") 使用 NVIDIA DOCA GPUNetIO 實(shí)現(xiàn)實(shí)時(shí)網(wǎng)絡(luò)處理功能
使用 NVIDIA DOCA GPUNetIO 實(shí)現(xiàn)實(shí)時(shí)網(wǎng)絡(luò)處理功能
GPU 提供的高度并行計(jì)算可以利用網(wǎng)絡(luò)流量的實(shí)時(shí)處理。在這些類型的應(yīng)用程序中,優(yōu)化的數(shù)據(jù)包獲取或傳輸可以避免瓶頸,并使整體執(zhí)行能夠跟上高速網(wǎng)絡(luò)的步伐。在這種情況下,DOCA GPUNetIO 將 GPU 提升為一個(gè)獨(dú)立的組件,可以在沒(méi)有 CPU 干預(yù)的情況下執(zhí)行網(wǎng)絡(luò)和計(jì)算任務(wù)。
本文提供了一個(gè) GPU 數(shù)據(jù)包處理應(yīng)用程序的列表,這些應(yīng)用程序雖然專注于不同和無(wú)關(guān)的場(chǎng)景,但都集成了NVIDIA DOCA GPUNetIO以降低延遲并最大限度地提高性能。
NVIDIA DOCA GPUNetIO API
NVIDIA DOCA GPUNetIO 是隨著 NVIDIA DOCA 軟件框架一起發(fā)布的新庫(kù)之一。DOCA GPUNetIO 庫(kù)通過(guò)一個(gè)或多個(gè) CUDA 內(nèi)核實(shí)現(xiàn)網(wǎng)卡和 GPU 之間的直接通信,從而將 CPU 從關(guān)鍵路徑中移除。
使用 DOCA GPUNetIO 庫(kù)中的 CUDA 設(shè)備函數(shù),CUDA 內(nèi)核可以直接向 GPU 發(fā)送和接收數(shù)據(jù)包,而無(wú)需 CPU 核心或內(nèi)存。此庫(kù)的主要功能包括:
-
GPUDirect 異步內(nèi)核啟動(dòng)的網(wǎng)絡(luò)(GPUDirect Async Kernel-Initiated Network,GDAKIN):是一種以太網(wǎng)通信,GPU(CUDA 內(nèi)核)在沒(méi)有 CPU 干預(yù)的情況下直接與網(wǎng)卡交互,并在 GPU 內(nèi)存(GPU Direct RDMA)中發(fā)送或接收數(shù)據(jù)包。
-
GPU 內(nèi)存暴露:在單個(gè)函數(shù)中結(jié)合利用 GDRCopy 庫(kù)的基本 CUDA 內(nèi)存分配功能,無(wú)需使用 CUDA API 即可將GPU 內(nèi)存緩沖區(qū)暴露給 CPU 進(jìn)行直接訪問(wèn)(讀或?qū)懀?/p>
-
準(zhǔn)確的發(fā)送調(diào)度:可以從 GPU 調(diào)度未來(lái)數(shù)據(jù)包突發(fā)的傳輸,將時(shí)間戳與之關(guān)聯(lián),并將此信息提供給網(wǎng)卡,網(wǎng)卡將負(fù)責(zé)在正確的時(shí)間發(fā)送數(shù)據(jù)包。
-
信號(hào)量:這是一種有用的消息傳遞對(duì)象,可在不同的 CUDA 內(nèi)核之間,或者在 CUDA 內(nèi)核和 CPU 線程之間共享信息和進(jìn)行同步。
如果您想深入了解 DOCA GPUNetIO 的原理和優(yōu)勢(shì),請(qǐng)參閱使用 NVIDIA DOCA GPUNetIO 進(jìn)行的內(nèi)聯(lián) GPU 數(shù)據(jù)包處理。如需獲取 DOCA GPUNetIO API 的更多詳細(xì)信息,請(qǐng)參閱 DOCA GPUNetIO SDK 編程指南。
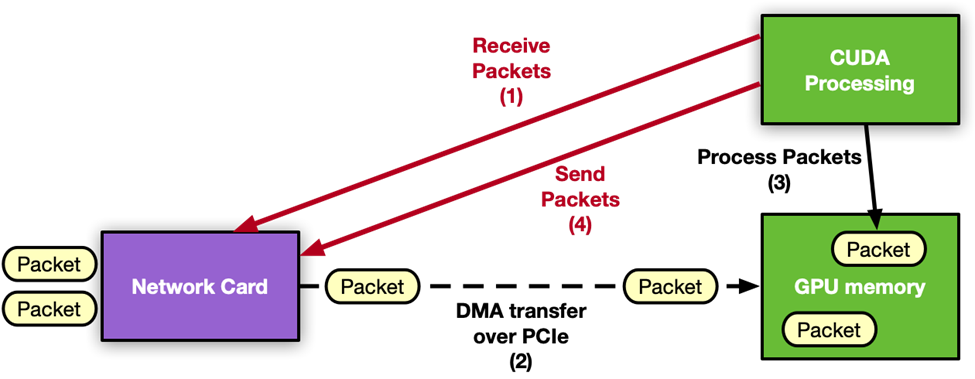
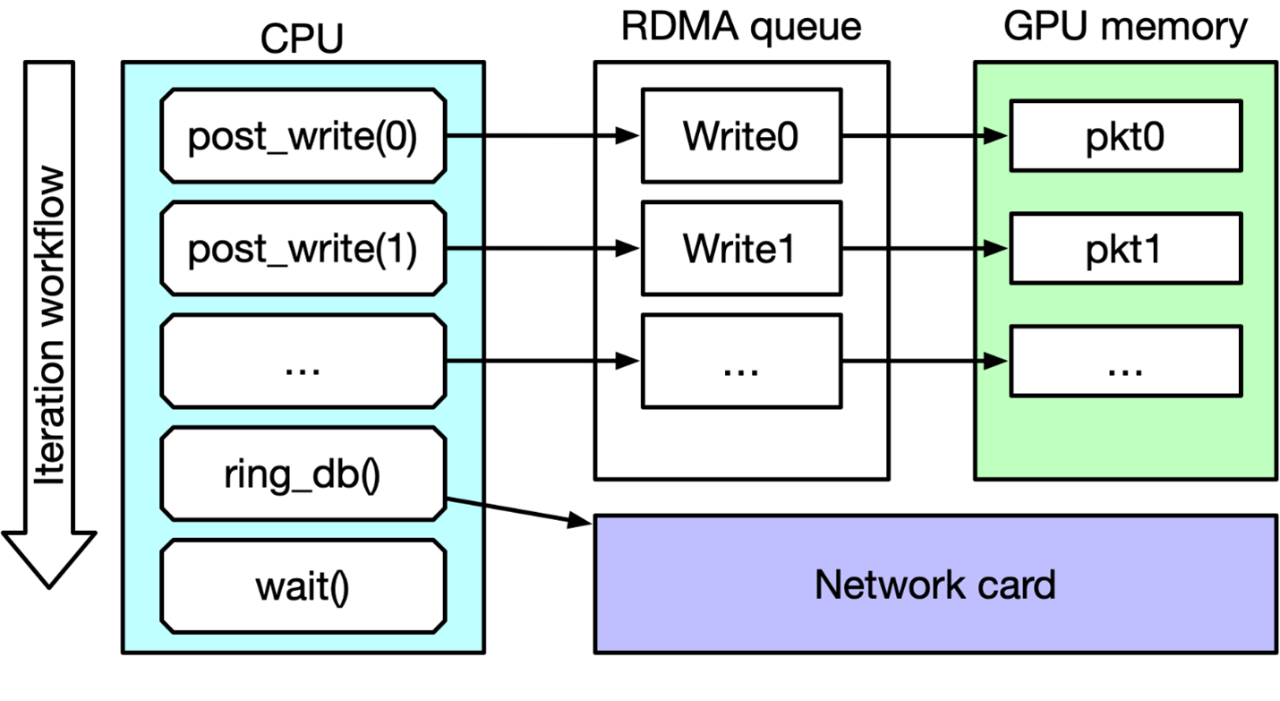
圖 1:NVIDIA DOCA GPUNetIO 應(yīng)用程序中接收進(jìn)程的布局。不涉及 CPU,因?yàn)?GPU 可以獨(dú)立地接收和處理網(wǎng)絡(luò)數(shù)據(jù)包
與該庫(kù)一起,以下 NVIDIA DOCA 應(yīng)用程序和 NVIDIA DOCA 示例還展示了如何使用該庫(kù)提供的功能和特性。
-
NVIDIA DOCA 應(yīng)用程序:這是一個(gè) GPU 數(shù)據(jù)包處理應(yīng)用程序,能夠檢測(cè)、管理、過(guò)濾和分析 UDP 、 TCP 和 ICMP 流量。此應(yīng)用程序還實(shí)現(xiàn)了 HTTP over TCP 服務(wù)器。使用簡(jiǎn)單的 HTTP 客戶端(例如 curl 或 wget ),可以建立 TCP 三次握手連接,并通過(guò)向 GPU 發(fā)出 HTTP GET 請(qǐng)求來(lái)獲取簡(jiǎn)單的 HTML 頁(yè)面。
-
NVIDIA DOCA 示例:這是一個(gè) GPU 僅發(fā)送示例,展示了如何使用“準(zhǔn)確發(fā)送調(diào)度(Accurate Sent Scheduling)”功能(包括系統(tǒng)配置和要使用的功能)。
DOCA GPUNetIO 在實(shí)際中的應(yīng)用
DOCA GPUNetIO 已被用于 NVIDIA Aerial SDK,用于使用 GPU 進(jìn)行發(fā)送和接收,從而無(wú)需 CPU 介入。想要了解更多詳細(xì)信息,請(qǐng)參閱使用 NVIDIA DOCA GPUNetIO 進(jìn)行內(nèi)聯(lián) GPU 數(shù)據(jù)包處理。下面的部分提供了成功使用 DOCA GPUNetIO 來(lái)利用 GDAKIN 技術(shù)進(jìn)行 GPU 數(shù)據(jù)包獲取的新示例。
NVIDIA Morpheus AI
NVIDIA Morpheus 是一個(gè)面向性能的應(yīng)用程序框架,使網(wǎng)絡(luò)安全開(kāi)發(fā)人員能夠創(chuàng)建完全優(yōu)化的 AI 流水線,用于過(guò)濾、處理和分類大量實(shí)時(shí)數(shù)據(jù)。該框架通過(guò)一個(gè)由 Python 和 C ++ API 組成的可訪問(wèn)編程模型來(lái)抽象 GPU 和 CPU 的并行性和并發(fā)性。
利用這個(gè)框架,開(kāi)發(fā)人員可以快速構(gòu)建由為下游消費(fèi)者獲取、變異和發(fā)布數(shù)據(jù)的階段組成任意數(shù)據(jù)流水線。您可以在不同的環(huán)境中應(yīng)用 Morpheus,包括惡意軟件檢測(cè)、網(wǎng)絡(luò)釣魚(yú)/魚(yú)叉式網(wǎng)絡(luò)釣魚(yú)檢測(cè)、勒索軟件檢測(cè)等。其靈活性和高性能是實(shí)時(shí)網(wǎng)絡(luò)流量分析的理想選擇。
針對(duì)于網(wǎng)絡(luò)監(jiān)控用例,NVIDIA Morpheus 團(tuán)隊(duì)最近集成了 DOCA 框架,以實(shí)現(xiàn)高速、低延遲的 GPU 數(shù)據(jù)包獲取的源階段,并將實(shí)時(shí)數(shù)據(jù)包饋送到負(fù)責(zé)分析數(shù)據(jù)包內(nèi)容的 AI 流水線。想要了解更多詳細(xì)信息,請(qǐng)?jiān)L問(wèn)GitHub 上的 Morpheus。
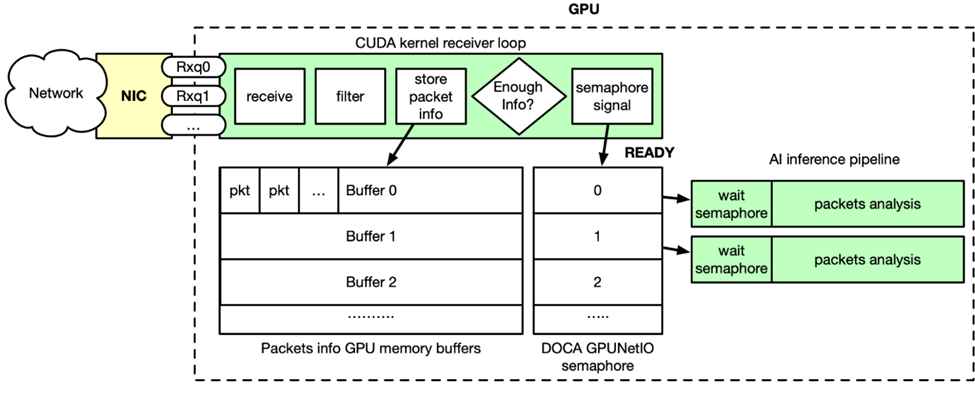
圖 2 : DOCA GPUNetIO 和 NVIDIA Morpheus AI 流水線通過(guò) CUDA 內(nèi)核連接,該內(nèi)核接收、過(guò)濾和分析傳入數(shù)據(jù)包
如圖 2 所示,GPU 數(shù)據(jù)包獲取是實(shí)時(shí)發(fā)生的。通過(guò) DOCA Flow,流轉(zhuǎn)向規(guī)則應(yīng)用于以太網(wǎng)接收隊(duì)列,這意味著隊(duì)列只能接收特定類型的數(shù)據(jù)包(例如 TCP )。Morpheus 啟動(dòng) CUDA 內(nèi)核,該內(nèi)核在一個(gè)循環(huán)中執(zhí)行以下步驟:
-
使用 DOCA GPUNetIO 接收功能接收數(shù)據(jù)包
-
在 GPU 內(nèi)存中過(guò)濾和分析并行數(shù)據(jù)包
-
復(fù)制相關(guān)數(shù)據(jù)包信息到 GPU 內(nèi)存緩沖區(qū)的列表中
-
當(dāng)緩沖區(qū)已經(jīng)累積了足夠的數(shù)據(jù)包信息時(shí),相關(guān)的 DOCA GPUNetIO 信號(hào)量被設(shè)置為 READY
-
AI 流水線前面的 CUDA 內(nèi)核正在輪詢信號(hào)量
-
當(dāng)信號(hào)量為 READY 時(shí),由于在緩沖區(qū)中的數(shù)據(jù)包信息已準(zhǔn)備就緒, AI 將被解鎖
GTC 會(huì)議 Defensive Cyber Operations(DCO)on Edge Newtorks 提供了一個(gè)具體的示例,展示了如何使用該架構(gòu)部署一個(gè)高性能的、支持人工智能的 SPAN /網(wǎng)絡(luò) TAP 解決方案。該解決方案由信息技術(shù)(IT)和運(yùn)營(yíng)技術(shù)(OT)網(wǎng)絡(luò)中的高數(shù)據(jù)速率、第 7 層應(yīng)用程序數(shù)據(jù)的異構(gòu)性和邊緣計(jì)算的尺寸、重量和功率(SWaP)約束所驅(qū)動(dòng)。
在邊緣計(jì)算的情況下,當(dāng)計(jì)算需求增加時(shí),許多組織無(wú)法“將突發(fā)上云”,尤其是在斷開(kāi)連接的邊緣網(wǎng)絡(luò)上。這個(gè)場(chǎng)景需要為應(yīng)對(duì) I/O 和計(jì)算挑戰(zhàn)設(shè)計(jì)一個(gè)架構(gòu),以在整個(gè) SWaP 范圍內(nèi)提供性能。
此 DCO 示例通過(guò)一個(gè)常見(jiàn)的網(wǎng)絡(luò)安全問(wèn)題來(lái)解決這些限制,識(shí)別未加密 TCP 流量中的泄露數(shù)據(jù)(例如,泄露的密碼、密鑰和 PII),并代表了 Morpheus SID 演示的擴(kuò)展。識(shí)別和修復(fù)這些漏洞可以減少攻擊面,提高組織的安全狀況。
在該示例中,DCO 解決方案將數(shù)據(jù)包接收到異構(gòu) Morpheus 流水線(用 Python 和 C ++ 混合形式編寫的 GPU 和并發(fā) CPU 階段)中,該流水線應(yīng)用 transformer 模型來(lái)檢測(cè)第 7 層應(yīng)用程序數(shù)據(jù)中泄漏的敏感數(shù)據(jù)。它將輸出與 ELK 堆棧集成,包括安全運(yùn)營(yíng)中心(SOC)分析師可利用的直觀可視化(圖 3 和圖 4)。
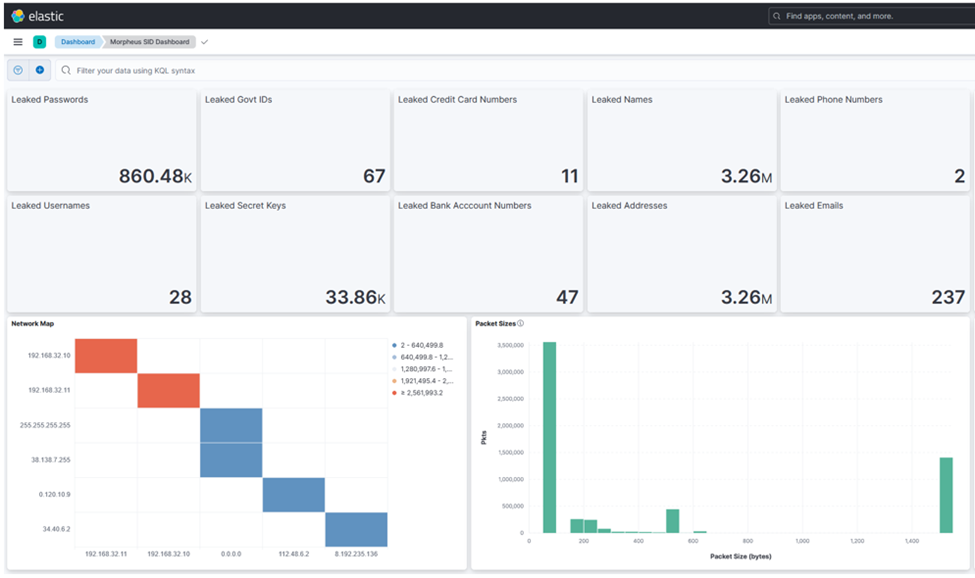
圖 3:Kibana 儀表板顯示 DOCA GPUNetIO
加上 Morpheus 敏感信息檢測(cè)的結(jié)果,包括每種類型的總檢測(cè)數(shù)、
成對(duì)網(wǎng)絡(luò)圖和數(shù)據(jù)包大小的分布
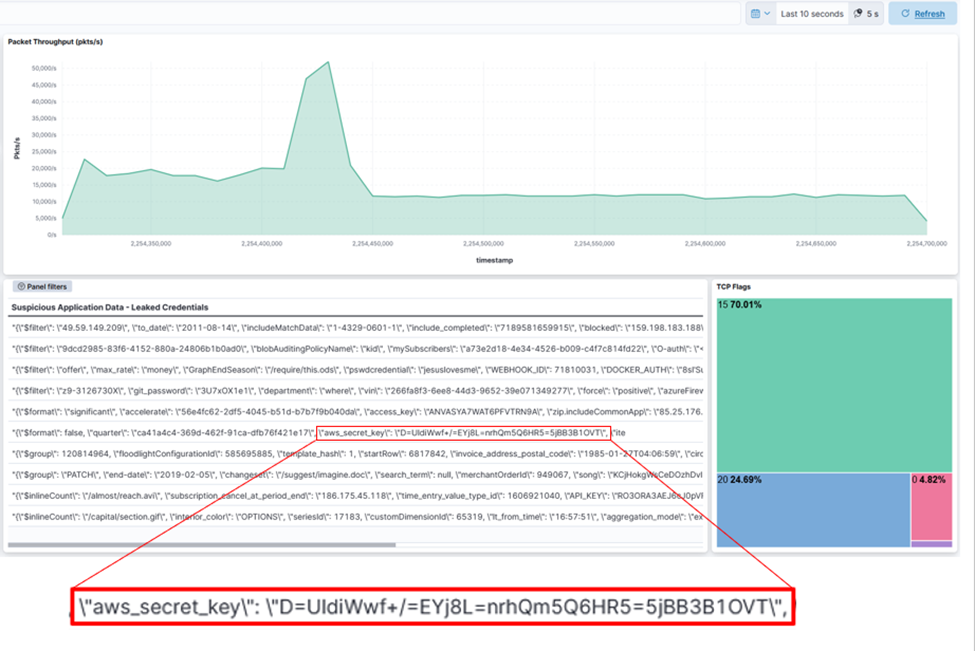
圖 4:Kibana 儀表板顯示 DOCA GPUNetIO 加上 Morpheus 敏感信息檢測(cè)的結(jié)果,
包括每秒高達(dá) 50K 數(shù)據(jù)包的過(guò)濾和處理的網(wǎng)絡(luò)數(shù)據(jù)包索引,包括帶有泄露密鑰的有效負(fù)載表
實(shí)驗(yàn)設(shè)置包括在具有 100Gbps NVIDIA BlueField-2 DPU 的虛擬機(jī)上運(yùn)行的云原生 UDP 多播和 REST 應(yīng)用程序。這些應(yīng)用程序通過(guò) SWaP 高效的 NVIDIA Spectrum SN2100 以太網(wǎng)交換機(jī)進(jìn)行通信。數(shù)據(jù)包生成器將敏感數(shù)據(jù)注入到由這些應(yīng)用程序傳輸?shù)臄?shù)據(jù)包中。網(wǎng)絡(luò)數(shù)據(jù)包經(jīng)過(guò) NVIDIA Spectrum SN2100 上的 SPAN 端口聚合和鏡像,然后發(fā)送到 NVIDIA A30X融合加速器,為 Morpheus 數(shù)據(jù)包檢查流水線提供支持,實(shí)現(xiàn)了令人印象深刻的吞吐量結(jié)果。
-
該流水線包括來(lái)自第三方 SIEM 平臺(tái)(Elasticsearch)中進(jìn)行 I/O 、數(shù)據(jù)包過(guò)濾、數(shù)據(jù)包處理和索引的多個(gè)組件。DOCA GPUNetIO 主要關(guān)注 I/O 方面,使得 Morpheus 能夠通過(guò)單一接收隊(duì)列,以高達(dá) 100 Gbps 的速度將數(shù)據(jù)包接收到 GPU 內(nèi)存中,從而消除了網(wǎng)絡(luò)數(shù)據(jù)包處理應(yīng)用程序中的一個(gè)關(guān)鍵瓶頸。
-
利用階段級(jí)并發(fā),該流水線將 Elasticsearch 索引吞吐量提高了 60%。
-
在 NVIDIA A30X 融合加速器上運(yùn)行端到端數(shù)據(jù)流水線會(huì)生成的豐富的數(shù)據(jù)包,容量約為 Elasticsearch 索引器的 50%。使用兩倍數(shù)量的 A30X 將使索引器完全飽和,從而提供一種方便擴(kuò)展的探索方法。
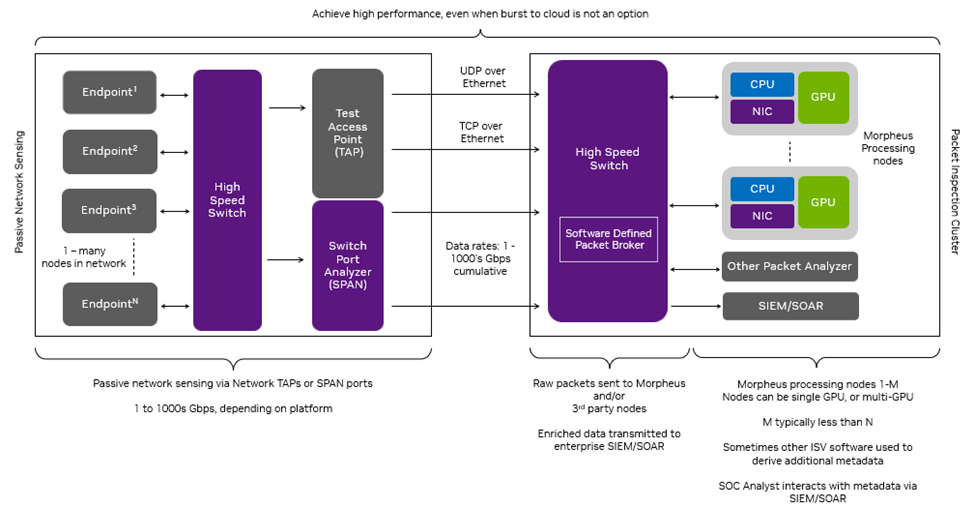
圖 5:端到端數(shù)據(jù)包處理應(yīng)用程序加速敏感信息的檢測(cè)
雖然這個(gè)用例演示了 Morpheus 的特定應(yīng)用程序,但它展示了網(wǎng)絡(luò)數(shù)據(jù)包處理應(yīng)用程序的基本組件。Morpheus 加上 DOCA GPUNetIO 共同為大量延遲敏感和計(jì)算密集型數(shù)據(jù)包處理應(yīng)用程序提供了性能和可擴(kuò)展性。
線速雷達(dá)信號(hào)處理
本節(jié)介紹了一個(gè)示例,在該示例中,雷達(dá)檢測(cè)應(yīng)用程序以 100Gbps 線速?gòu)?a href="http://www.asorrir.com/analog/" target="_blank">模擬的僅測(cè)距雷達(dá)系統(tǒng)獲取變頻的 I/Q 樣本,執(zhí)行將接收到的 I/Q RF 樣本實(shí)時(shí)轉(zhuǎn)換為物體檢測(cè)所需的所有信號(hào)處理。
雷達(dá)、激光雷達(dá)和光學(xué)平臺(tái)等遙感應(yīng)用依賴于信號(hào)處理算法,將從測(cè)量環(huán)境中收集的原始數(shù)據(jù)轉(zhuǎn)化為可操作的信息。這些算法通常具有很高的并行性,并且需要很高的計(jì)算負(fù)載,這使得它們非常適合基于 GPU 的處理。
此外,輸入傳感器會(huì)生成大量的原始數(shù)據(jù),這意味著處理解決方案的入口/出口能力必須能夠在低延遲下處理非常高的帶寬。
使問(wèn)題進(jìn)一步復(fù)雜化的是,許多基于邊緣的傳感器系統(tǒng)具有嚴(yán)格的 SWaP 約束,限制了可能用于其他高通量網(wǎng)絡(luò)方法(如基于 DPDK 的 GPUDirect RDMA)的可用 CPU 核心的數(shù)量和功率。
DOCA GPUNetIO 使 GPU 能夠直接處理網(wǎng)絡(luò)負(fù)載以及成功實(shí)現(xiàn)了實(shí)時(shí)傳感器流應(yīng)用程序所需的信號(hào)處理。
常用的信號(hào)處理算法被用于雷達(dá)探測(cè)應(yīng)用中。圖 6 中的流程圖顯示了用于將 I/Q 樣本轉(zhuǎn)換為檢測(cè)的信號(hào)處理流水線的圖形表示。

圖 6:用于在僅測(cè)距雷達(dá)系統(tǒng)中從反射 RF 波形計(jì)算檢測(cè)的信號(hào)處理流水線
MTI 濾波是一種在雷達(dá)系統(tǒng)中常用的技術(shù),用于消除反射的 RF 波形中的靜止背景雜波(如地面或建筑物)。這里使用的方法被稱為 Three-Pulse Canceler(三脈沖消除器),它是在脈沖維度上的 I/Q 數(shù)據(jù)與濾波器系數(shù) ‘[+1,-2,+1]’ 的卷積。
脈沖壓縮使接收波形相對(duì)于目標(biāo)存在的信噪比(SNR)最大化。它是通過(guò)計(jì)算接收到的 RF 數(shù)據(jù)與發(fā)射波形的互相關(guān)來(lái)實(shí)現(xiàn)的。
恒虛警率(CFAR)檢測(cè)器計(jì)算噪聲的經(jīng)驗(yàn)估計(jì),該噪聲被定位于濾波數(shù)據(jù)的每個(gè)距離倉(cāng)。然后將每個(gè)倉(cāng)的功率與噪聲進(jìn)行比較,并在給定噪聲估計(jì)和分布的情況下,如果在統(tǒng)計(jì)上有可能,則宣布為檢測(cè)到。
大小為(#波形)x(#信道)x(#樣本)的 3D 緩沖區(qū)用于保持正在接收組織好的 RF 數(shù)據(jù)(注意,在數(shù)據(jù)包接收時(shí)應(yīng)用 MTI 濾波器將脈沖維度的大小減小到 1)。假設(shè) UDP 數(shù)據(jù)流式傳輸沒(méi)有排序,只是大致按照數(shù)據(jù)包的波形 ID 升序進(jìn)行流傳輸。每個(gè)數(shù)據(jù)包傳輸大約 500 個(gè)復(fù)雜樣本,樣本在 3D 緩沖區(qū)中的位置取決于波形 ID、信道 ID 和樣本索引。
此應(yīng)用程序持續(xù)運(yùn)行兩個(gè) CUDA 內(nèi)核和一個(gè) CPU 核心。第一個(gè) CUDA 內(nèi)核負(fù)責(zé)使用 DOCA GPUNetIO API 將數(shù)據(jù)包從網(wǎng)卡讀取到 GPU。第二個(gè) CUDA 內(nèi)核基于數(shù)據(jù)包頭部中的元數(shù)據(jù)將數(shù)據(jù)包數(shù)據(jù)放入正確的內(nèi)存位置,并應(yīng)用 MTI 過(guò)濾器,CPU 核心負(fù)責(zé)啟動(dòng)處理脈沖壓縮和 CFAR 的 CUDA 內(nèi)核。使用 cuFFT 庫(kù)進(jìn)行 FFT。
圖 7 顯示了應(yīng)用程序的圖形表示。
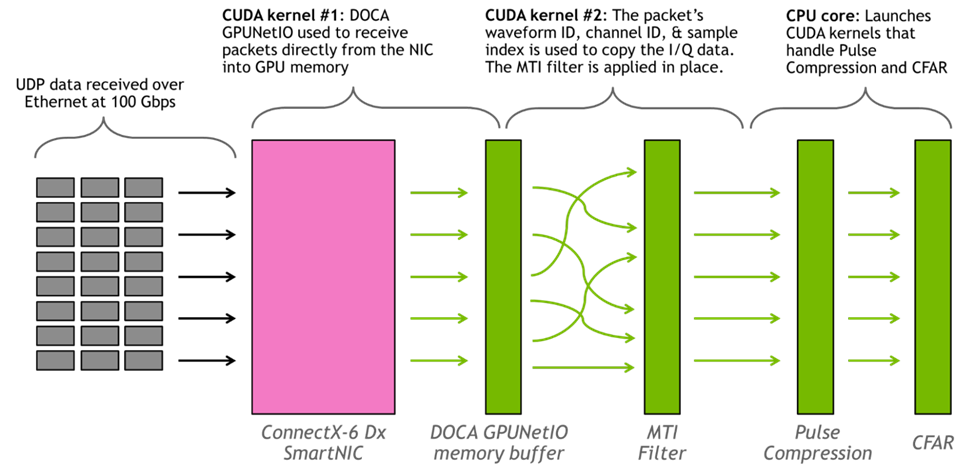
圖 7:基于 GPU 的信號(hào)處理流水線的工作分配的圖形表示
雷達(dá)探測(cè)流水線的吞吐量大 100Gbps。以 100Gbps 的線速運(yùn)行 100 萬(wàn)個(gè) 16 信道波形,沒(méi)有丟棄任何數(shù)據(jù)包,信號(hào)處理從未落后于數(shù)據(jù)流的吞吐量。從接收到獨(dú)立波形 ID 的最后一個(gè)數(shù)據(jù)包開(kāi)始測(cè)量的延遲大約為 3 毫秒。使用 NVIDIA ConnectX-6 Dx 智能網(wǎng)卡和 NVIDIA A100 80GB GPU 。數(shù)據(jù)是通過(guò)以太網(wǎng)上的 UDP 數(shù)據(jù)包發(fā)送的。
未來(lái)的工作將評(píng)估該架構(gòu)僅在具有集成 GPU 的 BlueField DPU 上運(yùn)行時(shí)的性能。
GPU 上的實(shí)時(shí) DSP 服務(wù)
模擬信號(hào)無(wú)處不在,既有人工信號(hào)(例如 Wi-Fi 無(wú)線電),也有自然信號(hào)(例如太陽(yáng)輻射和地震)。為了以數(shù)字方式捕獲模擬數(shù)據(jù),聲波必須使用數(shù)模轉(zhuǎn)換器進(jìn)行轉(zhuǎn)換,該轉(zhuǎn)換器由采樣率和采樣位深度等參數(shù)控制。數(shù)字音頻和視頻可以使用 FFT 進(jìn)行處理,使聲音設(shè)計(jì)師能夠使用均衡器(EQ)等工具來(lái)改變信號(hào)的一般特性。
此示例說(shuō)明了 NVIDIA 產(chǎn)品和 SDK 是如何通過(guò)網(wǎng)絡(luò)使用 GPU 執(zhí)行實(shí)時(shí)音頻 DSP 的。為此,該團(tuán)隊(duì)構(gòu)建了一個(gè)客戶端,該客戶端用于解析 WAV 文件,將數(shù)據(jù)封裝成多個(gè)以太網(wǎng)數(shù)據(jù)包,并通過(guò)網(wǎng)絡(luò)將其發(fā)送到服務(wù)器應(yīng)用程序。該應(yīng)用程序負(fù)責(zé)接收數(shù)據(jù)包、應(yīng)用 FFT、操縱音頻信號(hào),并最終發(fā)回修改后的數(shù)據(jù)。
客戶端的責(zé)任是識(shí)別哪個(gè)部分應(yīng)該發(fā)送到信號(hào)處理鏈的“服務(wù)器”,以及在從服務(wù)器接收到處理后的樣本時(shí)如何處理它們。這種方法支持多種 DSP 算法,如重疊相加和各種采樣窗口選擇。
服務(wù)器應(yīng)用程序使用 DOCA CUDANetIO 從 GPU 內(nèi)核接收 GPU 內(nèi)存中的數(shù)據(jù)包。當(dāng)已經(jīng)接收到數(shù)據(jù)包的子集時(shí),CUDA 內(nèi)核通過(guò) cuFFTDx 庫(kù)并行將 FFT 應(yīng)用于每個(gè)數(shù)據(jù)包的有效負(fù)載。同時(shí),不同的 CUDA 線程對(duì)每個(gè)數(shù)據(jù)包應(yīng)用頻率濾波器,從而降低低頻或高頻的幅度。基本上,它采用低通或高通濾波器。
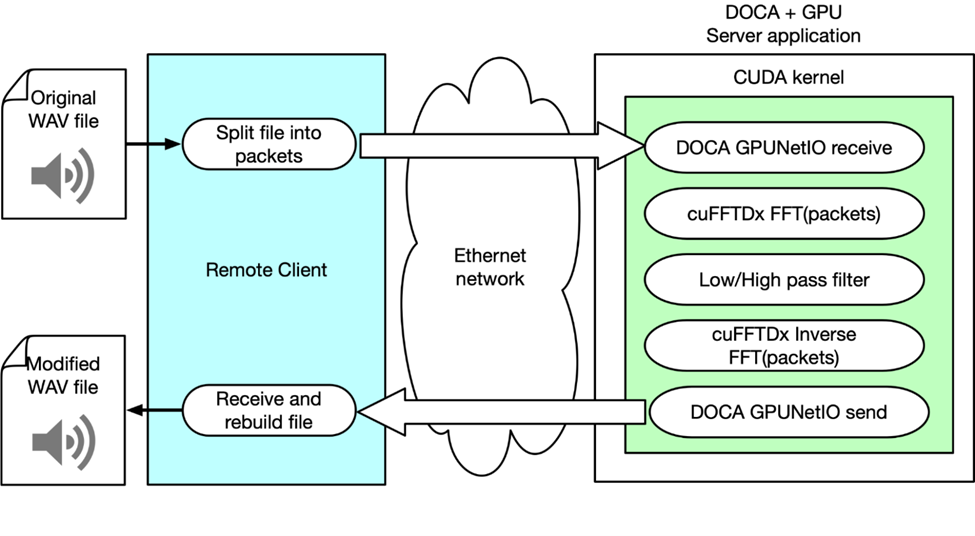
圖 8:客戶端 – 服務(wù)器體系結(jié)構(gòu)旨在演示如何通過(guò)網(wǎng)絡(luò)使用 GPU 執(zhí)行實(shí)時(shí) DSP 服務(wù)
對(duì)每個(gè)數(shù)據(jù)包應(yīng)用逆 FFT。通過(guò) DOCA GPUNetIO,CUDA 內(nèi)核將修改后的數(shù)據(jù)包發(fā)送回客戶端。客戶端重新排序數(shù)據(jù)包并重新構(gòu)建它們,以重新創(chuàng)建應(yīng)用了音效的可聽(tīng)且可再現(xiàn)的 WAV 音頻文件。
使用該客戶端,該團(tuán)隊(duì)可以調(diào)整參數(shù)以優(yōu)化音頻輸出的性能和質(zhì)量。可以將流和多路復(fù)用流分離到它們的處理鏈中,從而將許多復(fù)雜的計(jì)算卸載到 GPU 中。通過(guò)挖掘該解決方案的潛力,它可以為云 DSP 服務(wù)提供商打開(kāi)新的市場(chǎng)機(jī)會(huì)。
總結(jié)
DOCA GPUNetIO 庫(kù)促進(jìn)了一種以 GPU 為中心的通用方法,用于在進(jìn)行實(shí)時(shí)流量分析的網(wǎng)絡(luò)應(yīng)用程序中獲取和傳輸數(shù)據(jù)包。這篇文章展示了如何在不同上下文的各種應(yīng)用程序中采用該庫(kù),從而在延遲、吞吐量和系統(tǒng)資源利用率方面提供了巨大的改進(jìn)。掃描下方二維碼,查看更多有關(guān)NVIDIA DOCA 的信息。

 ?
?更多精彩內(nèi)容 使用 NVIDIA DOCA GPUNetIO 進(jìn)行內(nèi)聯(lián) GPU 數(shù)據(jù)包處理
利用 NVIDIA DOCA 2.0 改變 IPsec 的部署
原文標(biāo)題:使用 NVIDIA DOCA GPUNetIO 實(shí)現(xiàn)實(shí)時(shí)網(wǎng)絡(luò)處理功能
文章出處:【微信公眾號(hào):NVIDIA英偉達(dá)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
-
英偉達(dá)
+關(guān)注
關(guān)注
22文章
3912瀏覽量
93042
原文標(biāo)題:使用 NVIDIA DOCA GPUNetIO 實(shí)現(xiàn)實(shí)時(shí)網(wǎng)絡(luò)處理功能
文章出處:【微信號(hào):NVIDIA_China,微信公眾號(hào):NVIDIA英偉達(dá)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
NVIDIA將為每家AI工廠提供網(wǎng)絡(luò)安全

NVIDIA實(shí)現(xiàn)神經(jīng)網(wǎng)絡(luò)渲染技術(shù)的突破性增強(qiáng)功能
NVIDIA推出全新硅光網(wǎng)絡(luò)交換機(jī)
NVIDIA技術(shù)助力Pantheon Lab數(shù)字人實(shí)時(shí)交互解決方案
【AIBOX應(yīng)用】通過(guò) NVIDIA TensorRT 實(shí)現(xiàn)實(shí)時(shí)快速的語(yǔ)義分割

索尼空間現(xiàn)實(shí)顯示屏與NVIDIA Omniverse適配集成,進(jìn)一步增強(qiáng)兼容性
NVIDIA DOCA 2.9版本的亮點(diǎn)解析

借助NVIDIA Holoscan實(shí)現(xiàn)實(shí)時(shí)手術(shù)指導(dǎo)
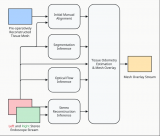
NVIDIA DOCA-OFED的主要特性
簡(jiǎn)單認(rèn)識(shí)NVIDIA網(wǎng)絡(luò)平臺(tái)
使用OpenVINO C# API部署YOLO-World實(shí)現(xiàn)實(shí)時(shí)開(kāi)放詞匯對(duì)象檢測(cè)

IB Verbs和NVIDIA DOCA GPUNetIO性能測(cè)試
在NVIDIA Holoscan SDK中使用OpenCV構(gòu)建零拷貝AI傳感器處理管線

NVIDIA 通過(guò) Holoscan 為 NVIDIA IGX 提供企業(yè)軟件支持,實(shí)現(xiàn)邊緣實(shí)時(shí)醫(yī)療、工業(yè)和科學(xué) AI 應(yīng)用






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論