") 英特爾助力百度智能云千帆大模型平臺(tái)加速LLM推理
英特爾助力百度智能云千帆大模型平臺(tái)加速LLM推理

“大模型在各行業(yè)的廣泛應(yīng)用驅(qū)動(dòng)了新一輪產(chǎn)業(yè)革命,也凸顯了在AI算力方面的瓶頸。通過攜手英特爾釋放英特爾 至強(qiáng) 可擴(kuò)展處理器的算力潛力,我們?yōu)橛脩籼峁┝烁咝阅堋㈧`活、經(jīng)濟(jì)的算力基礎(chǔ)設(shè)施方案,結(jié)合千帆大模型平臺(tái)在大模型工具鏈、豐富的預(yù)置模型等方面的升級(jí),我們將進(jìn)一步推動(dòng)大模型技術(shù)在各行各業(yè)的廣泛應(yīng)用,為企業(yè)智能化提供更多可能性。”
—— 謝廣軍
百度副總裁
“百花齊放的大模型時(shí)代呼喚著更加經(jīng)濟(jì)、可及的AI算力資源,通過百度智能云千帆大模型平臺(tái),用戶能夠快捷、高效地部署基于CPU的LLM推理服務(wù),并發(fā)揮英特爾 至強(qiáng) 可擴(kuò)展處理器在AI推理方面的巨大價(jià)值。我們將進(jìn)一步加速大模型的生態(tài)建設(shè)與軟硬件創(chuàng)新,助力更多的用戶利用大模型推動(dòng)業(yè)務(wù)創(chuàng)新。”
—— 陳葆立
英特爾數(shù)據(jù)中心與人工智能集團(tuán)副總裁
中國(guó)區(qū)總經(jīng)理
概 述
以文心大模型、Llama、GPT和ChatGLM為代表的大語言模型(LLM)展示了人工智能(AI)的驚人潛力,其在藝術(shù)創(chuàng)作、辦公、娛樂、生產(chǎn)方面的廣泛應(yīng)用激發(fā)了新一輪的產(chǎn)業(yè)革命。雖然LLM在各種自然語言處理任務(wù)中表現(xiàn)優(yōu)越,但也帶來了巨量的算力資源消耗。目前機(jī)器學(xué)習(xí)開源框架如PyTorch等雖然支持基于CPU平臺(tái)執(zhí)行計(jì)算,但CPU上的算力并沒有被充分挖掘,通用框架軟件基于CPU硬件的優(yōu)化程度欠佳,其推理性能并不能滿足真實(shí)業(yè)務(wù)的吞吐和時(shí)延需求。
百度智能云千帆大模型平臺(tái)是一個(gè)面向開發(fā)者和企業(yè)的人工智能服務(wù)平臺(tái)。它為開發(fā)者提供了豐富的人工智能模型和算法,尤其是豐富的LLM支持,能夠幫助用戶構(gòu)建各種智能應(yīng)用。為了提升基于CPU的LLM推理性能,百度智能云利用英特爾 至強(qiáng) 可擴(kuò)展處理器搭載的英特爾 高級(jí)矩陣擴(kuò)展(英特爾 AMX)等高級(jí)硬件能力,助力千帆大模型平臺(tái)在CPU端的推理加速。
挑戰(zhàn):LLM推理帶來算力、資源利用率等挑戰(zhàn)
目前開源的LLM網(wǎng)絡(luò)結(jié)構(gòu)主要以Transformer子結(jié)構(gòu)為基礎(chǔ)模塊,其推理解碼的過程是一個(gè)自回歸的過程,當(dāng)前詞的生成計(jì)算依賴于所有前文的計(jì)算結(jié)果。LLM推理過程中涉及大量的、多維度的矩陣乘法計(jì)算,在不同參數(shù)量級(jí)模型、不同并發(fā)、不同數(shù)據(jù)分布等場(chǎng)景下,模型推理的性能瓶頸可能在于計(jì)算或者帶寬,為了保證模型生成的吞吐和時(shí)延,對(duì)硬件平臺(tái)的算力和訪存帶寬都會(huì)提出較高的要求。
目前,行業(yè)還存在大量離線的LLM應(yīng)用需求,如生成文章總結(jié)、摘要、數(shù)據(jù)分析等,與在線場(chǎng)景相比,離線場(chǎng)景通常會(huì)利用平臺(tái)的閑時(shí)算力資源,對(duì)于推理的時(shí)延要求不高,而對(duì)于推理的成本較為敏感,因此用戶更加傾向采用低成本、易獲得的CPU來進(jìn)行推理。百度智能云等云平臺(tái)中部署著大量基于CPU的云服務(wù)器,釋放這些CPU的AI算力潛力將有助于提升資源利用率,滿足用戶快速部署LLM模型的需求。
此外,對(duì)于30B等規(guī)模的LLM,需要采用高規(guī)格的GPU來進(jìn)行推理,普通GPU無法支持。但是,高規(guī)格的GPU的成本較高、供貨緊缺,對(duì)于離線場(chǎng)景的用戶來說不是一個(gè)理想的選擇。而針對(duì)該場(chǎng)景,CPU不僅可以很好地支持30B及以下規(guī)模的模型,而且在性價(jià)比上更具優(yōu)勢(shì)。
解決方案:千帆大模型采用英特爾至強(qiáng)可擴(kuò)展處理器加速LLM推理
百度智能云千帆大模型平臺(tái)為企業(yè)提供大模型全生命周期工具鏈和整套環(huán)境,用戶可以在百度智能云千帆上開發(fā)、訓(xùn)練、部署和調(diào)用自己的大模型服務(wù)。其提供智能計(jì)算基礎(chǔ)設(shè)施、豐富的大模型、數(shù)據(jù)集和精選應(yīng)用范式,以及包含數(shù)據(jù)管理、模型訓(xùn)練、評(píng)估和優(yōu)化、推理服務(wù)部署、Prompt工程等大模型全生命周期工具鏈,能夠顯著提升模型精調(diào)效果和應(yīng)用集成效率。
?覆蓋大模型全生命周期:提供數(shù)據(jù)標(biāo)注,模型訓(xùn)練與評(píng)估,推理服務(wù)與應(yīng)用集成的全面功能服務(wù);
?推理能力大幅提升:可充分釋放CPU、GPU等硬件的推理性能潛力,算力利用率大幅提升,滿足不同規(guī)模模型的推理所需;
?快速應(yīng)用編排與插件集成:預(yù)置百度文心大模型與國(guó)內(nèi)外主流大模型,支持插件與應(yīng)用靈活編排,助力大模型多場(chǎng)景落地應(yīng)用。
百度智能云千帆大模型平臺(tái)可以利用百度智能云平臺(tái)中豐富的英特爾 至強(qiáng) 可擴(kuò)展處理器資源,加速LLM模型的推理,滿足LLM模型實(shí)際部署的需求。
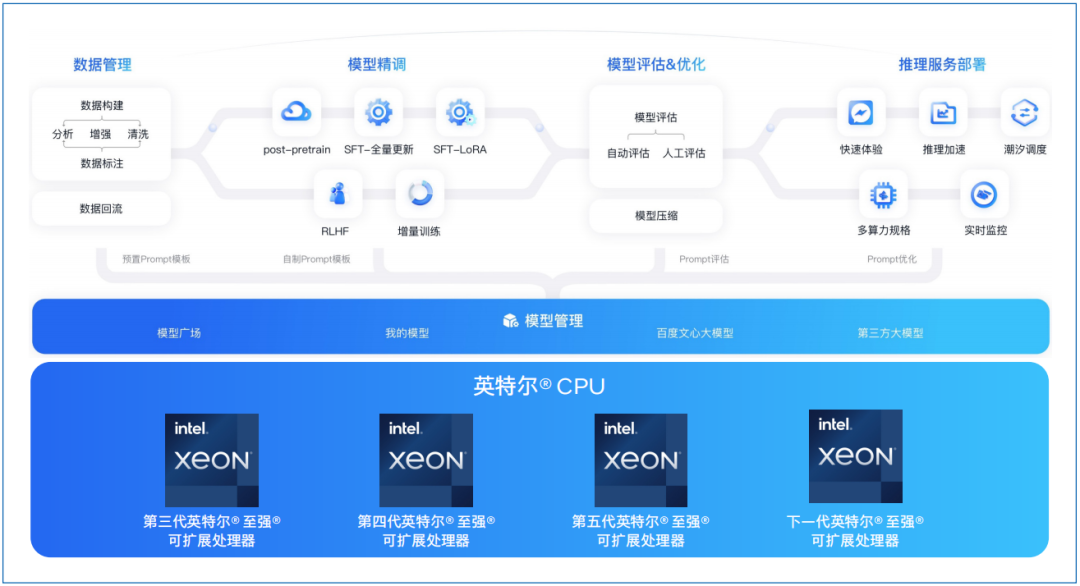
圖1. 百度智能云千帆大模型平臺(tái)支持的英特爾 CPU
新一代英特爾 至強(qiáng) 可擴(kuò)展處理器通過創(chuàng)新架構(gòu)增加了每個(gè)時(shí)鐘周期的指令,有效提升了內(nèi)存帶寬與速度,并通過PCIe 5.0實(shí)現(xiàn)了更高的PCIe帶寬提升。英特爾 至強(qiáng) 可擴(kuò)展處理器提供了出色性能和安全性,可根據(jù)用戶的業(yè)務(wù)需求進(jìn)行擴(kuò)展。借助內(nèi)置的加速器,用戶可以在AI、分析、云和微服務(wù)、網(wǎng)絡(luò)、數(shù)據(jù)庫(kù)、存儲(chǔ)等類型的工作負(fù)載中獲得優(yōu)化的性能。通過與強(qiáng)大的生態(tài)系統(tǒng)相結(jié)合,英特爾 至強(qiáng) 可擴(kuò)展處理器能夠幫助用戶構(gòu)建更加高效、安全的基礎(chǔ)設(shè)施。
第四代和第五代英特爾 至強(qiáng) 可擴(kuò)展處理器中內(nèi)置了英特爾 AMX加速器,可優(yōu)化深度學(xué)習(xí)(DL)訓(xùn)練和推理工作負(fù)載。英特爾 AMX架構(gòu)由兩部分組件構(gòu)成:第一部分為TILE,由8個(gè)1KB大小的2D寄存器組成,可存儲(chǔ)大數(shù)據(jù)塊。
第二部分為平鋪矩陣乘法(TMUL),它是與TILE連接的加速引擎,可執(zhí)行用于AI的矩陣乘法計(jì)算。英特爾 AMX支持INT8和BF16兩種數(shù)據(jù)類型以滿足不同精度的加速需求。AMX讓英特爾 至強(qiáng) 可擴(kuò)展處理器實(shí)現(xiàn)了大幅代際性能提升,與內(nèi)置英特爾 高級(jí)矢量擴(kuò)展512矢量神經(jīng)網(wǎng)絡(luò)指令(Intel Advanced Vector Extensions 512 Vector Neural Network Instructions,英特爾 AVX-512 VNNI)的第三代英特爾 至強(qiáng) 可擴(kuò)展處理器 相比,內(nèi)置英特爾 AMX的第四代英特爾 至強(qiáng) 可擴(kuò)展處理器將單位計(jì)算周期內(nèi)執(zhí)行INT8運(yùn)算的次數(shù)從256次提高至2048次,是AVX512_VNNI同樣數(shù)據(jù)類型的8倍。
英特爾 至強(qiáng) 可擴(kuò)展處理器可支持High Bandwidth Memory(HBM)內(nèi)存,高帶寬內(nèi)存HBM和DDR5相比,具有更多的訪存通道和更長(zhǎng)的讀取位寬,理論帶寬可達(dá)DDR5的4倍。雖然HBM的容量相對(duì)較小(每個(gè)CPU Socket 64 GB),每個(gè)物理核心僅可以平均獲得超過1GB的高帶寬內(nèi)存容量,但對(duì)于包括大模型推理任務(wù)在內(nèi)的絕大多數(shù)計(jì)算任務(wù),HBM可以容納全部的權(quán)重?cái)?shù)據(jù),顯著提升訪存限制型的計(jì)算任務(wù)。經(jīng)實(shí)測(cè),在真實(shí)的大模型推理任務(wù)上可以實(shí)現(xiàn)明顯的端到端加速。
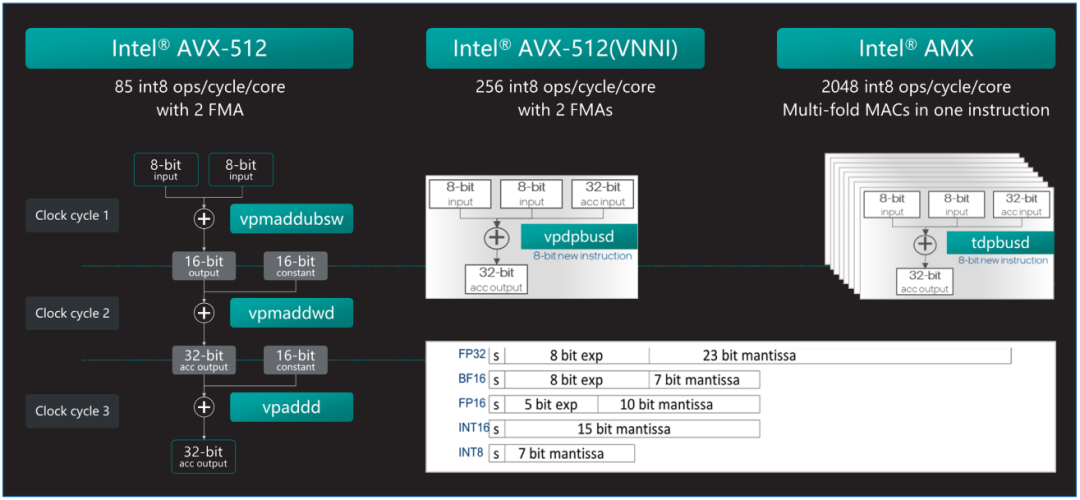
圖2. 英特爾 AMX可以更高效的實(shí)現(xiàn)AI加速
百度智能云千帆大模型平臺(tái)采用基于AMX加速器和HBM硬件特性極致優(yōu)化的大模型推理軟件解決方案xFasterTransformer(xFT),進(jìn)一步加速英特爾 至強(qiáng) 可擴(kuò)展處理器的LLM推理速度。軟件架構(gòu)的詳細(xì)信息如圖3所示,其具備如下優(yōu)勢(shì):
?通過模型轉(zhuǎn)換工具,xFT實(shí)現(xiàn)了對(duì)HuggingFace上開源模型格式的全面支持。
?軟件的核心高性能計(jì)算庫(kù)包括oneDNN、MKL以及針對(duì)LLM特別優(yōu)化的計(jì)算實(shí)現(xiàn),這些高性能計(jì)算庫(kù)把對(duì)AMX/AVX512等加速部件的相關(guān)實(shí)現(xiàn)進(jìn)行隱藏,上層的LLM基礎(chǔ)算子實(shí)現(xiàn)以及網(wǎng)絡(luò)層的實(shí)現(xiàn)都建立在此基礎(chǔ)之上,形成了軟件和硬件特性的解耦。
?最上層提供C++以及Python接口方便測(cè)試,且由于全部的核心代碼均基于C++實(shí)現(xiàn),因此集成進(jìn)現(xiàn)有的框架非常便捷。
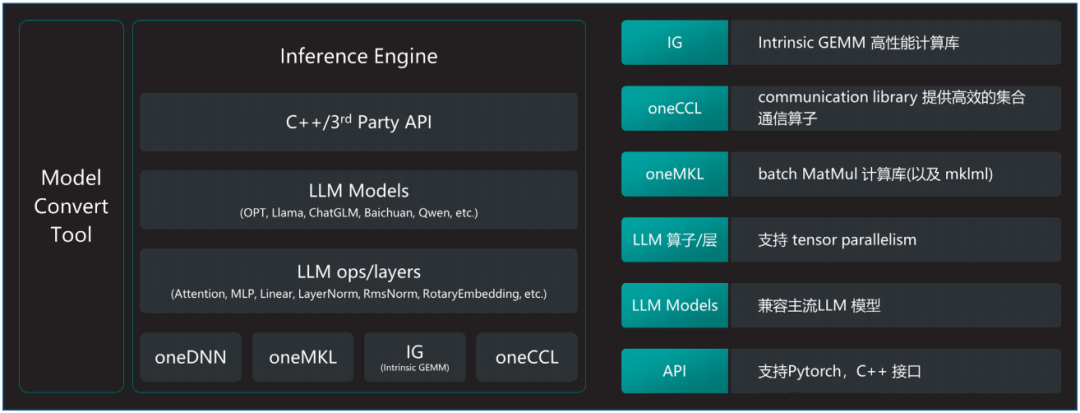
圖3. 英特爾 至強(qiáng) 可擴(kuò)展處理器LLM推理軟件解決方案
具體的優(yōu)化策略如下:

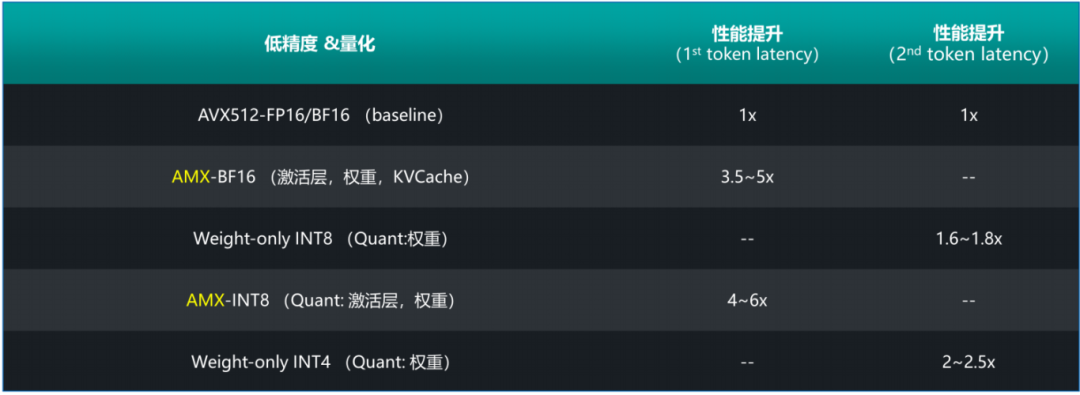
圖4. 將模型轉(zhuǎn)化為低精度數(shù)據(jù)格式可帶來性能提升
在千帆大模型平臺(tái)上實(shí)現(xiàn)CPU推理加速
當(dāng)前千帆大模型平臺(tái)已經(jīng)引入了針對(duì)英特爾 至強(qiáng) 可擴(kuò)展平臺(tái)深度優(yōu)化的LLM推理軟件解決方案xFT,并將其作為后端推理引擎,助力用戶在千帆大模型平臺(tái)上實(shí)現(xiàn)基于CPU的LLM推理加速。目前,使用該方案針對(duì)超長(zhǎng)上下文和長(zhǎng)輸出進(jìn)行了優(yōu)化,已經(jīng)支持Llama-2-7B/13B,ChatGLM2-6B等模型部署在線服務(wù)(參見表1)。
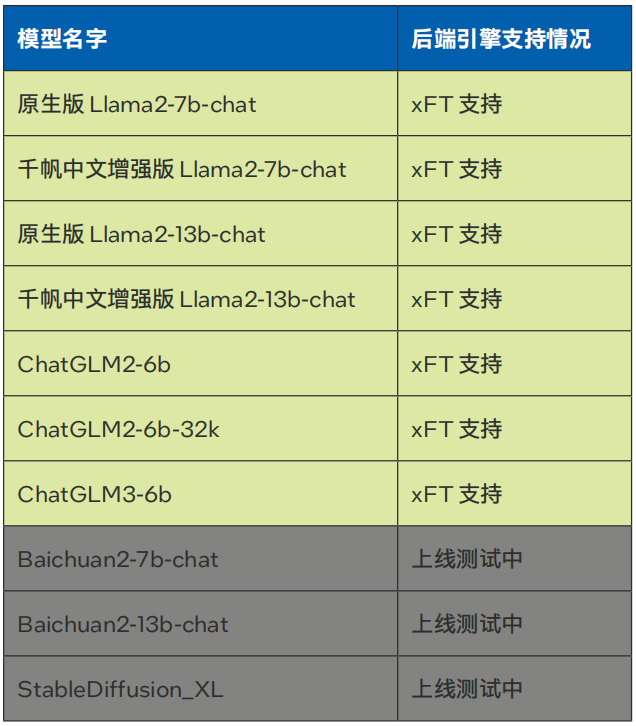
表1. 百度智能云千帆大模型平臺(tái)xFasterTransformer后端支持模型種類
Llama-2-7b模型測(cè)試數(shù)據(jù)如圖5和圖6所示,第四代英特爾 至強(qiáng) 可擴(kuò)展處理器上輸出Token吞吐可達(dá)100TPS以上,相比第三代英特爾 至強(qiáng) 可擴(kuò)展處理器提升了60%。在低延遲的場(chǎng)景,同等并發(fā)下,第四代英特爾 至強(qiáng) 可擴(kuò)展處理器的首Token時(shí)延比第三代英特爾 至強(qiáng) 可擴(kuò)展處理器可降低50%以上。在將處理器升級(jí)為第五代英特爾 至強(qiáng) 可擴(kuò)展處理器之后,吞吐可提升45%左右,首Token時(shí)延下降50%左右1 。
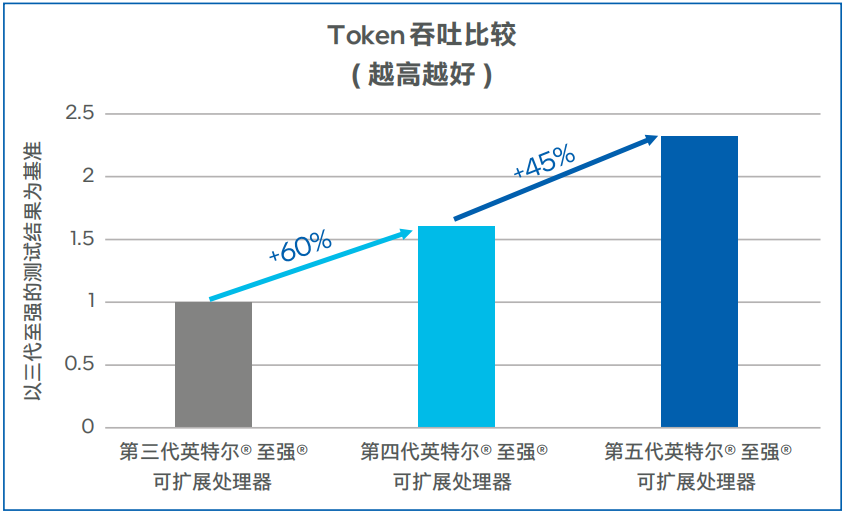
圖5. Llama-2-7b模型輸出Token吞吐
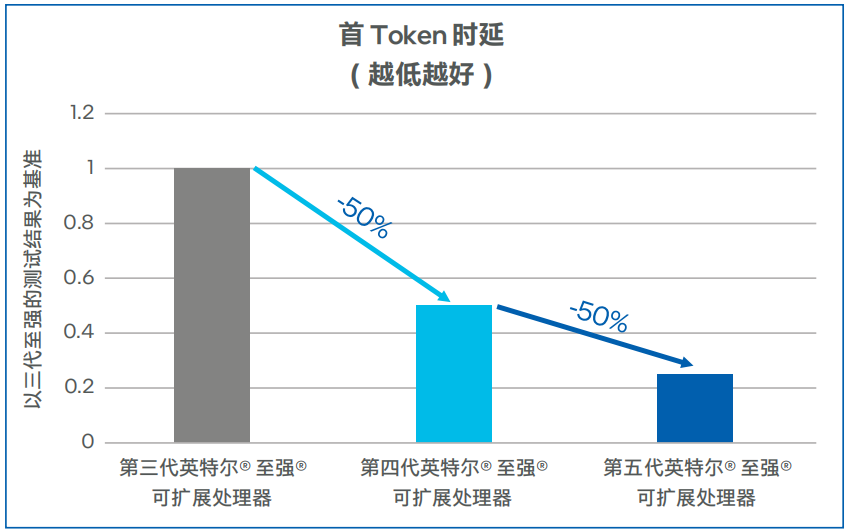
圖6. Llama-2-7b模型首Token時(shí)延
方案效果
通過在千帆大模型平臺(tái)中采用英特爾 至強(qiáng) 可擴(kuò)展處理器進(jìn)行LLM模型推理,方案效果如下:
?通過千帆大模型平臺(tái)提供的全生命周期工具鏈,快速在英特爾 至強(qiáng) 可擴(kuò)展平臺(tái)中部署LLM模型推理服務(wù);
?高效釋放英特爾 至強(qiáng) 可擴(kuò)展處理器的AI推理性能,降低LLM生成時(shí)延,提供更佳的服務(wù)體驗(yàn);
?針對(duì)30B以下規(guī)模的LLM模型,皆可采用英特爾 至強(qiáng) 可擴(kuò)展處理器結(jié)合xFT推理解決方案,獲得良好性能體驗(yàn);
?利用充足的CPU資源,降低對(duì)于AI加速卡的需求,從而降低LLM推理服務(wù)的總體擁有成本(TCO),特別是在離線的LLM推理場(chǎng)景中表現(xiàn)出色。
展 望
通過xFasterTransformer等軟件方案,百度智能云千帆大模型平臺(tái)充分利用了英特爾 至強(qiáng) 可擴(kuò)展處理器的計(jì)算能力以及新一代AI內(nèi)置加速引擎英特爾 AMX,成功解決了大模型推理中的計(jì)算密集型和訪存受限型算子挑戰(zhàn),實(shí)現(xiàn)了基于CPU的LLM推理加速,助力用戶更加高效地利用CPU資源。
未來,英特爾與百度將繼續(xù)深化合作,推動(dòng)大模型平臺(tái)的發(fā)展,計(jì)劃進(jìn)一步優(yōu)化LLM推理算法和實(shí)現(xiàn),提升推理性能和計(jì)算資源效率,使得更多類型和規(guī)模的大模型能夠在CPU平臺(tái)上得到支持和加速。同時(shí),雙方將不斷完善軟硬件配套解決方案,提供更加全面和靈活的技術(shù)支持,滿足用戶在自然語言處理領(lǐng)域的不斷增長(zhǎng)的需求。
-
處理器
+關(guān)注
關(guān)注
68文章
19890瀏覽量
235098 -
英特爾
+關(guān)注
關(guān)注
61文章
10194瀏覽量
174659 -
大模型
+關(guān)注
關(guān)注
2文章
3138瀏覽量
4061
原文標(biāo)題:看至強(qiáng)? 可擴(kuò)展處理器如何為千帆大模型平臺(tái)推理加速
文章出處:【微信號(hào):英特爾中國(guó),微信公眾號(hào):英特爾中國(guó)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
65%央企大模型落地首選百度智能云
將英特爾?獨(dú)立顯卡與OpenVINO?工具套件結(jié)合使用時(shí),無法運(yùn)行推理怎么解決?
百度智能云千帆AppBuilder全面接入DeepSeek模型
百度智能云發(fā)布昆侖芯三代萬卡集群及DeepSeek-R1/V3上線
百度智能云四款大模型應(yīng)用接入DeepSeek
百度智能云四款大模型應(yīng)用完成DeepSeek適配
百度云與阿里云上線DeepSeek模型部署服務(wù)
新品| LLM630 Compute Kit,AI 大語言模型推理開發(fā)平臺(tái)

英特爾與扣子云平臺(tái)合作推出AI PC Bot專區(qū)與端側(cè)插件商店
ElfBoard開源項(xiàng)目|百度智能云平臺(tái)的人臉識(shí)別項(xiàng)目

英特爾攜手百度智能云加速AI落地
英特爾與百度共同為AI時(shí)代打造高性能基礎(chǔ)設(shè)施

開箱即用,AISBench測(cè)試展示英特爾至強(qiáng)處理器的卓越推理性能






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論