") 追趕GPT-4的多模態(tài)大模型對比分析
追趕GPT-4的多模態(tài)大模型對比分析
引言
今年 3 月 14 日,OpenAI 發(fā)布了 GPT-4 多模態(tài)大模型,但是僅公開了文本能力的接口,遲遲未向公眾開放體驗多模態(tài)能力。學術界和工業(yè)界立刻跟進研究并開源多模態(tài)大模型的相關工作。目前熱度最高的三個同期工作依次是 LLaVA [1]、MiniGPT-4 [2] 和 mPLUG-Owl [3]。本文意在分析這三個工作,探討“類 GPT-4 模型”的研究方向。
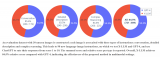
援引自 mPLUG-Owl,這三個工作的主要區(qū)別如圖 1 所示,總體而言,模型結構和訓練策略方面大同小異,主要體現(xiàn)在LLaVA 和 MiniGPT4 都凍住基礎視覺編碼器,mPLUG-Owl 將其放開,得到了更好的視覺文本跨模態(tài)理解效果;在實驗方面mPLUG-Owl 首次構建并開源視覺相關的指令理解測試集 OwlEval,通過人工評測對比了已有的模型,包括 BLIP2 [4]、LLaVA、MiniGPT4 以及系統(tǒng)類工作 MM-REACT [5]。
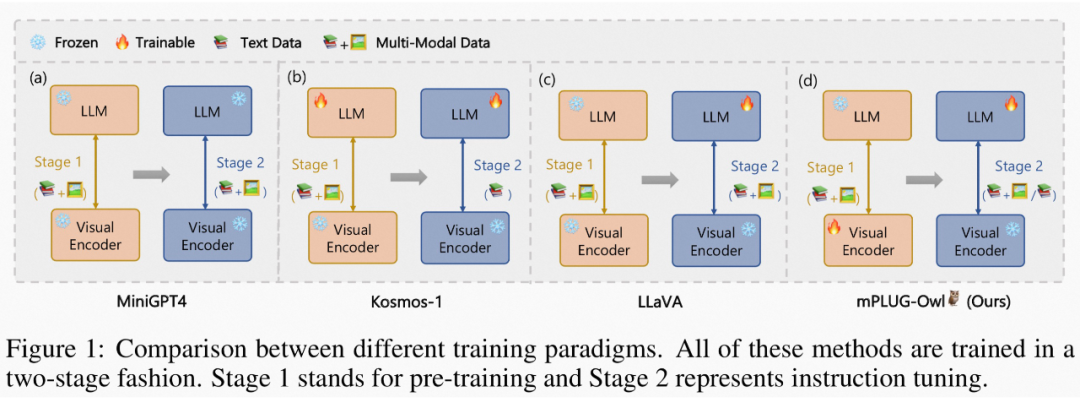
▲ 圖1: mPLUG-Owl vs MiniGPT4 vs LLaVA
LLaVA
自然語言處理領域的 instruction tuning 可以幫助 LLM 理解多樣化的指令并生成比較詳細的回答。LLaVA 首次嘗試構建圖文相關的 instruction tuning 數(shù)據(jù)集來將 LLM 拓展到多模態(tài)領域。 具體來說,基于 MSCOCO 數(shù)據(jù)集,每張圖有 5 個較簡短的 ground truth 描述和 object bbox(包括類別和位置)序列,將這些作為 text-only GPT4 的輸入,通過 prompt 的形式讓 GPT4 生成 3 種類型的文本:1)關于圖像中對象的對話;2)針對圖片的詳細描述;3)和圖片相關的復雜的推理過程。 注意,這三種類型都是 GPT4 在不看到圖片的情況下根據(jù)輸入的文本生成的,為了讓 GPT4 理解這些意圖,作者額外人工標注了一些樣例用于 in-context learning。
模型結構:采用 CLIP 的 ViT-L/14 [6] 作為視覺編碼器,采用 LLaMA [7] 作為文本解碼器,通過一個簡單的線性映射層將視覺編碼器的輸出映射到文本解碼器的詞嵌入空間,如圖 2。
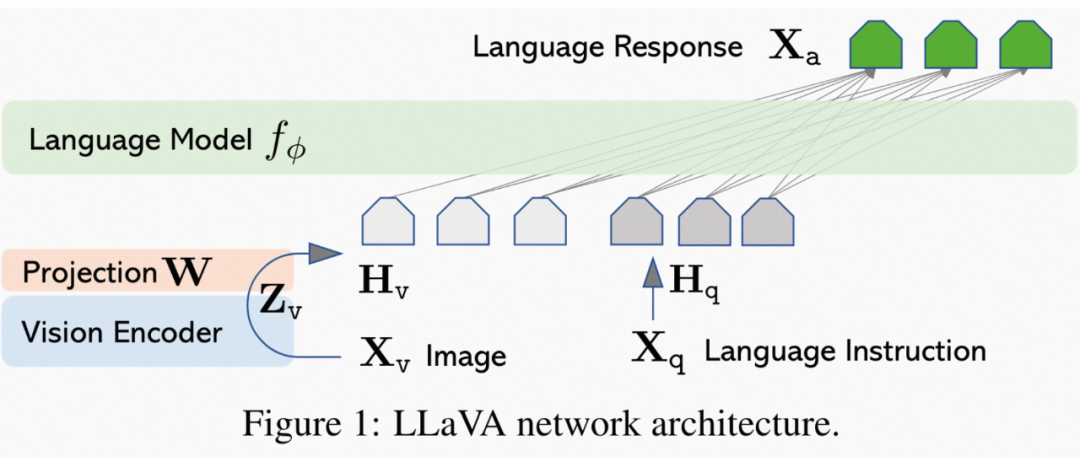
▲ 圖2: LLaVA模型結構
模型訓練:
第一階段:跨模態(tài)對齊預訓練,從CC3M中通過限制 caption 中名詞詞組的最小頻率過濾出595k圖文數(shù)據(jù),凍住視覺編碼器和文本解碼器,只訓練線性映射層;
第二階段:指令微調(diào),一版針對多模態(tài)聊天機器人場景,采用自己構建的158k多模態(tài)指令數(shù)據(jù)集進行微調(diào);另一版針對 Science QA 數(shù)據(jù)集進行微調(diào)。微調(diào)階段,線性層和文本解碼器(LLaMA)都會進行優(yōu)化。
實驗分析:
消融實驗:在 30 個 MSCOCO val 的圖片上,每張圖片設計 3 個問題(對話、詳細描述、推理),參考 Vicuna [8],用 GPT4 對 LLaVA 和 text-only GPT4 的回復進行對比打分,報告相對 text-only GPT4 的相對值。
SOTA 對比:在Science QA上微調(diào)的版本實現(xiàn)了該評測集上的SOTA效果。
MiniGPT-4
Mini-GPT4 和 LLaVA 類似,也發(fā)現(xiàn)了多模態(tài)指令數(shù)據(jù)對于模型在多模態(tài)開放式場景中表現(xiàn)的重要性。
模型結構:采用 BLIP2 的 ViT 和 Q-Former 作為視覺編碼器,采用 LLaMA 經(jīng)過自然語言指令微調(diào)后的版本 Vicuna 作為文本解碼器,也通過一個線性映射層將視覺特征映射到文本表示空間,如圖 3。
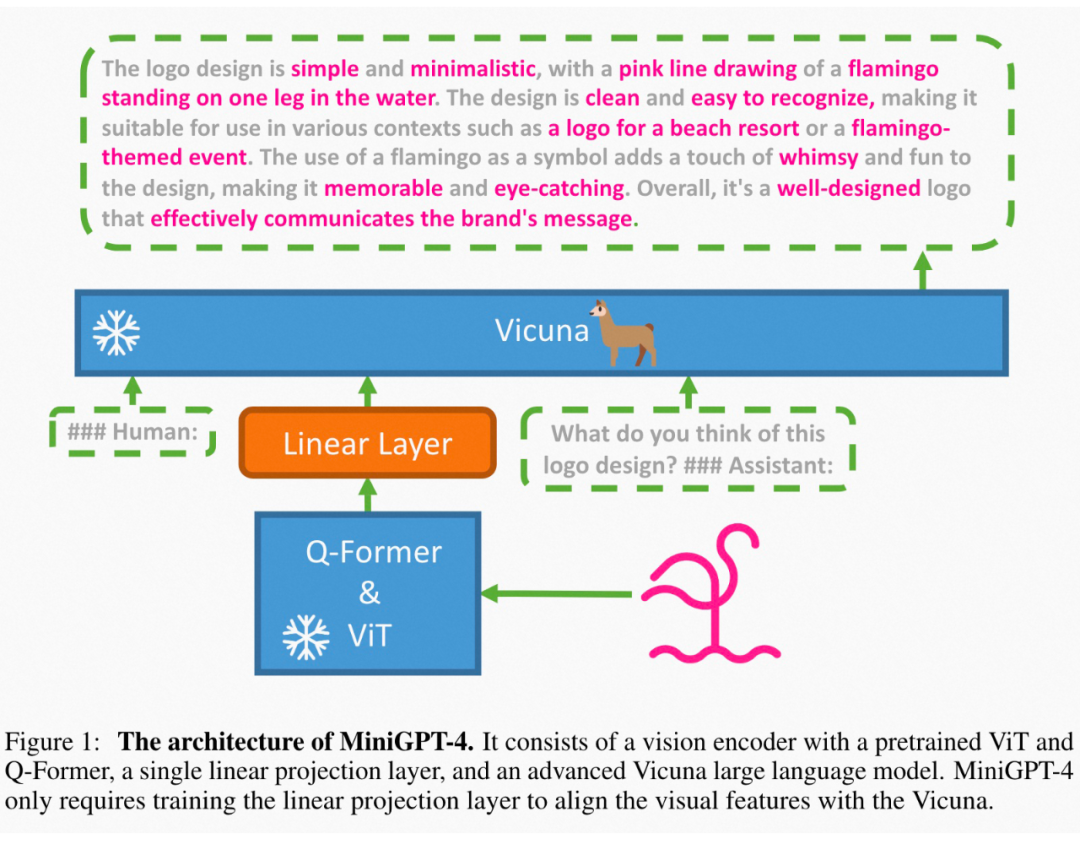
▲ 圖3: MiniGPT-4模型結構
模型訓練:
第一階段:目標通過大量圖文對數(shù)據(jù)學習視覺和語言的關系以及知識,采用 CC+SBU+LAION 數(shù)據(jù)集,凍住視覺編碼器和文本解碼器,只訓練線性映射層; 第二階段:作者發(fā)現(xiàn)只有第一階段的預訓練并不能讓模型生成流暢且豐富的符合用戶需求的文本,為了緩解這個問題,本文也額外利用 ChatGPT 構建一個多模態(tài)微調(diào)數(shù)據(jù)集。 具體來說,1)其首先用階段 1 的模型對 5k 個 CC 的圖片進行描述,如果長度小于 80,通過 prompt 讓模型繼續(xù)描述,將多步生成的結果合并為一個描述;2)通過 ChatGPT 對于構建的長描述進行改寫,移除重復等問題;3)人工驗證以及優(yōu)化描述質(zhì)量。最后得到 3.5k 圖文對,用于第二階段的微調(diào)。第二階段同樣只訓練線性映射層。
實驗分析:
主要進行效果展示,沒有定量的實驗分析。
mPLUG-Owl
mPLUG-Owl 是阿里巴巴達摩院 mPLUG 系列的最新工作,繼續(xù)延續(xù)mPLUG 系列的模塊化訓練思想,將 LLM 遷移為一個多模態(tài)大模型。此外,Owl第一次針對視覺相關的指令評測提出一個全面的測試集 OwlEval,通過人工評測對比了已有工作,包括 LLaVA 和 MiniGPT-4。該評測集以及人工打分的結果都進行了開源,助力后續(xù)多模態(tài)開放式回答的公平對比。
模型結構:采用 CLIP ViT-L/14 作為“視覺基礎模塊”,采用 LLaMA 初始化的結構作為文本解碼器,采用類似 Flamingo 的 Perceiver Resampler 結構對視覺特征進行重組(名為“視覺摘要模塊”),如圖 4。
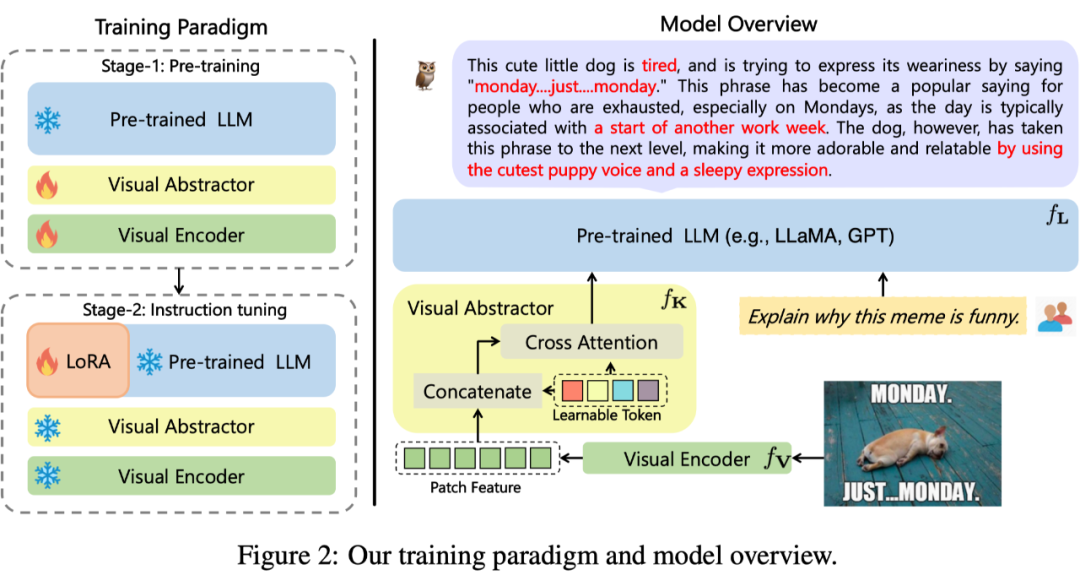
▲ 圖4: mPLUG-Owl模型結構模型訓練: 第一階段:主要目的也是先學習視覺和語言模態(tài)間的對齊。不同于前兩個工作,Owl提出凍住視覺基礎模塊會限制模型關聯(lián)視覺知識和文本知識的能力。因此 Owl 在第一階段只凍住 LLM 的參數(shù),采用 LAION-400M,COYO-700M,CC 以及 MSCOCO訓練視覺基礎模塊和視覺摘要模塊。 第二階段:延續(xù) mPLUG [9] 和 mPLUG-2 [10] 中不同模態(tài)混合訓練對彼此有收益的發(fā)現(xiàn),Owl 在第二階段的指令微調(diào)訓練中也同時采用了純文本的指令數(shù)據(jù)(102k from Alpaca+90k from Vicuna+50k from Baize)和多模態(tài)的指令數(shù)據(jù)(150k from LLaVA)。 作者通過詳細的消融實驗驗證了引入純文本指令微調(diào)在指令理解等方面帶來的收益。第二階段中視覺基礎模塊、視覺摘要模塊和原始 LLM 的參數(shù)都被凍住,參考 LoRA,只在 LLM 引入少量參數(shù)的 adapter 結構用于指令微調(diào)。實驗分析:
除了訓練策略,mPLUG-Owl 另一個重要的貢獻在于通過構建OwlEval 評測集,對比了目前將 LLM 用于多模態(tài)指令回答的 SOTA 模型的效果。和 NLP 領域一樣,在指令理解場景中,模型的回答由于開放性很難進行評估。
SOTA 對比:本文初次嘗試構建了一個基于 50 張圖片(21 張來自MiniGPT-4, 13 張來自 MM-REACT,9 張來自 BLIP-2, 3 來自 GPT-4 以及 4 張自收集)的 82 個視覺相關的指令回答評測集 OwlEval。由于目前并沒有合適的自動化指標,本文參考 Self-Intruct [11] 對模型的回復進行人工評測,打分規(guī)則為:A=“正確且令人滿意”;B=“有一些不完美,但可以接受”;C=“理解了指令但是回復存在明顯錯誤”;D=“完全不相關或不正確的回復”。 實驗證明 Owl 在視覺相關的指令回復任務上優(yōu)于已有的 OpenFlamingo、BLIP2、LLaVA、MiniGPT4 以及集成了 Microsoft 多個 API 的 MM-REACT。作者對這些人工評測的打分同樣進行了開源以方便其他研究人員檢驗人工評測的客觀性。多維度能力對比:多模態(tài)指令回復任務中牽扯到多種能力,例如指令理解、視覺理解、圖片上文字理解以及推理等。為了細粒度地探究模型在不同能力上的水平,本文進一步定義了多模態(tài)場景中的 6 種主要的能力,并對 OwlEval 每個測試指令人工標注了相關的能力要求以及模型的回復中體現(xiàn)了哪些能力。
在該部分實驗,作者既進行了 Owl 的消融實驗,驗證了訓練策略和多模態(tài)指令微調(diào)數(shù)據(jù)的有效性,也和上一個實驗中表現(xiàn)最佳的 baseline——MiniGPT4 進行了對比,結果顯示 Owl 在各個能力方面都優(yōu)于 MiniGPT4。
總結
mPLUG-Owl, MiniGPT4, LLaVA 三篇工作的目標都是希望在已有 LLM 的基礎上,通過較少的訓練代價達到 GPT4 技術報告中所展示多模態(tài)理解效果。他們都證明第一階段的圖文預訓練對于建立圖文之間的聯(lián)系十分關鍵,第二階段的多模態(tài)指令微調(diào)對于模型理解指令以及生成詳細的回復十分必要。三個工作都通過樣例展示了不錯的效果,mPLUG-Owl 進一步構建一個公平比較的多模態(tài)指令評測集,雖然還不夠完善(例如測試指令數(shù)量還不夠多,依賴人工評測等),但也是為了該領域標準化發(fā)展的一個探索和嘗試。
審核編輯 :李倩
-
編碼器
+關注
關注
45文章
3775瀏覽量
137190 -
模型
+關注
關注
1文章
3488瀏覽量
50006 -
GPT
+關注
關注
0文章
368瀏覽量
15948
原文標題:追趕GPT-4的多模態(tài)大模型對比分析
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
高性能計算與多模態(tài)處理的探索之旅:英偉達GH200性能優(yōu)化與GPT-4V的算力加速未來

GPT-4發(fā)布!多領域超越“人類水平”,專家:國內(nèi)落后2-3年

ChatGPT升級 OpenAI史上最強大模型GPT-4發(fā)布
GPT-4多模態(tài)模型發(fā)布,對ChatGPT的升級和斷崖式領先
GPT-4 的模型結構和訓練方法
阿里達摩院:GPT-4的成本只有高級數(shù)據(jù)分析員的0.45%
VisCPM:邁向多語言多模態(tài)大模型時代

GPT-4沒有推理能力嗎?
OpenAI最新大模型曝光!劍指多模態(tài),GPT-4之后最大升級!

新火種AI|谷歌深夜發(fā)布復仇神器Gemini,原生多模態(tài)碾壓GPT-4?

全球最強大模型易主:GPT-4被超越,Claude 3系列嶄露頭角
Anthropic推出Claude 3系列模型,全面超越GPT-4,樹立AI新標桿
微軟Copilot全面更新為OpenAI的GPT-4 Turbo模型
商湯科技發(fā)布5.0多模態(tài)大模型,綜合能力全面對標GPT-4 Turbo
國內(nèi)直聯(lián)使用ChatGPT 4.0 API Key使用和多模態(tài)GPT4o API調(diào)用開發(fā)教程!






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論