") 邊緣AI開發(fā),如何駛上快車道?
邊緣AI開發(fā),如何駛上快車道?
在云計算之后,邊緣計算將成為未來十年物聯(lián)網市場新的增長點,這已經是不爭的事實。據(jù)市場研究機構Gartner預測,到2025年將有75%的數(shù)據(jù)產生于網絡邊緣,也就是說整個智能世界的計算資源分布重心正在移向“邊緣”。
不同于傳統(tǒng)云計算架構中將所有計算資源都集中在云端的做法,邊緣計算將更多的計算任務放到網絡邊緣端完成,這樣的計算架構在減少延遲、避免大量數(shù)據(jù)傳輸對帶寬的占用、保護本地敏感數(shù)據(jù)安全等方面有獨特的優(yōu)勢。
特別是隨著人工智能(AI)應用的普及,“在云端訓練,在邊緣端推理”的模式已被普遍認同。通過在邊緣設備中部署經過訓練的機器學習模型,讓邊緣設備能夠快速、高效地完成AI推理工作,可以促使越來越多的AI應用加速落地。
國際電信咨詢公司STL Partners預測,邊緣計算的潛在市場將從2020年的90億美元快速攀升至2030年的4,450億美元,復合年增長率高達48%!而如此蓬勃發(fā)展的市場,也給置身其中的玩家提出了更高的要求——想要跟上市場發(fā)展的速度,就需要你的邊緣AI開發(fā)也能夠駛入快車道。
邊緣AI催生自適應計算
應用開發(fā)想要“上高速”,一個先決條件就是要選一臺跑得快的好“車”——針對邊緣AI開發(fā)來講,就是要挑選一個可以任性“加速”的開發(fā)平臺。
一個AI推理應用,既需要對AI處理部分進行加速,也需要滿足非AI的預處理和后處理等環(huán)節(jié)的功能要求,也就是說要對整體的應用流程進行優(yōu)化。
針對這樣的開發(fā)需求,使用單一架構的通用CPU,雖然靈活可擴展,可以支持不同應用的要求,但對于整體應用流程加速顯然會捉襟見肘,力不從心。而如果為AI應用開發(fā)專門的ASIC或ASSP,雖然可以提供高度優(yōu)化的應用實現(xiàn)方案以及高確定性與低時延,但又會面臨著開發(fā)周期長、研發(fā)成本高的困擾。與此同時,采用固定專用芯片架構還面臨著一個更嚴峻的挑戰(zhàn),那就是AI模型的技術迭代速度遠遠快于芯片開發(fā)的周期,這就會導致芯片好不容易開發(fā)出來就已經落伍了,成為無可挽回的沉沒成本。
圖1:AI推理應用需要全流程的整體應用加速
(圖源:AMD)
面對多樣化的邊緣應用、快速迭代的AI技術,既然通用的CPU和專用的芯片都無法滿足要求,就需要一種新的開發(fā)平臺來補位——這就是基于可編程邏輯的自適應計算平臺。
所謂自適應計算平臺,就是在不同規(guī)模的FPGA結構上集成一個或多個嵌入式CPU 子系統(tǒng)、IO及其他外設模塊的異構計算平臺。這種平臺也被稱為自適應SoC或FPGA SoC,它既有嵌入式CPU子系統(tǒng)所具備的靈活性,又可通過硬件編程提供所需的數(shù)據(jù)處理加速性能,因此開發(fā)者能夠將正確的任務分配給正確的計算引擎,最終既能夠為AI推理進行加速,又可以滿足非AI部分的計算要求,進而為各類特定應用提供理想的解決方案。而且,即使工作負載或標準發(fā)生演進和變化,自適應SoC仍能根據(jù)需要快速配置、靈活適應。
正是因為自適應SoC兼具性能和靈活性的優(yōu)勢,近年來其已經發(fā)展成為邊緣計算中一個重要的計算架構,也是FPGA廠商在著力打造的一個產品線。比如AMD的ZynqUltraScale+TMMPSoC器件就是其中的代表作。(如圖2所示)

圖2:ZynqUltraScale+TMMPSoC平臺框圖
(圖源:AMD)
加速自適應計算的應用開發(fā)
顯而易見,自適應計算SoC可以為用戶帶來三重自由度,即軟件可編程能力、硬件可編程能力以及嵌入式平臺的可擴展能力。
不過這種“自由度”對開發(fā)者來講也是一把“雙刃劍”——它們雖然比其他嵌入式計算架構更加靈活,但也會令開發(fā)變得更加復雜。這種復雜性來自兩個方面:其一,F(xiàn)PGA的設計開發(fā)流程本身就有較高的門檻,能夠熟練掌握的開發(fā)者并不多;其二,基于異構平臺的整體優(yōu)化,往往需要多個團隊之間的協(xié)同工作,使得開發(fā)時間和成本不易掌控。
因此,雖然自適應計算SoC對性能的“加速”能力顯而易見,但是想讓其應用開發(fā)過程也得以“加速”,并不是一件簡單的事。
不過,聰明的工程師們總有辦法讓“不簡單”的事情變簡單。在“為自適應計算應用開發(fā)加速”這件事兒上,AMD的工程師就為開發(fā)者們提供了一個可行而高效的方法——基于自適應系統(tǒng)模塊(SOM)的解決方案。
所謂SOM,想必大家不會陌生,這是一個集成了內核芯片以及外圍的存儲器、IO接口等功能電路的完整計算系統(tǒng),它通常不是獨立使用的,而是要通過連接器插入到母板(即一個更大型的邊緣應用系統(tǒng))中實現(xiàn)一個特定的完整應用。
SOM為開發(fā)者帶來的好處,歸納起來主要有三點:
#1
首先,SOM都是經過嚴格調試、測試和驗證的產品,因此開發(fā)過程不必從更為底層的芯片進行,可以節(jié)省大量的時間和成本。
其次,SOM具有很強的可擴展性,插入不同的系統(tǒng)板,即能實現(xiàn)定制的方案,這就為系統(tǒng)設計帶來了更強的靈活性與易用性。
#2
#3
此外,SOM是可量產化的,在性價比、可靠性等方面都經過了全面的優(yōu)化,因此使用在批量的商用產品中完全沒有問題。
而上面這些優(yōu)勢,正是自適應計算應用開發(fā)中面臨的“痛點”,因此設計一個自適應SOM,并利用其為自適應計算提速,為邊緣AI方案賦能,也就成了駛上邊緣AI“高速公路”的關鍵“入口”。
AMD的自適應SOM
AMD的Kria K26 SOM就是大家在駛入邊緣AI快車道時,在尋找的這個關鍵“入口”。

圖3:Kria K26 SOM
(圖源:AMD)
該SOM基于Zynq UltraScale+ MPSoC架構,內置一個64位的四核Arm Cortex-A53應用處理器組,并配套一個32位的雙核Arm Cortex-R5F實時處理器和一個Arm Mali-400MP2 3D圖形處理器。SOM上還包括4GB的64位DDR4存儲器和QSPI與eMMC存儲器。
Kria K26 SOM可提供25.6萬個系統(tǒng)邏輯單元、1,248個DSP、26.6Mb的片上內存。這使得用戶能夠獲得豐富的資源和設計自由度,以實現(xiàn)不同應用中的視覺功能以及可編程邏輯中額外的機器學習預處理和后處理硬件加速功能。
此外,該SOM還為H.264/H.265提供了內置的視頻編解碼器,可支持高達32個編碼、解碼并發(fā)流,只要視頻總像素在60FPS下不超過3840 x 2160P。
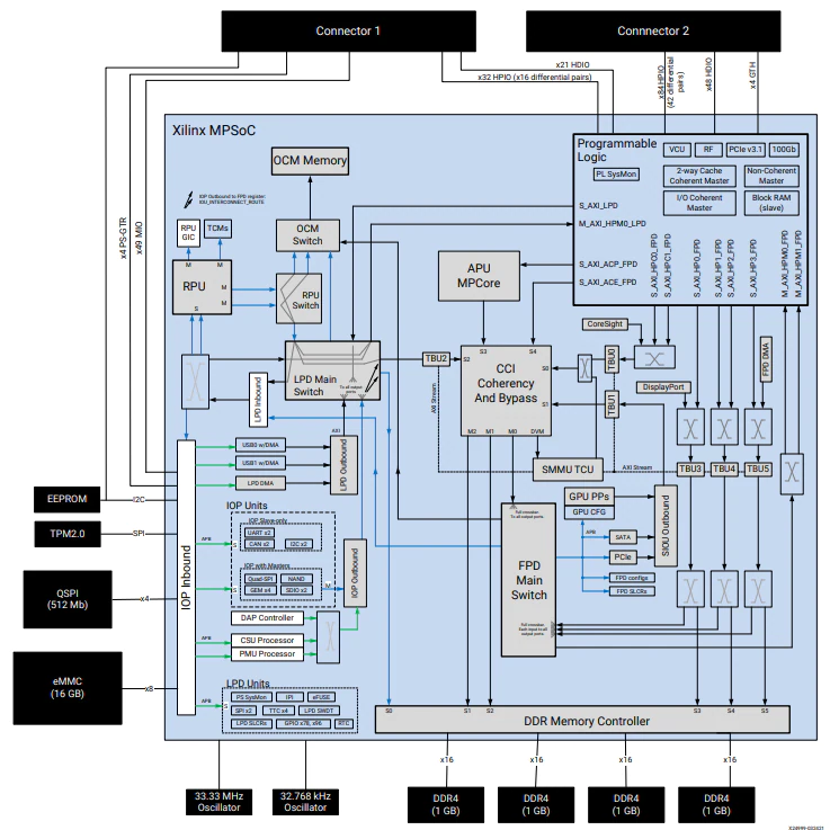
圖4:Kria K26 SOM框圖
(圖源:AMD)
在安全性方面,Kria K26 SOM采用Zynq UltraScale+架構內置的硬件可信根實現(xiàn)的固有的安全啟動功能,通過外部TPM2.0擴展用于測量啟動并遵循IEC 62443規(guī)范。
此外,出色的I/O靈活性也是Kria K26 SOM一大亮點——它擁有大量的1.8V、3.3V單端與差分I/O,四個6Gb/s收發(fā)器和四個12.5Gb/s收發(fā)器,便于SOM支持更多的圖像傳感器以及多種傳感器接口類型,其中包括通常ASSP和GPU不支持的MIPI、LVDS、SLVS 和SLVS-EC。
此外,用戶還能通過可編程邏輯實現(xiàn)DisplayPort、HDMI、PCIe、USB2.0/3.0等標準,以及其他用戶自定義的標準。
在外形上,Kria K26 SOM的尺寸為77mm x 60mm x 11mm,緊湊的外形非常便于集成到系統(tǒng)中,且根據(jù)規(guī)劃,未來AMD還將推出更小尺寸的SOM。目前Kria K26 SOM分為商用級和工業(yè)級兩個版本,用戶可以根據(jù)終端應用的需要進行選擇。
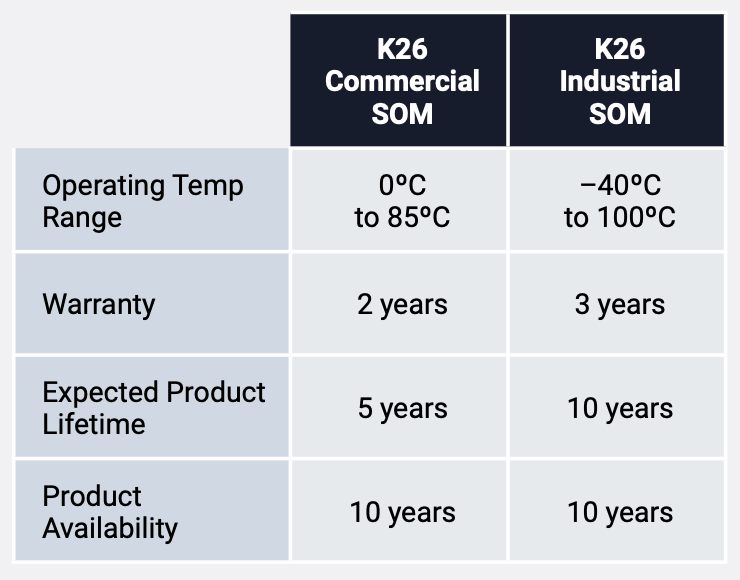
圖5:商用級和工業(yè)級K26 SOM特性比較
(圖源:AMD)
Kria K26 SOM帶來的價值
使用Kria K26 SOM會是一種什么樣的體驗?在設計實戰(zhàn)中,Kria K26 SOM的表現(xiàn)如何?想必這是大家都關心的問題。
首先,從簡化硬件設計流程來看,與傳統(tǒng)的基于器件的設計相比,基于SOM的設計省去了RTL/硬件設計、器件調試、電路板設計等環(huán)節(jié),直接從系統(tǒng)級設計開始,因此可以大大簡化開發(fā)流程——據(jù)AMD的分析,基于SOM的設計可以縮短新產品上市時間多達9個月!
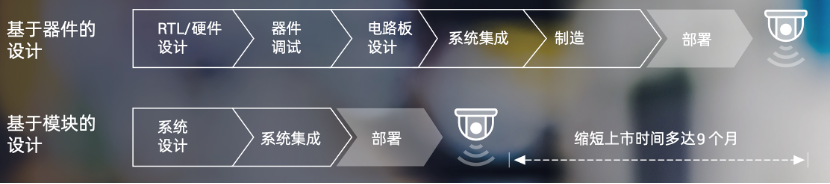
圖6:基于SOM的設計與基于芯片的設計過程相比,可以縮短新產品上市時間多達9個月(圖源:AMD)
在硬件性能方面,在AMD提供的一個汽車車牌識別(ANPR)應用案例中,基于Kria K26 SOM的解決方案出色地完成了包含視頻解碼、圖像預處理、機器學習(檢測)和OCR字符識別在內全流程的加速和優(yōu)化,與采用GPU架構的SOM方案相比,在計算性能、能效表現(xiàn)、以及每視頻流成本上都有明顯的優(yōu)勢(如圖7)。相信隨著K26 SOM應用的擴展,其在性能上的潛質也會被越來越多地挖掘出來。
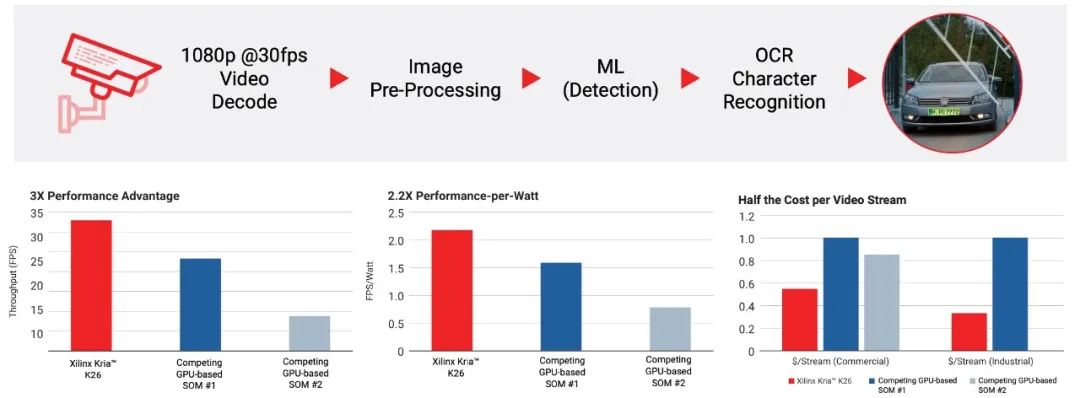
圖7:在ANPR案例中,K26 SOM表現(xiàn)出明顯性能優(yōu)勢(圖源:AMD)
特別值得一提的是,Kria K26 SOM除了可以為硬件開發(fā)者帶來諸多好處,對軟件開發(fā)者也是一個福音。隨著與Kria K26 SOM配套的邊緣AI軟件工具、庫和框架的發(fā)展,一些設計團隊可以在無需硬件工程師介入的情況下使用自適應計算。
對于軟件開發(fā)者而言,Kria K26 SOM和AMD提供的綜合軟件平臺,可以使其在熟悉的Python、C++、TensorFlow和PyTorch等環(huán)境下進行開發(fā),為其提供易于使用、開箱即用的體驗。再加上AMD生態(tài)系統(tǒng)中第三方軟件廠商資源的支持,更是可以讓邊緣AI開發(fā)的性能和靈活性提升到一個更高的水平。
快速體驗Kria K26 SOM
為了方便開發(fā)者快速體驗到Kria K26 SOM的強大能力,挖掘Kria K26 SOM的價值,AMD針對一些典型的邊緣AI應用,還提供了開箱即用的入門級開發(fā)套件。
Kria KV260是專為視覺應用而開發(fā)的視覺AI入門套件,它配有非生產版本的Kria K26 SOM,以及安裝有風扇散熱器的評估載板,可通過onsemi成像器訪問系統(tǒng)(IAS)和Raspberry Pi連接器提供多攝像頭支持。該開發(fā)套件還可由PMOD擴展支持豐富的傳感器模塊。
基于KV260視覺AI入門套件,軟硬件開發(fā)人員無需FPGA經驗,即可在1小時內啟動和運行應用程序,進而在Kria K26 SOM上快速實現(xiàn)視覺AI應用的批量部署。

圖8:Kria KV260視覺AI入門套件
(圖源:AMD)
Kria KR260機器人入門套件是AMD新推出的一款基于Kria K26 SOM的開發(fā)平臺,它具有高性能接口和原生ROS 2支持,旨在為機器人和嵌入式開發(fā)人員提供快速簡便的開發(fā)體驗。
該開發(fā)套件包括Kria K26 SOM、載板和散熱系統(tǒng),以及電源解決方案、多個以太網接口、SFP+連接、SLVS-EC傳感器接口和microSD卡,其目標應用包括工廠自動化、通信、控制和視覺,特別是機器人和機器視覺應用。

圖9:Kria KR260機器人入門套件
(圖源:AMD)
本文小結
云計算已經深刻改變了IT和IoT世界的格局,而邊緣計算的興起正在重塑新的游戲規(guī)則。在這一趨勢中,如何讓越來越多的邊緣AI應用快速落地,需要一種不同以往的計算平臺,以及與之相適應的開發(fā)方法。自適應SOM也就應運而生了。
AMD的Kria K26 SOM可以讓你的邊緣AI開發(fā)駛上快車道,并沿著這條高速公路,將邊緣AI應用范圍延伸至到更廣闊的領域。想要快速起步,即刻上路,就來貿澤電子網站中的Kria K26 SOM專題深入了解一下吧!
Kria K26模塊化系統(tǒng)(SOM)專題
>> 點擊了解詳情 <<
該發(fā)布文章為獨家原創(chuàng)文章,轉載請注明來源。對于未經許可的復制和不符合要求的轉載我們將保留依法追究法律責任的權利。
關于貿澤電子貿澤電子(Mouser Electronics)是一家全球知名的半導體和電子元器件授權代理商,分銷超過1200家品牌制造商的680多萬種產品,為客戶提供一站式采購平臺。我們專注于快速引入新產品和新技術,為設計工程師和采購人員提供潮流選擇。歡迎關注我們!
更多精彩

原文標題:邊緣AI開發(fā),如何駛上快車道?
文章出處:【微信公眾號:貿澤電子】歡迎添加關注!文章轉載請注明出處。
-
貿澤電子
+關注
關注
16文章
1168瀏覽量
97407
原文標題:邊緣AI開發(fā),如何駛上快車道?
文章出處:【微信號:貿澤電子,微信公眾號:貿澤電子】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
AI應用落地駛入快車道,產業(yè)應如何夯實算力根基?
Deepseek海思SD3403邊緣計算AI產品系統(tǒng)
DevEco Studio AI輔助開發(fā)工具兩大升級功能 鴻蒙應用開發(fā)效率再提升
充電樁建設駛上“快車道”,才茂智慧充電樁聯(lián)網方案守護民眾低碳出行

AI賦能邊緣網關:開啟智能時代的新藍海
芯動力神速適配DeepSeek-R1大模型,AI芯片設計邁入“快車道”!

2024年星閃進入規(guī)模商用快車道
研華科技邊緣AI平臺榮獲2024年IoT邊緣計算卓越獎
Arm推出GitHub平臺AI工具,簡化開發(fā)者AI應用開發(fā)部署流程
邊緣AI:實時智能的新前沿

創(chuàng)星未來訪談|時擎科技:端側智能芯片領域的新銳力量







 工商網監(jiān)
工商網監(jiān)
評論