") CVPR 2023論文總結(jié)!CV最熱領(lǐng)域頒給多模態(tài)、擴(kuò)散模型
CVPR 2023論文總結(jié)!CV最熱領(lǐng)域頒給多模態(tài)、擴(kuò)散模型
【導(dǎo)讀】CVPR 2023有哪些亮點(diǎn)?從錄用論文中我們又能看到CV領(lǐng)域有哪些趨勢?
一年一度的CVPR即將在6月18-22日加拿大溫哥華正式開幕。
每年,來自世界各地的成千上萬的CV研究人員和工程師聚集在一起參加頂會(huì)。這個(gè)久負(fù)盛名的會(huì)議可以追溯到1983年,它代表了計(jì)算機(jī)視覺發(fā)展的巔峰。
目前,CVPR的h5指數(shù)所有會(huì)議或出版物中位列第四,僅次于《自然》、《科學(xué)》和《新英格蘭醫(yī)學(xué)雜志》。

前段時(shí)間,CVPR公布了論文接收結(jié)果。根據(jù)官網(wǎng)上統(tǒng)計(jì)數(shù)據(jù),一共接受論文9155篇,錄用2359篇,接受率為25.8%。
此外,還公布了12篇獲獎(jiǎng)候選論文。
那么,今年的CVPR有哪些亮點(diǎn)?從錄用論文中我們又能看到CV領(lǐng)域有哪些趨勢?
接下來一并揭曉。
CVPR一覽
初創(chuàng)公司Voxel51就所有被接收論文列表中進(jìn)行了分析。
先來整體看一張論文標(biāo)題的匯總圖,每個(gè)字的大小與數(shù)據(jù)集中出現(xiàn)的頻率成正比。
簡要說明
- 2359篇論文被接收(9155份論文提交)
- 1724篇Arxiv論文
- 68份文件提交到其他地址
每篇論文的作者
- CVPR論文的平均作者約為5.4人
- 論文當(dāng)中作者最多的是: 「Why is the winner the best?」有125位作者
- 有13篇論文只有一個(gè)作者。
主要Arxiv分類
在1724篇Arxiv論文中,有1545篇,或者說接近90%的論文將cs.CV列為主要類別。
cs.LG位列第二,有101篇。eess.IV (26)和 cs.RO (16)也分得一杯羹。
CVPR 論文的其他類別包括: cs.HC,cs.CV,cs.AR,cs.DC,cs.NE,cs.SD,cs.CL,cs.IT,cs.CR,cs.AI,cs.MM,cs.GR,eess.SP,eess.AS,math.OC,math.NT,physics.data-an和stat.ML。
「Meta」數(shù)據(jù)
- 「數(shù)據(jù)集」和「模型」這2個(gè)詞共同出現(xiàn)在567篇摘要中。「數(shù)據(jù)集」在265篇論文摘要中單獨(dú)出現(xiàn),而「模型」則單獨(dú)出現(xiàn)了613次。只有16.2%的 CVPR接收論文沒有包含這兩個(gè)詞。
- 根據(jù)CVPR論文摘要,今年最受歡迎的數(shù)據(jù)集是ImageNet(105),COCO(94),KITTI(55)和CIFAR(36)。
- 28篇論文提出了一個(gè)新的「基準(zhǔn)」。
縮寫詞比比皆是
似乎沒有首字母縮略詞就沒有機(jī)器學(xué)習(xí)項(xiàng)目。2359篇論文中,1487篇的標(biāo)題有多個(gè)大寫字母的縮略詞或復(fù)合詞,占比63%。
這些首字母縮略詞中有一些很容易記住,甚至可以脫口而出:
- CLAMP: Prompt-based Contrastive Learning for Connecting Language and Animal PoseCLAMP
- PATS: Patch Area Transportation with Subdivision for Local Feature Matching
- CIRCLE: Capture In Rich Contextual Environments
有些則要復(fù)雜得多:
- SIEDOB: Semantic Image Editing by Disentangling Object and Background
- FJMP: Factorized Joint Multi-Agent Motion Prediction over Learned Directed Acyclic Interaction GraphsFJMP
他們中的一些人似乎在首字母縮略詞構(gòu)建上借鑒了別人的創(chuàng)意:
- SCOTCH and SODA: A Transformer Video Shadow Detection Framework(荷蘭流行潮牌Scotch & Soda)
- EXCALIBUR: Encouraging and Evaluating Embodied Exploration(Ex咖喱棒,笑)
什么最熱?
除了2023年的論文標(biāo)題,我們抓取了2022年所有接受的論文標(biāo)題。從這兩個(gè)列表中,我們計(jì)算了各種關(guān)鍵詞的相對頻率,從讓大家對什么是上升趨勢、什么是下降趨勢有更深入的了解。
模型
2023年,擴(kuò)散模型(Diffusion models)占據(jù)了主導(dǎo)地位。

擴(kuò)散模型
隨著Stable Diffusion和Midjourney等圖像生成模型的走紅,擴(kuò)散模型發(fā)展的火熱趨勢也就不足為奇了。
擴(kuò)散模型在去噪、圖像編輯和風(fēng)格轉(zhuǎn)換方面也有應(yīng)用。把所有這些加起來,到目前為止,它是所有類別中最大的贏家,比去年同期增長了573% 。
輻射場
神經(jīng)輻射場(NERF)也越來越受歡迎,論文中使用單詞「radiance」增加了80% ,「NERF」增加了39% 。NeRF已經(jīng)從概念驗(yàn)證轉(zhuǎn)向編輯、應(yīng)用和訓(xùn)練過程優(yōu)化。
Transformers
「Transformer」和「ViT」的使用率下降并不意味著Transformer模型過時(shí),而是反映了這些模型在2022年的主導(dǎo)地位。2021年,「Transformer」這個(gè)詞只出現(xiàn)在37篇論文中。2022年,這個(gè)數(shù)字飆升至201。Transformer不會(huì)很快消失。
CNN
CNN曾經(jīng)是計(jì)算機(jī)視覺的寵兒,到了2023年,似乎失去了它們的優(yōu)勢,使用率下降了68%。許多提到 CNN 的標(biāo)題也提到了其他模型。例如,這些論文提到了CNN和Transformer:
- Lite-Mono: A Lightweight CNN and Transformer Architecture for Self-Supervised Monocular Depth EstimationLite-Mono
- Learned Image Compression with Mixed Transformer-CNN Architectures
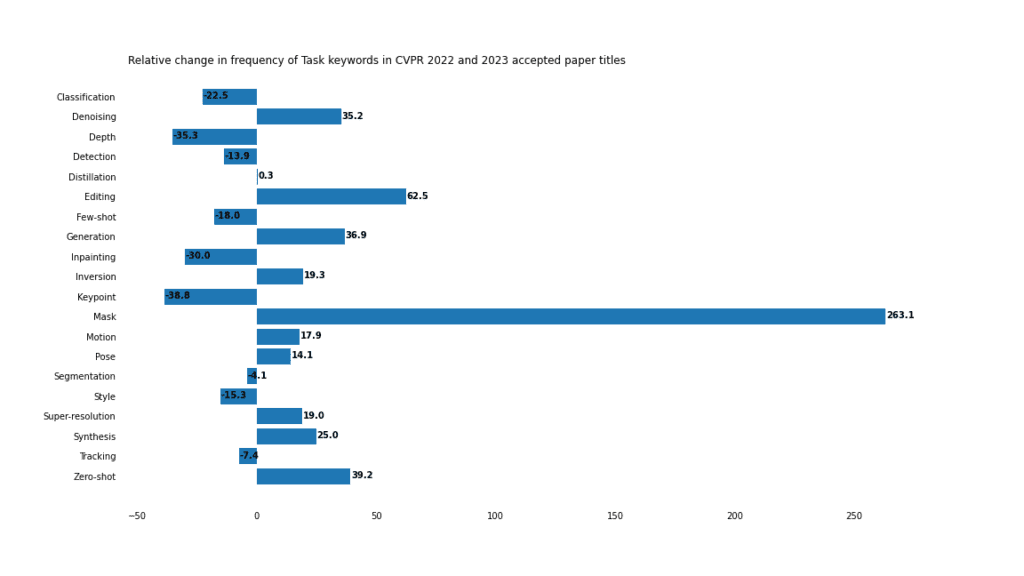
任務(wù)
掩碼任務(wù)和掩碼圖像建模相結(jié)合,在CVPR中占據(jù)了主導(dǎo)地位。
生成
傳統(tǒng)的判別任務(wù),如檢測、分類和分割并沒有失寵,但是由于生成應(yīng)用的一系列進(jìn)步,它們在CV的份額正在縮小,包括「編輯」、「合成」以及「生成」的上升就證明這點(diǎn)。
掩碼
關(guān)鍵字「mask」比去年同期增長了263% ,在2023年被接收的論文中出現(xiàn)了92次,有時(shí)在一個(gè)標(biāo)題中出現(xiàn)了2次。
- SIM: Semantic-aware Instance Mask Generation for Box-Supervised Instance SegmentationSIM
- DynaMask: Dynamic Mask Selection for Instance SegmentationDynaMask
但大多數(shù)(64%)實(shí)際上指的是「掩碼」任務(wù),包括8個(gè)「掩碼圖像建模」和15個(gè)「掩碼自動(dòng)編碼器」任務(wù)。此外,還有8篇出現(xiàn)「掩碼」。
同樣值得注意的是,3篇帶有單詞「mask」的論文標(biāo)題實(shí)際上指的是「無掩碼」任務(wù)。
零樣本vs小樣本
隨著遷移學(xué)習(xí)、生成方法、提示和通用模型的興起,「零樣本」學(xué)習(xí)正在獲得關(guān)注。與此同時(shí),「小樣本」學(xué)習(xí)比去年有所下降。然而,就原始數(shù)字而言,至少目前而言,「小樣本」(45)比「零樣本」(35)略有優(yōu)勢。
模態(tài)
2023年,多模態(tài)和跨模態(tài)應(yīng)用加速發(fā)展。
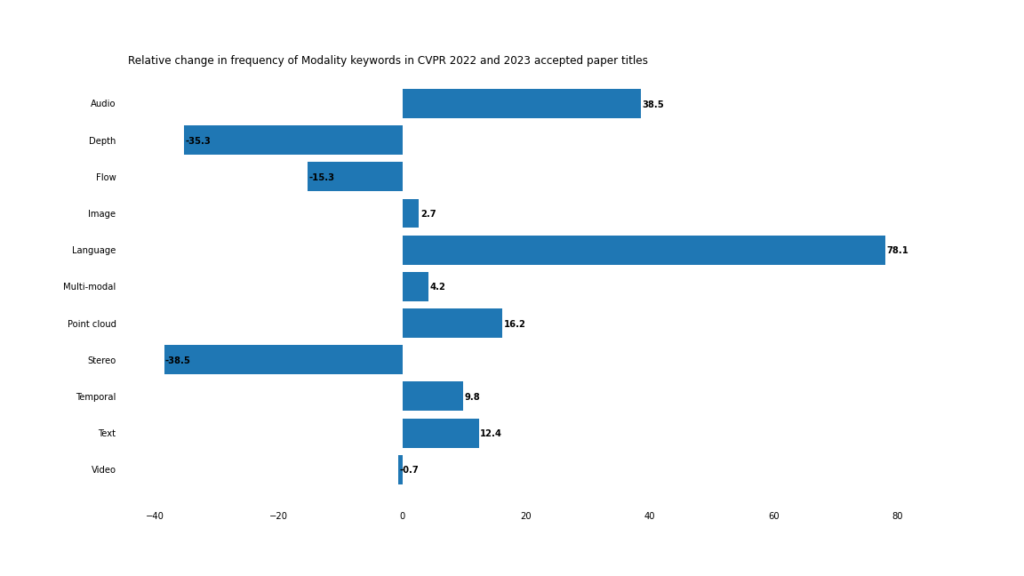
邊界模糊
雖然傳統(tǒng)計(jì)算機(jī)視覺關(guān)鍵詞如「圖像」和「視頻」的頻率相對保持不變,但「文本」/「語言」和「音頻」出現(xiàn)的頻率更高。
即使「多模態(tài)」這個(gè)詞本身沒有在論文標(biāo)題中出現(xiàn),也很難否認(rèn)計(jì)算機(jī)視覺正在走向多模態(tài)的未來。
這在視覺-語言任務(wù)中尤其明顯,正如「開放」、「提示」和「詞匯」的急劇上升所表明的那樣。
這種情況最極端的例子是「開放詞匯」這個(gè)復(fù)合詞,它在2022年只出現(xiàn)了3次,但在2023年出現(xiàn)了18次。
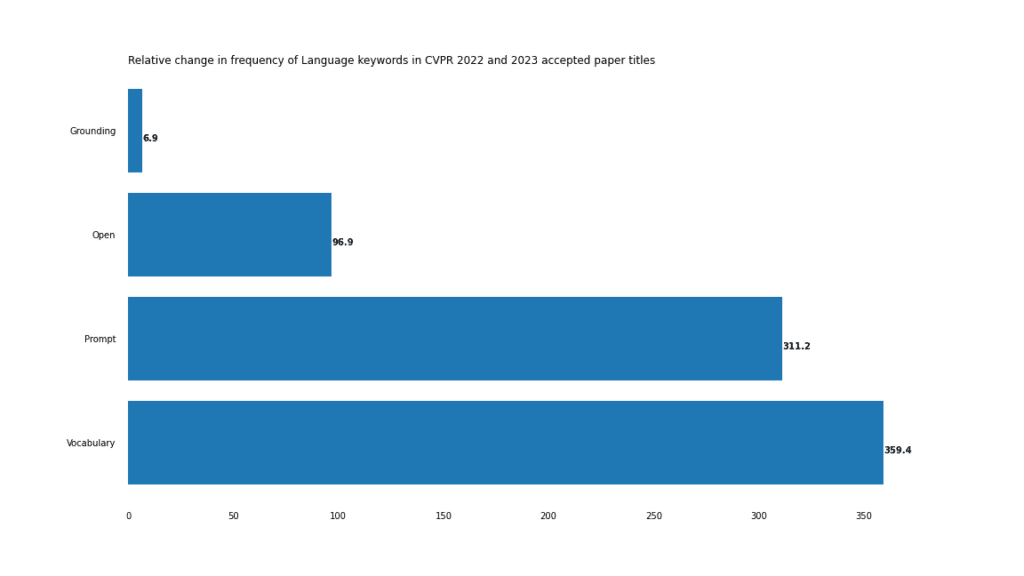
深入挖掘CVPR 2023論文標(biāo)題中的關(guān)鍵詞
點(diǎn)云9
三維計(jì)算機(jī)視覺應(yīng)用正在從以二維圖像推斷3D信息(「深度」和「立體」)轉(zhuǎn)向直接在3D點(diǎn)云數(shù)據(jù)上進(jìn)行工作的計(jì)算機(jī)視覺系統(tǒng)。
CV標(biāo)題的創(chuàng)造力
如果不將ChatGPT納入其中,2023年任何與機(jī)器學(xué)習(xí)相關(guān)的全面報(bào)道都是不完整的。我們決定讓事情變得有趣,并使用ChatGPT來尋找CVPR 2023中最有創(chuàng)意的標(biāo)題。
對于每一篇上傳到Arxiv的論文,我們抓取了摘要,并要求 ChatGPT (GPT-3.5 API)為相應(yīng)的CVPR論文生成一個(gè)標(biāo)題。
然后,我們將這些由ChatGPT生成的標(biāo)題和實(shí)際的論文標(biāo)題,使用OpenAI的text-embedding-ada-002模型生成嵌入向量,并計(jì)算ChatGPT生成的標(biāo)題和作者生成的標(biāo)題之間的余弦相似度。
這可以告訴我們什么?ChatGPT越接近實(shí)際的論文標(biāo)題,這個(gè)標(biāo)題就越可預(yù)測。換句話說,ChatGPT的預(yù)測越「偏」,作者給論文命名的「創(chuàng)造性」就越強(qiáng)。
嵌入和余弦相似度為我們提供了一個(gè)有趣的,盡管遠(yuǎn)非完美的,量化方法。
我們按照這個(gè)指標(biāo)對論文進(jìn)行了排序。話不多說,下面是最具創(chuàng)造性的標(biāo)題:
實(shí)際的標(biāo)題:Tracking Every Thing in the Wild
預(yù)測的標(biāo)題:Disentangling Classification from Tracking: Introducing TETA for Comprehensive Benchmarking of Multi-Category Multiple Object Tracking
實(shí)際的標(biāo)題:Learning to Bootstrap for Combating Label Noise
預(yù)測的標(biāo)題:Learnable Loss Objective for Joint Instance and Label Reweighting in Deep Neural Networks
實(shí)際的標(biāo)題:Seeing a Rose in Five Thousand Ways
預(yù)測的標(biāo)題:Learning Object Intrinsics from Single Internet Images for Superior Visual Rendering and Synthesis
實(shí)際的標(biāo)題:Why is the winner the best?
預(yù)測的標(biāo)題:Analyzing Winning Strategies in International Benchmarking Competitions for Image Analysis: Insights from a Multi-Center Study of IEEE ISBI and MICCAI 2021
審核編輯 :李倩
-
模型
+關(guān)注
關(guān)注
1文章
3483瀏覽量
49955 -
計(jì)算機(jī)視覺
+關(guān)注
關(guān)注
9文章
1706瀏覽量
46556 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1222瀏覽量
25268
原文標(biāo)題:CVPR 2023論文總結(jié)!CV最熱領(lǐng)域頒給多模態(tài)、擴(kuò)散模型
文章出處:【微信號:CVSCHOOL,微信公眾號:OpenCV學(xué)堂】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
愛芯通元NPU適配Qwen2.5-VL-3B視覺多模態(tài)大模型

海康威視發(fā)布多模態(tài)大模型AI融合巡檢超腦
階躍星辰開源多模態(tài)模型,天數(shù)智芯迅速適配
海康威視發(fā)布多模態(tài)大模型文搜存儲(chǔ)系列產(chǎn)品

【「具身智能機(jī)器人系統(tǒng)」閱讀體驗(yàn)】2.具身智能機(jī)器人大模型
商湯日日新多模態(tài)大模型權(quán)威評測第一
一文理解多模態(tài)大語言模型——下

一文理解多模態(tài)大語言模型——上

擴(kuò)散模型的理論基礎(chǔ)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論