") 內(nèi)存架構演進:CXL與RDMA的協(xié)同發(fā)展
內(nèi)存架構演進:CXL與RDMA的協(xié)同發(fā)展
隨著第一代芯片的發(fā)布,圍繞CXL的早期炒作逐漸被現(xiàn)實的性能期望所取代。與此同時,關于內(nèi)存分層的軟件支持正在不斷發(fā)展,借鑒了NUMA和持久內(nèi)存方面的先前工作。最后,運營商已經(jīng)部署了RDMA以實現(xiàn)存儲分離和高性能工作負載。由于這些進步,主內(nèi)存分離現(xiàn)在已經(jīng)成為可能。
分層解決內(nèi)存危機
隨著近期AMD和Intel服務器處理器的推出,內(nèi)存分層技術正取得重大進展。無論是AMD的新EPYC(代號Genoa)還是Intel的新Xeon Scalable(代號Sapphire Rapids),都引入了CXL,標志著新的內(nèi)存互連架構的開始。第一代支持CXL的處理器處理的是規(guī)范的1.1版本,然而CXL聯(lián)盟在2022年8月發(fā)布了3.0版本的規(guī)范。
當CXL推出時,關于主內(nèi)存分離的夸張言論出現(xiàn)了,忽略了訪問和傳輸延遲的現(xiàn)實情況。隨著第一代CXL芯片現(xiàn)已發(fā)貨,客戶需要處理軟件適應分層要求的問題。運營商或供應商還必須開發(fā)編排軟件來管理池化和共享內(nèi)存。與軟件同時進行的是,CXL硬件生態(tài)系統(tǒng)將需要數(shù)年的時間來充分發(fā)展,特別是包括CPU、GPU、交換機和內(nèi)存擴展器在內(nèi)的CXL 3.x組件。最終,CXL承諾將演變成一個真正的架構,可以將CPU和GPU連接到共享內(nèi)存,但網(wǎng)絡連接的內(nèi)存仍然具有一定的作用。
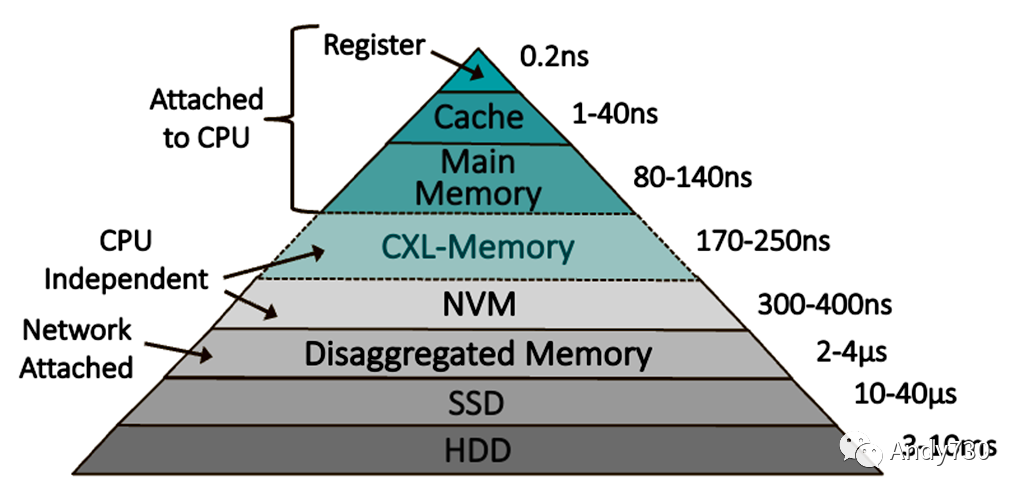
圖1. 內(nèi)存層次結構
正如圖1所示,內(nèi)存層次正在變得更加精細,以換取訪問延遲和容量以及靈活性之間的平衡。金字塔的頂部是性能層,需要將熱數(shù)據(jù)存儲以獲得最大性能。冷數(shù)據(jù)可以降級為容量層,傳統(tǒng)上由存儲設備提供服務。然而,在近年來,開發(fā)人員已經(jīng)優(yōu)化了軟件,以在多插槽服務器中不同NUMA域中以及在持久(非易失性)內(nèi)存(例如Intel的Optane)中存放頁面時提高性能。雖然Intel停止了Optane的開發(fā),但其大量的軟件投資仍然適用于CXL連接的內(nèi)存。
將內(nèi)存頁面交換到固態(tài)硬盤會引發(fā)嚴重的性能損失,從而為新的基于DRAM的容量層創(chuàng)造了機會。有時被稱為“遠程內(nèi)存”,這種DRAM可以存在于另一臺服務器或內(nèi)存設備中。在過去的二十年中,軟件開發(fā)人員推進了基于網(wǎng)絡的交換的概念,該概念使得服務器能夠訪問網(wǎng)絡上另一臺服務器中的遠程內(nèi)存。通過使用支持遠程DMA(RDMA)的網(wǎng)卡,系統(tǒng)架構師可以將訪問網(wǎng)絡連接的內(nèi)存的延遲降低到不到4微秒,如圖1所示。因此,與傳統(tǒng)的將數(shù)據(jù)交換到存儲進行交換相比,通過網(wǎng)絡交換可以顯著提高某些工作負載的性能。
內(nèi)存擴展推動了CXL的導入
雖然CXL只有三年多的歷史,但已經(jīng)取得了超過之前的相干互連標準(如CCIX、OpenCAPI和HyperTransport)的行業(yè)支持。關鍵是,盡管Intel是原始規(guī)范的開發(fā)者,但AMD仍然支持并實現(xiàn)了CXL。
不斷增長的CXL生態(tài)系統(tǒng)包括將DDR4或DDR5 DRAM連接到支持CXL的服務器(或主機)的內(nèi)存控制器(或擴展器)。CXL早期導入的一個重要因素是它重新使用了PCIe物理層,實現(xiàn)了I/O的靈活性,同時不增加處理器引腳數(shù)。這種靈活性延伸到了插卡和模塊,這些插卡和模塊使用與PCIe設備相同的插槽。對于服務器設計者來說,添加CXL支持只需要最新的EPYC或Xeon處理器,并注意PCIe通道的分配情況。
CXL規(guī)范定義了三種不同用例所需的三種設備類型和三種協(xié)議。在這里,我們將重點放在用于內(nèi)存擴展的Type 3設備上,以及用于緩存一致性內(nèi)存訪問的CXL.mem協(xié)議上。所有三種設備類型都需要CXL.io協(xié)議,但Type 3設備只在配置和控制方面使用它。與CXL.io和PCIe相比,CXL.mem協(xié)議棧使用不同的鏈路和事務層。關鍵區(qū)別在于,CXL.mem(和CXL.cache)采用固定長度的消息,而CXL.io使用類似PCIe的可變長度數(shù)據(jù)包。在1.1和2.0版本中,CXL.mem使用68字節(jié)的流控單元(flit),處理64字節(jié)的緩存行。CXL 3.0采用了PCIe 6.0中引入的256字節(jié)flit,以適應前向糾錯(FEC),但還添加了一個將錯誤檢查(CRC)分成兩個128字節(jié)塊的延遲優(yōu)化flit。
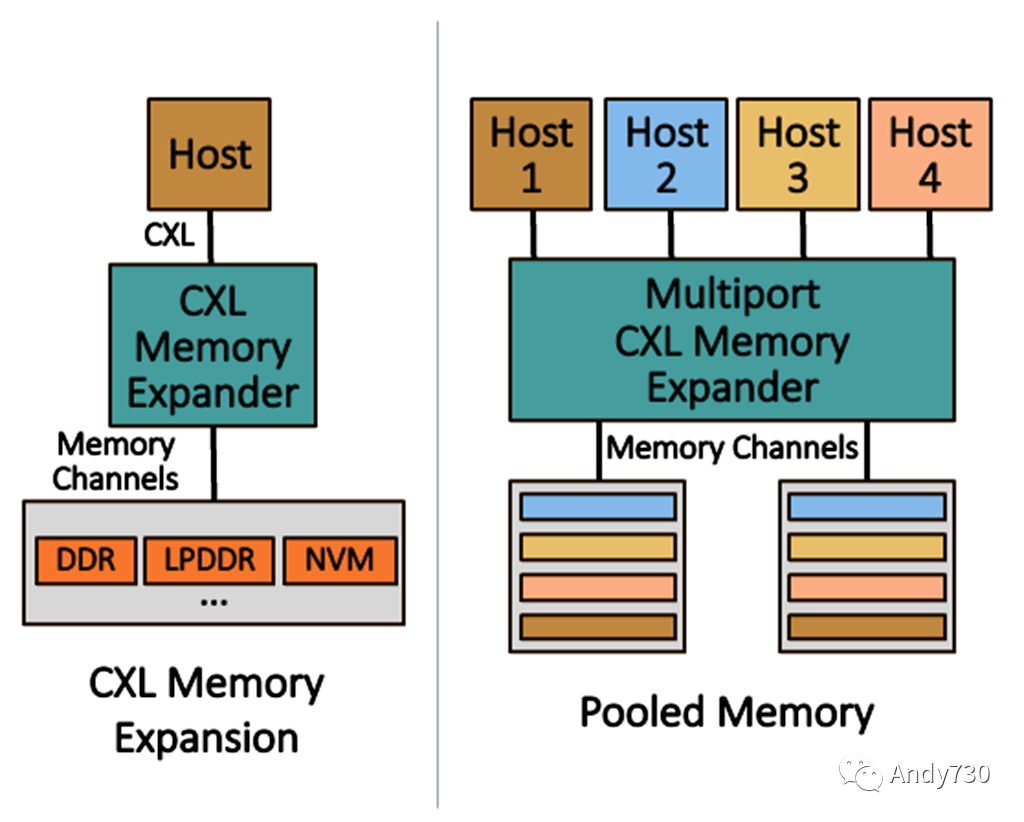
圖2. CXL 1.1/2.0 應用案例
從根本上講,CXL.mem為PCIe接口引入了加載/存儲語義,實現(xiàn)了內(nèi)存帶寬和容量的擴展。如圖2所示,第一個CXL用例圍繞著內(nèi)存擴展展開,從單主機配置開始。最簡單的示例是CXL內(nèi)存模塊,例如Samsung的512GB DDR5內(nèi)存擴展器,具有一個PCIe Gen5 x8接口,采用EDSFF外形尺寸。該模塊使用來自Montage Technology的CXL內(nèi)存控制器,供應商聲稱支持CXL 2.0。同樣,Astera Labs提供了一個帶有CXL 2.0 x16接口的DDR5控制器芯片。該公司開發(fā)了一個PCIe插卡,將其Leo控制器芯片與四個RDIMM插槽相結合,處理高達合計2TB的DDR5 DRAM。
連接到CXL的DRAM的未加載訪問延遲應該比連接到處理器集成內(nèi)存控制器的DRAM大約100納秒。內(nèi)存通道顯示為單一邏輯設備(SLD),可以分配給一個單一的主機。使用單個處理器和SLD進行內(nèi)存擴展代表了CXL內(nèi)存性能的最佳情況,假設直接連接,沒有中間設備或?qū)樱缰?a href="http://www.asorrir.com/tags/定時器/" target="_blank">定時器和交換機。
下一個用例是池化內(nèi)存,它可以將內(nèi)存區(qū)域靈活地分配給特定的主機。在池化中,內(nèi)存只分配給并且只能被單一主機訪問,即一個內(nèi)存區(qū)域不會被多個主機同時共享。當將多個處理器或服務器連接到內(nèi)存池時,CXL可以采用兩種方法。原始方法是在主機和一個或多個擴展器(Type 3設備)之間添加CXL交換組件。這種方法的缺點是交換機會增加延遲,我們估計大約為80納秒。盡管客戶可以設計這樣的系統(tǒng),但我們不認為這種用例會取得高量級的采用,因為增加的延遲會降低系統(tǒng)性能。
相反,另一種方法是使用多頭(MH)擴展器將少量主機直接連接到內(nèi)存池,如圖2中央所示。例如,初創(chuàng)公司Tanzanite Silicon Solutions在被Marvell收購之前展示了一個基于FPGA的原型,擁有四個頭部,后來披露將推出具有8個x8主機端口的芯片。這些多頭控制器可以成為一個內(nèi)存設備的核心,為少量服務器提供一池DRAM。然而,直到CXL 3.0之前,管理MH擴展器的命令接口并沒有標準化,這意味著早期的演示使用了專有的結構管理。
CXL 3.x實現(xiàn)了共享內(nèi)存結構
盡管CXL 2.0可以實現(xiàn)小規(guī)模的內(nèi)存池,但它有許多限制。在拓撲結構方面,它僅限于16個主機和單層交換器層次結構。對于連接GPU和其它加速器來說更重要的是,每個主機只支持一個Type 2設備,這意味著CXL 2.0不能用于構建一個一致性GPU服務器。CXL 3.0允許每個主機支持多達16個加速器,使其成為用于GPU的標準一致性互連。它還增加了點對點(P2P)通信、多級交換和最多4,096個節(jié)點的結構。
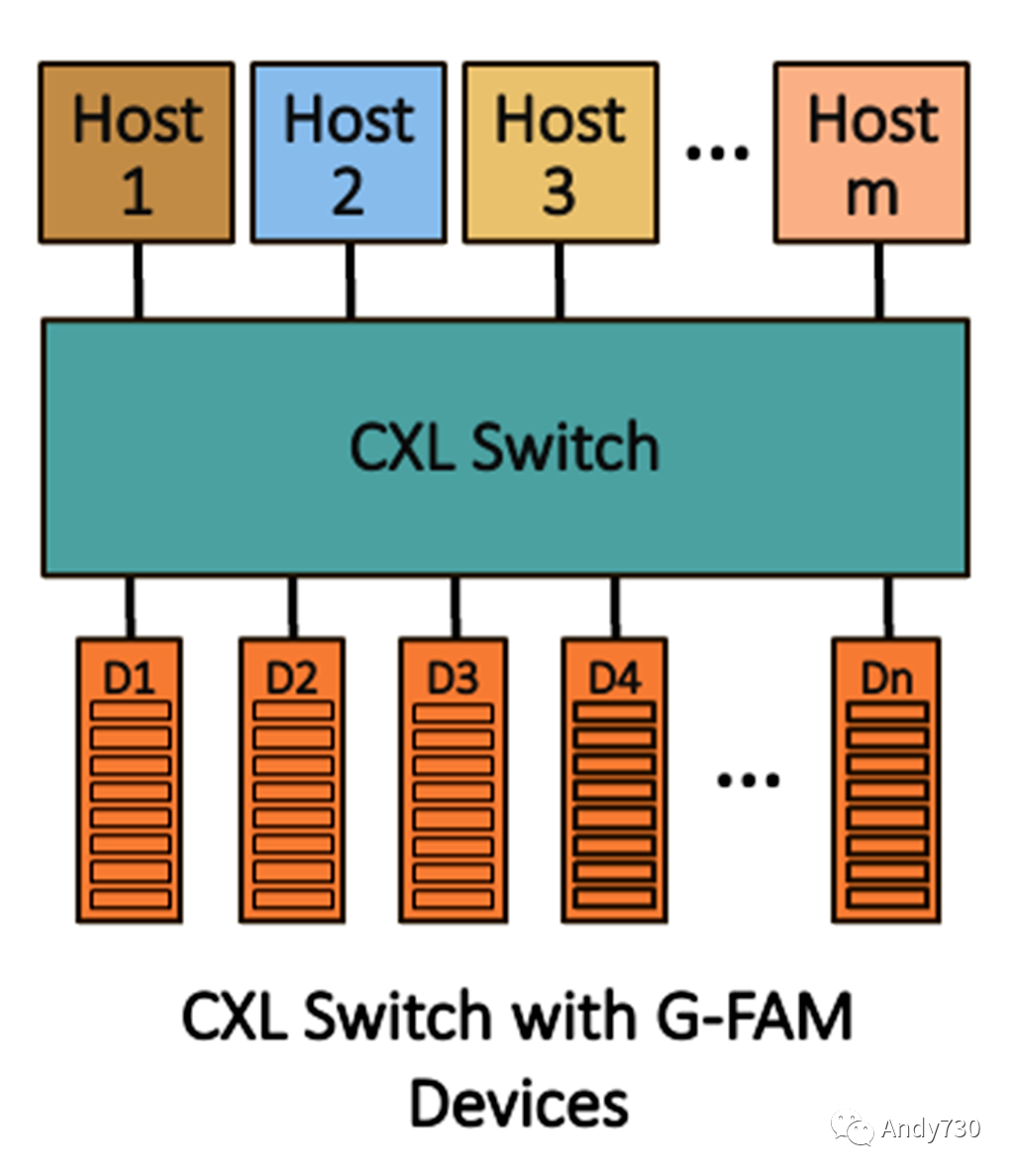
圖3. CXL 3.X 共享內(nèi)存
雖然內(nèi)存池化可以實現(xiàn)將DRAM靈活分配給服務器,但CXL 3.0可以實現(xiàn)真正的共享內(nèi)存。共享內(nèi)存擴展器被稱為全局布局附加內(nèi)存(G-FAM)設備,它允許多個主機或加速器共同共享內(nèi)存區(qū)域。3.0規(guī)范還為更精細的內(nèi)存分配添加了最多8個動態(tài)容量(DC)區(qū)域。圖3展示了一個簡單的示例,使用單個交換機將任意數(shù)量的主機連接到共享內(nèi)存。在這種情況下,主機或設備可能會管理緩存一致性。
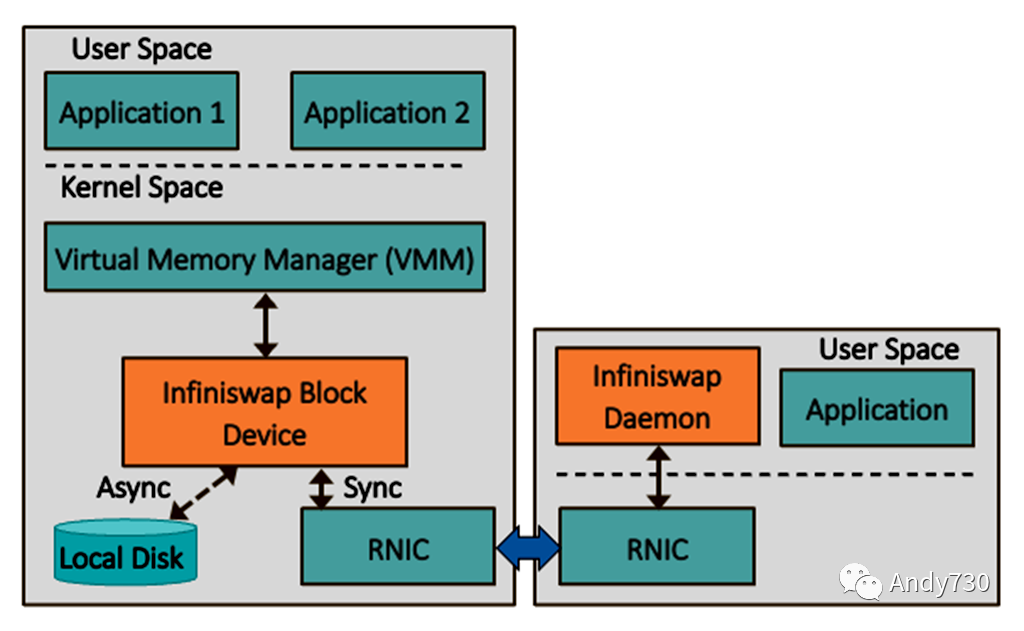
圖4. 以太網(wǎng)上的內(nèi)存交換
然而,為了使加速器可以直接訪問共享內(nèi)存,擴展器必須實現(xiàn)帶有回收失效的一致性(HDM-DB),這是3.0規(guī)范中新增的。換句話說,要使CXL連接的GPU可以共享內(nèi)存,擴展器必須實現(xiàn)包含性嗅探過濾器。這種方法引入了潛在的阻塞,因為規(guī)范對某些CXL.mem事務強制執(zhí)行嚴格的順序。共享內(nèi)存結構會出現(xiàn)擁塞,導致不太可預測的延遲和更大的尾延遲的可能性。盡管規(guī)范包括QoS遙測功能,基于主機的速率限制是可選的,而且這些能力在實踐中尚未得到驗證。
RDMA實現(xiàn)遠程內(nèi)存
隨著CXL結構在規(guī)模和異構性上的增長,性能問題也在擴大。例如,在解耦式機架的每個架子上放置一個交換機是一種優(yōu)雅的方法,但它會在不同資源(計算、內(nèi)存、存儲和網(wǎng)絡)之間的每次事務中增加一個交換機跳數(shù)。擴展到集群和更大規(guī)模會增加鏈路延遲的挑戰(zhàn),甚至傳輸延遲也變得有意義。當多個因素導致延遲超過600納秒時,系統(tǒng)可能會出現(xiàn)錯誤。最后,盡管對于小事務而言,加載/存儲語義很有吸引力,但對于頁面交換或虛擬機遷移等大規(guī)模數(shù)據(jù)傳輸來說,DMA通常更高效。
最終,一致性域的范圍只需要擴展到一定程度。超出CXL的實際限制,以太網(wǎng)可以滿足對高容量分離內(nèi)存的需求。從數(shù)據(jù)中心的角度來看,以太網(wǎng)的覆蓋范圍是無限的,超大規(guī)模的超大規(guī)模企業(yè)已經(jīng)將RDMA-over-Ethernet(RoCE)網(wǎng)絡擴展到數(shù)千個服務器節(jié)點。然而,運營商已經(jīng)部署了這些大型RoCE網(wǎng)絡,用于使用SSD進行存儲分離,而不是DRAM。
圖3展示了內(nèi)存RDMA交換的一個示例實現(xiàn),即密歇根大學的Infiniswap設計。研究人員的目標是將閑置內(nèi)存在服務器之間進行分離,解決內(nèi)存未充分利用的問題,也稱為閑置。他們的方法使用現(xiàn)成的RDMA硬件(RNIC),避免了應用程序的修改。系統(tǒng)軟件使用Infiniswap塊設備,對虛擬內(nèi)存管理器(VMM)而言,它類似于傳統(tǒng)存儲。VMM將Infiniswap設備處理為交換分區(qū),就像使用本地SSD分區(qū)進行頁面交換一樣。
目標服務器在用戶空間運行一個Infiniswap守護進程,僅處理將本地內(nèi)存映射到遠程塊設備。一旦內(nèi)存被映射,讀寫請求將繞過目標服務器的CPU,使用RDMA進行傳輸,從而實現(xiàn)零開銷的數(shù)據(jù)平面。在研究人員的系統(tǒng)中,每個服務器都加載了兩個軟件組件,以便它們可以同時充當請求方和目標方,但這個概念也可以擴展到僅充當目標方的內(nèi)存設備。
密歇根大學團隊使用56Gbps InfiniBand RNIC構建了一個32節(jié)點集群,盡管以太網(wǎng)RNIC應該可以完全運行。他們測試了幾個內(nèi)存密集型應用程序,包括運行TPC-C基準測試的VoltDB和運行Facebook工作負載的Memcached。在只有50%的工作集存儲在本地DRAM中,其余由網(wǎng)絡交換提供支持的情況下,VoltDB和Memcached分別提供了66%和77%的性能,與完整工作集存儲在本地DRAM中的性能相比。
通往內(nèi)存網(wǎng)絡的漫長道路
云數(shù)據(jù)中心成功地將存儲和網(wǎng)絡功能從CPU分離出來,但主內(nèi)存的分離仍然難以實現(xiàn)。十年前,Intel的機架規(guī)模架構路線圖上有關于內(nèi)存池化的計劃,但從未實現(xiàn)。Gen-Z聯(lián)盟于2016年成立,追求內(nèi)存為中心的結構架構,但系統(tǒng)設計僅達到了原型階段。歷史告訴我們,隨著行業(yè)標準增加復雜性和可選功能,它們被大規(guī)模采用的可能性降低。CXL提供了沿著架構演進路徑的增量步驟,允許技術迅速發(fā)展,同時提供未來迭代,承諾實現(xiàn)真正的可組合系統(tǒng)。
從內(nèi)存擴展中受益的工作負載包括SAP HANA和Redis等內(nèi)存數(shù)據(jù)庫、Memcached等內(nèi)存緩存、大型虛擬機,以及必須處理日益增長的大型語言模型的AI訓練和推斷。當這些工作負載的工作集不能完全適應本地DRAM時,它們的性能會急劇下降。內(nèi)存池化可以緩解閑置內(nèi)存問題,這影響了超大規(guī)模數(shù)據(jù)中心運營商的資本支出。微軟在2022年3月的一篇論文中詳細介紹的研究發(fā)現(xiàn),在高度利用的Azure集群中,高達25%的服務器DRAM被閑置。該公司對不同數(shù)量的CPU插槽進行了內(nèi)存池化建模,并估計它可以將整體DRAM需求減少約10%。
在目前的GPU市場動態(tài)下,純粹采用CXL 3.x結構的情況不太具有說服力,部分原因是GPU市場的動態(tài)。目前來自Nvidia、AMD和Intel的數(shù)據(jù)中心GPU在GPU與GPU之間的通信中實現(xiàn)了專有的一致性互連,同時還使用PCIe與主機進行連接。Nvidia的頂級Tesla GPU已經(jīng)支持通過專有的NVLink接口進行內(nèi)存池化,解決了高帶寬內(nèi)存(HBM)的閑置內(nèi)存問題。市場領導者可能會更青睞NVLink,但它也可能通過共享(serdes)的方式支持CXL。類似地,AMD和Intel未來的GPU可能會在Infinity和Xe-Link之外采用CXL。然而,由于沒有公開的GPU支持,對于CXL 3.0先進功能的采用存在不確定性,而對于現(xiàn)有用例轉(zhuǎn)向PCIe Gen6通道速率是無爭議的。無論如何,我們預計在2027年之前,CXL 3.x共享內(nèi)存擴展器將實現(xiàn)大規(guī)模出貨。
與此同時,多個超大規(guī)模數(shù)據(jù)中心運營商采用RDMA來處理存儲分離以及高性能計算。盡管在大規(guī)模部署RoCE方面存在挑戰(zhàn),但這些大客戶有能力解決性能和可靠性問題。他們可以將這種已部署和理解的技術擴展到新的場景,如基于網(wǎng)絡的內(nèi)存解耦。研究已經(jīng)證明,連接到網(wǎng)絡的容量層在將其應用于適當?shù)墓ぷ髫撦d時可以提供強大的性能。
我們將CXL和RDMA視為互補的技術,前者提供最大的帶寬和最低的延遲,而后者提供更大的規(guī)模。Enfabrica開發(fā)了一種稱為Accelerated Compute Fabric (ACF)的架構,將CXL/PCIe交換和RNIC功能合并為一個單一的設備。當在多太位(multi-terabit)芯片中實例化時,ACF可以連接一致性本地內(nèi)存,同時使用高達800G以太網(wǎng)端口跨機箱和機架進行擴展。關鍵是,這種方法消除了對將來需要多年才能進入市場的高級CXL功能的依賴。
數(shù)據(jù)中心運營商將采用多種路徑來實現(xiàn)內(nèi)存分離,因為每個運營商有不同的優(yōu)先事項和獨特的工作負載。那些有明確定義內(nèi)部工作負載的運營商可能會領先,而那些優(yōu)先考慮公有云實例的運營商可能會更加保守。早期使用者為那些可以解決特定客戶最迫切需求的供應商創(chuàng)造了機會。
-
芯片
+關注
關注
459文章
52205瀏覽量
436467 -
cpu
+關注
關注
68文章
11040瀏覽量
216047 -
服務器
+關注
關注
13文章
9702瀏覽量
87320 -
內(nèi)存
+關注
關注
8文章
3109瀏覽量
75006 -
RDMA
+關注
關注
0文章
82瀏覽量
9208
原文標題:內(nèi)存架構演進:CXL與RDMA的協(xié)同發(fā)展
文章出處:【微信號:SDNLAB,微信公眾號:SDNLAB】歡迎添加關注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
基于CXL的直接訪問高性能內(nèi)存分解框架
利用CXL技術重構基于RDMA的內(nèi)存解耦合
一窺CXL協(xié)議
一文解析CXL系統(tǒng)架構
CXL內(nèi)存協(xié)議介紹
DirectCXL內(nèi)存分解原型設計實現(xiàn)
陳海波:OpenHarmony技術領先,產(chǎn)學研深度協(xié)同,生態(tài)蓬勃發(fā)展
“5G+車聯(lián)網(wǎng)”的車路協(xié)同發(fā)展模式促進智能汽車與智慧城市協(xié)同發(fā)展
數(shù)字產(chǎn)業(yè)協(xié)同發(fā)展的意義和作用
數(shù)字產(chǎn)業(yè)協(xié)同發(fā)展的例子及主要內(nèi)容
訪問CXL 2.0設備中的內(nèi)存映射寄存器
多網(wǎng)協(xié)同發(fā)展探討

什么是內(nèi)存語義?CXL是如何劃分語義的

內(nèi)存擴展CXL加速發(fā)展,繁榮AI存儲






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論