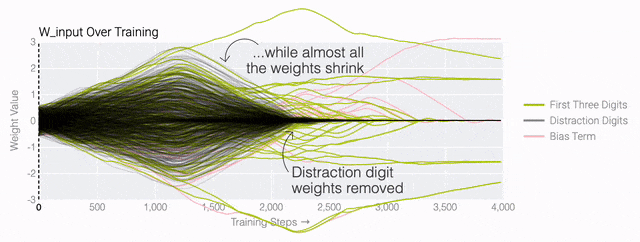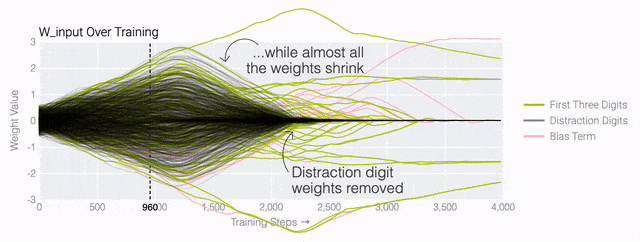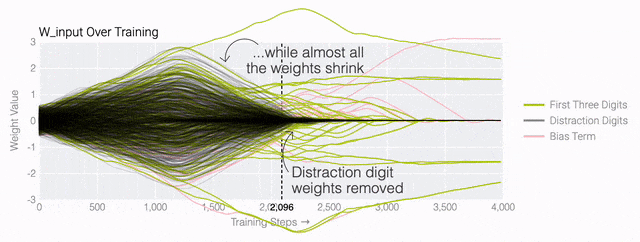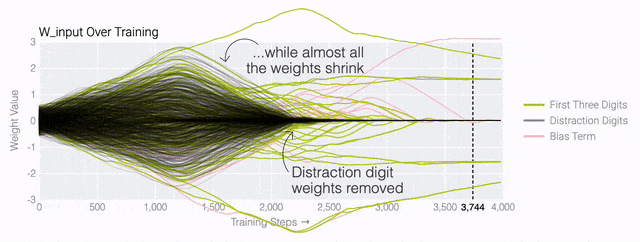 ?
?
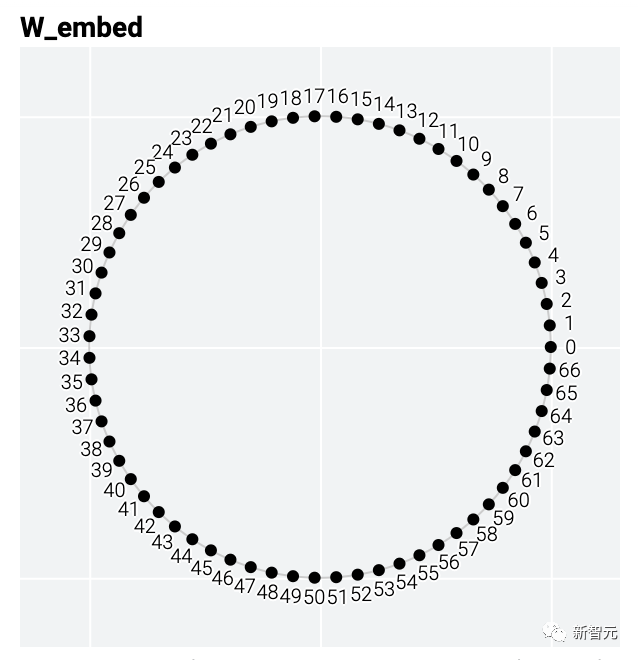 模型只用了5個神經(jīng)元就完美地找到了解決方案。
模型只用了5個神經(jīng)元就完美地找到了解決方案。 然后還是回到a+b mod 67的問題上,研究人員從頭訓(xùn)練模型,沒有內(nèi)置周期,這個模型有很多頻率。
然后還是回到a+b mod 67的問題上,研究人員從頭訓(xùn)練模型,沒有內(nèi)置周期,這個模型有很多頻率。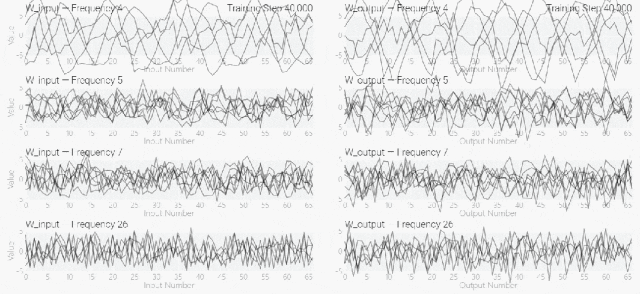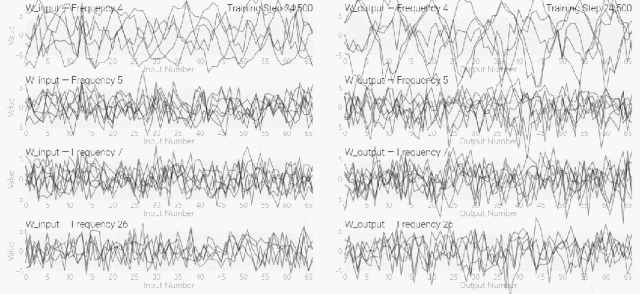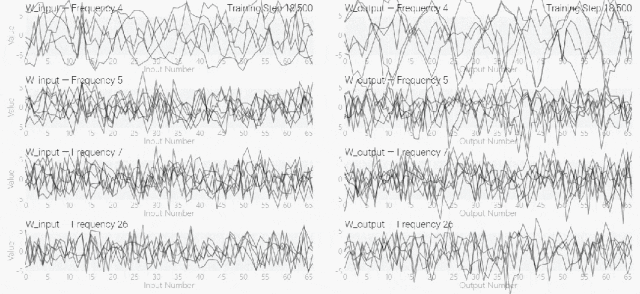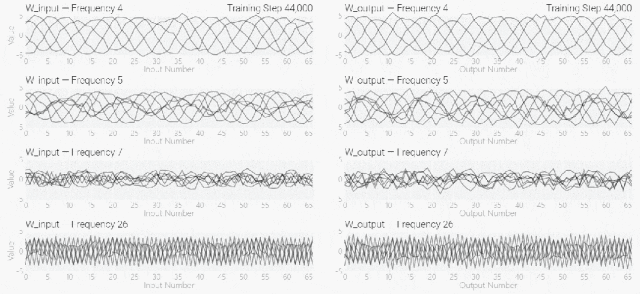 然后研究人員使用離散傅里葉變換分離出頻率,會分離出輸入數(shù)據(jù)中的周期性模式。
然后研究人員使用離散傅里葉變換分離出頻率,會分離出輸入數(shù)據(jù)中的周期性模式。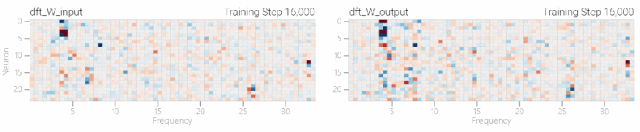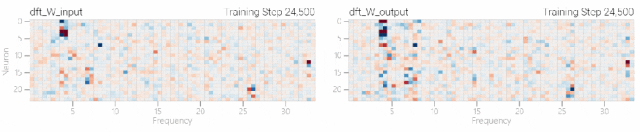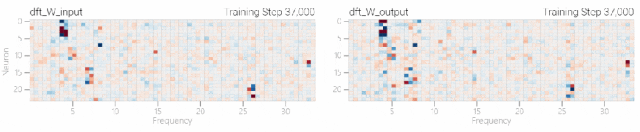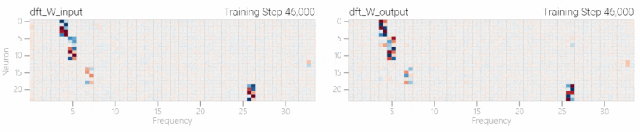 而結(jié)果就和之前在數(shù)列中數(shù)1的任務(wù)一樣,隨著模型的泛化,權(quán)重會迅速衰減到很低。而且在不同的頻率任務(wù)中,模型也都出現(xiàn)了「頓悟」。
而結(jié)果就和之前在數(shù)列中數(shù)1的任務(wù)一樣,隨著模型的泛化,權(quán)重會迅速衰減到很低。而且在不同的頻率任務(wù)中,模型也都出現(xiàn)了「頓悟」。

 甚至可以找到模型開始泛化的超參數(shù),然后切換到記憶,然后再切換回泛化!
甚至可以找到模型開始泛化的超參數(shù),然后切換到記憶,然后再切換回泛化!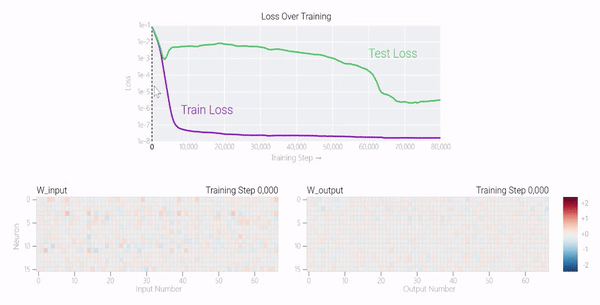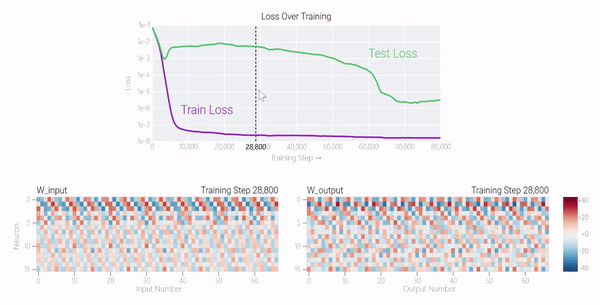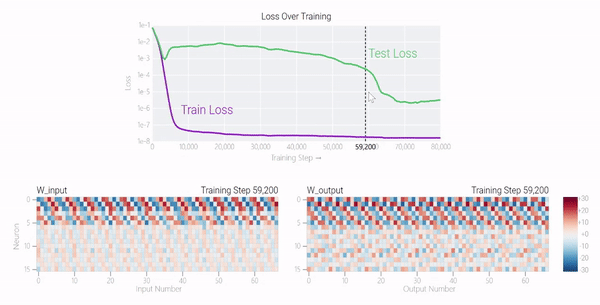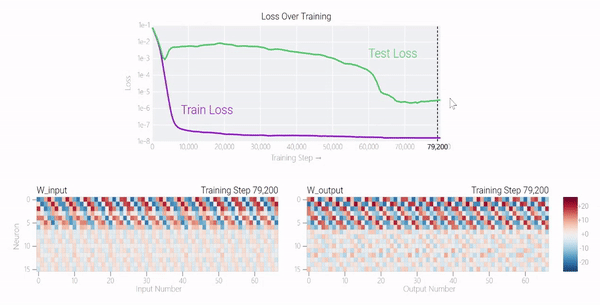
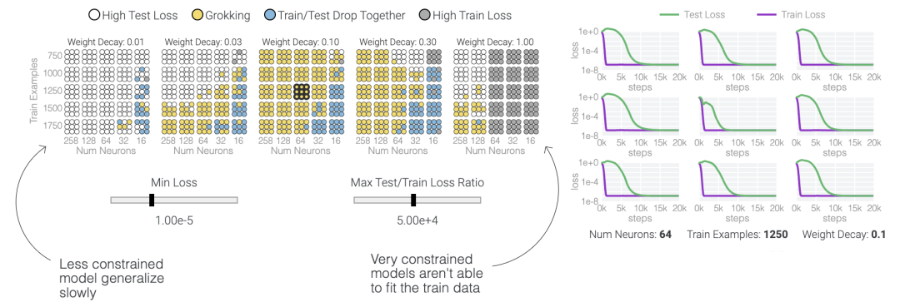
在這篇文章中,谷歌研究人員提供了有關(guān)這一現(xiàn)象和當(dāng)前研究的視覺展示。該團(tuán)隊對超過1000個不同訓(xùn)練參數(shù)的小型模型進(jìn)行了算法任務(wù)的訓(xùn)練,展示了「有條件的現(xiàn)象——如果模型大小、權(quán)重衰減、數(shù)據(jù)大小和其他超參數(shù)不合適,這種現(xiàn)象會消失。」
了解「頓悟」可能會改進(jìn)大型AI模型
根據(jù)該團(tuán)隊的說法,仍然有許多未解之謎,例如哪些模型限制會可靠地引起「頓悟」,為什么模型最初更喜歡記住訓(xùn)練數(shù)據(jù),以及研究中用于研究小型模型中這一現(xiàn)象的方法在大型模型中是否適用。對「頓悟」的理解進(jìn)步可能會為未來大型AI模型的設(shè)計提供信息,使它們能夠可靠且快速地超越訓(xùn)練數(shù)據(jù)。

頓悟模加法
模加法是檢測「頓悟」最好的方法。(模加法指的是兩個數(shù)據(jù)相加,如果合大于某一個值,結(jié)果就自動回歸某一個值。以12小時計時為例,時間相加超過12點之后就會自動歸零,就是一個典型的模加法。)
一個具有24個神經(jīng)元的單層MLP。模型的所有權(quán)重如下面的熱圖所示;通過將鼠標(biāo)懸停在上面的線性圖上,可以看到它們在訓(xùn)練過程中如何變化。模型通過選擇與輸入a和b對應(yīng)的兩列,然后將它們相加以創(chuàng)建一個包含24個獨立數(shù)字的向量來進(jìn)行預(yù)測。接下來,它將向量中的所有負(fù)數(shù)設(shè)置為0,最后輸出與更新向量最接近的列。模型的權(quán)重最初非常嘈雜,但隨著測試數(shù)據(jù)上的準(zhǔn)確性提高和模型逐漸開始泛化,它們開始展現(xiàn)出周期性的模式。在訓(xùn)練結(jié)束時,每個神經(jīng)元,也就是熱圖的每一行在輸入數(shù)字從0增加到66時會多次在高值和低值之間循環(huán)。如果研究人員根據(jù)神經(jīng)元在訓(xùn)練結(jié)束時的循環(huán)頻率將其分組,并將每個神經(jīng)元分別繪制成一條單獨的線,會更容易看出產(chǎn)生的變化。這些周期性的模式表明模型正在學(xué)習(xí)某種數(shù)學(xué)結(jié)構(gòu);當(dāng)模型開始計算測試樣本時出現(xiàn)這種現(xiàn)象,意味著模型開始出現(xiàn)泛化了。但是為什么模型會拋開記憶的解決方案?而泛化的解決方案又是什么呢?
在0和1的數(shù)列中訓(xùn)練模型泛化
同時解決這兩個問題確實很困難。研究人員可以設(shè)計一個更簡單的任務(wù),其中研究人員知道泛化解決方案應(yīng)該是什么樣的,然后嘗試?yán)斫饽P妥罱K是如何學(xué)習(xí)它的。研究人員又設(shè)計了一個方案,他們先隨機生成30個由0和1組成的數(shù)字組成一個數(shù)列,然后訓(xùn)練一個模型去預(yù)測數(shù)列中前三個數(shù)字中是否有奇數(shù)個1,如果有奇數(shù)個1,輸出就為1,否則輸出為0。例如,010110010110001010111001001011等于1 。000110010110001010111001001011等于0。基本上這就是稍微復(fù)雜一些的異或運算,略微帶有一些干擾噪聲。而如果一個模型產(chǎn)生了泛化能力,應(yīng)該就只關(guān)注序列的前三位數(shù)字進(jìn)行輸出;如果模型是在記憶訓(xùn)練數(shù)據(jù),它就會使用到后邊的干擾數(shù)字。研究人員的模型仍然是一個單層MLP,使用固定的1,200個序列進(jìn)行訓(xùn)練。起初,只有訓(xùn)練數(shù)據(jù)準(zhǔn)確性增加了,說明模型正在記憶訓(xùn)練數(shù)據(jù)。與模算數(shù)一樣,測試數(shù)據(jù)的準(zhǔn)確性一開始基本上是隨機的。但是模型學(xué)習(xí)了一個泛化解決方案后,測試數(shù)據(jù)的準(zhǔn)確性就急劇上升。下面的權(quán)重圖標(biāo)顯示,在記憶訓(xùn)練數(shù)據(jù)時,模型看起來密集而嘈雜,有許多數(shù)值很大的權(quán)重(顯示為深紅色和藍(lán)色方塊)分布在數(shù)列靠后的位置,表明模型正在使用所有的數(shù)字進(jìn)行預(yù)測。隨著模型泛化后獲得了完美的測試數(shù)據(jù)準(zhǔn)確性,研究人員看到,與干擾數(shù)字相關(guān)的所有權(quán)重都變?yōu)榛疑捣浅5停P蜋?quán)重全部集中在前三位數(shù)字上了。這與研究人員預(yù)期的泛化結(jié)構(gòu)相一致。通過這個簡化的例子,更容易理解為什么會發(fā)生這種情況:其實在訓(xùn)練過程中,研究人員的要求是模型要同時完成兩個目標(biāo),一個是盡量高概率地輸出正確的數(shù)字(稱為最小化損失),另一個是使用盡量小的全權(quán)重來完成輸出(稱為權(quán)重衰減)。在模型泛化之前,訓(xùn)練損失略微增加(輸出準(zhǔn)確略微降低),因為它在減小與輸出正確標(biāo)簽相關(guān)的損失的同時,也在降低權(quán)重,從而獲得盡可能小的權(quán)重。而測試數(shù)據(jù)損失的急劇下降,讓模型看起來像是似乎突然開始了泛化,但其實不是,這個過程在之前就已經(jīng)在進(jìn)行了。但是,如果觀察記錄模型在訓(xùn)練過程中的權(quán)重,大部分權(quán)重是平均分布在這兩個目標(biāo)之間的。當(dāng)與干擾數(shù)字相關(guān)的最后一組權(quán)重被權(quán)重衰減這個目標(biāo)「修剪」掉時,泛化馬上就發(fā)生了。
?何時發(fā)生頓悟?
值得注意的是,「頓悟」是一種偶然現(xiàn)象——如果模型大小、權(quán)重衰減、數(shù)據(jù)大小以及其他超參數(shù)不合適,它就不會出現(xiàn)。當(dāng)權(quán)重衰減過小時,模型無法擺脫對訓(xùn)練數(shù)據(jù)的過擬合。增加更多的權(quán)重衰減會推動模型在記憶后進(jìn)行泛化。進(jìn)一步增加權(quán)重衰減會導(dǎo)致測試數(shù)據(jù)和訓(xùn)練數(shù)據(jù)的不準(zhǔn)確率提高;模型直接進(jìn)入泛化階段。當(dāng)權(quán)重衰減過大時,模型將無法學(xué)到任何東西。在下面的內(nèi)容中,研究人員使用不同的超參數(shù)在「1和0」任務(wù)上訓(xùn)練了一千多個模型。因為訓(xùn)練是有噪聲的,所以每組超參數(shù)都訓(xùn)練了九個模型。

五個神經(jīng)元的模加法
舉個例子,模加法問題a+b mod 67是周期性的。從數(shù)學(xué)上講,可以將式子的和看成是將a和b繞在一個圓圈上來表示。泛化模型的權(quán)重也具有周期性,也就是說,解決方案可能也會有周期性。
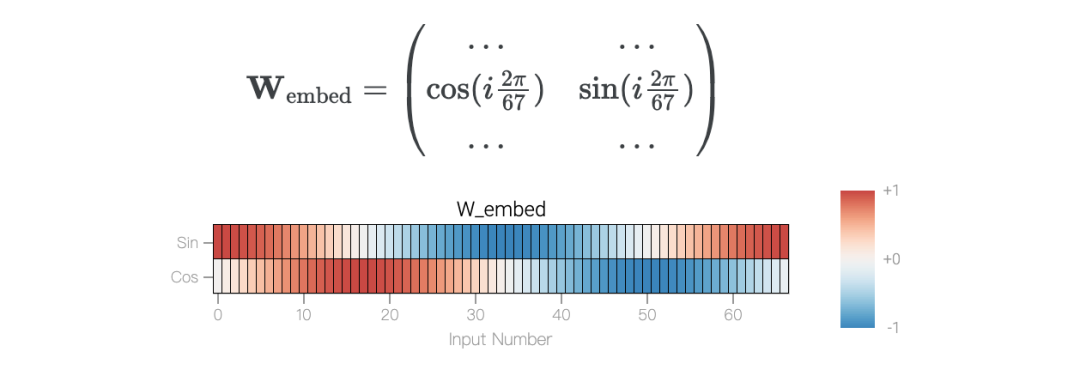
模型只用了5個神經(jīng)元就完美地找到了解決方案。然后還是回到a+b mod 67的問題上,研究人員從頭訓(xùn)練模型,沒有內(nèi)置周期,這個模型有很多頻率。然后研究人員使用離散傅里葉變換分離出頻率,會分離出輸入數(shù)據(jù)中的周期性模式。而結(jié)果就和之前在數(shù)列中數(shù)1的任務(wù)一樣,隨著模型的泛化,權(quán)重會迅速衰減到很低。而且在不同的頻率任務(wù)中,模型也都出現(xiàn)了「頓悟」。
進(jìn)一步的問題
什么原因?qū)е路夯某霈F(xiàn)?雖然研究人員現(xiàn)在對用單層MLP解決模加法的機制以及它們在訓(xùn)練過程中出現(xiàn)的原因有了深入的了解,但仍然存在許多關(guān)于記憶和泛化的有趣的懸而未決的問題。從廣義上講,權(quán)重衰減確實會導(dǎo)致多種模型不再記憶訓(xùn)練數(shù)據(jù) 。其他有助于避免過度擬合的技術(shù)包括 dropout、較小的模型,甚至數(shù)值不穩(wěn)定的優(yōu)化算法 。這些方法以復(fù)雜、非線性的方式相互作用,使得很難預(yù)先預(yù)測最終什么原因和方式會導(dǎo)致泛化。
為什么記憶比概括更容易?
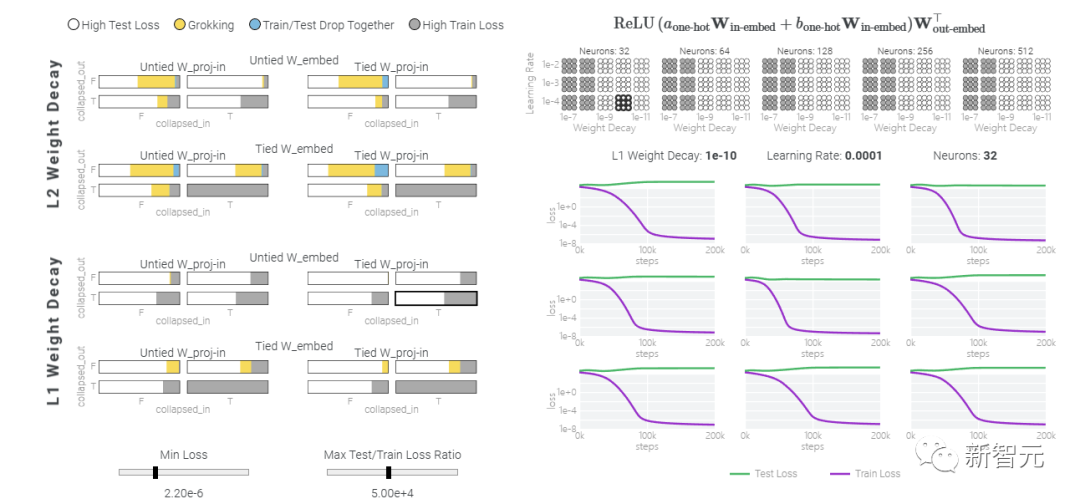
一種理論:記憶訓(xùn)練數(shù)據(jù)集的解決方法可能比泛化解決方法多得多。因此從統(tǒng)計上看,記憶應(yīng)該更有可能先發(fā)生。有研究表明泛化與結(jié)構(gòu)良好的表示相關(guān)。然而,這不是必要條件;一些沒有對稱輸入的 MLP 變體在求解模加法時學(xué)習(xí)的「循環(huán)」表示較少 。研究人員還觀察到,結(jié)構(gòu)良好的表示并不是泛化的充分條件。比如這個小模型(沒有權(quán)重衰減的情況下訓(xùn)練)開始泛化,然后切換到使用周期性嵌入進(jìn)行記憶。甚至可以找到模型開始泛化的超參數(shù),然后切換到記憶,然后再切換回泛化!而較大的模型呢?
首先,之前的研究證實了小型Transformer和MLP算法任務(wù)中的頓悟現(xiàn)象。涉及特定超參數(shù)范圍內(nèi)的圖像、文本和表格數(shù)據(jù)的更復(fù)雜的任務(wù)也出現(xiàn)了頓悟研究人員認(rèn)為:1)訓(xùn)練具有更多歸納偏差和更少移動部件的更簡單模型,2)用它們來解釋更大模型難以理解的部分是如何工作的3)根據(jù)需要重復(fù)。都可以有效幫助理解更大的模型。而且本文中這種機制化的可解釋性方法可能有助于識別模式,從而使神經(jīng)網(wǎng)絡(luò)所學(xué)算法的研究變得容易,甚至有自動化的潛力。參考資料:https://pair.withgoogle.com/explorables/grokking
原文標(biāo)題:谷歌證實大模型能頓悟,特殊方法能讓模型快速泛化,或?qū)⒋蚱拼竽P秃谙?/p>
文章出處:【微信公眾號:智能感知與物聯(lián)網(wǎng)技術(shù)研究所】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
聲明:本文內(nèi)容及配圖由入駐作者撰寫或者入駐合作網(wǎng)站授權(quán)轉(zhuǎn)載。文章觀點僅代表作者本人,不代表電子發(fā)燒友網(wǎng)立場。文章及其配圖僅供工程師學(xué)習(xí)之用,如有內(nèi)容侵權(quán)或者其他違規(guī)問題,請聯(lián)系本站處理。
舉報投訴
-
物聯(lián)網(wǎng)
+關(guān)注
關(guān)注
2927文章
45875瀏覽量
387963
原文標(biāo)題:谷歌證實大模型能頓悟,特殊方法能讓模型快速泛化,或?qū)⒋蚱拼竽P秃谙?/p>
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯(lián)網(wǎng)技術(shù)研究所】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
熱點推薦
FA模型訪問Stage模型DataShareExtensionAbility說明
FA模型訪問Stage模型DataShareExtensionAbility
概述
無論FA模型還是Stage模型,數(shù)據(jù)讀寫功能都包含客戶端和服務(wù)端兩部分。
FA
發(fā)表于 06-04 07:53
如何將一個FA模型開發(fā)的聲明式范式應(yīng)用切換到Stage模型
模型切換概述
本文介紹如何將一個FA模型開發(fā)的聲明式范式應(yīng)用切換到Stage模型,您需要完成如下動作:
工程切換:新建一個Stage模型
發(fā)表于 06-04 06:22
如何使用Docker部署大模型
隨著深度學(xué)習(xí)和大模型的快速發(fā)展,如何高效地部署這些模型成為了一個重要的挑戰(zhàn)。Docker 作為一種輕量級的容器化技術(shù),能夠將
KaihongOS操作系統(tǒng)FA模型與Stage模型介紹
KaihongOS中提供了不同的開發(fā)方式和架構(gòu)選擇,Stage模型因其在分布式應(yīng)用開發(fā)中的優(yōu)勢而被推薦使用。
說明:KaihongOS文檔中心中應(yīng)用開發(fā)(開發(fā)準(zhǔn)備、快速入門、進(jìn)階提高模塊中的示例代碼均基于Stage模型。)
發(fā)表于 04-24 07:27
將YOLOv4模型轉(zhuǎn)換為IR的說明,無法將模型轉(zhuǎn)換為TensorFlow2格式怎么解決?
遵照 將 YOLOv4 模型轉(zhuǎn)換為 IR 的 說明,但無法將模型轉(zhuǎn)換為 TensorFlow2* 格式。
將 YOLOv4 darknet
發(fā)表于 03-07 07:14
【「基于大模型的RAG應(yīng)用開發(fā)與優(yōu)化」閱讀體驗】+大模型微調(diào)技術(shù)解讀
重復(fù)項或使用編輯距離算法比較文本相似度。數(shù)據(jù)標(biāo)注:高質(zhì)量的數(shù)據(jù)標(biāo)注直接影響模型的性能。標(biāo)注過程應(yīng)遵循明確標(biāo)注規(guī)則、選擇合適的標(biāo)注工具、進(jìn)行多輪審核和質(zhì)量控制等原則。數(shù)據(jù)增強:提高模型泛
發(fā)表于 01-14 16:51
【「大模型啟示錄」閱讀體驗】營銷領(lǐng)域大模型的應(yīng)用
解目標(biāo)市場,從而制定更有效的營銷策略。
大模型擅長分析,可以非常好的提煉IP,為決策者提供輔助參考。
基于消費者的歷史數(shù)據(jù)和行為模式,大模型能夠提供個性化的產(chǎn)品或服務(wù)推薦。這種個性
發(fā)表于 12-24 12:48
AI模型部署邊緣設(shè)備的奇妙之旅:目標(biāo)檢測模型
介紹了如何使用分類任務(wù)進(jìn)行手寫數(shù)字的分類。相信大家腦海中可能會產(chǎn)生如下疑問:
數(shù)據(jù)依賴性強:分類模型的表現(xiàn)通常依賴于大量的標(biāo)注數(shù)據(jù)進(jìn)行訓(xùn)練。獲取高質(zhì)量、大規(guī)模的數(shù)據(jù)集既耗時又昂貴。
泛化能力有限:
發(fā)表于 12-19 14:33
【「大模型啟示錄」閱讀體驗】如何在客服領(lǐng)域應(yīng)用大模型
多個因素以確保所選模型能夠滿足企業(yè)的具體需求和目標(biāo)。首先,企業(yè)需要明確自己的客服需求和目標(biāo)。例如,是否需要24小時在線客服服務(wù)?是否需要處理復(fù)雜問題的能力?是否需要個性化服務(wù)?明確這些需求有助于企業(yè)更好
發(fā)表于 12-17 16:53
深度學(xué)習(xí)模型的魯棒性優(yōu)化
。異常值和噪聲可能會誤導(dǎo)模型的訓(xùn)練,導(dǎo)致模型在面對新數(shù)據(jù)時表現(xiàn)不佳。 數(shù)據(jù)標(biāo)準(zhǔn)化/歸一化 :將數(shù)據(jù)轉(zhuǎn)換到同一尺度上,有助于
AI大模型與深度學(xué)習(xí)的關(guān)系
人類的學(xué)習(xí)過程,實現(xiàn)對復(fù)雜數(shù)據(jù)的學(xué)習(xí)和識別。AI大模型則是指模型的參數(shù)數(shù)量巨大,需要龐大的計算資源來進(jìn)行訓(xùn)練和推理。深度學(xué)習(xí)算法為AI大模型提供了核心的技術(shù)支撐,使得大模型能夠更好地擬
LLM模型和LMM模型的區(qū)別
在重復(fù)測量或分層數(shù)據(jù)中。 LMM(線性混合效應(yīng)模型)是一種特殊類型的線性混合模型,它包括固定效應(yīng)和隨機效應(yīng)。它通常用于分析具有多個層次的數(shù)據(jù)結(jié)構(gòu),例如在多層次
如何使用Tensorflow保存或加載模型
繼續(xù)訓(xùn)練也是必要的。本文將詳細(xì)介紹如何使用TensorFlow保存和加載模型,包括使用tf.keras和tf.saved_model兩種主要方法。
深度學(xué)習(xí)的模型優(yōu)化與調(diào)試方法
深度學(xué)習(xí)模型在訓(xùn)練過程中,往往會遇到各種問題和挑戰(zhàn),如過擬合、欠擬合、梯度消失或爆炸等。因此,對深度學(xué)習(xí)模型進(jìn)行優(yōu)化與調(diào)試是確保其性能優(yōu)越的關(guān)鍵步驟。本文將從數(shù)據(jù)預(yù)處理、模型設(shè)計、超參





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論