") 關(guān)于領(lǐng)域大模型-訓(xùn)練Trick&落地的一點(diǎn)思考
關(guān)于領(lǐng)域大模型-訓(xùn)練Trick&落地的一點(diǎn)思考
一、領(lǐng)域技術(shù)標(biāo)準(zhǔn)文檔或領(lǐng)域相關(guān)數(shù)據(jù)是領(lǐng)域模型Continue PreTrain的關(guān)鍵。
現(xiàn)有大模型在預(yù)訓(xùn)練過(guò)程中都會(huì)加入書(shū)籍、論文等數(shù)據(jù),那么在領(lǐng)域預(yù)訓(xùn)練時(shí)這兩種數(shù)據(jù)其實(shí)也是必不可少的,主要是因?yàn)檫@些數(shù)據(jù)的數(shù)據(jù)質(zhì)量較高、領(lǐng)域強(qiáng)相關(guān)、知識(shí)覆蓋率(密度)大,可以讓模型更適應(yīng)考試。當(dāng)然不是說(shuō)其他數(shù)據(jù)不是關(guān)鍵,比如領(lǐng)域相關(guān)網(wǎng)站內(nèi)容、新聞內(nèi)容都是重要數(shù)據(jù),只不過(guò)個(gè)人看來(lái),在領(lǐng)域上的重要性或者知識(shí)密度不如書(shū)籍和技術(shù)標(biāo)準(zhǔn)。
二、領(lǐng)域數(shù)據(jù)訓(xùn)練后,往往通用能力會(huì)有所下降,需要混合通用數(shù)據(jù)以緩解模型遺忘通用能力。
如果僅用領(lǐng)域數(shù)據(jù)進(jìn)行模型訓(xùn)練,模型很容易出現(xiàn)災(zāi)難性遺忘現(xiàn)象,通常在領(lǐng)域訓(xùn)練過(guò)程中加入通用數(shù)據(jù)。那么這個(gè)比例多少比較合適呢?目前還沒(méi)有一個(gè)準(zhǔn)確的答案,BloombergGPT(從頭預(yù)訓(xùn)練)預(yù)訓(xùn)練金融和通用數(shù)據(jù)比例基本上為1:1,ChatHome(繼續(xù)預(yù)訓(xùn)練)發(fā)現(xiàn)領(lǐng)域:通用數(shù)據(jù)比例為1:5時(shí)最優(yōu)。個(gè)人感覺(jué)應(yīng)該跟領(lǐng)域數(shù)據(jù)量有關(guān),當(dāng)數(shù)據(jù)量沒(méi)有那多時(shí),一般數(shù)據(jù)比例在1:5到1:10之間是比較合適的。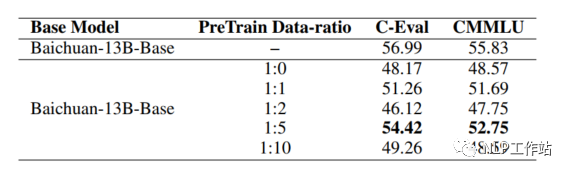
三、領(lǐng)域模型Continue PreTrain時(shí)可以同步加入SFT數(shù)據(jù),即MIP,Multi-Task Instruction PreTraining。
預(yù)訓(xùn)練過(guò)程中,可以加下游SFT的數(shù)據(jù),可以讓模型在預(yù)訓(xùn)練過(guò)程中就學(xué)習(xí)到更多的知識(shí)。例如:T5、ExT5、Glm-130b等多任務(wù)學(xué)習(xí)在預(yù)訓(xùn)練階段可能比微調(diào)更有幫助。并且ChatHome發(fā)現(xiàn)MIP效果在領(lǐng)域上評(píng)測(cè)集上絕群。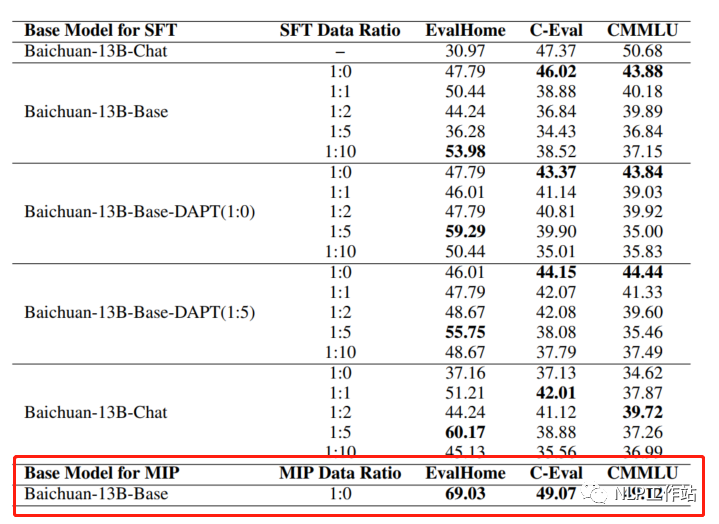
四、 僅用SFT做領(lǐng)域模型時(shí),資源有限就用在Chat模型基礎(chǔ)上訓(xùn)練,資源充足就在Base模型上訓(xùn)練。(資源=數(shù)據(jù)+顯卡)
跟很多人討論過(guò)一個(gè)問(wèn)題,就是我們?cè)赟FT的時(shí)候是在Base模型上訓(xùn)練還是在Chat模型上訓(xùn)練。
其實(shí)很簡(jiǎn)單,如果你只有5k數(shù)據(jù),建議你在Chat模型上進(jìn)行微調(diào);如果你有10w數(shù)據(jù),建議你在Base模型上進(jìn)行微調(diào)。因?yàn)槟悴恢狢hat模型在SFT時(shí)的數(shù)據(jù)質(zhì)量如何,當(dāng)自己有能力時(shí),靠人不如靠己。
五、在Chat模型上進(jìn)行SFT時(shí),請(qǐng)一定遵循Chat模型原有的系統(tǒng)指令&數(shù)據(jù)輸入格式。
如果你在Chat模型上進(jìn)行SFT的時(shí)候,請(qǐng)跟Chat模型的輸入格式一致,否則當(dāng)你數(shù)據(jù)量不足時(shí),可能會(huì)導(dǎo)致訓(xùn)練效果不明顯。并且建議不采用全量參數(shù)訓(xùn)練,否則模型原始能力會(huì)遺忘較多。
六、領(lǐng)域評(píng)測(cè)集時(shí)必要內(nèi)容,建議有兩份,一份選擇題形式自動(dòng)評(píng)測(cè)、一份開(kāi)放形式人工評(píng)測(cè)。
一定要有自己的領(lǐng)域數(shù)據(jù)集來(lái)驗(yàn)證模型效果,來(lái)選擇最好的checkpoint。選擇題形式可以自動(dòng)評(píng)測(cè),方便模型進(jìn)行初篩;開(kāi)放形式人工評(píng)測(cè)比較浪費(fèi)時(shí)間,可以用作精篩,并且任務(wù)形式更貼近真實(shí)場(chǎng)景。
七、領(lǐng)域模型詞表擴(kuò)增是不是有必要的。
個(gè)人感覺(jué),領(lǐng)域詞表擴(kuò)增真實(shí)解決的問(wèn)題是解碼效率的問(wèn)題,給模型效果帶來(lái)的提升可能不會(huì)有很大。(這里領(lǐng)域詞表擴(kuò)充是指在同語(yǔ)言模型上擴(kuò)充詞表,而不是英文模型的中文漢化)
八、所謂的領(lǐng)域大模型會(huì)更新的越來(lái)越快,越來(lái)越多。
由于很多人&公司并沒(méi)有資源搞底座,因此需要在現(xiàn)有底座模型上進(jìn)行增量預(yù)訓(xùn)練、微調(diào)等。而以目前各廠(ChatGLM、BaiChuan、Qwen、Llama)搶占開(kāi)源社區(qū)占比的架勢(shì),感覺(jué)會(huì)有很多7B、13B級(jí)別模型開(kāi)源。
請(qǐng)等待一言、ChatGPT開(kāi)源小模型的一天,說(shuō)不定GPT5出來(lái)的時(shí)候,Openai會(huì)開(kāi)源個(gè)GPT3.5的小版本模型。
領(lǐng)域大模型落地的想法
一、常說(shuō)通用模型的領(lǐng)域化可能是偽命題,那么領(lǐng)域大模型的通用化是否也是偽命題。
自訓(xùn)練模型開(kāi)始,就一直再跟Leader Battle這個(gè)問(wèn)題,領(lǐng)域大模型需不需要有通用化能力。就好比華為盤(pán)古大模型“只做事不作詩(shī)”的slogan,是不是訓(xùn)練的領(lǐng)域大模型可以解決固定的幾個(gè)任務(wù)就可以了。
個(gè)人的一些拙見(jiàn)是,如果想快速的將領(lǐng)域大模型落地,最簡(jiǎn)單的是將系統(tǒng)中原有能力進(jìn)行升級(jí),即大模型在固定的某一個(gè)或某幾個(gè)任務(wù)上的效果超過(guò)原有模型。
以Text2SQL任務(wù)舉例,之前很多系統(tǒng)中的方法是通過(guò)抽取關(guān)鍵要素&拼接方式來(lái)解決,端到端解決的并不是很理想,那么現(xiàn)在完全可以用大模型SQL生成的能力來(lái)解決。在已有產(chǎn)品上做升級(jí),是代價(jià)最小的落地方式。就拿我司做的“云中問(wèn)道”來(lái)說(shuō),在解決某領(lǐng)域SQL任務(wù)上效果可以達(dá)到90%+,同比現(xiàn)有開(kāi)源模型&開(kāi)放API高了不少。
當(dāng)然還有很多其他任務(wù)可以升級(jí),例如:D2QA、D2SPO、Searh2Sum等等等。
二、領(lǐng)域大模型落地,任務(wù)場(chǎng)景要比模型能力更重要。
雖說(shuō)在有產(chǎn)品上做升級(jí),是代價(jià)最小的落地方式,但GPT4、AutoGPT已經(jīng)把人們胃口調(diào)的很高,所有人都希望直接提出一個(gè)訴求,大模型直接解決。但這對(duì)現(xiàn)有領(lǐng)域模型是十分困難的,所以在哪些場(chǎng)景上來(lái)用大模型是很關(guān)鍵的,并且如何將模型進(jìn)行包裝,及時(shí)在模型能力不足的情況下,也可以讓用戶(hù)有一個(gè)很好的體驗(yàn)。
現(xiàn)在很多人的疑惑是,先不說(shuō)有沒(méi)有大模型,就算有了大模型都不知道在哪里使用,在私有領(lǐng)域都找不到一個(gè)Special場(chǎng)景。
所以最終大模型的落地,拼的不是模型效果本身,而是一整套行業(yè)解決方案,“Know How”成為了關(guān)鍵要素。
三、大多數(shù)企業(yè)最終落地的模型規(guī)格限制在了13B。
由于國(guó)情,大多數(shù)企業(yè)最終落地的方案應(yīng)該是本地化部署,那么就會(huì)涉及硬件設(shè)備的問(wèn)題。我并不絕的很有很多企業(yè)可以部署的起100B級(jí)別的模型,感覺(jué)真實(shí)部署限制在了10B級(jí)別。即使現(xiàn)在很多方法(例如:llama.cpp)可以對(duì)大模型進(jìn)行加速,但100B級(jí)別的模型就算加速了,也是龐大資源消耗。
我之前說(shuō)過(guò)“沒(méi)有體驗(yàn)過(guò)33B模型的人,只會(huì)覺(jué)得13B就夠”,更大的模型一定要搞,但不影響最后落地的是10B級(jí)別。
做大模型的心路歷程
一開(kāi)始ChatGPT剛剛爆火的時(shí)候,根本沒(méi)想過(guò)我們也配做大模型。但當(dāng)國(guó)內(nèi)涌現(xiàn)出了許多中文大模型,并Alpaca模型證明70億參數(shù)量的模型也有不錯(cuò)效果的時(shí)候,給了我很大的信心,當(dāng)然也給很多人和很多企業(yè)更多的信心。
在中小企業(yè)做大模型,經(jīng)常被質(zhì)問(wèn)的是“沒(méi)有100張卡也可以做大模型”,我只想說(shuō)需要看對(duì)“大”的定義,175B的模型確實(shí)沒(méi)有資格觸碰,但33B的模型還是可以玩耍的。真正追趕OpenAI是需要一批人,但模型落地還是需要另外一批人的。
趕上大模型是我們的幸運(yùn),可以在領(lǐng)域大模型上發(fā)聲是我幸運(yùn)。
總結(jié)
最后共勉:BERT時(shí)代況且還在用TextCNN,難道13B的模型就不叫大模型嗎?
審核編輯:劉清
-
MIP
+關(guān)注
關(guān)注
0文章
38瀏覽量
14223 -
SQL
+關(guān)注
關(guān)注
1文章
780瀏覽量
44805 -
SFT
+關(guān)注
關(guān)注
0文章
9瀏覽量
6876 -
OpenAI
+關(guān)注
關(guān)注
9文章
1201瀏覽量
8635 -
ChatGPT
+關(guān)注
關(guān)注
29文章
1587瀏覽量
8796
原文標(biāo)題:領(lǐng)域大模型-訓(xùn)練Trick&落地思考
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
IGBT的物理結(jié)構(gòu)模型—BJT&MOS模型(1)
【大規(guī)模語(yǔ)言模型:從理論到實(shí)踐】- 每日進(jìn)步一點(diǎn)點(diǎn)
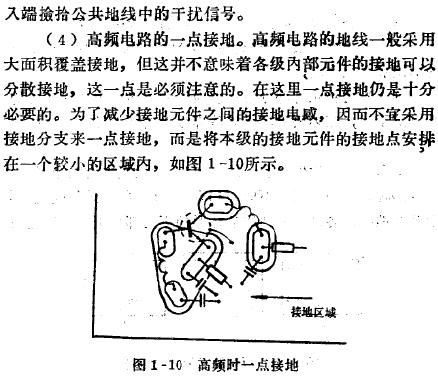
一點(diǎn)接地,什么是一點(diǎn)接地,一點(diǎn)接地應(yīng)注意的問(wèn)題
關(guān)于畫(huà)高頻PCB板的一點(diǎn)心得
存儲(chǔ)類(lèi)&作用域&生命周期&鏈接屬性

關(guān)于連接的問(wèn)答:歐盟 Wi-Fi 6 &amp; 6E 的未來(lái)發(fā)展

如何區(qū)分Java中的&amp;和&amp;&amp;
if(a==1 &amp;&amp; a==2 &amp;&amp; a==3),為true,你敢信?

攝像機(jī)&amp;amp;雷達(dá)對(duì)車(chē)輛駕駛的輔助
如何讓網(wǎng)絡(luò)模型加速訓(xùn)練





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論