") 一個(gè)使用Java語言實(shí)現(xiàn)的向量化BLAS庫VectorBLAS
一個(gè)使用Java語言實(shí)現(xiàn)的向量化BLAS庫VectorBLAS
VectorBLAS簡介
VectorBLAS是一個(gè)使用Java語言實(shí)現(xiàn)的向量化BLAS高性能庫,目前已在openEuler社區(qū)開源。
VectorBLAS通過循環(huán)展開、矩陣分塊和內(nèi)存布局優(yōu)化等算法優(yōu)化,對(duì)BLAS函數(shù)進(jìn)行了深度優(yōu)化,并利用VectorAPI JDK提供的多種向量化API實(shí)現(xiàn)。
可以理解為:VectorBLAS = VectorAPI + BLAS。
BLAS簡介:
BLAS(Basic Linear Algebra Subprograms)是進(jìn)行向量和矩陣等基本線性代數(shù)操作的數(shù)值庫,是LAPACK(Linear Algebra Package)的一部分。
在高性能計(jì)算領(lǐng)域中被廣泛應(yīng)用,由此衍生出大量優(yōu)化版本,如OpenBLAS、Intel的Intel MKL等優(yōu)化版本。
主要支持三個(gè)級(jí)別的運(yùn)算:分別支持向量與向量、向量與矩陣、矩陣與矩陣的相關(guān)操作。
VectorAPI簡介:
VectorAPI是Java端為實(shí)現(xiàn)SIMD向量化功能提供的一個(gè)抽象層,從JDK16開始發(fā)布,目前已孵化到第六代(JDK21)。
VectorAPI提供的能力包括:
1. 定義更清晰及準(zhǔn)確的向量化API,使用戶更直接的實(shí)現(xiàn)向量化;
2. 與平臺(tái)無關(guān):支持AArch64和x86等平臺(tái),支持NEON、SVE、AVX等多種向量化指令,一份代碼多處可用;
應(yīng)用場(chǎng)景:
目前BLAS庫在大數(shù)據(jù)、HPC和機(jī)器學(xué)習(xí)等高性能計(jì)算中被廣泛使用。例如大數(shù)據(jù)組件`Spark`中的多種機(jī)器學(xué)習(xí)算法(如:`KMeans`、 `LDA`、 `PCA`、 `Bayes`、 `GMM`、 `SVM`等)都用到了BLAS函數(shù)接口`gemm`、 `gemv`、 `axpy`、 `dot`、 `spr`等。
主要優(yōu)化方法
1. VectorAPI向量化
BLAS庫中的函數(shù)分為矢量-矢量、矢量-矩陣、矩陣-矩陣的計(jì)算,其中多數(shù)場(chǎng)景為對(duì)數(shù)組、矩陣進(jìn)行計(jì)算,因此使用向量化進(jìn)行優(yōu)化,一次處理多個(gè)數(shù)據(jù),提升效率,下面以daxpy函數(shù)為例:
daxpy => y = alpha * x + y, 其中alpha為常數(shù),x和y為一維向量,數(shù)據(jù)類型均為double;
原生樸素實(shí)現(xiàn):對(duì)x和y中的元素逐個(gè)計(jì)算;
向量化實(shí)現(xiàn):以256位寬的寄存器為例,一次可以處理2個(gè)double類型,即一次對(duì)alpha、x和y做兩次乘加操作;
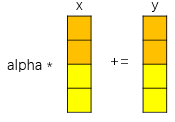
可以看出,向量化操作可以成倍的提升處理效率,目前的向量化寄存器有128、256、512等大小的位寬,SVE等指令集甚至最高可支持2048位。
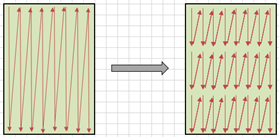
2. 循環(huán)展開
循環(huán)展開是一種循環(huán)轉(zhuǎn)換技術(shù), 通過減少或消除控制程序循環(huán)的指令,來減少計(jì)算開銷,這種開銷包括增加指向數(shù)組中下一個(gè)索引或者指令的指針?biāo)銛?shù)等,還可以減少循環(huán)的次數(shù),每次循環(huán)內(nèi)的計(jì)算也可以利用CPU的流水線提升效率;
JDK中的JIT即時(shí)編譯器也有針對(duì)循環(huán)進(jìn)行自動(dòng)優(yōu)化,尤其是使用int, short, 或者char變量作為計(jì)數(shù)器的計(jì)數(shù)循環(huán)(counted loops)
VectorBLAS主要分析函數(shù)特性,通過把循環(huán)改造為counted loop,或手動(dòng)對(duì)關(guān)鍵循環(huán)進(jìn)行展開,以此提高執(zhí)行效率;
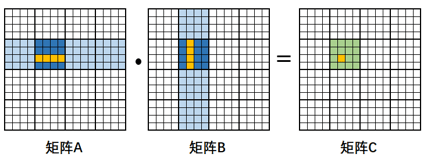
3. 矩陣分塊
矩陣分塊是一種cache優(yōu)化手段,當(dāng)數(shù)組、矩陣的規(guī)模較大的時(shí)候,在N層循環(huán)中的跨度太大時(shí),無法`fit in the cache`,數(shù)據(jù)則會(huì)被清出了緩存,造成較高的`cache miss`率; 通過矩陣分塊,可以將小塊數(shù)據(jù)鎖在L1/L2 Cache中,提高cache命中,降低`cache miss`率。
4. Packing
Packing優(yōu)化又稱為內(nèi)存布局優(yōu)化,因矩陣在數(shù)組中一般是按列存儲(chǔ)或者按行存儲(chǔ),若計(jì)算時(shí)不是按照整行整列的順序進(jìn)行,那么就需要跨列或跨行讀取數(shù)據(jù)。
Packing指的是在內(nèi)存中新開一塊空間,在這塊空間內(nèi)重新排布數(shù)據(jù),使得數(shù)據(jù)的讀取可以變得連續(xù),減少cache miss,提升讀取速度,Packing一般與矩陣分塊搭配使用。
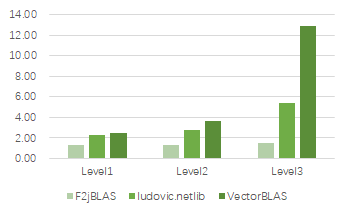
性能數(shù)據(jù)
現(xiàn)有版本基于鯤鵬服務(wù)器測(cè)試驗(yàn)證,性能相較于業(yè)界同類庫F2jBLAS/ludovic.netlib都有提升,如下圖所示:
后續(xù)規(guī)劃
本項(xiàng)目已開源在openEuler社區(qū),當(dāng)前版本實(shí)現(xiàn)了BLAS庫中的主要接口,后續(xù)規(guī)劃如下:
1. 支持Level1、Level2、Level3中更多的函數(shù)接口;
2. 補(bǔ)充完善UT和Benchmark;
3. 對(duì)于不同平臺(tái)/指令集的調(diào)優(yōu);
4.結(jié)合Spark MLlib等機(jī)器學(xué)習(xí)算法庫進(jìn)行性能優(yōu)化。
審核編輯:湯梓紅
-
JAVA
+關(guān)注
關(guān)注
20文章
2984瀏覽量
106785 -
開源
+關(guān)注
關(guān)注
3文章
3575瀏覽量
43426 -
函數(shù)
+關(guān)注
關(guān)注
3文章
4367瀏覽量
64105 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8488瀏覽量
134010 -
BLAS
+關(guān)注
關(guān)注
0文章
3瀏覽量
6744
原文標(biāo)題:【openEuler創(chuàng)新項(xiàng)目探索】一個(gè)Java端的向量化BLAS庫VectorBLAS
文章出處:【微信號(hào):openEulercommunity,微信公眾號(hào):openEuler】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
C語言實(shí)現(xiàn):見縫插針游戲!代碼思路+源碼分享
介紹一個(gè)C語言實(shí)現(xiàn)的http下載器
SQL語言實(shí)現(xiàn)數(shù)據(jù)庫記錄的查詢
請(qǐng)問怎樣實(shí)現(xiàn)H.264的量化?
基于Miracl庫的中國剩余定理C語言實(shí)現(xiàn)資料分享
用JAVA語言實(shí)現(xiàn)RSA公鑰密碼算法
Verilog HDL語言實(shí)現(xiàn)時(shí)序邏輯電路
如何使用C語言實(shí)現(xiàn)一個(gè)比較簡單的猜數(shù)游戲的程序免費(fèi)下載







 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論