") 聚類(lèi)分析中的機(jī)器學(xué)習(xí)與統(tǒng)計(jì)方法綜述(二)
聚類(lèi)分析中的機(jī)器學(xué)習(xí)與統(tǒng)計(jì)方法綜述(二)
在本節(jié)中,我們將闡述八種應(yīng)用在單細(xì)胞轉(zhuǎn)錄組數(shù)據(jù)的聚類(lèi)方法,并總結(jié)了這些方法的優(yōu)點(diǎn)、局限性和時(shí)間復(fù)雜度等。一部分單細(xì)胞聚類(lèi)的工具會(huì)使用多種聚類(lèi)算法,因此會(huì)在多個(gè)類(lèi)別中列出。
01
基于劃分的聚類(lèi)
基于劃分的聚類(lèi)方法主要是確定最佳的K個(gè)中心,將數(shù)據(jù)點(diǎn)劃分為K個(gè)簇,其中心要么是質(zhì)心(均值),稱(chēng)為k-means,要么是中心點(diǎn),稱(chēng)為k-medoids。 k-means方法的思想是找到質(zhì)心,以最小化每個(gè)數(shù)據(jù)點(diǎn)與其最近質(zhì)心之間的歐氏距離的平方和。它具有時(shí)間復(fù)雜度低的優(yōu)點(diǎn)。但是,它對(duì)異常值很敏感,并且用戶必須預(yù)先指定聚類(lèi)的數(shù)量K。對(duì)于將N個(gè)D維數(shù)據(jù)點(diǎn)聚為K個(gè)類(lèi),使用Lloyd 's算法的k-means每次迭代的時(shí)間復(fù)雜度為O(KND)。 以下是一些使用k-means聚類(lèi)的單細(xì)胞轉(zhuǎn)錄組數(shù)據(jù)分析工具。SAIC在迭代聚類(lèi)過(guò)程中使用k-means并結(jié)合ANOVA識(shí)別特征基因;SCUBA使用k-means將每個(gè)時(shí)間點(diǎn)的細(xì)胞分為兩組,并使用間隔統(tǒng)計(jì)量來(lái)識(shí)別分叉事件;SC3的步驟之一是在細(xì)胞距離矩陣上使用k-means聚類(lèi)(圖3)。k-medoids方法是將原始N個(gè)數(shù)據(jù)點(diǎn)中的K個(gè)數(shù)據(jù)點(diǎn)識(shí)別為中心點(diǎn),以最小化數(shù)據(jù)點(diǎn)到中心點(diǎn)的距離之和。它非常適用于以有意義的中心點(diǎn)作為聚類(lèi)中心的離散數(shù)據(jù)。然而,與k-means類(lèi)似,它對(duì)異常值很敏感,用戶必須預(yù)先指定聚類(lèi)的數(shù)量K。對(duì)于從N個(gè)數(shù)據(jù)點(diǎn)中選擇最優(yōu)K個(gè)點(diǎn)的組合問(wèn)題,采用圍繞中心點(diǎn)劃分算法的k-medoids的時(shí)間復(fù)雜度為O(K(N?K)2)。
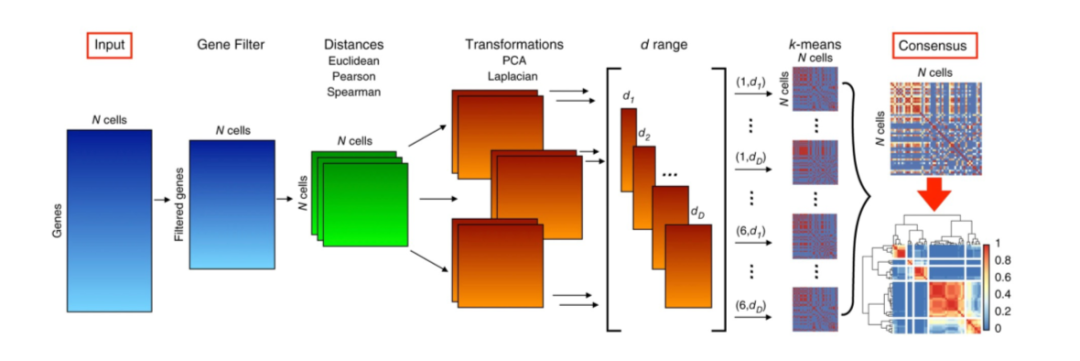
Figure 3. SC3聚類(lèi)流程圖
RaceID2用于利用單細(xì)胞轉(zhuǎn)錄組數(shù)據(jù)識(shí)別罕見(jiàn)細(xì)胞類(lèi)型,結(jié)果表明用k-medoids取代k-means方法進(jìn)行聚類(lèi)可以明顯改善聚類(lèi)的結(jié)果。
02
層次聚類(lèi)
次聚類(lèi)是基因表達(dá)數(shù)據(jù)分析中應(yīng)用最廣泛的聚類(lèi)方法。層次聚類(lèi)在數(shù)據(jù)點(diǎn)之間構(gòu)建層次結(jié)構(gòu),它根據(jù)層次樹(shù)中的分支定義不同的類(lèi)群。許多單細(xì)胞轉(zhuǎn)錄組數(shù)據(jù)的聚類(lèi)算法都是基于層次聚類(lèi)或?qū)哟尉垲?lèi)作為分析的步驟之一。
層次聚類(lèi)對(duì)數(shù)據(jù)本身的分布并沒(méi)有過(guò)多要求,因此,它適用于許多不同形狀的數(shù)據(jù)集;層次聚類(lèi)的另一個(gè)優(yōu)點(diǎn)是通過(guò)數(shù)據(jù)點(diǎn)之間的層次關(guān)系,可以用于發(fā)現(xiàn)其內(nèi)在的關(guān)聯(lián),有助于對(duì)結(jié)果的解釋。層次聚類(lèi)主要有兩種實(shí)現(xiàn)方法:聚合式(agglomerative)和分裂式(divisive)。 聚合式又叫“自下而上式(bottom-up)”的聚類(lèi),它從N個(gè)數(shù)據(jù)點(diǎn)開(kāi)始,每一個(gè)數(shù)據(jù)點(diǎn)作為一個(gè)單獨(dú)的類(lèi),在每一步中,類(lèi)群依據(jù)它們之間的距離進(jìn)行合并,直到所有類(lèi)群在層次結(jié)構(gòu)的根處合并在一起。分裂式又叫“自上而下式(top-down)”聚類(lèi),相比之下,該方法首先將所有數(shù)據(jù)點(diǎn)當(dāng)成一個(gè)類(lèi)群,然后每一步遞歸劃分更小的類(lèi)群,直到分成N個(gè)類(lèi)群為止。無(wú)論是哪一種,層次聚類(lèi)的一個(gè)顯著缺點(diǎn)是時(shí)間復(fù)雜度高,運(yùn)行時(shí)間非常久。此外,層次關(guān)系并不能提供數(shù)據(jù)點(diǎn)的最佳聚類(lèi)劃分,還需要一個(gè)額外的步驟來(lái)從層次樹(shù)中決定最終劃分的類(lèi)群數(shù)量。 BackSPIN是一種雙聚類(lèi)算法,分別在細(xì)胞和基因的維度上應(yīng)用層次聚類(lèi)。BackSPIN使用SPIN迭代地拆分基因表達(dá)矩陣,直到在分支處不再滿足拆分標(biāo)準(zhǔn);cellTree通過(guò)在話題分布上構(gòu)造最小生成樹(shù),從而在單個(gè)細(xì)胞之間構(gòu)建層次結(jié)構(gòu);CIDR對(duì)PCoA獲得的低維嵌入使用了層次聚類(lèi);ICGS采用層次聚類(lèi),將篩選后得到的一組基因的表達(dá)數(shù)據(jù)按表達(dá)水平和動(dòng)態(tài)范圍進(jìn)行聚類(lèi),并進(jìn)行配對(duì)相關(guān)分析;SC3對(duì)多個(gè)k-means聚類(lèi)結(jié)果合并得到的一致性矩陣進(jìn)行層次聚類(lèi);為了獲得層次結(jié)構(gòu)中的實(shí)際類(lèi)群,DendroSplit通過(guò)衡量與原始表達(dá)數(shù)據(jù)的分離分?jǐn)?shù),使用動(dòng)態(tài)拆分和合并分支來(lái)檢測(cè)層次樹(shù)中的類(lèi)群。
03
混合模型
混合模型聚類(lèi)基于的假設(shè)思想是,數(shù)據(jù)點(diǎn)是從幾個(gè)混合的概率分布中采樣,每個(gè)概率分布代表一個(gè)聚類(lèi)。樣本的聚類(lèi)是通過(guò)從每個(gè)分布中學(xué)習(xí)其生成的概率來(lái)推斷的。用于聚類(lèi)的常見(jiàn)混合模型主要包括應(yīng)用于連續(xù)型數(shù)據(jù)的高斯混合模型(GMM)和計(jì)數(shù)型數(shù)據(jù)的分類(lèi)混合模型。
混合模型的優(yōu)點(diǎn)包括嚴(yán)格的概率建模和在模型中引入先驗(yàn)知識(shí)的靈活性。然而,解決混合模型需要先進(jìn)的優(yōu)化或采樣技術(shù),具有較高的計(jì)算復(fù)雜度,并依賴于關(guān)于數(shù)據(jù)分布的假設(shè)的準(zhǔn)確性。混合模型通常是用期望最大算法學(xué)習(xí)的,它可以推斷混合參數(shù)和類(lèi)分配似然性,也可以用抽樣和變分方法學(xué)習(xí)圖概率模型。此外,混合模型的時(shí)間復(fù)雜度取決于混合的分布,比如在GMM中,時(shí)間復(fù)雜度為O(N2K)。 BISCUIT基于層次狄利克雷過(guò)程混合模型(HDMM),并附加細(xì)胞特定的標(biāo)準(zhǔn)化和dropouts矯正。它的過(guò)程首先是應(yīng)用HDMM對(duì)細(xì)胞建模,形成包含Dirichlet先驗(yàn)的混合系數(shù)、均值、Wishart先驗(yàn)的協(xié)方差矩陣的高斯混合模型,而細(xì)胞特定的縮放因子代表了技術(shù)變異。早先版本的Seurat能夠?qū)渭?xì)胞轉(zhuǎn)錄組數(shù)據(jù)與原位RNA測(cè)序相結(jié)合,用于單細(xì)胞的空間聚類(lèi)。在雙峰混合模型中,針對(duì)一組選定的標(biāo)志基因,將單細(xì)胞轉(zhuǎn)錄組數(shù)據(jù)與二值化的原位RNA數(shù)據(jù)整合,然后通過(guò)雙峰混合模型中單細(xì)胞轉(zhuǎn)錄組表達(dá)譜的后驗(yàn)概率將每個(gè)單細(xì)胞分配到不同的空間類(lèi)群區(qū)域。
04
基于圖的聚類(lèi)
在基于圖的聚類(lèi)中,數(shù)據(jù)點(diǎn)被表示為圖(Graph)中的節(jié)點(diǎn),而節(jié)點(diǎn)間的邊(Edge)由數(shù)據(jù)點(diǎn)之間的相似性表示。基于圖的聚類(lèi)基于一個(gè)簡(jiǎn)單的假設(shè),即圖中的密集社區(qū)(community)表示為密集的子圖或譜成分,因此對(duì)于數(shù)據(jù)的分布并沒(méi)有過(guò)于依賴。兩種最常用的圖聚類(lèi)算法是譜聚類(lèi)和團(tuán)(clique)發(fā)現(xiàn)。
在譜聚類(lèi)中,通過(guò)相似函數(shù)(如RBF核函數(shù))建立相似性矩陣及其拉普拉斯圖。通過(guò)計(jì)算拉普拉斯圖的頂部特征向量,以便后續(xù)的k-means聚類(lèi)。雖然可以使用更有效的方法來(lái)尋找固定數(shù)量的頂部特征向量,但尋找所有特征向量的時(shí)間復(fù)雜度為O(N3),因此,譜聚類(lèi)并不適用于大數(shù)據(jù)集。當(dāng)細(xì)胞類(lèi)型作為先驗(yàn)已知時(shí),基于TCC的聚類(lèi)利用細(xì)胞間的Jensen-Shannon距離構(gòu)建相似性矩陣進(jìn)行譜聚類(lèi);未知時(shí)則應(yīng)用近鄰傳播聚類(lèi)。 在圖論中,團(tuán)被定義為每對(duì)節(jié)點(diǎn)都相鄰的子圖,因此,團(tuán)代表了圖中數(shù)據(jù)點(diǎn)的類(lèi)群。由于在圖中找到團(tuán)是一個(gè)NP-hard問(wèn)題,通常會(huì)使用啟發(fā)式方法。SNN-Cliq利用單細(xì)胞轉(zhuǎn)錄組數(shù)據(jù)對(duì)細(xì)胞進(jìn)行團(tuán)簇檢測(cè)。在稀疏圖中團(tuán)通常很少見(jiàn),因此,SNN-cliq在SNN圖中檢測(cè)到的團(tuán)一般是密集但是不完全連通的。
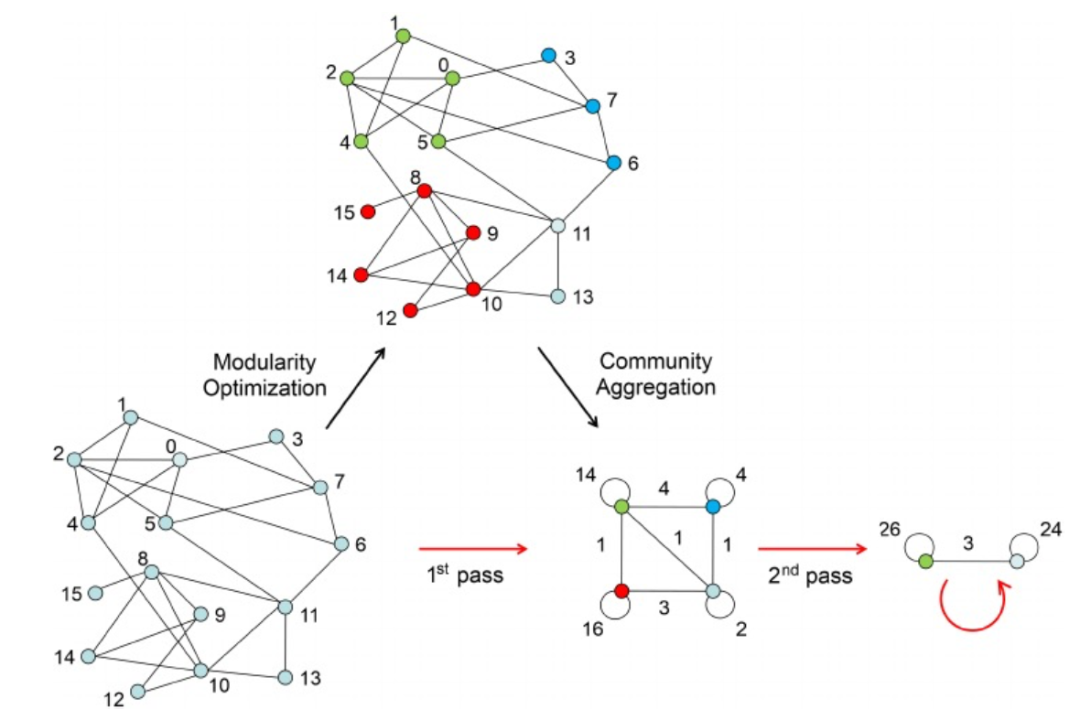
Figure 4. Louvain算法示意圖
另一種常用于單細(xì)胞分析的基于圖聚類(lèi)的算法是Louvain算法(圖4)。Louvain是一種社區(qū)檢測(cè)算法,它比其他基于圖的算法更具可擴(kuò)展性,通過(guò)貪婪方式將節(jié)點(diǎn)分配給社區(qū),并更新網(wǎng)絡(luò)以獲得低分辨率的聚類(lèi)。Louvain的時(shí)間復(fù)雜度為O(NlogN)。Scanpy是一個(gè)集成了Louvain算法、提供了一個(gè)能夠分析大規(guī)模單細(xì)胞轉(zhuǎn)錄組數(shù)據(jù)集的工具。Seurat在默認(rèn)情況下也是利用Louvain算法在細(xì)胞SNN圖上來(lái)發(fā)現(xiàn)細(xì)胞類(lèi)型。
05
基于密度的聚類(lèi)
基于密度的聚類(lèi)將類(lèi)群定義為一個(gè)空間中具有高密度數(shù)據(jù)點(diǎn)的區(qū)域。DBSCAN和密度峰值聚類(lèi)是基于密度的聚類(lèi)的兩個(gè)例子。
給定一個(gè)數(shù)據(jù)點(diǎn),將其作為中心以ε為半徑劃分出一個(gè)球形,球形內(nèi)的數(shù)據(jù)點(diǎn)數(shù)量如果超過(guò)指定的閾值,那么這些數(shù)據(jù)點(diǎn)就被DBSCAN認(rèn)為是一個(gè)類(lèi)群。對(duì)每個(gè)數(shù)據(jù)點(diǎn)重復(fù)該過(guò)程,不斷擴(kuò)展,最終完成聚類(lèi)。該方法具有效率高、適用于任何形狀的數(shù)據(jù)的優(yōu)點(diǎn)。然而,密度聚類(lèi)對(duì)參數(shù)非常敏感,如果類(lèi)群密度不平衡,結(jié)果會(huì)非常差。DBSCAN聚類(lèi)的時(shí)間復(fù)雜度為O(NlogN)。基于密度的聚類(lèi)通常用于單細(xì)胞轉(zhuǎn)錄組數(shù)據(jù)分析中的異常細(xì)胞識(shí)別,如GiniClust和Monocle2。 GiniClust是基于DBSCAN來(lái)發(fā)現(xiàn)罕見(jiàn)的細(xì)胞亞群,它使用基尼指數(shù)作為基因表達(dá)值變異性的衡量標(biāo)準(zhǔn),以篩選高變基因,然后由DBSCAN對(duì)細(xì)胞聚類(lèi)。密度峰值聚類(lèi)考慮數(shù)據(jù)點(diǎn)之間的距離,而不是像DBSCAN那樣考慮密度閾值,同時(shí)假設(shè)聚類(lèi)的中心是聚類(lèi)中數(shù)據(jù)點(diǎn)密度的局部最大值。密度峰值聚類(lèi)的時(shí)間復(fù)雜度為O(N2)。在Monocle2中,就是對(duì)t-SNE空間內(nèi)的細(xì)胞進(jìn)行密度峰值聚類(lèi)。
06
Kohonen神經(jīng)網(wǎng)絡(luò),也稱(chēng)為自組織特征映射神經(jīng)網(wǎng)絡(luò)(SOMs),運(yùn)用競(jìng)爭(zhēng)學(xué)習(xí)策略逐步優(yōu)化網(wǎng)絡(luò)進(jìn)行聚類(lèi),使用隨機(jī)梯度下降通過(guò)不斷迭代訓(xùn)練數(shù)據(jù)點(diǎn)和每個(gè)中心的相似度來(lái)更新聚類(lèi)中心。類(lèi)群中心使用預(yù)定義的結(jié)構(gòu)(如網(wǎng)格)進(jìn)行初始化。SOM具有相當(dāng)強(qiáng)的可擴(kuò)展性,因?yàn)殡S機(jī)梯度下降不需要把所有的數(shù)據(jù)點(diǎn)保存在計(jì)算機(jī)內(nèi)存中。此外,中心之間的預(yù)定義結(jié)構(gòu)可以引入先驗(yàn)知識(shí),并在類(lèi)群之間提供可解釋的關(guān)系。然而,SOM對(duì)參數(shù)異常敏感,比如用于更新權(quán)重的學(xué)習(xí)率。
SOM也已用于單細(xì)胞轉(zhuǎn)錄組數(shù)據(jù)的可視化和聚類(lèi)。在一些研究中應(yīng)用SOM在二維熱圖中直觀的可視化相似關(guān)系。SCRAT為用戶提供了可視化二維熱圖的選項(xiàng),該熱圖反映了跨細(xì)胞群的基因之間的相關(guān)性。SOMSC利用SOM將高維基因表達(dá)數(shù)據(jù)折疊成二維,用于識(shí)別處于中間過(guò)渡狀態(tài)的細(xì)胞以及擬時(shí)間排序。
07
集成聚類(lèi)
集成聚類(lèi),也稱(chēng)為共識(shí)聚類(lèi),是一種廣泛使用的策略。在該策略中,通過(guò)不同的應(yīng)用場(chǎng)景(例如不同的聚類(lèi)算法,相似的度量和特征選擇/映射等)對(duì)同一數(shù)據(jù)集進(jìn)行聚類(lèi),然后基于單個(gè)聚類(lèi)結(jié)果之間的一致性,通過(guò)共識(shí)函數(shù)對(duì)它們進(jìn)行合并。集成學(xué)習(xí)可以捕獲不同數(shù)據(jù)或聚類(lèi)模型中的多樣性,并且已被證明比單一模型更健壯,并產(chǎn)生更好的結(jié)果。集成聚類(lèi)的局限性是依賴于其他的數(shù)據(jù)轉(zhuǎn)換和基本聚類(lèi)方法。
SC3是一種用于單細(xì)胞轉(zhuǎn)錄組數(shù)據(jù)聚類(lèi)的共識(shí)聚類(lèi)方法。SC3首先通過(guò)三種不同的度量(斯皮爾曼、皮爾森和歐氏距離)來(lái)計(jì)算細(xì)胞間相似性,然后使用PCA和拉普拉斯轉(zhuǎn)換進(jìn)行分解,通過(guò)k-means對(duì)不同類(lèi)型的低維嵌入進(jìn)行聚類(lèi),接著用CSPA共識(shí)函數(shù)構(gòu)建一致性矩陣,最后,利用該矩陣進(jìn)行層次聚類(lèi)。conCluster是另一種共識(shí)聚類(lèi)方法,它使用多個(gè)不同的參數(shù)通過(guò)t-SNE和k-means進(jìn)行了組合,然后將這些不同的組合連接起來(lái),用于最后的k-means聚類(lèi)。
08
近鄰傳播聚類(lèi)
該聚類(lèi)方法的主要思想是通過(guò)不同點(diǎn)之間的信息傳遞來(lái)選擇聚類(lèi)中心:吸引度(responsibility)用于描述一個(gè)數(shù)據(jù)點(diǎn)k作為數(shù)據(jù)點(diǎn)i的聚類(lèi)中心的適合程度;歸屬度(availability)則描述了數(shù)據(jù)點(diǎn)i選擇數(shù)據(jù)點(diǎn)k作為聚類(lèi)中心的適合程度。近鄰傳播聚類(lèi)的主要優(yōu)點(diǎn)是不需要知道類(lèi)群的數(shù)量。缺點(diǎn)是時(shí)間復(fù)雜度較高,對(duì)異常值敏感。當(dāng)細(xì)胞類(lèi)型數(shù)量未知時(shí),基于TCC的聚類(lèi)以該方式進(jìn)行細(xì)胞的聚類(lèi)。在SIMLR中也選項(xiàng)可以選擇對(duì)數(shù)據(jù)進(jìn)行該方法的聚類(lèi)。
Table 1聚類(lèi)方法的分類(lèi)及優(yōu)缺點(diǎn)
審核編輯 :李倩
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4807瀏覽量
102783 -
算法
+關(guān)注
關(guān)注
23文章
4698瀏覽量
94740 -
聚類(lèi)
+關(guān)注
關(guān)注
0文章
146瀏覽量
14360 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8492瀏覽量
134088
原文標(biāo)題:?jiǎn)渭?xì)胞轉(zhuǎn)錄組 | 聚類(lèi)分析中的機(jī)器學(xué)習(xí)與統(tǒng)計(jì)方法綜述(二)
文章出處:【微信號(hào):SBCNECB,微信公眾號(hào):上海生物芯片】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
車(chē)聯(lián)網(wǎng)建模和統(tǒng)計(jì)性質(zhì)分析及其路由策略綜述
聚類(lèi)分析方法有哪些
聚類(lèi)分析方法有什么好處
機(jī)器學(xué)習(xí)入門(mén)寶典《統(tǒng)計(jì)學(xué)習(xí)方法》的介紹
基于Python的聚類(lèi)分析及其應(yīng)用簡(jiǎn)介
機(jī)器學(xué)習(xí)在衛(wèi)星遙測(cè)分析建模中的應(yīng)用綜述
水聲被動(dòng)定位中的機(jī)器學(xué)習(xí)方法研究進(jìn)展綜述

機(jī)器學(xué)習(xí)之關(guān)聯(lián)分析介紹
機(jī)器學(xué)習(xí)之分類(lèi)分析與聚類(lèi)分析
聚類(lèi)分析中的機(jī)器學(xué)習(xí)與統(tǒng)計(jì)方法綜述(一)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論