") 如何在英特爾? 平臺上實現(xiàn)高效的大語言模型訓(xùn)練后量化
如何在英特爾? 平臺上實現(xiàn)高效的大語言模型訓(xùn)練后量化
本文介紹了可提升大語言模型的訓(xùn)練后量化表現(xiàn)的增強(qiáng)型 SmoothQuant 技術(shù),說明了這項技術(shù)的用法,并證明了其在準(zhǔn)確率方面的優(yōu)勢。此方法已整合至英特爾Neural Compressor1中。英特爾 Neural Compressor 是一個包含量化、剪枝(稀疏性)、蒸餾(知識提煉)和神經(jīng)架構(gòu)搜索等多種常用模型壓縮技術(shù)的開源 Python 庫。目前,諸如 TensorFlow、英特爾Extension for TensorFlow2、PyTorch、英特爾Extension for PyTorch3、ONNX Runtime 和 MXNet等主流框架,都能與之兼容。
英特爾 Neural Compressor已經(jīng)支持多款英特爾架構(gòu)的硬件,比如英特爾至強(qiáng)可擴(kuò)展處理器4、英特爾至強(qiáng)CPU Max 系列5、英特爾數(shù)據(jù)中心GPU Flex 系列6和英特爾數(shù)據(jù)中心 GPU Max 系列7。本文涉及的實驗基于第四代英特至強(qiáng)可擴(kuò)展處理器8進(jìn)行。
 ?大語言模型
?大語言模型
大語言模型 (Large Language Model, LLM) 需基于海量數(shù)據(jù)集進(jìn)行訓(xùn)練,可能擁有數(shù)十億權(quán)重參數(shù)。其先進(jìn)的網(wǎng)絡(luò)結(jié)構(gòu)和龐大的參數(shù)量,使它們能夠很好地應(yīng)對自然語言本身的復(fù)雜性。完成訓(xùn)練后的大語言模型,可針對各種下游的自然語言處理 (NLP) 和自然語言生成 (NLG) 任務(wù)進(jìn)行調(diào)優(yōu),讓其更適合對話式聊天機(jī)器人(如 ChatGPT)、機(jī)器翻譯、文本分類、欺詐檢測和情感分析等任務(wù)場景。
?大語言模型部署面臨的挑戰(zhàn)
大語言模型在執(zhí)行自然語言處理和自然語言生成任務(wù)方面表現(xiàn)出色,但其訓(xùn)練和部署頗為復(fù)雜,主要面臨以下挑戰(zhàn):
AI 與內(nèi)存墻9瓶頸問題:算力每兩年提高 3.1 倍,內(nèi)存帶寬卻只提高 1.4 倍;
網(wǎng)絡(luò)帶寬挑戰(zhàn):訓(xùn)練大語言模型需要采用分布式系統(tǒng),這對網(wǎng)絡(luò)帶寬提出了較高要求;
系統(tǒng)資源有限:訓(xùn)練后的模型往往會部署在算力和內(nèi)存資源均有限的系統(tǒng)上。
因此,采用訓(xùn)練后量化的方法來為大語言模型瘦身,對于實現(xiàn)低時延推理至關(guān)重要。
?大語言模型的量化
量化是一種常見的壓縮操作,可以減少模型占用的內(nèi)存空間,提高推理性能。采用量化方法可以降低大語言模型部署的難度。具體來說,量化是將浮點矩陣轉(zhuǎn)換為整數(shù)矩陣:
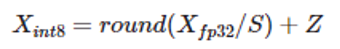
其中 X_fp32、S 和 Z 分別為輸入矩陣、比例因子和整數(shù)零點。有關(guān)每通道 (per-channel) 量化策略雖然可能會減少量化損失,但不能用于激活值量化的原因,請參看 SmoothQuant 相關(guān)文檔10。不過,激活值量化誤差損失卻是導(dǎo)致模型量化準(zhǔn)確率下降的重要因素。為此,人們提出了很多方法來降低激活值量化損失,例如:SPIQ11、OutlierSuppression12 和 SmoothQuant13。這三種方法思路相似,即把激活值量化的難度轉(zhuǎn)移到權(quán)重量化上,只是三者在轉(zhuǎn)移難度的多少上有所不同。
?增強(qiáng)型 SmoothQuant
SmoothQuant 引入了一個超參數(shù) α 作為平滑因子來計算每個通道的量化比例因子,并平衡激活值和權(quán)重的量化難度。
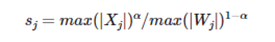
其中 j 是輸入通道索引。
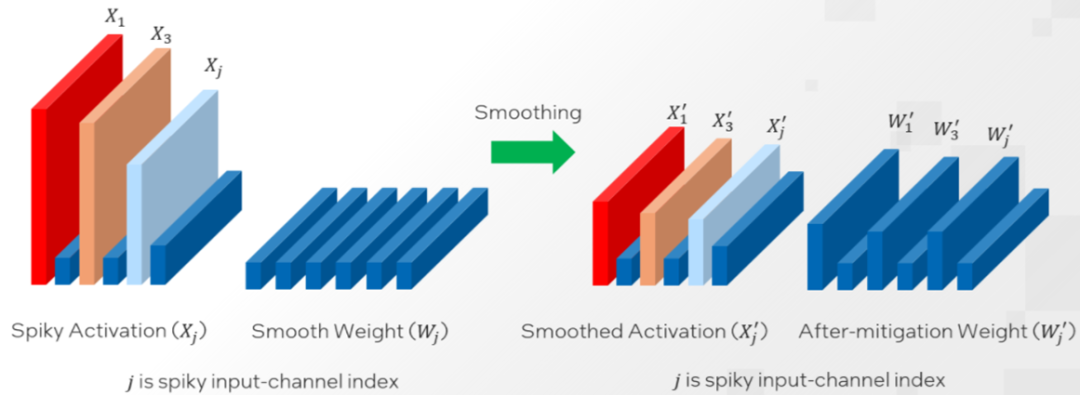
對于OPT 和 BLOOM 等大多數(shù)模型來說,α=0.5 是一個能夠較好實現(xiàn)權(quán)重和激活值量化難度分割的平衡值。模型的激活異常值越大,就越需要使用更大的 α 值來將更多的量化難度轉(zhuǎn)移到權(quán)重上。原始的 SmoothQuant 旨在通過針對整個模型使用一個固定值 α 來分割權(quán)重和激活值的量化難度。然而,由于激活異常值的分布不僅在不同模型之間存在差異,而且在同一模型的不同層之間也不盡相同,因此,本文推薦使用英特爾 Neural Compressor 的自動調(diào)優(yōu)能力,逐層獲取最佳 α 值。
相關(guān)方法包括以下五個主要步驟(偽代碼如下所示):
-
通過特殊的回調(diào)函數(shù) register_forward_hook 捕獲 (hook) 模型各層的輸入和輸出值。
-
根據(jù)用戶定義的 α 范圍和步長生成一個 α 值列表。
-
根據(jù)給定的 α 值重新計算平滑因子并調(diào)整參數(shù)(權(quán)重值和激活值)。
-
對權(quán)重執(zhí)行每通道量化與反量化 (quantization_dequantization),對輸入值執(zhí)行每張量 (per-tensor) 量化與反量化,以預(yù)測與給定 α 值對應(yīng)的每層輸出值。
-
計算相對實際輸出值的均方損失,將調(diào)整后的參數(shù)恢復(fù)回來,并保存每層的最佳 α 值。

本文提出的方法支持用多個標(biāo)準(zhǔn)(如最小值、最大值和平均值)來確定 Transformer 塊的輸入層歸一化 (LayerNorm) 操作的 α 值。實驗發(fā)現(xiàn),將 α 范圍設(shè)為 [0.3, 0.7],步長設(shè)為 0.05,對大多數(shù)模型來說都能達(dá)到很好的平衡。 這一方法有兩個顯著特點:一是全自動化,二是比原始方法支持的融合模式多。 下圖提供了在 BLOOM-1b7 模型上執(zhí)行 SmoothQuant α 值自動調(diào)優(yōu)的樣例代碼:
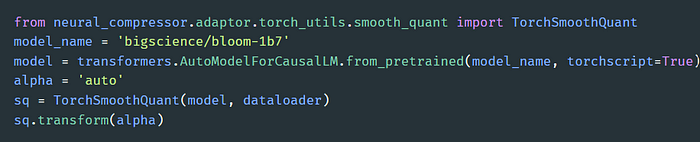
啟用增強(qiáng)型 SmoothQuant 的樣例代碼
用戶只需傳遞一個模型名稱 (model_name) 和一個數(shù)據(jù)加載器。值得注意的是,模型分析主要依靠的是 Torch JIT。用戶可以在加載Hugging Face 模型14時將 torchscript 設(shè)置為 True,或?qū)?return_dict 設(shè)置為 False。更多信息請參閱英特爾Neural Compressor 文檔10。
?結(jié)果
本文提出的增強(qiáng)型 SmoothQuant 的主要優(yōu)勢在于提高了準(zhǔn)確率。 經(jīng)過對多種主流大語言模型的評估,具備自動調(diào)優(yōu)能力的 INT8 SmoothQuant 最后一個詞元 (last-token) 的預(yù)測準(zhǔn)確率要高于原始 INT8 SmoothQuant 和 FP32 基線方法。詳見下圖: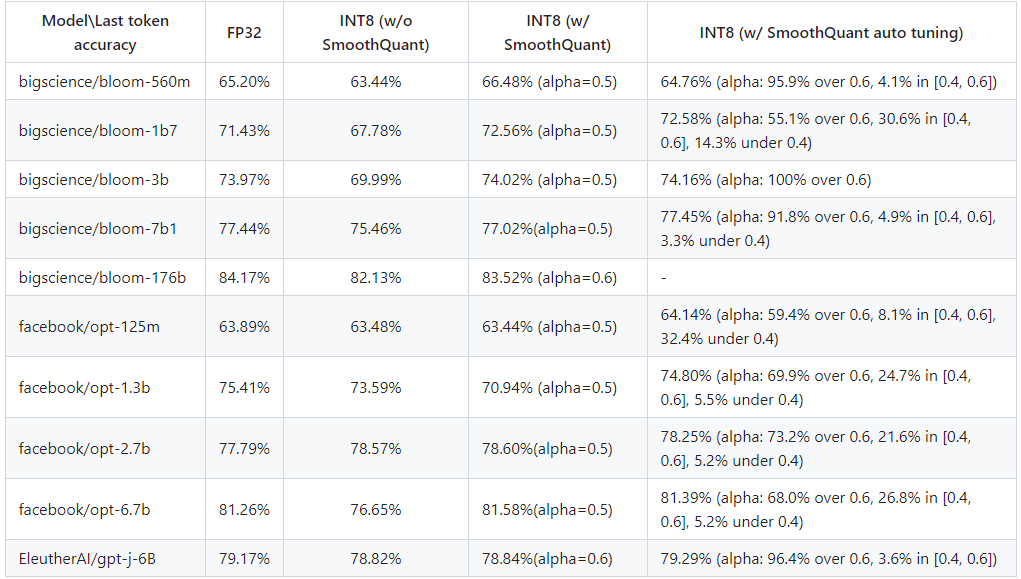
FP32 基線方法、INT8(啟用和不啟用 SmoothQuant)以及 INT8(啟用本文提出的增強(qiáng)型 SmoothQuant)的準(zhǔn)確率對比
從上圖可以看出,在 OPT-1.3b 和 BLOOM-1b7 模型上,本文提出的增強(qiáng)型 SmoothQuant 的準(zhǔn)確率比默認(rèn)的 SmoothQuant 分別高 5.4% 和 1.6%。量化后的模型也縮小到 FP32 模型的四分之一,大大減少了內(nèi)存占用空間,從而有效地提升大模型在英特爾平臺上的推理性能。 更全面的結(jié)果請見 GitHub 存儲庫10。同時,也歡迎您創(chuàng)建拉取請求或就 GitHub 問題15發(fā)表評論。期待聽到您的反饋意見和建議。 作者
他們都在從事模型量化
及壓縮的研究與優(yōu)化工作
注釋:
本文主要介紹在英特爾平臺上提升大語言模型的訓(xùn)練后量化表現(xiàn)的增強(qiáng)型SmoothQuant技術(shù),說明了這項技術(shù)的用法,并證明了其在準(zhǔn)確率方面的優(yōu)勢。本文中列出的鏈接和資源。需要說明的是,將SmoothQuant適配到英特爾平臺并實現(xiàn)它在英特爾平臺上的增強(qiáng),是英特爾的原創(chuàng)。1.英特爾Neural Compressor
https://www.intel.cn/content/www/cn/zh/developer/tools/oneapi/neural-compressor.html2.英特爾Extension for TensorFlowhttps://www.intel.cn/content/www/cn/zh/developer/tools/oneapi/optimization-for-tensorflow.html3.英特爾Extension for PyTorchhttps://www.intel.cn/content/www/cn/zh/developer/tools/oneapi/optimization-for-pytorch.html4.英特爾至強(qiáng)可擴(kuò)展處理器https://www.intel.cn/content/www/cn/zh/products/details/processors/xeon/scalable.html5.英特爾至強(qiáng)CPU Max 系列https://www.intel.cn/content/www/cn/zh/products/details/processors/xeon/max-series.html6.英特爾數(shù)據(jù)中心 GPU Flex 系列https://www.intel.cn/content/www/cn/zh/products/details/discrete-gpus/data-center-gpu/flex-series.html7.英特爾數(shù)據(jù)中心 GPU Max 系列https://www.intel.com/content/www/us/en/products/details/discrete-gpus/data-center-gpu/max-series.html8. 第四代英特爾至強(qiáng)可擴(kuò)展處理器https://www.intel.cn/content/www/cn/zh/events/accelerate-with-xeon.html9. AI 與內(nèi)存墻https://medium.com/riselab/ai-and-memory-wall-2cb4265cb0b810. SmoothQuant 相關(guān)文檔 /英特爾Neural Compressor 文檔 / GitHub 存儲庫https://github.com/intel/neural-compressor/blob/master/docs/source/smooth_quant.md11. SPIQhttps://arxiv.org/abs/2203.1464212. Outlier Suppressionhttps://arxiv.org/abs/2209.1332513. SmoothQuanthttps://arxiv.org/abs/2211.1043814. Hugging Face 模型https://huggingface.co/models15. GitHub 問題https://github.com/intel/neural-compressor/issues-
英特爾
+關(guān)注
關(guān)注
61文章
10164瀏覽量
173865 -
cpu
+關(guān)注
關(guān)注
68文章
11030瀏覽量
215876
原文標(biāo)題:如何在英特爾? 平臺上實現(xiàn)高效的大語言模型訓(xùn)練后量化
文章出處:【微信號:英特爾中國,微信公眾號:英特爾中國】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
更高效更安全的商務(wù)會議:英特爾聯(lián)合海信推出會議領(lǐng)域新型垂域模型方案

用PaddleNLP為GPT-2模型制作FineWeb二進(jìn)制預(yù)訓(xùn)練數(shù)據(jù)集

是否可以輸入隨機(jī)數(shù)據(jù)集來生成INT8訓(xùn)練后量化模型?
請問OpenVINO?工具套件英特爾?Distribution是否與Windows? 10物聯(lián)網(wǎng)企業(yè)版兼容?
英特爾?NCS2運(yùn)行演示時“無法在啟動后找到啟動設(shè)備”怎么解決?
如何在英特爾平臺上高效部署DeepSeek模型

英特爾賦能DeepSeek本地運(yùn)行,助力汽車升級“最強(qiáng)大腦”
使用英特爾AI PC為YOLO模型訓(xùn)練加速

英特爾助力百度智能云千帆大模型平臺加速LLM推理

使用PyTorch在英特爾獨立顯卡上訓(xùn)練模型





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論