") 最新3D表征自監(jiān)督學習+對比學習:FAC
最新3D表征自監(jiān)督學習+對比學習:FAC
論文題目:《FAC: 3D Representation Learning via Foreground Aware Feature Contrast》
作者機構(gòu):Nanyang Technological University(南洋理工大學)
項目主頁:https://github.com/KangchengLiu/FAC_Foreground_Aware_Contrast (基于 PyTorch )
對比學習,最近在 3D 場景理解任務(wù)中展示了無監(jiān)督預訓練的巨大潛力。該作者提出了一個通用的前景感知特征對比 (FAC) 框架, 一種用于大規(guī)模 3D 預訓練的前景感知特征對比框架。FAC 由兩個新穎的對比設(shè)計組成,以構(gòu)建更有效和信息豐富的對比對。構(gòu)建區(qū)域級對比,以增強學習表征中的局部連貫性和更好的前景意識。設(shè)計了一個孿生對應(yīng)框架,可以定位匹配良好的鍵,以自適應(yīng)增強視圖內(nèi)和視圖間特征相關(guān)性,并增強前景-背景區(qū)分。
對多個公共基準的廣泛實驗表明,F(xiàn)AC 在各種下游3D 語義分割和對象檢測任務(wù)中實現(xiàn)了卓越的知識轉(zhuǎn)移和數(shù)據(jù)效率。
摘要
對比學習最近在 3D 場景理解任務(wù)中展示了無監(jiān)督預訓練的巨大潛力。然而,大多數(shù)現(xiàn)有工作在建立對比度時隨機選擇點特征作為錨點,導致明顯偏向通常在 3D 場景中占主導地位的背景點。此外,對象意識和前景到背景的辨別被忽略,使對比學習效果不佳。
為了解決這些問題,我們提出了一個通用的前景感知特征對比 (FAC) 框架,以在預訓練中學習更有效的點云表示。FAC 由兩個新穎的對比設(shè)計組成,以構(gòu)建更有效和信息豐富的對比對。
第一個是在相同的前景段內(nèi)構(gòu)建正對,其中點往往具有相同的語義。
第二個是我們防止 3D 片段/對象之間的過度判別,并通過 Siamese 對應(yīng)網(wǎng)絡(luò)中的自適應(yīng)特征學習鼓勵片段級別的前景到背景的區(qū)別,該網(wǎng)絡(luò)有效地自適應(yīng)地學習點云視圖內(nèi)和點云視圖之間的特征相關(guān)性。
使用點激活圖進行可視化表明,我們的對比對在預訓練期間捕獲了前景區(qū)域之間的清晰對應(yīng)關(guān)系。定量實驗還表明,F(xiàn)AC 在各種下游 3D 語義分割和對象檢測任務(wù)中實現(xiàn)了卓越的知識轉(zhuǎn)移和數(shù)據(jù)效率。
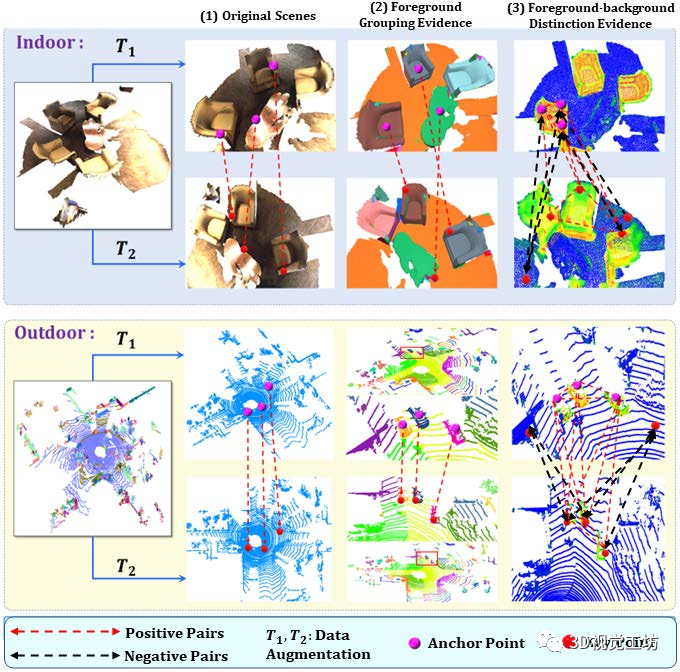
圖1
圖 1構(gòu)建信息對比對在對比學習中很重要:傳統(tǒng)對比需要嚴格的點級對應(yīng)。
所提出的 FAC 方法同時考慮了前景分組 fore-ground 和前景-背景 foreground-background 區(qū)分線索,從而形成更好的對比對以學習更多信息和辨別力的 3D 特征表示。
一、前言
3D 場景理解對于許多任務(wù)至關(guān)重要,例如機器人抓取和自主導航。
然而,大多數(shù)現(xiàn)有工作都是全監(jiān)督的,這在很大程度上依賴于通常很難收集的大規(guī)模帶注釋的 3D 數(shù)據(jù)。自監(jiān)督學習 (SSL)允許從大規(guī)模未注釋的數(shù)據(jù)中學習豐富且有意義的表示,最近顯示出減輕標注約束的巨大潛力。它通過來自未標注數(shù)據(jù)的輔助監(jiān)督信號進行學習,這些數(shù)據(jù)通常更容易收集。特別是,對比學習作為一種流行的 SSL 方法在各種視覺 2D 識別任務(wù)中取得了巨大成功。
在語義分割、實例分割和對象檢測等各種下游任務(wù)中,還探索了用于點云表示學習的對比學習。然而,許多成功的 2D 對比學習方法對 3D 點云效果不佳,這主要是因為點云通常捕獲由許多不規(guī)則分布的前景對象的復雜點以及大的背景點的數(shù)量。一些研究試圖設(shè)計特定的對比度來迎合點云的幾何形狀和分布。
例如,[14, 55] 使用兩個增強場景的最大池化特征來形成對比,但它們往往過分強調(diào)整體信息而忽略了前景對象的信息特征。
[12,19,51] 直接使用配準的點/體素特征作為正對,并對待所有未配準為否定對,導致語義上有許多錯誤的對比對。
我們建議利用場景前景 foreground 證據(jù)和前景-背景 foreground-background 區(qū)別來構(gòu)建更多的前景分組意識和前景-背景區(qū)別意識對比,以學習有區(qū)別的 3D 表示。
對于前景分組感知對比,我們首先獲得與過度分割的區(qū)域?qū)?yīng)關(guān)系,然后在視圖中與同一區(qū)域的點建立正對,從而產(chǎn)生語義連貫的表示。此外,我們設(shè)計了一種采樣策略,在建立對比的同時采樣更多的前景點特征,因為背景點特征通常信息量較少,并且具有重復或同質(zhì)的模式。
對于前景-背景對比,我們首先增強前景-背景點特征區(qū)分,然后設(shè)計一個 Siamese 對應(yīng)網(wǎng)絡(luò),通過自適應(yīng)學習前景和背景視圖內(nèi),及跨視圖的特征對之間的親和力來選擇相關(guān)特征,以避免部分/對象之間的過度判別。
可視化顯示,前景增強對比度引導學習朝向前景區(qū)域,而前景-背景對比度以互補的方式有效地增強了前景和背景特征之間的區(qū)別,兩者合作學習更多的信息和判別表示,如圖 1 所示。
這項工作的貢獻可以概括為三個方面。
第一,我們提出了 FAC,一種用于大規(guī)模 3D 預訓練的前景感知特征對比框架。
第二,我們構(gòu)建區(qū)域級對比,以增強學習表征中的局部連貫性和更好的前景意識。
第三,最重要的是,我們設(shè)計了一個孿生對應(yīng)框架,可以定位匹配良好的鍵,以自適應(yīng)增強視圖內(nèi)和視圖間特征相關(guān)性,并增強前景-背景區(qū)分。
最后,對多個公共基準的廣泛實驗表明,與最先進的技術(shù)相比,F(xiàn)AC 實現(xiàn)了卓越的自監(jiān)督學習。
FAC 兼容流行的 3D 分割主干網(wǎng)絡(luò) SparseConv 和 3D 檢測主干網(wǎng)絡(luò),包括 PV-RCNN、PointPillars 和 PointRCNN。
它也適用于室內(nèi)密集 RGB-D 和室外稀疏 LiDAR 點云。
二、相關(guān)工作
2.1 3D 場景理解
3D 場景理解旨在理解 3D 深度或點云數(shù)據(jù),它涉及多個下游任務(wù),例如 3D 語義分割 ,3D 對象檢測等。在 3D 深度學習策略的進步和不斷增加的大規(guī)模 3D 數(shù)據(jù)集的推動下,它最近取得了令人矚目的進展。已經(jīng)提出了不同的方法來解決 3D 場景理解中的各種挑戰(zhàn)。
例如,基于點的方法可以很好地學習點云,但在面對大規(guī)模點云數(shù)據(jù)集時往往會受到高計算成本的困擾。
基于體素的方法具有計算和內(nèi)存效率,但通常會因體素量化而丟失信息。
此外,基于體素的 SparseConv 網(wǎng)絡(luò)在室內(nèi)場景分割中表現(xiàn)出非常有前途的性能,而結(jié)合點和體素通常在基于 LiDAR 的室外檢測中具有明顯的優(yōu)勢。我們提出的 SSL 框架在室內(nèi)/室外 3D 感知任務(wù)中顯示出一致的優(yōu)勢,并且它也是 backbone 不可知論的。
2.2 點云的自監(jiān)督預訓練。
對比預訓練
近年來,在學習無監(jiān)督表示的對比學習方面取得了顯著的成功。
例如,對比場景上下文 (CSC)使用場景上下文描述符探索對比預訓練。然而,它過于關(guān)注優(yōu)化低級配準點特征,而忽視了區(qū)域同質(zhì)語義模式和高級特征相關(guān)性。
一些工作使用最大池化場景級信息進行對比,但它往往會犧牲局部幾何細節(jié)和對象級語義相關(guān)性,從而導致語義分割等密集預測任務(wù)的次優(yōu)表示。
不同的是,我們明確考慮區(qū)域前景意識以及前景和背景區(qū)域之間的特征相關(guān)性和區(qū)別,這會導致 3D 下游任務(wù)中提供更多信息和判別性表示。
此外,許多方法結(jié)合了輔助時間或空間 3D 信息,用于與增強的未標記數(shù)據(jù)集和合成 CAD 模型進行自監(jiān)督對比:
例如通過將 3D 場景視為 RGB-D 視頻序列,從動態(tài) 3D 場景中引入學習合成 3D。
Randomrooms 通過將合成 CAD 模型隨機放入常規(guī)合成 3D 場景中,來合成人造 3D 場景。
一些作品利用合成 3D 形狀的時空運動先驗,來學習更好的 3D 表示。
然而,大多數(shù)這些先前的研究都依賴于輔助時空信息的額外監(jiān)督。不同的是,我們在沒有額外合成 3D 模型的情況下對原始 3D 掃描進行自監(jiān)督學習。
基于 mask 生成的預訓練
隨著視覺轉(zhuǎn)換器的成功,mask 圖像建模已證明其在各種圖像理解任務(wù)中的有效性 。最近,基于掩碼的預訓練也被探索用于理解小型 3D 形狀。
然而,基于掩碼的設(shè)計通常涉及一個 transformer 主干,它在處理大型 3D 場景時對計算和內(nèi)存都有很高的要求。
我們專注于對比學習的預訓練,它與基于點和基于體素的 backbone 網(wǎng)絡(luò)兼容。
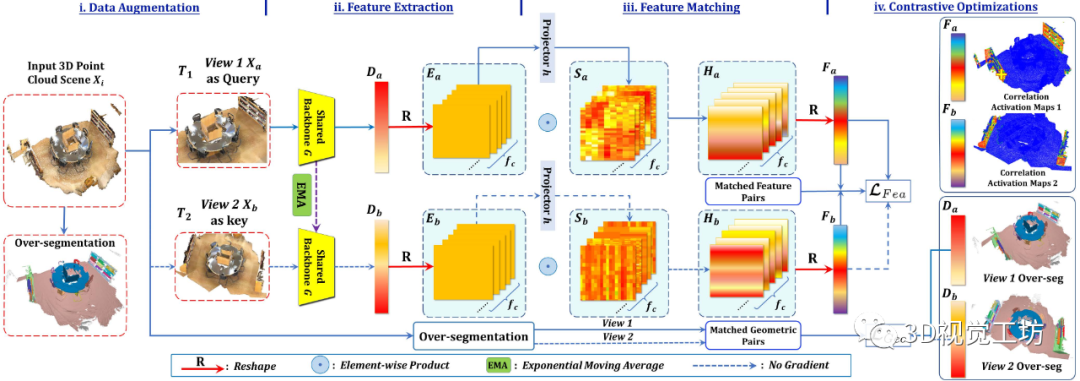
圖 2. 我們提議的 FAC 的框架。
FAC 將兩個增強的 3D 點云視圖作為輸入,首先提取主干特征 和 以與 進行前景感知對比。
然后將主干特征重塑為正則化表示 和 ,以找到兩個視圖之間的對應(yīng)關(guān)系以進行特征匹配。具體來說,我們采用投影頭將 和 傳輸?shù)教卣鲌D 和 ,以自適應(yīng)地學習它們的相關(guān)性并產(chǎn)生增強的表示 和 。
最后, 和 被重塑回 和 ,其中匹配的特征對通過特征對比度損失 得到增強。
因此,F(xiàn)AC 在視圖內(nèi)和視圖之間利用互補的前景意識,以及前景-背景區(qū)別來進行更多信息表示學習。
三、方法
如圖 2 所示,我們提出的 FAC 框架由四個部分組成:數(shù)據(jù)增強、骨干網(wǎng)絡(luò)特征提取、特征匹配和具有匹配對比對的前景-背景感知特征對比優(yōu)化。
在下文中,我們首先重新審視 3D 點云的典型對比學習方法,并討論它們可能導致信息較少的表示的局限性。
然后,我們從三個主要方面闡述了我們提出的 FAC:
區(qū)域分組對比,利用過度分割的局部幾何同質(zhì)性,來鼓勵局部區(qū)域的語義連貫性;
一個由連體網(wǎng)絡(luò)和特征對比損失組成的對應(yīng)框架,用于捕獲所學特征表示之間的相關(guān)性;
利用更好的對比對,進行更具辨別力的自監(jiān)督學習的優(yōu)化損失。
3.1 重新思考點級和場景級對比
基于對比學習的 3D SSL 的關(guān)鍵是在兩個增強視圖之間構(gòu)建有意義的對比對。正對已在 PointContrast (PCon) 中的點級別或 DepthContrast (DCon) 中的場景級別中構(gòu)建。
具體來說,給定 3D 局部點/深度掃描的增強視圖,應(yīng)用對比損失來最大化正對的相似性和負對之間的區(qū)別。在大多數(shù)情況下,可以應(yīng)用 InfoNCE loss來進行對比:
這里:
和 是兩個增強視圖的特征向量,用于對比。
是匹配正對的索引集。 是正對,其特征嵌入被強制相似;
而 是負對,其特征嵌入被鼓勵相似與眾不同。
PCon 直接采用配準點級特征對,而 DCon 使用最大池化場景級特征對進行對比。盡管它們在 3D 下游任務(wù)中表現(xiàn)不錯,但先前研究中構(gòu)建的對比對往往是次優(yōu)的。如圖 1 所示:
點級對比度往往過分強調(diào)細粒度的低級細節(jié),而忽略了通常提供對象級信息的區(qū)域級幾何連貫性。
場景級對比聚合了整個場景的特征以進行對比,這可能會丟失對象級空間上下文和獨特的特征,從而導致下游任務(wù)的信息表示較少。
因此,我們推測區(qū)域級對應(yīng)更適合形成對比度,并且如圖 1 所示,這已經(jīng)通過實驗驗證,更多細節(jié)將在隨后的小節(jié)中詳細說明。
3.2 前景感知對比度
Region-wise 特征表示已被證明在考慮下游任務(wù)(如語義分割和檢測)的上下文時非常有用。在我們提出的幾何區(qū)域級前景感知對比中,我們通過利用現(xiàn)成的點云過分割技術(shù)來獲得區(qū)域。采用過度分割(over-segmentation)的動機是其在三個主要方面的優(yōu)點。
首先,它可以以完全無監(jiān)督的方式工作,不需要任何帶標注的數(shù)據(jù)。
其次,我們提出的區(qū)域采樣(稍后描述)允許我們以無監(jiān)督的方式過濾掉天花板、墻壁和地面等背景區(qū)域,其中背景區(qū)域通常由具有大量點的幾何均勻圖案表示。也可以過濾掉點數(shù)非常有限的區(qū)域,這些區(qū)域在幾何和語義上都是嘈雜的。
第三,過分割提供了具有高語義相似性的幾何連貫區(qū)域,而不同的遠距離區(qū)域在采樣后往往在語義上是不同的,這有效地促進了判別特征學習。
具體來說,過分割將原始點云場景劃分為 類不可知區(qū)域 , 對于任何 來說:。
我們的實證實驗表明,我們的框架 FAC 在沒有微調(diào)的情況下,可以有效地與主流的過分割方法一起工作。
平衡學習的區(qū)域抽樣
我們設(shè)計了一種簡單但有效的區(qū)域采樣技術(shù),以從通過過度分割導出的幾何均勻區(qū)域獲得有意義的前景。具體來說:
我們首先統(tǒng)計每個區(qū)域的點數(shù),并根據(jù)區(qū)域包含的點數(shù)對區(qū)域進行排序。
然后我們將具有中位數(shù)點數(shù)的區(qū)域識別為 。
接下來,我們選擇點數(shù)與 最接近的 個區(qū)域來形成對比對。
本地區(qū)域一致性的對比
與上述 PCon 和 DCon 不同,我們直接利用區(qū)域同質(zhì)性來獲得對比度對。
具體來說,以區(qū)域內(nèi)的平均點特征為錨點,我們將同一區(qū)域內(nèi)的選定特征視為正鍵,將不同區(qū)域內(nèi)的選定特征視為負鍵。
受益于區(qū)域采樣策略,我們可以專注于前景以更好地表示學習。將區(qū)域內(nèi)的點數(shù)表示為 ,將主干特征表示為 ,我們將它們的點特征聚合以產(chǎn)生區(qū)域內(nèi)的平均區(qū)域特征作為錨點,以增強魯棒性:
將 作為錨點,我們提出了一種前景感知幾何對比度損失,將點特征拉到局部幾何區(qū)域中對應(yīng)的正特征,并將其與不同分離區(qū)域的負點特征推開:
這里, 和 分別表示具有 的正樣本和負樣本。
我們將每個區(qū)域錨點的正負點特征對的數(shù)量均等地設(shè)置為 。請注意,我們提出的前景對比度是 PCon 的通用版本,前景增強,如果所有區(qū)域都縮小到一個點,它會返回到 PCon。受益于區(qū)域幾何一致性和平衡的前景采樣,僅前景感知對比度就在經(jīng)驗實驗結(jié)果的數(shù)據(jù)效率方面優(yōu)于最先進的 CSC 。
3.3 前景-背景(foreground-background)感知對比度
如圖 2 所示,我們提出了一個連體對應(yīng)網(wǎng)絡(luò) (SCN) ,來明確識別視圖內(nèi)和視圖之間的特征對應(yīng)關(guān)系,并引入特征對比度損失以自適應(yīng)地增強它們的相關(guān)性。 SCN 僅在預訓練階段用于提高表示質(zhì)量。預訓練后,只有骨干網(wǎng)絡(luò)針對下游任務(wù)進行微調(diào)。
用于自適應(yīng)相關(guān)挖掘的孿生通信網(wǎng)絡(luò)。給定具有 個點的輸入3D場景
FAC首先將其轉(zhuǎn)換為兩個增強視圖和
并通過將兩個視圖輸入骨干網(wǎng)絡(luò) 及其動量來獲得骨干特征和 分別更新(通過指數(shù)移動平均)( 是特征通道數(shù))。
為了公平比較,我們采用與現(xiàn)有工作相同的增強方案。
此外,我們將主干點級特征重塑為特征圖 和 ,以獲得正則化點云表示并降低計算成本。
然后,我們將投影儀分別應(yīng)用于 和 ,以獲得與 和 相同維度的特征圖 和 。我們采用兩個簡單的點 MLP,中間有一個 ReLU 層來形成投影儀 。特征圖 和 作為可學習的分數(shù),自適應(yīng)地增強兩個視圖內(nèi)和跨兩個視圖的重要和相關(guān)特征。
最后,我們在 and 之間進行逐元素乘積,以獲得增強的特征 和 進一步轉(zhuǎn)化回逐點特征 和 進行對應(yīng)挖掘。所提出的 SCN 增強了全局特征級判別表示學習,從而能夠與匹配的特征進行后續(xù)對比。
與 Matched Feature 和 ForegroundBackground Distinction 對比。
將獲得的采樣前景-背景對標記為負,我們進行特征匹配以選擇最相關(guān)的正對比對。如圖 2 所示,我們評估 和 之間的相似性并選擇最相關(guān)的對進行對比。區(qū)域錨點的選擇方式與 3.2 小節(jié)相同。
具體地,我們首先引入一個區(qū)域內(nèi)點特征的平均特征作為形成對比時的錨點,給出,基于點的觀察在同一局部區(qū)域中往往具有相同的語義。
對于 中的第 個點級特征 ,我們計算其與區(qū)域特征 的相似度:
這里 表示向量 和 之間的余弦相似度。我們從 中采樣前 個元素作為正鍵,同時從前景和背景點特征中提取區(qū)域特征 。通過將 操作重新表述為最優(yōu)傳輸問題,很容易使其變得可微分。
此外,我們同樣選擇其他 個前景-背景對作為負對:
這里, 表示在另一個視圖中從 中識別出的與 最相似的 個元素的正鍵。 分別表示一批中采樣的其他 個負點特征。因此,通過學習 3D 場景的點級特征圖 和 ,可以自適應(yīng)地增強相關(guān)的交叉視點特征。
我們的特征對比通過明確地找到前景錨點的區(qū)域到點最相關(guān)的鍵作為查詢來增強視圖內(nèi)和視圖之間特征級別的相關(guān)性。通過學習特征圖,自適應(yīng)地強調(diào)相關(guān)前景/背景點的特征,同時抑制前景-背景特征。FAC 在點激活圖中定性有效,在下游遷移學習和數(shù)據(jù)效率方面定性有效。
3.4 FAC聯(lián)合優(yōu)化
同時考慮局部區(qū)域級前景幾何對應(yīng)和視圖內(nèi)與視圖間的全局前景-背景區(qū)分,F(xiàn)AC框架 的總體目標函數(shù)如下:
這里 是平衡兩個損失項的權(quán)重。我們根據(jù)經(jīng)驗設(shè)置 而不進行調(diào)整。

圖3
圖 3. 室內(nèi) ScanNet(第 1-4 行)和室外 KITTI (第 5-8 行)投影點相關(guān)圖關(guān)于黃色十字突出顯示的查詢點的可視化。
每個示例中的視圖 1 和視圖 2 ,分別顯示視圖內(nèi)和交叉視圖相關(guān)性。
我們將 FAC 與最先進的 CSC 在分割(第 1-4 行)和 ProCo 在檢測(第 5-8 行)方面進行比較。
FAC 清楚地捕獲了視圖內(nèi)和視圖之間更好的特征相關(guān)性(第 3-4 列)。
四、實驗
數(shù)據(jù)高效學習和知識轉(zhuǎn)移能力已被廣泛用于評估自監(jiān)督預訓練和學習的無監(jiān)督表示[12]。在下面的實驗中,我們首先在大規(guī)模未標記數(shù)據(jù)上預訓練模型,然后對其進行微調(diào)使用下游任務(wù)的少量標記數(shù)據(jù)來測試其數(shù)據(jù)效率。
我們還將預訓練模型轉(zhuǎn)移到其他數(shù)據(jù)集,以評估它們的知識轉(zhuǎn)移能力。這兩個方面通過多個下游任務(wù)進行評估,包括3D 語義分割、實例分割和對象檢測。附錄中提供了所涉及數(shù)據(jù)集的詳細信息。
4.1.實驗設(shè)置
3D 對象檢測。
對象檢測實驗涉及兩個主干,包括 VoxelNet 和 PointPillars。按照 ProCo,我們在 Waymo 上預訓練模型并在 KITTI 和 Waymo 上對其進行微調(diào)。繼 ProCo 和 CSC 之后,我們通過隨機旋轉(zhuǎn)、縮放和翻轉(zhuǎn)以及隨機點丟失來增強數(shù)據(jù)以進行公平比較。
我們在 ProCo 之后將 和 中的超參數(shù) 設(shè)置為 ,,并且在所有實驗中正/負對的總數(shù)為 ,包括檢測和分割而不調(diào)整。
在 Waymo 和 KITTI [8] 的室外目標檢測中,我們使用 Adam 優(yōu)化器對網(wǎng)絡(luò)進行預訓練,并遵循 ProCo 的 epoch和批量大小設(shè)置,以便與現(xiàn)有作品進行公平比較。
在 ScanNet 上的室內(nèi)物體檢測中,我們遵循 CSC 采用 SparseConv 作為骨干網(wǎng)絡(luò)和 VoteNet 作為 3D 檢測器,并遵循其訓練設(shè)置,場景重建數(shù)量有限。
3D 語義分割。
對于 3D 分割,我們在有限的重建設(shè)置中嚴格遵循 CSC。具體來說,我們在 ScanNet 上進行預訓練,并對室內(nèi) S3DIS、ScanNet 和室外 SemanticKITTI (SK)上的預訓練模型進行微調(diào)。
我們在預訓練中使用 SGD,學習率為 ,批量大小為 ,步長為 ,以確保與其他 3D 預訓練方法(包括 CSC 和 PCon)進行公平比較。此外,我們在 SK 上測試了 ScanNet 預訓練模型,以評估其對室外稀疏 LiDAR 點云的學習能力。
唯一的區(qū)別是我們對 SK 的模型進行了 次微調(diào),而對室內(nèi)數(shù)據(jù)集進行了 次微調(diào)。使用 SK 進行更長時間的微調(diào)是因為將在室內(nèi)數(shù)據(jù)上訓練的模型轉(zhuǎn)移到室外數(shù)據(jù)需要更多時間來優(yōu)化和收斂。
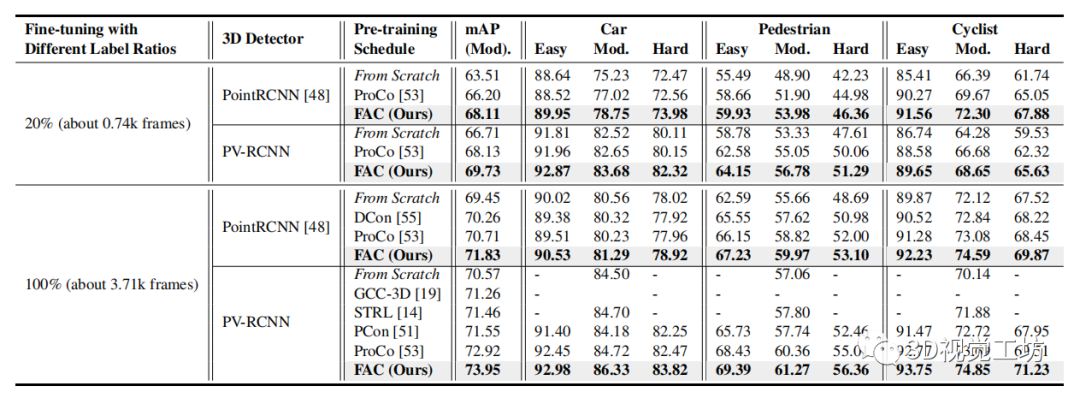
表1
表 1. KITTI 上的數(shù)據(jù)高效3D 對象檢測。
我們在 Waymo 上預訓練了 PointRCNN 和 PV-RCNN 的骨干網(wǎng)絡(luò),并在微調(diào)中以 和 的注釋比例轉(zhuǎn)移到 KITTI。對于兩種設(shè)置,F(xiàn)AC 始終優(yōu)于最先進的 ProCo。“From Scratch”表示從頭開始訓練的模型。所有實驗結(jié)果均取三個運行的平均值。
4.2.數(shù)據(jù)高效的遷移學習
3D 對象檢測。
自監(jiān)督預訓練的一個主要目標是使用更少的標記數(shù)據(jù)進行更高效的數(shù)據(jù)遷移學習以進行微調(diào)。我們評估了從 Waymo 到 KITTI 的數(shù)據(jù)高效傳輸,如表 1 和圖 4 所示。
我們可以看到 FAC 始終優(yōu)于最新技術(shù)。通過使用 的標記數(shù)據(jù)進行微調(diào),F(xiàn)AC 通過使用 的訓練數(shù)據(jù)實現(xiàn)了與從頭開始訓練相當?shù)男阅埽故玖怂跍p輕 3D 對象檢測中對大量標記工作的依賴方面的潛力。如圖 3 所示,F(xiàn)AC 對車輛和行人等視圖間和視圖內(nèi)對象具有明顯更大的激活,表明其學習到的信息和判別表示。
我們還研究了數(shù)據(jù)高效學習,同時在具有 1% 標簽的標簽極其稀缺的情況下執(zhí)行域內(nèi)傳輸?shù)?Waymo 驗證集。如表 2 所示,F(xiàn)AC 明顯且一致地優(yōu)于 ProCo,證明了其在減少數(shù)據(jù)注釋方面的潛力。此外,我們在 ScanNet 上進行了室內(nèi)檢測實驗。
如表 3 所示,與 From Scratch 相比,F(xiàn)AC 實現(xiàn)了出色的轉(zhuǎn)移,并將 AP 顯著提高了 ,標簽為 10%。此外,當應(yīng)用較少的注釋數(shù)據(jù)時,改進會更大。卓越的對象檢測性能主要歸功于我們利用信息前景區(qū)域形成對比度的前景感知對比度,以及增強整體對象級表示的自適應(yīng)特征對比度。
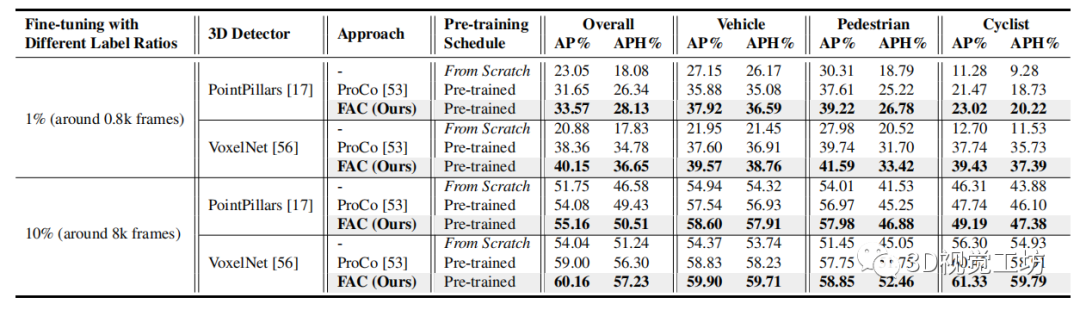
表2
表 2. Waymo 上具有 1% 和 10% 標記訓練數(shù)據(jù)的數(shù)據(jù)高效3D 對象檢測實驗結(jié)果。與最先進的 ProCo 相比,表 1 中針對 FAC 的 KITTI 獲得了類似的實驗結(jié)果。
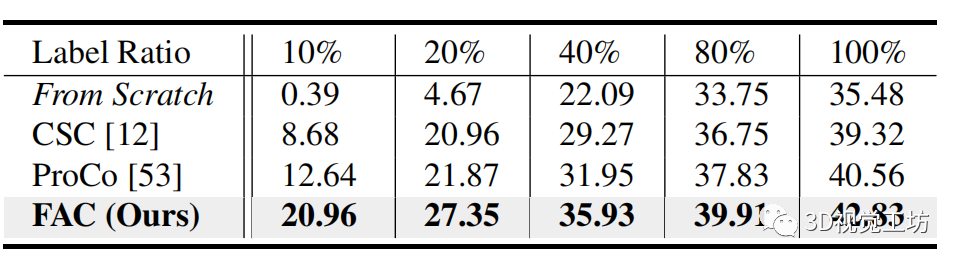
表3
表 3. 以 VoteNet 作為主干網(wǎng)絡(luò)的 ScanNet 上,有限數(shù)量的場景重建的數(shù)據(jù)高效3D 對象檢測平均精度 (AP%) 結(jié)果。
3D 語義分割。
我們首先對數(shù)據(jù)集 ScanNet 上的點激活圖進行定性分析。如圖 3 所示,與最先進的 CSC 相比,F(xiàn)AC 可以在 3D 場景內(nèi)和之間找到更多的語義關(guān)系。這表明 FAC 可以學習捕捉相似特征同時抑制不同特征的極好的表征。
我們還進行了如表 4 所示的定量實驗,我們在訓練中采用有限的標簽(例如,{1%、5%、10%、20%})。我們可以看到,對于不同標記百分比下的兩個語義分割任務(wù),F(xiàn)AC 的性能始終大大優(yōu)于基線 From Scratch。
此外,當僅使用 1% 的標簽時,F(xiàn)AC 的性能顯著優(yōu)于最先進的 CSC,證明其在使用有限標簽學習信息表示方面的強大能力。注意 FAC 在使用較少標記數(shù)據(jù)的同時實現(xiàn)了更多改進。對于數(shù)據(jù)集 SK 上的語義分割,F(xiàn)AC 在標記數(shù)據(jù)減少的情況下實現(xiàn)了一致的改進和類似的趨勢。
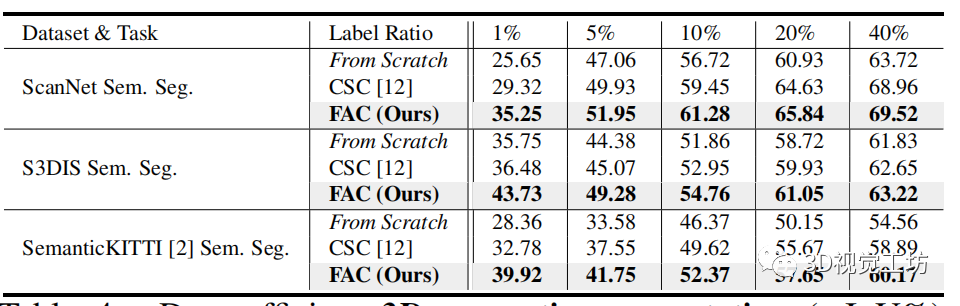
表4
表 4. 具有不同標簽比率的 ScanNet、S3DIS 和 SemanticKITTI (SK) 上有限場景重建 的數(shù)據(jù)高效3D 語義分割(mIoU%) 結(jié)果。
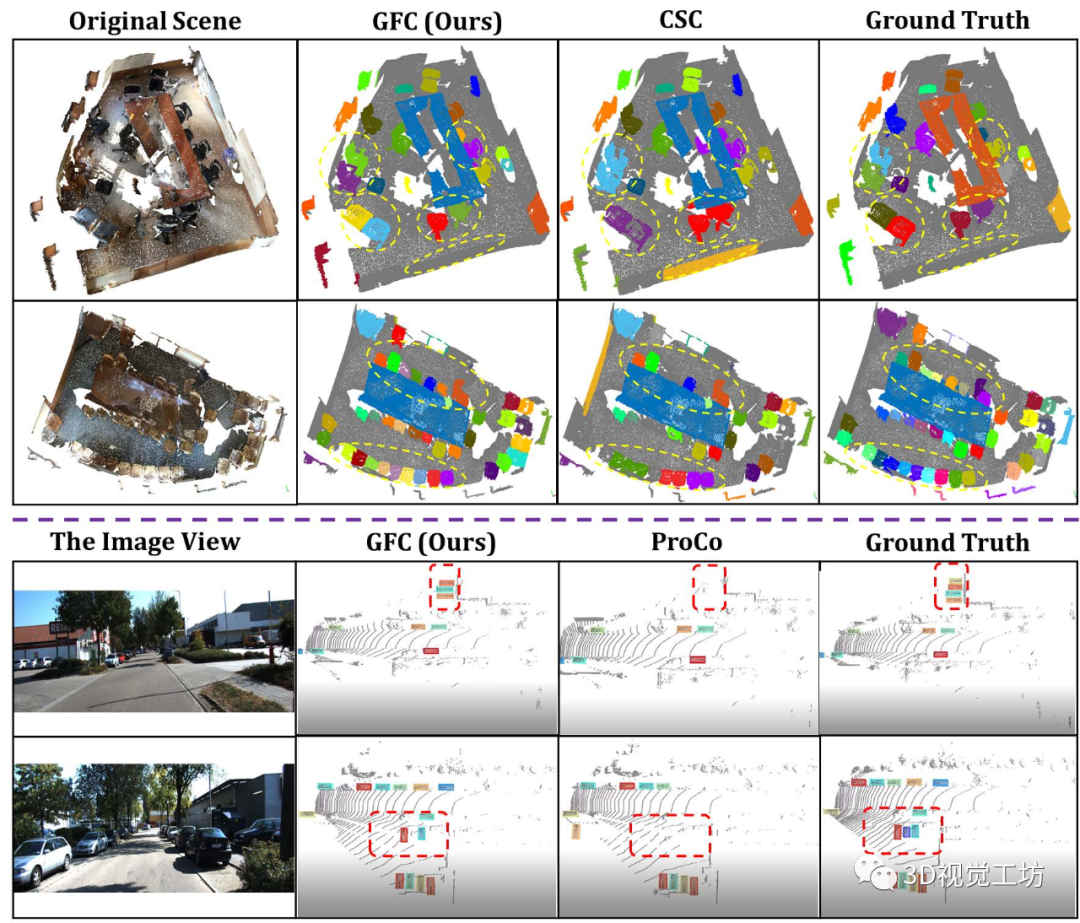
圖 4. 與 CSC 相比,ScanNet 的室內(nèi) 3D 分割可視化與 ProCo 相比,使用 10% 標記訓練數(shù)據(jù)和 KITTI 進行微調(diào),帶有 20% 標記訓練數(shù)據(jù)。
不同的分割實例和檢測到的對象,用不同的顏色突出顯示。
預測的差異,用黃色橢圓和紅色框突出顯示。
歡迎關(guān)注微信公眾號「3D視覺工坊」,加群/文章投稿/課程主講,請加微信:dddvisiona,添加時請備注:加群/投稿/主講申請
方向主要包括:3D視覺領(lǐng)域各細分方向,比如相機標定|三維點云|三維重建|視覺/激光SLAM|感知|控制規(guī)劃|模型部署|3D目標檢測|TOF|多傳感器融合|AR|VR|編程基礎(chǔ)等。
4.3.消融研究和分析
我們對 FAC 中的關(guān)鍵設(shè)計進行廣泛的消融研究。具體來說,我們檢查了所提出的區(qū)域采樣、特征匹配網(wǎng)絡(luò)和兩個損失的有效性。最后,我們提供t-SNE 可視化以將 FAC 學習的特征空間與最先進的進行比較。
在消融研究中,我們在語義分割實驗中采用 5% 的標簽,在 ScanNet 上的室內(nèi)檢測實驗中采用 10% 的標簽,在 KITTI 上采用 PointRCNN 作為 3D 檢測器的室外物體檢測實驗中采用 20% 的標簽。
區(qū)域抽樣和特征匹配。
區(qū)域采樣將前景區(qū)域中的點采樣為錨點。表 5 顯示了由抽樣表示的相關(guān)消融研究。
我們可以看到,在沒有采樣的情況下,分割和檢測都會惡化,這表明過度分割中的前景區(qū)域在形成對比度的同時可能提供重要的對象信息。它驗證了所提出的區(qū)域采樣不僅可以抑制噪聲,還可以減輕對背景的學習偏差,從而在下游任務(wù)中提供更多信息。
此外,我們用匈牙利二分匹配(即H-FAC)替換建議的 Siamese 對應(yīng)網(wǎng)絡(luò),如表 5 所示。我們可以觀察到一致的性能下降,表明我們的 Siamese 對應(yīng)框架可以實現(xiàn)更好的特征匹配并提供用于下游任務(wù)的相關(guān)性良好的特征對比對。附錄中報告了更多匹配策略的比較。
FAC 損失。
FAC 采用前景感知幾何損失 和特征損失 ,這對其在各種下游任務(wù)中的學習表示至關(guān)重要。幾何損失指導前景感知對比度以捕獲局部一致性,而特征損失指導前景背景區(qū)分。它們是互補的,并且協(xié)作學習下游任務(wù)的判別表示。
如表 5 中的案例 4 和案例 6 所示,包括損失明顯優(yōu)于基線以及最先進的 CSC 在分割方面和 ProCo 在檢測方面的表現(xiàn)。
例如,僅包括 (案例 6)在 KITTI 和 ScanNet 上的目標檢測平均精度達到 67.22% 和 18.79%,分別優(yōu)于 ProCo(66.20% 和 12.64%)1.02% 和 6.15%,如表 1 和表3。
最后,表 5 中的完整 FAC(包括兩種損失)在各種下游任務(wù)中學習到具有最佳性能的更好表示。
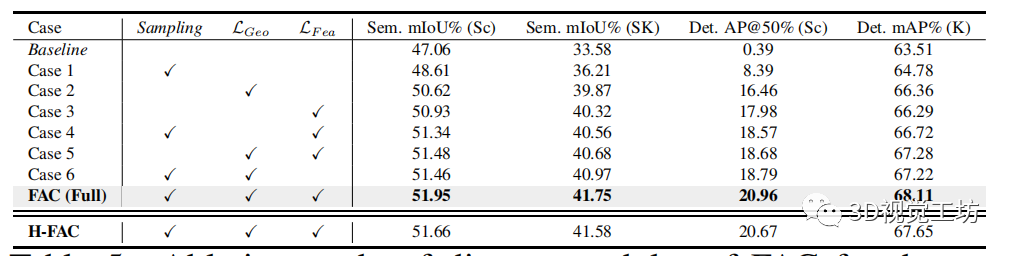
表5
表 5. FAC 不同模塊在 ScanNet (Sc) 和 SemanticKITTI (SK) , 及 KITTI (K) 下游任務(wù)的消融研究
使用 t-SNE 進行特征可視化。
我們使用 tSNE 來可視化為 SemanticKITTI 語義分割任務(wù)學習的特征表示,如圖 5 所示。
與 PCon 和 CSC 等其他對比學習方法相比,F(xiàn)AC 學習了更緊湊和判別特征空間,可以清楚地區(qū)分不同語義類的特征。
如圖 5 所示,F(xiàn)AC 學習的特征具有最小的類內(nèi)方差和最大的類間方差,表明 FAC 學習的表示有助于在下游任務(wù)中學習更多的判別特征。

圖 5. t-SNE SemanticKITTI 語義分割的特征嵌入可視化,使用 5% 的標簽進行微調(diào)(ScanNet 預訓練)。
顯示了具有最少點數(shù)的十個類,其中 表示類內(nèi)和類間方差。
與最先進的方法 PCon、CSC 相比,F(xiàn)AC 學習了更緊湊的特征空間,具有最小的類內(nèi)方差和最大的類間方差。
五、結(jié)論
我們提出了一種用于 3D 無監(jiān)督預訓練的前景感知對比框架 (FAC)。FAC 構(gòu)建更好的對比對以產(chǎn)生更多幾何信息和語義意義的 3D 表示。
具體來說,我們設(shè)計了一種區(qū)域采樣技術(shù),來促進過度分割的前景區(qū)域的平衡學習并消除噪聲區(qū)域,這有助于基于區(qū)域?qū)?yīng)構(gòu)建前景感知對比對。
此外,我們增強了前景-背景的區(qū)別,并提出了一個即插即用的 Siamese 對應(yīng)網(wǎng)絡(luò),以在前景和背景部分的視圖內(nèi)和視圖之間找到相關(guān)性良好的特征對比對。
大量實驗證明了 FAC 在知識轉(zhuǎn)移和數(shù)據(jù)效率方面的優(yōu)越性。
審核編輯 :李倩
-
3D
+關(guān)注
關(guān)注
9文章
2948瀏覽量
109400 -
框架
+關(guān)注
關(guān)注
0文章
404瀏覽量
17780 -
FAC
+關(guān)注
關(guān)注
0文章
7瀏覽量
7642
原文標題:CVPR2023 | 最新 3D 表征自監(jiān)督學習+對比學習:FAC
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
使用MATLAB進行無監(jiān)督學習

深非監(jiān)督學習-Hierarchical clustering 層次聚類python的實現(xiàn)
基于半監(jiān)督學習的跌倒檢測系統(tǒng)設(shè)計_李仲年
基于半監(jiān)督學習框架的識別算法
你想要的機器學習課程筆記在這:主要討論監(jiān)督學習和無監(jiān)督學習
如何用Python進行無監(jiān)督學習
機器學習算法中有監(jiān)督和無監(jiān)督學習的區(qū)別
最基礎(chǔ)的半監(jiān)督學習
半監(jiān)督學習最基礎(chǔ)的3個概念
為什么半監(jiān)督學習是機器學習的未來?
半監(jiān)督學習:比監(jiān)督學習做的更好
機器學習中的無監(jiān)督學習應(yīng)用在哪些領(lǐng)域
自監(jiān)督學習的一些思考






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論