") 檢索增強(qiáng)LLM的方案全面的介紹
檢索增強(qiáng)LLM的方案全面的介紹
ChatGPT 的出現(xiàn),讓我們看到了大語言模型 ( Large Language Model, LLM ) 在語言和代碼理解、人類指令遵循、基本推理等多方面的能力,但幻覺問題 Hallucinations[1] 仍然是當(dāng)前大語言模型面臨的一個(gè)重要挑戰(zhàn)。簡單來說,幻覺問題是指 LLM 生成不正確、荒謬或者與事實(shí)不符的結(jié)果。此外,數(shù)據(jù)新鮮度 ( Data Freshness ) 也是 LLM 在生成結(jié)果時(shí)出現(xiàn)的另外一個(gè)問題,即 LLM 對(duì)于一些時(shí)效性比較強(qiáng)的問題可能給不出或者給出過時(shí)的答案。而通過檢索外部相關(guān)信息的方式來增強(qiáng) LLM 的生成結(jié)果是當(dāng)前解決以上問題的一種流行方案,這里把這種方案稱為 檢索增強(qiáng) LLM ( Retrieval Augmented LLM )。這篇長文將對(duì)檢索增強(qiáng) LLM 的方案進(jìn)行一個(gè)相對(duì)全面的介紹。主要內(nèi)容包括:
-
檢索增強(qiáng) LLM 的概念介紹、重要性及其解決的問題
-
檢索增強(qiáng) LLM 的關(guān)鍵模塊及其實(shí)現(xiàn)方法
-
檢索增強(qiáng) LLM 的一些案例分析和應(yīng)用
這篇文章算是自己對(duì)這個(gè)領(lǐng)域的一篇學(xué)習(xí)總結(jié),所以可能不是很專業(yè)和深入,也難免會(huì)有一些不準(zhǔn)確的地方,歡迎討論。為了方便后期的更新和網(wǎng)頁閱讀,我也創(chuàng)建了一個(gè) Github 倉庫 A Guide to Retrieval Augmented LLM [2]
01 什么是檢索增強(qiáng) LLM
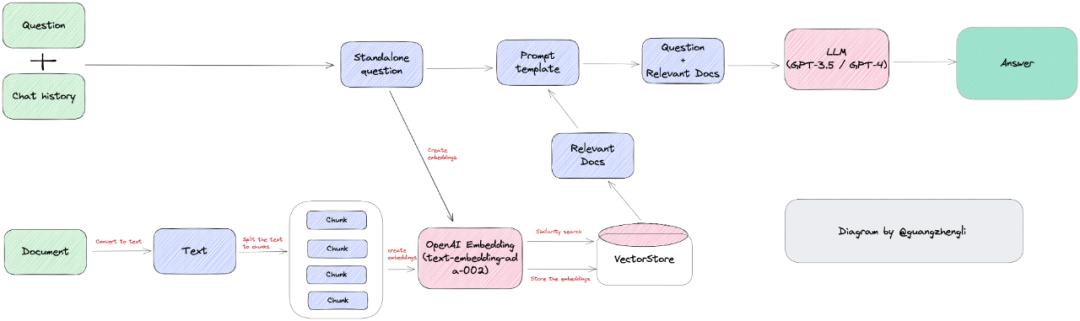
檢索增強(qiáng) LLM ( Retrieval Augmented LLM ),簡單來說,就是給 LLM 提供外部數(shù)據(jù)庫,對(duì)于用戶問題 ( Query ),通過一些信息檢索 ( Information Retrieval, IR ) 的技術(shù),先從外部數(shù)據(jù)庫中檢索出和用戶問題相關(guān)的信息,然后讓 LLM 結(jié)合這些相關(guān)信息來生成結(jié)果。這種模式有時(shí)候也被稱為 檢索增強(qiáng)生成 ( Retrieval Augmented Generation, RAG )。下圖是一個(gè)檢索增強(qiáng) LLM 的簡單示意圖。
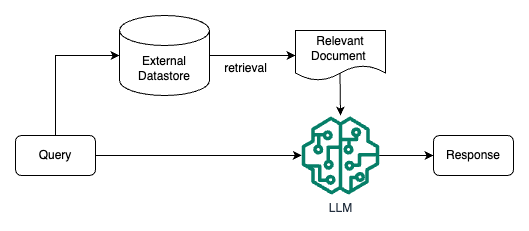
OpenAI 研究科學(xué)家 Andrej Karpathy 前段時(shí)間在微軟 Build 2023 大會(huì)上做過一場(chǎng)關(guān)于 GPT 模型現(xiàn)狀的分享 State of GPT[3],這場(chǎng)演講前半部分分享了 ChatGPT 這類模型是如何一步一步訓(xùn)練的,后半部分主要分享了 LLM 模型的一些應(yīng)用方向,其中就對(duì)檢索增強(qiáng) LLM 這個(gè)應(yīng)用方向做了簡單介紹。下面這張圖就是 Andrej 分享中關(guān)于這個(gè)方向的介紹。
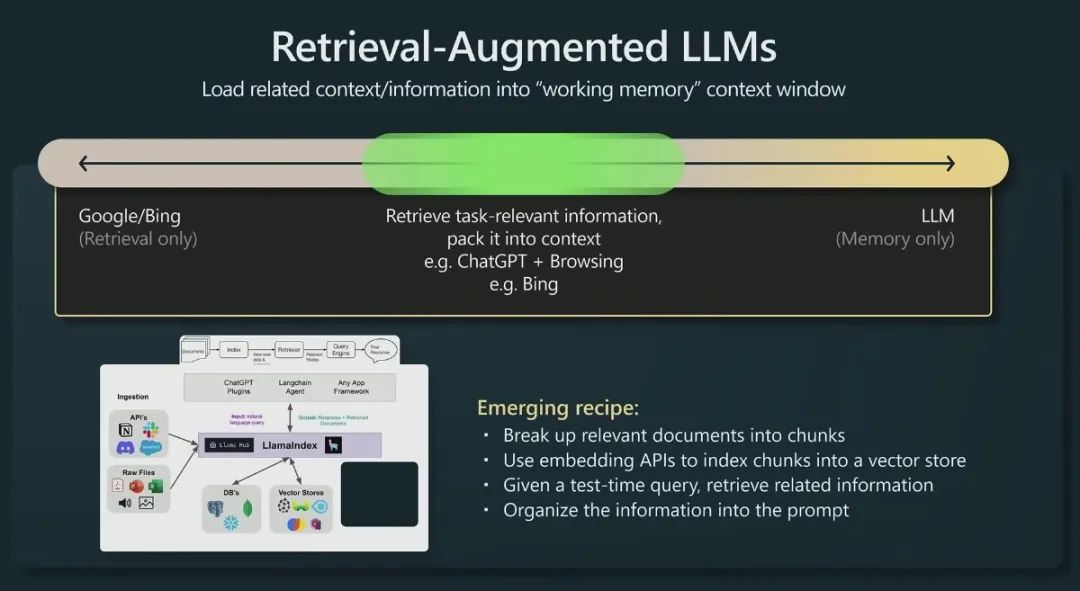
傳統(tǒng)的信息檢索工具,比如 Google/Bing 這樣的搜索引擎,只有檢索能力 ( Retrieval-only ),現(xiàn)在 LLM 通過預(yù)訓(xùn)練過程,將海量數(shù)據(jù)和知識(shí)嵌入到其巨大的模型參數(shù)中,具有記憶能力 ( Memory-only )。從這個(gè)角度看,檢索增強(qiáng) LLM 處于中間,將 LLM 和傳統(tǒng)的信息檢索相結(jié)合,通過一些信息檢索技術(shù)將相關(guān)信息加載到 LLM 的工作內(nèi)存 ( Working Memory ) 中,即 LLM 的上下文窗口 ( Context Window ),亦即 LLM 單次生成時(shí)能接受的最大文本輸入。
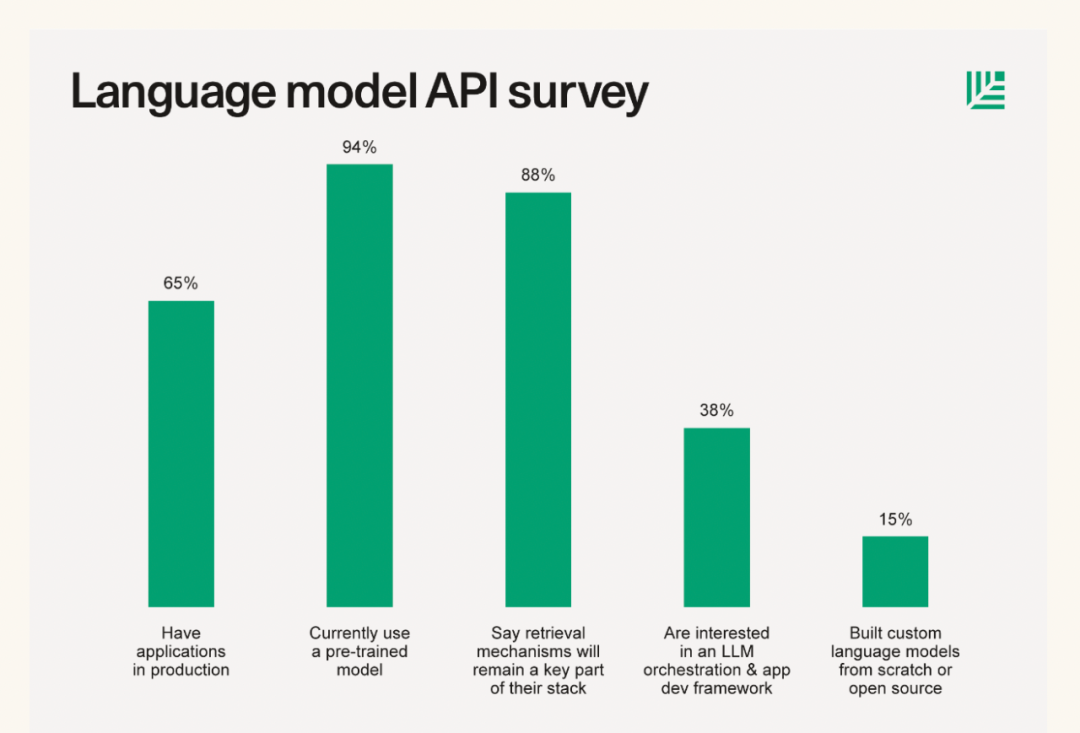
不僅 Andrej 的分享中提到基于檢索來增強(qiáng) LLM 這一應(yīng)用方式,從一些著名投資機(jī)構(gòu)針對(duì) AI 初創(chuàng)企業(yè)技術(shù)棧的調(diào)研和總結(jié)中,也可以看到基于檢索來增強(qiáng) LLM 技術(shù)的廣泛應(yīng)用。比如今年6月份紅杉資本發(fā)布了一篇關(guān)于大語言模型技術(shù)棧的文章 The New Language Model Stack[4],其中就給出了一份對(duì)其投資的33家 AI 初創(chuàng)企業(yè)進(jìn)行的問卷調(diào)查結(jié)果,下圖的調(diào)查結(jié)果顯示有 88% 左右的創(chuàng)業(yè)者表示在自己的產(chǎn)品中有使用到基于檢索增強(qiáng) LLM 技術(shù)。
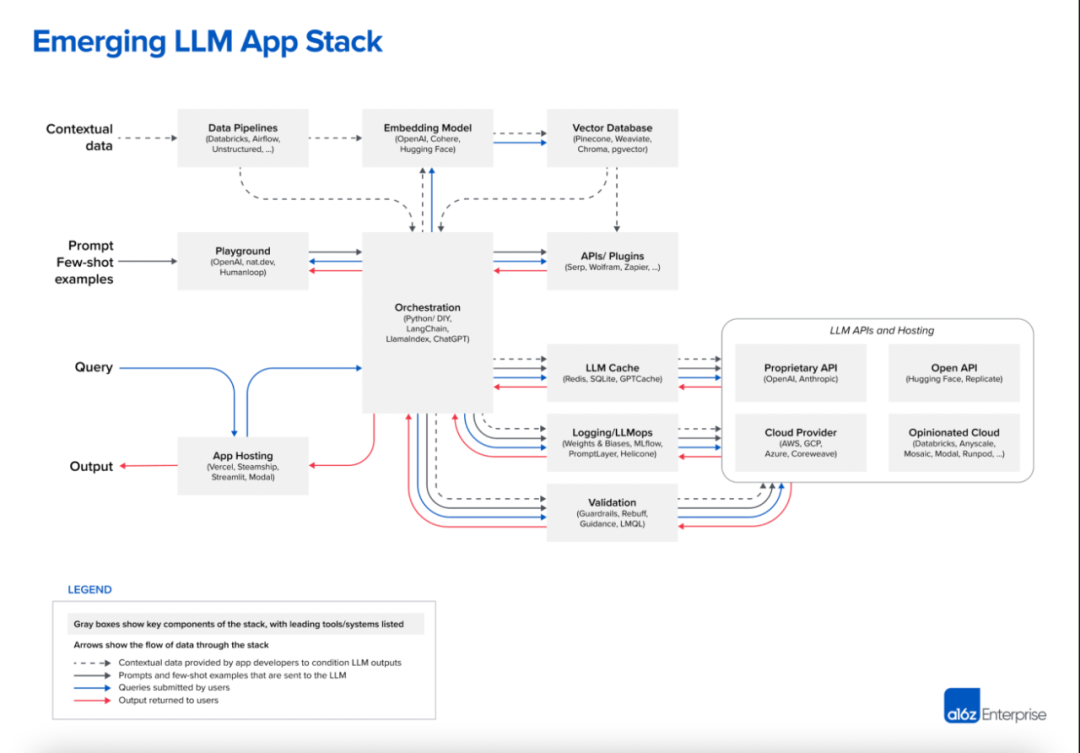
無獨(dú)有偶,美國著名風(fēng)險(xiǎn)投資機(jī)構(gòu) A16Z 在今年6月份也發(fā)表了一篇介紹當(dāng)前 LLM 應(yīng)用架構(gòu)的總結(jié)文章 Emerging Architectures for LLM Applications[5],下圖就是文章中總結(jié)的當(dāng)前 LLM 應(yīng)用的典型架構(gòu),其中最上面 Contextual Data 引入 LLM 的方式就是一種通過檢索來增強(qiáng) LLM 的思路。
02 檢索增強(qiáng) LLM 解決的問題
為什么要結(jié)合傳統(tǒng)的信息檢索系統(tǒng)來增強(qiáng) LLM ?換句話說,基于檢索增強(qiáng)的 LLM 主要解決的問題是什么?這部分內(nèi)容參考自普林斯頓大學(xué)陳丹琦小組之前在 ACL 2023 大會(huì)上關(guān)于基于檢索的語言模型的分享 ACL 2023 Tutorial: Retrieval-based Language Models and Applications[6]
長尾知識(shí)
雖然當(dāng)前 LLM 的訓(xùn)練數(shù)據(jù)量已經(jīng)非常龐大,動(dòng)輒幾百 GB 級(jí)別的數(shù)據(jù)量,萬億級(jí)別的標(biāo)記數(shù)量 ( Token ),比如 GPT-3 的預(yù)訓(xùn)練數(shù)據(jù)使用了3000 億量級(jí)的標(biāo)記,LLaMA 使用了 1.4 萬億量級(jí)的標(biāo)記。訓(xùn)練數(shù)據(jù)的來源也十分豐富,比如維基百科、書籍、論壇、代碼等,LLM 的模型參數(shù)量也十分巨大,從幾十億、百億到千億量級(jí),但讓 LLM 在有限的參數(shù)中記住所有知識(shí)或者信息是不現(xiàn)實(shí)的,訓(xùn)練數(shù)據(jù)的涵蓋范圍也是有限的,總會(huì)有一些長尾知識(shí)在訓(xùn)練數(shù)據(jù)中不能覆蓋到。
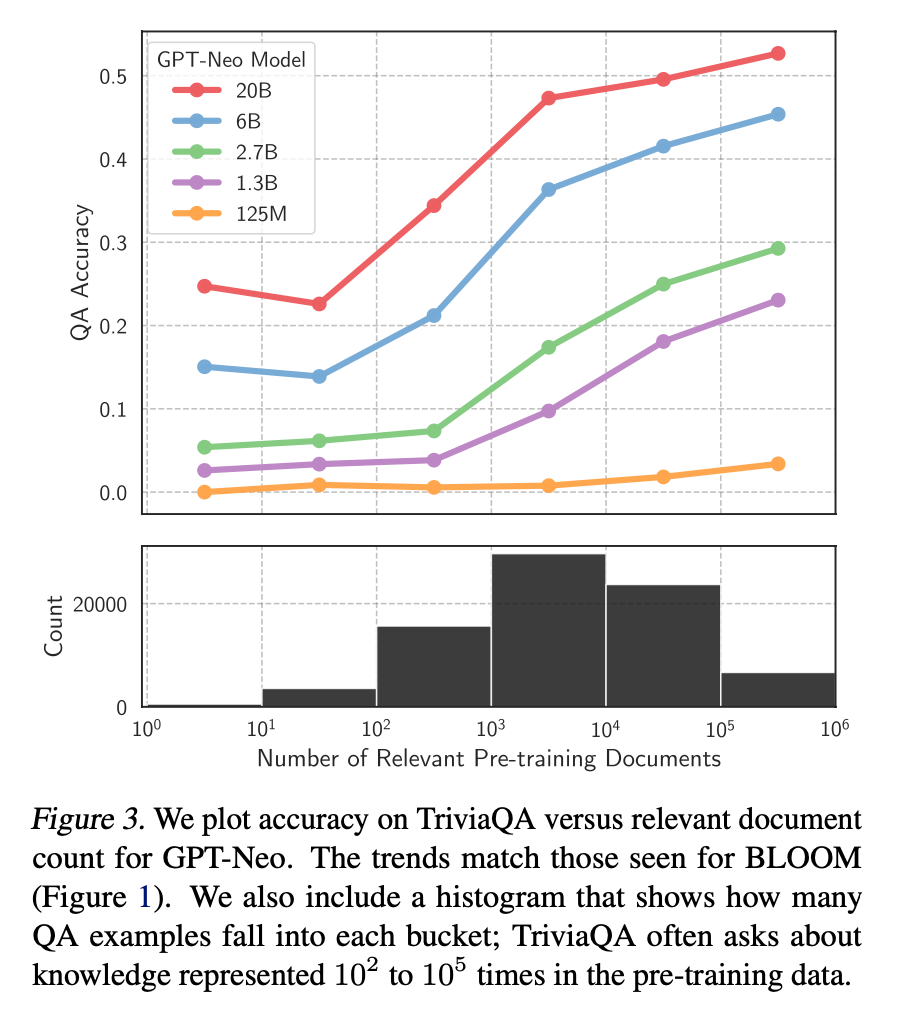
對(duì)于一些相對(duì)通用和大眾的知識(shí),LLM 通常能生成比較準(zhǔn)確的結(jié)果,而對(duì)于一些長尾知識(shí),LLM 生成的回復(fù)通常并不可靠。ICML 會(huì)議上的這篇論文 Large Language Models Struggle to Learn Long-Tail Knowledge[7],就研究了 LLM 對(duì)基于事實(shí)的問答的準(zhǔn)確性和預(yù)訓(xùn)練數(shù)據(jù)中相關(guān)領(lǐng)域文檔數(shù)量的關(guān)系,發(fā)現(xiàn)有很強(qiáng)的相關(guān)性,即預(yù)訓(xùn)練數(shù)據(jù)中相關(guān)文檔數(shù)量越多,LLM 對(duì)事實(shí)性問答的回復(fù)準(zhǔn)確性就越高。從這個(gè)研究中可以得出一個(gè)簡單的結(jié)論 —— LLM 對(duì)長尾知識(shí)的學(xué)習(xí)能力比較弱。下面這張圖就是論文中繪制的相關(guān)性曲線。
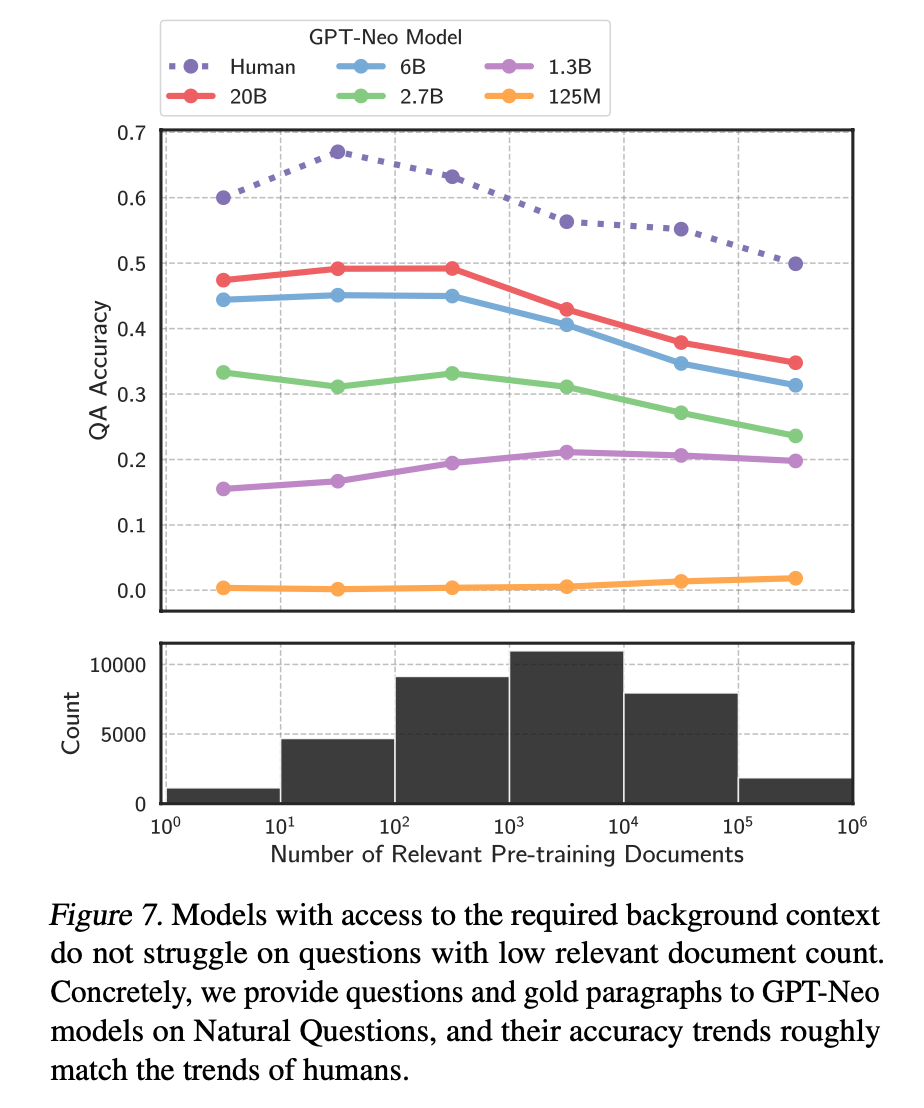
為了提升 LLM 對(duì)長尾知識(shí)的學(xué)習(xí)能力,容易想到的是在訓(xùn)練數(shù)據(jù)加入更多的相關(guān)長尾知識(shí),或者增大模型的參數(shù)量,雖然這兩種方法確實(shí)都有一定的效果,上面提到的論文中也有實(shí)驗(yàn)數(shù)據(jù)支撐,但這兩種方法是不經(jīng)濟(jì)的,即需要一個(gè)很大的訓(xùn)練數(shù)據(jù)量級(jí)和模型參數(shù)才能大幅度提升 LLM 對(duì)長尾知識(shí)的回復(fù)準(zhǔn)確性。而通過檢索的方法把相關(guān)信息在 LLM 推斷時(shí)作為上下文 ( Context ) 給出,既能達(dá)到一個(gè)比較好的回復(fù)準(zhǔn)確性,也是一種比較經(jīng)濟(jì)的方式。下面這張圖就是提供相關(guān)信息的情況下,不同大小模型的回復(fù)準(zhǔn)確性,對(duì)比上一張圖,可以看到對(duì)于同一參數(shù)量級(jí)的模型,在提供少量相關(guān)文檔參與預(yù)訓(xùn)練的情況下,讓模型在推斷階段利用相關(guān)信息,其回復(fù)準(zhǔn)確性有了大幅提升。
私有數(shù)據(jù)
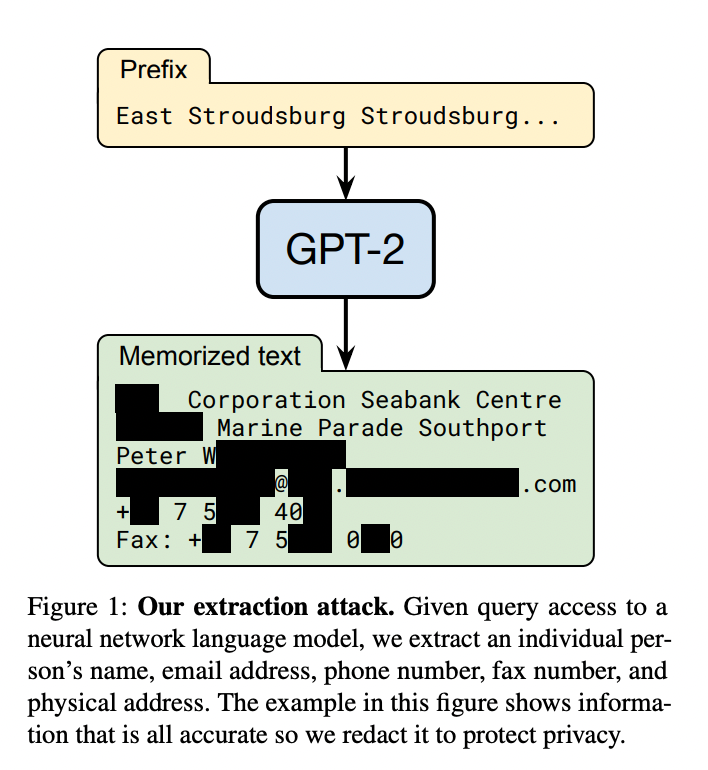
ChatGPT 這類通用的 LLM 預(yù)訓(xùn)練階段利用的大部分都是公開的數(shù)據(jù),不包含私有數(shù)據(jù),因此對(duì)于一些私有領(lǐng)域知識(shí)是欠缺的。比如問 ChatGPT 某個(gè)企業(yè)內(nèi)部相關(guān)的知識(shí),ChatGPT 大概率是不知道或者胡編亂造。雖然可以在預(yù)訓(xùn)練階段加入私有數(shù)據(jù)或者利用私有數(shù)據(jù)進(jìn)行微調(diào),但訓(xùn)練和迭代成本很高。此外,有研究和實(shí)踐表明,通過一些特定的攻擊手法,可以讓 LLM 泄漏訓(xùn)練數(shù)據(jù),如果訓(xùn)練數(shù)據(jù)中包含一些私有信息,就很可能會(huì)發(fā)生隱私信息泄露。比如這篇論文 Extracting Training Data from Large Language Models[8] 的研究者們就通過構(gòu)造的 Query 從 GPT-2 模型中提取出了個(gè)人公開的姓名、郵箱、電話號(hào)碼和地址信息等,即使這些信息可能只在訓(xùn)練數(shù)據(jù)中出現(xiàn)一次。文章還發(fā)現(xiàn),較大規(guī)模的模型比較小規(guī)模的更容易受到攻擊。
如果把私有數(shù)據(jù)作為一個(gè)外部數(shù)據(jù)庫,讓 LLM 在回答基于私有數(shù)據(jù)的問題時(shí),直接從外部數(shù)據(jù)庫中檢索出相關(guān)信息,再結(jié)合檢索出的相關(guān)信息進(jìn)行回答。這樣就不用通過預(yù)訓(xùn)練或者微調(diào)的方法讓 LLM 在參數(shù)中記住私有知識(shí),既節(jié)省了訓(xùn)練或者微調(diào)成本,也一定程度上避免了私有數(shù)據(jù)的泄露風(fēng)險(xiǎn)。
數(shù)據(jù)新鮮度
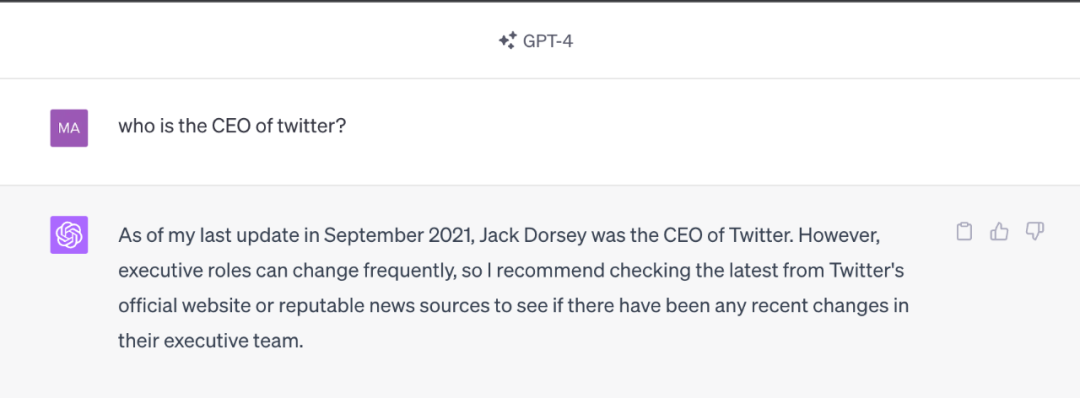
由于 LLM 中學(xué)習(xí)的知識(shí)來自于訓(xùn)練數(shù)據(jù),雖然大部分知識(shí)的更新周期不會(huì)很快,但依然會(huì)有一些知識(shí)或者信息更新得很頻繁。LLM 通過從預(yù)訓(xùn)練數(shù)據(jù)中學(xué)到的這部分信息就很容易過時(shí)。比如 GPT-4 模型使用的是截止到 2021-09 的預(yù)訓(xùn)練數(shù)據(jù),因此涉及這個(gè)日期之后的事件或者信息,它會(huì)拒絕回答或者給出的回復(fù)是過時(shí)或者不準(zhǔn)確的。下面這個(gè)示例是問 GPT-4 當(dāng)前推特的 CEO 是誰,GPT-4 給出的回復(fù)還是 Jack Dorsey,并且自己會(huì)提醒說回復(fù)可能已經(jīng)過時(shí)了。
如果把頻繁更新的知識(shí)作為外部數(shù)據(jù)庫,供 LLM 在必要的時(shí)候進(jìn)行檢索,就可以實(shí)現(xiàn)在不重新訓(xùn)練 LLM 的情況下對(duì) LLM 的知識(shí)進(jìn)行更新和拓展,從而解決 LLM 數(shù)據(jù)新鮮度的問題。
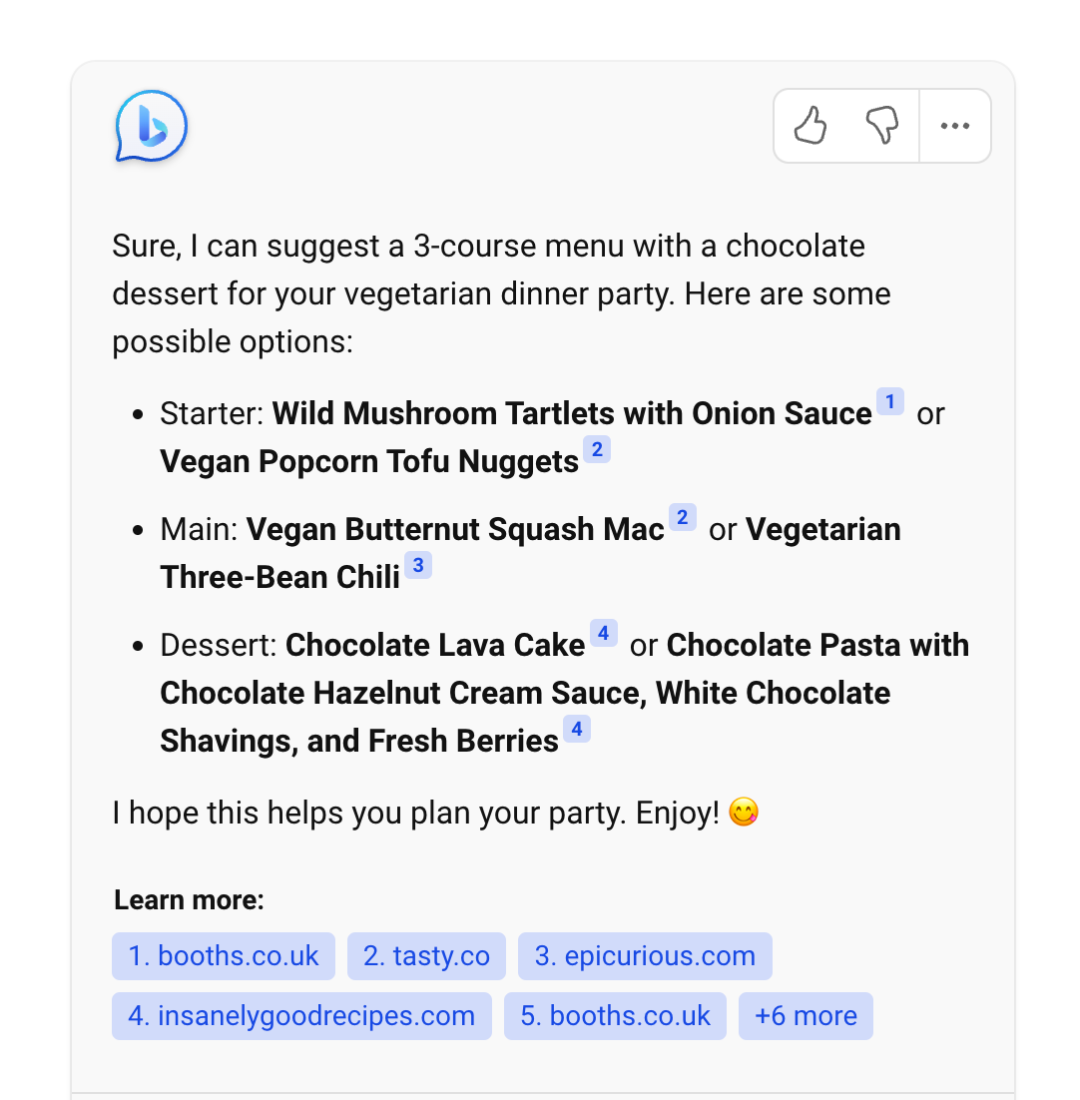
來源驗(yàn)證和可解釋性
通常情況下,LLM 生成的輸出不會(huì)給出其來源,比較難解釋為什么會(huì)這么生成。而通過給 LLM 提供外部數(shù)據(jù)源,讓其基于檢索出的相關(guān)信息進(jìn)行生成,就在生成的結(jié)果和信息來源之間建立了關(guān)聯(lián),因此生成的結(jié)果就可以追溯參考來源,可解釋性和可控性就大大增強(qiáng)。即可以知道 LLM 是基于什么相關(guān)信息來生成的回復(fù)。Bing Chat 就是利用檢索來增強(qiáng) LLM 輸出的典型產(chǎn)品,下圖展示的就是 Bing Chat 的產(chǎn)品截圖,可以看到其生成的回復(fù)中會(huì)給出相關(guān)信息的鏈接。
利用檢索來增強(qiáng) LLM 的輸出,其中很重要的一步是通過一些檢索相關(guān)的技術(shù)從外部數(shù)據(jù)中找出相關(guān)信息片段,然后把相關(guān)信息片段作為上下文供 LLM 在生成回復(fù)時(shí)參考。有人可能會(huì)說,隨著 LLM 的上下文窗口 ( Context Window ) 越來越長,檢索相關(guān)信息的步驟是不是就沒有必要了,直接在上下文中提供盡可能多的信息。比如 GPT-4 模型當(dāng)前接收的最大上下文長度是 32K, Claude 模型最大允許 100K[9] 的上下文長度。
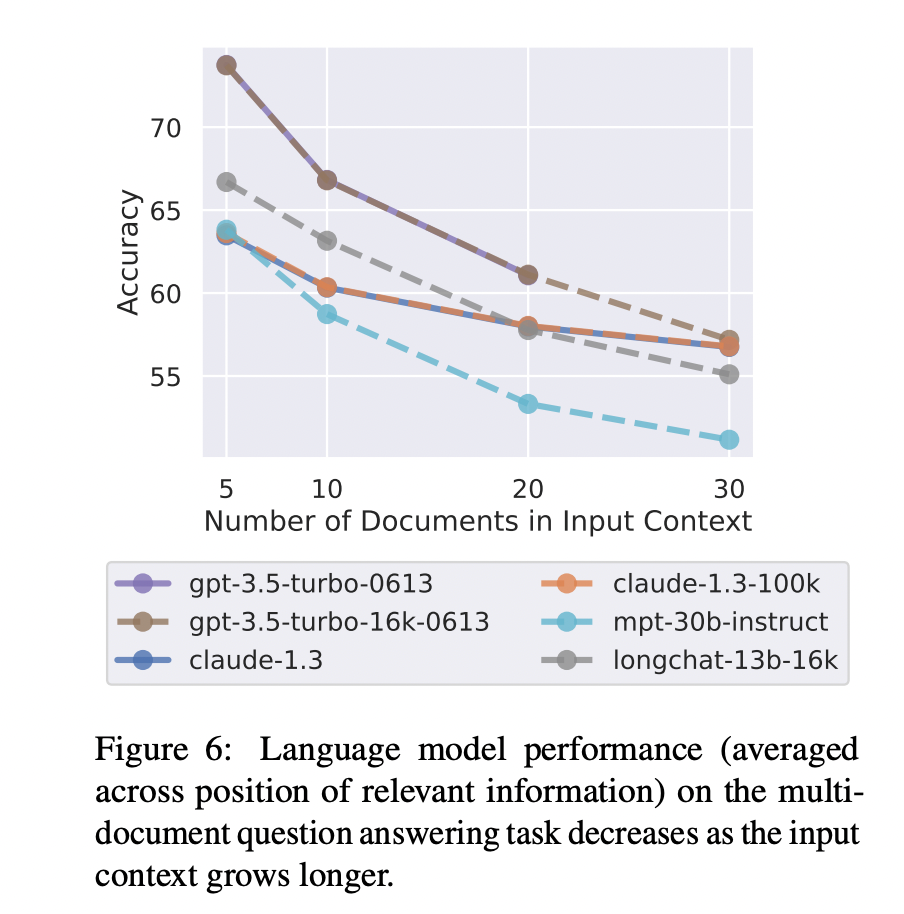
雖然 LLM 的上下文窗口越來越大,但檢索相關(guān)信息的步驟仍然是重要且必要的。一方面當(dāng)前 LLM 的網(wǎng)絡(luò)架構(gòu)決定了其上下文窗口的長度是會(huì)有上限的,不會(huì)無限增長。另外看似很大的上下文窗口,能容納的信息其實(shí)比較有限,比如 32K 的長度可能僅僅相當(dāng)于一篇大學(xué)畢業(yè)論文的長度。另一方面,有研究表明,提供少量更相關(guān)的信息,相比于提供大量不加過濾的信息,LLM 回復(fù)的準(zhǔn)確性會(huì)更高。比如斯坦福大學(xué)的這篇論文 Lost in the Middle[10] 就給出了下面的實(shí)驗(yàn)結(jié)果,可以看到 LLM 回復(fù)的準(zhǔn)確性隨著上下文窗口中提供的文檔數(shù)量增多而下降。
利用檢索技術(shù)從大量外部數(shù)據(jù)中找出與輸入問題最相關(guān)的信息片段,在為 LLM 生成回復(fù)提供參考的同時(shí),也一定程度上過濾掉一些非相關(guān)信息的干擾,便于提高生成回復(fù)的準(zhǔn)確性。此外,上下文窗口越大,推理成本越高。所以相關(guān)信息檢索步驟的引入也能降低不必要的推理成本。
03 關(guān)鍵模塊
為了構(gòu)建檢索增強(qiáng) LLM 系統(tǒng),需要實(shí)現(xiàn)的關(guān)鍵模塊和解決的問題包括:
-
數(shù)據(jù)和索引模塊: 如何處理外部數(shù)據(jù)和構(gòu)建索引
-
查詢和檢索模塊: 如何準(zhǔn)確高效地檢索出相關(guān)信息
-
響應(yīng)生成模塊: 如何利用檢索出的相關(guān)信息來增強(qiáng) LLM 的輸出
數(shù)據(jù)和索引模塊
數(shù)據(jù)獲取
數(shù)據(jù)獲取模塊的作用一般是將多種來源、多種類型和格式的外部數(shù)據(jù)轉(zhuǎn)換成一個(gè)統(tǒng)一的文檔對(duì)象 ( Document Object ),便于后續(xù)流程的處理和使用。文檔對(duì)象除了包含原始的文本內(nèi)容,一般還會(huì)攜帶文檔的元信息 ( Metadata ),可以用于后期的檢索和過濾。元信息包括但不限于:
-
時(shí)間信息,比如文檔創(chuàng)建和修改時(shí)間
-
標(biāo)題、關(guān)鍵詞、實(shí)體(人物、地點(diǎn)等)、文本類別等信息
-
文本總結(jié)和摘要
有些元信息可以直接獲取,有些則可以借助 NLP 技術(shù),比如關(guān)鍵詞抽取、實(shí)體識(shí)別、文本分類、文本摘要等。既可以采用傳統(tǒng)的 NLP 模型和框架,也可以基于 LLM 實(shí)現(xiàn)。
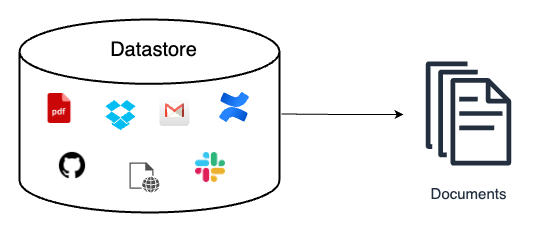
外部數(shù)據(jù)的來源可能是多種多樣的,比如可能來自
-
Google 套件里各種 Doc 文檔、Sheet 表格、Slides 演示、Calendar 日程、Drive 文件等
-
Slack、Discord 等聊天社區(qū)的數(shù)據(jù)
-
Github、Gitlab 上托管的代碼文件
-
Confluence 上各種文檔
-
Web 網(wǎng)頁的數(shù)據(jù)
-
API 返回的數(shù)據(jù)
-
本地文件
外部數(shù)據(jù)的類型和文件格式也可能是多樣化的,比如
-
從數(shù)據(jù)類型來看,包括純文本、表格、演示文檔、代碼等
-
從文件存儲(chǔ)格式來看,包括 txt、csv、pdf、markdown、json 等格式
外部數(shù)據(jù)可能是多語種的,比如中文、英文、德文、日文等。除此之外,還可能是多模態(tài)的,除了上面討論的文本模態(tài),還包括圖片、音頻、視頻等多種模態(tài)。不過這篇文章中討論的外部數(shù)據(jù)將限定在文本模態(tài)。
在構(gòu)建數(shù)據(jù)獲取模塊時(shí),不同來源、類型、格式、語種的數(shù)據(jù)可能都需要采用不同的讀取方式。
文本分塊
文本分塊是將長文本切分成小片段的過程,比如將一篇長文章切分成一個(gè)個(gè)相對(duì)短的段落。那么為什么要進(jìn)行文本分塊?一方面當(dāng)前 LLM 的上下文長度是有限制的,直接把一篇長文全部作為相關(guān)信息放到 LLM 的上下文窗口中,可能會(huì)超過長度限制。另一方面,對(duì)于長文本來說,即使其和查詢的問題相關(guān),但一般不會(huì)通篇都是完全相關(guān)的,而分塊能一定程度上剔除不相關(guān)的內(nèi)容,為后續(xù)的回復(fù)生成過濾一些不必要的噪聲。
文本分塊的好壞將很大程度上影響后續(xù)回復(fù)生成的效果,切分得不好,內(nèi)容之間的關(guān)聯(lián)性會(huì)被切斷。因此設(shè)計(jì)一個(gè)好的分塊策略十分重要。分塊策略包括具體的切分方法 ( 比如是按句子切分還是段落切分 ),塊的大小設(shè)為多少合適,不同的塊之間是否允許重疊等。Pinecone 的這篇博客 Chunking Strategies for LLM Applications[11] 中就給出了一些在設(shè)計(jì)分塊策略時(shí)需要考慮的因素。
-
原始內(nèi)容的特點(diǎn):原始內(nèi)容是長文 ( 博客文章、書籍等 ) 還是短文 ( 推文、即時(shí)消息等 ),是什么格式 ( HTML、Markdown、Code 還是 LaTeX 等 ),不同的內(nèi)容特點(diǎn)可能會(huì)適用不同的分塊策略;
-
后續(xù)使用的索引方法:目前最常用的索引是對(duì)分塊后的內(nèi)容進(jìn)行向量索引,那么不同的向量嵌入模型可能有其適用的分塊大小,比如 sentence-transformer 模型比較適合對(duì)句子級(jí)別的內(nèi)容進(jìn)行嵌入,OpenAI 的 text-embedding-ada-002 模型比較適合的分塊大小在 256~512 個(gè)標(biāo)記數(shù)量;
-
問題的長度:問題的長度需要考慮,因?yàn)樾枰趩栴}去檢索出相關(guān)的文本片段;
-
檢索出的相關(guān)內(nèi)容在回復(fù)生成階段的使用方法:如果是直接把檢索出的相關(guān)內(nèi)容作為 Prompt 的一部分提供給 LLM,那么 LLM 的輸入長度限制在設(shè)計(jì)分塊大小時(shí)就需要考慮。
分塊實(shí)現(xiàn)方法
那么文本分塊具體如何實(shí)現(xiàn)?一般來說,實(shí)現(xiàn)文本分塊的整體流程如下:
-
將原始的長文本切分成小的語義單元,這里的語義單元通常是句子級(jí)別或者段落級(jí)別;
-
將這些小的語義單元融合成更大的塊,直到達(dá)到設(shè)定的塊大小 ( Chunk Size ),就將該塊作為獨(dú)立的文本片段;
-
迭代構(gòu)建下一個(gè)文本片段,一般相鄰的文本片段之間會(huì)設(shè)置重疊,以保持語義的連貫性。
那如何把原始的長文本切分成小的語義單元? 最常用的是基于分割符進(jìn)行切分,比如句號(hào) ( . )、換行符 ( )、空格等。除了可以利用單個(gè)分割符進(jìn)行簡單切分,還可以定義一組分割符進(jìn)行迭代切分,比如定義 [" ", " ", " ", ""] 這樣一組分隔符,切分的時(shí)候先利用第一個(gè)分割符進(jìn)行切分 ( 實(shí)現(xiàn)類似按段落切分的效果 ),第一次切分完成后,對(duì)于超過預(yù)設(shè)大小的塊,繼續(xù)使用后面的分割符進(jìn)行切分,依此類推。這種切分方法能比較好地保持原始文本的層次結(jié)構(gòu)。
對(duì)于一些結(jié)構(gòu)化的文本,比如代碼,Markdown,LaTeX 等文本,在進(jìn)行切分的時(shí)候可能需要單獨(dú)進(jìn)行考慮:
-
比如 Python 代碼文件,分割符中可能就需要加入類似
class,def這種來保證類和函數(shù)代碼塊的完整性; -
比如 Markdown 文件,是通過不同層級(jí)的 Header 進(jìn)行組織的,即不同數(shù)量的 # 符號(hào),在切分時(shí)就可以通過使用特定的分割符來維持這種層級(jí)結(jié)構(gòu)。
文本塊大小的設(shè)定也是分塊策略需要考慮的重要因素,太大或者太小都會(huì)影響最終回復(fù)生成的效果。文本塊大小的計(jì)算方法,最常用的可以直接基于字符數(shù)進(jìn)行統(tǒng)計(jì) ( Character-level ),也可以基于標(biāo)記數(shù)進(jìn)行統(tǒng)計(jì) ( Token-level )。至于如何確定合適的分塊大小,這個(gè)因場(chǎng)景而異,很難有一個(gè)統(tǒng)一的標(biāo)準(zhǔn),可以通過評(píng)估不同分塊大小的效果來進(jìn)行選擇。
上面提到的一些分塊方法在 LangChain[12] 中都有相應(yīng)的實(shí)現(xiàn)。比如下面的代碼示例
from langchain.text_splitter import CharacterTextSplitterfrom langchain.text_splitter import RecursiveCharacterTextSplitter, Language# text splittext_splitter = RecursiveCharacterTextSplitter( # Set a really small chunk size, just to show.
chunk_size = 100,
chunk_overlap = 20,
length_function = len,
add_start_index = True,
)# code splitpython_splitter = RecursiveCharacterTextSplitter.from_language(
language=Language.PYTHON,
chunk_size=50,
chunk_overlap=0 )# markdown splitmd_splitter = RecursiveCharacterTextSplitter.from_language(
language=Language.MARKDOWN,
chunk_size=60,
chunk_overlap=0 )
數(shù)據(jù)索引
經(jīng)過前面的數(shù)據(jù)讀取和文本分塊操作后,接著就需要對(duì)處理好的數(shù)據(jù)進(jìn)行索引。索引是一種數(shù)據(jù)結(jié)構(gòu),用于快速檢索出與用戶查詢相關(guān)的文本內(nèi)容。它是檢索增強(qiáng) LLM 的核心基礎(chǔ)組件之一。
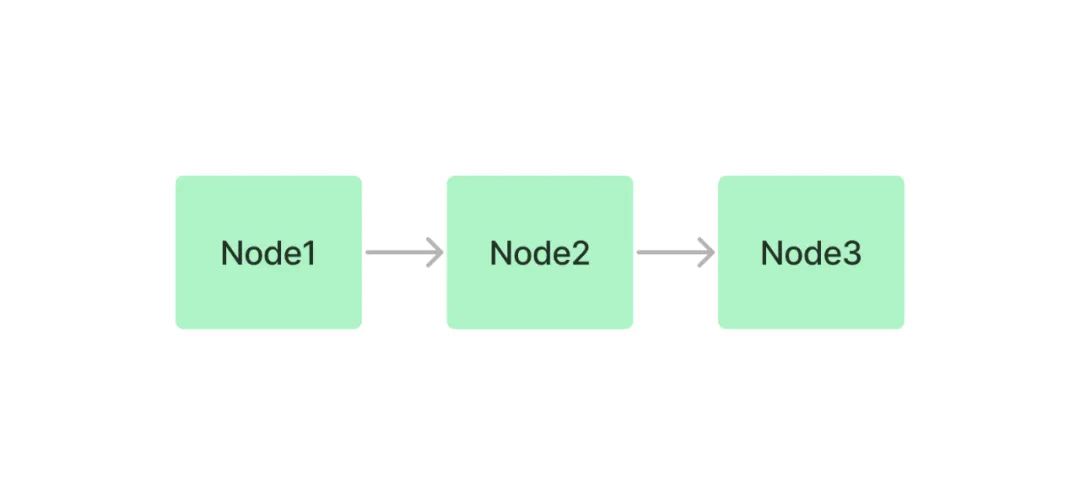
下面介紹幾種常見的索引結(jié)構(gòu)。為了說明不同的索引結(jié)構(gòu),引入節(jié)點(diǎn)(Node)的概念。在這里,節(jié)點(diǎn)就是前面步驟中對(duì)文檔切分后生成的文本塊(Chunk)。下面的索引結(jié)構(gòu)圖來自 LlamaIndex 的文檔 How Each Index Works[13]。
鏈?zhǔn)剿饕?/h4>
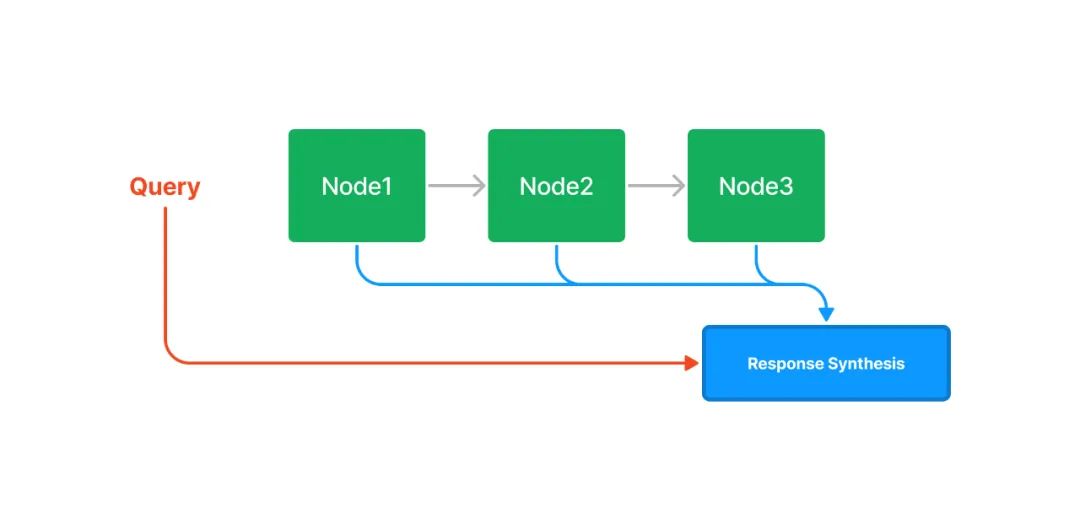
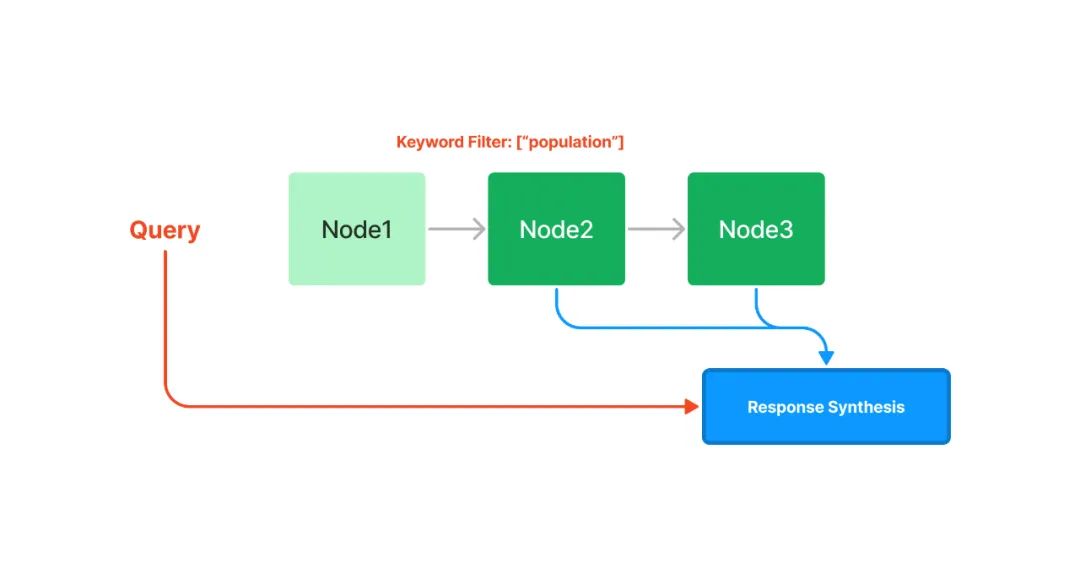
鏈?zhǔn)剿饕ㄟ^鏈表的結(jié)構(gòu)對(duì)文本塊進(jìn)行順序索引。在后續(xù)的檢索和生成階段,可以簡單地順序遍歷所有節(jié)點(diǎn),也可以基于關(guān)鍵詞進(jìn)行過濾。
樹索引
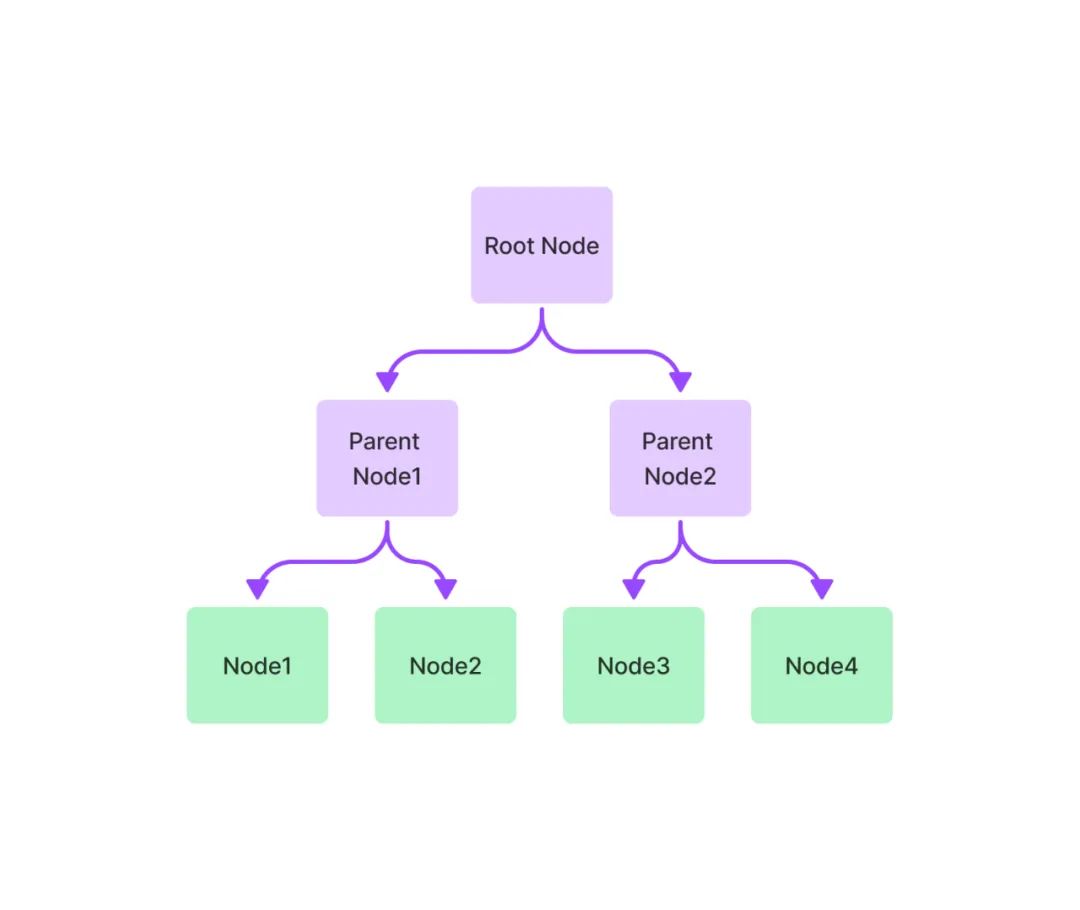
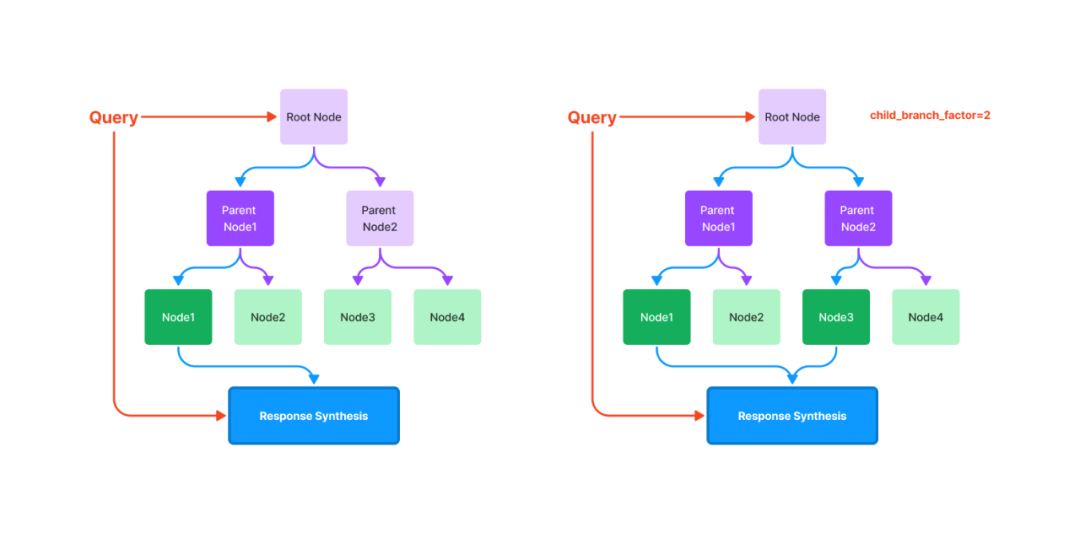
樹索引將一組節(jié)點(diǎn) ( 文本塊 ) 構(gòu)建成具有層級(jí)的樹狀索引結(jié)構(gòu),其從葉節(jié)點(diǎn) (原始文本塊) 向上構(gòu)建,每個(gè)父節(jié)點(diǎn)都是子節(jié)點(diǎn)的摘要。在檢索階段,既可以從根節(jié)點(diǎn)向下進(jìn)行遍歷,也可以直接利用根節(jié)點(diǎn)的信息。樹索引提供了一種更高效地查詢長文本塊的方式,它還可以用于從文本的不同部分提取信息。與鏈?zhǔn)剿饕煌瑯渌饕裏o需按順序查詢。
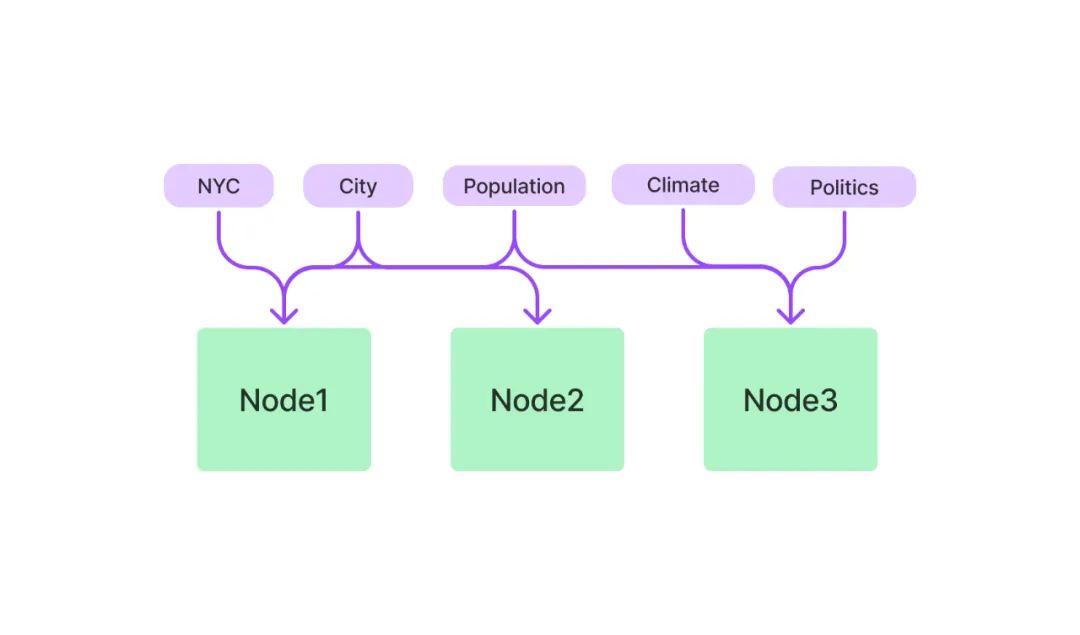
關(guān)鍵詞表索引
關(guān)鍵詞表索引從每個(gè)節(jié)點(diǎn)中提取關(guān)鍵詞,構(gòu)建了每個(gè)關(guān)鍵詞到相應(yīng)節(jié)點(diǎn)的多對(duì)多映射,意味著每個(gè)關(guān)鍵詞可能指向多個(gè)節(jié)點(diǎn),每個(gè)節(jié)點(diǎn)也可能包含多個(gè)關(guān)鍵詞。在檢索階段,可以基于用戶查詢中的關(guān)鍵詞對(duì)節(jié)點(diǎn)進(jìn)行篩選。
向量索引
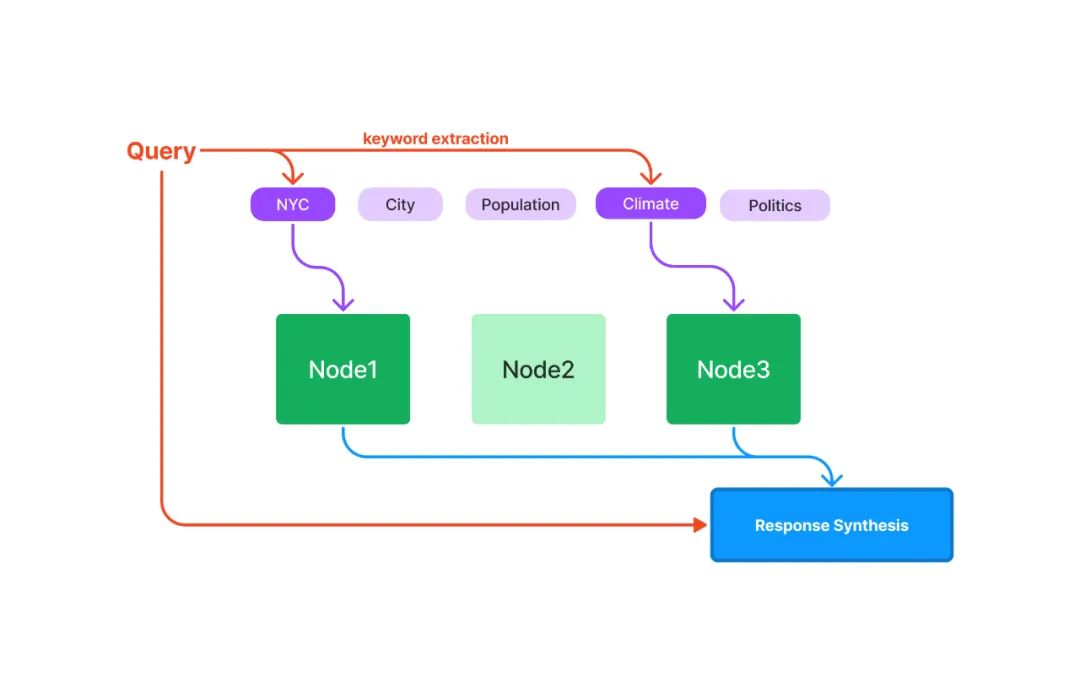
向量索引是當(dāng)前最流行的一種索引方法。這種方法一般利用文本嵌入模型 ( Text Embedding Model ) 將文本塊映射成一個(gè)固定長度的向量,然后存儲(chǔ)在向量數(shù)據(jù)庫中。檢索的時(shí)候,對(duì)用戶查詢文本采用同樣的文本嵌入模型映射成向量,然后基于向量相似度計(jì)算獲取最相似的一個(gè)或者多個(gè)節(jié)點(diǎn)。
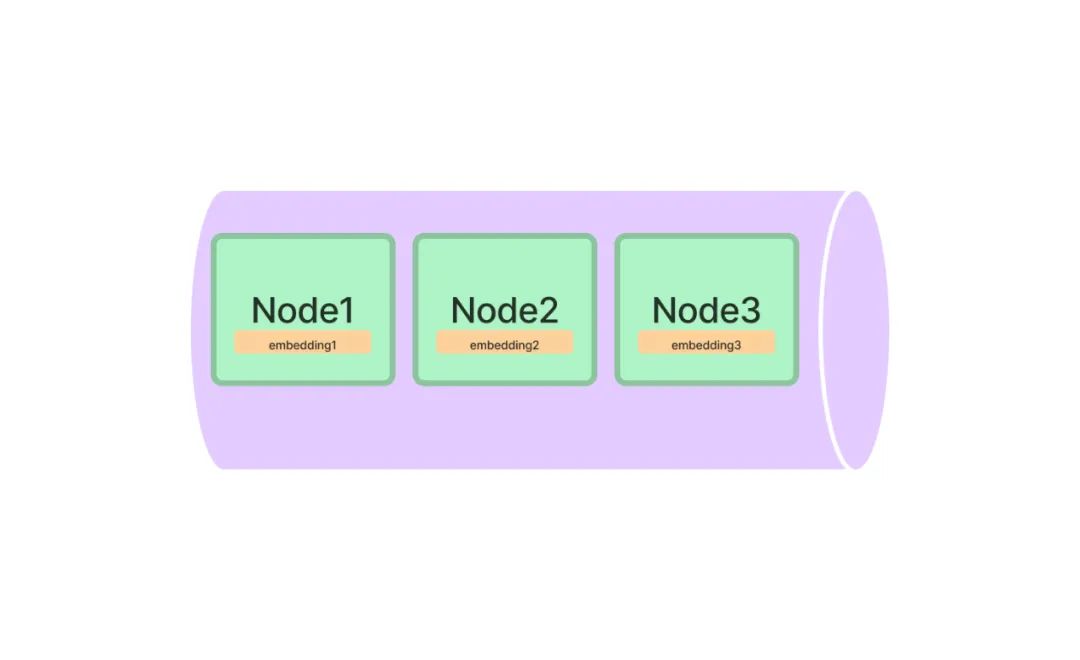
上面的表述中涉及到向量索引和檢索中三個(gè)重要的概念: 文本嵌入模型、相似向量檢索和向量數(shù)據(jù)庫。下面一一進(jìn)行詳細(xì)說明。
文本嵌入模型
文本嵌入模型 ( Text Embedding Model ) 將非結(jié)構(gòu)化的文本轉(zhuǎn)換成結(jié)構(gòu)化的向量 ( Vector ),目前常用的是學(xué)習(xí)得到的稠密向量。
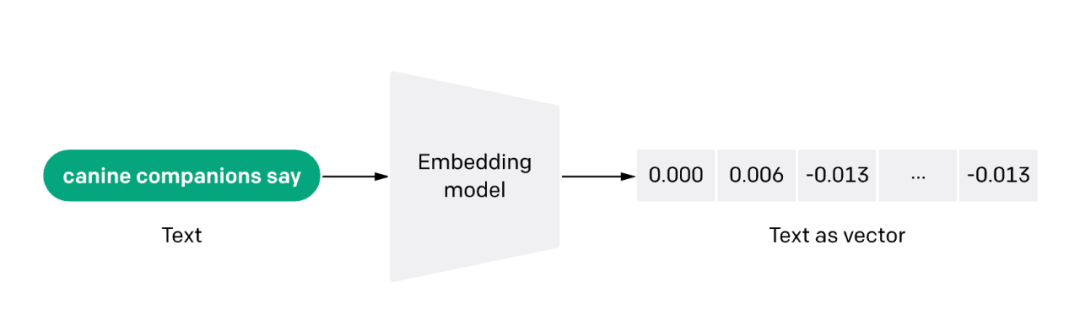
當(dāng)前有很多文本嵌入模型可供選擇,比如
-
早期的 Word2Vec、GloVe 模型等,目前很少用。
-
基于孿生 BERT 網(wǎng)絡(luò)預(yù)訓(xùn)練得到的 Sentence Transformers[14] 模型,對(duì)句子的嵌入效果比較好
-
OpenAI 提供的 text-embedding-ada-002[15] 模型,嵌入效果表現(xiàn)不錯(cuò),且可以處理最大 8191 標(biāo)記長度的文本
-
Instructor[16] 模型,這是一個(gè)經(jīng)過指令微調(diào)的文本嵌入模型,可以根據(jù)任務(wù)(例如分類、檢索、聚類、文本評(píng)估等)和領(lǐng)域(例如科學(xué)、金融等),提供任務(wù)指令而生成相對(duì)定制化的文本嵌入向量,無需進(jìn)行任何微調(diào)
-
BGE[17] 模型: 由智源研究院開源的中英文語義向量模型,目前在MTEB中英文榜單都排在第一位。
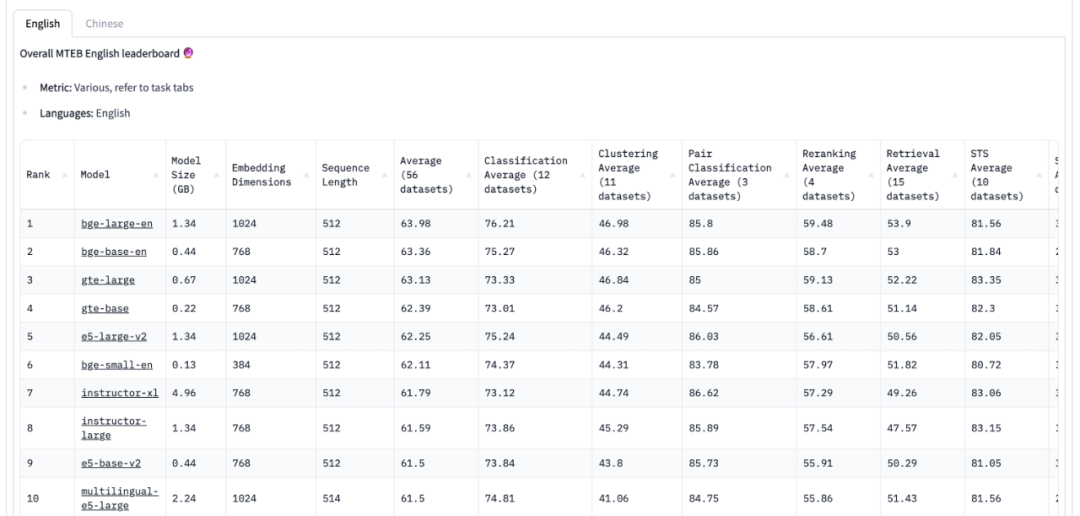
下面就是評(píng)估文本嵌入模型效果的榜單 MTEB Leaderboard[18] (截止到 2023-08-18 )。值得說明的是,這些現(xiàn)成的文本嵌入模型沒有針對(duì)特定的下游任務(wù)進(jìn)行微調(diào),所以不一定在下游任務(wù)上有足夠好的表現(xiàn)。最好的方式一般是在下游特定的數(shù)據(jù)上重新訓(xùn)練或者微調(diào)自己的文本嵌入模型。
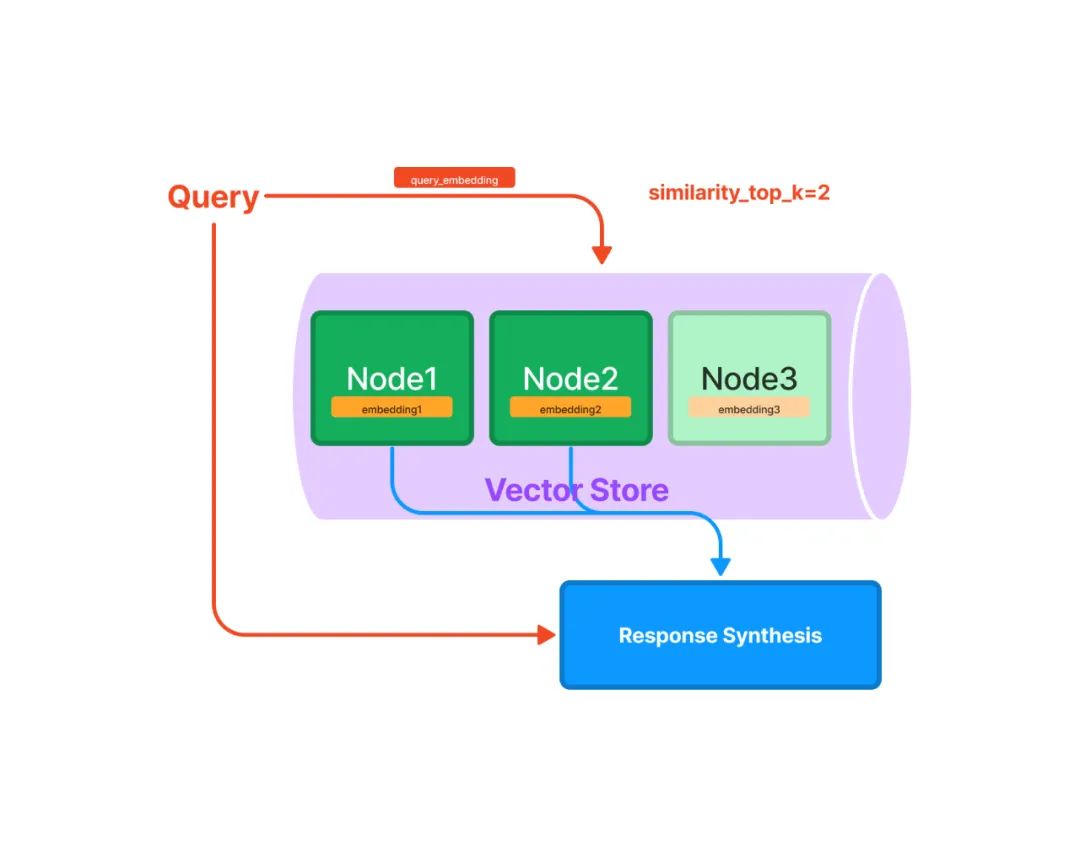
相似向量檢索
相似向量檢索要解決的問題是給定一個(gè)查詢向量,如何從候選向量中準(zhǔn)確且高效地檢索出與其相似的一個(gè)或多個(gè)向量。首先是相似性度量方法的選擇,可以采用余弦相似度、點(diǎn)積、歐式距離、漢明距離等,通常情況下可以直接使用余弦相似度。其次是相似性檢索算法和實(shí)現(xiàn)方法的選擇,候選向量的數(shù)量量級(jí)、檢索速度和準(zhǔn)確性的要求、內(nèi)存的限制等都是需要考慮的因素。
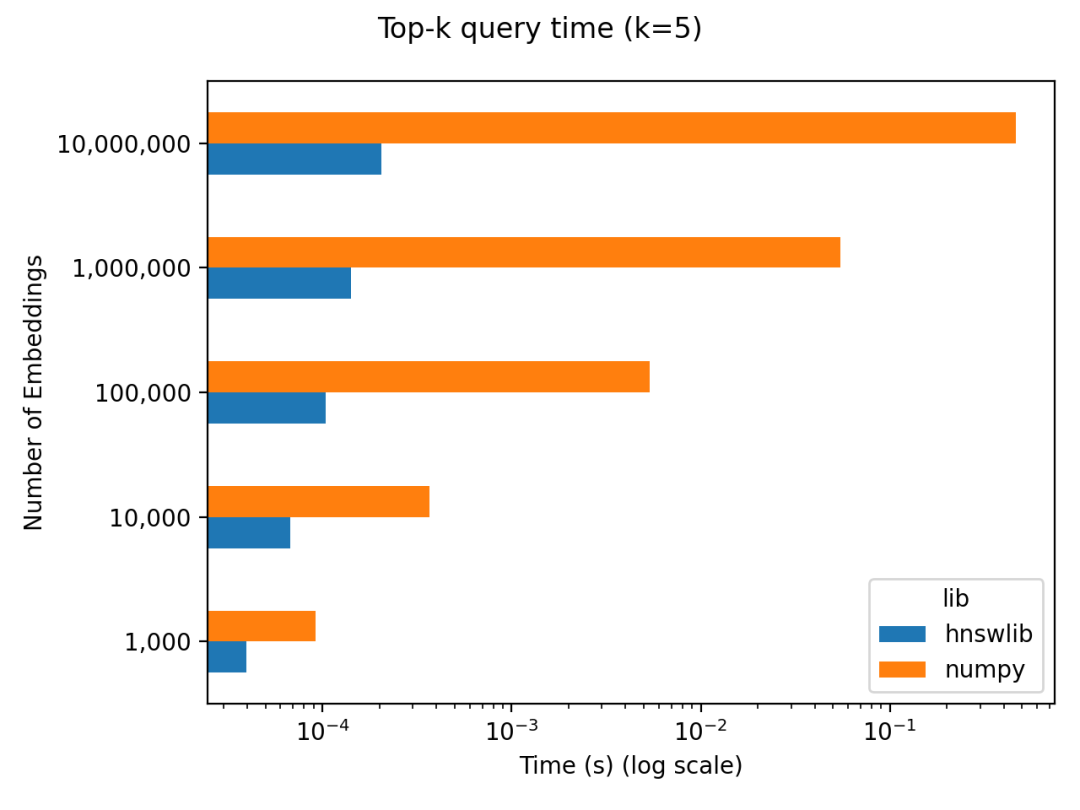
當(dāng)候選向量的數(shù)量比較少時(shí),比如只有幾萬個(gè)向量,那么 Numpy 庫就可以實(shí)現(xiàn)相似向量檢索,實(shí)現(xiàn)簡單,準(zhǔn)確性高,速度也很快。國外有個(gè)博主做了個(gè)簡單的基準(zhǔn)測(cè)試發(fā)現(xiàn) Do you actually need a vector database[19] ,當(dāng)候選向量數(shù)量在 10 萬量級(jí)以下時(shí),通過對(duì)比 Numpy 和另一種高效的近似最近鄰檢索實(shí)現(xiàn)庫 Hnswlib[20] ,發(fā)現(xiàn)在檢索效率上并沒有數(shù)量級(jí)的差異,但 Numpy 的實(shí)現(xiàn)過程更簡單。
下面就是使用 Numpy 的一種簡單實(shí)現(xiàn)代碼:
import numpy as np# candidate_vecs: 2D numpy array of shape N x D# query_vec: 1D numpy array of shape D# k: number of top k similar vectorssim_scores = np.dot(candidate_vecs, query_vec)
topk_indices = np.argsort(sim_scores)[::-1][:k]
topk_values = sim_scores[topk_indices]
對(duì)于大規(guī)模向量的相似性檢索,使用 Numpy 庫就不合適,需要使用更高效的實(shí)現(xiàn)方案。Facebook團(tuán)隊(duì)開源的 Faiss[21] 就是一個(gè)很好的選擇。Faiss 是一個(gè)用于高效相似性搜索和向量聚類的庫,它實(shí)現(xiàn)了在任意大小的向量集合中進(jìn)行搜索的很多算法,除了可以在CPU上運(yùn)行,有些算法也支持GPU加速。Faiss 包含多種相似性檢索算法,具體使用哪種算法需要綜合考慮數(shù)據(jù)量、檢索頻率、準(zhǔn)確性和檢索速度等因素。
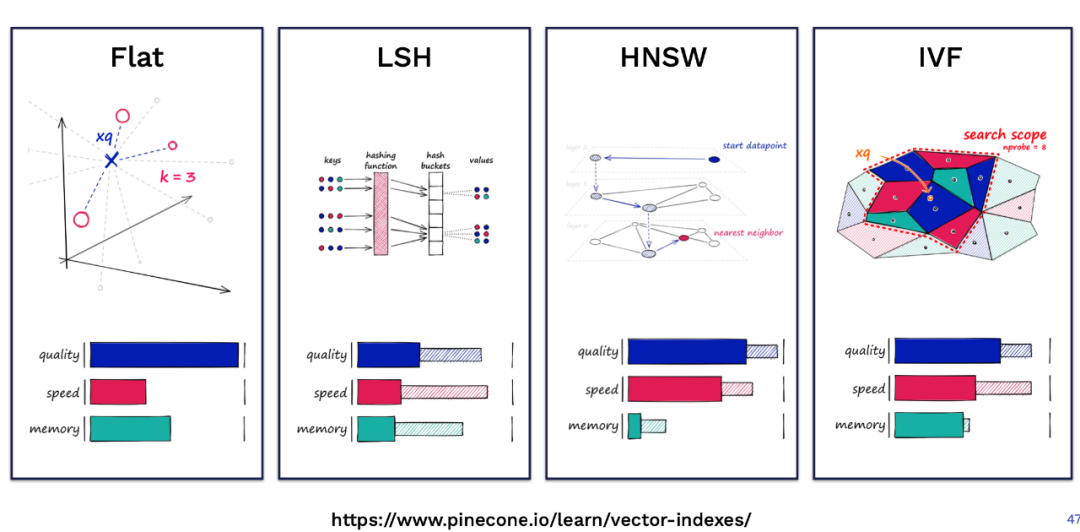
Pinecone 的這篇博客 Nearest Neighbor Indexes for Similarity Search[22] 對(duì) Faiss 中常用的幾種索引進(jìn)行了詳細(xì)介紹,下圖是幾種索引在不同維度下的定性對(duì)比:
向量數(shù)據(jù)庫
上面提到的基于 Numpy 和 Faiss 實(shí)現(xiàn)的向量相似檢索方案,如果應(yīng)用到實(shí)際產(chǎn)品中,可能還缺少一些功能,比如:
-
數(shù)據(jù)托管和備份
-
數(shù)據(jù)管理,比如數(shù)據(jù)的插入、刪除和更新
-
向量對(duì)應(yīng)的原始數(shù)據(jù)和元數(shù)據(jù)的存儲(chǔ)
-
可擴(kuò)展性,包括垂直和水平擴(kuò)展
所以向量數(shù)據(jù)庫應(yīng)運(yùn)而生。簡單來說,向量數(shù)據(jù)庫是一種專門用于存儲(chǔ)、管理和查詢向量數(shù)據(jù)的數(shù)據(jù)庫,可以實(shí)現(xiàn)向量數(shù)據(jù)的相似檢索、聚類等。目前比較流行的向量數(shù)據(jù)庫有 Pinecone[23]、Vespa[24]、Weaviate[25]、Milvus[26]、Chroma[27] 、Tencent Cloud VectorDB[28]等,大部分都提供開源產(chǎn)品。
Pinecone 的這篇博客 What is a Vector Database[29] 就對(duì)向量數(shù)據(jù)庫的相關(guān)原理和組成進(jìn)行了比較系統(tǒng)的介紹,下面這張圖就是文章中給出的一個(gè)向量數(shù)據(jù)庫常見的數(shù)據(jù)處理流程:

-
索引: 使用乘積量化 ( Product Quantization ) 、局部敏感哈希 ( LSH )、HNSW 等算法對(duì)向量進(jìn)行索引,這一步將向量映射到一個(gè)數(shù)據(jù)結(jié)構(gòu),以實(shí)現(xiàn)更快的搜索。
-
查詢: 將查詢向量和索引向量進(jìn)行比較,以找到最近鄰的相似向量。
-
后處理: 有些情況下,向量數(shù)據(jù)庫檢索出最近鄰向量后,對(duì)其進(jìn)行后處理后再返回最終結(jié)果。
向量數(shù)據(jù)庫的使用比較簡單,下面是使用 Python 操作 Pinecone 向量數(shù)據(jù)庫的示例代碼:
# install python pinecone client# pip install pinecone-clientimport pinecone
# initialize pinecone clientpinecone.init(api_key="YOUR_API_KEY", environment="YOUR_ENVIRONMENT")# create index pinecone.create_index("quickstart", dimension=8, metric="euclidean")# connect to the indexindex = pinecone.Index("quickstart")# Upsert sample data (5 8-dimensional vectors) index.upsert([
("A", [0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1]),
("B", [0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2]),
("C", [0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3]),
("D", [0.4, 0.4, 0.4, 0.4, 0.4, 0.4, 0.4, 0.4]),
("E", [0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5])
])# queryindex.query(
vector=[0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3],
top_k=3,
include_values=True
)
# Returns: # {'matches': [{'id': 'C', # 'score': 0.0, # 'values': [0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3]}, # {'id': 'D', # 'score': 0.0799999237, # 'values': [0.4, 0.4, 0.4, 0.4, 0.4, 0.4, 0.4, 0.4]}, # {'id': 'B', # 'score': 0.0800000429, # 'values': [0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2]}], # 'namespace': ''}# delete index pinecone.delete_index("quickstart")
查詢和檢索模塊
查詢變換
查詢文本的表達(dá)方法直接影響著檢索結(jié)果,微小的文本改動(dòng)都可能會(huì)得到天差萬別的結(jié)果。直接用原始的查詢文本進(jìn)行檢索在很多時(shí)候可能是簡單有效的,但有時(shí)候可能需要對(duì)查詢文本進(jìn)行一些變換,以得到更好的檢索結(jié)果,從而更可能在后續(xù)生成更好的回復(fù)結(jié)果。下面列出幾種常見的查詢變換方式。
變換一: 同義改寫
將原始查詢改寫成相同語義下不同的表達(dá)方式,改寫工作可以調(diào)用 LLM 完成。比如對(duì)于這樣一個(gè)原始查詢: What are the approaches to Task Decomposition?,可以改寫成下面幾種同義表達(dá):
How can Task Decomposition be approached?
What are the different methods for Task Decomposition?
What are the various approaches to decomposing tasks?
對(duì)于每種查詢表達(dá),分別檢索出一組相關(guān)文檔,然后對(duì)所有檢索結(jié)果進(jìn)行去重合并,從而得到一個(gè)更大的候選相關(guān)文檔集合。通過將同一個(gè)查詢改寫成多個(gè)同義查詢,能夠克服單一查詢的局限,獲得更豐富的檢索結(jié)果集合。
變換二: 查詢分解
有相關(guān)研究表明 ( self-ask[30],ReAct[31] ),LLM 在回答復(fù)雜問題時(shí),如果將復(fù)雜問題分解成相對(duì)簡單的子問題,回復(fù)表現(xiàn)會(huì)更好。這里又可以分成單步分解和多步分解。
單步分解將一個(gè)復(fù)雜查詢轉(zhuǎn)化為多個(gè)簡單的子查詢,融合每個(gè)子查詢的答案作為原始復(fù)雜查詢的回復(fù)。
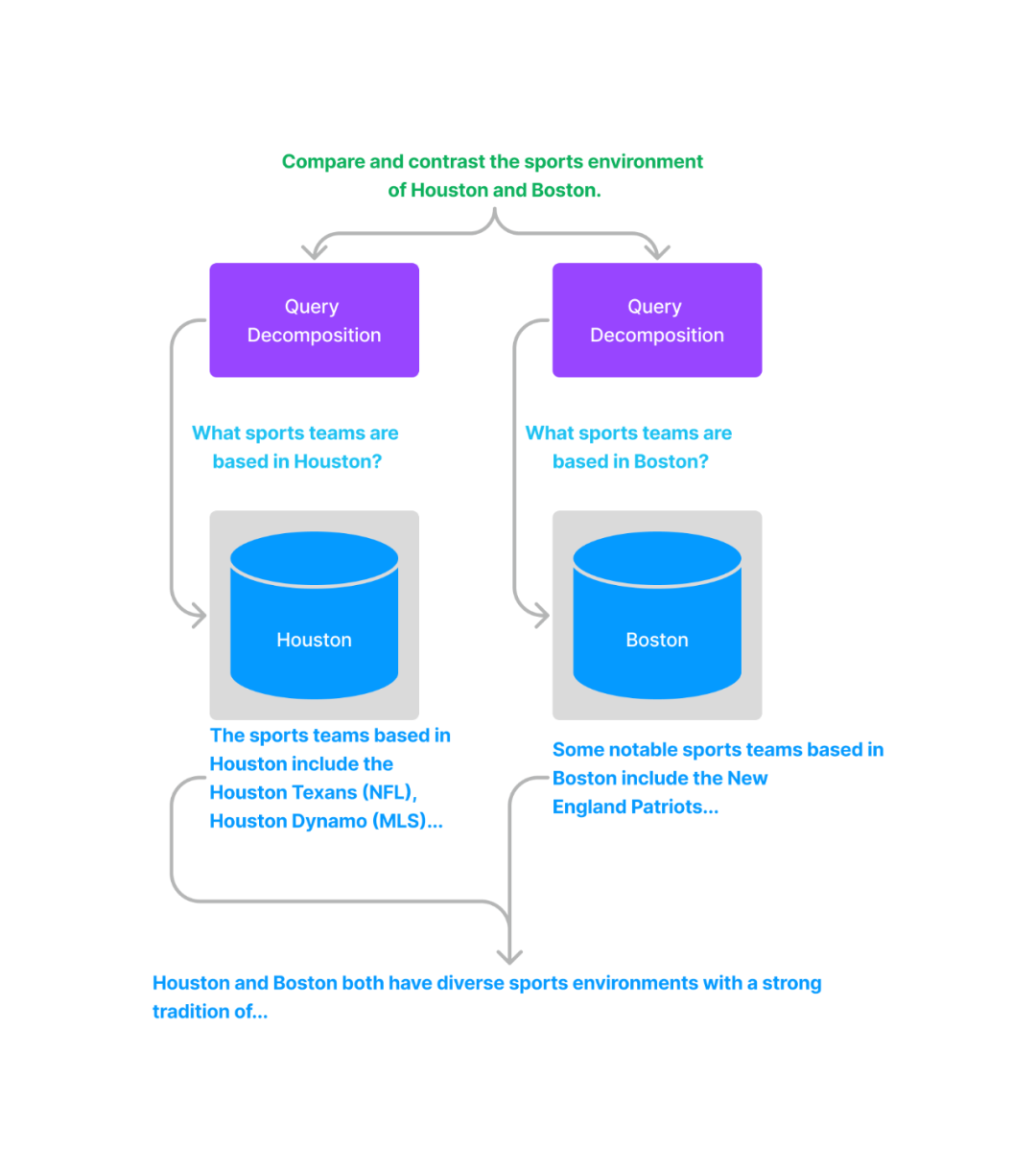
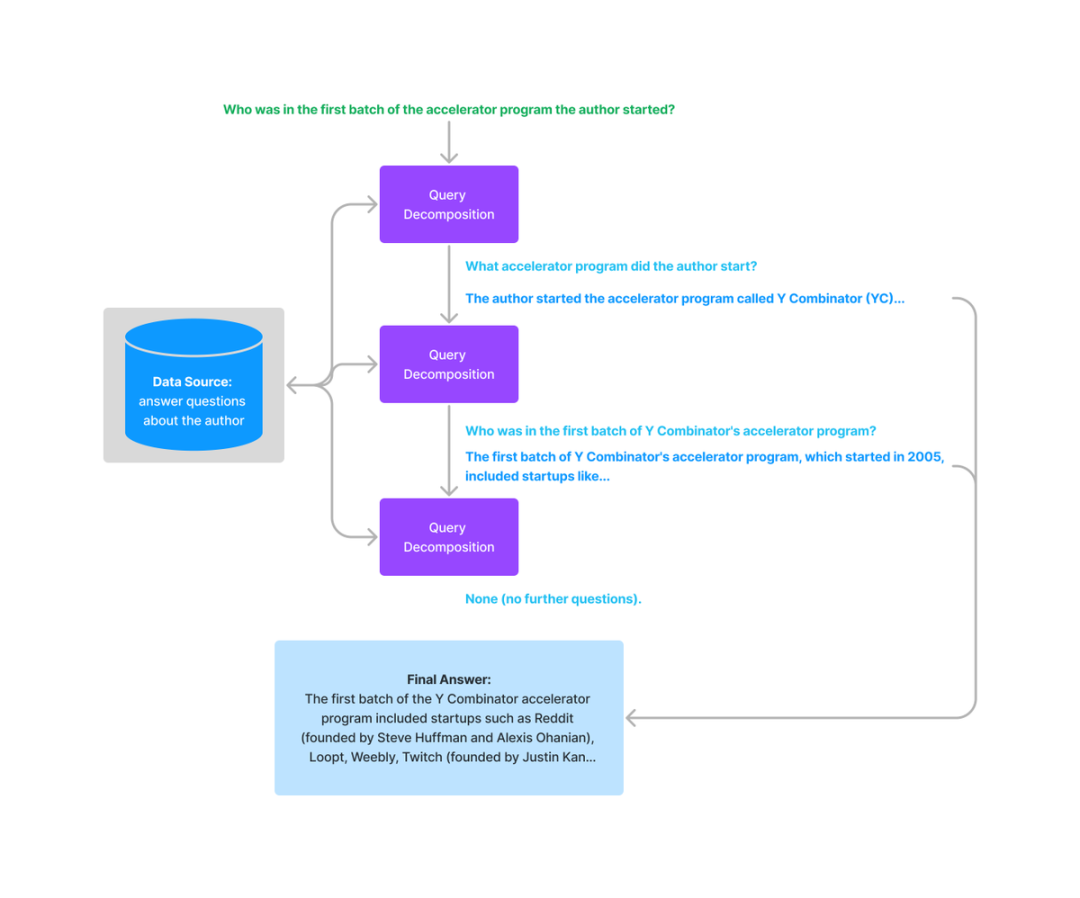
對(duì)于多步分解,給定初始的復(fù)雜查詢,會(huì)一步一步地轉(zhuǎn)換成多個(gè)子查詢,結(jié)合前一步的回復(fù)結(jié)果生成下一步的查詢問題,直到問不出更多問題為止。最后結(jié)合每一步的回復(fù)生成最終的結(jié)果。
變換三: HyDE
HyDE[32],全稱叫 Hypothetical Document Embeddings,給定初始查詢,首先利用 LLM 生成一個(gè)假設(shè)的文檔或者回復(fù),然后以這個(gè)假設(shè)的文檔或者回復(fù)作為新的查詢進(jìn)行檢索,而不是直接使用初始查詢。這種轉(zhuǎn)換在沒有上下文的情況下可能會(huì)生成一個(gè)誤導(dǎo)性的假設(shè)文檔或者回復(fù),從而可能得到一個(gè)和原始查詢不相關(guān)的錯(cuò)誤回復(fù)。下面是論文中給出的一個(gè)例子:

排序和后處理
經(jīng)過前面的檢索過程可能會(huì)得到很多相關(guān)文檔,就需要進(jìn)行篩選和排序。常用的篩選和排序策略包括:
-
基于相似度分?jǐn)?shù)進(jìn)行過濾和排序
-
基于關(guān)鍵詞進(jìn)行過濾,比如限定包含或者不包含某些關(guān)鍵詞
-
讓 LLM 基于返回的相關(guān)文檔及其相關(guān)性得分來重新排序
-
基于時(shí)間進(jìn)行過濾和排序,比如只篩選最新的相關(guān)文檔
-
基于時(shí)間對(duì)相似度進(jìn)行加權(quán),然后進(jìn)行排序和篩選
回復(fù)生成模塊
回復(fù)生成策略
檢索模塊基于用戶查詢檢索出相關(guān)的文本塊,回復(fù)生成模塊讓 LLM 利用檢索出的相關(guān)信息來生成對(duì)原始查詢的回復(fù)。LlamaIndex 中有給出一些不同的回復(fù)生成策略。
一種策略是依次結(jié)合每個(gè)檢索出的相關(guān)文本塊,每次不斷修正生成的回復(fù)。這樣的話,有多少個(gè)獨(dú)立的相關(guān)文本塊,就會(huì)產(chǎn)生多少次的 LLM 調(diào)用。另一種策略是在每次 LLM 調(diào)用時(shí),盡可能多地在 Prompt 中填充文本塊。如果一個(gè) Prompt 中填充不下,則采用類似的操作構(gòu)建多個(gè) Prompt,多個(gè) Prompt 的調(diào)用可以采用和前一種相同的回復(fù)修正策略。
回復(fù)生成 Prompt 模板
下面是 LlamaIndex 中提供的一個(gè)生成回復(fù)的 Prompt 模板。從這個(gè)模板中可以看到,可以用一些分隔符 ( 比如 ——— ) 來區(qū)分相關(guān)信息的文本,還可以指定 LLM 是否需要結(jié)合它自己的知識(shí)來生成回復(fù),以及當(dāng)提供的相關(guān)信息沒有幫助時(shí),要不要回復(fù)等。
template = f'''
Context information is below.
---------------------
{context_str}
---------------------
Using both the context information and also using your own knowledge, answer the question: {query_str}
If the context isn't helpful, you can/don’t answer the question on your own.
'''
下面的 Prompt 模板讓 LLM 不斷修正已有的回復(fù)。
template = f'''
The original question is as follows: {query_str}
We have provided an existing answer: {existing_answer}
We have the opportunity to refine the existing answer (only if needed) with some more context below.
------------
{context_str}
------------
Using both the new context and your own knowledege, update or repeat the existing answer.
'''
04 案例分析和應(yīng)用
ChatGPT 檢索插件
ChatGPT 檢索插件 ChatGPT Retrieval Plugin[33] 是 OpenAI 官方給出的一個(gè)通過檢索來增強(qiáng) LLM 的范例,實(shí)現(xiàn)了讓 ChatGPT 訪問私有知識(shí)的一種途徑,其在 Github 上的開源倉庫短時(shí)間內(nèi)獲得了大量關(guān)注。下面是 ChatGPT 檢索插件內(nèi)部原理的一張示意圖(圖片來源: openai-chatgpt-retrieval-plugin-and-postgresql-on-azure[34])。
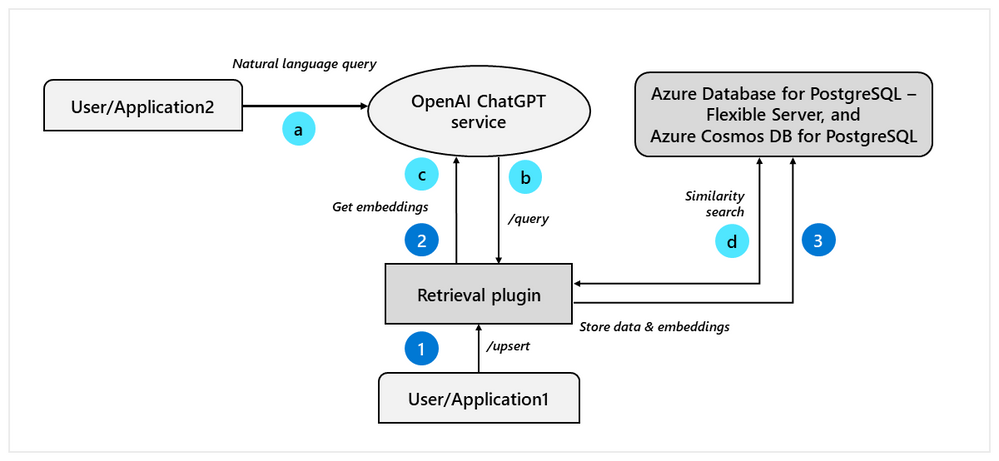
在 API 接口設(shè)計(jì)上,檢索插件提供了下面幾種接口:
-
/upsert: 該接口將上傳的一個(gè)或多個(gè)文本文檔,先切分成文本塊,每個(gè)文本塊大小在 200 個(gè) Token,然后利用 OpenAI 的 文本嵌入模型將文本塊轉(zhuǎn)換成向量,最后連同原始文本和元信息存儲(chǔ)在向量數(shù)據(jù)庫中,代碼倉庫中實(shí)現(xiàn)了對(duì)幾乎所有主流向量類數(shù)據(jù)庫的支持。 -
/upsert-file: 該接口允許上傳 PDF、TXT、DOCX、PPTX 和 MD 格式的單個(gè)文件,先轉(zhuǎn)換成純文本后,后續(xù)處理流程和/upsert接口一樣。 -
/query: 該接口實(shí)現(xiàn)對(duì)給定的查詢,返回和查詢最相關(guān)的幾個(gè)文本塊,實(shí)現(xiàn)原理也是基于相似向量檢索。用戶可以在請(qǐng)求中通過filter參數(shù)對(duì)文檔進(jìn)行過濾,通過top_k參數(shù)指定返回的相關(guān)文本塊數(shù)量。 -
/delete: 該接口實(shí)現(xiàn)從向量數(shù)據(jù)庫中對(duì)一個(gè)或多個(gè)文檔進(jìn)行刪除操作。
LlamaIndex 和 LangChain
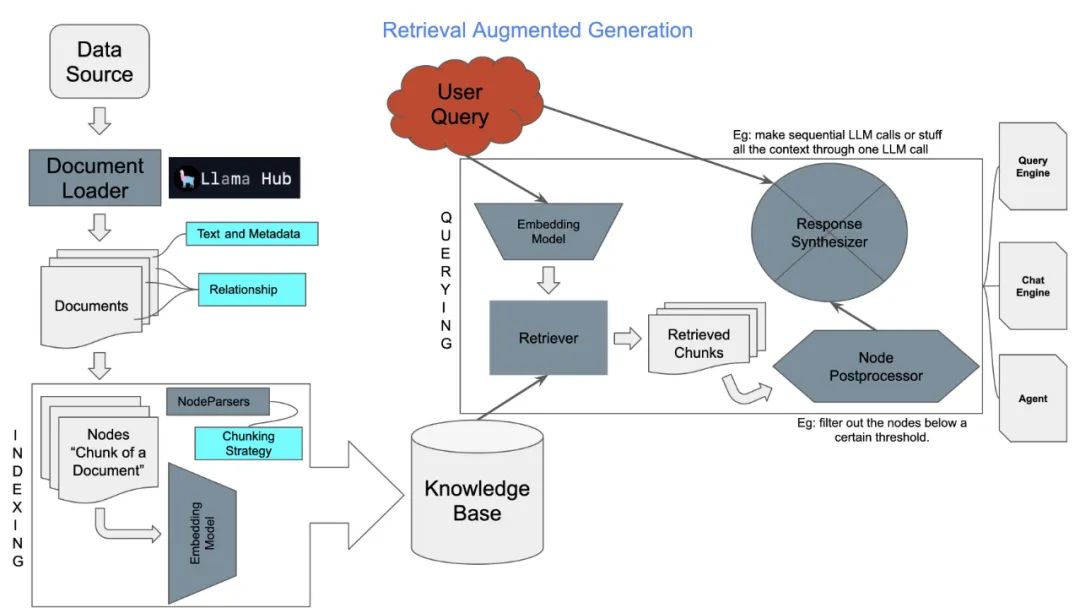
LlamaIndex[35] 是一個(gè)服務(wù)于 LLM 應(yīng)用的數(shù)據(jù)框架,提供外部數(shù)據(jù)源的導(dǎo)入、結(jié)構(gòu)化、索引、查詢等功能,這篇文章的結(jié)構(gòu)和內(nèi)容有很大一部分是參考 LlamaIndex 的文檔,文章中提到的很多模塊、算法和策略,LlamaIndex 基本都有對(duì)應(yīng)的實(shí)現(xiàn),提供了相關(guān)的高階和低階 API。
LlamaIndex 主要包含以下組件和特性:
-
數(shù)據(jù)連接器:能從多種數(shù)據(jù)源中導(dǎo)入數(shù)據(jù),有個(gè)專門的項(xiàng)目 Llama Hub[36],可以連接多種來源的數(shù)據(jù)
-
數(shù)據(jù)索引:支持對(duì)讀取的數(shù)據(jù)進(jìn)行多種不同的索引,便于后期的檢索
-
查詢和對(duì)話引擎:既支持單輪形式的查詢交互引擎,也支持多輪形式的對(duì)話交互引擎
-
應(yīng)用集成:可以方便地與一些流行的應(yīng)用進(jìn)行集成,比如 ChatGPT、LangChain、Flask、Docker等
下面是 LlamaIndex 整體框架的一張示意圖。
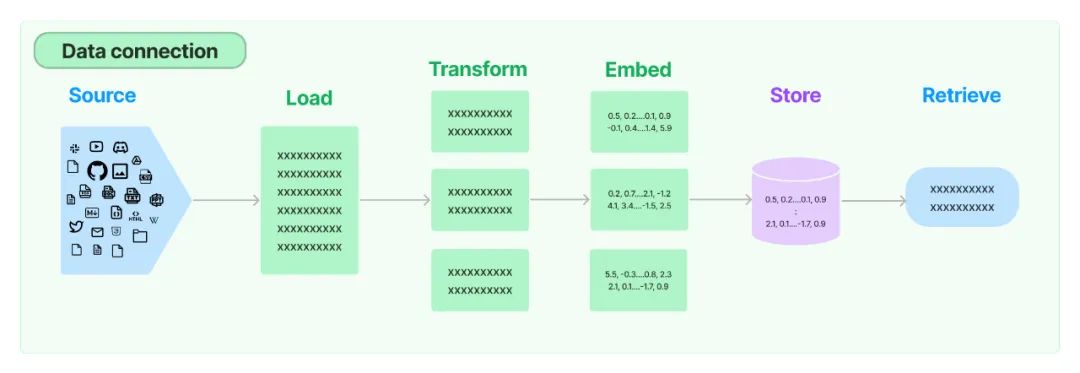
除了 LlamaIndex,LangChain[37] 也是當(dāng)前流行的一種 LLM 應(yīng)用開發(fā)框架,其中也包含一些檢索增強(qiáng) LLM 的相關(guān)組件,不過相比較而言,LlamaIndex 更側(cè)重于檢索增強(qiáng) LLM 這一相對(duì)小的領(lǐng)域,而 LangChain 覆蓋的領(lǐng)域更廣,比如會(huì)包含 LLM 的鏈?zhǔn)綉?yīng)用、Agent 的創(chuàng)建和管理等。下面這張圖就是 LangChain 中 Retrieval[38] 模塊的整體流程示意圖,包含數(shù)據(jù)加載、變換、嵌入、向量存儲(chǔ)和檢索,整體處理流程和 LlamaIndex 是一樣的。
Github Copilot 分析
Github Copilot[39] 是一款 AI 輔助編程工具。如果使用過就會(huì)發(fā)現(xiàn),Github Copilot 可以根據(jù)代碼的上下文來幫助用戶自動(dòng)生成或者補(bǔ)全代碼,有時(shí)候可能剛寫下類名或者函數(shù)名,又或者寫完函數(shù)注釋,Copilot 就給出了生成好的代碼,并且很多時(shí)候可能就是我們想要實(shí)現(xiàn)的代碼。由于 Github Copilot 沒有開源,網(wǎng)上有人對(duì)其 VSCode 插件進(jìn)行了逆向分析,比如 copilot internals[40] 和 copilot analysis[41],讓我們可以對(duì) Copilot 的內(nèi)部實(shí)現(xiàn)有個(gè)大概的了解。簡單來說,Github Copilot 插件會(huì)收集用戶在 VSCode 編程環(huán)境中的多種上下文信息構(gòu)造 Prompt,然后把構(gòu)造好的 Prompt 發(fā)送給代碼生成模型 ( 比如 Codex ),得到補(bǔ)全后的代碼,顯示在編輯器中。如何檢索出相關(guān)的上下文信息 ( Context ) 就是其中很重要的一個(gè)環(huán)節(jié)。Github Copilot 算是檢索增強(qiáng) LLM 在 AI 輔助編程方向的一個(gè)應(yīng)用。
需要說明的是,上面提到的兩份逆向分析是幾個(gè)月之前做的,Github Copilpot 目前可能已經(jīng)做了很多的更新和迭代,另外分析是原作者閱讀理解逆向后的代碼得到的,所以可能會(huì)產(chǎn)生一些理解上的偏差。而下面的內(nèi)容是我結(jié)合那兩份分析產(chǎn)生的,因此有些地方可能是不準(zhǔn)確甚至是錯(cuò)誤的,但不妨礙我們通過 Copilot 這個(gè)例子來理解上下文信息對(duì)增強(qiáng) LLM 輸出結(jié)果的重要性,以及學(xué)習(xí)一些上下文相關(guān)信息檢索的實(shí)踐思路。
下面是一個(gè) Prompt 的示例,可以看到包含前綴代碼信息 ( prefix ),后綴代碼信息 ( suffix ),生成模式 ( isFimEnabled ),以及 Prompt 不同組成元素的起始位置信息 ( promptElementRanges )。

拋開代碼生成模型本身的效果不談,Prompt 構(gòu)造的好壞很大程度上會(huì)影響代碼補(bǔ)全的效果,而上下文相關(guān)信息 ( Context ) 的提取和構(gòu)成很大程度上又決定了 Prompt 構(gòu)造的好壞。讓我們來看一下 Github Copilot 的 Prompt 構(gòu)造中有關(guān)上下文相關(guān)信息抽取的一些關(guān)鍵思路和實(shí)現(xiàn)。
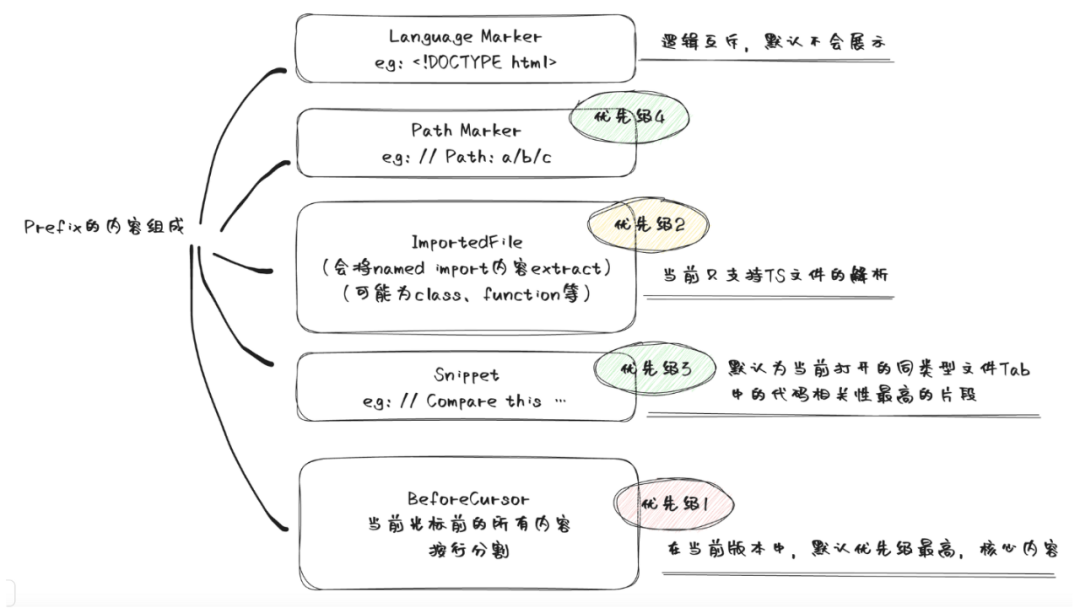
Copilot 的 Prompt 包含不同類型的相關(guān)信息,包括
-
BeforeCursor:光標(biāo)前的內(nèi)容 -
AfterCursor:光標(biāo)后的內(nèi)容 -
SimilarFile:與當(dāng)前文件相似度較高的代碼片段 -
ImportedFile:import 依賴 -
LanguageMarker:文件開頭的語言標(biāo)記 -
PathMarker:文件的相對(duì)路徑信息
其中相似代碼片段的抽取,會(huì)先獲取最近訪問過的多份同種語言的文件,作為抽取相似代碼片段的候選文檔。然后設(shè)定窗口大小 ( 比如默認(rèn)為 60 行 ) 和步長 ( 比如默認(rèn)為 1 行 ),以滑動(dòng)窗口的方式將候選文檔切分成代碼塊。接著計(jì)算每個(gè)切分后的代碼塊和當(dāng)前文件的相似度,最后保留相似度較高的幾個(gè)代碼塊。這里當(dāng)前文件的獲取是從當(dāng)前光標(biāo)往前截取窗口大小的內(nèi)容,相似度的度量采用的是 Jaccard 系數(shù),具體來說,會(huì)對(duì)代碼塊中的每一行進(jìn)行分詞,過濾常見的代碼關(guān)鍵字 ( 比如 if, then, else, for 這些),得到一個(gè)標(biāo)記 ( Token ) 集合,然后就可以在當(dāng)前代碼塊和候選代碼塊的 Token 集合之間計(jì)算 Jaccard 相似度。在 Copilot 的場(chǎng)景下,這種相似度的計(jì)算方式簡單有效。
$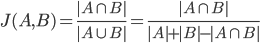 $
$
上面的一篇分析文章中將 Prompt 的組成總結(jié)成下面的一張圖。
構(gòu)造好 Prompt 后,Copilot 還會(huì)判斷是否有必要發(fā)起請(qǐng)求,代碼生成模型的計(jì)算是非常耗費(fèi)算力的,因此有必要過濾一些不必要的請(qǐng)求。其中一個(gè)判斷是利用簡單的線性回歸模型對(duì) Prompt 進(jìn)行打分,當(dāng)分?jǐn)?shù)低于某個(gè)閾值時(shí),請(qǐng)求就不會(huì)發(fā)出。這個(gè)線性回歸模型利用的特征包括像代碼語言、上一次代碼補(bǔ)全建議是否被采納或拒絕、上一次采納或拒絕距現(xiàn)在的時(shí)長、光標(biāo)左邊的字符等。通過分析模型的權(quán)重,原作者給出了一些觀察:
-
一些編程語言的權(quán)重相對(duì)于其他語言權(quán)重要更高 ( php > js > python > rust > … ),PHP 權(quán)重最高,果然 PHP是世界上最好的語言 ( ^_^ )。
-
右半邊括號(hào) ( 比如
),]) 的權(quán)重要低于左半邊括號(hào),這是符合邏輯的。
通過對(duì) Github Copilot 這個(gè)編程輔助工具的分析可以看到:
-
檢索增強(qiáng) LLM 的思路和技術(shù)在 Github Copilot 的實(shí)現(xiàn)中發(fā)揮著重要作用
-
上下文相關(guān)信息 ( Context ) 可以是一個(gè)廣義概念,可以是相關(guān)的文本或者代碼片段,也可以是文件路徑、相關(guān)依賴等,每個(gè)場(chǎng)景都可以定義其特定的上下文元素
-
相似性的度量和相似檢索方法可以因場(chǎng)景而異,不一定所有場(chǎng)景都需要用余弦相似度,都需要通過向量相似檢索的方式找出相關(guān)文檔,比如 Copilot 的實(shí)現(xiàn)中就利用簡單的 Jaccard 系數(shù)來計(jì)算分詞后 Token 集合的相似度,簡單高效。
文檔和知識(shí)庫的檢索與問答
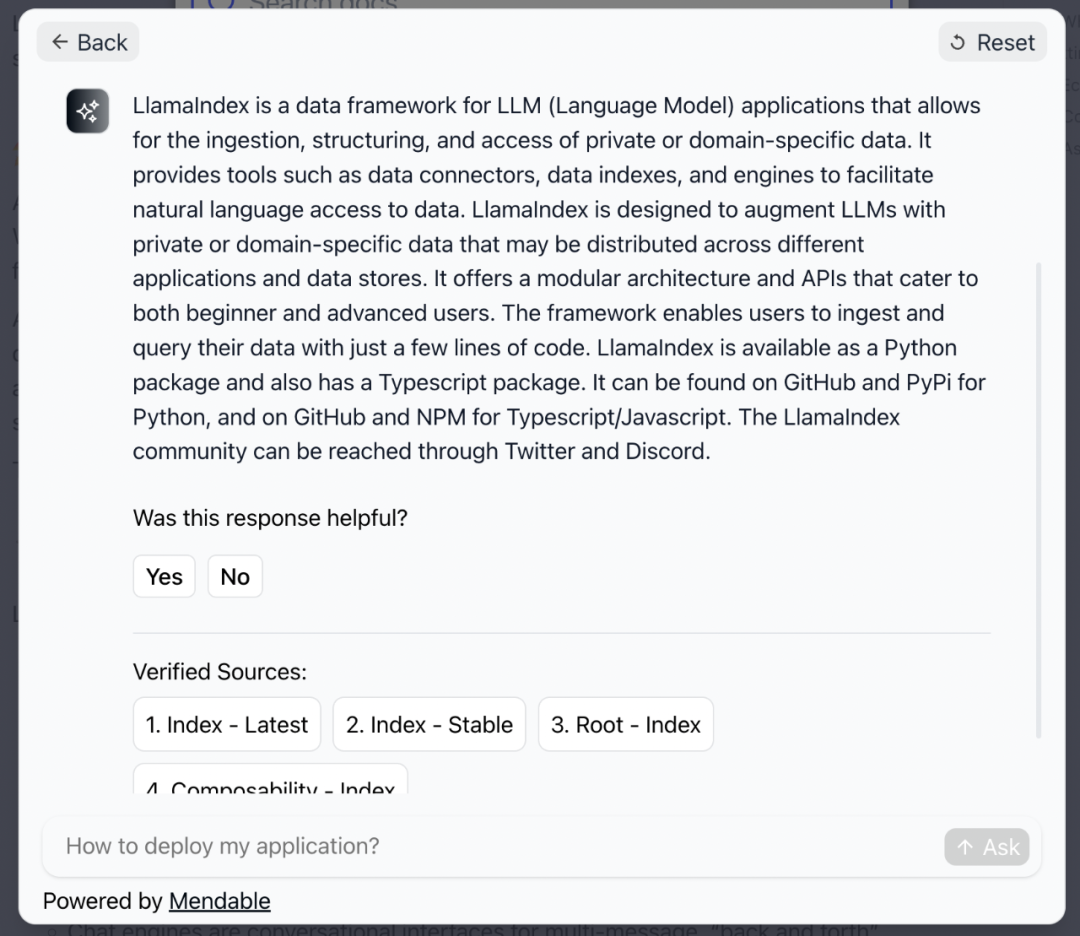
檢索增強(qiáng) LLM 技術(shù)的一個(gè)典型應(yīng)用是知識(shí)庫或者文檔問答,比如針對(duì)企業(yè)內(nèi)部知識(shí)庫或者一些文檔的檢索與問答等。這個(gè)應(yīng)用方向目前已經(jīng)出現(xiàn)了很多商業(yè)化和開源的產(chǎn)品。比如 Mendable[42] 就是一款商業(yè)產(chǎn)品,能提供基于文檔的 AI 檢索和問答能力。上面提到的 LlamaIndex 和 LangChain 項(xiàng)目官方文檔的檢索能力就是由 Mendable 提供的。下面就是一張使用截圖,可以看到 Mendable 除了會(huì)給出生成的回復(fù),也會(huì)附上參考鏈接。
除了商業(yè)產(chǎn)品,也有很多類似的開源產(chǎn)品。比如
-
Danswer[43]: 提供針對(duì)企業(yè)內(nèi)部文檔的問答功能,能實(shí)現(xiàn)多種來源的數(shù)據(jù)導(dǎo)入,支持傳統(tǒng)的檢索和基于 LLM 的問答,能智能識(shí)別用戶的搜索意圖,從而采用不同的檢索策略,支持用戶和文檔的權(quán)限管理,以及支持Docker部署等
-
PandaGPT[44]: 支持用戶上傳文件,然后可以針對(duì)文件內(nèi)容進(jìn)行提問
-
FastGPT[45]: 一個(gè)開源的基于 LLM 的 AI 知識(shí)庫問答平臺(tái)
-
Quivr[46]: 這個(gè)開源項(xiàng)目能實(shí)現(xiàn)用戶對(duì)個(gè)人文件或者知識(shí)庫的檢索和問答,期望成為用戶的「第二大腦」
-
ChatFiles[47]: 又一個(gè)基于 LLM 的文檔問答開源項(xiàng)目
下面這張圖是 ChatFiles 項(xiàng)目的技術(shù)架構(gòu)圖,可以發(fā)現(xiàn)這類項(xiàng)目的基本模塊和架構(gòu)都很類似,基本都遵從檢索增強(qiáng) LLM 的思路,這類知識(shí)庫問答應(yīng)用幾乎成為 LLM 領(lǐng)域的 Hello World 應(yīng)用了。
-
檢索
+關(guān)注
關(guān)注
0文章
27瀏覽量
13255 -
GitHub
+關(guān)注
關(guān)注
3文章
481瀏覽量
17441 -
LLM
+關(guān)注
關(guān)注
1文章
319瀏覽量
678
原文標(biāo)題:05 參考
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
基于ICL范式的LLM的最高置信度預(yù)測(cè)方案
《AI Agent 應(yīng)用與項(xiàng)目實(shí)戰(zhàn)》閱讀心得3——RAG架構(gòu)與部署本地知識(shí)庫
有沒有比較全面的介紹NI ASSISTANT的文章
【太實(shí)用了吧】非常全面的開關(guān)電源認(rèn)證技術(shù)介紹
可擴(kuò)展的對(duì)稱密文檢索架構(gòu)

關(guān)于遙感圖像檢索方案的簡單說明
檢索增強(qiáng)的語言模型方法的詳細(xì)剖析
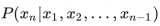
基于檢索的大語言模型簡介

什么是檢索增強(qiáng)生成?

Long-Context下LLM模型架構(gòu)全面介紹

如何利用OpenVINO加速LangChain中LLM任務(wù)
全面解析大語言模型(LLM)

什么是LLM?LLM的工作原理和結(jié)構(gòu)
- 設(shè)計(jì)技術(shù)
- 可編程邏輯
- 電源/新能源
- MEMS/傳感技術(shù)
- 測(cè)量儀表
- 嵌入式技術(shù)
- 制造/封裝
- 模擬技術(shù)
- RF/無線
- 接口/總線/驅(qū)動(dòng)
- 處理器/DSP
- EDA/IC設(shè)計(jì)
- 存儲(chǔ)技術(shù)
- 光電顯示
- EMC/EMI設(shè)計(jì)
- 連接器
- 行業(yè)應(yīng)用
- LEDs
- 汽車電子
- 音視頻及家電
- 通信網(wǎng)絡(luò)
- 醫(yī)療電子
- 人工智能
- 虛擬現(xiàn)實(shí)
- 可穿戴設(shè)備
- 機(jī)器人
- 安全設(shè)備/系統(tǒng)
- 軍用/航空電子
- 移動(dòng)通信
- 工業(yè)控制
- 便攜設(shè)備
- 觸控感測(cè)
- 物聯(lián)網(wǎng)
- 智能電網(wǎng)
- 區(qū)塊鏈
- 新科技
- 特色內(nèi)容
- 專欄推薦
- 學(xué)院
- 設(shè)計(jì)資源
- 設(shè)計(jì)技術(shù)
- 電子百科
- 電子視頻
- 元器件知識(shí)
- 工具箱
- VIP會(huì)員
- 最新技術(shù)文章
- 產(chǎn)品地圖
- 品牌地圖
- 社區(qū)
- 小組
- 論壇
- 問答
- 評(píng)測(cè)試用
- 企業(yè)服務(wù)
- 產(chǎn)品
- 資料
- 文章
- 方案
- 企業(yè)
- 供應(yīng)鏈服務(wù)
- 硬件開發(fā)
- 華秋電路
- 華秋商城
- 華秋智造
- nextPCB
- BOM配單
- 媒體服務(wù)
- 網(wǎng)站廣告
- 在線研討會(huì)
- 活動(dòng)策劃
- 新聞發(fā)布
- 新品發(fā)布
- 小測(cè)驗(yàn)
- 設(shè)計(jì)大賽
- 華秋
- 關(guān)于我們
- 投資關(guān)系
- 新聞動(dòng)態(tài)
- 加入我們
- 聯(lián)系我們
- 舉報(bào)投訴
- 社交網(wǎng)絡(luò)
- 微博
- 移動(dòng)端
- 發(fā)燒友APP
- 硬聲APP
- WAP
- 聯(lián)系我們
- 廣告合作
- 王婉珠:[email protected]
- 內(nèi)容合作
- 黃晶晶:[email protected]
- 內(nèi)容合作(海外)
- 張迎輝:[email protected]
- 供應(yīng)鏈服務(wù) PCB/IC/PCBA
- 江良華:[email protected]
- 投資合作
- 曾海銀:[email protected]
- 社區(qū)合作
- 劉勇:[email protected]
-
關(guān)注我們的微信

-
下載發(fā)燒友APP

-
電子發(fā)燒友觀察



版權(quán)所有 ? 湖南華秋數(shù)字科技有限公司
長沙市望城經(jīng)濟(jì)技術(shù)開發(fā)區(qū)航空路6號(hào)手機(jī)智能終端產(chǎn)業(yè)園2號(hào)廠房3層(0731-88081133)
電子發(fā)燒友 (電路圖) 湘公網(wǎng)安備43011202000918 工商網(wǎng)監(jiān)
湘ICP備2023018690號(hào)-1
工商網(wǎng)監(jiān)
湘ICP備2023018690號(hào)-1
評(píng)論