") 上海AI lab提出VideoChat:可以與視頻對話啦
上海AI lab提出VideoChat:可以與視頻對話啦
視頻相比語言、圖像,是更復(fù)雜更高級的一類表征世界的模態(tài),而視頻理解也同樣是相比自然語言處理與計算機(jī)視覺的常見工作更復(fù)雜的一類工作。在當(dāng)下大模型的洪流中,自然而然的想法就是大規(guī)模語言模型(LLMs)可以基于語言訓(xùn)練的強(qiáng)大理解推理能力,完成視頻理解的工作嗎?現(xiàn)在答案到來了,上海 AI Lab 提出了以 Chat 為中心的端到端的視頻理解系統(tǒng) VideoChat,集成了視頻基礎(chǔ)模型與 LLMs,并且在如空間、時間推理,事件定位、因果推斷等多個方面都表現(xiàn)十分出色。

區(qū)別于現(xiàn)有多模態(tài)大模型針對視頻輸入的處理方法,即首先文本化視頻內(nèi)容再接入大模型利用大模型自然語言理解的優(yōu)勢,這篇論文從模型角度以可學(xué)習(xí)的方式集成了視頻和語言的基礎(chǔ)模型,通過構(gòu)建視頻基礎(chǔ)模型與 LLMs 的接口,通過對接口進(jìn)行訓(xùn)練與學(xué)習(xí)從而完成視頻與語言的對齊。這樣一種方式可以有效的避免視覺信息、時空復(fù)雜性信息丟失的問題,第一次創(chuàng)立了一個高效、可學(xué)習(xí)的視頻理解系統(tǒng),可以實現(xiàn)與 VideoChat 對視頻內(nèi)容的有效交流。
論文題目:
VideoChat : Chat-Centric Video Understanding
論文鏈接:
https://arxiv.org/pdf/2305.06355.pdf
代碼地址:
https://github.com/OpenGVLab/Ask-Anything
如果要問大模型有什么樣的能力,那我們可能洋洋灑灑從理解推理到計算判斷都可以列舉許多,但是如果要問在不同場景下如何理解大模型的不同作用,那有可能就是一個頗為玄妙的“藝術(shù)”問題。在 VideoChat 中,論文作者將大模型理解為一個視頻任務(wù)的解碼器,即將視頻有關(guān)的描述或更進(jìn)一步的嵌入理解為人類可理解的文本。這一過程可以被形式化的理解為:
這里 與 表示一個圖片或視頻的模型,通過將 I(圖像) 與 V(視頻)輸入到模型中,得到視頻或圖像的嵌入表示 E,而一個解碼的過程,就是:
其中 與 分別表示在第 t 輪中 LLM 的回答和在 t 輪前用戶提出的所有問題及答案, 即一個 LLM 模型。傳統(tǒng)上針對多模態(tài)大模型的解決方法,一般是一種將視頻信息文本化的方法,通過將視頻序列化為文本,構(gòu)成 Video Description,再輸入到大模型之中,這種文本流可以很好的適應(yīng)理解類的工作,但是卻對如時間、空間感知這類任務(wù)表現(xiàn)不佳,因為幾乎是必然的,將視頻信息文本化后很容易使得這類基礎(chǔ)信息出現(xiàn)丟失。而因此論文試圖完成一個端到端的一體化的方法,直接提取視頻的嵌入信息,如下圖對比所示:
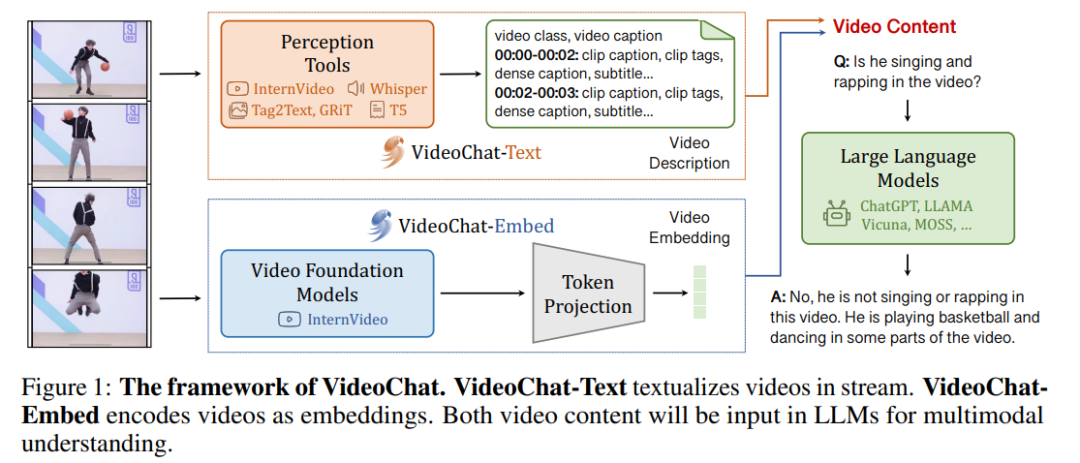
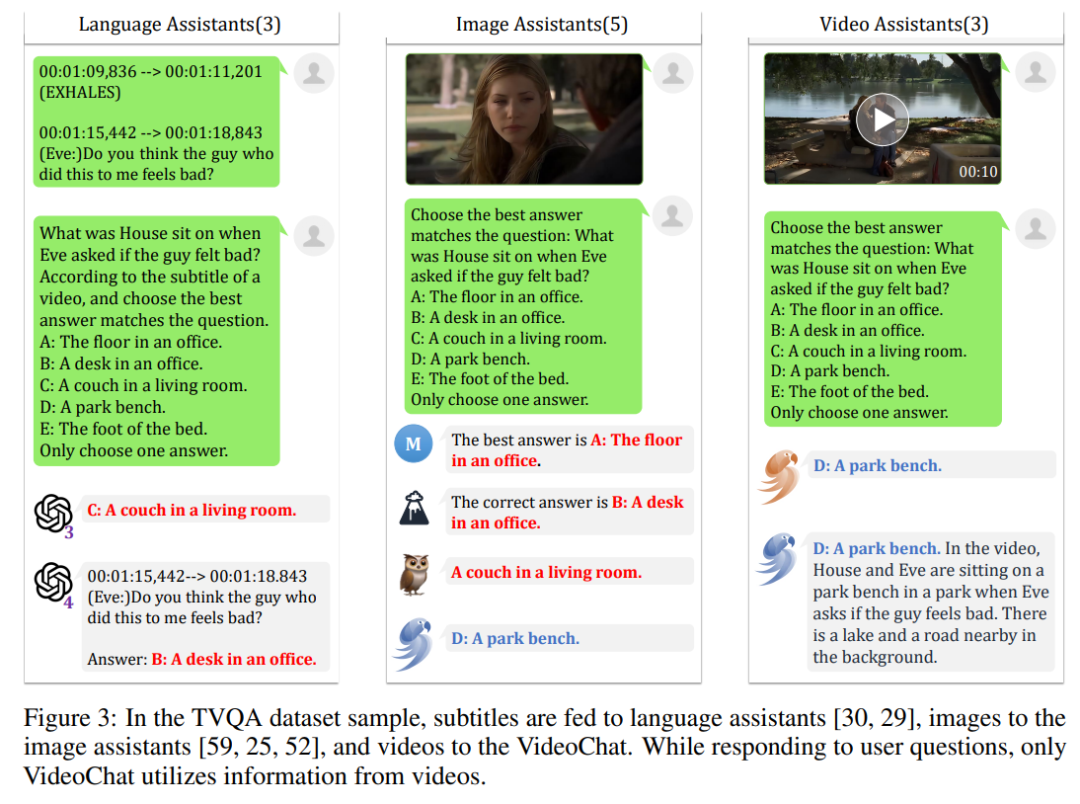
通過整合這樣兩種視頻架構(gòu),即整合 VideoChat-Text 與 VideoChat-Embed 得到的 Video Context 輸入到大模型之中,以獲得更全面的視頻信息理解能力,如在上圖的任務(wù)中,用戶提問“他是在唱、跳和 Rap 嗎”,VideoChat 回復(fù)“不是,他是在打籃球(和跳舞)”
對于 VideoChat-Text 部分,論文作者詳細(xì)的解構(gòu)了一個視頻包含的內(nèi)容,比如動作、語音、對象及帶有位置注釋的對象等等,基于這些分析,VideoChat-Text 模塊綜合利用各種視頻與圖像模型獲得這些內(nèi)容的表征,再使用 T5 整合模型輸出,得到文本化的視頻之中,使用如下圖所示的模板完成對 LLMs 的輸入:

而對于 VideoChat-Embed 則采用如下架構(gòu)將視頻和大模型與可學(xué)習(xí)的 Video-Language Token Interface(VLTF)相結(jié)合,基于 BLIP-2 和 StableVicuna 來構(gòu)建 VideoChat-Embed,具體而言,首先通過 GMHRA 輸入視頻,同時引入圖像數(shù)據(jù)進(jìn)行聯(lián)合訓(xùn)練并接入一個經(jīng)過預(yù)訓(xùn)練的 Q-Former,完成視頻的 Embedding。
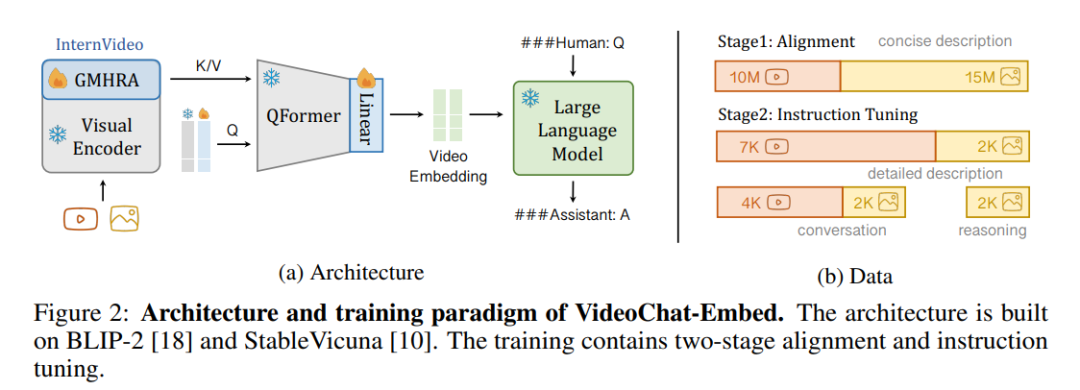
整個訓(xùn)練過程可以分為兩個階段,分別是對齊與微調(diào)。在對齊階段,作者引入了 25M 個視覺-文本對針對接口進(jìn)行微調(diào),整體的輸入提示如下:

而在微調(diào)階段,論文自行構(gòu)建并開源了包含 7k 個詳細(xì)的視頻描述與圖像描述以及 4k 個視頻對話,3k 個圖像描述,2k 個圖像對話,2k 個圖像推理的指令數(shù)據(jù)集對 VideoChat 完成微調(diào)。

對比 LLaVa、miniGPT-4 以及 mPLUG-owl,論文對 VideoChat 的多方面能力進(jìn)行了定性研究。其中,在空間感知與分析中,VideoChat 可以識別日式服裝來推斷出相應(yīng)的音樂,并且確定視頻中的人數(shù)。這即是證明了 VideoChat 識別捕獲視覺元素并給予視覺元素進(jìn)行分析的能力。

在時間感知與分析中,VideoChat 可以識別出視頻中做瑜伽的動作,甚至給出了它摔倒可能性的判斷并進(jìn)行提醒了安全問題。
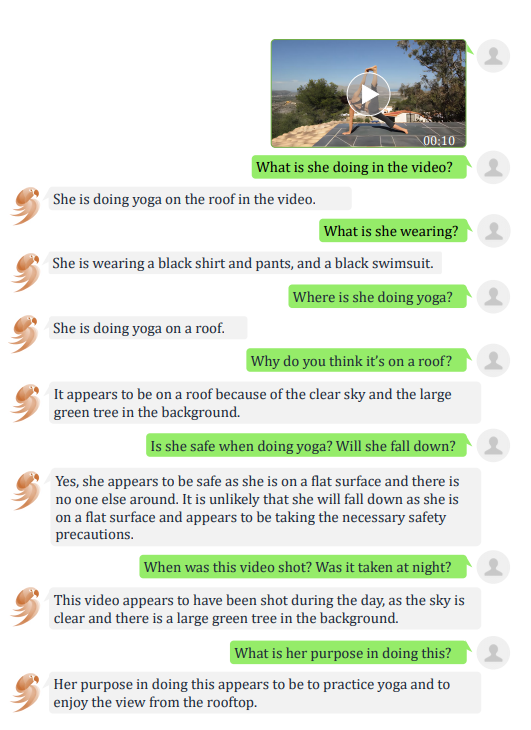
在非正式推斷中,VideoChat 也可以解釋“為什么這個視頻是好笑的”這一問題,并且解釋的也符合我們對視頻好笑的一些抽象判斷,如不協(xié)調(diào),突然性等等。
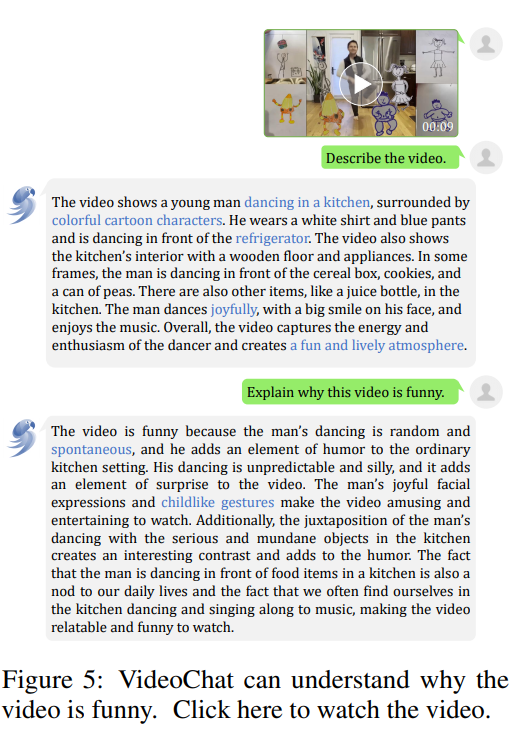
而對比最近的基于圖像的多模態(tài)對話系統(tǒng),VideoChat 可以正確的識別場景,而其他系統(tǒng)則錯誤的將對話環(huán)境視為室內(nèi),這充分的體現(xiàn)了 Video-Chat 在空間感知方面非常強(qiáng)大的比較優(yōu)勢。
這樣一個開源的視頻理解框架可以為視頻理解這樣一個目前還沒有什么非常成熟的解決方案的問題鋪好道路,顯然,將視頻信息與文本信息對齊,大規(guī)模語音模型的優(yōu)秀能力是可以允許他們理解視頻信息。而如果將大模型看作一個有推理、理解能力的黑盒,視頻理解的問題就變成了如何對視頻進(jìn)行解碼以及與文本對齊的問題,這可以說是大模型為這一領(lǐng)域帶來的“提問方式”的改變。
但是針對我們期望的成熟的視頻理解器,這篇工作仍然具有局限性,比如 VideoChat 還是難以處理 1 分鐘以上的長視頻,當(dāng)然這主要是來自于大模型上下文長度的限制,但是在有限的上下文長度中如何更好的壓縮視頻信息也成為一個復(fù)雜的問題,當(dāng)視頻時長變長后,系統(tǒng)的響應(yīng)時間也會對用戶體驗帶來負(fù)面影響。另外總的來說,這篇論文使用的數(shù)據(jù)集仍然不算大,因此使得 VideoChat 的推理能力仍然停留在簡單推理的層級上,還無法完成復(fù)雜一點的推理工作,總之,盡管 VideoChat 還不是一個盡善盡美的解決方案,但是已然可以為當(dāng)下視頻理解系統(tǒng)增添重要一筆,讓我們期待基于它的更加成熟的工作吧!
審核編輯 :李倩
-
Video
+關(guān)注
關(guān)注
0文章
196瀏覽量
45743 -
自然語言
+關(guān)注
關(guān)注
1文章
291瀏覽量
13608
原文標(biāo)題:上海AI lab提出VideoChat:可以與視頻對話啦
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
ESP32P4小智AI演示
正點原子 AI BOX0 智能伴侶,1.54寸高清屏+長效續(xù)航,語音暢聊,情景對話,知識科普,多色可選,隨身攜帶!
芯資訊|WT2605C藍(lán)牙語音芯片:AI對話大模型賦能的智能交互新引擎

單次、多次對話與RTC對話AI交互模式,如何各顯神通?

能和Ai-M61模組對話了?手搓一個ChatGPT 語音助手
《AI Agent 應(yīng)用與項目實戰(zhàn)》----- 學(xué)習(xí)如何開發(fā)視頻應(yīng)用
AI正在對硬件互連提出“過分”要求 | Samtec于Keysight開放日深度分享

行業(yè)集結(jié):共同定制 RK3566 集成 AI 眼鏡的前沿 AR 方案
正點原子ESP32S3系列開發(fā)板全面支持小智AI
商湯科技推出SenseNova-5o,限時免費實時音視頻對話服務(wù)
NVIDIA技術(shù)助力Pantheon Lab數(shù)字人實時交互解決方案
HarmonyOS NEXT 應(yīng)用開發(fā)練習(xí):AI智能對話框
一桿有AI的路燈:感知環(huán)境監(jiān)測路況還能“對話”無人駕駛AI燈桿屏
AI對話魔法 Prompt Engineering 探索指南






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論