 利用AMD本能加速器將HPC的可持續性提升到一個新的水平
利用AMD本能加速器將HPC的可持續性提升到一個新的水平
高性能計算 (HPC) 已成為我們現代世界的重要組成部分,執行對科學研究、工程、安全和其他領域至關重要的復雜模擬和計算。然而,隨著對HPC的需求不斷增長,通常是在超級計算機和大型數據中心,對其環境影響的擔憂也在增加。近年來,鑒于對總擁有成本和氣候問題的影響,人們越來越關注數據中心的可持續性。在這篇博文中,我們將探討有關數據中心能效的一些關鍵問題,并討論 AMD 幫助減少 HPC 對環境的影響的一些策略。
數據中心面臨的最大挑戰之一是當您擴展到百萬兆次級及更高規模時,它們的能耗。服務器節點消耗大量能量,HPC 需要更多能量,其所有 CPU 和加速器,這使得提高效率成為重要優先事項。隨著對 HPC 計算需求的不斷增加,我們遇到了能耗是一個門控因素的情況。這種能源消耗不僅給環境帶來了壓力,也給數據中心運營商的底線帶來了壓力,因為行業需要更多的計算性能。因此,隨著行業邁向下一個里程碑,需要大幅提高每瓦性能。
由于 AMD 是尖端服務器 CPU 和 GPU 的設計者,我們認識到我們在解決這些關鍵優先事項方面的重要作用。我們專注于提高服務器能效,降低數據中心總擁有成本 (TCO),并提供高性能計算 (HPC),以幫助應對世界上一些最嚴峻的挑戰。早在 2021 年 2 月,AMD 就宣布了一個雄心勃勃的目標,即提高運行處理器的能效......要實現這一目標,AMD 需要以比過去五年中全行業總體改進快 5.<> 倍以上的速度提高計算節點的能效。
AMD Instinct? 加速器通過在設備和系統級別提供卓越的每瓦性能,從而實現高能效的 HPC 和 AI,從而提高計算的能效。要實現 AMD HPC 和 AI 能效目標,需要圍繞架構、內存和互連進行更高水平的思考,這些架構、內存和互連相結合,可加速系統級改進。對于我們的 AMD Instinct MI200 系列加速器,我們從多方面的角度看待它,我們將在下面更詳細地解釋一些關鍵技術,以實現每瓦特和效率的領先性能。
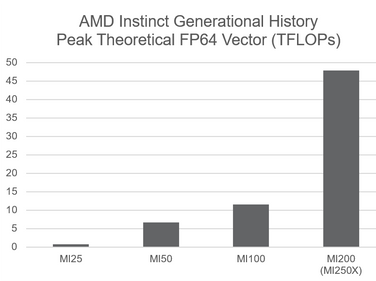
架構技術 – MI2 系列中的 AMD CDNA? 200 架構通過增強面向 HPC 和 AI 的矩陣核心技術,推動雙精度浮點數據和各種矩陣乘法基元的計算能力,代表了與上一代產品相比的重大飛躍。一個特別強調的是使用FP64矩陣和矢量數據的科學計算,以便在橡樹嶺國家實驗室前沿超級計算機等大型系統中擴展時實現百萬兆次級的性能,性能為1.1 exaflops。與上一代 MI4 CDNA 架構相比,這些改進使 FP64 矢量 TFLOP/s 和 2.5 倍 FP64 TFLOPS/瓦特相應提高了 100 倍,從而提高了每瓦性能。
封裝技術 – 小芯片和先進的封裝技術是提高性能和整體效率的巨大杠桿。它們允許您將不同的技術用于不同的功能,組合多個加速器芯片,并使加速器更接近內存等。互連密度越密集,解決方案的效率就越高,并有助于降低昂貴的數據傳輸能耗。
MCM - 全球首款多芯片 GPU,旨在通過單個封裝最大限度地提高計算和數據吞吐量。MI250 和 MI250X 在單個封裝中使用兩個 AMD CDNA 2 圖形內核芯片 (GCD),在高度精簡的封裝中提供 58 億個晶體管,與 AMD 上一代加速器相比,內核數量增加了 1.8 倍,內存帶寬提高了 2.6 倍 。兩個GCD通過高速接口連接在一起,用于芯片到芯片的通信。
高架扇出橋 – 將 AMD CDNA 芯片連接到基板上各自的 HBM2E 內存堆棧,這可以降低復雜性并提高可擴展性,同時降低成本。傳統上,硅中介層部署有微凸塊以支持高密度互連。這種方法需要一個大的硅襯底來支撐上面的整個硅加HBM組件。
通信技術 – 在開發高性能計算機時,通信是處理大量數據的關鍵。在處理器和外部世界之間高效移動數據的能力對于向上和向外擴展的系統性能也至關重要。將硅芯片在物理和電氣上更緊密地結合在一起,可以大大降低通信能量,同時提供更高的吞吐量潛力。AMD Infinity 架構是我們在 CPU 和 GPU 以及 GPU 到 GPU 之間的高速通信高速公路,我們將在加速器中討論提高通信效率的兩個領域。
芯片到芯片互連 - 封裝內 AMD 無限結構?接口是 AMD CDNA 2 系列的關鍵創新之一,可連接 MI2 或 MI250X 中的 250 個 GCD。它利用封裝內 GCD 之間的極短距離,以 25 Gbps 和極低的功耗運行,在 GCD 之間提供高達 400 GB/s 的理論最大雙向帶寬。
Infinity Architecture – 最新的 AMD Instinct 產品使用我們的第 3 代 Infinity Fabric,與上一代產品相比有了顯著的改進。MI200 系列為 AMD Instinct? MI8(或 MI2X)加速器上的 GPU P250P 或 I/O 提供多達 250 個外部無限結構?鏈路,提供高達 800 GB/s 的總理論帶寬,提供高達 235% 的 GPU P2P(或 I/O)理論帶寬性能,是上一代產品 (3)。
結論
如今,AMD 使用我們當前的 EPYC(霄龍)和本能處理器和加速器為一些最高效的超級計算機提供支持。Green500 是超級計算機的行業排名,每年兩次通過測量每瓦性能按能效排名。AMD 在最新的 2 年 7 月 Green2023 名單上保持著 #500 到 #<> 的位置,這證明了 AMD CPU 和 GPU 技術不僅提供了一些最強大的超級計算機,而且還提供了名單上一些最節能的超級計算機。
為了推動Zetascale的未來計算里程碑,需要圍繞架構、內存和互連進行更高水平的思考,這些架構、內存和互連相結合,以加速系統級改進。AMD 已經邁出了第一步,將關鍵部分組合成一個新的加速器,其中包括最好的 AMD EPYC(霄龍)? CPU 和 AMD 本能?加速器,旨在實現比之前的 MI250 設計更高的代際效率和性能提升。這款名為 MI300 的全新 AMD Instinct 加速器將成為全球首款結合 CPU + GPU + 共享 HBM 的集成數據中心 APU,并提供突破性的架構,為未來的百萬兆次級 AI 和 HPC 超級計算機提供動力。正是 MI300 上的單片集成利用了剛才討論的所有方法,實現了比之前的 MI250 設計更大的代際效率提升。
總之,長期提高計算機能效對于降低運營成本和推進高性能計算機、超級計算機和數據中心的可持續發展目標非常重要。AMD Instinct 團隊致力于解決設備和系統級別的每瓦性能問題,從而提高計算效率并推進數據中心對 HPC 和 AI 的可持續性。
審核編輯:郭婷
-
cpu
+關注
關注
68文章
11040瀏覽量
216042 -
加速器
+關注
關注
2文章
824瀏覽量
38935 -
服務器
+關注
關注
13文章
9702瀏覽量
87318
發布評論請先 登錄
玩游戲能減少延時,超級QQ登陸IP隱藏軟件 智雨網絡加速器
把可持續性運營放在最前線
如何進行電流檢測放大器使用,以達到電壓提升到可用水平?
使用AMD-Xilinx FPGA設計一個AI加速器通道
英飛凌穩居全球最具可持續性公司行列 再度入選《可持續性年鑒》
手機 UL 110 可持續性標準認證被 EPEAT 認證系統采用
利用以下八個開源AI技術,你的機器學習項目可提升到新水平
歐司朗的Oslon為新概念提升了HX 將駕駛員輔助系統提升到一個新的水平
如何利用物聯網將工業自動化提升到新的水平
AMD宣布推出全新AMD Instinct MI200系列加速器








 工商網監
工商網監
評論