") 開發(fā)和部署ML模型介紹
開發(fā)和部署ML模型介紹
本系列介紹 開發(fā)和部署 ( M L ) 模型 。本文概述了 ML 工作流,考慮到使用機器學習和數(shù)據(jù)科學來實現(xiàn)業(yè)務價值所涉及的各個階段。在第 2 部分中,訓練并保存 ML 模型 可以將其部署為 ML 系統(tǒng)的一部分。第 3 部分向您展示了 如何部署 ML 模型到 Google 云平臺 ( GCP )。
當使用 machine learning 解決問題并提供業(yè)務價值時,您使用的技術、工具和模型會根據(jù)用例而變化。然而,當從一個想法轉(zhuǎn)移到一個已部署的模型時,需要經(jīng)過一組通用的工作流階段。
之前,我討論過 如何搭建機器學習微服務 和 如何使用 Streamlit 和 FastAPI 構(gòu)建即時機器學習 Web 應用程序 。在這兩個教程中, ML 模型僅在本地運行。這對于演示來說已經(jīng)足夠了,但如果您的模型必須在互聯(lián)網(wǎng)上持續(xù)提供預測,則這是不切實際的。
機器學習工作流
ML 工作流包含以下主要組件:
勘探和數(shù)據(jù)處理
建模
部署
每個階段都可以細分為更小的程序。
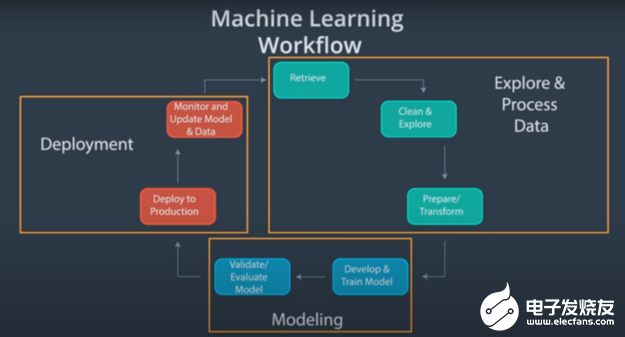 圖 1. 機器學習工作流
圖 1. 機器學習工作流
(Source: Become a Machine Learning Engineer Nanodegree (Udacity) )
圖 1 顯示了典型機器學習項目的端到端工作流的可視化表示。下面是有關每個組件的更多信息。
勘探和加工
重要的工作是確保用于 ML 項目的數(shù)據(jù)集質(zhì)量良好,因為這些數(shù)據(jù)是建模階段可靠性能的基礎。如果您向模型提供低質(zhì)量的數(shù)據(jù),則可能會產(chǎn)生較差或錯誤的結(jié)果。
這部分工作流程通常占用最多的時間。數(shù)據(jù)勘探和處理可進一步分為以下幾個階段:
Data retrieval : ML 項目需要高質(zhì)量的數(shù)據(jù),而這些數(shù)據(jù)并不總是可以立即訪問的。您可能需要實施數(shù)據(jù)采集技術,例如刮取或手動數(shù)據(jù)采集。
數(shù)據(jù)清理和探索 :數(shù)據(jù)也很少能夠立即處理。您必須對其進行清理,以在所需的用例中獲得最佳性能。您還應該了解正在使用的數(shù)據(jù)集,因此需要進行探索。
數(shù)據(jù)準備或轉(zhuǎn)換 :在最后階段,對數(shù)據(jù)進行設計,以提取正在解決的現(xiàn)實世界問題的代表性特征。然后將數(shù)據(jù)轉(zhuǎn)換為 ML 模型可以使用的格式。
建模
當大多數(shù)數(shù)據(jù)從業(yè)者想到機器學習時,他們的注意力都集中在建模組件上。建模階段包括以下階段:
模型開發(fā)和培訓 :這一階段是關于向機器學習模型提供數(shù)據(jù),然后調(diào)整超參數(shù),以便模型可以很好地推廣到不可見的數(shù)據(jù)輸入。
模型驗證和評估 :必須評估機器學習模型的性能,以確定其行為是否符合預期。這涉及到確定一個數(shù)字度量,以評估模型對未知數(shù)據(jù)輸入的性能。
模型部署
最后,部署階段涉及使最終用戶可以訪問 ML 模型,監(jiān)控模型在生產(chǎn)中的性能,并更新模型。
部署 ML 模型不僅僅是孤立的模型。數(shù)據(jù)從業(yè)者部署整個 ML 管道,這決定了如何編碼和自動化端到端工作流。
如何實現(xiàn)這一點有幾個選項。
不同的模型部署選項
生成 ML 應用程序是為了解決特定問題。因此,任何 ML 應用程序的真正價值通常只有在模型或算法在生產(chǎn)環(huán)境中被積極使用時才能實現(xiàn)。
將 ML 模型從離線研究環(huán)境轉(zhuǎn)換到實時生產(chǎn)環(huán)境的過程稱為 deployment 。
部署是 ML 工作流的一個關鍵組件。它使模型能夠達到其預期目的。在項目規(guī)劃階段,必須考慮如何部署 ML 模型。在決定部署類型時要考慮的因素超出了本文的范圍。然而,我提供了一些關于可用選項的見解。
Web 服務
部署機器學習模型最直接的選擇是創(chuàng)建 web 服務。這意味著通過查詢 web 服務來獲得來自模型的預測。
使用 web 服務部署機器學習模型包括以下主要步驟:
Building the model: 必須創(chuàng)建 ML 模型,然后將其包裝在 web 服務中。然而,模型構(gòu)建通常需要與主 web 服務應用程序不同的一組資源。將模型培訓和 web 服務應用程序環(huán)境分開是有意義的。
構(gòu)建 web 應用程序: 訓練模型后,必須將其持久化,以便將其導入 web 應用程序。 web 應用程序是使用開發(fā) web 服務的框架(如 Flask 、 FastAPI 和 Django )包裝的推理邏輯。
托管 web 服務: 為了讓您的 web 服務全天候、自動化和可擴展,您必須托管應用程序。這可以通過使用托管提供商來完成。在本系列的第三部分中,您將使用 Google App Engine 。
有關前兩個步驟的更多信息,請參見 Building a Machine Learning Microservice with FastAPI 。
無服務器計算
使用無服務器計算部署機器學習模型意味著您希望為模型預測提供服務,而不必擔心如何管理底層基礎設施,例如計算資源。
仍然有一個服務器。所發(fā)生的一切是,您將管理服務器的責任交給了云提供商。現(xiàn)在,您可以更加專注于編寫性能更好的代碼。
無服務器計算提供程序的示例包括:
Amazon Web Services (AWS) Lambda
Microsoft Azure
Google Cloud Functions
要使用 Google Cloud Functions 部署機器學習模型,請參閱本系列的第 3 部分“實踐中的機器學習:在 Google Cloud Provider 上部署 ML 模型[LINK]”。
托管 AI 云
一個管理的人工智能云正是它在錫上所說的。您提供了一個串行化模型,云提供商以較少的控制為代價,為您完全管理基礎架構(gòu)。換句話說,您可以獲得云計算的優(yōu)化好處,而不必成為任何方面的專家。
托管 AI 云提供商的示例包括:
Amazon SageMaker
Google Cloud AI Platform
IBM Watson
Microsoft Azure Machine Learning
接下來是什么?
現(xiàn)在您已經(jīng)了解了端到端 ML 工作流,并且已經(jīng)看到了部署 ML 模型的可能方法,請繼續(xù)第 2 部分 Machine Learning in Practice: Build an ML Model ,在這里您將根據(jù)一些數(shù)據(jù)訓練模型。
-
NVIDIA
+關注
關注
14文章
5240瀏覽量
105768 -
AI
+關注
關注
87文章
34197瀏覽量
275348 -
機器學習
+關注
關注
66文章
8491瀏覽量
134083
發(fā)布評論請先 登錄
添越智創(chuàng)基于 RK3588 開發(fā)板部署測試 DeepSeek 模型全攻略
介紹在STM32cubeIDE上部署AI模型的系列教程
eIQ軟件對ML模型有何作用
介紹一種Arm ML嵌入式評估套件
通過Cortex來非常方便的部署PyTorch模型
部署基于嵌入的機器學習模型
如何將ML模型部署到微控制器?
使用Flask和Docker容器化一個簡單的ML模型評分服務器
GTC2022大會亮點:Modulus用于開發(fā)physics-ML模型的AI框架
管理 ML 模型部署中的權(quán)衡
PerfXCloud大模型開發(fā)與部署平臺開放注冊





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論